
基于gcFor est算法的恶意URL检测
2022-12-13 10:56涛李思鉴何智帆姚兴博
机电信息 2022年23期
刘 涛李思鉴 何智帆 周 宇 姚兴博
(1.深圳供电局有限公司,广东 深圳 518133;2.南瑞集团(国网电力科学研究院),江苏 南京 210000;3.南京农业大学人工智能学院,江苏 南京 210095)
0 引言
恶意URL(Malicious URLs)是网络犯罪的重要途径,它作为钓鱼网站、网络恶意程序和脚本的载体,为网络违法犯罪活动提供了可乘之机[1]。这些恶意URL有着和一般URL几乎一致的特征,一般不易被检测出,且具有诱导、欺骗的特征,对用户和企业的隐私、数据和财产等安全问题造成很大威胁。随着网络攻击形式逐渐多样化,恶意URL变得更加复杂、隐蔽且更具危害性,这就要求网络安全研究人员研究更加高效的检测方案以实现对其有效检测。因此,对恶意URL的高效识别与检测至关重要[2]。
传统的恶意URL检测方法包括黑名单技术[3]、启发式技术[4-5],随着新型恶意URL的逐渐复杂化,传统技术的检测水平逐渐下降,且具有误报率高、更新复杂等特点,无法满足网络安全的需求。
近年来,机器学习为恶意URL的检测提供了新的研究方向。其中具有代表性的算法为k近邻算法(KNN)[6]、Random Forest[7-8],此类算法常被用于一般的恶意URL检测场景。但是随着时间的推移以及恶意URL的逐渐复杂化、隐蔽化,这种分类模型往往不能达到预期的分类效果,变得误判率高且稳定性随时间下降。而gcForest算法[9]由于其易训练、可扩展、效率高的优点,在恶意URL检测领域具有很大的发展空间。
本文对URL的特性展开针对性研究,并对机器学习模型训练过程中的特征工程技术与分类算法展开实验,结果表明,gcForest算法训练出的模型在准确率、精确率、召回率、F1-score等各方面远优于一般机器学习算法,能实现对恶意URL的高效检测。
1 总体处理框架
机器学习的一般流程包括数据集获取、数据集预处理、特征工程、选取算法训练模型、模型调优与应用等步骤。因此,恶意URL高效检测的机器学习模型包括以下步骤:
(1)获取由正常URL和恶意URL组成的数据集,并分析其特征;
(2)对数据进行预处理,划分训练集、测试集,去除冗余信息;
(3)开展特征工程,对URL数据集进行分词、特征提取,并转化为词向量形式;
(4)部署gcForest算法,输入URL数据进行模型训练;
(5)选取评估指标,通过测试集对模型进行评估,判断其是否符合标准;
(6)将训练完的模型导出并应用,实现对新的URL的检测,判断其是否为恶意URL。
以上步骤的流程图如图1所示。
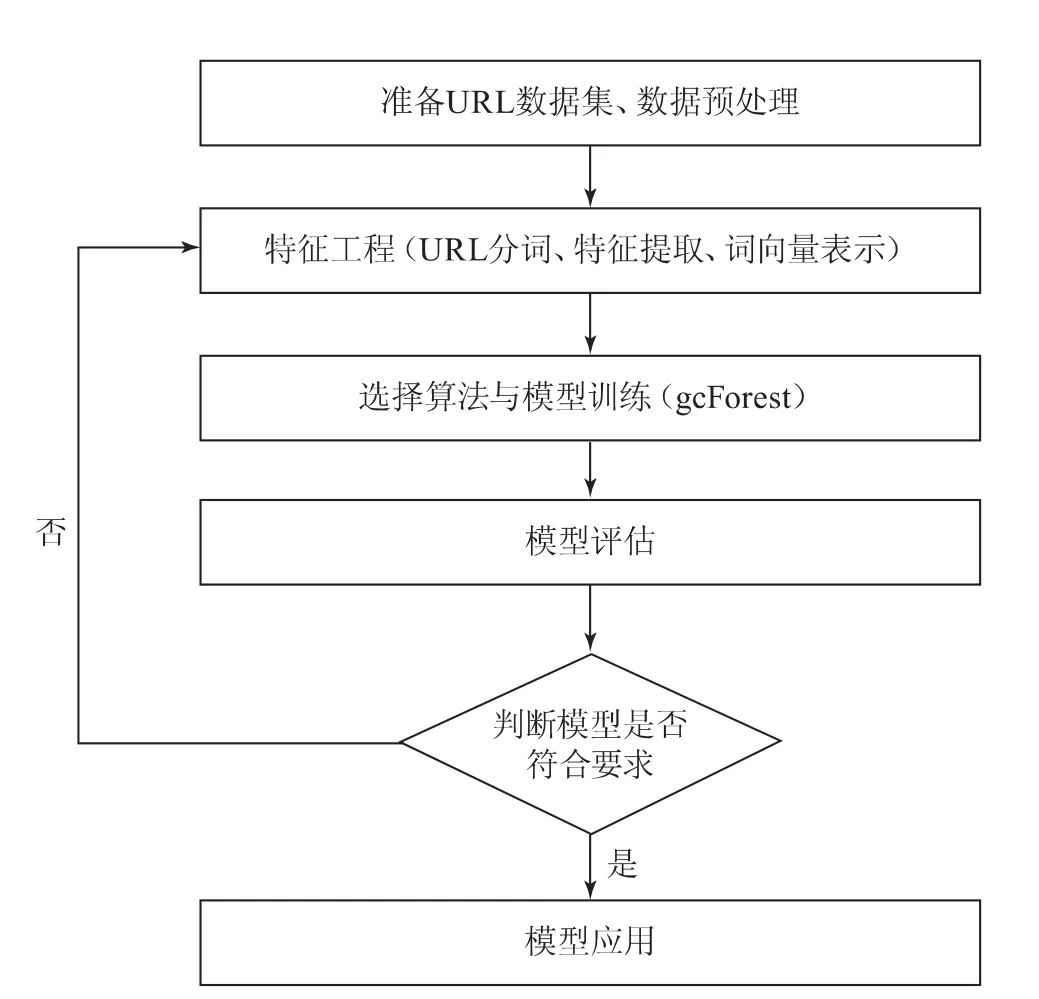
图1 基于gcForest的恶意URL检测模型开发流程图
其中,最为关键的部分为特征工程和机器学习算法选取与模型训练。在特征工程部分,本文对原始的URL数据进行分词、特征提取、词向量表示,最终作为机器学习模型训练的数据输入。在算法选取与模型训练部分,本文利用gcForest研究在恶意URL检测方面的应用,通过准确度、精确率、召回率、F1-score等多项指标对其进行评估,并将其与传统的k近邻算法(KNN)和Random Forest算法进行对比。最终,将模型导出并应用于恶意URL的检测。
2 实验原理
gcForest[9]即多粒度级联森林算法,是一种基于决策树的集成方法,其思想是通过随机森林的级联结构进行学习。gcForest的性能较之深度神经网络有很强的竞争力,将其用于恶意URL检测模型中,可以达到极佳的性能。本部分将介绍gcForest应用于URL分类问题的原理以及实现方法。
gcForest采用的多层级结构如图2所示,每层(layer)由4个随机森林组成,包括2个随机森林和2个极端随机森林,每个森林都会对数据进行训练并输出结果,这个结果被称为森林生成的类向量。同时由图2可知,每层都会输出2个结果,即每个森林的预测结果与4个森林的预测的平均结果。
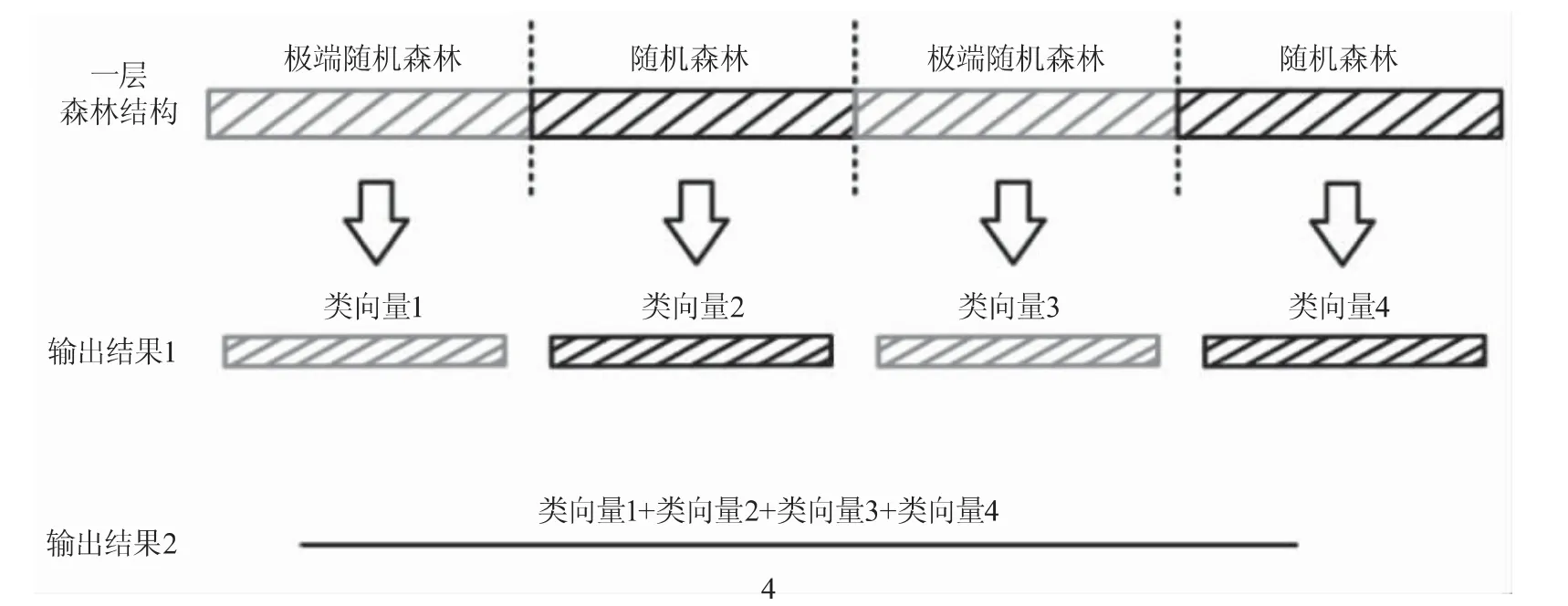
图2 每层随机森林结构及输出结果示意图
如图3所示,为防止过拟合,先对输入给每个森林的训练数据进行k折交叉验证。同时,由于每一层结构(layer)都会生成4个类向量,故将上一层的4个类向量以及原有的数据作为新的训练数据,输入下一层进行训练,如此叠加,最后一层将类向量进行平均,作为预测结果。
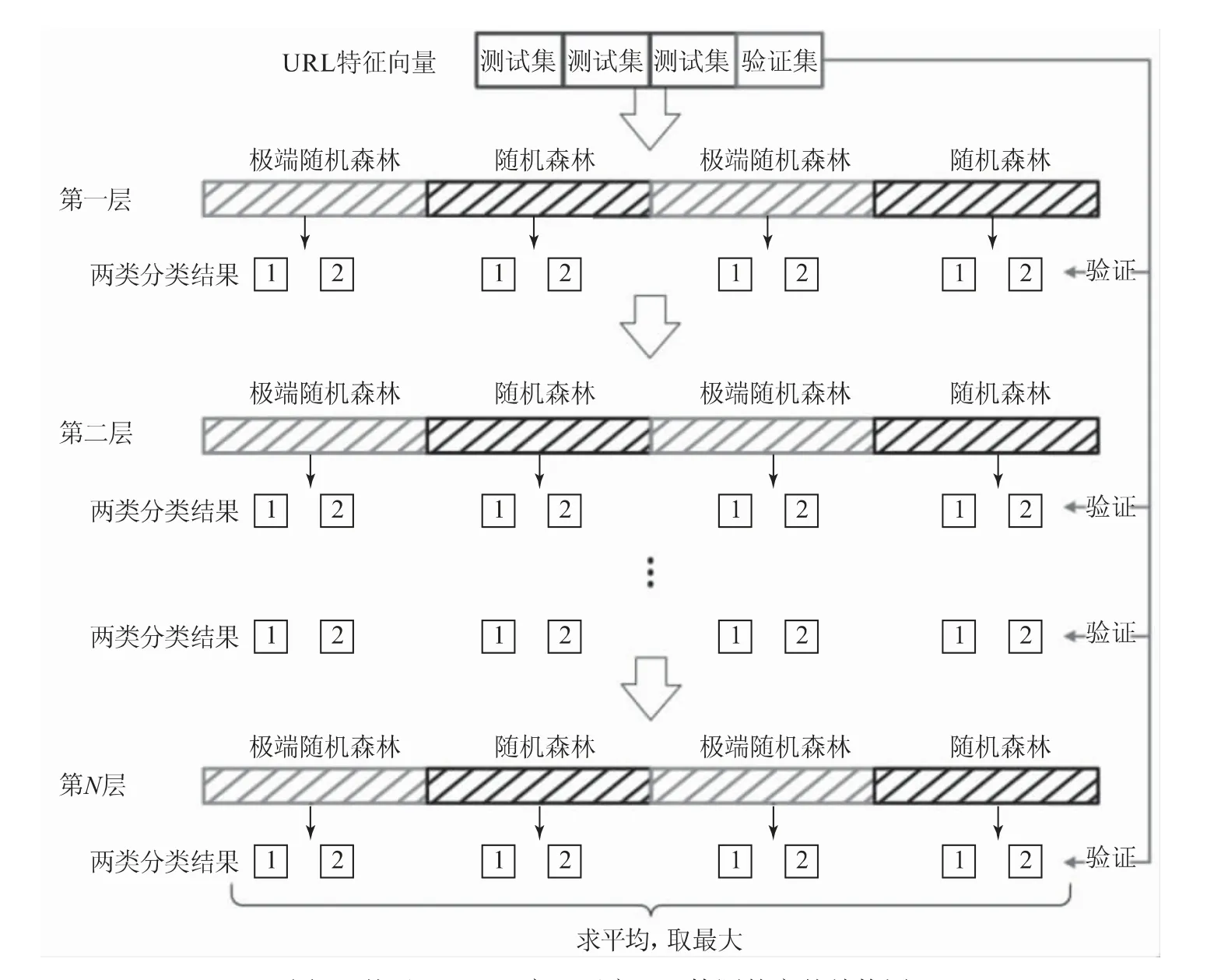
图3 基于gcForest实现恶意URL检测的完整结构图
3 实验及结果
3.1 环境配置
实验平台为Windows 10,64位操作系统,CPU为i5-10200H,2.40 GHz,GPU为NVIDA GeForce GTX 1650,内存为16.0 GB。Python版本为3.9.12,pandas为1.3.4,conda为4.12.0。
3.2 模型评估指标
本文使用准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1-score、maro avg和weighted avg这6种指标来评估模型的分类能力[10]。
准确率(Accuracy)表示分类正确样本占总样本的比例,是最直观的评价指标,其公式为:
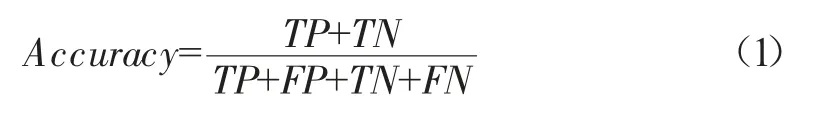
式中:TP表示预测为正样本且实际为正样本;FP表示预测为正样本而实际为负样本;TN表示预测为负样本且实际为负样本;FN表示预测为负样本而实际为正样本。
精确率(Precision)表示所有预测结果为正例样本中真实为正例的比例,其计算公式为:

召回率(Recall)表示在所有真实为正例的样本中预测结果为正例的比例,其计算公式为:

F1-score是对模型精确率和召回率的加权平均计算,反映了模型的稳健性,结合精确率和召回率计算公式如下:
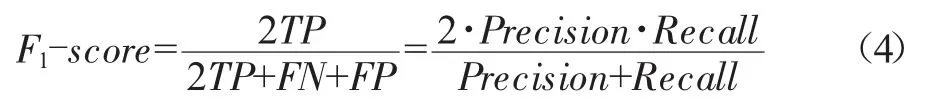
maro avg为宏平均,其计算方式是对某个指标求其所有类别指标值的算术平均,以精确率Pi为例,Pi的maro avg计算公式如下:
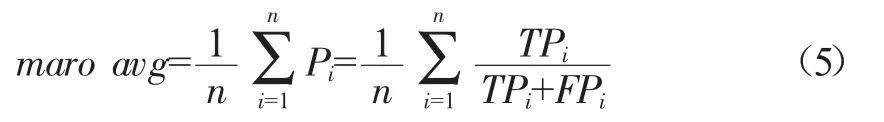
weighted avg为加权平均,其计算方式是对某个指标求其所有类别指标值的加权平均,记Si表示支持第i类的样本数,以精确率Pi为例,Pi的weighted avg计算公式如下:
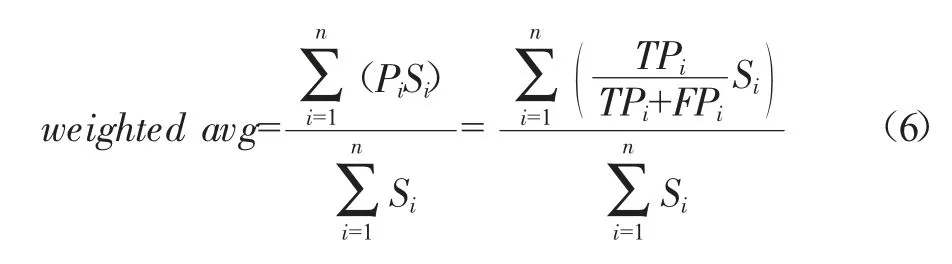
3.3 数据集准备
在数据集的选取上,本实验中所需的URL数据集来源于kaggle,网址为:https://www.kaggle.com/taruntiwarihp/phishing-site-urls。先对URL数据进行初步筛选,并按照8:2的比例划分训练集和测试集,得到数据集情况如表1所示。
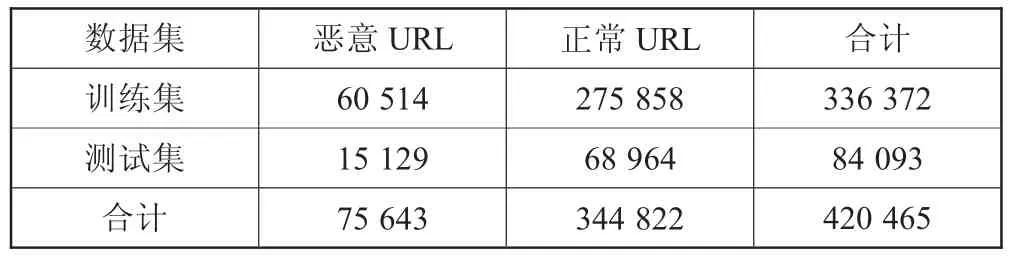
表1 URL数据集
3.4 特征工程
由 于URL中 的 协 议 部 分 中 如“http”“https”和“www.”等字段对URL分类基本无影响[6],因此,在对URL分词前可先将这些部分去除掉,以提高分类效率。去除协议部分后的部分URL如表2所示。

表2 去除协议部分后的URL举例
其次,由于URL是紧密连接的字符与符号,因此要对其进行分词,以此为基础才能实现对URL的词向量表示。如表3所示,经过对比测试常用的分词工具发现,基于正则表达式Re工具可以实现对URL的最准确分词,其效果远优于Jieba或Nltk等分词工具。

表3 分词结果对比
最后,本文借助sklearn中的TfidfVectorizer工具,完成对URL的文本特征提取和词向量表示工作,以作为机器学习分类算法的数据输入。
3.5 检测结果
将上述预处理数据作为初始训练数据输入gcForest,进行模型训练即可得到分类模型。使用gcForest模型得到的训练结果评估如表4所示。
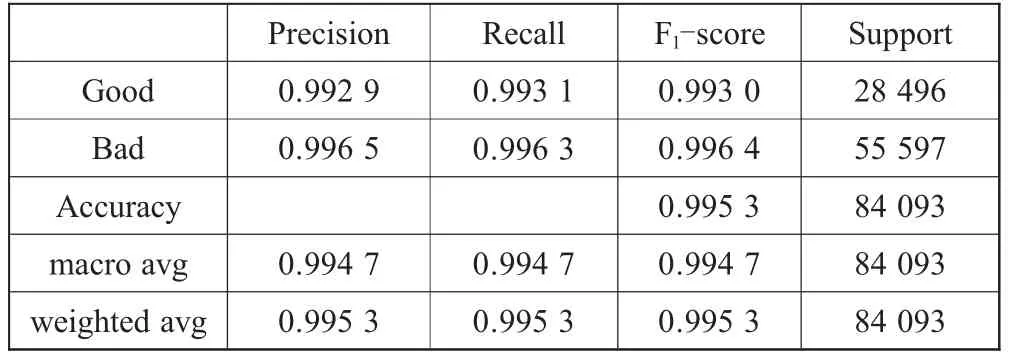
表4 基于gcForest的恶意URL检测训练结果评估
由表4可知,该模型的分类准确率(Accuracy)达到了99.53%,在保留两位小数的情况下,该模型对恶意URL识别的精确率(Precision)、召回率(Recall)、F1-score均达到0.996以上;而对正常URL识别的精确率(Precision)、召回率(Recall)、F1-score能达到0.992以上。因此,该模型在恶意URL检测的应用中具有极高的准确度与稳定性,具有很大的应用价值。
此外,本文将基于gcForest算法训练出的模型与KNN和Random Forest算法模型进行对比,结果如图4所示。
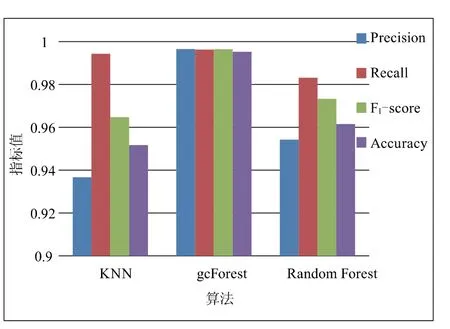
图4 不同学习算法分类URL结果对比
gcForest在准确率、精确率、召回率、F1-score、macro avg和weighted avg指标下均远高于传统的KNN算法,其中准确率提升4.40%,精确率提升3.17%。而对比gcForest底层的Random Forest算法,其在精确率上带来了3.42%的提升,衡量模型稳定性的F1-score提升了2.31%。由此可以得出,gcForest在恶意URL检测方面具有远优于传统机器学习算法的性能。
4 结论
本文将gcForest算法应用于恶意URL检测,训练出能够准确且高效识别恶意URL的机器学习模型,并从原理出发,系统介绍了基于gcForest算法的恶意URL检测模型训练过程。本文的机器学习模型准确率达到99.53%,远高于传统的机器学习分类算法,且其精确率、召回率、F1-score、maro avg和weighted avg值均高于0.99,具有很好的检测效果。
猜你喜欢
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
中学生数理化·高一版(2021年2期)2021-03-19
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
领导决策信息(2018年16期)2018-09-27
电影(2018年8期)2018-09-21
数学学习与研究(2017年3期)2017-03-09
西南学林(2011年0期)2011-11-12
