
语义兴趣点检测算法在图像分割中的研究
2022-12-11 09:42陆宏菊
智能计算机与应用 2022年11期
陆宏菊
(济南市技师学院 信息工程学院,济南 250115)
0 引言
图像分割是计算机视觉中最基础的研究问题之一,其目的是根据相关性原则将图像分成若干互不重叠的区域,并将感兴趣的区域与背景标记出来[1]。图像分割算法中,交互式分割研究相对比较成熟,包括基于边界的和基于区域的方法[2]。其中,基于边界的方法通过用户获得边界信息,例如Snake 模型[3]、GAC 模型[4]和LSM 模型[5]。基于区域的方法预定义或交互标记不同的目标和背景,通过相似性计算完成分割,如Intelligent Paint[6]和Marker Drawing[7]。为了降低用户干预,Dambreville等人[8]提出KPCA 算法在GAC 中引入形状先验模型。Liao 等人[2]提出结合显著性特征和星型形状先验进行前景特征点定位。尽管已经获得较好的分割结果,交互式分割算法仍存在时间长、操作繁琐和结果易受标记点位置影响的问题。
在上述方法中,局部特征相似性计算在像素级分割算法中起着关键的作用,但也随即带来了较高的计算代价。对于某些参数依赖和模型依赖的算法,数据标签化成本也很高,且只适用于特定种类和指定的数据集。针对这些问题,本文提出一种无监督学习的多模态特征语义分割模型。受FCN 模型的启发,多种像素级特征(颜色、显著性、空间、深度等)联合进行图像表示能够获得更加完整的图像描述。针对不同类型的图像,多种特征在图像分割解空间的贡献度不同。本文提出特征选择矩阵S,能够将多模态特征在解空间进行映射,从而获得低维、平滑的解平面用于图像分割,通过引入语义检索模型简化求解难度。
1 本文方法
1.1 多模态图像特征描述
目前,出现了众多针对图像特征的描述子,例如显著性特征、景深特征、空间特征和颜色特征等。这些特征针对图像的不同侧面进行了描述和表示。在图像分割中,采用显著性特征表示对于包含有明显主题物体的图像、采用景深特征表示对于具有距离深度的图像非常有效。每一种特征单独表示能对于相关类型图像具有良好的分割效果。本文提出假设:采用多模态特征融合的方法进行图像分割,相对于单一特征描述,分割效果则会更佳。因此,本文提出基于多模态特征的无监督学习算法进行图像前景和背景的分割。
特征合并是多特征学习算法常用的策略,即将不同模态的特征通过合并(多维特征组成一维特征)进行分割训练。这种方法简单易行,但是未考虑不同模态特征对于最终分割问题解平面的贡献度不同。比如说在空旷风景照中景深特征会对于区分前景和背景贡献度较大;对于人的肖像照,显著性特征和颜色特征贡献度较大。图像及其多模态特征表示如图1 所示。因此本文提出通过学习策略获得特征选择矩阵S。针对不同类型的图像,矩阵S能够合理地将不同模态特征在分割解空间内进行投影,使得贡献度大的特征能够在投影中占据主导。

图1 图像及其多模态特征表示Fig.1 The image and multi-modality representation of the features
1.2 多模态特征映射
在规模为n的邻域内,像素多模态特征Ω可以表示为所有特征组成的高维向量,Ω={Cri,j,Cgi,j,Cbi,j,Xposition,Yposition,ftexture,flightness,fsaliency,…}。每个像素的特征向量表示为n邻域范围内所有像素的特征集合。本文中提出的“语义”与FCN中的语义有所不同,本文中主要是指在高维特征空间内,针对目标函数的特征的投影,也就是本文提出的特征语义。因此,可以将分割问题表示为:

其中,tr(.)为迹运算。经过化简,L∈ℝ(n+1)×(n+1)体现了在n维空间内的相似度度量目标函数。对于L的估算仍旧很难进行,经过分析发现,虽然不同的特征对于不同类型图像的贡献度不同,但是可以认为其贡献度皆为非负的。本文研究提出存在一个潜在的特征选择矩阵S,通过S可以将多模态特征进行全局映射,即:Ωpi=ΩSn。
因此,公式(1)可以进一步化简为:

将公式(1)带入到公式(2)中可以得到:

本文采用文献[9]中的方法对式(3)进行求解。学习出的模型(Φk(x),λk)可以用来将高维的特征矩阵Ω映射到由用户指定相似距离阈值θ的解空间上。
1.3 基于多模态特征映射的图像分割算法
经过式(3)可以针对目标图像学习出其相应的特征模式(modes),并寻找到相似度最小的像素集,如图2 所示。
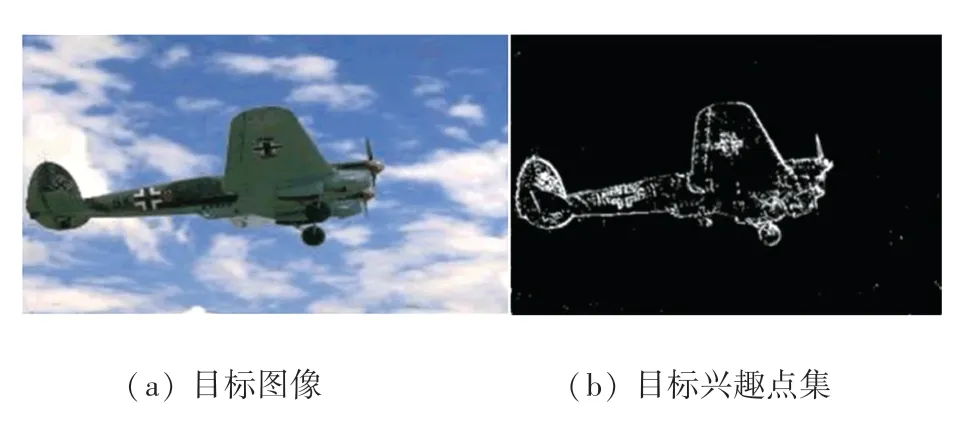
图2 目标兴趣点集Fig.2 Object interesting pixels set
针对目标兴趣点集完成自动分割,首先利用检测出的兴趣点产生种子区域。通过图像的颜色距离dc和位置距离ds[10],将与兴趣点像素“同质”的像素计算出来。因此,本文提出的算法代码的设计表述如下。
输入:图像I,特征n,距离阈值θ
输出:分割结果
3:[特征向量,特征值]←Ln;
4:训练学习出特征模式,从而得到兴趣点;
5:通过式(3)和距离阈值,根据兴趣点得到兴趣区域;
6:根据兴趣区域获得分割结果。
2 实验结果与分析
2.1 实验内容
本文实验环境为Windows 10,I9CPU,32GB 内存,英伟达GTX 1080Ti 11G。实验选取图像的显著性[11]、Focal 长度[12]、空间特征[13]和颜色直方图[14]四种不同模态的图像特征进行对比实验。实验选用的是BSD 数据集。与3 种最新方法,即高斯混合模型(GMM)[15]、Level-set 算法[16]和LSC 超像素分割算法[17]进行定性比较。
2.2 实验结果定性分析
本文进行了分割结果的可视化定性比较,对比结果如图3 所示。图3(a)是从BSD500 数据集选定的待分割图像。图3(b)受复杂背景图像的影响,有部分区域被误分类为前景区域,对于边界保持也并不令人满意。图3(c)受初始位置的选择影响,当初始位置选择合理时,分割结果较好,例如“鸵鸟”图像;反之则不然,例如“飞机”图像。图3(d)为LSC超像素算法的结果,在前景物体分割上出现错误。图3(e)为本文算法、采用了多模态的特征,对于2幅“飞机”图像,景深特征的作用可以确保前景边界信息的完整。“老人”图像中,显著性特征能够有效分割出老人与椅子背景区域。本节实验呈现结果并不是在相同模式下,所有代码均来自于作者本人自主研发。经过视觉对比可以明显看出,本文方法在场景图像、人物图像、动物图像等不同类型图像前景背景分割中均获得了理想的结果。

图3 定性对比Fig.3 The qualitative comparison
2.3 实验结果定量分析
在定量对比方面,本文主要设置2 组实验:采用参数PRI、GCE和VOI指标的对比;采用F -measure与BSD500 数据集中的标定数据进行对比。对此拟展开探讨分述如下。
(1)采用PRI、GCE、VOI指标的对比。在BSD500图库中抽取30 幅图像进行定量分析对比实验。采用PRI[18](probabilistic rand index)、GCE[19](Global Consistency Error)和VOI(Variation of Information)评价指标进行评估[20]。其中,PRI计算分割结果与真实标记相一致的像素数的比例,其值越大、分割结果与参考值间的属性共生一致性也就越好。VOI是信息差异指标,计算像素点分割产生的信息熵的变化程度。在概率论和信息论中,信息或共享信息距离的变化是对2 个聚类(元素分区)间距离的度量,且与相互信息密切相关;实际上,这就是一个包含相互信息的简单线性表达式,其值越小越好。GCE衡量分割结果之间互相包括的概率,其值越小越好。本次研究中,计算50 次的平均值作为最终结果,见表1。由表1 中可以看出,本文算法在3 项指标上皆高于文中选择的对比方法。

表1 PRI、GCE和VOI 的平均值Tab.1 The average value of PRI,GCE and VOI
(2)采用F -measure指标的对比。采用F -measure衡量本文分割方法与BSD500 中提供的6 个人工标注数据之间的性能比较,数学定义式具体如下:

其中,β2=0.3[21]。
与BSD 标定数据性能对比结果见表2。在表2中,本文从BSD500 数据集中选取20 个图像,求其平均准确率、召回率和F -measure数值。通过实验可以看出,这些指标大多超过95%。实验结果表明本文方法的效果接近BSD500 所提供的6 个人工标注分割结果。

表2 与BSD 标定数据性能对比Tab.2 The quantitative comparison with BSD labels
2.4 与FCN 模型的分割对比分析
深度学习模型是当下研究热点,本文思路也是受深度模型多层次、多特征加工启发产生,因此,本文针对目前广泛应用的FCN[22]进行对比实验。FCN 通过梯度累积、正则化loss函数和标准化动量方式进行训练,比较结果如图4 所示。本次研究中,选取了FCN8s(2 stream,8 pixel prediction)、FCN16s(2 stream,16 pixel prediction)和FCN32s(1 stream,32 pixel prediction)模型进行对比实验。
由图4 可知,FCN8s 模型效果明显好于其他2个。但是由于FCN 模型的主要目的是进行语义分割(Semantic segmentation),即将具有相同语义的物体进行分割和标注。因此,在对于边缘分割准确率方面也并不精确。在这一方面,本文算法的结果较FCN 更加准确。

图4 FCN 模型分割对比Fig.4 FCN models segmentation comparison
在1.3 节提到的本文算法中,相似度距离阈值θ为超参,表示相似度距离,也就是当相似度距离小于θ就表示2 个像素同质,否则表示2 个像素异质。
参数分析结果如图5 所示。图5中,图5(a)~(c)中的各子图从左至右的θ取值依次为8,9,10,11,12。从图5 中可以看出,当θ取值趋向于0,检测到的兴趣点像素就非常多,但包含有大量的噪声,从而出现过分割。当θ取值很大时,相似度距离会比较严格,检测出的兴趣点会减少,从而出现欠分割现象。总之,合适的相似度距离阈值θ对于结果是非常重要的,本文中选取的θ在[9,11]之间,一般情况下θ=10。

图5 参数分析结果Fig.5 The parameters analysis results
3 结束语
本文提出一种基于无监督的多模态特征映射策略,将传统的图像分割问题转化为在全局范围内寻找相似距离最小的最优化问题。通过引入特征选择矩阵和语义哈希模型,简化了计算复杂度,降低了计算代价,实现了对不同种类图像的前景-背景分割。通过与其他无监督算法和深度学习模型进行对比,验证了本文方法的可行性。
本文方法中还有很多需要改进的地方。首先,虽然多模态特征映射采用的是无监督学习策略,但相似度距离阈值θ是由用户指定的。如何能够在学习过程中将阈值参数加入到目标函数中是未来工作亟待解决的问题。通过引入显著性、景深、空间和颜色特征,本文方法展现出对于多类型图像分割的鲁棒性。在当前框架下,如何引入新的特征能够适应更加泛化的图像类型将成为本文后续工作的重点。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
小哥白尼(军事科学)(2022年2期)2022-05-25
昆明医科大学学报(2022年3期)2022-04-19
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
中国人兽共患病学报(2020年11期)2020-12-08
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2019年24期)2019-02-23
西南交通大学学报(2018年5期)2018-11-08
中国与非洲(法文版)(2017年10期)2017-11-23
知识产权(2016年8期)2016-12-01
