
基于模型的强化学习在无人机路径规划中的应用
2022-12-13 13:52杨思明单征曹江郭佳郁高原郭洋王平王景王晓楠
计算机工程 2022年12期
杨思明,单征,曹江,郭佳郁,高原,郭洋,王平,王景,王晓楠
(1.数学工程与先进计算国家重点实验室,郑州 450001;2.军事科学院,北京 100091)
0 概述
随着当前城市内移动通信终端数量的快速增长以及物联网、云计算、高清视频等新应用新技术的迅速发展,大型城市中数据月均流量消耗增长迅猛[1]。无人机升空平台作为辅助地面基站,可为城市提供无线覆盖保障。当前无人机升空平台多采用低空无人机,如何根据环境信息和用户位置信息实时规划路径,以规避建筑物对于信号的遮挡以及调整合适的飞行方向、速度以避免发生多普勒频移造成的快衰落,是当前无人机升空平台在提供无线通信保障任务中亟待解决的问题。
解决上述问题的传统方法是通过对目标区域进行建模,然后使用最优控制算法进行路径规划。ROMERO等[2]利用地面用户和无人机基站之间发送的控制信息,提出一种基于随机梯度下降法的分布式自适应无人机轨迹优化算法。ZENG等[3]研究在已知地面用户位置的情况下使用无人机升空平台为地面用户提供数据传输服务的内容,进行圆形飞行轨迹设计,以在固定时间内最大化地面用户的上行速率。LYU等[4]提出一种高效的螺旋式无人机布局算法,意在使用最少的无人机升空平台,保证每一个地面用户都能被有效覆盖,但是该算法需要无人机平台在固定高度悬停。ALZENAD等[5]设计一个无人机升空平台在三维空间中的评估模型,以利用最小的发射功率实现对于目标区域的覆盖。KALANTARI等[6]提出一种粒子群优化框架,使得可以利用最少数量的无人机完成对目标区域的无线覆盖。AL-HOURANI等[7]根据地面静态用户的位置信息,将无人机升空平台的部署问题表示为一个二次约束混合整数非线性问题,用以得到最优的三维部署方案,最大化地面静态用户的下行速率。但上述算法主要存在以下问题:一是需要对环境进行复杂且精确的建模,而精确建模需要耗费大量时间以及计算资源,并且当前很多实际应用问题并不能准确地建模;二是当前算法更多考虑的是为地面静态用户提供通信覆盖的场景。目前对于地面多移动用户的无人机升空平台实时路径规划方法的研究还处于初期阶段。
基于深度强化学习(Deep Reinforcement Learning,DRL)的方法通过将路径规划任务建模为时序决策优化问题,利用神经网络的泛化性能以及强化学习的优化思想最大化累积收益,使智能体学习到最优策略。文献[8-9]使用DQN 算法[10]对无人机升空平台进行路径规划,以最大化数据传输速率。但该算法只能应用于离散动作空间任务,并且存在价值函数估值过高的问题,对智能体学习路径规划策略造成了偏差。对此,WANG等[11]使用Double DQN 算法[12]优化无人机平台飞行轨迹,用以在对地面所有用户进行覆盖的前提下最大化下行速率。Double DQN 算法弥补了DQN 价值函数估值过高的问题,但仍然不能应用在连续动作空间任务中。同时,由于智能体探索能力随着策略更新次数的增加而下降,智能体会出现收敛到局部最优策略的情况。文献[13-14]使用DDPG 算法[15]成功地将深度强化学习应用在连续动作空间的路径规划任务中,但是该算法超参数过多,在复杂问题中训练速度慢且不稳定。可见,当前DRL 算法在处理路径规划这一类高维状态动作空间任务时,存在探索性能差、训练过程不稳定、样本效率低等问题。针对上述问题,文献[16]提出了基于内在奖励的强化学习算法,使得智能体可以高效地对环境进行探索,并且单调提升策略性能。
目前提升样本效率的方法主要有off-policy 类算法[15,17]以及基于模型的算法。前者由于行动策略与目标策略不同,需要设计合理的重要性采样方法,并对超参数进行反复调整,否则会使学习过程出现较大偏差,导致智能体学习不稳定,收敛到局部最优策略;后者通过使智能体学习环境的动态模型,从而提升样本效率,但当前仍存在探索能力低下[18-19]、数据收集效率较低[20-21]、价值函数预测偏差较大[22-23]的问题。本文研究利用基于模型的方法结合内在奖励强化学习算法,提出基于模型的强化学习算法在无人机升空平台路径规划中的应用,在保证最终性能的前提下提升样本效率,以使用较少数据完成对于智能体的训练。
1 模拟环境构建
本节主要阐述无人机升空平台通信保障任务的模拟环境构建工作,该模拟环境不仅为智能体提供用于训练的经验数据,同时可以作为一个算法验证平台,用于比较各类算法在任务中的性能。为了使得模拟环境贴近实际环境,首先建立城市环境中的空对地信道模型,用于估算不同情况下的路径损耗值。在此基础上,将任务归纳为一个时序决策问题,并使用OpenAI-GYM 架构搭建环境。
1.1 空对地信道建模
本文基于城市环境建立一个空对地信道路径损耗模型,主要考虑城市建筑物对信号遮挡造成的路径损耗。国际电信联盟(ITU)在其官方标准文件中提出一种基于建筑物遮挡对无线电信号传输造成损耗的通用模型[24]。该模型可适用于多种城市环境,将发射机和接收机之间的视距通信及非视距通信传输概率定义为仰角和环境参数的函数,并且通过数学推导,可以得到通过Sigmod 渐进化简后的公式:

其中:a、b为S-curve 参数。
无人机升空平台与用户之间发生非视距传输的概率为:
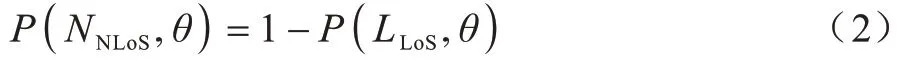
因此,传播模型的路径损耗为:

其中:FFSPL为自由空间损耗,是针对理想全向天线传输计算得到的损耗公式;ηξ是由环境决定的过度路径损耗,ξ代表传播组。本文将传播模型分为视距通信和非视距通信模型,即ξ∈{LLoS,NNLoS}。
总的路径损耗模型可以写为:

其中:PPL是信道模型的总路径损耗,可以计算无人机升空平台与每个地面移动用户之间信号的路径损耗。
1.2 任务优化方程
无人机升空平台通信保障任务的目标是使无人机升空平台在应急通信保障任务期间最大化所有用户的下行速率之和,同时需要保证任何用户的下行速率高于预设的门限速率,并保证每个用户不会出现由多普勒频移造成的快衰落。
无人机升空平台与一个地面移动用户的三维关系如图1 所示。在图1 中,参数h和L分别表示无人机升空平台的飞行高度以及与用户之间的水平面距离,参数Vf和Vm为无人机升空平台及用户的速度向量,d是三维坐标系中无人机平台位置指向用户位置的向量。

图1 无人机升空平台与用户的关系Fig.1 Relationship between UAV aerial platform and user
此外,定义光速为c,信号频率为f,基站发射功率为Ps,带宽为W,高斯白噪声的功率为N。由此,根据多普勒频移定理,可以得到用户m在时隙t收到的信号频率为:

通过式(5)可以计算得到路径损耗PPL(单位为dB)。所以,用户m在时隙t收到的信号功率为:
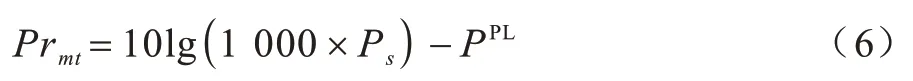
通过香农公式可以得到理论上用户的最大下行速率:

其中:Cmt是用户m在时隙t的下行速率。
定义模拟环境在时隙t的奖励值为:
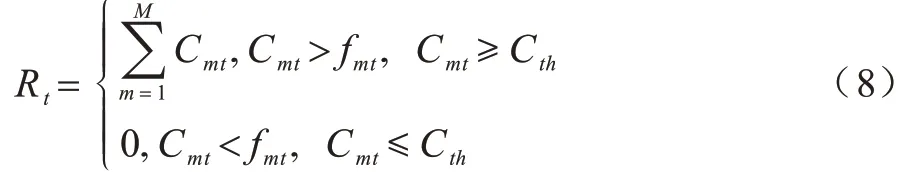
其中:M和Cth分别为用户的数量和任务预设的用户最小门限下行速率。为了防止用户接收信号发生快衰落,需要确保符号时间大于相关时间,即Cmt>fmt。同时,要保证每个用户的下行速率高于设定的门限速度,所以要设置Cmt≥Cth,如果这两个条件都满足,则时隙t的奖励值是所有用户下行速率之和,否则为0。设任务总的收益为:

即设置总的收益为所有时隙奖励值的和,但如果某个时隙的奖励值为0,即触发了约束条件,则任务直接结束。基于上述分析,将无人机升空平台的应急通信保障问题概括为一个马尔科夫时序决策问题,可以采用强化学习的手段进行求解,目标就是最大化累积收益Gt。
在得到时序决策优化方程后,使用OpenAI-Gym架构[25]进行环境构建。任务设置如下:在尺寸为50 km×50 km×5 km 的城区范围内,随机分布着一些高度在50~150 m 的建筑物。无人机升空平台为地面随机分布的10 个移动目标提供通信保障,无人机升空平台可以在0°~360°范围内调整飞行方向,在0°~180°方位内调整飞行仰角,在每小时180~300 km范围内调整飞行速度。无人机升空平台需要保证每个用户的下行速率大于门限速率,同时防止由于多普勒频移造成的快衰落。在此前提下,任务的目标是最大化用户的总下行速率。任务中如果出现飞机碰撞到建筑物,则判定实验结束,并返回-100 的奖励值,如果出现任何一个用户的下行速率低于阈值速率或由于多普勒频移出现了快衰落现象,则判定实验结束,并返回-50 的奖励值;如果在通信保障任务期间未发生上述问题,则返回奖励值100。
2 算法设计
在利用无模型算法进行学习时,为了准确估计价值函数,根据任务的复杂性不同,需要采样上万幕的数据才能得到较为准确的价值估计网络。因此,本文借鉴MVE 算法[23]的思想,采用基于模型的算法对动态模型进行学习,其中包含3 个重要的待学习函数:状态转移函数Tξ(s,a)用来预测后继状态;状态终止预测函数dξ(s)用来预测状态s为终止状态的概率;奖励预测函数rφ(s,a,s')用来预测返回的奖励值。状态价值函数被设定为结合了短期和长期价值函数的形式,短期价值函数是通过学习到的环境动态模型经过数步规划得到的奖励值之和,而长期价值函数则是通过神经网络直接预测得到的价值函数,形式如下:
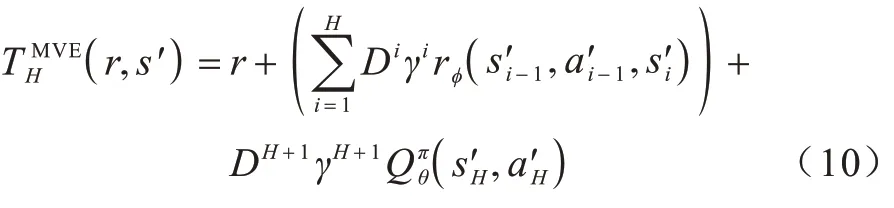
但是MVE 算法只有在当模型复杂度不高,并且在所有学习到的动作价值函数具有相似的误差时具有较好性能。当模型较为复杂时,MVE 算法难以调整固定的超参数H,而模型误差的累积会导致价值函数评估出现严重偏差。为了解决上述问题,需要综合考量H+1 个不同预测步长的MVE 形式的状态价值来计算得到一个合适的价值函数。候选的TD目标为,即考量从0 步规划到H步的H+1 种不同状态价值。传统的方法是使用对于候选目标的平均或者以指数衰减的方法对候选目标值进行加权的方法,本文选择通过平衡Q函数学习中的误差以及规划模型的误差,得到对于候选目标更好的加权方式。针对每个候选,其在规划中有3 个重要参数,分别为Q函数预测参数θ、奖励函数预测参数φ、状态转换函数预测参数ξ,如式(10)所示,它们共同作用组成一个H=i步的TD 目标。为了增强算法的鲁棒性,设置一个候选的TD 目标中有L个预测参数θ={θ1,θ2,…,θL},N个奖励函数预测参数φ={φ1,φ2,…,φN},M个状态转移预测参数ζ={ζ1,ζ2,…,ζM}。
算法的概述图如图2 所示。图2 展示了M=N=L=2 情况下(s0,a0)的TD 目标值的估计值,可以通过这些数据求得的均值和方差。为了找到合适的权值w,使得加权后的TD 目标值之和与真实的动作价值的均方误差最小,将两者的泛化误差进行分解得到:


图2 基于模型算法的概述图Fig.2 Overview figure of model-based algorithm
为使得均方误差最小,使用经验数据中估计得到的方差来估计方差项,并最小化方差项。采用逆方差权重法,将wi设置为Var()的倒数,并对最终结果进行规范化,最终得到加权后的状态价值函数为:

将算法与内在奖励RL 算法以及impala 并行架构结合,最终得到基于模型的内在奖励强化学习算法,算法流程架构如图3 所示。可以看到,算法采用并行架构完全解耦了数据采集和策略更新过程。Worker 独立地进行经验数据收集,在结束一幕数据交互后,同步Learner 最新的策略,并将收集到的数据存入Buffer。Learner 周期地从Buffer 中提取数据进行更新,通过V-trace 方法对行动策略采集到的数据进行重要性采样,得到适合目标策略学习的价值函数预测值,分内部、外部奖励两个部分使用上述基于模型的方法对价值函数进行评估,最终合并内部奖励和外部奖励预测得到的价值函数,并利用PPO 的方法对策略进行更新。实验结果表明,该方法在智能体取得相同性能的情况下提高了样本效率。
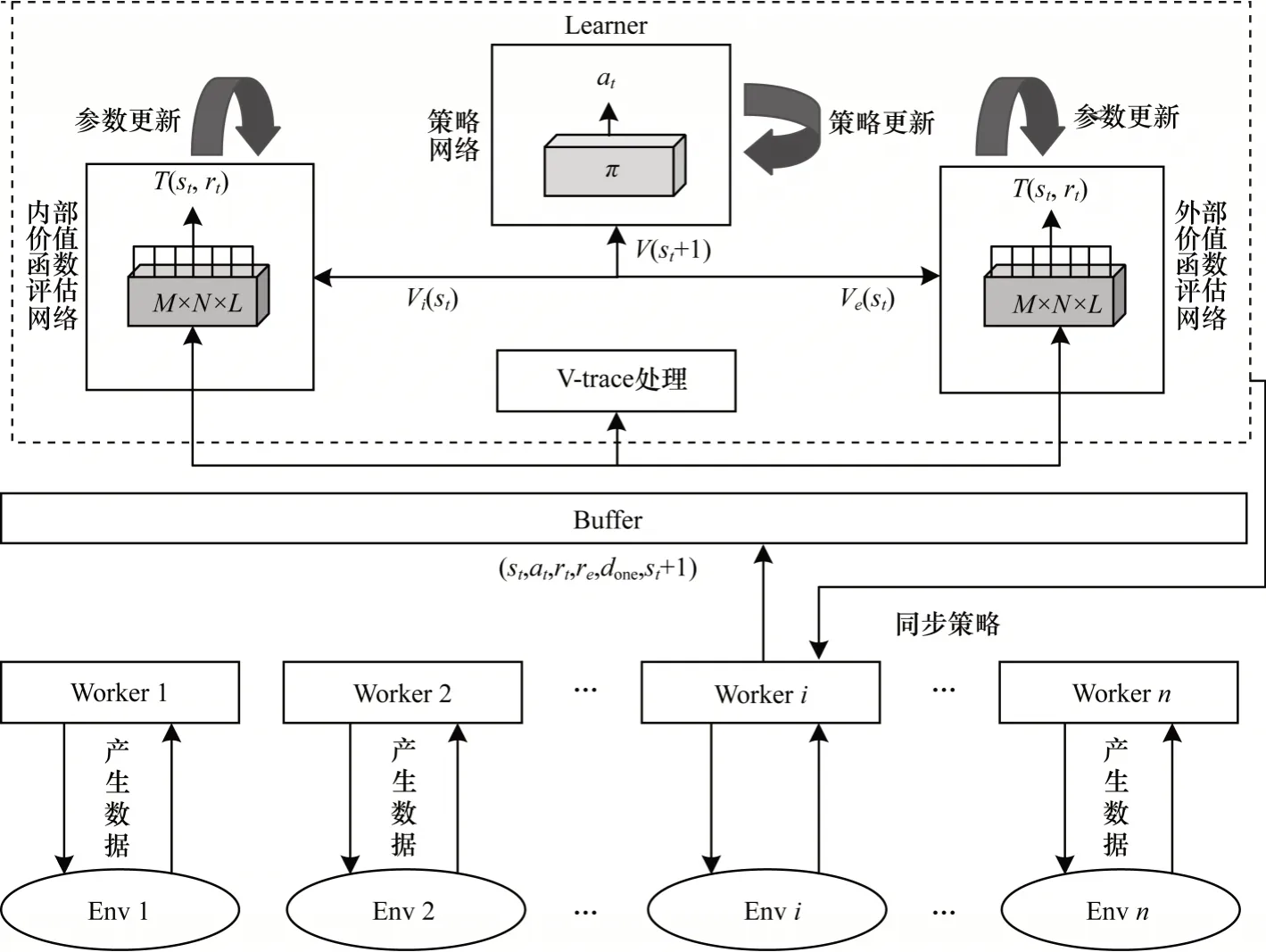
图3 基于模型的内在奖励算法结构Fig.3 Structure of model-based intrinsic reward algorithm
3 实验结果与分析
本文程序使用python3.8 编写,运行环境为Win 10 操作系统,装有2 块NVIDIA 3090 显卡以及64 GB 内存。实验中神经网络均由全连接网络和ReLu 网络组成,使用32 个并行的实验环境进行数据采集。本文提出的基于模型的内在奖励算法与基于Impala 架构的无模型内在奖励算法的性能对比如图4 所示。

图4 不同算法的性能对比Fig.4 Performance comparison of different algorithms
从图4 可以看出,本文算法相较于拥有相同架构但不使用对环境动态模型进行学习的算法具有更好的性能,可以利用很少的经验数据快速完成对于策略的学习,并且学习过程更加稳定。为了比较本文算法与非强化学习启发式算法的性能,基于文献[3-5]的思想,构建一套简化的启发式算法。该算法将当前分布在地面的多个用户包含在一个最小的圆内,要求无人机始终保持在圆心位置,速度方向则为所有用户当前速度向量之和的方向。可以看到,启发式算法在环境中可以达到近6 000 分的水平,微小的波动是由于地面用户在遇到障碍物时进行随机避障,速度方向并不保持一致,从而导致无人机飞行方向发生偏移,进而影响最终得分情况。相较于启发式算法,本文算法在前期学习过程得分较差,但当智能体能够对状态价值函数进行准确评估后,最终算法的得分远高于启发式算法。
此外为了说明的本文算法相较于其他基于模型算法的优势,在模拟环境中采用了多种算法进行测试比较,结果如图5 所示。
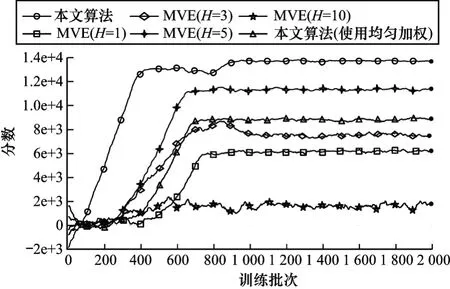
图5 本文算法与不同视界MVE 算法的性能对比Fig.5 Performance comparison between the proposed algorithm and MVE algorithm in different horizons
从图5 可以看出,相比于MVE 采用固定规划值(H)的情况,基于组合规划值的方法训练速度和效果更好,同时训练过程更为平稳,并且对于MVE类规划值固定的算法,如何调节超参数H也是一个难题,从图5 可以看出,当H从1提高到5 的过程中,规划值的增大减小了价值函数预测的方差,而准确的价值函数提高了算法的学习速率,也决定了最终收敛到的策略性能。而当H取10 时,智能体在整个训练过程中波动很大,并且最终无法学习到一个较好的策略。原因在于:在训练初期,当预测模型没有得到准确学习时,过长的规划值会导致价值函数方差、偏差都较大,在这种情况下由于方差、偏差的累积,智能体始终无法学到准确的预测模型参数以及价值函数,这就使得智能体在训练过程中全程无法进行有效的策略迭代。所以,对于固定规划值类的算法,超参数的调整是一个难题。而使用均匀加权训练算法与本文算法有着相同的架构,但在组合规划值时,权值使用的是均匀加权算法。可以看出,该算法的速度和最终性能都与本文算法有差距。
实验中还针对算法对于不同超参数集的鲁棒性进行了研究,利用20 组有较大差异的超参数集对算法进行了测试,并且对最终得分求均值,结果如图6所示。
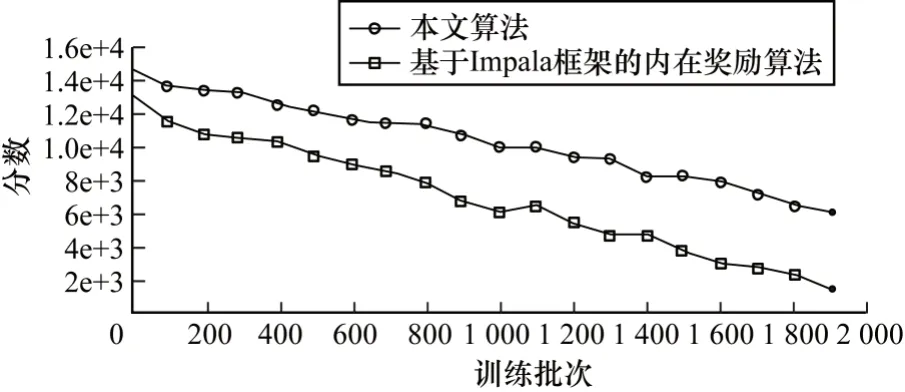
图6 不同算法的鲁棒性对比Fig.6 Robustness comparison of different algorithms
图6 比较了基于模型的权值组合规划值扩展算法与基于Impala 框架的内在奖励算法在20 组不同超参数集下作用于模拟环境中的平均得分。从图6可以看出,基于Impala 框架的内在奖励算法在使用接近20 组超参数集时,其得分均值已低于2 000 分,而基于模型的权值组合规划值扩展算法稳定在6 000 分左右。实验结果表明,基于模型的算法针对不同超参数具有更强的鲁棒性。原因在于:基于模型的权值组合规划值扩展算法在训练过程中对于环境动态模型的学习,在一定程度上弥补了超参数设置带来的价值函数预测偏差。
4 结束语
本文针对强化学习算法在无人机升空平台路径规划任务中存在的样本效率低的问题,提出基于模型的内在奖励强化学习算法。通过将任务概述为一个时序决策优化问题,基于OpenAI-GYM 构建模拟环境,并结合规划与预测的方法提高价值函数的评估准确性。实验结果表明,该算法在保证智能体性能的前提下,在样本效率、学习速度、算法鲁棒性上都有较大提升。下一步将研究提升算法的迁移能力,并结合迁移学习和元学习的思想对算法进行改进,以将训练完毕的智能体投入到相似的场景中执行任务。
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
中学生数理化·中考版(2021年3期)2021-07-22
新世纪智能(数学备考)(2020年9期)2021-01-04
今日农业(2020年23期)2020-12-15
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
国防(2019年7期)2019-08-21
领导决策信息(2018年50期)2018-02-22
商周刊(2017年5期)2017-08-22
中国卫生(2016年2期)2016-11-12
太空探索(2016年8期)2016-07-10
