
FP-VTON:基于注意力机制的特征保持虚拟试衣网络
2022-12-06 10:33谭泽霖张少敏秦飞巍
计算机工程与应用 2022年23期
谭泽霖,白 静,2,陈 冉,张少敏,秦飞巍
1.北方民族大学 计算机科学与工程学院,银川 750021
2.国家民委图像图形智能处理实验室,银川 750021
3.杭州电子科技大学 计算机学院,杭州 310018
当今社会,网络和快递业高速发展,越来越多的消费者开始在网上购买服装,尤其是在疫情期间,在线购买服装更加成为一种主流。与传统购衣相比,网上购衣在时间、价格等方面都有着巨大的优势;但是另一方面,网店无法像实体店一样提供良好的试衣服务。在这样的情况下,虚拟试衣技术应运而生,它利用特定算法“将目标衣服穿着在模特身上”,为消费者提供逼真的试穿效果和良好的购物体验,有效降低退换货给销售商和消费者带来的时间、经济成本。
传统的虚拟试衣基于计算图形学,首先利用深度摄像机[1]或者基于图像的三维建模算法[2]建立消费者的三维测量数据,然后通过三维建模和虚拟仿真技术完成“试衣”,并渲染出最终的试穿图像。由于建立了三维模型,这种方法可以很好地处理几何变换与物理上的约束问题,提供相对真实的试穿效果。但是在三维模型建立的过程中往往需要大量的手工标注或者额外的硬件设备,这不仅增加了虚拟试衣的经济成本和时间成本,同时也使得这类方法难以适应服装产品的更新速度,严重制约了其应用前景。
随着深度学习技术在数字图像处理领域的飞速发展,基于二维图像的虚拟试衣技术作为一种更加简单经济的方案,受到越来越多的关注。这类算法将虚拟试衣问题转换为图像的条件生成任务,在不提供任何三维信息的情况下,仅仅利用目标服装和模特的二维图像,生成最终的试衣结果。其中,开山之作VITON[3]采用由粗到细的网络实现了基于图像的虚拟试衣;CP-VTON[4]则以VITON为基础,提出了可学习的几何匹配模板和掩码最大化损失,进一步提升了虚拟试衣结果对细节的保持能力。还有部分算法引入生成对抗网络完成虚拟试衣,如GarmentGAN[5]和VTON-GAN[6],它们较好地解决了手臂等对衣服的遮挡问题,但是在服装的细节保持方面仍然不够理想。
图1以细节保持能力突出且开放了源码的CPVTON为例,展示了现有算法在一些特殊情况下的试衣效果。可以看到:如图1结果1,当目标服装较为复杂,包含细节图案时,CP-VTON输出结果往往会产生模糊或变形,即,难以充分捕捉目标服装的细节特征;如图1结果2,当目标服装包含条纹等全局特征,而模特存在大姿态动作时,CP-VTON输出结果中的目标服装往往会产生较大的变形,即无法保留服装的全局纹理特征;如图1结果3,当模特体型偏胖,无法与目标服装直接对齐时,CP-VTON的输出结果往往会一定程度地抑制模特体型特征,即无法完整地保留模特的身体特征。

图1 FP-VTON与CP-VTON的试衣结果对比Fig.1 Visual comparison of synthesized images by CP-VTON and FP-VTON
仔细分析会发现,这是由于在虚拟试衣中人体模特是非刚性模型,穿着的过程也是一个非刚性变换。而传统的卷积神经网络受到卷积核大小和矩形感受野的限制,难以适应非刚性物体的大尺寸变形[7],因此当前所提出的这些基于深度学习的虚拟试衣网络往往无法在大变形的情况下充分保留人体模特和目标服装的全局属性特征(纹理特征和形状特征)和局部细节特征。为克服以上问题,需引入非局部操作,充分捕捉并保留目标服装变形前后的显著特征,确保虚拟试衣结果的合理性和真实性。为此,本文以CP-VTON网络框架为基础,提出了一种基于注意力机制的特征保持虚拟试衣网络FP-VTON(feature preserving virtual try-on network),具体效果如图1中第四列所示。本文的主要贡献包括3个方面:
(1)设计了服装保真损失,并将其应用于服装变形阶段,在确保目标服装与模特体型匹配的前提下,更好地保留了目标服装的全局属性特征。
(2)在人体特征表示、服装表示及试穿三个阶段分别引入特征注意力FA(feature attention),消除了传统规则卷积神经网络无法有效适应非刚性物体变形的问题,进一步增强了网络对目标服装全局属性特征的保持能力,且自动识别并有效保持目标服装的细节特征及模特的人体特征。
(3)在标准数据集上的定量定性实验充分说明了本文算法在较小的参数量和训练时间代价下,在目标服装及人体特征保持方面获得了突出性能。
1 相关工作
虚拟试衣隶属于时尚分析与合成这一领域.近年来,随着互联网经济和人工智能技术的飞速发展,时尚分析与合成相关的任务在实际应用中展现出了巨大潜力,受到了研究者们的广泛关注。现有研究大多聚焦在服装相容性和匹配学习[8-9]、时尚分析[10-12]、虚拟试衣[3-6]等,其中虚拟试衣是时尚分析中最具有挑战性的任务。
1.1 人体解析
人体解析和理解在许多任务中都得到了应用,如行为识别、交通监控等.现有工作可以分为三类:(1)身体部分解析[13];(2)人体姿势解析[14-15],包括2D姿势、3D姿势或者身体形状等;(3)服装解析[16]。
二维虚拟试衣网络的输入包括模特图像及目标服装图像,为了在试衣结果中既体现目标服装的效果,又保留人物体型和姿势特征,需在虚拟试衣之前提取人物体型、姿势等特征作为条件指导虚拟试衣结果的生成。CAGAN[17]中没有使用人体解析模型,直接使用模特和目标服装的二维图像完成虚拟试衣,只能生成粗略的试衣图像,无法适应细节和几何变化。VITON[3]和CP-VTON[4]在虚拟试衣中使用了相同的人体解析模型,包括人体姿态表示、身体形状表示和身份特征表示,在完成虚拟换衣的同时更好地保留了模特的身份信息及身体姿态。本文中,将采用相同的人体解析模型。
1.2 虚拟试衣
整体来看,虚拟试衣可以分为两类:基于三维人体建模的方法和基于二维图像的方法.其中基于三维人体建模的方法可以产生更好的效果,但是需要额外的3D测量和大量的计算[1-2,18-20],本文不做重点介绍。
目前主流的研究集中于二维图像的方法。2018年,Han等人[3]提出了基于二维图像的深度学习网络VITON,将虚拟试衣问题转换为三个阶段:首先利用编码器解码器网络生成初步试衣结果;然后采用上下文匹配计算TPS变换参数,扭曲服装使其与模特姿态相匹配;最后将扭曲后的衣服与初步试衣结果图像合成,生成最终结果。该工作利用深度学习解决虚拟试衣问题,构建了适用于虚拟试衣的数据集,且取得了较好的效果;但是,当目标服装包含复杂细节时,其试穿结果会与目标服装存在一定差异。此后,Wang等人[4]提出的CP-VTON,设计了几何匹配模块实现目标服装与人体姿态的对齐,通过试穿模块完成最终的虚拟试穿,显著改善了虚拟试衣算法对目标服装的细节保持能力。
生成对抗网络能够通过生成器和判别器之间的彼此对抗提高生成图像的质量,自2014年提出后[21],在图像生成和图像翻译领域得到了广泛应用[22-24]。2017年,Jetchev等人[17]将生成对抗网络引入虚拟试衣中,提出了CAGAN,使用CycleGan[25]的思想实现了简单的服装更换功能,但是试衣效果较VITON架构有较大差距。2019年,Honda等人[6]在VITON的基础上,引入了对抗损失,提出了VTON-GAN,改善了虚拟试衣中的手臂遮挡问题。Xu等人[26]在CAGAN基础上进行了改进,但是在服装的细节保持方面较CP-VTON有所减弱。2020年,Raffiee等人[5]提出了一种基于生成对抗技术的网络框架GarmentGAN,通过形状传输网络与外观传输网络,结合分割信息和人体关键点信息,改进了生成图像的真实性与遮挡问题。总体来说,通过引入生成对抗的思想,以上网络在人体遮挡等方面具有更好的效果;但是另一方面,上述网络不能很好地保留生成图像中如商标图案等一些细节。在这一点上,本文提出的基于注意力机制的特征保持虚拟试衣网络FP-VTON可以有效地改善这一问题。
2 本文方法
如图2所示,本文以CP-VTON的网络框架为基础,提出了FP-VTON,该网络分别在人体表示、服装表示、服装融合三个阶段加入特征注意力FA,充分捕捉人体及目标服装的显著特征;在TPS变换后加入网格正则化的服装保真损失,确保服装整体纹理特征的不变性。下面将围绕特征注意力,网络整体架构两个部分介绍FP-VTON。
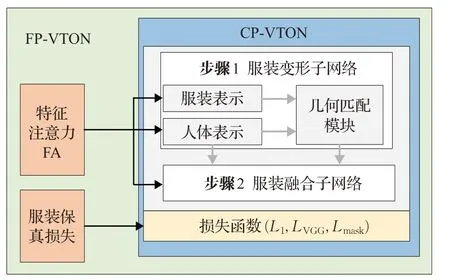
图2 FP-VTON算法的整体框架Fig.2 Overview of FP-VTON
2.1 特征注意力模块
为了突破传统卷积核的空间限制,捕捉人体模型的非刚性特征,实现虚拟试衣非刚性变换中的特征不变性,本文引入本小组先前在图像翻译任务中所提出,具有非局部属性的特征注意力模块FA[27]。具体地,如图3所示,输入特征x,通过以下三步构建其非局部增强特征:
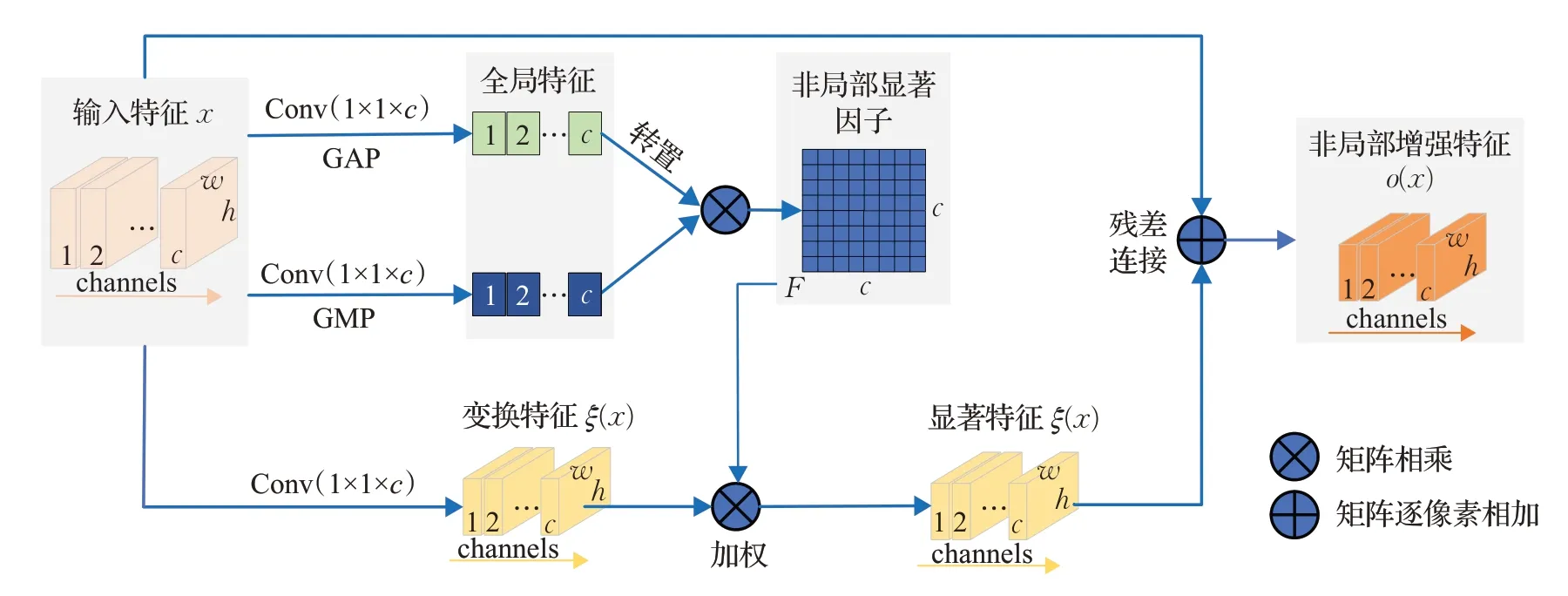
图3 特征注意力模块Fig.3 Feature attention(FA)module
步骤1构建非局部显著因子矩阵F。通过1×1的卷积及全局平均池化,1×1的卷积及全局最大池化分别获取两个1×1×c的全局特征,再转置相乘得到不同特征间的相关矩阵F。该矩阵中第i行的取值反映了通道i的特征和其他通道间特征的相关性,具有非局部属性,且通过相乘操作进一步突出了显著特征,本文称其为非局部显著因子矩阵。该矩阵具有“突破卷积核大小和矩形感受野的限制,捕捉特征间的长距离依赖关系”的优良特性。
步骤2计算显著特征ξ(x)。通过1×1的卷积将输入特征变换到特征空间ξ(x),再将显著权重因子作用于变换后特征,可获得显著特征ξ(x)。由于显著因子矩阵F突破了局部感受野的限制,捕捉了特征之间的全局依赖关系,因而,以上的加权操作可捕捉ξ(x)中各点对全局显著特征的响应。
步骤3通过加权残差连接构建非局部增强特征o(x),有o(x)=λξ(x)+x,λ∈[0,1]。显然,输出特征o(x)既保留了原始输入特征的局部特征信息,同时又一定程度地体现了非局部显著特征,即全局属性特征。
本文将在虚拟试衣网络的各个阶段引入特征注意力模块以充分捕捉目标服装及人体姿态的整体特征及局部细节特征。
2.2 网络整体结构
图4给出了FP-VTON网络的整体结构:以人体解析模型p和目标服装c为输入,依次通过服装变形和服装融合两个子网络,可输出模特的虚拟试穿结果ro。其中,服装c为一张二维图像,无需特别介绍;下面将给出人体解析模型p的表示及各个阶段的主要步骤。
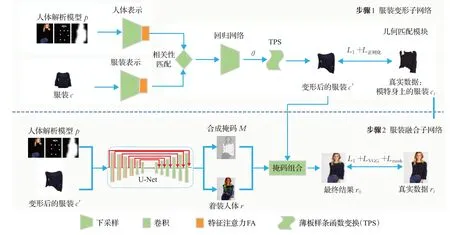
图4 FP-VTON的整体网络结构Fig.4 Overall network architecture of FP-VTON
2.2.1 人体解析模型
本文中,为有效保留模特的整体姿态和身份信息,采用了与VITON[3]相同的人体解析模式,由3部分组成:(1)人体姿态表示,旨在刻画人体的整体姿态,对应一个18通道的特征图,每个通道对应人体姿态的一个关键点,每个关键点被转化为一个11×11的热图;(2)身体形状表示,旨在区别人体的身体部分和其他部分,对应一个单通道的二进制MASK,1表示人体部分,0表示其他部分;(3)身份特征表示,旨在刻画人物的身份信息,对应脸部和头发的RGB图像,即3通道特征图。以上3部分信息共同组成一个22通道的特征图,构成了包含人体身份信息、人体身体定位和人体关键点信息的完整描述。
2.2.2 服装变形子网络
服装变形子网络旨在学习生成与人体相匹配的变形后的服装c"。该网络结构同CP-VTON[4]相同:输入目标服装c及人体解析模型p,首先通过包含特征注意力模块FA的下采样层,提取它们的高层次特征;然后通过相关性匹配层,计算两个高层特征之间的相关性,并将它们组合为单个张量;再输入回归网络预测薄板样条函数TPS(thin-plate spline)的空间变换参数θ;最后将变换参数θ输入TPS变换,完成输入服装c到形变服装c"的变换。本文与CP-VTON不同的是,在人体和服装的高层次特征提取网络中均加入了特征注意力模块FA,以更好地捕捉人体及服装的全局属性特征和局部显著特征,详细对比将在实验部分给出。
服装变形子网络是一个相对独立的端到端可学习的子网络。在训练阶段,使用了CP-VTON所提出的像素级L1损失,以评价该网络所生成形变服装c"与真实服装ct之间的一致性。式(1)给出了该损失函数的具体定义:
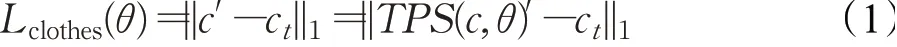
其中,θ为网络学习所得的TPS空间变换参数。该损失函数要求目标服装和真实服装图像对应像素之间的距离尽可能近,当目标服装包含复杂图案且模特存在大姿态动作时,会产生如图5所示的局部变形。深入分析可发现,这是由于式(1)仅仅考虑了像素级别的一致性,忽略了局部结构的一致性,因而可能产生局部形状特征或全局纹理特征的变形。

图5 CP-VTON失败案例Fig.5 Failure cases of CP-VTON
针对以上问题,本文在L1损失基础上,设计新增了用于服装保真的网格正则化损失函数。如图6所示,该损失函数作用在TPS变形后的网格之上,要求其水平和垂直方向的距离及两对斜率的差值(k1-k2),(k3-k4)尽可能小。具体表达式如下:
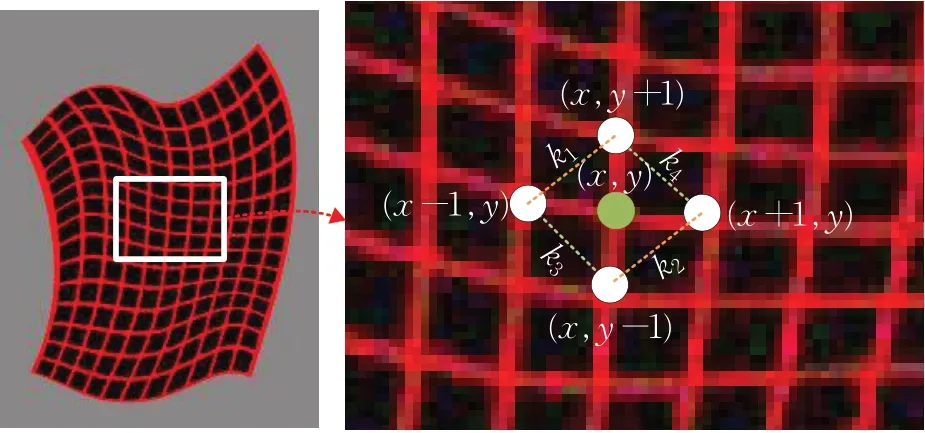
图6 网格正则化损失函数卷积形式示意图Fig.6 Diagram of convolution form of grid regularization loss function
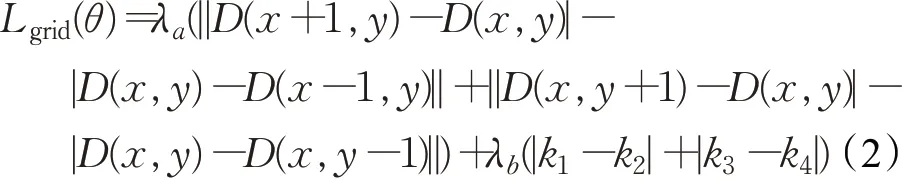
式中,D(x,y)为对应点在网格中的坐标值,λa和λb为权重因子,用以调节拉普拉斯正则项损失同斜率损失之间的比重。
综合式(1)和式(2),第一阶段服装扭曲子网络的整体损失为:
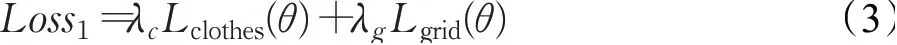
式中,λc和λg为权重因子,旨在调节像素级损失Lclothes同服装保真的网格正则化损失Lgrid之间的比重。
图7展示了网格正则化损失对服装变形的保真能力。图中左侧第一列为输入网格;第二列为两幅目标服装;第三列展示了无保真损失时的变形网格结果,即λc=1,λg=0;第四列展示了仅仅在Lclothes基础上加入距离约束的网格变形结果,即,λc=1,λg=40,λa=1,λb=0;第五列展示了完整加入网格正则化损失函数Lgird后的网格变形结果,此时,λc=1,λg=40,λa=1,λb=1/3。如图7所示,通过增加水平和垂直方向的距离约束,可以提高服装变形结果在局部区域水平方向和垂直方向变形的对称性;通过增加斜率约束,可以进一步提高服装变形结果的全局对称性。

图7 网格正则化损失的应用结果Fig.7 Application results of grid regularization loss
2.2.3 服装融合子网络
服装变形子网络输出的形变服装c"大致符合模特的体型与姿态,还需经过服装融合子网络实现服装同人物的融合,以得到更加逼真的试穿结果。如图4给出的网络结构,本文首先使用编码器-解码器网络,将人体表示p与形变服装c"同时输入U-Net[28]网络,输出一幅粗略的人物图像r与合成掩码M,其中M为输出图像的最后一层;然后利用合成掩码M将粗糙的合成图像和扭曲服装融合在一起,生成最终试穿结果ro,其计算公式为:

其中,⊗为矩阵内对应像素之间的乘法运算。
为了充分捕捉人体与目标服装的关键特征,与传统编码器-解码器网络不同的是,本文在U-Net网络的编码器的前四层加入了特征注意力模块FA,以更好地聚焦关键特征,提高合成图像质量,详细对比将在实验部分给出。
与服装变形子网络类似,服装融合子网络也是一个相对独立的端到端可学习的子网络。在训练阶段,为了最小化生成结果ro和真实图像rt之间的差异,采用了CP-VTON所提出的损失函数[4],包括三部分:图像像素级的L1损失,特征层面的VGG感知损失[29]和针对掩码M的L1正则化损失。
图像像素级的L1损失定义如下:

VGG感知损失通过计算VGG网络特征间的距离来刻画两个图像间的语义差异,计算公式如下:
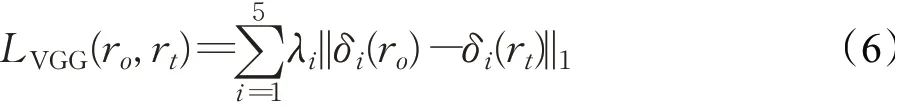
其中,δi(r)代表视觉感知网络VGG19[30]中图像r的第i层特征图(使用ImageNet预训练得到的网络模型)。i取 值从1到5分 别代 表conv1_2、conv2_2、conv3_2、conv4_2、conv5_2。这里,VGG损失中同时使用了低层和高层图像特征,结合图像像素级损失,能够更好地关注到图像间的细节信息和全局内容。
此外,为了尽可能地保留目标服装的特征信息,在掩码M上增加L1正则化损失。最终得到第二阶段服装融合子网络的整体损失:
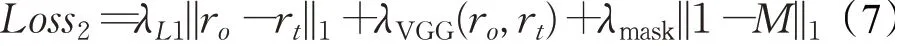
3 实验结果及分析
3.1 数据集与实验设置
本文所有的实验都基于Han等人[3]所提出的数据集。该数据集包含了16 253对女性正面图像和上衣图像,其中14 221对作为训练集,2 032对作为测试集。数据集中所有图像的分辨率均为256×192。
本文采用PyTorch作为深度学习框架,在Intel Core i5-9400 CPU和NVDIA RTX 2070 GPU上进行训练。在训练阶段,参照CP-VTON,对两个子网络采用相同的参数设置:batch size设置为4;Adam优化器中β1=0.5,β2=0.999;最大迭代步数为2×105,初始学习率设置为0.000 1,在迭代到1×105后线性匀速衰减至0。实验中,两个子网络的具体结构如表1、表2所示。在服装融合子网络的上采样模块中,为了减轻棋盘效应,用最近邻插值和步长为1的卷积的组合替换了传统的反卷积[31]。
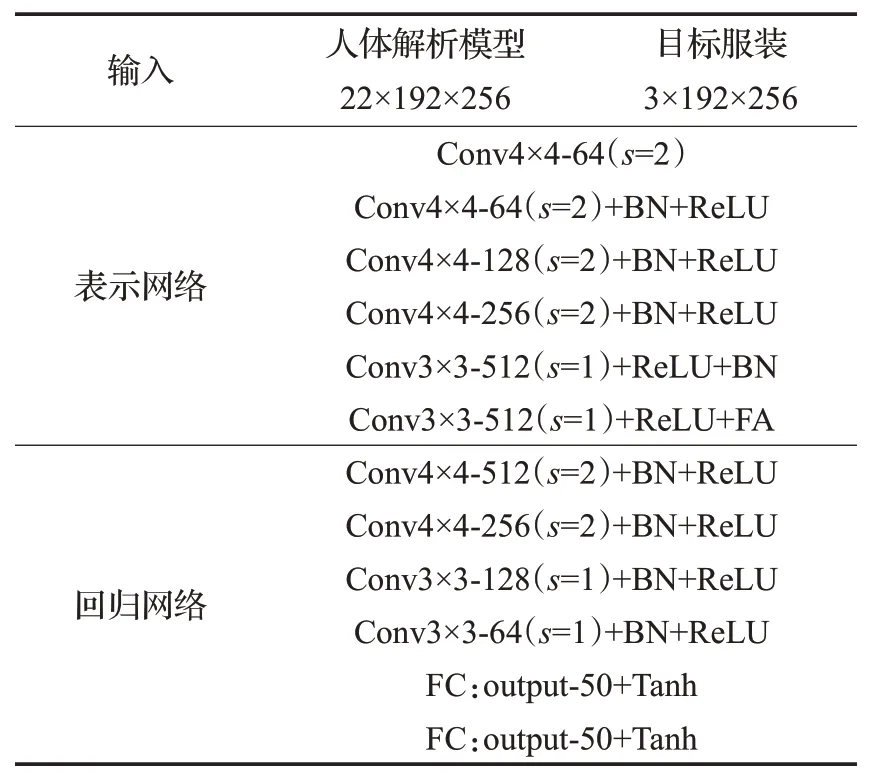
表1 服装变形子网络的网络结构Table 1 Structure of clothing deformation network

表2 服装融合子网络的网络结构Table 2 Structure of clothing fusion network
3.2 评价指标
基于图像的虚拟试衣本质上属于一种图像翻译。就图像生成任务而言,研究者们提出了一些客观评价指标,可以较好地衡量生成图像的质量。因此本文中,采用两种图像生成指标定量评估虚拟试衣模型的性能,采用可视化方法定性对比虚实试衣效果。
SSIM:结构相似度指标(structural similarity index)[32],计算生成图像和真实图像之间的亮度、对比度和结构相似性,以综合评估生成图像与真实图像之间的相似性。SSIM指数越高表示图像生成效果越好。
FID:弗雷歇感知距离(Fréchet inception distance)[33],计算生成图像和真实图像在特征空间中的距离。首先利用预训练好的Inception-V3网络提取图像特征,然后使用高斯模型对特征进行建模,最后计算两图像对应特征之间的距离。FID越低,表明生成图像和真实图像的距离越小,意味着生成图像的质量越高、多样性越好。
需要特别说明的是,虚拟试穿数据集中并未提供一个模特穿着不同服装的成组数据,因此在所有定量实验中,其计算结果均为模特穿着其原始服装产生的生成图像和真实图像的对比结果。
实验中,将对Baseline(CP-VTON,基础网络)、FP-VTON w/o FA(仅加入服装保真损失)、FP-VTON w/o FA in P(加入服装保真损失,并在人体表示中加入FA)、FP-VTON w/o FA in C(加入服装保真损失,并在服装表示中加入FA)、FP-VTON(加入服装保真损失,并在人体表示和服装表示中均加入FA)在服装变形阶段的生成结果进行了定量比较。
3.3 虚拟试衣对比实验
本文选用了2种不同类型、性能突出的虚拟试衣工作:CP-VTON[4]和GarmentGAN[5],作为对比对象,综合评价FP-VTON的虚拟试衣效果。
表3中,CP-VTON[4]和GarmentGAN[5]的测试结果均来自论文,由于文献[5]未提供SSIM指标,也未提供源码,因而其对应的SSIM为空。由表可见,本文所提出的FP-VTON较CP-VTON有明显提高:在SSIM上提高了0.046 2,在FFID上降低了8.511;相比于GarmentGAN,FP-VTON在FFID上也降低了2.004。以上数据从定量的角度验证了本文方法的有效性。
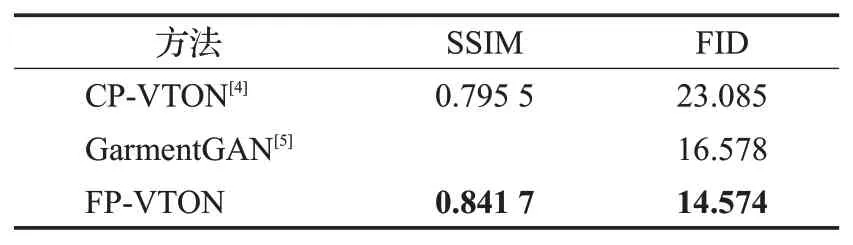
表3 虚拟试衣的定量评价Table 3 Quantitative evaluation of virtual try-on
图8从可视化的角度给出了3种不同方法的6组虚拟试穿结果(GarmentGAN未提供源码,因此本实验结果限于文献[5]所提供的实验数据)。由对比结果可见,本文方法具有以下特点:

图8 三种方法的虚拟试衣结果可视化比较Fig.8 Visual comparison of three different methods
(1)具有更好的局部细节特征保持能力。如结果1、3、4、5所示,当目标服装包含较多细节信息时,CP-VTON的虚实试穿结果会存在一定程度的细节丢失和扭曲变形,GarmentGAN则存在模糊和局部尺寸放大的问题。相比较而言,如结果1,本文方法FP-VTON生成结果的“501”及其底部的波纹清晰,且相对尺寸、比例都合理;如结果3,FP-VTON生成结果不仅清晰地体现了“Lee”的局部细节,且有效捕捉了目标服装袖子末端的玫红色条纹;如结果4 T恤衫中心的复杂图案和结果5内部的“adidas”图标,FP-VTON生成结果的颜色及细节都更加清晰、合理。
(2)具有更好的全局纹理保持能力。如结果2和结果6所示,当目标服装包含全局纹理特征时,CP-VTON的虚实试穿结果会存在较为明显的扭曲变形,GarmentGAN则存在丢失细节和局部模糊的问题。相比较而言,FP-VTON生成结果的整体纹理尺寸、比例更加合理,细节也更加清晰。
(3)当目标服装和原始服装差异较大时,所有算法在领口、袖口、衣服裤子邻接的地方都会产生不太理想的结果。如结果2、3、6所示的无袖变短袖,结果5的长袖变短袖,CP-VTON的试穿结果会在胳膊和衣服交接的地方出现局部丢失的问题,GarmentGAN和本文方法相对较好,但也存在不同类型的问题。如针对结果2,GarmentGAN虚拟试穿结果中衣服和裤子交接部分更为自然,FP-VTON对领口部分的颜色保持更好;针对结果3,GarmentGAN虚拟试穿结果中衣服领口的变形更加自然,然而袖口却丢失细节,而本文方法在领口变形中存在将衣服背部信息填充在领口的错误;针对结果5,GarmentGAN虚拟试穿结果中衣服袖口多出了一些黑色边界,FP-VTON则存在袖口未闭合的问题;针对结果6,GarmentGAN和本文在袖口领口变形的结果都较为自然,但是GarmentGAN存在将衣服拉长遮盖部分裤子的问题。
3.4 消融实验
本实验分别对文中所提出的特征注意力模块FA和服装保真损失进行了消融实验,以此来验证各个模块对于虚拟试穿的作用。消融实验分为两部分:第一部分旨在对比FA和服装保真损失对服装变形的作用,第二部分则完整对比FA和服装保真损失对虚拟试穿的作用。
本节对比实验中将用到七个不同配置的网络,分别是基础网络CP-VTON,仅加入服装保真损失的网络,加入服装保真损失和人体表示阶段FA的网络,加入服装保真损失和服装表示阶段FA的网络,加入服装保真损失和服装变形阶段FA的网络(人体表示&服装表示均加入FA),在网络三个阶段加入FA的网络(人体表示&服装表示&服装融合均加入FA),完整网络FP-VTON。为了方便查阅,表4列出了相应缩写。
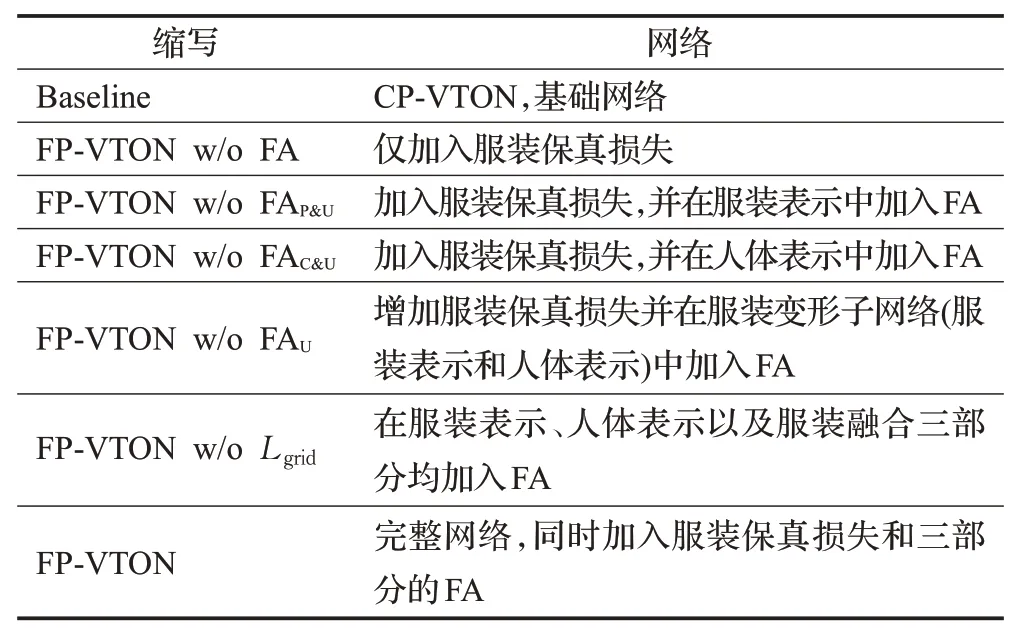
表4 实验网络及其缩写Table 4 Experimental networks and their abbreviation
3.4.1 服装变形消融实验
实验1定量比较
为了验证FA模块和服装保真损失保留特征的能力,本文首先对Baseline、FP-VTON w/o FA、FP-VTON w/o FAP&U、FP-VTON w/o FAC&U、FP-VTON在服装变形阶段的生成结果进行了定量比较。考虑到该阶段旨在扭曲目标服装以匹配模特身形,SSIM刻画图像间的相似性,而FID刻画图像的生成质量和多样性,因而,本实验仅仅计算FID指标。
服装变形阶段的定量比较结果如表5所示。由于该阶段的生成图像未适应模特身形的扭曲服装,而真实图像为输入服装,因此FID值整体偏高,但是其相对数值反映了服装变形的效果。通过对比可知:

表5 服装变形阶段定量评价Table 5 Quantitative evaluation on clothing deformation stage
(1)在基网上加入服装保真损失后,图像生成质量较原始基网效果更好。
(2)加入服装保真损失,再加入FA后(无论加在人体表示还是服装表示中),生成质量都得到了进一步提高。
(3)在人体表示和服装表示中同时加入FA较仅在服装表示中加入FA提高22.359 3,较仅在人体表示中加入FA提高0.609 2。两者都有改善,但是前者改善更为明显。通过分析可知,这是因为FA旨在捕捉全局特征相关性,而人体表示包含更多的全局信息,因此在人体表示中加入FA效果更加明显。
实验2整体可视化比较。
为了更加直观地对比生成结果,图9~图11分别给出了基础网络CP-VTON和本文方法FP-VTON在模特有大姿态动作、服装包含纹理或局部细节图案、模特为孕妇三种情况下的服装变形结果。
图9旨在测试服装变形阶段对人体大姿态的适应能力。由图可见,在面对模特有大姿态动作的情况下,CP-VTON生成的服装扭曲严重,而加入服装保真损失和FA的FP-VTON生成结果比CP-VTON更加真实、自然,也更符合人体特征。

图9 大尺度人体姿态下服装变形结果的可视化对比Fig.9 Visual comparison of clothing deformation results under large scale human postures
图10旨在测试服装变形阶段对目标服装全局纹理特征和局部细节特征的保持能力。由第一行可见,CP-VTON在面对条纹服装时生成结果严重变形,形成螺旋纹理且丢失细节;而因为服装保真损失的作用,FP-VTON可以较好地保持条纹的整体属性。由第二行可见,当目标服装包含复杂的全局特征时,CP-VTON可以较好地保持衣服形状,但是不能很好地保留细节图案(如树叶,花等);而因为FA的作用,FP-VTON对复杂图案的细节保持能力更强。第三行中包含局部细节的服装变形结果再次验证了FP-VTON对服装细节的捕捉和保持能力。

图10 复杂服装变形结果可视化对比Fig.10 Visual comparison of complex clothing deformation results
图11旨在测试服装变形阶段对人物特征的保持能力。当模特为孕妇时,FP-VTON生成结果更加真实、自然,且较好地保留了人物特征(隆起的肚子)。这也使得本文方法能够更好地服务于特殊人群(如不方便在线下试穿服装的孕妇,或不愿意在线下试穿的特殊体型用户)的虚拟试衣需求。

图11 特殊体型(孕妇)下服装变形结果可视化对比Fig.11 Visual comparison of clothing deformation results under special body shapes(pregnant women)
综合以上定量和定性实验可以得出如下结论:本文所提出的算法FP-VTON通过加入注意力机制和服装保真损失,在服装变形阶段能够更好地捕捉目标服装的整体纹理特征和局部细节特征,能够更好地贴合模特的不同体型,能够更好地适应模特的大姿态动作,整体效果明显优于基础网络。
实验3分模块可视化比较
为了进一步测试服装保真损失及不同位置FA的作用,图12给出了6种不同网络配置下的可视化对比结果。由图可见:

图12 各个模块对服装变形结果影响的可视化对比Fig.12 Visual comparison of influence of each module on clothing deformation results
(1)在网络中加入服装保真损失可以一定程度地保证服装整体结构(如图中第三列)、纹理(如结果5、6中第三列)及大面积图案(如结果1、2中第三列)的合理性。
(2)在人体表示中加入FA可以更好地捕捉模特的身体特征。以结果3、4为例,模特为孕妇,通过在人体表示中加入FA(第五、六列)后的服装变形结果能够更加真实、自然地体现模特的身体特征。
(3)在服装表示中加入FA可以更好地捕捉服装的形状及纹理特征。图中第六列为在第五列的基础上加入了服装表示阶段FA的结果。可以发现,无论是对结果5服装的衣袖部分(形状特征),还是结果6服装中的条纹特征(纹理特征),第六列的结果都要明显优于第五列。
3.4.2 虚拟试穿消融实验
为了进一步测试FA模块和服装保真损失对虚拟试穿最终结果的影响,特设计本实验。如表6所示,给出了5种不同网络配置下的虚拟试穿定量测试结果。对比表中各行数据,可知:
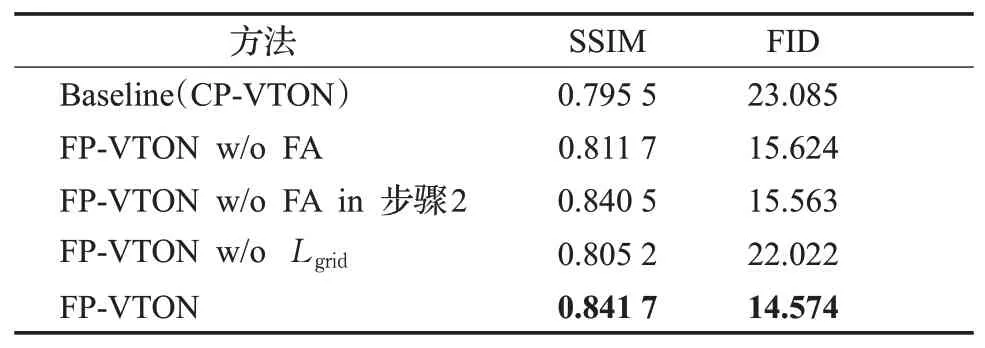
表6 虚拟试穿结果定量评价Table 6 Quantitative evaluation of virtual try-on results
(1)在仅仅加入服装保真损失,不加入特征注意力模块时,如第二行所示,网络在SSIM及FID都较Baseline网络有了0.016 2和7.461的改进。
(2)在仅仅加入特征注意力模块不加入服装保真损失时,如第四行所示,网络在SSIM和FID上分别有0.009 7和1.063的改进。
(3)在加入服装保真损失的基础上,将特征注意力FA加入第一阶段,即服装变形子网络中时(第三行所示),网络在SSIM和FID上分别有0.029和0.061的改善;在所有阶段都加入特征注意力FA时(第五行所示),网络在SSIM和FID上分别又有了0.001和0.989的改善,取得最好的虚拟试穿结果。
综合(1)、(2)可知,服装保真损失和FA对虚拟试穿都有一定的改进作用,但服装保真损失对网络性能的提升较FA更加明显。这是因为相比于FA,服装保真损失可以从整体上保持服装的整体形状和全局纹理,对最终生成图像的整体质量影响更大。
图13从可视化的角度对比了各个模块对虚拟试穿的影响。可以看到加了服装保真损失后衣服形状更完整,局部图案保持效果也更好;在此基础上再加入FA,图案的细节更加清晰,颜色更加真实,领子袖口等局部区域也更贴合模特身体。

图13 各个模块对虚拟试穿影响的可视化对比Fig.13 Visual comparison of influence of each module on virtual try-on results
3.5 性能对比及分析
为了更加全面地分析本文方法的性能,表7给出了FP-VTON相比于基础网络CP-VTON的参数量及训练时间。可以看到,在第一阶段的服装变形子网络中,训练参数量和时间分别增加了0.6%和3.6%;在第二阶段服装融合子网络中训练参数量和时间分别增加了5%和10%(第二阶段因为损失函数复杂,计算量大,所以参数少但是训练时间长)。对于整体网络的参数量和训练时间增加了0.1%和7%,而测试时间增加可忽略不计。因此,可以得出以下结论:本文算法FP-VTON在仅增加少量运算代价的前提下可生成比CP-VTON效果更好更真实的试穿结果。
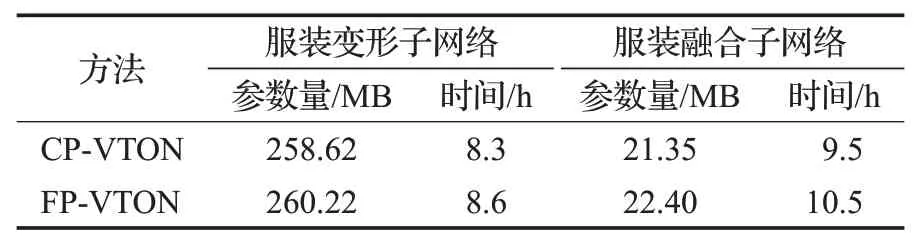
表7 训练时间和参数量定量对比Table 7 Comparison of parameters and training time
3.6 不足及讨论
当模特存在手臂遮挡时,如图14,FP-VTON可以较好地清晰、准确地捕捉目标服装的局部细节,但是会丢失部分手臂信息。而本文在实验中尝试加入GAN网络解决手臂遮挡问题,但在保留手臂的同时会丢失掉部分服装细节,经分析认为GAN网络为了保持手臂时会平滑模糊手臂附近的服装导致细节丢失。未来工作中将考虑建立符合目标服装特性的人体分割图与GAN网络进行平衡来解决这一问题。

图14 失败案例Fig.14 Failure case
4 总结
本文提出了一种虚拟试衣网络FP-VTON,设计并引入了服装保真损失,并在网络的人体表示、服装表示、服装融合三个阶段加入特征注意力模块,相互协同共同作用,充分捕捉了模特的特征及目标服装的整体形状、全局纹理及局部细节特征,生成了更加真实、自然的虚拟试穿结果。未来,将以此网络为基础,考虑建立人体分割,合理引入对抗机制,解决遮挡问题,提高网络对原始服装和目标服装差异过大的适应性。
猜你喜欢
客联(2021年4期)2021-09-10
智慧少年·故事叮当(2020年10期)2020-11-06
中华诗词(2020年1期)2020-09-21
小天使·二年级语数英综合(2019年10期)2019-11-08
智族GQ(2019年1期)2019-05-14
小学生作文(中高年级适用)(2018年5期)2018-06-11
今古传奇·故事版(2018年1期)2018-03-02
数学大王·中高年级(2016年12期)2016-12-26
科学启蒙(2016年10期)2016-10-14
共产党员(辽宁)(2015年2期)2015-12-06
