
碳排放数据报送联盟链的架构与信誉评价
2022-12-01 06:00汪鹏文亚凤
电子设计工程 2022年23期
汪鹏,文亚凤
(华北电力大学电气与电子工程学院,北京 102206)
我国已明确碳达峰与碳中和的目标[1],发电厂的碳减排很重要。碳排放配额指标是电力市场促进碳减排高效的政策工具,但是在碳排放配额指标分配中基准线值[2]的确定依赖于发电厂大量真实的碳排放数据。目前,碳排放数据报送过程中多方机构难以建立互信且发电厂参与积极性不高。
区块链凭借去中心化等优势为碳排放数据报送中多方机构建立互信提供了新的解决方案,发电厂参与积极性问题也可以通过激励机制解决[3]。目前已有若干学者将区块链与激励机制有机结合形成了一部分研究成果。文献[4]针对区块链激励架构展开研究,为激励机制的场景适配与效果评估提供了参考;文献[5]以通用代币作为激励开发了K-匿名激励机制系统;文献[6]引入了信誉值概念;文献[7]凭借信用评价体系为参与综合能源服务方注入活力;文献[8]依靠信任值促进车辆积极参与用户信息交易;文献[9]分析了清洁能源消纳激励机制的设计思想;文献[10]构建了基于智能合约的数据共享激励机制;文献[11]提出的激励模型将信任度高节点奖励作为主节点;文献[12]为多场景激励机制框架搭建提供了参考。
综上,现有研究主要将区块链技术与激励机制有机结合应用于数据共享或清洁能源消纳方面,在碳排放数据报送方面待进一步突破。因此该文在碳排放数据报送系统中构建了基于联盟链技术的应用架构,其次,在激励层设计了信誉评价机制,并通过实例仿真验证了其适用性。
1 碳排放数据报送中联盟链技术应用架构
1.1 碳排放数据报送系统的框架
现有区块链模式有三种:公有链、联盟链与私有链,它们在建链原则、共识机制方面存在显著差异[13]。公有链任何人都可以参与,去中心化程度最高但算力消耗巨大;联盟链只允许授权节点参与区块的生成、验证与访问,是当下区块链应用部署的热点;私有链记账权通常由中心机构掌握。将三种区块链模式进行对比,如表1 所示。

表1 三种区块链模式的优劣
实际应用需根据场景选择区块链模式,考虑碳排放数据的报送需碳排放数据分析中心与各类发电厂共同参与,且运行效率要求较高,因此应用联盟链技术。参照文献[14],将基于联盟链的碳排放数据报送系统框架分为物理层与虚拟层,如图1 所示。
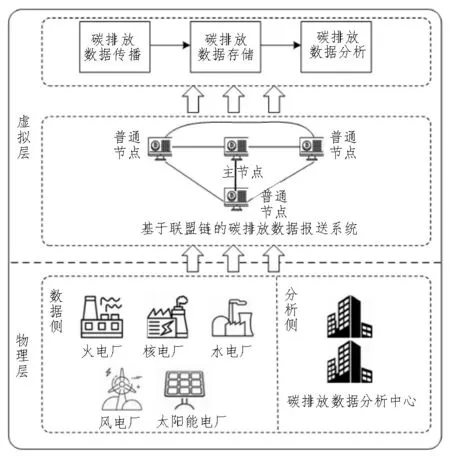
图1 碳排放数据报送系统框架
1)在物理层中,各类发电厂在数据源头把控碳排放数据质量,而碳排放数据分析中心依据报送数据进行研究得出分析报告,有利于电力行业基准线值划定,从而促进清洁能源的消纳。
2)虚拟层为碳排放数据报送系统中联盟链技术的应用,点对点传输技术去除了中心机构对数据报送的影响,分布式存储保障了数据的不可篡改与可溯源。另外,链中节点又被分为主节点与普通节点,碳排放数据分析中心为主节点,各类发电厂经过准入许可成为普通节点。准入过程使碳排放数据分析中心对各类发电厂起到了监管作用,保证了链上节点的可靠性。
发电厂通过授权加入联盟链的步骤如下:首先,发电厂发送加入意图至链上任一节点,收到信息的对应节点向其反馈联盟链中主节点地址。其次,发电厂向联盟链主节点发出公钥地址、身份认证等申请信息,在主节点确认其身份后,将其公钥地址写入联盟链头部注册表,然后新节点公钥进行全链广播。之后,新节点通过自己的私钥加密申请信息,并广播通知到主节点之外的所有节点。最后,主节点之外的所有节点成功获取新节点申请信息则进行回复,若新节点接收到所有节点的回复,则表明加入联盟链成功。联盟链中机构准入过程如图2 所示。

图2 联盟链中机构准入过程
1.2 联盟链的基础架构模型
区块链的基础架构分为六层[15],各层对应不同功能,总体实现去中心化,从而为多方提供可信的基础。根据碳排放数据报送系统需要设计联盟链基础架构模型,如图3 所示。
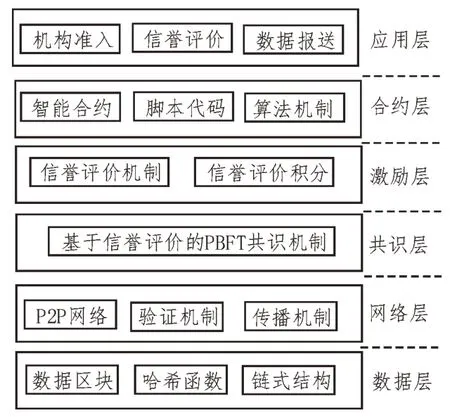
图3 联盟链的基础架构模型
1)数据层包括碳排放数据区块、哈希算法与链式结构。每个区块分为区块头和区块体两部分,其中,区块头记录了时间戳、默克尔树根与前一区块哈希值,而区块体包含一个区块的全部碳排放数据。链上首个区块到当前区块依据时间顺序按链式结构相连,实现碳排放数据可溯源。
2)网络层包括传播机制、验证机制与分布式对等网络(P2P 网络)。P2P 网络中节点地位对等,碳排放数据传递不依赖中心机构而在节点之间进行,通信的灵活性与可靠性得以提高。
3)针对传统实用拜占庭容错机制(PBFT)工作效率低的问题,专家通过对比实验证明,基于信誉投票的PBFT 优化方案起到改善的效果[16]。参照该方案在共识层设置基于信誉评价的PBFT 共识机制,动态选取信誉评价优的节点参与链内区块验证,从而缩短共识时间,提高联盟链的运行效率。
4)激励层设计了旨在促进发电厂参与积极性的信誉评价机制。发电厂只有提高碳排放数据报送满意度才能提高本身的信誉评价,而信誉评价优的发电厂更容易被碳排放数据中心选择。
5)合约层包括智能合约与预置的脚本代码及算法机制。在碳排放数据报送过程中,智能合约只要触发条件便立即执行预置条款。
6)联盟链在应用层封装了碳排放数据报送的各种典型应用,包括但不限于发电厂(机构)准入应用、信誉评价应用、碳排放数据报送应用等。
碳排放数据报送在联盟链的信息交互过程如图4 所示。碳排放数据分析中心上传数据要求后,合约层选择调用合适的合约,激励层读取信誉评价要求,共识层基于信誉评价的PBFT 共识机制选取节点参与共识,网络层完成数据报送全过程的节点互联互通,数据层将碳排放数据区块按照分布式存储方式存储在各个节点。
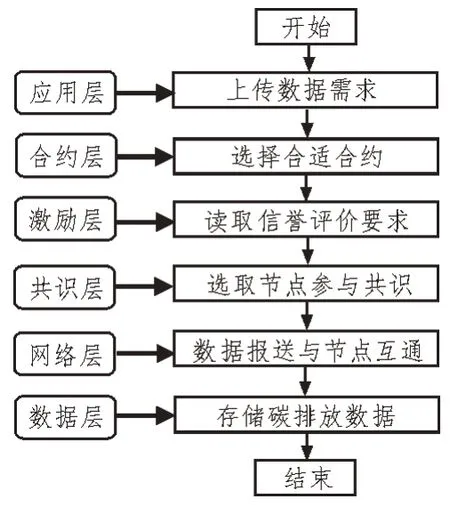
图4 联盟链信息交互过程
2 激励层的信誉评价机制设计
在分析了碳排放数据报送系统中的联盟链架构后,针对发电厂碳排放数据报送缺乏积极性的难题,在联盟链激励层设计信誉评价机制。发电厂每次数据报送完毕,碳排放数据分析中心可以根据报送全过程的体验对发电厂进行信誉评价,之后系统调用智能合约自动更新发电厂信誉评价积分。碳排放数据分析中心通过信誉评价机制能够充分了解发电厂的过往信誉情况,并在挑选发电厂时做出更合理的选择。
在碳排放数据报送中,发电厂将碳排放数据的数据总量D、报价P提交到联盟链系统,然后等待碳排放数据分析中心回复。智能合约将依据预置算法处理发电厂的报价P、数据总量D与信誉评价E数据,综合衡量后为碳排放数据分析中心推荐合适的方案。每次碳排放数据报送完毕,碳排放数据分析中心需提交参与该次报送发电厂的数据质量打分、交易履约情况打分、业务咨询情况打分,三项分值最终决定发电厂该次的信誉评价。综合考虑以上因素,设计了相应数学计算公式,数学计算公式为:
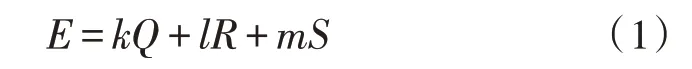
式中,Q表示之前x次数据质量打分的均值,R表示之前x次交易履约情况打分的均值,S表示之前x次业务咨询情况打分的均值,k、l、m表示各打分均值的相应权重。
CRITIC 权重法综合考虑了指标对比强度与指标之间的冲突性,在客观赋权方面性能优于标准离差法与熵权法[17],因此信誉评价机制选择采用CRITIC 权重法衡量各评价指标的权重。
设定存在n个评价对象,p项评价指标,则起始指标数据矩阵为:
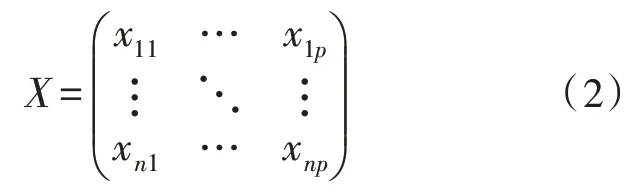
式中,xij代表第i个评价对象第j项评价指标的数值。
各评价指标需要进行如下无量纲化处理:

标准差(可以了解各评价指标内的取值差异波动状况)的计算方法为:
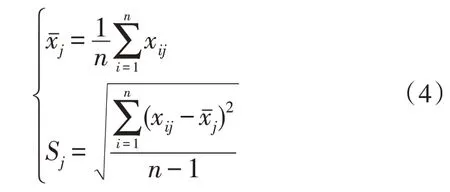
式中,Sj代表第j个评价指标的标准差。
相关系数(可以了解评价指标间的相关性)的计算方法为:
钢板路基箱临时道路是在长期实践的基础上研发的道路结构,但由于垃圾沉降及道路积水影响,钢板路基箱容易发生漂移、分离,行驶车辆经常发生轮陷、侧翻事故。为此对路基箱进行了多项改进,以钢板路基箱连接技术为基础[1],优化跨明沟钢板与路基箱连接,保障车辆通行安全;优化倒车平台与路基箱连接形成的简易卸料平台,在保证安全的前提下提高效率。

最后得到第j个评价指标Wj的权重:

式中,Cj代表第j个评价指标的信息量,计算方法为:

设定某一范围内存在若干电厂,信誉评价机制运行过程如图5 所示。首先,电厂上报碳排放数据的报价与数据总量。其次,智能合约调用对应电厂的信誉评价积分,然后在综合考虑报价、数据总量、信誉评价下核算推荐方案。最后碳排放数据分析中心决策出参与报送的电厂,并在报送完成后对该次参与的电厂进行评价,智能合约同步更新对应电厂的最新信誉评价积分。

图5 信誉评价运行过程
通常选择具体的发电厂时,报价低的发电厂更容易被考虑,但是报价低的发电厂难以保证碳排放数据的高可靠性,因而文中在激励层设计信誉评价机制,该机制依据各发电厂以往数据的报送情况计算其最终信誉评价积分。综合权衡报价、数据总量、信誉评价积分三因素选拔发电厂,有利于引导发电厂提高参与报送积极性。
3 案例分析
碳排放数据分析中心挑选发电厂进行碳排放数据有偿报送属于多目标优化问题,基于粒子群算法的多目标搜索算法[18]通常是解决该类实际问题的较好方法。该类问题解决步骤主要为:首先确定目标函数、约束条件与决策变量参数,然后通过随机解迭代计算求出一个非劣解子集,最后依据决策者意愿得出最终解。
设定碳排放数据分析中心希望获得五类发电厂(火电厂、风电厂、核电厂、水电厂、太阳能电厂)的碳排放数据,实际中每类发电厂有四家可供选择。这些发电厂在数据报价、数据总量、信誉评价方面都存在差异,而碳排放数据分析中心希望数据报价越低越好,数据量越大越好,信用评价满足约束条件。在以下碳排放数据报送模型中,数据报价通过P表示、数据总量通过D表示,出售方信誉评价通过E表示,选择的卖方用Y表示。构造的目标函数和约束条件为:
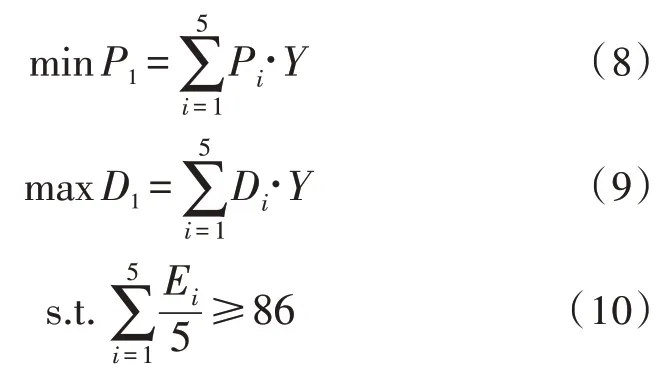
式中,P1表示购买数据总花费,D1表示购买数据的数据总量,另外出售方总体信誉评价约束条件为86 分。
现设定发电厂报价、数据总量、信誉评价分别如表2、表3、表4 所示。其中,k取值1~5 分别代表火电厂、风电厂、核电厂、水电厂、太阳能电厂,Mk、Nk、Ok、Pk代表每类电厂中可供选择的四个发电厂。

表2 发电厂报价表
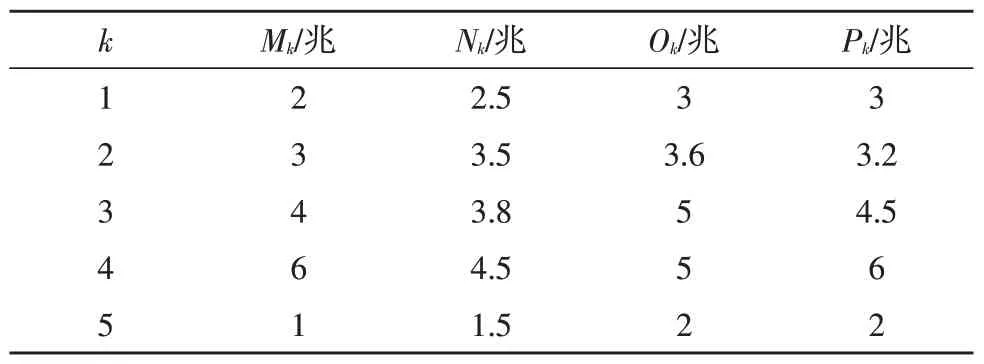
表3 发电厂数据总量表

表4 发电厂信誉评价表
对表格进行举例说明如下:表1 中,M1、N1、O1、P1代表四个不同火电厂,而它们的报价分别是400 元、500 元、600 元、400 元;表2 中,M2、N2、O2、P2代表四个不同风电场,它们的数据总量分别是3兆、3.5 兆、3.6 兆、3.2 兆;表3 中,M3、N3、O3、P3代表四个不同核电厂,它们的信誉评价分别为75 分、93 分、86 分、79 分。
按照上述确定好的目标函数、约束条件与决策变量参数,通过Matlab 将该实例进行仿真,得到非劣解空间分布如图5 所示,包括非劣解方案共计五种。图中纵轴对应每种方案所需的总花费,横轴对应每种方案包含的数据总量。
5 种非劣解方案对应电厂具体选择情况如表5所示。举例说明如下:方案1 中,选择火电厂P1、风电厂O2、核电厂O3、水电厂P4、太阳能电厂P5五个电厂报送数据;方案2 中,选择火电厂P1、风电厂M2、核电厂O3、水电厂P4、太阳能电厂P5五个电厂报送数据。
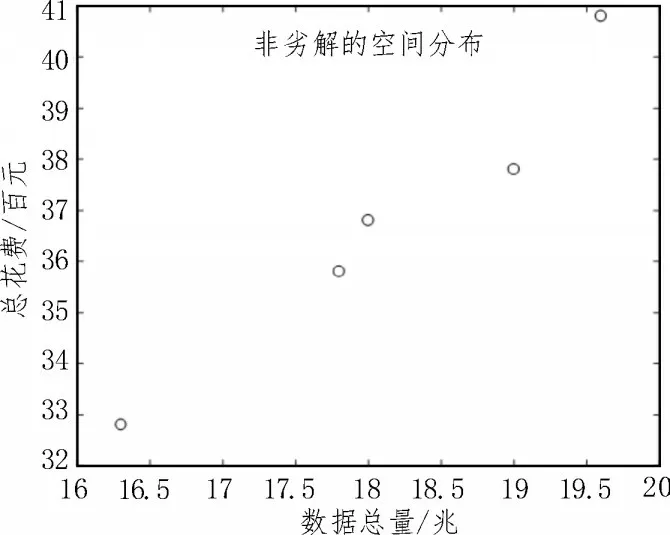
图6 粒子群寻优仿真结果图

表5 非劣解方案表
联盟链中智能合约将依据总花费将5 种非劣解方案进行排序,如表6 所示,每种方案同时附带数据总量与出售方信誉评价。将推荐方案表发送至碳排放数据分析中心,为其选择发电厂提供全面参考。
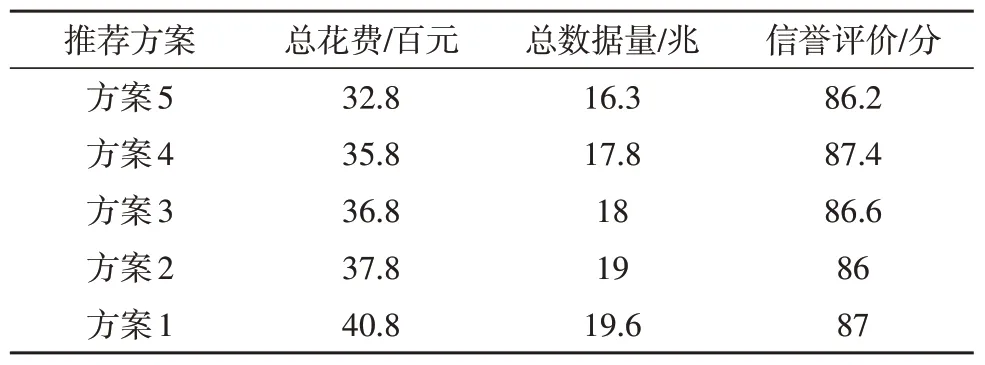
表6 推荐方案表
4 结束语
该文研究了碳排放数据报送联盟链架构,促进了发电厂与碳排放数据分析中心的互通、互信,设计的信誉评价机制解决了发电厂参与积极性不高的难题,实例分析验证了信誉评价在碳排放数据报送中的适用性。未来的工作中,信誉评价机制中的考核因素应随着相关部门最新政策的发布、市场的具体情况做出更合理的设计。
猜你喜欢
计算机应用文摘·触控(2022年8期)2022-05-25
小猕猴智力画刊(2022年3期)2022-03-29
小猕猴智力画刊(2022年3期)2022-03-28
疯狂英语·初中天地(2021年4期)2021-06-09
疯狂英语·初中天地(2021年3期)2021-05-21
华人时刊(2019年13期)2019-11-26
军事文摘(2018年24期)2018-12-26
电子制作(2017年1期)2017-05-17
山东工业技术(2016年15期)2016-12-01
金桥(2016年4期)2016-10-14
