
分布式链路异常日志采集方法研究
2022-12-13 10:56刘锦鸣
机电信息 2022年23期
刘锦鸣
(兴业数字金融服务(上海)股份有限公司广州分公司,广东 广州 510000)
0 引言
随着互联网业务快速扩展,软件架构设计也变得愈发复杂,为满足大量客户高并发的请求,系统逐步走向分布式,如单体架构的服务拆分为微服务,这些微服务构成了复杂的分布式网络。同时,复杂的分布式调用网络可能会有成千上万的服务,如果一个服务出现问题,可能会导致数十个服务出现异常,对异常问题的排查将十分困难。
分布式链路跟踪[1]是将分布式请求还原成请求的调用链路,如一次点击请求的处理过程,经过多个服务及实例。当出现异常节点时,需采集异常节点的全链路信息,文献[2]探讨了基于采样方式采集异常链路,该策略能提升异常链路采集速率,但实际生产中99.99%的非异常日志对问题排查作用不大,而0.01%的异常日志则起到关键作用。在保证异常日志链路查全率的前提下,提高异常日志采集速率能在业务高峰期起到重要作用。
本文提出了一种分布式链路异常日志采集方法,能在保证异常日志链路查全率的前提下,提高异常日志采集速率,以提升服务异常时的运维排查效率。
1 分布式技术
1.1 分布式系统
分布式系统是指由多台在网络上分散的计算机通过网络连接而成的系统,系统的计算处理逻辑和控制功能分布在这个系统网络的计算机上。而计算机的分布式部署就是将微服务应用有规则地分散在多台独立运行的计算机设备上,同一功能的微服务应用可能同时部署到多台计算机上,利用多台计算机服务器进行应用的负载均衡。
1.2 链路跟踪
链路跟踪在请求调用链路还原、调用网络重构方面对分布式服务起到关键作用[3],可以协助运维人员快速定位分布式服务框架下的请求调用链路,提高微服务的运维定位效率。
一个请求接口内可能调用了多个应用服务,排查接口内的异常节点,需要清楚请求服务调用多个服务的顺序,就是调用链。为了实现调用链,对请求调用的每个服务按先后排序标记唯一标志,该标志定义为spanId;为了标志每次请求的调用情况,需要对每一次请求也标记唯一标志,该标志定义为traceId,如图1所示。
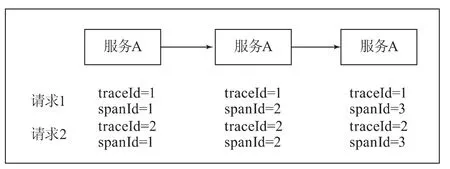
图1 分布式调用链
1.3 翻滚时间窗口
翻滚时间窗口指的是读取数据的窗口所含时间长度固定,若时间窗口设定为n s,则该时间窗口只读取当前n s内的数据,而不会读取前n s或后n s的数据,且时间连续,窗口不会出现重叠。
2 框架构建
2.1 基于翻滚移动窗口实时提取分布式流数据方案
随着业务的办理,业务执行日志将不断产生,并实时写入日志服务器。由于日志数据是实时产生并写入日志服务器的,读取日志数据就是一个面向流处理的场景[4-5],并非批处理的场景。每个日志服务器上的数据都是从上到下逐条写入,且时间上是顺序的。
因此,基于翻滚时间移动窗口读取日志流数据,该方案是每次在日志服务器从上到下按照固定时间长度非重复性地读取该时间段内日志数据。时间窗口是基于历史统计请求的最长时间×1.1获得,应用历史统计最长时长记为Reqmax,时间窗口宽度记为W,即W=Reqmax×1.1。
2.2日志数据暂存
每个时间窗口宽度提取出的日志数据将作为一个集合,并对每个集合按从小到大的顺序分配编号setId(eg:1,2,3,…)。同时,对当前集合的每条数据进行遍历,每条日志数据所含的标志字段有:traceId(请求标志)、status(请求状态)。由于请求是并发的,可能在短时间内大量请求进入系统,不同请求的traceId不同,每经过不同的应用服务后,都会产生相应的日志并存入日志文件,这样就造成同一个traceId下日志中间会存在各个不一样的traceId的请求调用到不同应用产生的日志,同一个traceId不同应用服务的日志将不会连续。
所以,为了把相同traceId的请求日志区分出来,引入了日志数据存入数据结构:Map
2.3 提取异常日志traceId
一个稳定的系统,业务办理的成功率都在99.99%以上,这些业务成功办理的日志信息对于极少数业务办理失败的原因排查无关紧要,最重要的是业务办理时出现的问题信息,需要通过暴露出来的异常信息进行排查,才能解决存在的问题。
然而,为了区分正常和异常的日志,需要把重要的异常日志从大量的日志信息中提取出来。通过判断读取出来的日志信息,判断该日志信息的状态是否为200,如果为非200,那么该日志为异常日志,需要把该日志所在读取的批次setId和该日志的traceId记录到错慢日志集合,并用Map
2.4 计算
通过上述三个步骤,完成对日志流数据的实时按批次读取和按批次存储,把识别到的异常日志对应的traceId提取出来,并使用集合方式存储起来。
以异常集合的traceId为出发点,从暂存的数据中提取出涉及该链路的所有节点日志数据。由于日志数据是按批次读取的,所以异常日志traceId也是按集合批次进行存储区分。但落在当前setId集合里的链路日志,可能存在该链路数据落在相邻的setId集合里,为了确保囊括该请求链路所有节点的日志数据,需要把setId集合的前后两个setId集合对应traceId提取出来。
所以,计算setId=n的日志数据时,需2.3点提到的集合(n-1,n,n+1)∈setId,并从2.2的traceId集合里获取key值一致的traceId所对应的List
3 实验
采用日志大小为4 GB的日志服务器作为日志流输出口,异常日志采集服务器分类4G内存。通过上述方法对日志流数据进行异常日志链路采集。通过对日志流输出进行调整,测试采用上述方法在不同日志流输出速率下的异常链路采集时长。
设定日志流速率在700~1 650 MB/s范围内,日志流速率间隔为50 MB/s,调整日志流速率,日志采集时长/日志流时长、异常日志查全率统计如图2所示。当日志流速率在1 200~1 300 MB/s时,采集时长和日志流时长的比值大于1,表明采集时间比日志流时间长,并且随着日志流速率提高,采集时间与日志流时长比值增大,那么异常日志采集最高速率在1 200~1 300 MB/s为宜。
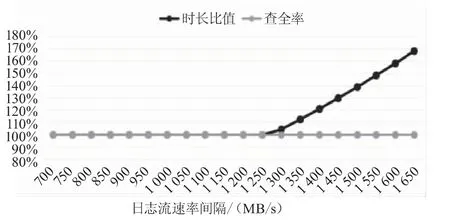
图2 700~1 650 MB/s速率的采集时长/日志流时长、异常链路查全率
为了更精确地获取异常日志采集速率,设定日志流速率在1 150~1 340 MB/s范围内,日志流速率间隔为10 MB/s,调整日志流速率,日志采集时长/日志流时长、异常日志查全率统计如图3所示。当日志流速率大于1 260 MB/s时,采集时长和日志流时长的比值大于1,如表1所示,表明采集速率达到最大值。
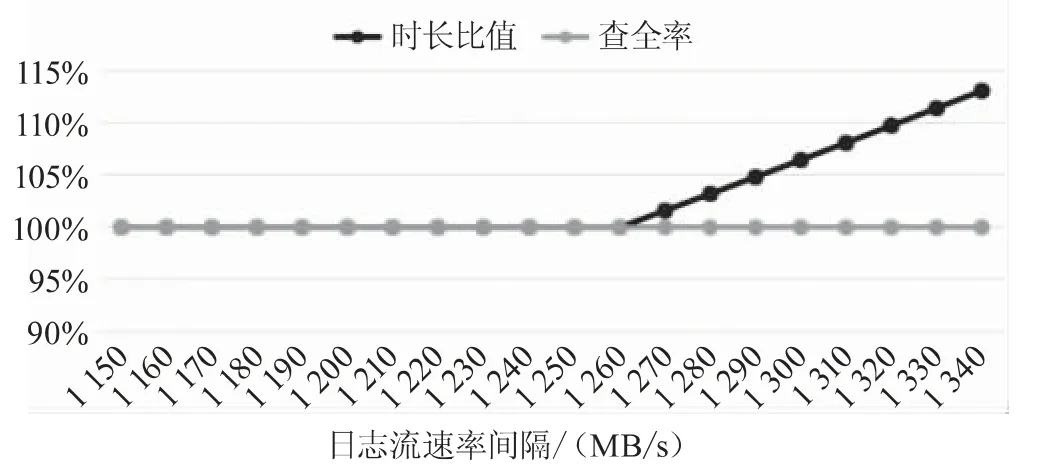
图3 1 150~1 340 MB/s速率的采集时长/日志流时长、异常链路查全率
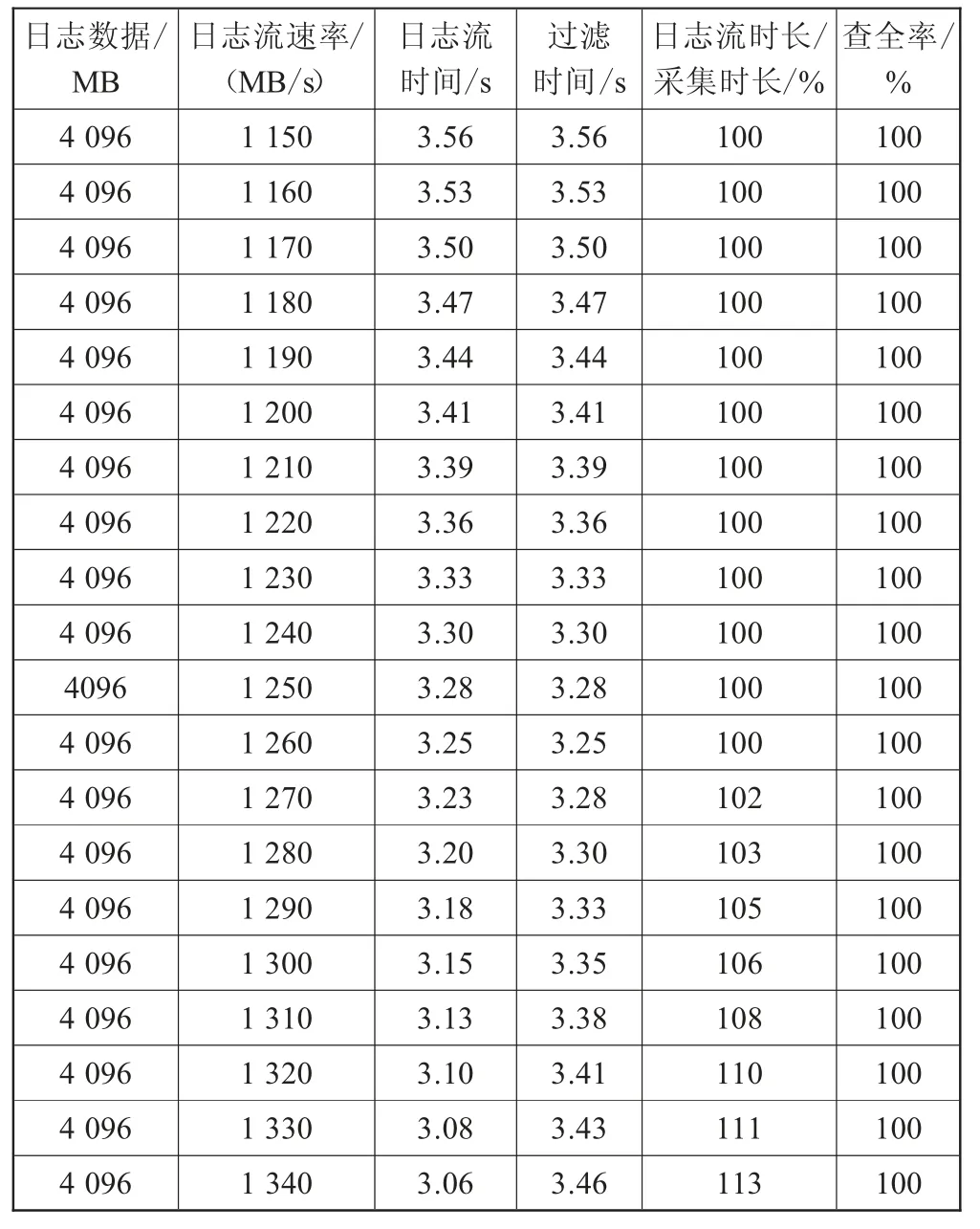
表1日志流输出时长/采集时长、查全率
4 结果与讨论
当日志流速率在1 260 MB/s以下时,采集时间与日志流时间一致;当日志流速率在1 260 MB/s以上时,采集时间比日志流时间长,并且随着日志流速率提高,采集时长与日志流时长比值增大。数据表明,采集速率达到1 260 MB/s,日志流速率在1 260 MB/s以内时能实时处理日志信息。
5 结语
本文旨在分析分布式系统链路日志的现况,提出了一种分布式链路异常日志采集的方法:只要请求的链路跟踪数据存在异常节点,那么该异常节点涉及的全链路数据将被采集。通过该方法,分布式链路异常日志采集速率达到了1 260 MB/s,查全率达到100%。该方法大幅提升了业务高峰期系统故障问题定位的效率,提高了系统故障处理能力和业务办理质量,提升了客户满意度。
猜你喜欢
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
商品与质量(2019年34期)2019-11-29
计算机系统应用(2019年3期)2019-03-11
思维与智慧·上半月(2018年10期)2018-11-30
现代电子技术(2018年20期)2018-10-24
思维与智慧·上半月(2018年9期)2018-09-22
现代情报(2018年11期)2018-01-07
中国信息化·学术版(2013年1期)2013-05-28
中国管理信息化(2009年10期)2009-06-19
