
基于太赫兹时域光谱的大米品种识别研究
2022-12-06 10:57葛宏义蒋玉英秦一菲
食品工业科技 2022年23期
王 倩,葛宏义,2,*,蒋玉英,2,张 元,2,秦一菲,2
(1.河南工业大学信息科学与工程学院,河南 郑州 450001;2.河南工业大学粮食信息处理与控制教育部重点实验室,河南 郑州 450001)
随着人们生活品质的不断提高,消费者越来越热衷于购买地域性特色大米,如:黑龙江五常大米、河南原阳大米、宁夏珍珠糯米和云南遮放贡米等。不同产地的大米不仅具有特殊的品质和信誉,且经济价值也比普通大米高。不良商家为获取不当高额利润,通过对低价大米染色或工业加工等方式伪造特色大米,牟取暴利,造成大米市场紊乱[1],严重损害消费者和生产者权益。因此,亟需相应的检测方法识别大米品种,以规范大米市场。
针对大米品种识别方法较多,传统检测方法主要有感官评价法[2]和理化指标技术法[3]等,具有分析简单、方法直观等优势,但也存在一些不足,如感官评价法主观性强,对于采用化学剂染色大米或工业加工研磨大米,仅从外观上难以判别真伪;理化指标技术法操作繁琐、检测速度慢等。目前常见识别技术主要有电子舌技术[4]、红外光谱技术[5]和高光谱图像技术[6],诸多学者以此为基础结合化学计量方法对大米识别做出研究,如惠延波等[7]利用电子舌技术结合PCA、DFA 两种模式对不同品种粉碎大米进行识别研究,区分指数D1 为95;王靖会等[8]以高光谱成像技术为基础结合光谱和纹理特性实现不同大米品种的识别,识别率为96.57%;王朝辉等[9]利用近红外光谱技术结合SG 平滑预处理方法和偏最小二乘判别分析方法对松原不同品种大米识别,识别率为100%;刘亚超等[10]利用近红外二维相关光谱对掺和大米识别,识别率最高为100%;虽然以上技术能有效解决传统技术检测精度不高、主观性强等缺点,但也存在一些不足,如电子舌技术检测结果易受传感器灵敏度和环境因素影响[11]、设备集成度不高、价格昂贵、使用周期短等[12];红外光谱技术灵敏度相对较低[13]、检测结果易受各种环境影响[14],红外光谱解释性差、化学计算依赖性高[15];高光谱图像技术图像处理复杂性高、检测速度慢等[16]。太赫兹(Terahertz,THz)[17]是介于微波和红外之间的电磁波,频率在0.1~10 THz 之间,具有穿透性强、电离辐射小、分子指纹等特点,还具有检测分析速度快、多成分同步分析、无损检测等优势,能有效弥补传统检测方法和目前常见技术的不足。其原理是利用飞秒脉冲产生THz 电磁波,通过探测设备获得待测样品的光谱信息,再通过傅里叶变换获得测物品吸收和折射光谱信息。由于大分子振动和转动能级大多处于THz 波段,并表现出明显吸收特性,因而可以通过光谱的指纹特性对大米品种进行识别。太赫兹时域光谱技术已被广泛应用到安全检查[18]、生物医学[19]、无线通信[20]等领域,目前在农产品品质检测方面的应用也在不断增多,如农产品掺假[21]、转基因作物检测[22]和农产品主要成分含量检测[23-24]等。太赫兹光谱技术的广泛应用,为大米品种识别提供了新思路。
本文采用太赫兹时域光谱技术结合标准差分析、区间偏最小二乘和决策树分类模型对不同大米品种进行识别。分析了大米在光谱技术作用下的特点,建立了一种准确识别大米品种的分析模型,为大米品种识别提供了一种精准检测方法。
1 材料与方法
1.1 材料与仪器
实验样品分别是河南红米、珍珠糯米、黑米和富硒大米 均采购于永辉超市,如图1 所示。大米颗粒利用研磨机研磨成粉末状,再利用电子称每次取0.2 g 的粉末放入模具,并对模具使用10 MPa 的压力施压3 min,使粉末压制成直径约为13 mm、厚度约为1.1 mm、表面均匀的圆形薄片。每种大米制备一组样品,每组样品制备14 份,四组样品共56 份。

图1 实验样品Fig.1 Experimental samples
太赫兹时域光谱仪 由河南工业大学教育部重点实验室提供,激光器波长800 nm,光谱范围0~3.5 THz,分辨率0.03 THz,重复频率80 MHz,脉冲波长100 fs,信噪比5000:1,具体系统结构如图2所示。
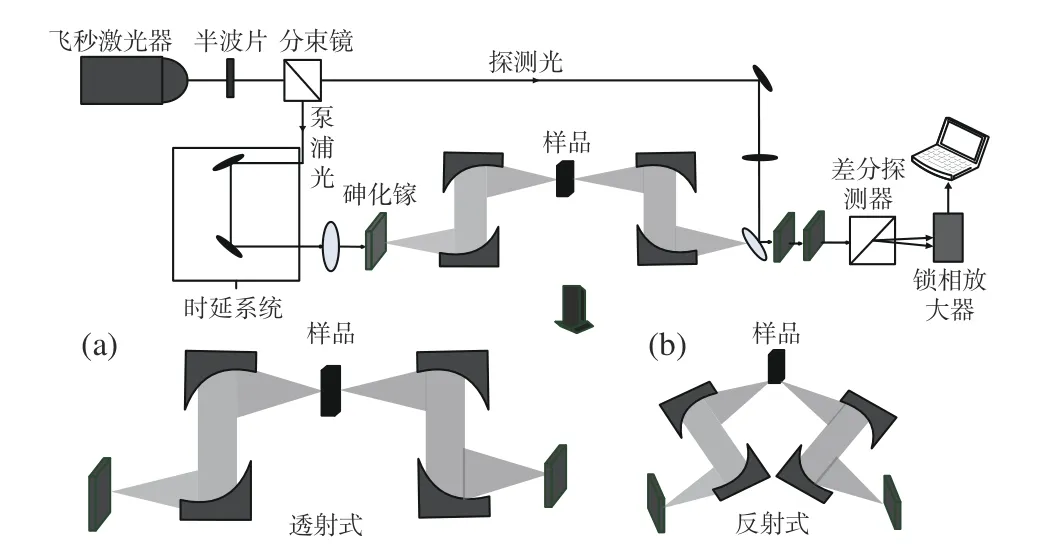
图2 太赫兹时域光谱系统透射式(a)和反射式(b)Fig.2 Terahertz time domain spectroscopy system transmission type (a) and reflection type (b)
时域光谱系统工作原理如下:飞秒激光器产生的光束作为输入光源,经分束镜分成能量较强的泵浦光和能量相对弱的探测光。泵浦光先传输至时间延迟控制系统,再入射到光导天线或半导体晶体上激发出太赫兹脉冲,最后经两组抛物面镜聚焦到待测物体上。探测光经多次反射后和太赫兹脉冲共线触发太赫兹探测器,探测器通过对脉冲偏振状态的检测获得待测样品的时域波形。在整个测试过程中,由于水分对太赫兹脉冲有强吸收性,因此为减少空气中水分含量对实验结果的影响,需要不断对时域光谱系统补充氮气,以保持实验环境干燥。
1.2 实验步骤
实验分为三个阶段:第一阶段主要是对仪器参数和实验环境进行调整,光谱系统设置为透射模式,测试温度保持在19 ℃左右,湿度保持在2.8%左右,并在测试正式开始前,仪器持续运行2 min,以确保各项参数指标达到稳定状态;第二阶段是对样品进行检测,把制备好的样品放置在检测台旁,按标签顺序依次放入太赫兹时域光谱系统中进行检测,重复测量三次,并取平均值作为该样品时域光谱信息。为减少环境因素对实验结果的影响,取样间隔时间不超过5 s;第三阶段是利用Origin 和Python 软件结合分类模型算法对获得的太赫兹光谱数据信息进行数据预处理和数据分类。
1.3 模型与建模方法
1.3.1 标准差 标准差(SD)值反映的是数据集的波动程度,即离散程度[25]。标准差值大表示数据和平均值之间差异较大,标准差值小表示数据和平均值之间差异小,在光谱信息中标准差值大小表示光谱波动范围,且两者为正比关系。标准差的计算公式如下:
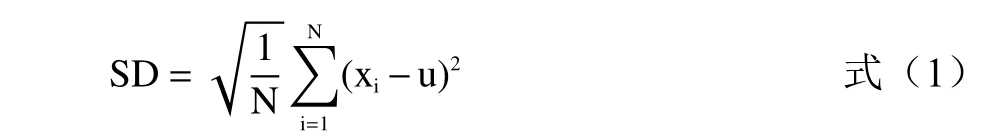
式中:xi为样品数据;u 为算术平均值;N 为数值个数。
1.3.2 区间偏最小二乘 区间偏最小二乘(iPLS)主要用于光谱波段的选择,其特点是采用偏最小二乘实现光谱波段的局部回归分析,并根据局部回归分析的最小均方根误差确定光谱特征波段的选择。偏最小二乘的原理是将全光谱划分为多个具有同样宽度的区间,然后在各个子区间内使用偏最小二乘回归,根据各个子区间均方根误差的比较,选择均方根误差最小的子区间对应的光谱波段为光谱特征波段[26]。
1.3.3 决策树 决策树(DT)模型是一种类似于二叉树的网络结构,具有可读性、分类速度快等优点,在分类、回归等方面有广泛的应用。决策树中每一个非叶子节点都是一个决策点,即判断条件,满足条件的放在节点的右侧,不满足的放在节点的左侧。如何确定决策点是构造决策树的重点,根据决策点特征选择的不同,常见的方法有ID3 算法、C4.5 算法和CART 算法。ID3 算法的核心是在决策树各个节点上应用信息增益准则选择特征,选择信息增益最大的特征作为决策点。但ID3 算法没有考虑到数据的连续性和过拟合问题,C4.5 算法在弥补ID3 算法的不足的同时也提出了根据信息增益率作为特征选择的准则。C4.5 和ID3 算法都能有效的解决分类问题,但不能处理回归问题,而根据CART 算法构建的决策树不仅能处理分类问题也能做回归分析,在分类问题时选择基尼系数最小的特征作为决策点,在回归分析中CART 算法使用平方误差最小值对应的特征作为决策点[27]。
1.3.4 SD-iPLS-DT 由于原始数据集维度高、信噪比低,直接使用决策树模型进行分类处理,易造成数据处理速度慢,模型分类准确率低等问题。因此采用SD-iPLS 与DT 联用的方法对测试样品进行分类,即先采用SD 和iPlS 选择合适的太赫兹波段作为模型的输入数据,再利用DT 模型进行分类识别。本次实验中原始数据维度为220,通过SD 选择稳定性较好的光谱波段,同时结合iPLS 选择均方根误差最小的光谱区间,根据两者最优结果,选择其中的38 维吸收光谱数据作为分类模型的输入数据,最后使用DT 算法进行大米品种识别研究。
1.4 数据处理
由于光谱信息中包含实验样品的振幅和相位信息,因此可以将时域光谱信号利用快速傅里叶变换得到实验样品的频域信息,并结合Dorney[28]和Dubillaret[29]等提出的数据处理模型处理光谱数据,得到大米样品的折射率和吸收系数。计算公式如下:
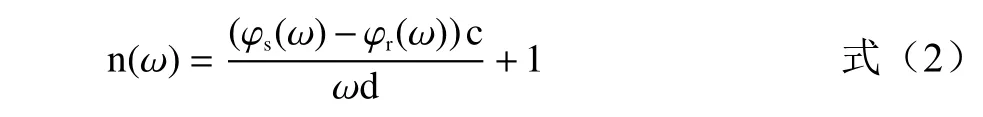
式中:n(ω) 表 示光谱折射率,n; ω代表角速度,rad/s;φs、 φr分别表示样品和参考信号的相位信息,p;c 表示光谱传播速度,m/s;d 表示样品的厚度,mm。
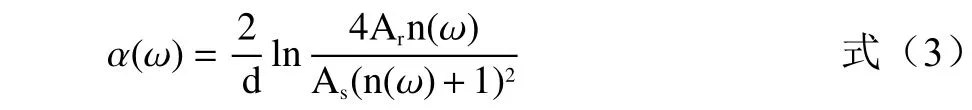
式中: α (ω)表 示光谱吸收系数,cm-1; Ar、 AS分别表示参考信号和样品的振幅值,a.u。
2 结果与分析
2.1 光谱分析
2.1.1 时域和频域 为减少实验误差,对每份实验样品的时域信号分别测量3 次,并取平均值作为样品的时域信号。图3(a)是样品的时域光谱,时域光谱信息经傅里叶变换得到样品的频谱信息,如图3(b)所示。可以看出样品信号相对于参考信号有一定的时延、衰减和重叠现象,产生时延可能是由于光谱穿透样用时较长,衰减可能是由样品表面的大颗粒物质对太赫兹光谱反射和内部样品的吸收造成的,而光谱之间区分度不明显可能是由于各种大米中的主要成分都是碳水化合物、蛋白质和脂肪。
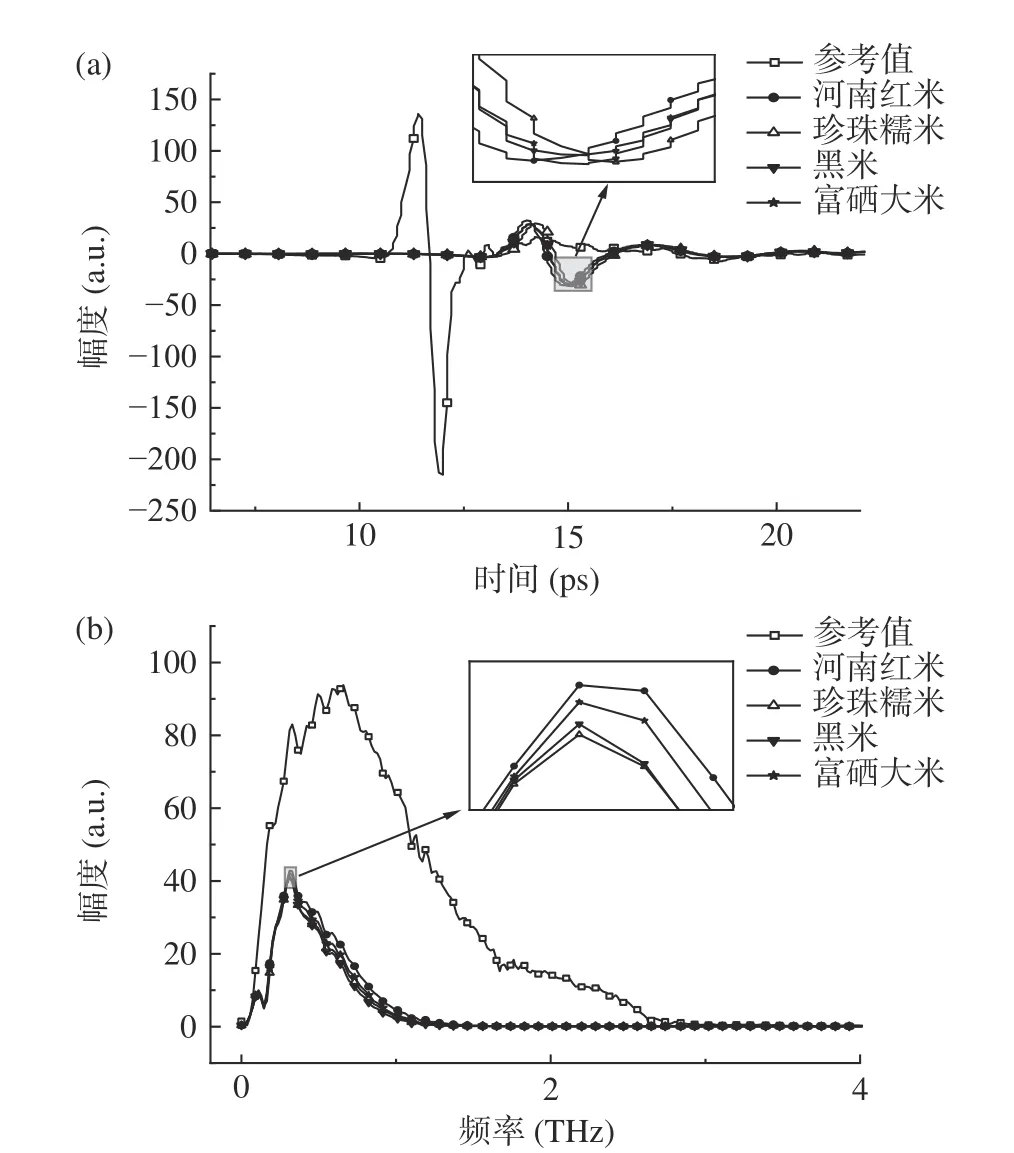
图3 时域光谱图(a)和频域光谱图(b)Fig.3 Time domain spectroscopy (a) and frequency domain spectroscopy (b)
2.1.2 折射率和吸收系数 太赫兹时域光谱数据中包含丰富的振幅和相位信息,经公式(2)和(3)计算得到样品的折射率和吸收系数,如图4 所示。可以看出四种样品的折射率曲线和吸收光谱曲线在低频波段均出现重叠现象,在高频波段折射率光谱曲线趋于一致,吸收光谱曲线区别明显,因此本文选择吸收光谱作为模型的输入数据。
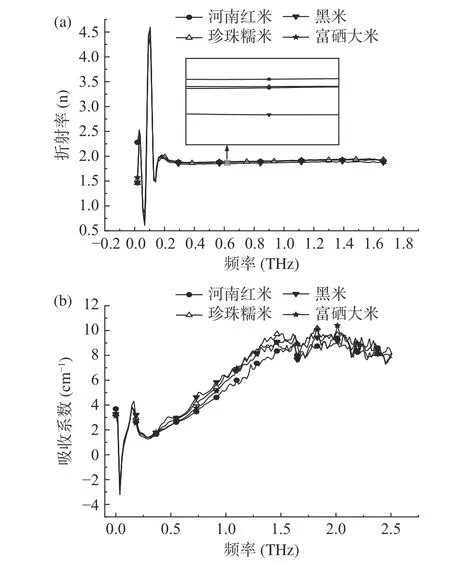
图4 折射光谱(a)和吸收光谱(b)Fig.4 Refraction spectrum (a) and absorption spectrum (b)
2.2 光谱处理
由于吸收光谱存在信噪比低和光谱重叠现象,为更好识别大米品种,本文首先对吸收光谱数据进行标准化处理解决光谱重叠问题,再利用标准差分析和区间偏最小二乘(iPlS)选取光谱稳定性好、信噪比高的太赫兹波段作为分类模型的输入数据。
2.2.1 吸收光谱预处理和稳定性分析 为增大吸收光谱曲线之间的差异性,本次实验采用标准化预处理方法对吸收光谱数据进行预处理操作。图5 为预处理后四种样品的吸收光谱数据平均值,通过观察光谱曲线可以看出,四种样品的吸收光谱曲线差异明显。同时,利用光谱角度[30]对光谱曲线之间的差异性进行评价,以河南红米吸收光谱为参照,结果如表1 所示,可以看出在经过预处理之后,光谱角度的数值明显增大,即光谱曲线之间的差异性增大。但标准化预处理后的光谱仍存在信噪比低、光谱波动大等问题,因此为减少噪声和光谱波动性对模型准确率的影响,需选择合适的光谱波段作为模型分类识别的输入数据。
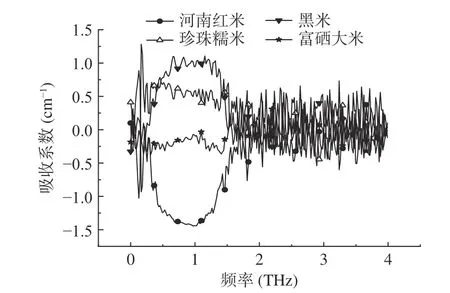
图5 吸收数据标准化预处理Fig.5 Standardized preprocessing of absorption data

表1 不同样品光谱角度Table 1 Different sample spectral angles
根据不同光谱波段的标准差对光谱的稳定性进行分析[31],实验过程中把吸收全光谱划分为7 个不同的区间,并对每个区间进行标准差分析,结果如表2、图6 所示,可以看出0.53~1.21 THz 之间四种大米样品标准差分别为0.06、0.07、0.08、0.06,平均值为0.07,是8 组光谱数据中标准差值最小的一组,即光谱波动最小,稳定性最好的一组;0~0.53 THz 之间的四种大米样品标准差分别为0.65、0.53、0.36、0.12,平均值为0.42,是8 组光谱数据中标准差值最大的一组,即光谱波动最大,稳定性最差的一组。
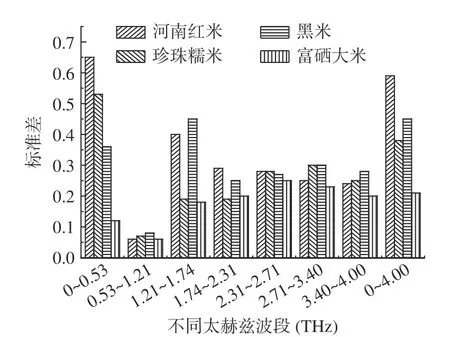
图6 四种样品预处理后不同波段标准差Fig.6 Standard deviation of different bands after pretreatment of four samples
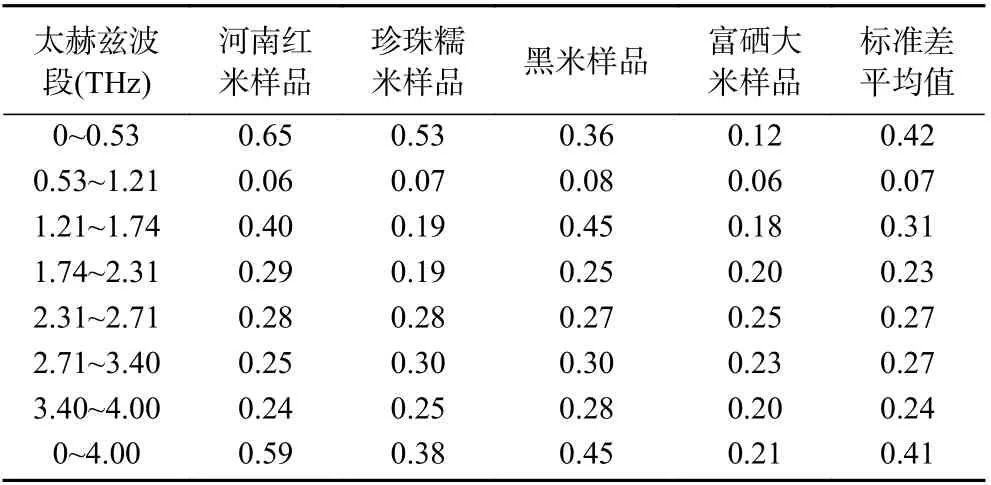
表2 四种样品预处理后不同波段标准差Table 2 Standard deviation of different bands after pretreatment of four samples
2.2.2 吸收光谱特征谱区间选择 实验过程中采用SPXY-iPLS 算法选择吸收光谱特征区间。首先利用SPXY 算法[32]进行数据集的划分,再利用iPLS算法计算每个子区间的均方根误差。在子区间划分中,把预处理后的全光谱分为2、3、4、5、6、7、8、10、15 和22 个子区间,分别对各子区间建立PLS 回归模型[33],进而比较模型的均方根误差,确定均方根误差最小的回归模型对应的子区间。由表3、图7可以看出当划分区间个数为2 时,最佳区间对应的均方根0.84,是10 组区间中均方根误差最大的区间;当划分区间个数为3 时,最佳区间1 区间对应的均方根误差为0.50,是10 组区间中均方根误差最小的区间,即模型效果最好,对应的THz 光谱波段为0~1.32 THz。
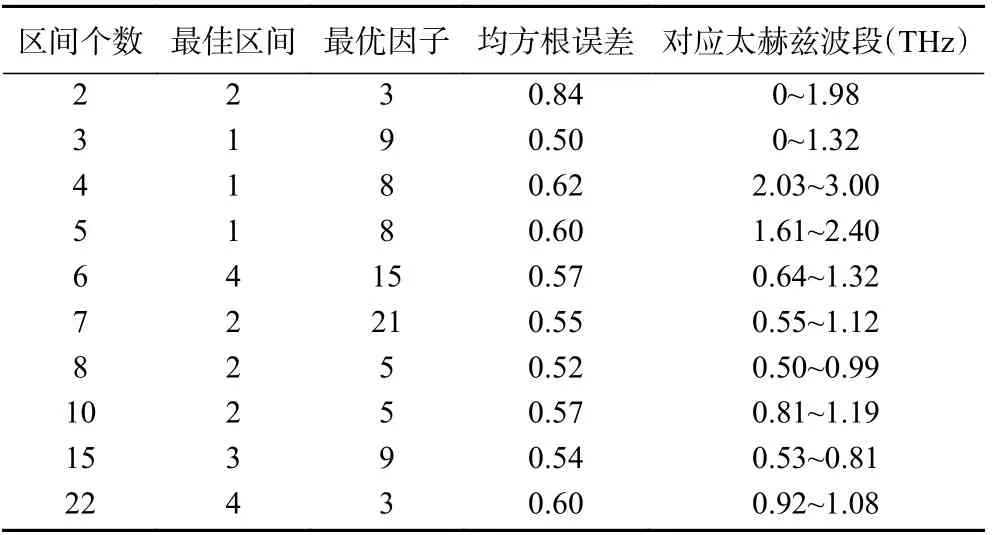
表3 iPLS 不同分割区间下最优区间列表Table 3 List of optimal intervals under different segmentation intervals of interval partial least square

图7 最优区间均方根误差Fig.7 Optimal interval root mean square error
结合光谱稳定性和区间偏最小二乘两者对应的最优波段,最终选择0.53~1.21 THz 之间的吸收光谱数据作为模型的输入数据。
2.3 模型分析
采用SD-iPLS-DT 联用模型对样品进行分类。首先对数据集进行划分,将0.53~1.21 THz 之间的光谱数据按照2:1 的比例划分为训练集和测试集。为实现模型最优分类结果,结合网格搜索算法寻找最优参数组合。在决策树模型中主要的参数有特征选择评价标准(criterion)、最大深度(max_depth)。其中在决策树模型中特征评价标准主要参数有基尼系数(gini),信息增益(entropy)。根据网格搜索算法最终确定模型的最优参数criterion 为gini、最大深度为3。模型对应的分类结果如表4 所示,分类准确率为95%。

表4 决策树分类准确率Table 4 Classification accuracy of decision tree
为证明本文模型的性能,将SD-iPLS-DT 模型与常见的分类模型逻辑回归(LC)和支持向量机[34](SVM)进行对比。其中在SVM 模型中,分别利用径向基核函数、线性核函数和Sigmoid 核函数等三种不同核函数对样本进行分类。如表5 所示,可以看出在SVM 模型中基于线性核函数的分类模型效果最好,分类准确率可达88.75%。由表6 可以看出,直接使用逻辑回归和支持向量机分类准确率分别为80.75%和88.75%,使用标准差和iPLS 结合选择合适的光谱波段后,再使用决策树模型进行分类准确率为95%,因此使用SD-iPLS-DT 联用模型效果要优于逻辑回归和支持向量机模型。
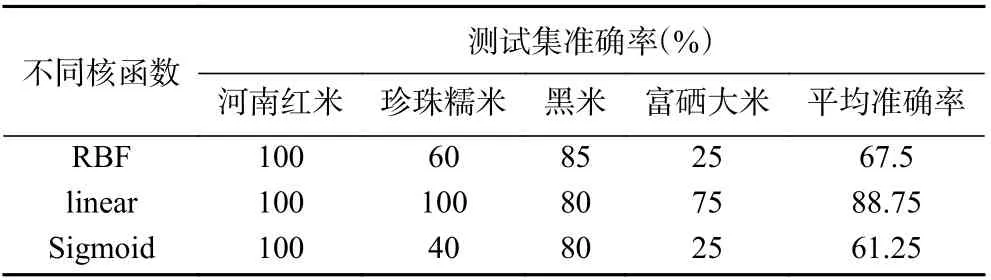
表5 不同核函数分类准确率Table 5 Classification accuracy of different kernel functions

表6 不同模型的分类准确率Table 6 Classification accuracy of different models
3 结论与讨论
本文利用太赫兹时域光谱技术获取四种大米的时域和频域光谱数据,并计算得到折射率和吸收系数。采用标准差对吸收光谱数据稳定性进行分析,得出0.53~1.21 THz 之间的光谱稳定性最好;区间偏最小二乘选择吸收光谱特征波段,确定0~1.32 THz 区间的均方根误差最小。结合稳定性最好和最小均方根误差对应的太赫兹波段,选择0.53~1.21 THz 波段吸收光谱信息作为决策树模型的输入数据。实验结果显示:所提出的SD-iPLS-DT 的方法分类准确率可达95%。为更好对比模型分类效果,利用逻辑回归、支持向量机与SD-iPLS-DT 方法进行实验对比,实验结果显示:逻辑回归分类准确率为80.75%,支持向量机准确率为88.75%,SD-iPLS-DT 模型分类准确率为95%。识别准确率高于现有利用近红外光谱技术进行稻花香大米定性分析研究94%准确率[35]、利用高光谱成像技术对大米无损检测92.96%准确率[36]、利用拉曼光谱大米产地识别91.11%准确率[37]等。因此可以得出结论:时域光谱技术结合SD-iPLSDT 方法可以实现不同大米品种的准确识别。同时也为太赫兹时域光谱技术在农产品识别和质量安全检测方面提供了新的检测方法。
猜你喜欢
昆钢科技(2022年2期)2022-07-08
昆钢科技(2021年4期)2021-11-06
飞天(2019年6期)2019-07-08
雷达学报(2018年1期)2018-04-04
雷达学报(2018年1期)2018-04-04
雷达学报(2018年1期)2018-04-04
分析化学(2018年12期)2018-01-22
山东工业技术(2016年15期)2016-12-01
新高考·高二数学(2015年2期)2015-05-27
新高考·高二数学(2014年7期)2014-09-18
