
数据挖掘技术在房价预测与分析中的应用
2022-11-30 02:48:12蔡天润
统计科学与实践 2022年10期
□蔡天润
党的十八大之后,我国全面加大对房地产市场的有效调控。特别是提出“房住不炒”概念之后,全国各地房价调控政策不断提出。保障人民群众合理住房的需求,保证房地产市场健康有序发展成为了当务之急。构建有效的房价预测模型对金融市场、民情民生有着重要意义。2021 年1 月27 日,杭州楼市发布新政策,加强了对限购、限售、税收调节等环节的监管,完善无房家庭认定标准以及高层次人才优先购房政策。同年8 月5 日,杭州楼市再发新政策,进一步完善新房销售和摇号政策。多重因素的作用下,杭州二手房房价整体呈现出明显变化,研究杭州二手房房价有利于帮助“新杭州人”更好地了解杭州楼市现状。
|数据来源和预处理
(一)数据的来源与说明
本文以爬取杭州链家上城区、余杭区、萧山区等10 个行政区域的二手房源数据为例。链家网正式成立于2010 年,其房源包含上海、北京、广州等42 个城市,在2015年荣获“传统企业互联网+”创新奖,是国内最热门的房源提供平台。
本文爬取了29027 条数据,数据所涵盖的时间跨度从2018 年到2021 年,爬取的部分数据共有46个类别,包含区域位置、纬度、经度、单价、总价、关注度、所在楼层、建筑面积、户型结构、套内面积、建筑类型等变量。
(二)数据预处理
在爬取数据的过程中,会产生异常值、噪声、数据丢失等情况,数据清洗能防止出现上述情况,从而提高模型预测效果,是预处理中重要的环节,不可或缺。在本次处理缺失数据中,我们首先删除空值的行、列。随后观察数据特征变量,删除一些对房价预测明显无关的信息,如看房时间、链家编号、房本备件等。随后,将暂无数据的数据全部转为空值,去除建筑面积后带有的单位,只保留数值部分。最后将区域拆分为区域和子区域,分离所在楼层的楼层数。
如果爬取房价是空值,可以自定义函数,用相同经纬度楼盘的数据做填充。如果房价数据的相关信息缺失,可使用该组数据的众数做填充。比如,对于配备电梯、房屋年限、户型结构等列,对其空值采用众数填充。对于像电梯这样只有两个类别的变量,可以通过布尔值将其转换为0 和1。但是对于房屋朝向等特征,此时可以用one-hot热编码将定性变量转化为数值变量,从而更好适应算法。
|数据探索分析
(一)房价影响因素分析
在经过数据清洗后,得到一份新的数据。观察可知,杭州十个行政区域中,滨江、上城、余杭的二手房价最高,房源数量较多且价格浮动较为平稳,而萧山、临安等区二手房价较低且数量较少,可见一些老城区二手房源不仅数量较多且价格也偏高。因此,对于年轻人来说,如果手中的现金流不太充足,可以考虑一些萧山、临安的二手房。
分析杭州市二手房挂牌时间,可以看出在2018 年之前杭州二手房的挂牌数量十分少,因此我们可以着重分析2020 年和2021 年这两年二手房楼市之间的变化情况,并进一步分析影响房价的相关因素。
通过进一步观察,可以发现房屋面积越大,价格大部分也越高,但是部分面积小的房价却比面积大的房价高。这种情况也可以侧面说明,房屋建筑面积不是影响房价的唯一因素。观察房价与楼层的关系,发现并不是楼层越高,二手房单价就越高,大部分35 层以下的房子还是受人欢迎的,说明楼层与房价单价之间存在一定的关联。最后分析已有数据,可以观察到目前市场上3 室2 厅1 厨2 卫的户型是市面上出售最多的户型,因此可以合理地猜测房价会受到户型的影响,并且不同的室、厅、卫分布情况对房价会产生不同的影响。
(二)特征变量选取
从已有数据绘制的相关系数热力图可以看出,房屋建筑不是影响房价的唯一因素。房屋的建筑面积与房价存在一定相关性,而关注度、燃气价格、楼层数与房价之间的关系不大,所以这几个方面的特征可以在构建特征工程时忽略不计。
|杭州二手房房价预测
(一)模型评价指标
在构建模型的过程中,需要选择合适的指标来衡量模型的预测效果。针对回归问题,常用的度量指标为均方误差(MSE)。均方误差反映了实际值和预测值平方和的期望,通常情况下均方误差越小,那么表明预测模型效果越好,其数学表示式可以记为:
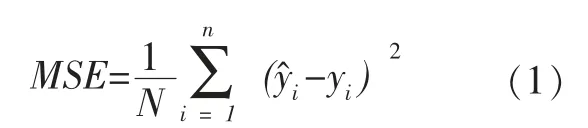
上式中的N 表示样本总数,i表示每个样本数据,其中yi 表示第i 个实际值,表示回归模型的预测第i 个样本的预测值,通常情况下均方误差越小,代表模型的预测越好。
同时,可以引入平均绝对误差(MAPE)作为一个评估模型准确性的另一个指标,该指标综合考虑了实际值与预测值之间的误差,也将误差与真实值之间的比例考虑其中。该指标的取值范围为[0,+∞),当MAPE 取值为0%代表完美模型,当大于100%时则表示为劣质模型,其公式如下所示:
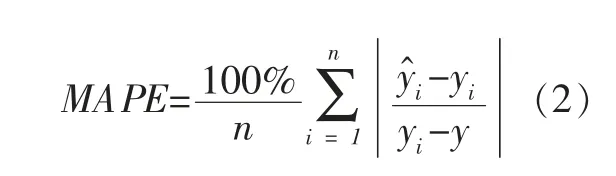
在此基础上,为了衡量预测值相对真实值拟合好坏的程度,本文引入了R2,该变量可以衡量线性回归的拟合程度,线性模型的可以理解为以最小化R2为目标,寻求y和x 之间的最优线性关系,其定义如下所示:

(二)杭州二手房价的多元线性回归模型
经过数据预处理后还剩下27977 条杭州市二手房房价数据,将数据集随机划分为训练集和测试集,使训练集占总数据集的70%,测试集占总数据集的30%,为了使模型预测的效果更加稳定,本次模型构建采用了三折交叉验证,将训练集分成3 份,2 份作为训练集,1份作为测试集,求得3 次试验的平均结果。本文使用python 中sklearn库中的多元线性回归算法,它的主要参数包含 fit_intercept、normalize、n_jobs 和copy_X。训练模型的评价指标具体如表1 所示:

表1 测试结果比较表
观察多元线性回归模型的均方误差和平均绝对误差,可以看出该模型的预测效果比较一般,而R 平方的值小于0.8,说明该模型的拟合效果也不是非常理想,于是考虑尝试建立其他回归模型进行二手房价的预测。
(三)杭州二手房价的随机森林模型
本文调用了python 中sklearn库中随机森林算法,用该算法对杭州二手房价进行预测,设置随机种子random_state=0,这样可以使每次构建的模型都是不同的,并采用5 折交叉验证对训练集和测试集进行验证。该算法的主要参数包含:n_estimator、max_depth、min_samples_leaf 等。
综合考虑算法处理时间和后续网格搜索空间,首先要确定随机森林各参数大致取值范围。这里以基评估器树目为例,该参数对随机森林模型的影响呈正相关性,当该参数取值越大,模型的预测效果也越好,当n_estimator 的取值上升到一定情况时,模型的预测效果便不会存在显著提升。这里设置n_estimators 取值范围为100 到4000,步长为 1000,绘 制n_estimators 和R 方之间的关系图(图1)。

图1 n_estimators 和R 方关系图
从图中可以看出,随着n_estimators 的增大,R 方的值也越大,说明模型的拟合效果也越好,因为在n_estimators 在取值为1100时,R 方的数值并没有明显的改进,考虑计算性能,可以将n_estimators 取值设为1100。随 后绘制min_samples_leaf 和R 方的学习曲线图(图2)。

图2 min_samples_leaf 和R 方学习曲线图
从图中可以发现,随着min_samples_leaf 数值的增大,模型的拟合效果越来越差,说明在为调整min_samples_leaf 后,模型的预测效果反而变差。因此,这里的min_samples_leaf 设置为默认值。同时,画出最小样本分枝数时的情况跟上图相类似,所以最小样本分数值也取默认值。
最后,进行网格搜索,将n_estimators 设为1100,最大深度设为15、20、25,分支的最大特征数设为auto,得到以下结果(表2):

表2 测试结果比较表
可以看出,相比对多元线性回归,随机森林模型的预测效果有了进一步提升,在训练集上的R 方达到0.97,但是测试集上缺只有0.799,说明该模型存在一定的过拟合现象,但是相对于多元线性回归模型,随机森林回归模型整体表现较好。
(四)杭州二手房价的XGBoost模型
XGBoost 实质上是一种基于梯度提升树的集成学习算法,因此具有和树相同的性质。它包含以下重要参数:n_estimators 代表弱评估器,若该值越大,说明模型的学习能力也就越强;subsample 的取值范围为 (0,1],表示随机抽样的比例;学习率用learning_rate 来表示,可以控制模型的迭代速度;gamma代表复杂度惩罚项;max_depth 代表树的最大深度,可以控制模型的复杂度。
随后,根据num_round 和R方、eta 和R 方的学习曲线,可以选 择 num_round 的值为 1500,subsample 的值为0.9,随后用xgb自带的网格搜索进行调参,绘制对比图可以发现,相比于初始默认参数来说,经过调参后的模型泛化能力变强。同时,模型在训练集上调整后的均方误差也变小了,这表明XGBoost 模型的预测效果还是相对理想,最后得到的训练结果如表3所示:
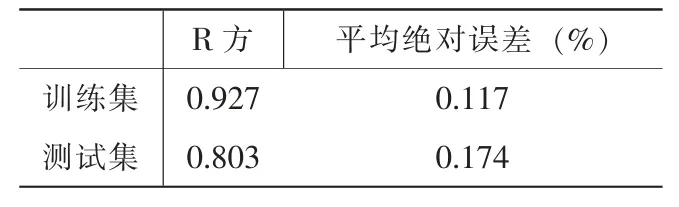
表3 测试结果比较表
(五)预测对比分析
分别使用随机森林、XGBoost、多元线性回归三个回归模型对杭州二手房房价进行预测,假设现在某购房者想购入一套二手房,该二手房具体信息如下:120 平方米,中层(16),3 室1 厅1 厨1 卫,朝东南,滨江区,平层,精装,有电梯,普通住宅,未满两年。使用三种不同的预测模型对该二手房进行房价预测,并将结果与实际值进行比较,比较结果如表4 所示:
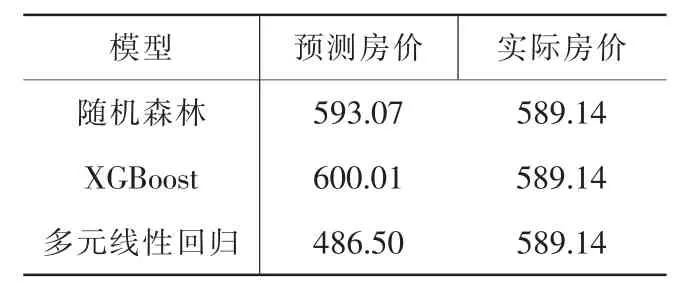
表4 杭州二手房房价预测表
从该测试结果可以看出,使用随机森林和XGBoost 训练出的模型可以较好地预测房价,而多元线性回归预测的结果不尽如人意,这可能是特征工程构建不当所导致。
|总结和展望
本次通过对杭州链家官网的数据进行爬取、预处理、构建特征工程等一系列操作,运用数据挖掘技术对已有的数据进行探索,初步了解了整个杭州二手房房价总体分布情况。根据已有的数据集划分测试集和训练集,运用已有的机器学习算法构建相应的房价预测模型,优化算法对超参数进行相应的优化,得到最优结果。
但是本次实验也有很多不足,如选取特征工程时候没有考虑到一些国家政策的因素,即缺少了一些文本信息,这在以后的实验中需要进一步改进。同时,本次训练得到的模型具有一定的局限性,不能准确预测中国各省市二手房价,这一点也要在未来仔细考量。本文理论方面创新不够,仅仅通过现在的机器学习模型进行预测,调优超参数方面也使用较为简单的网格搜索算法,后续可以考虑引入Stacking 组合模型等。
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:08:00
中学生数理化·高一版(2021年2期)2021-03-19 08:32:06
房地产导刊(2020年11期)2020-12-28 01:32:36
中华建设(2019年8期)2019-09-25 08:26:04
中央民族大学学报(自然科学版)(2018年3期)2018-11-09 01:16:34
中华建设(2017年3期)2017-06-08 05:49:29
财经(2016年19期)2016-08-11 08:07:28
公民与法治(2016年8期)2016-05-17 04:11:34
投资北京(2016年9期)2016-05-14 00:56:58
商业文化(2016年3期)2016-04-19 09:53:12
