
基于条件对抗网和层次特征融合的目标跟踪
2022-12-06 10:34单玉刚
计算机工程与应用 2022年23期
张 磊,单玉刚,袁 杰
1.新疆大学 电气工程学院,乌鲁木齐 830001
2.湖北文理学院 教育学院,湖北 襄阳 441053
目标跟踪是计算机视觉领域一个重要的研究方向,它在视频监控、人机交互等方面得到广泛应用[1]。现在目标跟踪仍面临很多挑战,当跟踪目标的外观变化和背景干扰等复杂情况发生时,易导致跟踪失败。因此,仍需深入研究准确率和稳健性更高的算法。
随着深度学习的发展,基于卷积神经网络(CNN)的目标跟踪方法引起了国内外专家学者的关注。基于CNN的目标跟踪通常有三种方法。第一种方法是深度学习与相关滤波相结合,这种方法将CNN提取的特征与相关滤波框架结合,比如ECO[2]、CCOT[3]。第二种方法使用CNN的跟踪框架,首先在离线状态下对网络进行预训练,在线运行时再进行调整,比如DLT[4]算法。第三种方法是使用孪生网络,比如SiamFC[5]、SiamRPN[6]、SiamMask[7]等。由于孪生网络的子网共享权重,加快了训练和检测速度,而且子网使用相同的模型处理输入,适用于图像匹配。因此,基于孪生网络目标跟踪成为当前目标跟踪领域研究热点。SiamFC使用AlexNet作为骨干网的全卷积孪生网络经典算法,具有跟踪精度高、速度快的特点。双重孪生网络SASiam[8],同时提取外观特征和语义特征,可以更好地刻画目标特征。SiamRPN使用候选区域生成网络(RPN)提升了尺度变化场景下跟踪器的表现。SiamRPN++[9]引入通道互相关操作,为了保持网络的平移不变性,使用空间感知采样策略。SiamDW[10]提出一种由CIR残差单元组成的深度网络,将SiamFC和SiamRPN的主网络替换为更深层的网络,获取到更丰富的特征信息。SiamMask实时进行目标跟踪和半监督视频对象分割。TransT[11]借鉴Transformer结构改进传统孪生网络中的特征融合操作,利用Transformer中的注意力机制将模板信息融合到搜索区域中,以便更好地进行目标定位和尺度回归。
全卷积孪生网络SiamFC存在两个问题。第一,在快速移动的情况下,跟踪器的定位能力不足,当目标剧烈运动时,容易造成图像模糊,SiamFC网络难以提取到目标的有效特征,易导致跟踪失败。第二,作为它的骨干网络,改进的AlexNet[12]作为SiamFC的骨干网络,其深度较浅,仅使用深层特征,特征提取能力不强。
为解决这两个问题,本文提出一种基于条件对抗网和层次特征融合的目标跟踪算法。针对当目标因跟踪视频序列分辨率较低时,SiamFC的表征能力下降的问题,本文算法嵌入条件对抗生成网络模型(DeblurGANv2)[13],提高图像的分辨率,以获得更为有效的特征,增强算法在低分辨率情况下的跟踪效果。针对SiamFC骨干网络信息表达能力不强的问题。首先,将SiamFC骨干网络AlexNet网络替换为具有19个卷积层的改进型VGG-19[14]深度网络。其次,在网络的浅层,提取高分辨率特征,其包含有效的位置信息;再选取一个中层特征用于融合;然后,在网络的高层,采集丰富的语义信息;最后,将三层特征信息进行加权融合,使跟踪器可以获得更为丰富的位置信息。
1 基于全卷积孪生网络的目标跟踪
SiamFC包括权重共享的两个输入分支,模板分支和搜索分支。模板图像和搜索图像分别被裁剪后输入网络,经过一个全卷积无填充的AlexNet,提取图像特征,通过互相关操作得到响应得分图。响应得分图通过匹配函数计算预测分数,函数表示如下:

式中,x是搜索图像;z是模板图像;f(z,x)是两者的相似度得分;变换ϕ(·)是卷积相关性计算;*表示互相关运算;b表示偏置项。
训练阶段的损失函数定义为:
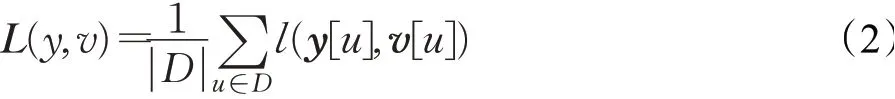
其中,D表示响应图共有多少个位置;y[]u是响应图在位置u的具体真实标签值,y[u]∈{+1,-1};v[u]表示响应图在位置u的预测值;l(·)表示损失函数,定义为:
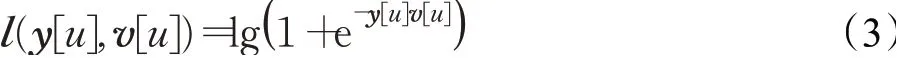
在SiamFC算法中为了最小化损失函数,采用了随机梯度下降法(SGD),以获得最优化模型参数θ。
2 基于条件对抗网和层次特征融合的目标跟踪
本文在SiamFC算法的基础上提出基于条件对抗网和层次特征融合的目标跟踪框架。首先,输入图像输入基于条件对抗网实现去模糊化;然后,经过多层卷积特征融合后,进行互相关操作后得响应得分图;取最大的得分位置,即是目标位置。使用条件对抗网络实现图像去模糊化,提高了对目标定位能力,和对小目标的辨别能力;低层特征包含更多空间信息,有助于目标定位,高层特征包含目标更多语义信息,有助于适应目标形变,通过多特征融合提高了目标表征能力。改进后的网络将会提高在复杂环境下目标跟踪精度,增强了目标跟踪鲁棒性。算法跟踪框架如图1所示。
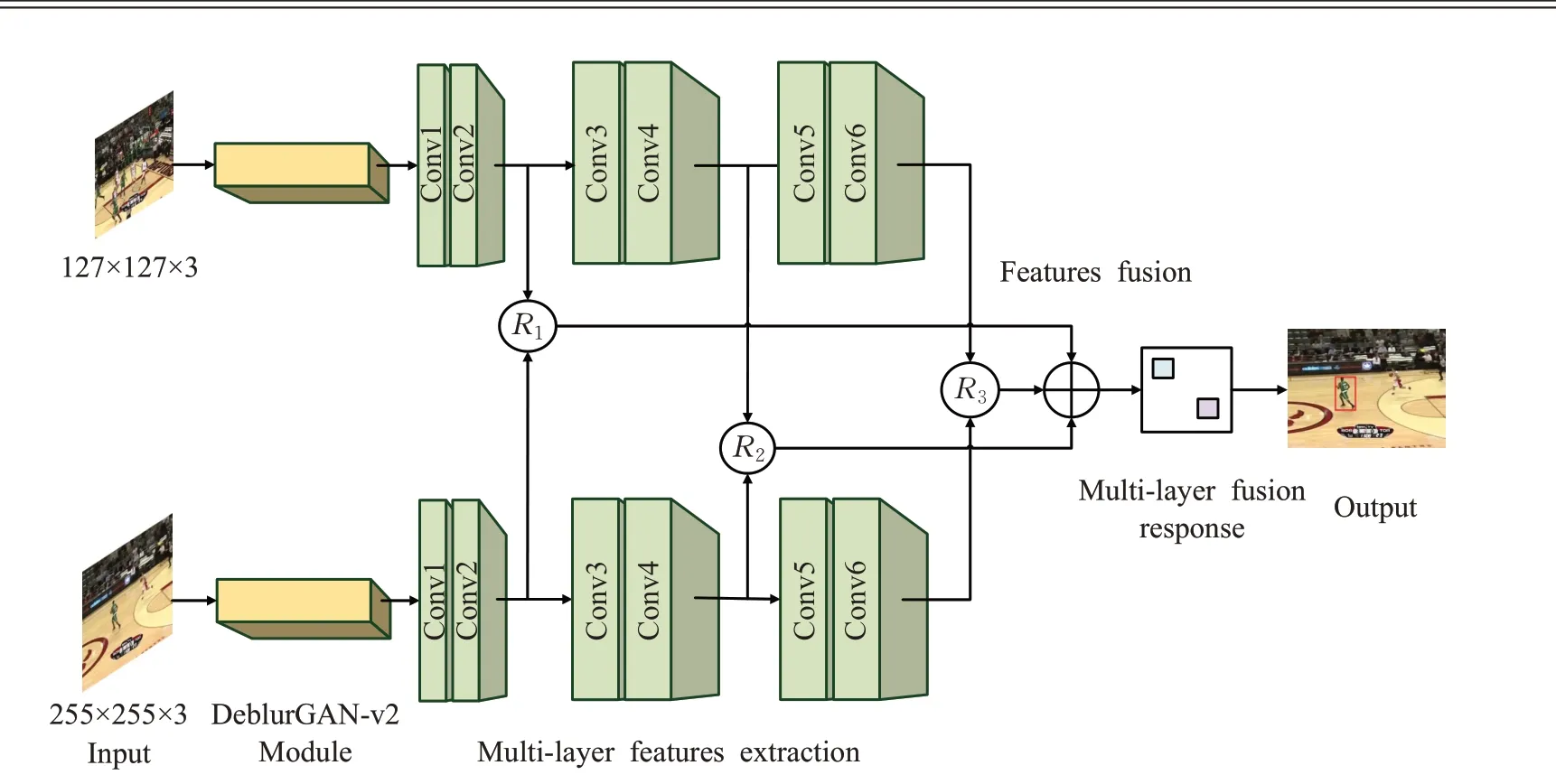
图1 本文算法跟踪框架Fig.1 Framework of propsed method
2.1 条件对抗生成网络模型
近些年来,生成对抗网络GAN[15]在图像生成领域得到广泛应用。GAN由生成器和判别器两部分组成。生成器采集数据并生成观测数据,判别器判别输入数据是否是真实数据。由于GAN存在梯度发散问题,会产生噪声,影响图像重建。结合GAN和多元内容损失来构建用于模糊移除的条件对抗生成(DeblurGAN-v2)模型,相比于CGAN等图像重建模型,DeblurGAN-v2模型对图像去模糊的精确率更高[13]。本文采用DeblurGAN-v2模型对SiamFC进行改进,使得跟踪网络能够通过条件对抗生成网络模型对低分率视频帧进行重建,提高图像分辨率,从而提高跟踪算法的精确度。
对模糊图像进行重建的数学模型如下:

其中,IB是模糊图像,k(M)是模糊核,Is是清晰图像,*代表卷积运算,N是噪声。本文对未知模糊核的计算采用卷积网络,模型基础框架如图2所示。网络框架可以分为两部分:生成器和判别器。当输入为模糊图像时,生成器可以生成清晰图像,然后将生成的图像输入判别器,判别器判断生成图像的“真假”。若图像为真,输出生成后的图像;若图像为假,重新输入生成器对图像进行重建。通过这种方式达到图像去模糊的作用。
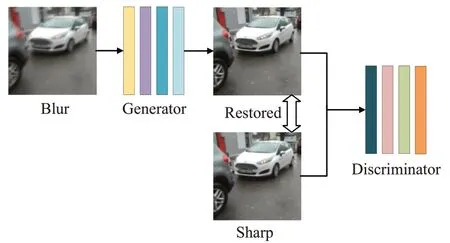
图2 条件对抗生成网络模型基础框架Fig.2 Basic framework of network model generated by conditional confrontation
2.1.1 条件对抗网络损失函数
传统GAN的训练过程十分不稳定,判别器D使用的是sigmoid函数,并且由于sigmoid函数饱和得十分迅速,sigmoid函数本质上不会惩罚远离决策边界的样本,尤其是在最小化目标函数时可能发生梯度弥散,使其很难再去更新生成器。而使用最小二乘GAN(LSGAN)作为判别器的损失函数可以解决这个问题,该损失有助于消除梯度消失,可以获得更加平滑且非饱和的梯度,LSGAN表达式为:
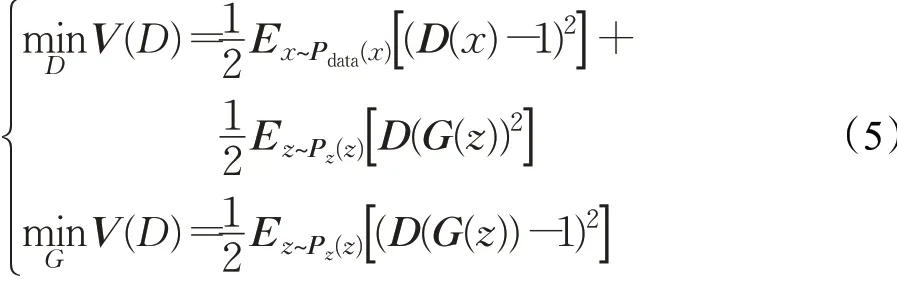
其中,D为判别器,G为生成器,x为真实数据,z为归一化噪声,Pdata(x)为x服从的概率分布,Pz(z)为z服从的概率分布,Ex~Pdata(x)为期望值,Ez~Pz(z)同为期望值。
本文所用的条件对抗生成网络模型损失函数RaGAN-LS在LSGAN基础上改进而来,适配了相对判别器模型,它可以使得训练更快、更稳定,同时生成的结果具有更高的感知质量、更优的锐度,该损失定义如下所示:
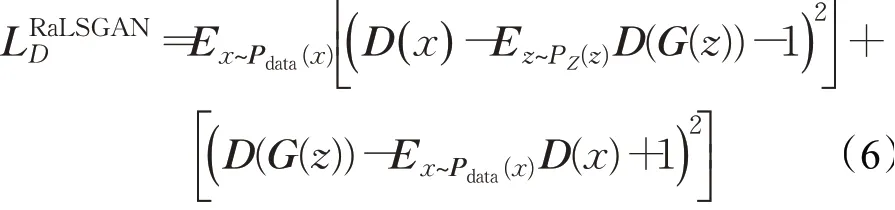
构建的损失函数定义如下:
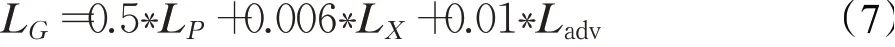
其中,LP表示mean-square-error(MSE),LX表示感知loss,表示内容的损失,Ladv表示全局和局部的损失,全局表示整个图片的损失,局部类比于PatchGAN,表示将整个图片分块为一个一个的70×70的局部图片的损失。
2.1.2 生成器和判别器网络结构
为了更好地保证生成质量,本文在生成器模型中使用feature pyramid network(FPN)结构进行特征融合。架构由一个FPN骨干网组成,从中获取五个不同尺度的最终特征图作为输出。这些特征被上采样到输入大小的1/4并连接成一个张量,其包含不同级别的语义信息。在网络的最后添加一个上采样层和一个卷积层来恢复清晰图像和去伪影。输入图像归一化到[-1,1],在输出部分添加tanh激活以确保生成图像的动态范围。FPN除具有多尺度特征汇聚功能外,它还在精度与效率之间取得均衡。本文在判别器模型中使用带有最小开方损失(least-square loss)的相对判别器(relativistic discriminator),并且分别结合了全局(global(image))和局部(local(patch))2个尺度的判别loss。
在上述框架基础下,骨干网络的选择直接影响最终的去模糊质量与效率。为了追求更高质量,本文选用Inception-Resnet-v2作为对抗网的骨干网络。本文采用的条件对抗生成模型结构如图3所示。
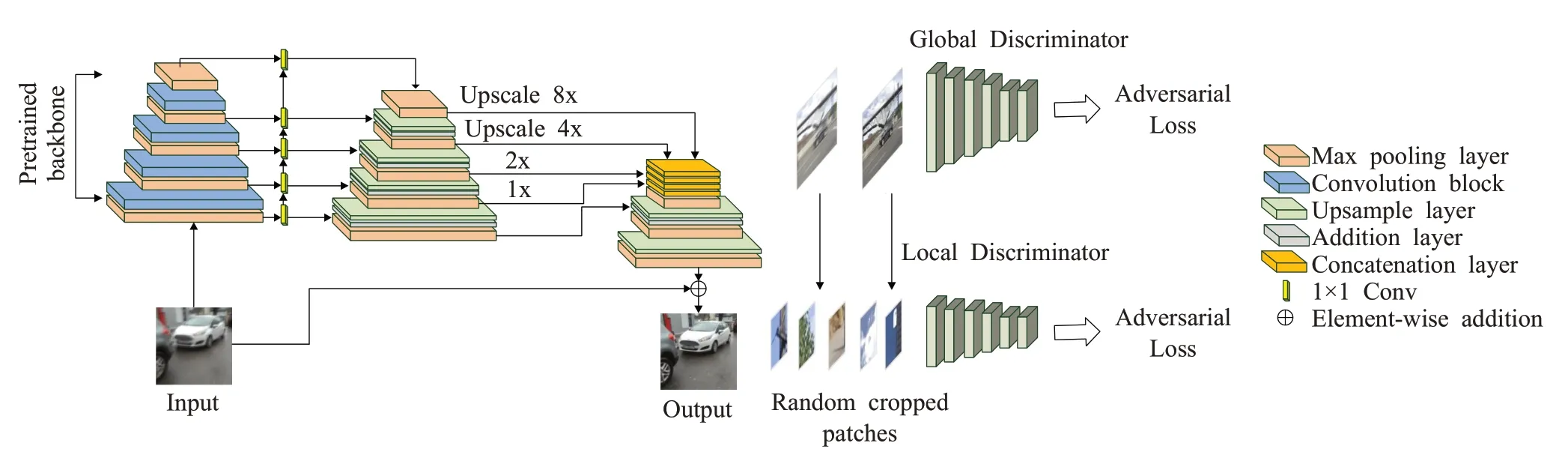
图3 条件对抗生成模型结构Fig.3 Model structure of conditional confrontation generation
2.2 孪生网络结构和参数
为了提升本文算法的特征提取能力,本文算法使用改进的VGG-19深度网络作为骨干网络[16]。因为直接用VGG网络替换AlexNet网络时,引入的padding会形成位置bias[8],导致预测准确度下降。针对padding带来的干扰,对于Conv1、Conv2层,裁剪(crop1)其特征图最外围两层,对于Conv3、Conv4、Conv5、Conv6层,裁剪其特征图最外围一层(crop2),可以有效消除padding给特征图边缘带来的影响。在这里使用了一种快速、高效的池化方法Softpool[17]来替换常用的最大池化层(maxpool),Softpool以指数加权方法累加激活,与一系列其他池化方法相比,Softpool在下采样激活映射中保留了更多的信息,可以获得更好的图像特征。综合以上讨论,本文网络参数如表1所示。

表1 骨干网络参数Table 1 Backbone network parameters
2.3 层次特征融合
孪生网络高层卷积特征具有更加丰富的语义信息,可以更好地区分不同对象;低层特征如边缘、颜色、形状等,包含更多的位置信息,可以帮助精确定位目标位置。对多层次卷积特征进行融合有助于提高算法的跟踪精度[18-19]。本文提取Conv2、Conv4、Conv6三层特征。
对提取到的不同层特征,高层分辨率较小,可以采用双线性插值的方法,将其特征图进行扩大,使各层的特征图具有相同的尺寸,实现融合。双线性插值可以描述为:

其中,P"i表示第i帧的多层特征融合后的得分图;wij表示第i帧第j层特征权重;Pij表示第i帧第j层响应得分图;j为需要融合的特征层序号,并且j=2,4,6。
层次特征融合的具体过程如下:
(1)将视频序列中第一帧图像输入模板分支。在Conv2层提取首帧位置特征,在Conv4层提取首帧中层特征,在Conv6层提取首帧语义特征
(2)在视频序列的后续帧i∈{1,2,…,N},将其输入搜索分支。在Conv2层提取位置特征;Conv4层提取中层特征,在Conv6层提取语义特征
(3)第i帧低层特征混合模板为,中层特征混合模板为,高层特征混合模板为使用自适应模板更新公式,确定
(4)将得到的混合模板作为响应模板,分别计算响应R1、R2、R3,对三个响应使用自适应权重进行融合。
(5)融合后的响应图中响应值最高的位置为预测目标位置。
3 实验和分析
为了验证本文算法有效性,使用OTB2015[20]和VOT2018[21]数据集作为验证集,与多个经典跟踪算法进行对比,基于各种实验分析,可以看出本文算法具有优秀的表现。
3.1 实验环境
本文算法使用Python语言在Pytorch框架下进行实验。实验环境如表2所示。

表2 实验环境Table 2 Experimental environment
3.2 训练集
训练阶段,对于条件对抗生成网络模型的训练,采用GoPro数据集,它包含2 013对模糊图像和清晰图像,全卷积孪生网络跟踪器的训练数据集选择GOT-10k和ILSVRC2015-VID两大公开标准数据集。GOT-10k数据集包含10 000个真实运动对象的视频片段和超过150万个手动标记的边界框。ILSVRC2015-VID包含了30多种目标,拥有超过4 000个视频,标注的帧数超过100万个。
3.3 实验结果分析
3.3.1 OTB2015定量分析
OTB2015拥有100个人工标注的视频序列,包含有11种属性,代表了当前目标跟踪领域的常见难点。将本文算法与CFNet[22]、SiamDW、SiamRPN、SRDCF[23]、DeepSRDCF[24]、fDSST[25]、Staple[26]以及SiamFC具有代表性的跟踪器进行比较。
如图4所示,是本文算法与对比算法在OTB2015数据上的定量对比结果。本文算法的精确度达到85.6%,成功率达到63.7%,都优于其他对比算法。与基准算法SiamFC相比,本文算法明显取得了很好的表现,精确度较之提升了8.5个百分点,成功率较之提升了5.5个百分点。
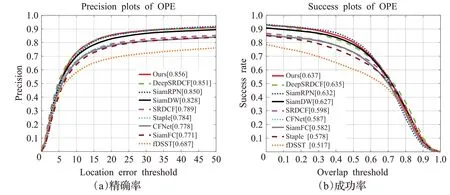
图4 不同算法在OTB2015数据集上的精确率与成功率对比图Fig.4 Comparison of accuracy and success rates of different algorithms on OTB2015 datasets
对于OTB2015数据集中各类难点属性的结果如图5所示,特别是对物体的低分辨率(low resolution)、快速运动(fast motion)、运动模糊(motion blur)等有很好的表现,在精确率方面分别取得了0.933、0.832、0.849,进一步证明了条件对抗生成网络模型和多层特征融合在目标跟踪上的有效性。
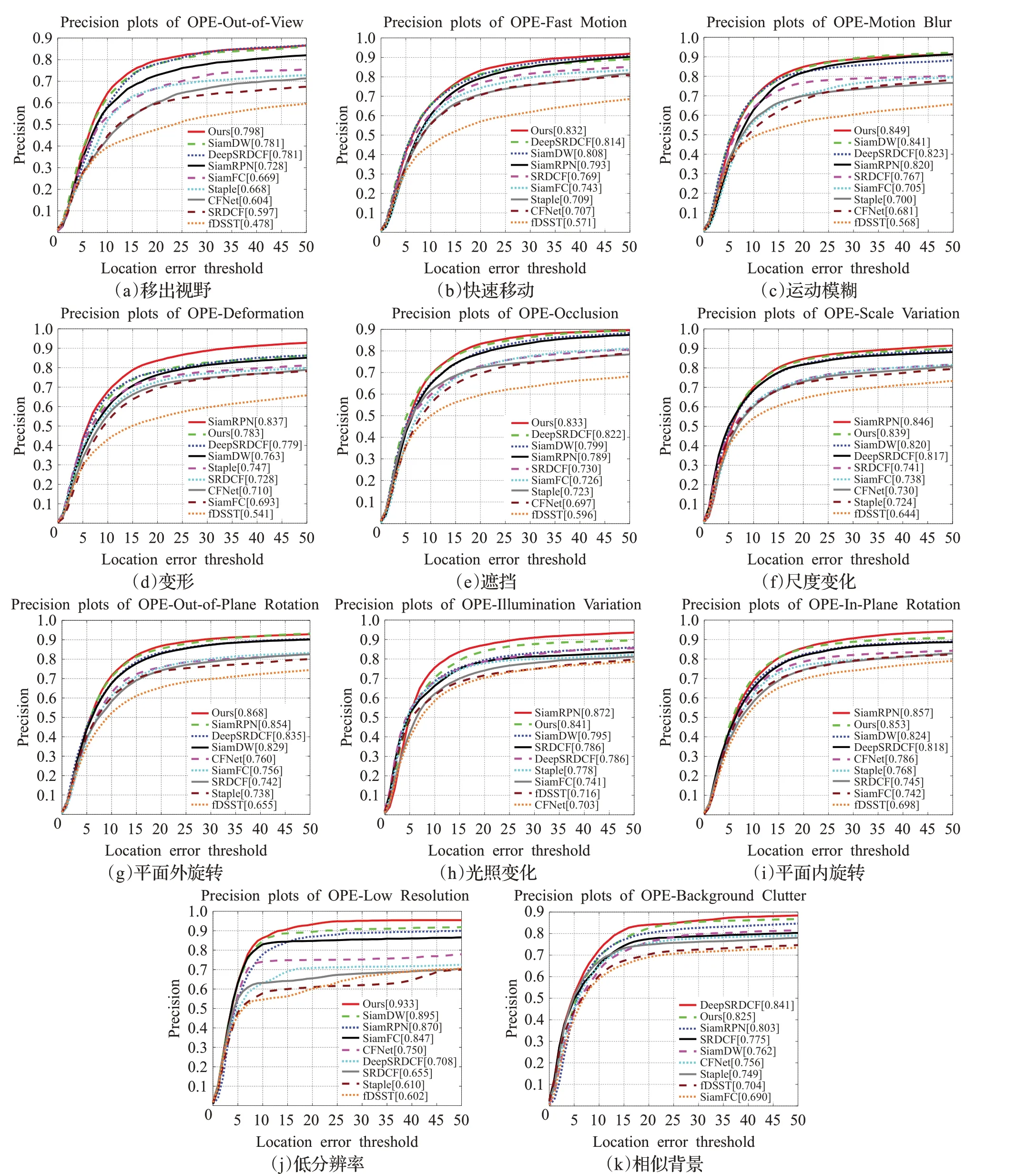
图5 不同算法在11类挑战下精确率的对比图Fig.5 Comparison of accuracy rates of different alogorithms under 11 types of challenges
3.3.2 OTB2015定性分析
为了对比本文算法与其他优秀算法的差异,选择了OTB2015的测试结果进行定性分析。测试结果如图6所示,由上到下分别为Skating1、Coke、MotorRolling、Skiing、CarScale、Football视频序列,六个视频序列包含了光照变化、遮挡、运动模糊、低分辨率、尺度变化、相似背景干扰等六种挑战场景。红色为本文算法,绿色、蓝色、黑色、粉色分别为SiamDW、SiamFC、CFNet、SiamRPN算法。

图6 在OTB2015不同视频序列下各类算法跟踪效果Fig.6 Tracking effect of various algorithms in different OTB2015 video sequences
(1)光照变化:在Skating1视频序列中,目标快速移动,其中还包括了遮挡,光照变化等情况,对跟踪过程造成了极大的影响。在第173帧左右,目标被遮挡,各算法均出现了一定程度的跟踪漂移。第312帧左右,由于光照变化,目标特征不明显,SiamFC算法跟踪跟踪失败,本文算法由于多特征融合模型的加入,可以获取到更多的目标特征,从而可以对当前目标位置做出有效判断。
(2)遮挡:在跟踪过程中,目标被遮挡会给跟踪带来较大的干扰。Coke视频序列中,随着目标移动,逐渐被绿叶遮挡,SiamFC已经出现了一定的偏移,目标继续移动,在整个跟踪过程中,相比其他对比算法,本文算法对目标的整体性跟踪效果良好。
(3)运动模糊:由于目标快速运动,会带来图像模糊等问题。在MotorRolling视频序列中,摩托车快速运动,造成了运动模糊,并且伴随目标旋转等挑战,跟踪难度较高。在32帧左右,SiamFC和CFNet已经出现了目标丢失,造成了后续的跟踪失败,本文算法和SiamRPN可以实现持续的跟踪。
(4)低分辨率:当图像帧的分辨率较低的时候,提取的特征不明显。在Skiing中,仅有本文算法和SiamRPN可以实现持续的跟踪,在60帧左右,SiamFC和CFNet均丢失了目标。而相比于SiamRPN,本文算法在低分辨率场景下有着更好的跟踪准确性,这很大一部分原因是基于对抗网络模型对视频帧的去模糊效果。
(5)尺度变化:在跟踪过程中,经常出现目标尺度变化的情况,在CarScale视频序列中,随着汽车由远及近驶来,目标不断变大,相比于其他对比算法,本文算法拥有更好的尺度估计结果。
(6)相似背景干扰:相似目标的干扰一直是目标跟踪中的难点问题之一,尤其在Football中,跟踪目标一方面运动较快,一方面光照变化剧烈,且存在目标被遮挡的情况。在289帧左右,目标被遮挡,基准算法SiamFC跟踪丢失,而本文算法在多层特征的特征增强下,对目标实现了持续且稳定的跟踪。
3.3.3 VOT2018定量分析
视觉目标跟踪(visual object tracking,VOT)是一个专门针对单目标跟踪的挑战赛。VOT2018一共有60个经过精细标注的短时跟踪视频集,且评价指标更为精细。VOT2018相比OTB2015,在跟踪序列上目标的变化更为复杂,跟踪难度更高。
如图7所示,在VOT2018数据集中本文算法与其他七个算法在基线上进行比较。表3显示,本文算法的平均期望重叠率EAO、准确率A仅低于SiamRPN,但是鲁棒性R好于SiamRPN。其中准确率越高性能越好,鲁棒性数值越低效果越好,期望平均重叠率越高效果越好。相比基准算法SiamFC,本文算法的EAO提升了16.4个百分点。同时,运行速度为每秒39帧,进一步证明本文算法具有较强的稳健性,满足实时性要求,可以实现很好的跟踪效果。
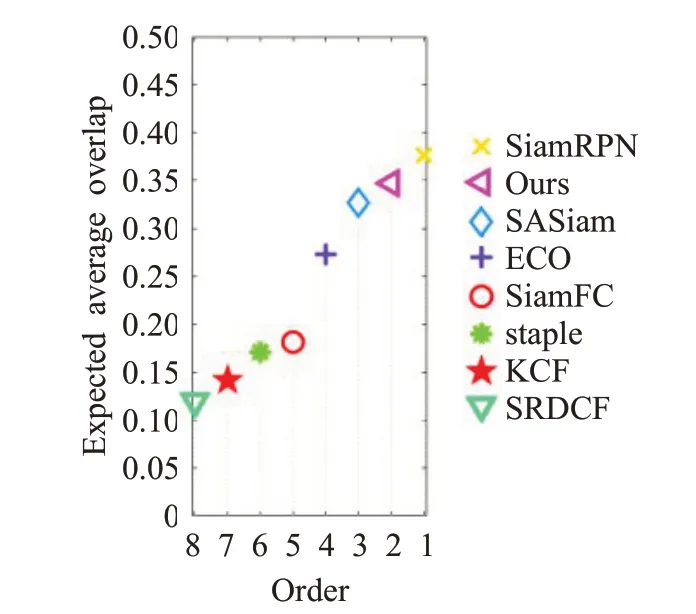
图7 不同算法在VOT2018数据集上EAO的对比图Fig.7 Comparision of EAO of different algorithms on VOT2018 datasets
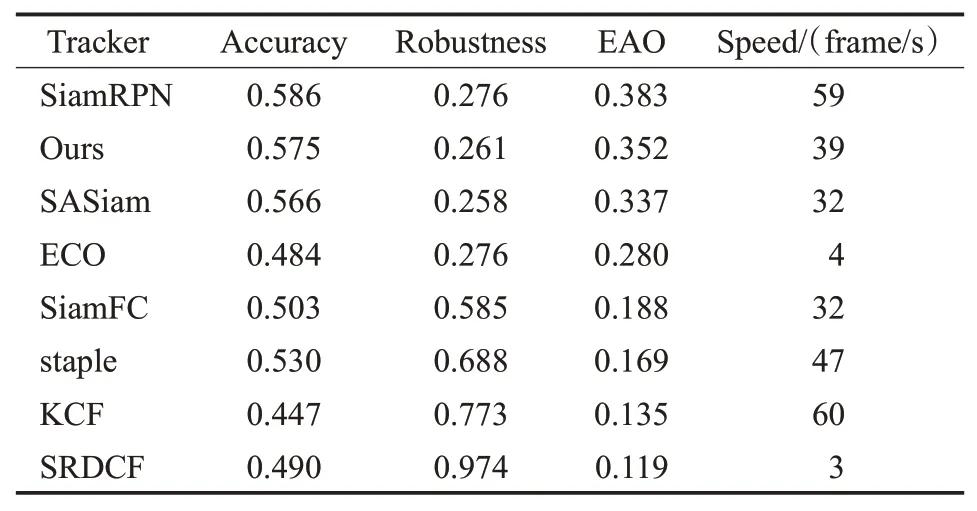
表3 不同算法在VOT2018数据集上的测试结果对比Table 3 Comparision of test results of different algorithms on VOT2018 datasets
3.3.4 VOT2018定性分析
在VOT2018数据集上选取五个视频序列进行定量分析,证明本文算法对小目标跟踪和模糊目标跟踪优于SiamRPN等算法。测试结果如图8所示,红色为本文算法,紫色、蓝色、绿色分别为SiamFC、SiamRPN、KCF[27]算法,青色为VOT2018数据集自带标注结果。

图8 选定VOT2018视频序列跟踪效果Fig.8 Selected VOT2018 video sequences tracking effect
在birds1序列,一方面序列的跟踪对象是一个小目标,另一方面图像较为模糊,目标特征不明显,本文算法仍可以有效地跟踪到目标,而且相比于其他算法,本文算法与VOT自带标注结果的重叠部分更多。basketball视频序列,图像模糊且存在相似目标的干扰,在265帧左右,已经有算法出现了跟踪异常的情况。在bmx序列中,由于目标旋转以及外观变化,其他算法已经无法有效跟踪到目标的整体特征,比如:bmx的第37、69帧。在soccer1序列,由于图像模糊,很容易干扰到跟踪器,在第115帧,目标被遮挡,SiamFC出现了跟踪丢失。在fernando序列,由于光照变化以及遮挡的发生,跟踪难度较大,相比于基准算法本文算法跟踪效果优异。
3.3.5 消融实验
对本文算法进行消融实验,分析参数影响。数据集使用OTB2015,实验结果如图9所示。其中,Ours代表本文算法,Ours-VGG表示基准算法只替换骨干网络为VGG-19并将层次特征进行融合,Ours-DeblurGAN表示在基准算法上加入用于模糊移除的DeblurGAN模型,Ours-CGAN表示加入典型对抗生成网络CGAN模型。从图9中可以看出,条件对抗网与多层特征融合等改进策略对原算法的性能均有着有效的提升,相比CGAN,DeblurGAN模型对算法性能提升更明显。
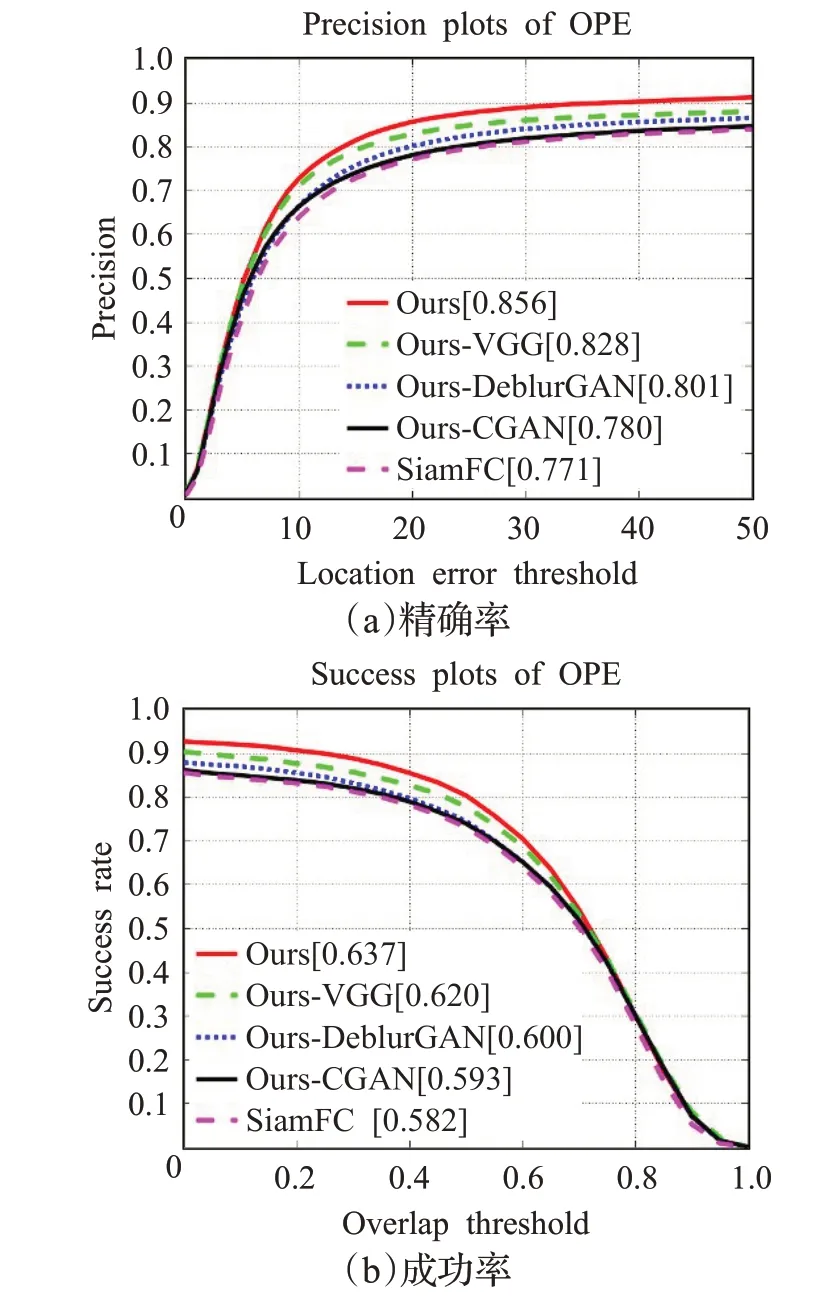
图9 算法关键环节对跟踪性能影响Fig.9 Influence of key parts of algorithm on tracking performance
4 结语
针对SiamFC在运动模糊和低分辨率等复杂场景下的跟踪能力不强问题,本文提出一种结合条件对抗生成网络和多层次特征融合的目标跟踪算法。在孪生网络中加入了条件对抗生成网络模型,对图像进行去模糊;并用VGG-19替换Alexnet作为孪生网络骨干网络。使用浅层特征提取位置信息,加入中层特征进行融合,使用高层特征提取语义信息,提高跟踪器的识别和定位能力。在OTB2015和VOT2018数据集上的测试结果表明,本文算法实时性能满足实际的跟踪需求,有效地提升了跟踪器的跟踪精度,在运动模糊以及低分辨率情况下具有良好的鲁棒性。但是本文算法在面对光照变化明显等极端情况时,跟踪效果不是非常理想,下一步的工作是尝试采用更深、更高效的主干网络来提取特征,以及引入模板更新机制。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
作文小学中年级(2020年6期)2020-07-24
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
北京航空航天大学学报(2018年1期)2018-04-20
