
基于自注意力机制的自动驾驶场景点云语义分割方法*
2022-12-08 12:05王大方夏祥腾韩雨霖
汽车工程 2022年11期
王大方,尚 海,曹 江,王 涛,夏祥腾,韩雨霖
(1.哈尔滨工业大学(威海)汽车工程学院,威海 264200;2.陆军装甲兵学院,北京 100072)
前言
语义分割是自动驾驶技术环境感知环节重要的任务之一,其旨在将传感器获取的场景(图片、点云等)进行理解并标注不同区域的语义信息,是目标识别、分类等视觉任务的基础[1]。全卷积神经网络(fully convolutional networks,FCN)[2]的提出使得深度学习的方法在2D图像的语义分割领域有了突破性的进展。但由于3D点云具有无序性、稀疏性、非结构化[3]的特点,使得许多已经在图像语义分割领域已经很成熟的方法无法直接运用到点云语义分割上,因此针对点云数据的语义分割任务更加困难,特别是在自动驾驶场景下对于算法效率、内存占用、鲁棒性等方面的要求更加严格。针对以上困难,目前主流的点云语义分割方法主要有4种:基于投影的方法、基于体素化的方法、基于点的方法和多模态融合的方法。
在2D图像分割领域许多算法如U-Net[4]、Mask R-CNN[5]、DeepLab[6]等已经非常成熟,因此部分学者便考虑将3D点云投影转化为2D图像,然后再利用2D图像的分割方法进行处理。多视图卷积神经网络(multi-view CNN,MVCNN)[7]通过多个视角将3D形状进行投影以得到多个2D视图,对每个视图使用卷积神经网络提取特征再进行池化聚合得到最终的语义分割结果,但这种方式会因为投影视图不连续而丢失部分特征。为了解决这一问题,SqueezeSeg[8]将3D点云经过球面投影得到前视图,然后再使用基于SqueezeNet[9]的神经网络对投影图像 进 行 特 征 提 取 分 割。SqueezeSegV2[10]和SqueezeSegV3[11]是SqueezeSeg的改进版,它们分别引入了域自适应聚合模块和空间自适应卷积模块来提高网络的性能。RangeNet++[12]将激光雷达数据转化为深度图的形式表示,然后对深度图进行语义分割,最后再使用基于KNN搜索的方式来对点云进行重建。以上方法虽然能够通过转换来利用2D语义分割的方法,但在投影的过程中不可避免地破坏了原始点云的空间结构信息,从而影响分割的精度。
为了解决3D点云数据非结构化的问题,一些研究通过体素化的方法将点云转化为整体排列的体素网格,然后再使用3D CNN等方式进行处理。3D UNet[13]使 用3D卷 积 替 换 了U-Net网 络 中 的 卷 积 模块,从而可以对三维数据进行特征提取。SEGCloud[14]在3D全卷积神经网络的基础上引入了三线性插值和全连通条件随机场来提高分割的准确率。然而基于体素的方法会带来内存消耗增大的问题,体素网格越小,点云表示越精密,但内存开销就越大。VV-Net[15]使用径向基函数代替体素的表示方法,并通过基于核的变分自编码器对每个体素内部几何结构进行编码。Cylinder 3D[16]设计了一种柱面划分的点云表示方法,可以很好地适应点云数据“近密远疏”的特点,并且引入了非对称残差块,增强了网络的泛化能力。OctreeNet[17]使用八叉树集合(Octree)来表示体素化后的点云,以减少体素网格的内存占用,并提出了可以直接应用于八叉树的最小非平凡和非重叠内核卷积以直接在构建好的树结构上进行卷积操作。
相较于投影和体素化等间接处理点云的方式,基于点的方法直接将点云送入神经网络,避免了处理过程中的结构损失和内存占用,但这种方法的难点在于如何从非结构化的点云中提取特征。PointNet[18]开创性地使用最大池化层(max-pooling)聚合特征,解决了直接输入的点云无序性和置换不变性的问题。PointNet++[19]通过最远点采样方法对点云进行多尺度分组聚合,然后分别使用PointNet操作来捕获点云空间中的上下文信息。PointSIFT[20]提出了一个基于SIFT算子(scale-invariant feature transform)的点云表示模块,使网络可以捕获所有方向的信息,以提高局部特征捕获能力。PointCNN[21]提出了一种X-Conv的卷积算子,该算子通过X变换矩阵解决了点云输入无序性的问题。KPConv[22]构造了一种核点卷积算子(kernel point convolution,KPC),并利用核函数计算中心点的权重矩阵以对提取到的局部特征进行特征变换。
一些学者结合以上两种或几种方法提出了多模态融合的网络对点云进行语义分割。PVCNN[23]将基于点的方法和基于体素的方法相结合,提出了点体素卷积模块,使网络具有较小的内存占用和良好的数据局部性、规律性的优点。RPVNet[24]分别提取深度图、点、体素的特征,然后将3个分支通过哈希映射融合以后送入编码器-解码器结构进行预测,显著提高了分割精度。
在自动驾驶场景中,点云语义分割的效率也是不可忽视的一个重要指标。为提高点云分割的实时性,RandLA-Net[25]使用随机降采样替代点云处理中常用的最远点采样方法,同时提出了局部特征聚合模块(local feature aggregation,LFA)来弥补随机降采样过程中的信息丢失问题,使得大场景点云语义分割的效率大大提高。但该网络的局部特征聚合模块对局部特征提取的能力仍有限,而且对于大场景的点云,无法很好地捕获全局上下文特征。鉴于此,本文中利用自注意力机制善于提取特征内部相关性的特点,设计了局部自注意力模块和全局自注意力模块来增强网络局部特征提取和全局上下文聚合的性能。
1 语义分割网络模型设计
自注意力机制通过对输入变量自身进行相关性运算以得到不同特征之间的权重关系图,然后再通过关系图对特征按照权重进行“赋分”编码:
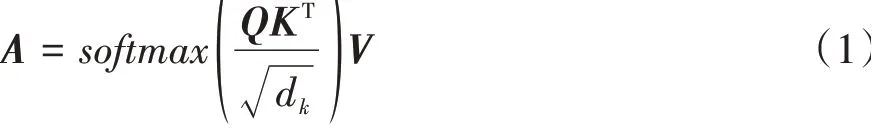
式中:Q、K、V分别是注意力机制里面的查询(query)、键(key)、值(value)矩阵,它们都是由输入特征通过线性变换得来;dk是特征线性变换后的维度数,除以dk使得Q和K的内积控制在一个范围内以避免数值过大;softmax是指数归一化函数,它将输入映射成0到1之间的概率分布,从而得到输入特征之间的注意力得分图,注意力得分图再与值矩阵V相乘即可得到按照注意力得分权重加权的最终输出。对于一组点云来说,不同点之间的相关性是不同的,属于同一个物体或结构之间的点的相关性是大于不同类别点的。卷积的方法由于感受野较小,每次只能对输入小部分点集进行特征变换,欠缺对上下文语义进行理解的能力。而自注意力机制对整个(或部分)输入点云计算相关性分布图,可以对全局信息(局部信息)进行理解,从而更好地捕获特征信息。本文以RandLA-Net为基础框架构造了基于注意力机制的语义分割网络,在原网络基础上设计了局部自注意力编码器和全局自注意力编码器,以提高网络从稀疏点云中提取局部和全局特征的能力。
1.1 网络整体结构
网络整体结构如图1所示,本文中网络采用“编码器-解码器”结构。在编码器阶段通过降采样和特征提取逐步减少点的数量、提升特征维度,聚合点云特征;在解码器阶段通过上采样将点云数量还原回输入点的数量,并通过线性变换将特征维度映射到最终的语义标签。

图1 网络整体结构
编码器的网络基本层由随机下采样(random sampling,RS)和特征聚合模块(feature aggregation module,FAM)组成。在编码器阶段,输入点云首先通过全连接层将维度升为8,然后再逐步进行下采样和编码。在每次随机降采样之后紧接着使用FAM提取特征。通过4次随机降采样将点云数量分别减少到N∕4、N∕16、N∕64、N∕256,为了对抗随机降采样导致的信息丢失,FAM逐步将维度数提升到32、128、256、512。在解码器阶段使用KNN算法查找点的近邻点,然后通过三线性插值对点云进行逐步上采样至输入的点云数N。由于降采样过程中被丢弃点的信息是不可逆的,为了减少损失,在上采样过程中通过跳跃连接将网络编码器阶段提取到的底层特征图与解码时的高层特征进行融合。最后将融合后的特征向量通过全连接层将维度映射到输出类别数class。
1.2 特征聚合模块
特征聚合模块是语义分割网络的基本单元,该模块通过局部自注意力编码器(local self-attention encoder,LSAE)和全局自注意力编码器(global selfattention encoder,GSAE)对输入点云进行特征提取和聚合,其结构如图2(a)所示。对于输入大小为N×din的点云首先使用MLP将维度变换dout∕2;然后通过两个级联的LSAE模块提取局部特征信息,图中绿色模块代表点云坐标信息,用于局部自注意力编码器中的位置编码δ操作;输出的N×dout张量再送入GSAE模块提取全局上下文信息;最后把输入张量通过MLP将维度对齐到输出维度以后与GSAE模块得到的特征进行残差连接即可得到输出。
1.3 局部自注意力编码器
RandLA-Net的局部空间编码模块通过中心点与邻近点的特征合并进行编码,从而提取到了点云局部的结构特征,但实际上同一组点云中心点与其邻近点的相关性是不同的,受Point Transformer[26]启发,本文中设计了局部自注意力编码器LSAE,通过自注意力机制计算中心点与各邻近点的相关性权重进行特征编码。
相比于以像素为单位整齐排列的2D图像,点云本质上是嵌入在度量空间中的向量,其原始坐标信息中包含点之间的关系,因此本文中使用中心点向量与邻近点向量之差作为两点之间的注意力关系,其计算公式如下:
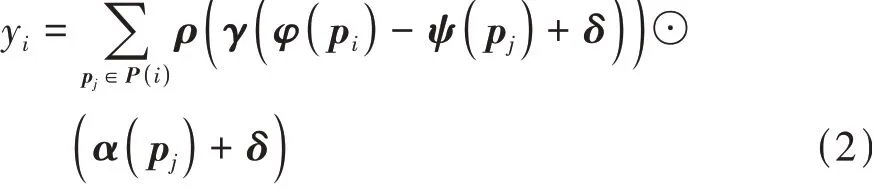
式中:P(i)为pi点的k个邻近点组成的点集;φ、ψ、α、γ均为MLP多层感知机操作;ρ为归一化操作;⊙为哈达玛积,即两矩阵逐元素相乘;δ为位置编码操作。

式中θ是MLP多层感知机操作,通过线性变换将中心点与邻近点坐标之差向量的维度与注意力关系矩阵的维度相同。
局部自注意力编码器结构如图2(b)所示。对于输入的每个点pi,通过KNN算法查找其k个邻近点pj;然后对pi和pj分别进行线性变换将维度映射到高维空间,再通过张量的广播机制相减计算注意力关系;将求得的注意力关系与位置编码向量相加后经过softmax函数归一化得到注意力图;将注意力图得分与邻近点变换后的特征矩阵α逐元素相乘即可赋予不同邻近点相应的权重;最后再通过求和操作聚合邻近点特征,即可得到局部注意力编码器的输出。
1.4 全局自注意力编码器
对于语义分割等场景理解任务来说,提取全局上下文信息也是影响分割性能的重要因素。由于卷积核感受野并不能覆盖全部点,所以仅通过卷积提取特征的方式并不能很好地提取全局信息。本文中基于自注意力机制设计了全局自注意力编码器GSAE,全局自注意力模块结构如图2(c)所示。与局部自注意力编码器不同,全局自注意力编码器将整个大小为N×d的点云作为输入,其中N为点的个数,d为输入的维度数;通过MLP变换分别得到查询矩阵Q、键矩阵KT(需要对K进行转置操作以进行矩阵相乘)和值矩阵V;Q与K通过矩阵相乘后再对特征维度进行softmax归一化得到大小为N×N的注意力图;将注意力图与值矩阵V相乘得到N×d'的注意力输出特征,最后再通过MLP将维度变换到输入的维度即为该模块最终的输出。
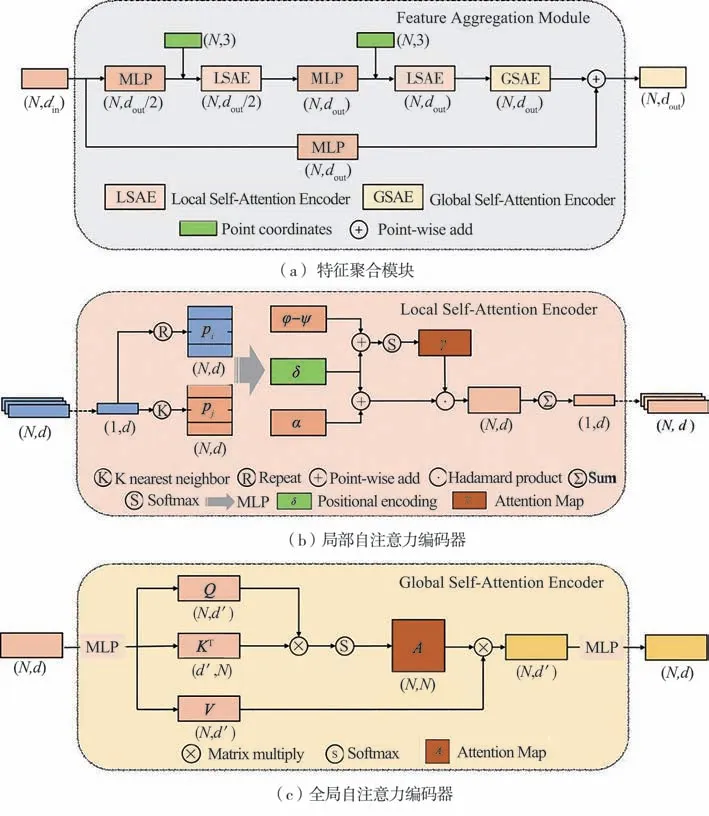
图2 网络基本层结构
2 实验验证
2.1 数据集和评价指标
本文中选取了大规模车载场景点云数据集SemanticKITTI[27]和SemanticPOSS[28]作为实验数据。SemanticKITTI是Behley等人基于德国卡尔斯鲁厄理工学院采集的KITTI[29]数据集中的激光雷达点云数据进行语义标注得到的。SemanticKITTI由22个点云序列组成,它包含了德国卡尔斯鲁厄市中心的交通场景、住宅区、高速道路场景和乡村道路。SemanticPOSS是由北京大学发布的数据集,它采用了与SemanticKITTI相同的数据格式,有6个点云序列,主要包含了北京大学校园内多个场景的点云。SemanticPOSS每帧点云数据包含的行人、车辆等小目标要比SemanticKITTI更加丰富,因此对于自动驾驶场景点云语义理解任务来说更具有挑战性。
语义分割任务常用平均交并比(mean intersection over union,MIoU)来评价分割精度:
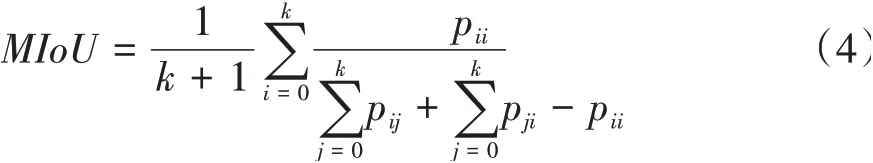
式中:k表示总类别数;i表示真实值;j表示预测值;pij表示将第i类预测为第j类的像素点数量。MIoU反映了对该场景所有类别预测的平均准确程度,本文中也通过MIoU来比较算法的分割精度。
2.2 实验参数
实验环境配置如下:硬件方面使用AMD Ryzen 9 3950X处理器,单块NVIDIA RTX3090 24G显卡;软件、系统方面使用ubuntu18.04,CUDA版本11.1,PyTorch1.9深度学习框架;参数设置方面批处理大小设置为4,最大训练轮数设置为100,采用Adam优化器,初始学习率设置为0.01,学习率衰减使用指数衰减方法,衰减指数设置为0.95,每训练完一轮进行一次推理验证。
2.3 实验结果分析
2.3.1 LSAE、GSAE模块消融实验
为了验证LSAE、GSAE两个模块的串联个数和方式对于整体分割精度的影响,以1个LSAE、1个GSAE模块串联顺序为网络基本结构,在此基础上分别增加2个模块个数、改变2个模块串联顺序,在SemanticKITTI数据集进行消融实验,对19个物体类别的MIoU进行验证,结果如表1所示。
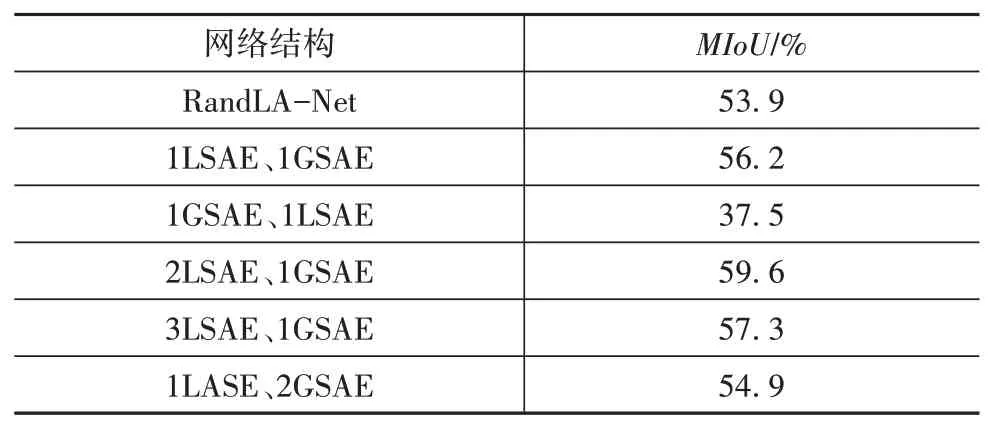
表1 LSAE、GSAE消融实验结果
表中“1LSAE、1GSAE”表示特征聚合模块先嵌入1个LSAE模块、再嵌入1个GSAE模块,“1GSAE、1LSAE”表示将2个模块串联顺序互换,先嵌入1个GSAE模块、再嵌入1个LSAE模块。
从结果 可 以看出,按照1个LSAE模块、1个GSAE模块顺序嵌入特征聚合模块组成的网络基本结构语义分割MIoU为56.2%,这说明2个注意力模块的加入使得本网络相比于基准网络RandLA-Net具有更好的特征提取能力;当把LSAE、GSAE的串联顺序互换,即先通过GSAE提取全局特征、后通过LSAE提取局部特征时,MIoU降为37.5%,这是因为GSAE模块通过计算注意力得分提取全局特征以后破坏了各点之间原本的结构信息,使得LSAE无法再捕获局部特征,从而导致分割精度下降;当按照“先LSAE,后GSAE”的串联方式增加1个LSAE模块时最终精度提升了3.4个百分点。分析可知,当网络中有2个LSAE模块时,网络先通过1个LSAE提取特征维度为dout∕2的局部特征,然后再通过1个LSAE提取特征维度为dout的局部特征,从而提高了特征提取能力;而继续将LSAE模块增加到3个时精度反而有所下降,这是因为当使用3个LSAE模块提取特征时,相邻2个LSAE模块特征维度相差较小,网络提取到了相似的特征,会使得网络趋向于过拟合,从而导致分割精度下降;当固定LSAE模块为1个,增加1个GSAE模块时,MIoU比原来下降了1.3个百分点,这说明了1个GSAE模块已经很好地提取全局上下文信息,2个GSAE模块使网络提取到了多余的特征,产生了过拟合的现象。因此在最终的网络实现中,选取“2LSAE、1GSAE”的串联方式搭建FAM模块。
2.3.2 LSAE模块小目标分割提升效果验证
车辆、行人等交通参与者是自动驾驶场景语义理解的重点,但受限于车载雷达采集的缺点,车辆、行人等小目标点云会出现部分缺失、远处点云密度稀疏等问题,这使得网络对于小目标物体的语义分割更加困难。为了验证本文设计的注意力模块对于小目标分割精度的提升效果,将RandLA-Net网络中的局部聚合模块分别替换为LSAE模块、GSAE模块和两者组合搭建的FAM模块,与原网络一起分别在SemanticPOSS数据集上测试,除特征提取模块不同以外,其他参数和超参数均与RandLA-Net原文中设置保持一致,选取数据集中汽车、行人、骑手3个交通参与者目标进行对比,结果如表2所示。
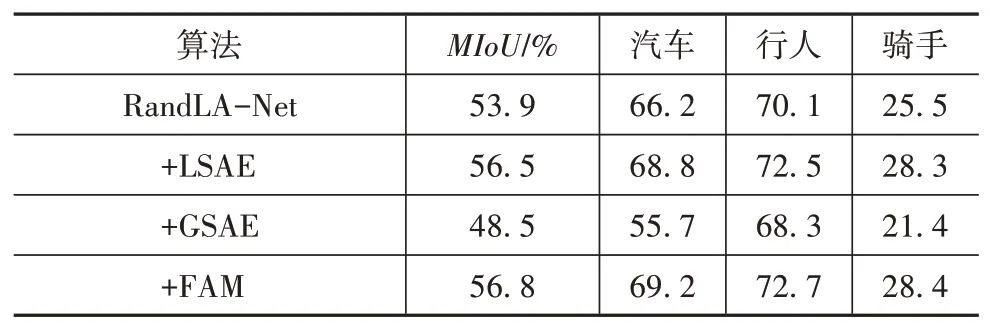
表2 小目标分割提升效果验证
表中“+LSAE”表示将RandLA-Net中的局部聚合模块替换为LSAE模块,“+GSAE”模块表示将局部聚合模块替换为GSAE模块,“+FAM”表示将局部聚合模块替换为FAM模块,即按照LSAE模块、GSAE模块的顺序串联后替换到原网络中。
由表2可知,将局部聚合模块替换为LSAE后,汽车、行人、骑手的分割精度均有提高,MIoU相比原网络也提高了2.6个百分点,分析可得,逐点的自注意力机制通过计算中心点与邻近点的注意力关系赋予特征提取的权重,对于小目标,其内部点的数量也比较少,LSAE模块的感受野能够覆盖这些物体,从而可以更好地捕获局部结构信息;把原网络局部聚合模块替换为GSAE模块后分割精度反而降低为48.5%,这是因为原网络中局部聚合模块具有局部特征提取的能力,而GSAE无法对局部特征进行提取,从而使分割精度有所下降;在加入FAM模块后分割精度为56.8%,与仅加入LSAE模块相比分割精度仅提升0.3个百分点,由此可知GSAE模块对于小目标特征提取能力的提升效果并不明显。
从图3对SemanticPOSS数据集预测结果可视化中可以看到,添加LSAE模块后本文网络可以准确预测出远点处有遮挡的行人、骑手等小目标(图中黄圈标出),甚至还分辨出了真值语义中标错的对象(图中白圈标出,在真值语义标注中,将该对象标注为行人,但通过动作可以看出目标为骑手),这也验证了本文方法的可靠性。
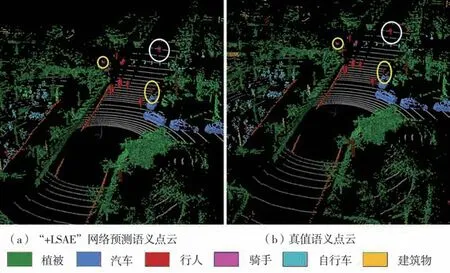
图3 SemanticPOSS数据集02序列第472帧
在LSAE模块中,影响感受野的参数是KNN最近邻查找中的邻近点个数k。为了探究邻近点个数k对于语义分割的影响,在上面的网络中改变邻近点个数k进行实验,在SemanticPOSS上的实验结果如表3所示。
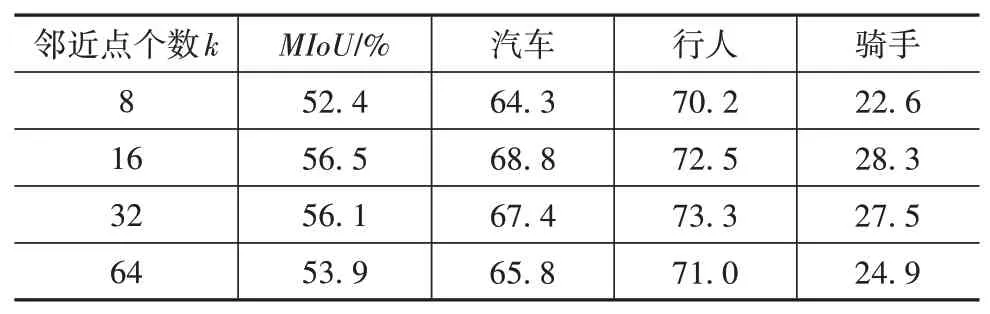
表3 邻近点数量实验结果
从表中结果可以看出,当邻近点个数为8时,由于单次局部自注意力聚合的点过少,LSAE模块能够学习到的局部特征信息很少,分割结果较差;当邻近点个数为16或32时,语义分割结果表现最好,LSAE模块能够充分提取内部特征;而当邻近点个数增加到64时,分割结果反而变差,这是因为邻近点个数过多,对于小目标点云,更多的其他相邻结构(如地面)被LSAE模块纳入相关性计算过程,从而使提取到的特征变差。而且激光雷达点云具有近密远疏的特点,远点处的小目标物体点密度更低,这也使得网络对邻近点个数更加敏感。总体来看,邻近点个数为16或32时均可以获得很好的分割效果,但当邻近点个数是16时网络参数量少、内存占用较小,因此在最终网络实现中邻近点个数选取为16。
2.3.3 语义分割网络实时性验证
在自动驾驶场景中,分割算法的实时性是必须考虑的重要指标。为了验证本文算法的计算实时性,将本网络、RandLA-Net和目前基于点的方法中分割精度最高的KPConv分别对SemanticKITTI数据集08序列(共有4 071帧点云数据)进行前向推理,将每帧的81 920个点输入网络中对比完成08序列点云前向推理所消耗的时间。3组实验均在同一块NVIDIA RTX3090显卡上进行,除网络结构不同外其他设置均相同,实验结果如表4所示。
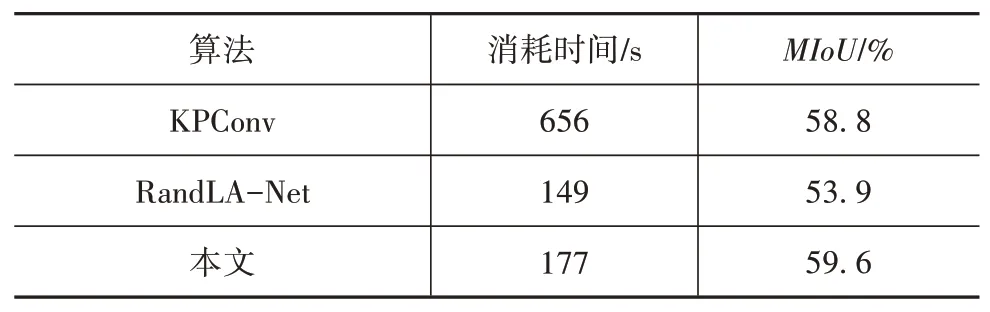
表4 前向推理消耗时间
表中MIoU一列标注出了3组网络在SemanticKITTI数据集上19类物体的语义分割交并比以便从分割精度和分割实时性上进行对比。从表中可以看出KPConv消耗时间最长,处理4 071帧点云使用了656 s(约6FPS),KPConv使用网格下采样方法以确保每次下采样点云位置的空间一致性,这增加了点云处理的时间消耗;得益于随机降采样的计算效率,RandLA-Net和本文网络所消耗时间相比于KPConv大大减少,RandLA-Net所用时间为149 s(约28FPS),本文网络所用时间为177 s(约23FPS)。与RandLA-Net和KPConv对比分析可知,本文网络在提高了分割精度的同时也保持了较高的分割效率。
2.3.4 最终结果分析
在SemanticKITTI数据集上对本文的网络进行测试验证,并将MIoU和19类物体分割交并比与现有网络进行对比,结果如表5所示。
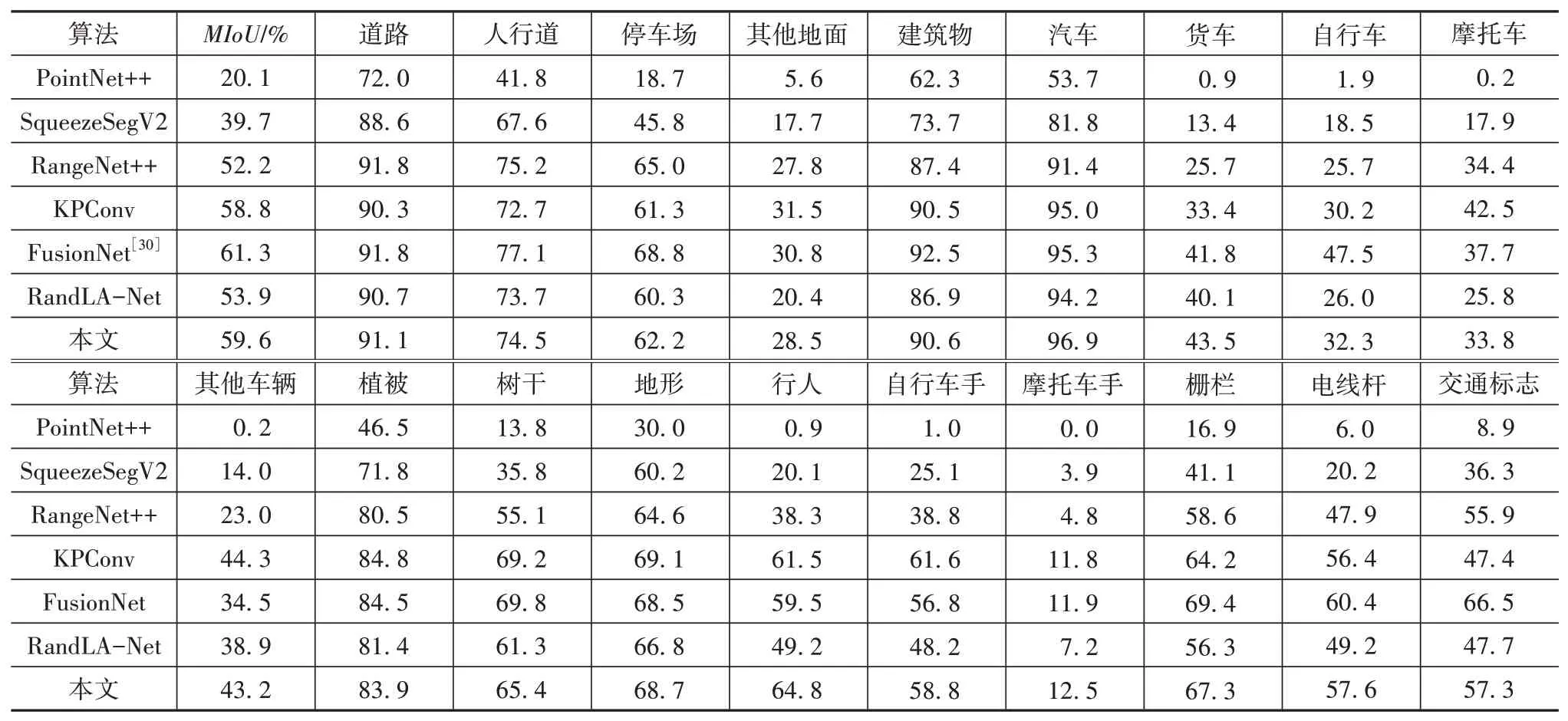
表5 SemanticKITTI数据集语义分割结果
从表中可以看出,本文网络的语义分割MIoU达到了59.6%,比目前基于点的最好的网络KPConv提高了0.8个百分点。与同样用局部特征聚合模块进行特征提取的RandLA-Net网络相比,最终MIoU提高了5.7个百分点。进一步对比分析可得,与RandLA-Net相比,本网络每个类别的分割交并比均有不同程度地提升,这也进一步验证了全局自注意力编码器对于全局上下文信息提取的作用。在对SemanticKITTI数据集中第08序列第729帧点云可视化的图4中可以看到,RandLA-Net将行人点云误判为地面和植被,而本文算法可以准确分割,这说明了本网络相比于RandLA-Net具有更强的局部特征提取能力。通过横向比较可以看到网络对于摩托车骑手(motorcyclist)分割精度很低,这是因为在数据集中摩托车骑手的数量相比于自行车骑手(bicyclist)较低,且在稀疏的点云表示中这两者结构相似,在网络特征提取时容易将两者混淆。另外还可以看到,本文的方法相比于多模态融合的方法(FusionNet)还有差距,基于点的方法虽然在速度和存储上具有很大优势,但在分割精度上仅仅通过提取稀疏点的信息相比于通过图像、体素、深度信息等多模态的方法仍有差距。在本文方法的基础上再通过融合图像、体素等方式以提高分割精度也是未来改进的重点方向。
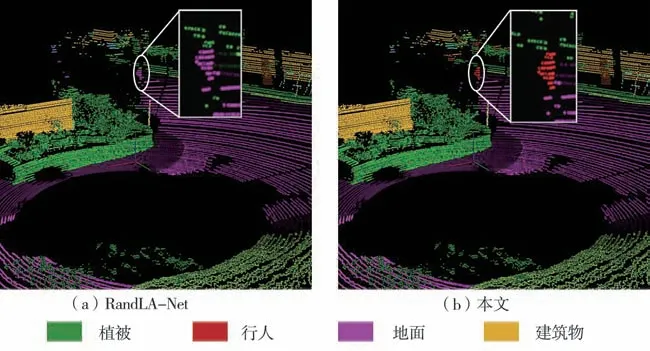
图4 SemanticKITTI数据集08序列第729帧
3 结论
本文中基于自注意力机制的特点,设计了局部自注意力编码器和全局自注意力编码器,将它们应用到了自动驾驶场景点云语义分割网络中,综合两种不同的自注意力特征提取方式来增强点对于邻域拓扑结构的学习能力,并在SemanticKITTI和SemanticPOSS两个大型语义分割数据集上进行测试。实验结果表明,本文方法超过了目前最优的基于点的点云语义分割网络,并且具有较高的分割效率,验证了自注意力机制在点云语义理解任务中的有效性。
但由于稀疏点云本身的特点,对于结构相似的物体仅通过对于点的拓扑结构进行特征提取无法保证准确性,如何设计编码器结构使得网络可以从更细粒度的结构中学习到相似物体的不同特征也是基于点的语义分割方法需要重点研究的方向之一。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
家庭医学(2022年3期)2022-04-07
锻压装备与制造技术(2021年5期)2021-11-13
贵州大学学报(自然科学版)(2021年5期)2021-09-26
电子技术与软件工程(2021年8期)2021-06-16
现代计算机(2021年8期)2021-05-13
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
