
基于条件生成对抗网络的深度点过程二次预测
2022-12-13 13:52:16卞玮李晨龙侯红卫
计算机工程 2022年12期
卞玮,李晨龙,侯红卫
(太原理工大学 数学学院,太原 030000)
0 概述
时序点过程是建模不规则时间间隔事件序列的概率生成模型,并在现实建模中成为处理这一问题的有效数学模型[1]。时序点过程将历史事件的依赖关系嵌入到强度函数的表达式中,得出事件发生时间间隔的概率密度函数[2],进而进行预测与分析。然而,传统统计建模方法严格限定强度函数形式,从而导致建模能力较弱。近年来,为了解决这一问题,DU等[3]提出将历史信息嵌入到循环神经网络(RNN)的隐藏状态中,利用深度学习的方法拓宽时序点过程的建模途径。此后,涌现出很多基于RNN 的时序点过程模型[4-5](本文简称深度点过程),使得强度函数或者时间间隔概率密度函数更加灵活多变[6-7]。目前,深度点过程在效果上达到甚至超越了传统点过程模型,为时序点过程在实际中的应用提供了更加有效的方案。然而,深度点过程灵活性的支撑是深度神经网络参数化的非线性变换,这造成在求解时间预测值时,时间间隔概率密度函数难以显式表达或者积分不存在解析解的问题,需要通过数值方法近似求解。此外,模型本身的系统误差也同样导致时间上的预测值与真实值之间的偏差较大。这两点原因造成的预测精度不足限制了深度点过程在实际场景中的应用,为深度点过程在实践中的推广带来极大挑战。
时序点过程序列可以理解为一连串相互关联的概率分布下的样本,因此,产生的偏差可以假设为分布上的差异。图像去运动模糊算法使用条件生成对抗网络(CGAN)[8]去除因抖动、光晕、运动而产生的图像模糊,从而提高图像的清晰度[9-10]。受此思路启发,本文将深度点过程预测值序列与真实值序列的偏差视为由模型及数值方法带来的“模糊”,即预测值序列和真实值序列在分布上的差异,使用CGAN 对预测值序列进行二次预测修正。此外,考虑到点过程序列是一个随机过程而非随机变量[11],本文采用时序点过程Wasserstein距离的对偶形式及1-Lipschitz 正则项对CGAN 进行约束[12-13],从而提高时间预测的准确度并降低预测的均方误差。
1 相关工作
1.1 时序点过程
时序点过程是一类特殊的计数过程,如图1 所示,其对时刻t之前的事件数量进行计数,核心是强度函数λ*(t)。若历史事件Ht={ti|ti 图1 时序点过程示意图Fig.1 Schematic diagram of sequence point process 其中:N(t)表示t时刻之前事件发生的总次数;E(dN(t)|Ht)是给定历史观测值Ht的情况下在时间间隔[t,t+dt)中发生的平均事件数。事件发生时间间隔概率密度函数为: 其中:t′为t时刻之前最后一个事件发生的时刻。 深度点过程是以RNN 嵌入式表达历史事件序列发生的潜在信息,并将强度函数或者事件发生时间间隔概率密度函数视为历史潜在信息非线性函数的点过程建模方法。相较于传统统计学上的点过程建模方法,深度点过程利用了神经网络强大的拟合能力,但同时带来大量的网络参数和一系列的非线性变化,对时间预测造成了困难,需要用数值方法来解决。例如,循环标记时序点过程(RMTPP)[3]将条件强度函数形式化为Gompertz 分布: 其中:vt、ht′、wt、bt均由神经网络得出。进而,事件发生时间间隔概率密度函数为: 由于式(5)中的积分通常不具有解析解,需要使用数值方法近似求解,因此产生了偏差。类似地,全神经网络时序点过程(FullyNN)[14]通过神经网络直接输出强度函数的积分: 但是,强度函数λ*(τ)只能通过Φ(t)求导得出,无法得到显示表达式,因此,使用中位数t*做预测值。然而,t*需要二分法求方程Φ(t*-t′)=loga2 的根得出,无法获得解析的最优解,存在数值误差。同时,由于模型设计上的缺陷,这两种模型都存在系统误差,即使巧妙地避开数值误差也会存在系统误差。例如,混合对数正态时序点过程(LogNormMix)[15]使用混合对数正态分布拟合时间间隔的概率密度函数: 通过上述过程后不存在数值误差,但由于大小不可控,容易出现极端值,对预测精度有很大影响,从而导致系统误差。 SHAHAM等[8]提出的CGAN是一种带条件约束的概率生成模型。CGAN 引入条件变量y作为辅助信息(类别标签、其他模态数据等),指导生成器的生成,其损失函数比生成对抗网络(GAN)[16]多加入额外的条件信息y,如下: 在训练时,WGAN[17]采用分布间的Wasserstein距离改进GAN,以减缓GAN 训练不稳定的问题。 图像去运动模糊的目标是将因抖动、光晕、运动而产生的模糊图像恢复成清晰图像[9-10],其模型定义为: 其中:IB、IS和K分别代表向量化的模糊图像、原始清晰图像和模糊核;B代表噪声;⊗代表卷积运算。图像去运动模糊过程是式(10)的逆操作,即从模糊图像IB中还原出清晰图像IS。由于CGAN 拥有概率生成模型的特性,能够对图像分布进行还原变换,因此通常被用来实现上述逆操作。 借鉴图像去运动模糊的原理,将深度点过程模型由于数值积分与模型本身造成的预测值序列误差视为与真实值序列分布上的差异[18],然后通过条件生成对抗网络还原初次预测值序列为真实值序列。 设输入的初次预测值序列为τ=,对应的真实值序列为t=,二次预测模型假设为: 其中:K为变换矩阵;N=为噪声序列。 由于原始WGAN 假设处理的数据为随机变量,这与时序点过程(属于随机过程)在样本空间上存在差异。对此,采用时序点过程之间的Wasserstein 距离来约束生成对抗网络的训练以保证理论上的正确性,其具体形式为[13]: 其中:x、y为2 个点过程的实例。 条件生成对抗网络中生成器的功能是逆向还原初次预测值序列为对应的真实值序列,也称伪值序列。判别器的目标是最大化生成器还原出伪值序列的时序点过程分布与对应真实值序列的时序点过程分布之间的Wasserstein 距离(初次预测值序列与真实值序列的对应关系为额外的辅助信息): 其中:Pt、Pg分布分别为真实值时序点过程分布、伪值时序点过程分布;φ为Pt、Pg的联合分布集合;g为CGAN 生成器的函数表示。为了便于计算处理,将式(13)转化为对偶形式[13]: 其中:f为CGAN 的判别器函数;|·|*为时序点过程之间的距离;‖f‖L≤1 为1-Lipschitz 约束[7]。 首先训练深度点过程模型得出初次预测值序列,接着对初次预测值序列进行修正[17]。二次预测流程分为3 个步骤: 步骤1将初次预测值序列τ输入条件生成对抗网络的生成器g中得出伪值序列g(τ),用ζ=g(τ)。 步骤2将伪值序列ζ及对应的真实值序列t输入判别器f中分别求出得分f(ζ)、f(t),以判别真假。 步骤3通过对抗训练得出具备还原能力的生成器。 算法训练过程中生成器g的损失函数为: 其中:w为生成器g的参数。 判别器d的损失函数为: 其中:V 为判别器d的参数。 二次预测模型中使用的条件生成对抗网络在结构上采用CGAN+LSTM[19-20]的形式,其中,LSTM(长短期记忆网络)是RNN 的一种常用变体。本文条件生成对抗网络结合了CGAN 的概率生成能力和LSTM 的嵌入历史潜在信息的能力,以达到准确还原初次预测值序列点过程分布并得到修正后二次预测值序列的目的[21]。在网络结构上,按作用可分为历史潜在信息读取、空间变换以及生成器/判别器输出层3个模块,如图2所示。 图2 条件生成对抗网络结构Fig.2 CGAN structure 2.3.1 历史潜在信息读取 在生成器和判别器中都需要将输入的序列(生成器为初次预测值序列,判别器为伪值序列或者真实值序列)中包含的历史潜在信息嵌入到神经网络中[22]。在生成器和判别器中,先使用LSTM 逐时间步读取序列中的数据,提取历史潜在信息。在保证分布转换前后时间连续的前提下,得到固定特征维度为d(d>1)的向量表示: 其中:x∈Rl×1为生成器或判别器的输入;v0∈Rl×d为对应的历史潜在信息向量;LSTM 表示LSTM 网络。 2.3.2 空间变换 在生成器中,通过LSTM 取得历史潜在信息向量后,需要使网络具备调整读取到的历史潜在信息为真实历史潜在信息的能力[23],网络中借助全连接层的空间变换和整合信息的能力来实现这一目的。 首先,将v0通过一个全连接层,变换潜在历史信息向量的空间维度d→h(h>d),从而到达更高的维度空间: 其中:Dense1表示全连接层;v1∈Rl×h。 变换空间之后,为了整合高维度空间带来的信息,使用2 个连续降低特征维度的全连接层h→k(k 其中:Dense2、Dense3表示2 个全连接层;v2∈Rl×k;v3∈Rl×n。 2.3.3 生成器和判别器的输出层 生成器的功能是得到一组序列长度与输入序列相同并且值大于零的时间序列,因此,在结构上首先采用一个全连接层将调整后的历史潜在信息整合为维度是l×1 的向量,然后经过Sigmoid 函数将向量值的范围约束为大于零,最后输出一组与输入序列同时间步长的伪值序列。以上过程形式上可以表示为: 其中:vg∈Rl×n表示生成器经过LSTM 及信息空间变换后的向量;vg∈Rl×n;ς∈Rl×1;Dense4表示全连接层;Sigmoid 表示Sigmoid 函数。 判别器的功能是输出序列真假评分,评分越高说明输入序列为真的可能性越大。在网络结构上,首先将伪值序列或者真实值序列的历史潜在信息向量在时间步维度上相加,然后经过一个全连接层整合信息,最后通过Sigmoid 函数输出大于零的评分。以上过程形式上可以表示为: 其中:vd∈Rl×n表示判别器经过LSTM 及信息空间变换后的向量;v5∈R1×n;v6∈R1×n;Score ∈R1×1;Dense5表示全连接层。如图2 所示,除最后一层外,结合层归一化操作(LN)[25]与Dense 层来缓解过拟合问题并加速训练。 为了检验二次预测方法的有效性,本文分别选取5 个仿真数据集和4 个真实数据集进行实验,数据均以Python 字典形式储存在.pickle 文件中。4 种用于仿真实验的数据参数设置如下: 1)齐次泊松过程(Poisson)。齐次泊松过程的条件强度函数形式为λ*(t)=1。 2)更新过程(Renewal)。更新过程的时间间隔服从对数正态概率密度函数: 参数设置为µ=1.0,σ=6.0。 3)自校正过程(Self-correcting)。自校正过程的条件强度函数形式为: 4)霍克斯过程(Hawkes)。霍克斯过程的条件强度函数形式为: 对于霍克斯过程,分别设置两组参数: (1)M=1,μ=0.02,α1=0.8,β1=1。 (2)M=2,μ=0.02,α1=0.4,β1=1,α2=0.4,β2=20。 真实数据集采用饭馆评论数据集Yelp toronto、网络慕课交互数据集Mooc、重症监护医学数据集Mimic 和维基百科修改数据集Wikipedia。真实数据集描述如下: 1)Yelp toronto 数据集来自对多伦多300 家最受欢迎的餐厅的评论序列,每条记录都表示某个餐厅的顾客光顾的时间序列。 2)Wikipedia 公共数据集是在维基百科编辑情况序列,其选择一个月内编辑次数最多的1 000 个页面作为研究对象,生成157 474 条用户交互数据。 3)Mooc 数据集是哈佛大学和麻省理工学院联合发布的公开数据集,包含7 047 名学生在Mooc 在线课程中的97 类互动信息。 4)Mimic 数据集是由贝斯以色列迪康医学中心(BIDMC)提供的重症监护医疗信息公开数据集,其记录了4 万多名患者的75 类诊断治疗数据,并选取至少出现3 次的病人作为研究对象。 本文选取3 种被学术界认可的深度点过程模型,分别为循环标记时序点过程(RMTPP)、全神经网络时序点过程(FullyNN)、混合对数正态时序点过程(LogNormMix),以产生初步的预测数据。其中,MTPP、FullyNN 用于探究数值误差和系统误差同时存在时的偏差,LogNormMix 用于探究由于系统误差而产生的偏差。此外,选取均方误差(RMSE)作为实验的度量指标,并对比二次预测前后的差异来验证本文方法的有效性。 模型采用Adam 优化方法动态调整学习率,避免模型参数陷入次优解。优化方法的初始学习率设置为α=1e-4,一阶和二阶指数衰减率分别设置为β1=0.5,β2=0.9。模型的训练批量设置为64,训练100 次循环并应用提前停止的方法,在每次循环训练过程中,训练5/10 次判别器后训练1 次生成器。 为了从客观上反映模型的二次修正效果,本文对比RMTPP、FullyNN、LogNormMix 在经过模型二次预测前后时间预测RMSE 值以及其下降的百分比,实验结果如图3、表1 所示,在表1 中,加粗表示二次预测及标准差。 图3 二次预测后RMSE 下降百分比Fig.3 Reduction percentage of RMSE after the second prediction 表1 二次预测前后的RMSE值Table 1 RMSE values before and after the second prediction 从图3 可以看出,二次预测后RMSE 均有不同程度的降低,其中最大降低99.86%,最小降低21.18%,平均降低77.02%,这说明本文所提模型拥有优异的修正能力,同时印证了理论假设的合理性。从RMTPP、FullyNN、LogNormMix 之间的差异上看,平均下降百分比由高到低排序为RMTPP(92.48%)>LogNormMix(74.03%)>FullyNN(64.32%),这可解释为:RMTPP 采用单峰Gompertz 分布拟合强度函数,系统误差高,且求期望数值积分时反常积分不收敛,数值误差较大;LogNormMix 采用混合对数正态分布计算期望时受到预测方差极端值的影响而造成预测值波动较大;FullyNN 输出条件强度函数的积分且预测求解中位数时采用类似二分法的方法求根,误差较小。因此,3 个模型误差大小排序为RMTPP >LogNormMix >FullyNN,更大的误差使得伪样本与真实样本更易区分,判别器在对抗训练中更易达到最优解从而促进生成器的学习。 为检验模型训练抵抗随机因素影响的鲁棒性,对每个数据的每种基线方法都进行10 次训练,得出均值和标准差如表1 所示,从中可以看出,标准差的均值在0.1%以内,这表明模型训练稳定,受随机扰动影响较小,鲁棒性较强。 本文所提模型对FullyNN 在Hawkes 1 数据集上训练时的损失函数如图4 所示,因为其他损失函数收敛情况大同小异,所以不再冗余表述。从图4 可以看出,判别器的损失在最开始的迭代中逐次提高,这时判别器的判别能力逐渐提升导致生成器损失降低。当判别器损失达到第一个峰值后,生成器损失逐渐提高,开始具备一定的生成能力,之后当生成器生成能力提高到第一个峰值后判别器损失又逐步提高。模型在对抗训练约70 个迭代周期后,生成器损失维持动态稳定同时判别器损失接近0,达到均衡状态[26]。较少的迭代次数也表明生成器的能力容易在对抗训练中得到有效提高。 图4 损失函数曲线Fig.4 Loss function curves 本文建立一种深度点过程二次预测模型。使用条件生成对抗网络对深度点过程的预测数据进行二次预测,通过逆变换初次预测值序列为真实时序值序列在点过程上的差异,以降低因模型系统误差和数值计算误差而带来的预测偏差。在条件生成对抗网络的损失函数中利用时序点过程Wasserstein 距离的对偶形式及其1-Lipschitz 约束来训练网络。实验结果表明,本文模型可以稳定有效地降低时间预测偏差,同时条件生成对抗网络的损失容易达到对抗平衡。下一步考虑将其他类型的生成对抗网络及自注意力网络应用于深度点过程二次预测模型中,以提高时间预测效果。

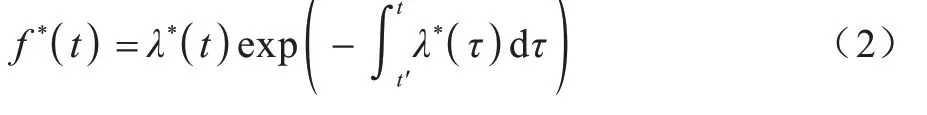
1.2 深度点过程及预测瓶颈
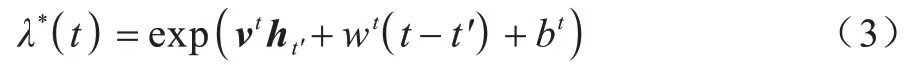
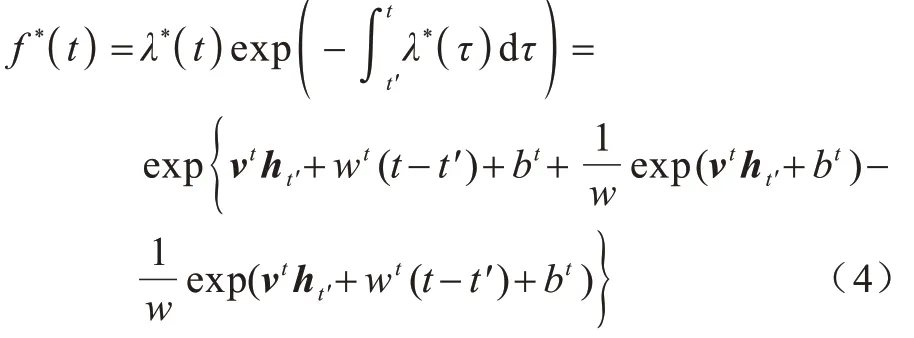



1.3 条件生成对抗网络
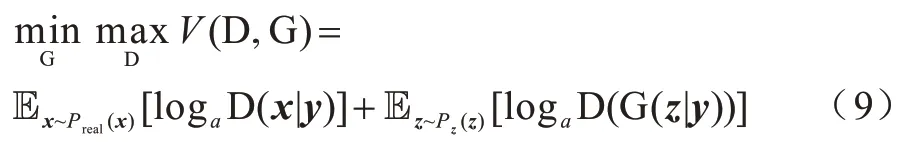
1.4 图像去运动模糊

2 深度点过程二次预测模型
2.1 二次预测原理
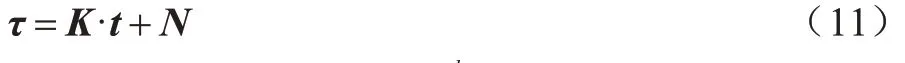

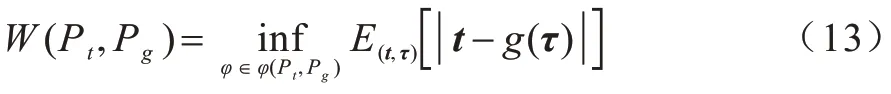
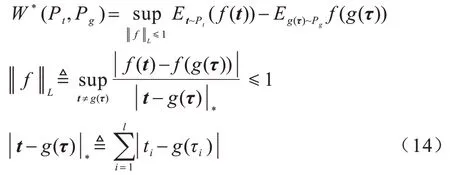
2.2 二次预测算法及训练流程

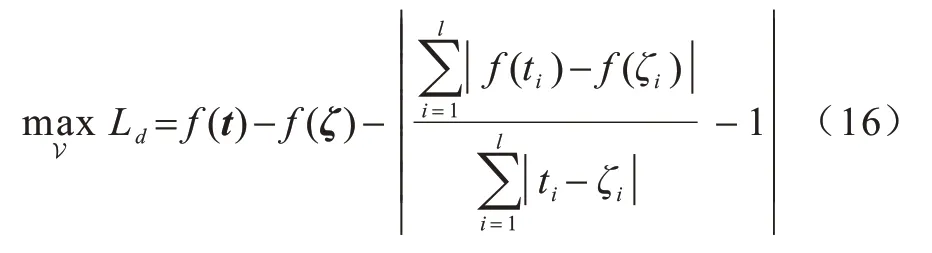
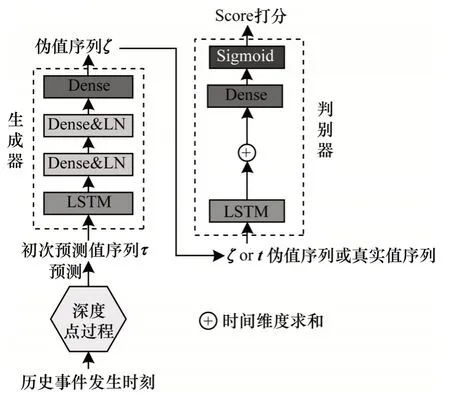
2.3 条件生成对抗网络结构





3 实验结果与分析
3.1 数据集
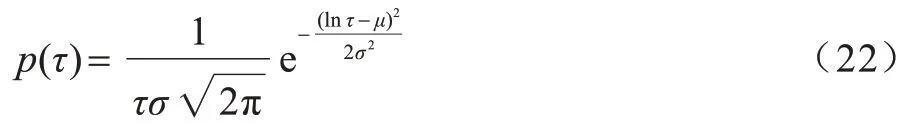

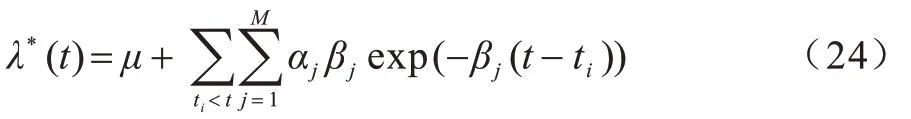
3.2 数据基准模型和实验设置
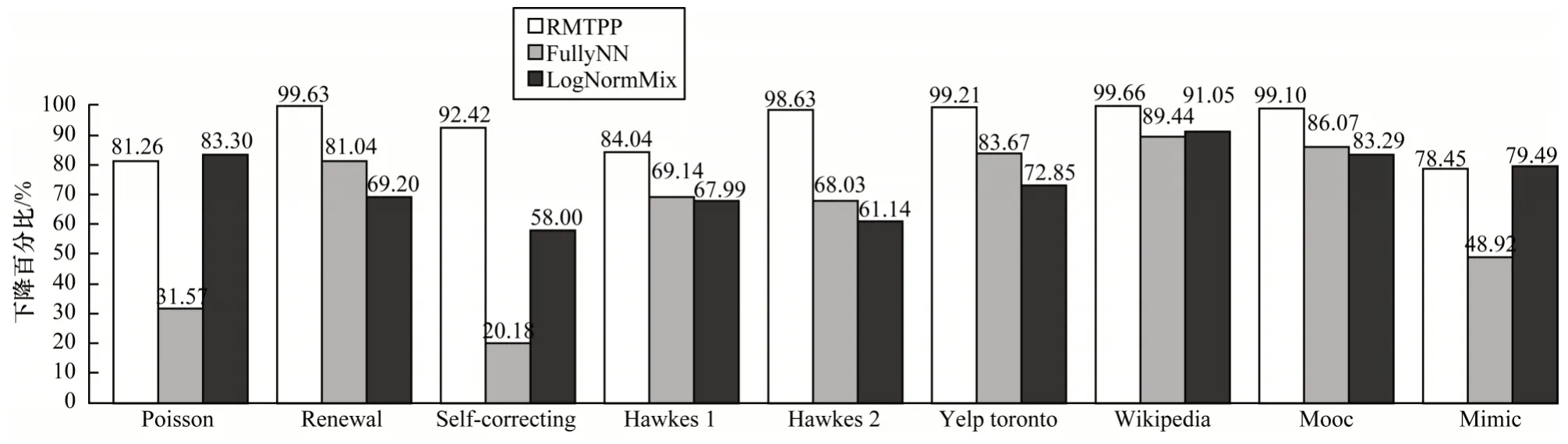
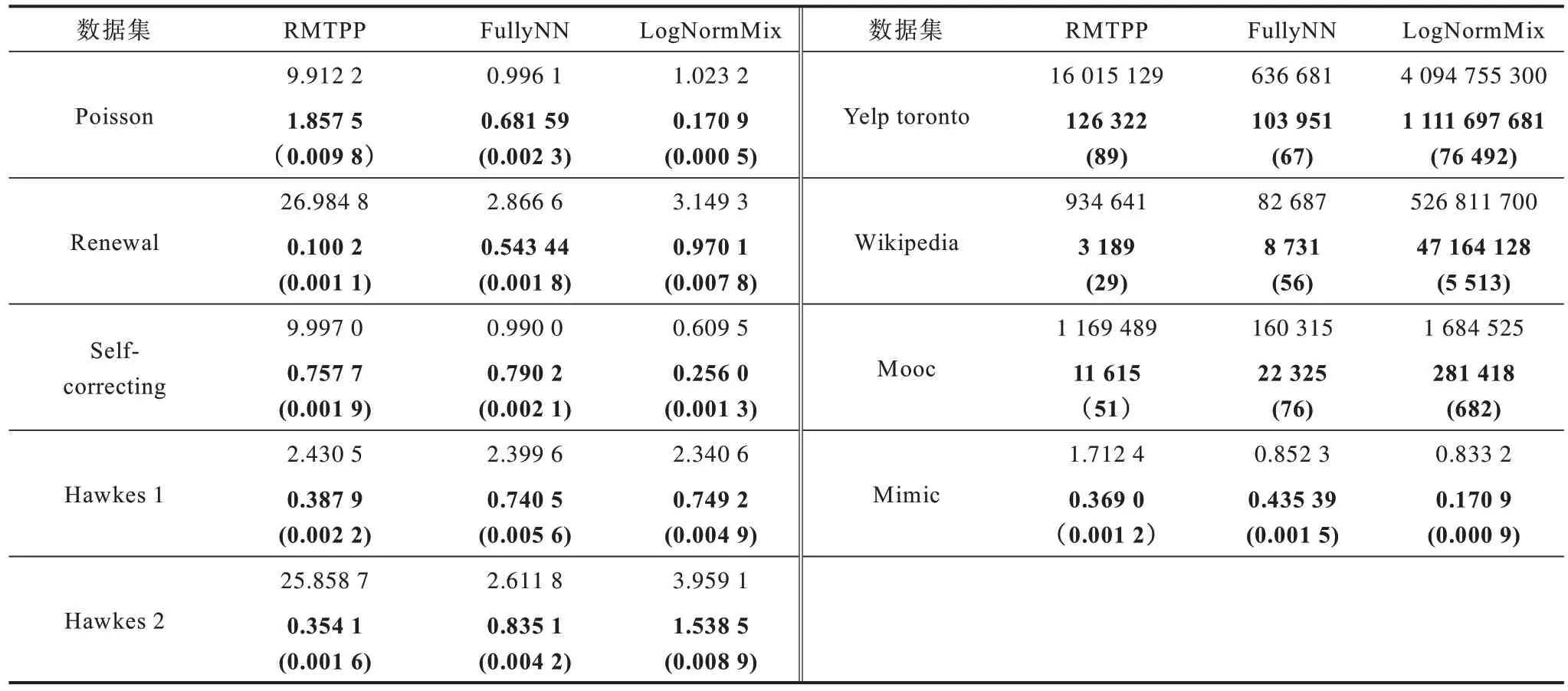
3.3 结果分析
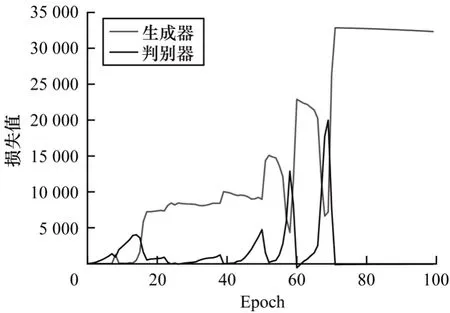
3.4 模型损失
4 结束语
猜你喜欢
《学习方法报》历史中考版(2024年8期)2024-12-31 00:00:00企业界(2024年8期)2024-07-05 10:59:04今日农业(2021年19期)2022-01-12 06:16:32中国农业信息(2021年3期)2021-11-22 06:44:48环境保护与循环经济(2021年7期)2021-11-02 08:10:54中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52国外核新闻(2020年8期)2020-03-14 02:09:19艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26艺术品鉴证.中国艺术金融(2018年12期)2018-08-26 06:03:48
