
基于目标检测的驾驶人分神驾驶行为检测方法研究
2022-11-26 02:23:52何廷全俞山川张生鹏兰栋超
公路交通科技 2022年10期
何廷全,俞山川,张生鹏,兰栋超,李 刚
(1. 广西新发展交通集团有限公司,广西 南宁 530029; 2.招商局重庆交通科研设计院有限公司,重庆 400067; 3. 长安大学 电子与控制工程学院,陕西 西安 710064; 4. 长安大学 能源与电气工程学院,陕西 西安 710064)
0 引言
根据2020年世界卫生组织的报告,全世界每年大约有135万人死于交通事故。全世界各地,大多数国家道路交通事故造成的经济损失约等于国内生产总值的3%。其中,造成重大交通事故的主要原因之一就是驾驶人的分神驾驶行为[1]。驾驶人分神驾驶行为包括开车时打电话、玩手机、喝水以及和他人交谈等行为,驾驶人会在开车时无意中发生这些行为。这些行为对交通安全带来极大的危害,例如,分神驾驶可能导致车辆异常变道,这可能导致严重的交通事故[2]。同时,近年来车载电子设备的普及,如车载导航系统、智能手机的使用,增加了驾驶人分神驾驶的频率。因此,对驾驶人分神驾驶行为进行深入研究是非常有必要的。通过图像分析方法,对驾驶人分神驾驶行为进行监测并同时发出预警信息,能够及时的提醒驾驶人专心驾驶,减少由分神驾驶造成的交通事故。
在过去的研究中,研究者为了检测驾驶人的分神驾驶行为,提出了一些基于驾驶人生理参数和驾驶状态的方法[3-4]。通过观测驾驶人生理参数的方法虽然具有很好的准确性,但是依赖大量的检测仪器,这些仪器不仅会干扰驾驶人,同时仪器成本较高、安装复杂。因此,基于驾驶人生理参数的检测方法只适用于一些特殊驾驶环境,不能够普及到大众。除此之外,曾杰等[5]开发了一套基于仿生机器人的驾驶人危险驾驶检测系统的测试技术,利用机器人模拟人的疲劳、打电话等动作,来测试检测系统的性能,对新开发的测试系统评估提供了便利的方法。
近年来,随着机器视觉和机器学习的快速发展,基于图像处理的方法也被应用于检测驾驶人分神驾驶行为。基于图像的检测方法主要是通过车载摄像头采集驾驶人图像对驾驶人的身体动作、眼睛、面部表情等部位提取关键信息来判断驾驶人的驾驶状态。文献[6]提出了一种基于视频的检测方法,通过分析驾驶人的面部与眼睛特征,判断视线方向和面部姿势来判断驾驶人是否存在分神驾驶行为。文献[7]基于驾驶模拟环境,分析驾驶人的眼部特征来检测驾驶人眼睛凝视时长和眨眼睛次数,建立了基于随机森林的分神驾驶识别模型,可以达到较好的准确率。深度学习同样被用来识别分神驾驶行为,文献[8]利用预训练深度模型,结合支持向量机分类器来检测驾驶人分神驾驶行为。文献[9]利用视觉几何组(Visual Geometry Group,VGG16),VGG19以及Inception模型对驾驶人分神驾驶行为进行检测和分类。在VGG模型的基础上,文献[10]加入了正则化技术,提高了分神驾驶检测和分类的精度。文献[2, 11]中通过微软研发的Kinect相机采集到驾驶人的驾驶行为图像,提出了基于卷积神经网络CNN模型的分神驾驶行为检测系统。同时,结合高斯混合模型GMM分割算法对原始图像进行分割,该方法基于CNN的分神驾驶行为分类器的平均分类精确度可以达到91%。
然而由于深度学习技术的不断发展,对于驾驶人分神驾驶行为的检测与分类精度有了更高的要求。同时上述基于深度学习的分神驾驶行为检测和分类模型参数计算量大,冗余参数较多。
1 基于改进YOLOv5的驾驶人分神驾驶行为识别算法
分神驾驶行为检测的目的是通过一系列算法对驾驶人的分神驾驶行为进行识别和分类。根据识别结果对驾驶人行为进行判定,当判断为危险驾驶行为后则发出报警,从而实现对驾驶人的实时提醒,保证安全驾驶。
本研究提出一种基于目标检测模型的驾驶人常见分神驾驶行为检测方法。构建一种改进YOLOv5模型的驾驶人分神驾驶行为检测网络,通过捕捉驾驶人在驾驶过程中的图像信息进行分神驾驶行为检测。驾驶人分神驾驶行为检测算法的训练及测试流程如图1所示。
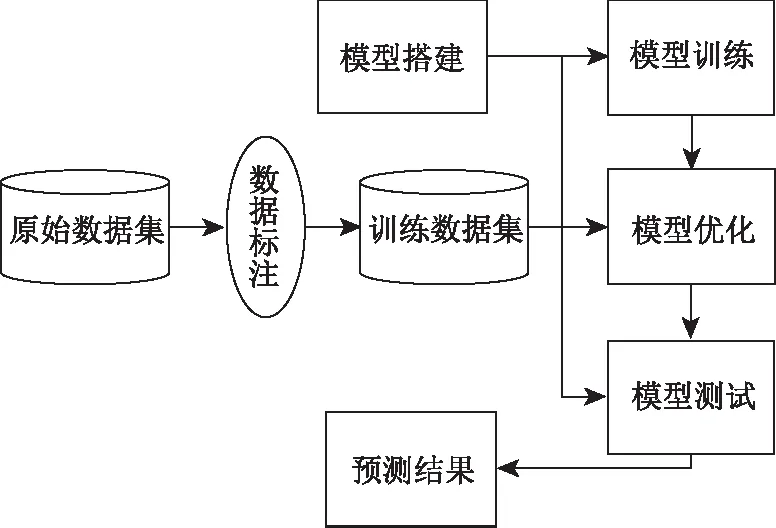
图1 试验流程
1.1 数据集
对于目标检测模型的训练,图像数据集的选取和制作非常重要。本研究的数据集来自于Kaggle组织的一场驾驶人危险驾驶行为图像分类竞赛。以往的分神驾驶数据集只包含几类常见的分神驾驶行为,而Kaggle的数据集包含了9种不同的驾驶行为,具有更好的广泛性。如图2所示,显示了9种常见的驾驶行为动作图像。

图2 九种常见的驾驶行为
选用原始数据集中5 000张驾驶人驾驶行为图像,其中包含正常驾驶660张、右手玩手机556张、右手打电话558张、操作多媒体543张、左手玩手机545张、左手打电话550张、喝水545张、与他人交谈525张、化妆等其他动作518张。
由于分神驾驶行为检测仅关注驾驶人的行为动作,因此选取原始数据完成后,采用LabelImg软件对驾驶人的驾驶行为进行标注。在驾驶室内,驾驶人的驾驶行为主要表现在上半身,能够反映驾驶行为的主要特征是手部行为,面部方向。基于原始数据,对驾驶人上半身以及方向盘进行标注,并且给予相应的行为标签。将所有的图片顺序打乱,把数据集分为训练集、验证集、测试集,比例为3∶1∶1。训练集包含3 000张图像,验证集和测试集各包含1 000 张图像。根据原始数据集的9种不同的驾驶行为,使用不同的标签给不同的驾驶人动作进行标注。标注完成后生成对应的xml文件,包含了图像中目标框坐标以及类别信息。本研究将利用上述数据集对目标检测网络进行训练,最终得到分神驾驶行为检测模型。
1.2 目标检测模型及分神驾驶行为检测问题
在现阶段的研究中,基于深度学习的目标检测模型可以分为两阶段检测算法和单阶段检测算法。两阶段检测算法的思路是,在第1阶段生成可能包含所有目标物体的候选区域,第2阶段在第1阶段生成的候选区域中提取特征进入到分类和回归网络,最终得到检测结果。而单阶段检测模型直接根据图像中的特征对目标进行检测和分类,最终得出预测结果。相比较单阶段检测算法,两阶段的检测算法可以获得更加良好的边界框回归,但是在获取更高精度的结果的同时,两阶段检测算法比单阶段检测算法的效率更低。文献[12]中对现阶段基于深度卷积网络的各类目标检测算法进行了综述,表1总结了部分两阶段与单阶段算法的性能表现。其中包了算法的类别、检测速率、检测时的GPU型号以及在计算机视觉挑战赛(Visual Object Classes,VOC2012)和微软构建的(Common Objects in Context,COCO)两种数据集上的检测指标结果,“-”代表无相关数据。通过观察相关数据发现,单阶段目标检测算法在检测速度上明显优于两阶段算法。同时单阶段算法经过不断改进后,算法的检测精度不断提高,甚至超过了两阶段算法。
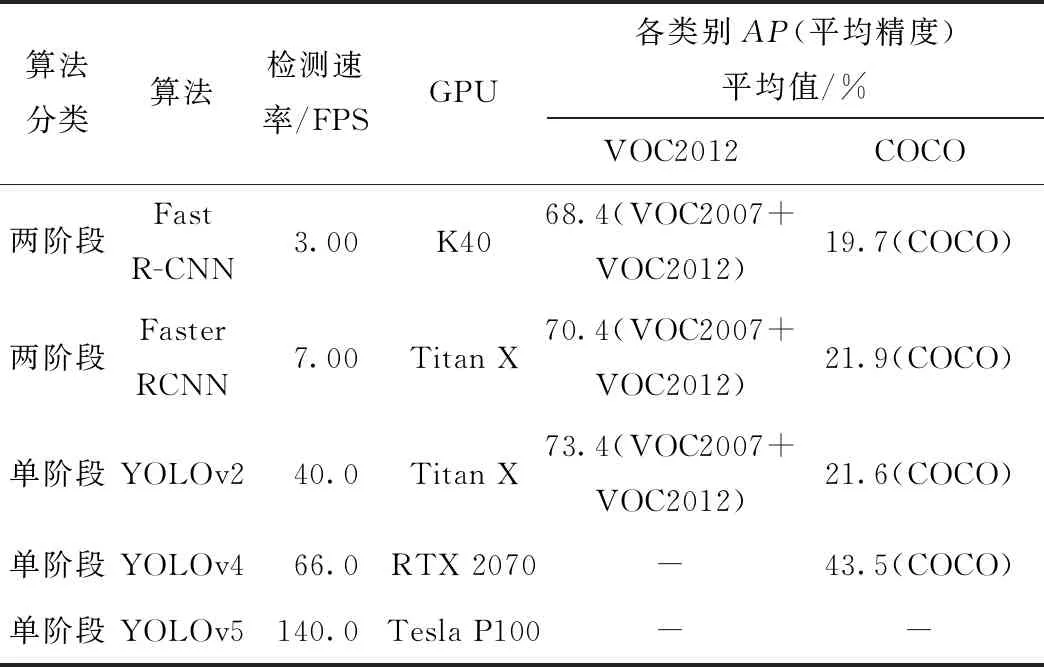
表1 部分目标检测算法性能对比
本研究的分神驾驶行为只需要对驾驶室中的驾驶人动作进行准确的预测分类,每一张图像或者视频帧中一般只存在一个目标类别。同时,在驾驶人驾驶过程中需要对驾驶人进行实时监测和提醒,单阶段检测模型在可以保证精度的前提下保证更高的效率,而且对硬件设备要求更低,因此选用相对效率更高的单阶段检测模型来对驾驶人分神驾驶行为进行监测。
1.2.1 YOLOv5目标检测网络
YOLO(You Only Look Once)系列目标检测算法,是单阶段检测算法中代表性的网络。YOLOv5是YOLOv3及YOLOv4基础上改进得到的最新产物,而且YOLOv5在COCO以及PASCAL VOC数据集上表现出较好的效果。相较于YOLOv4,YOLOv5在检测精度降低很小的基础上,提升了模型的训练效率以及推理速度。
YOLOv5的整体架构由输入(Input),骨干(Backbone),颈部(Neck),预测(Prediction) 4个部分组成,模型架构图如图3所示。输入端主要包括3个部分,依次是自适应图片缩放、马赛克Mosaic数据增强、自适应锚框计算。由于该网络的输入图像要求大小为608×608,为了适应不同尺寸的输入图像,需要自适应图片缩放这一模块来对原始图片进行预处理。自适应图片缩放将原始尺寸的图片进行比例缩小或者放大,添加最少的黑边,从而减少图像缩放过程对原始特征的影响。Mosaic数据增强方法,是将4张图片采用随机排布、随机裁剪、随机缩放的方式进行拼接,丰富图像背景数据,增加网络训练的鲁棒性。同时,在批量归一化(Batch Normalization)时一次计算4张图像数据,提高模型训练效率。而自适应锚框计算,是将预测框和真实框进行差值,反向更新预测框,通过多次迭代获取更为精确的锚框。
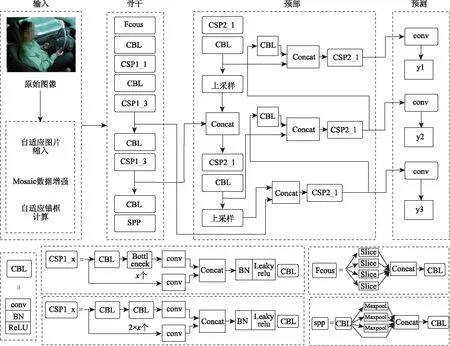
图3 YOLOv5整体架构
Backbone部分包含了集中(Focus)模块和CSP(Cross Stage Partial)结构[13]。Focus模块主要采用slice操作对输入图像进行裁剪,扩充输入通道,经过卷积操作得到特征图。Focus操作可以提升感受野,保证获取更加完整的特征信息,同时可以提高计算速度。另一方面借用CSP网络的思想,提升网络的特征提取能力。Neck仍然采用FPN[14]加PAN[15]的结构,在YOLOv4的基础上改进卷积操作,使用CSP2结构,充分融合位置信息和语义特征,提升网络特征融合能力。图中CBL为Yolov网络结构中的最小组件,由Conv+Bn+Leaky_relu激活函数三者组成,CSP由卷积层和残差模块连接,Concat层的作用是将两个及以上的特征图按照在channel或num维度上进行拼接。输出层输出不同尺寸的特征图,用来关注不同大小的目标以及特征信息,通过使用GIoU_Loss(Generalized Intersection of Union Loss)作为损失函数进行优化训练,最终得出预测结果。
1.2.2 分神驾驶行为检测问题分析
通常在解决图像检测实际问题时,需要根据具体的场景选择和优化方法。YOLOv5在目标检测领域已经有了非常良好的效果,但是针对本研究的分神驾驶行为检测和分类问题,仍然存在部分缺陷。
(1)YOLOv5试验使用的数据集为COCO等常用目标检测数据集,原始模型采用K-Means聚类方法获取,COCO数据集中包含几十种类别,且锚框大小皆不相同。而本研究的对象为驾驶室里的驾驶人,标注的目标部分仅仅为驾驶人以及方向盘图像信息,单张图像一般只包含一个类别,原始的先验锚框参数不适用于本研究。仅靠人获取先验锚框信息,如果锚框的大小设置不合理,在训练和检测过程就会产生一定的偏差。
(2)分神驾驶行为检测和分类是要依据驾驶人的上半身整体动作进行综合判断,因此需要分析驾驶人整个上半身以及方向盘的图像才能获取更加客观的信息。但是,在网络获取特征时,需要在整个标注图中再获取驾驶人的局部动作信息,这些动作往往会比较小。虽然在检测过程中需要关注驾驶人整体信息,但是表现出来的危险驾驶动作仅仅体现在图像局部区域,因此需要在检测过程中提取局部信息的特征,如果在特征提取时忽略小目标的特征,容易发生误判。
(3)算法的Backbone中含有较多的BottleneckCSP网络结构,卷积过程中包含大量的参数,模型计算量较大。同时,在提取特征信息的过程中,大量的卷积操作可能忽略图像的浅层特征,会造成局部信息的丢失,从而影响了最后的类别判定。
1.3 针对分神驾驶行为检测改进算法
根据上述YOLOv5在分神驾驶行为检测问题中存在的问题,对检测算法进行了以下的优化来提升对分神驾驶行为检测的精度:(1)针对锚框设定问题进行优化,原先的锚框由人为设定,设定的锚框大小不灵活,会出现丢失特征信息的情况。因此在模型的锚框设置阶段借用DAFS(Dynamic Anchor Feature Selection)[16]的思想设置动态锚框。(2)对于Backbone中的BottleneckCSP网络结构进行修改,减少卷积操作,从而保证更少的浅层特征丢失。同时,在主干网络部分添加注意力机制,提高模型获取局部感兴趣区域信息的能力。
1.3.1 锚框设定问题的优化
本研究在YOLOv5模型的基础上对锚框选择进行优化。在DAFS中提到,原先的锚框改良模块(anchor refinement module,ARM)利用背景和前景评分,利用二值化评分预测容易出现漏掉正确信息的情况,导致特征点锚框和感受野不匹配。因此,提出了在检测器头部之前添加了特征选择操作,动态调整特征点,为每个回归器和分类器选择了合适的特征点,减少不匹配问题的出现。其次,将传输连接块(transfer connection block,TCB)替换为双向特征融合块(bidirectional feature fusion,BFF),其主要目的是利用自上而下和自下而上的方式组合不同层的信息。根据这一思想,对YOLOv5的锚框选择方式进行优化,如图4所示。首先利用初始方法,产生初始锚框,然后在模型的输入端添加ARM模块,从而达到过滤锚框负样本的效果,再根据真实值对锚框进行调节获取先验信息。其次,通过双向特征融合块将ARM与主干网络进行连接,通过动态更新锚框生成模型训练的先验锚框。
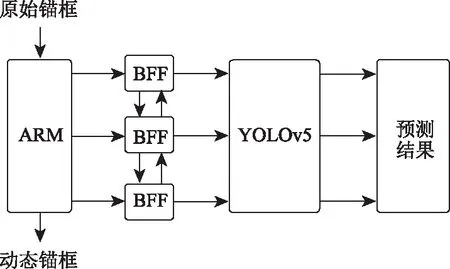
图4 锚框优化
1.3.2 针对主干网络优化
(1)BottlenckCSP网络结构优化
在YOLOv5的Backbone模块中采用多个平静层卷积残差BottlenckCSP网络结构,在卷积操作中会减少部分局部特征,从而失去有一部分关键的特征信息。在Backbone网络的特征提取层进行了修改,修改后的BottlenckCSP网络模块如图5所示。

图5 BottlenckCSP网络改进
将BottlenckCSP网络结构数量(×3,×9,×9,×3)改为(×2,×6,×6,×2),从而保护局部特征信息不被丢失。同时针对多个卷积核导致的参数量大的问题也进行了相应的优化,将BottlenckCSP网络的输入特征映射与输出特征直接连接,删除掉模块的分支卷积,减少了参数的数量,这样做的目的是减少计算量的同时提取更多的浅层特征。
(2)注意力机制的融合
注意力机制模块可以让网络模型更加注重具有关键特征信息的区域,排除掉一些无关信息,从而提升网络的局部特征提取能力,进一步优化检测效果。为了提升分神驾驶检测网络的检测效果,本研究考虑将注意力机制应用到原始网络。
本研究采用SEBlock(Squeeze-and-Excitation Networks)[17]的注意力机制模块,将该模块融合到YOLOv5框架。SEBlock结构图如图6所示。
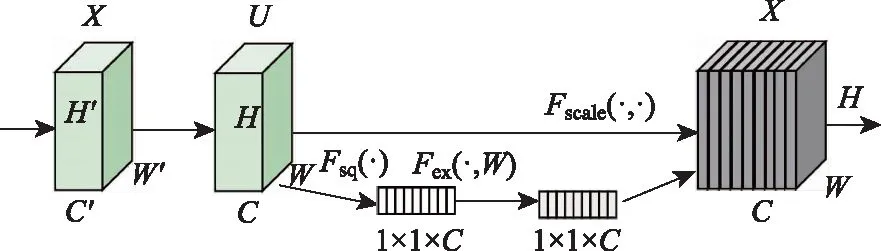
图6 SEBlock结构
图6中,X为网络的输入,Ftr为一系列卷积操作,U∈RH×W×C为卷积操作的输出,U=[u1,u2,…,uC]。SEBlock主要有3部分组成,Sequeez,Excitation,Scale。Sequeez操作将U输出压缩成Z∈R1×1×C,为了充分提取上下文信息,使用GAP(global average pooling)作用于每个通道实现通道选择。Excitation利用非线性的Sigmoid激活函数保证非线性的情况进行通道选择。Scale是将学习到的通道权重应用到原有的特征上。GAP有利于识别全局信息,而GMP(global max pooling)可以通过识别全局最大点来检测目标的特征信息,针对局部小目标特征提取有更好的效果。在本研究的通道注意力机制模块将二者同时使用。
本研究在原有的网络添加通道注意力机制和空间注意力机制,添加方法如图7所示。在CBL模块添加通道注意力机制,CSP模块卷积操作之后添加混合注意力机制,从而使模型更好地获取重要的特征。
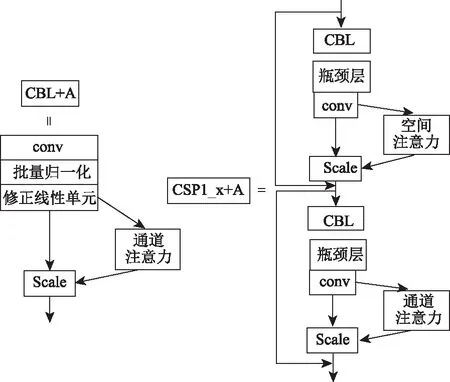
图7 注意力机制的融合
提出了一种基于改进YOLOv5的分神驾驶行为检测和分类模型YOLOv5_DD (YOLOv5_Distracted Driving),针对具体的分神驾驶行为检测和分类问题对YOLOv5进行了优化。主要在锚框设定方式以及主干网络进行了改进,使得模型更适合应用于分神驾驶行为检测。在损失函数方面,仍然使用YOLOv5原有的损失函数对模型进行训练优化。
2 试验结果与分析
2.1 试验环境与模型训练
试验采用的计算机配置,CPU为Inter(R)Core(TM)i7-7800,GPU为NVIDIA1080Ti。基于Tensorflow的深度学习环境进行模型的训练和测试。软件环境Tensorflow版本为2.2,Python版本为3.8。
模型训练时,按照1.1节中提到的数据集比例将数据随机分为训练集、验证集、测试集。采用监督学习的训练方式对模型进行训练,经过多次训练和测试,选取了模型训练最终参数。学习率设置为1e-4,迭代次数设置为300,使用Adam优化器进行优化,图8为模型训练损失变化曲线。
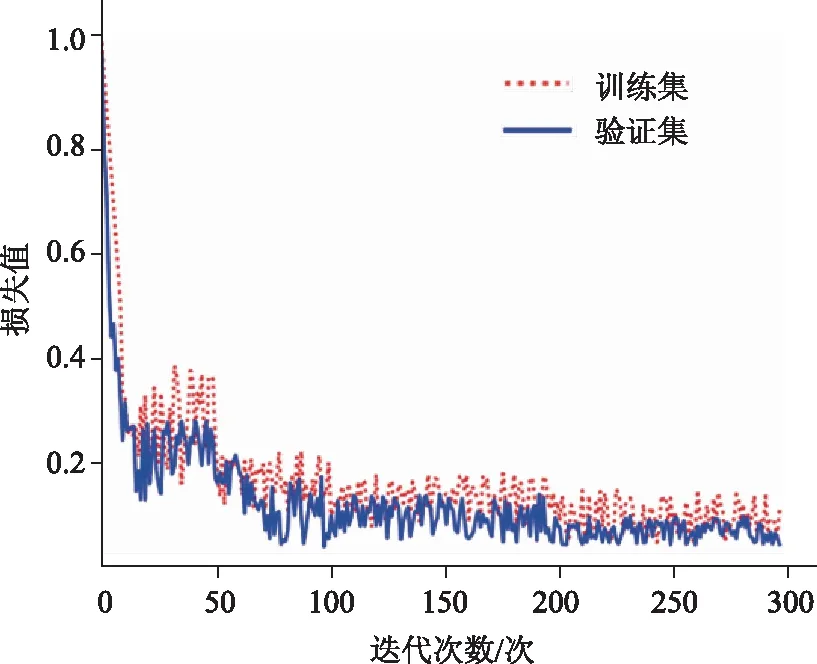
图8 训练损失变化曲线
由图8可以看出,训练过程损失在0到50迭代次数时迅速下降,最终趋于平稳。经过多次训练,发现损失曲线会在200迭代次数以后趋于平稳,因此选用300迭代次数进行训练,使得模型达到较好的训练效果。
2.2 评价指标的选择
为了验证模型的检测效果,选取了几种目标检测和分类领域的典型指标进行评估。对于分神驾驶行为检测和分类,注重检测精度和召回率,以及分类准确率。因此选择混淆矩阵,精确率(precision),召回率(recall)以及F1_Score对模型进行评估。式中,TP为预测正确,样本为正的数量,FP为预测错误,样本被预测为正,但样本实际为负数的数量,FN为预测错误,样本被预测为负,但样本实际为正的数量,F1为F1分数,评价指标的计算公式如下:
(1)
(2)
(3)
2.3 结果分析与对比
模型训练完成以后,在测试集对模型进行测试和评价。为了更好的评估模型的性能,使用各项评价指标对模型进行定量评估。如图9所示,是模型在测试集上进行测试得到的结果,通过混淆矩阵的形式进行展示。

图9 测试集分类结果混淆矩阵
通过观察检测结果混淆矩阵,误检和漏检的类型是其他驾驶行为,由于其他驾驶行为数据中包含多种动作,可能会出现与其他8种行为相似的动作。观察整体检测结果,模型表现出较好的效果,下面通过具体的数值指标进行分析。在以上检测结果的基础上计算各个种类的性能指标。经过计算,每个行为的检测精确率、召回率、F1分数以及对应的平均值如表2所示。
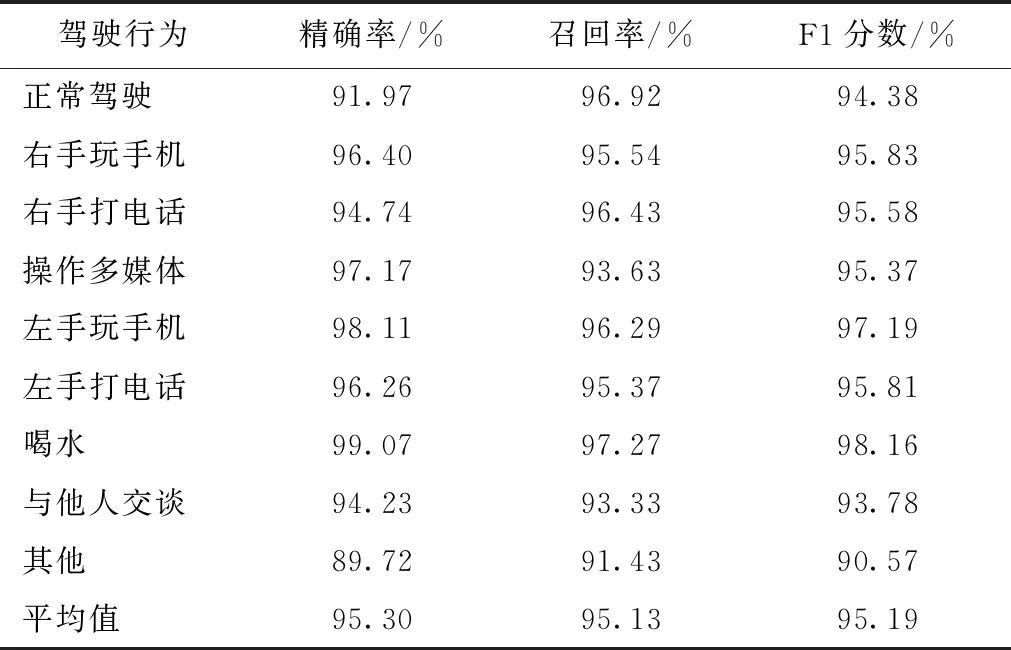
表2 九种驾驶行为检测评价指标
由表2中数据所知,正常驾驶和其他行为的检测精确率分别为91.97%,89.72%,这是因为某些动作特征可能不够明显造成的。同时,其他驾驶行为包含的动作种类较多,没有固定的特征,因此造成检测精度较低。模型在测试集检测的平均精确率为95.30%,平均召回率为95.13%,平均F1分数为95.19%,整体表现出比较好的检测效果。
为了验证分神驾驶检测模型的优势,本研究对一些流行的目标检测算法用相同的数据进行训练和测试。对比试验使用的方法有Faster-RCNN[18],SSD[19],YOLOv3,原始YOLOv5模型。各个模型检测结果平均指标如表3所示。
如表3所示,将5种方法在本研究的数据集上进行了试验,其中FPS是目标网络每秒可以处理多少帧。结果表明,本研究提出的分神驾驶模型检测精度明显优于Faster-RCNN,SSD,YOLOv3,对YOLOv5进行优化后,检测精度相对于YOLOv5也表现的更好。在检测速度方面,本研究方法比原始YOLOv5速度稍慢,造成这一结果的原因是网络在增加注意力机制后增加了推理时间,但是相比其他3种方法检测速度仍然表现更好,满足实时检测的要求。模型大小方面,本研究方法相对于其他方法更小。综合考虑各个方面,本研究方法在分神驾驶行为检测上具有优越性。
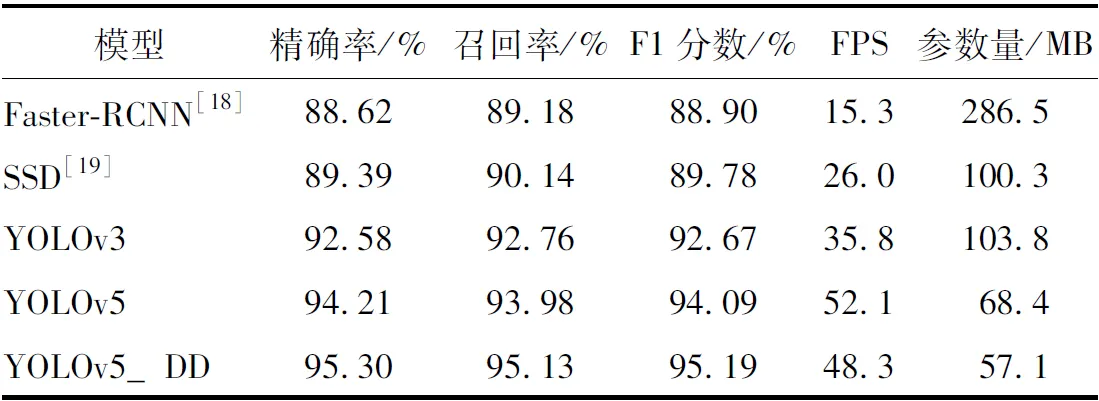
表3 各个检测模型测试平均指标对比
3 结论与展望
本研究针对驾驶人常见分神驾驶行为监测提出一种检测方法。在YOLOv5模型的基础上,针对分神驾驶行为检测问题进行了优化,主要在锚框选择部分和主干网络部分进行改进得到本研究的分神驾驶行为检测模型。对Kaggle危险驾驶行为数据进行再标注作为本研究的训练数据集,对模型进行优化训练。最终,通过试验测试和对比,表明本研究的分神驾驶行为检测模型具有更好的性能,同时可以到达实时检测的目的。
虽然本研究方法的检测性能表现出较好的性能,但仍然存在一部分问题。驾驶人在驾驶过程中可能会有更多的危险驾驶动作,本研究选用的数据只包含部分常见的类型。同时,本研究方法仅在实验室电脑进行了试验和测试。在接下来的研究中,将考虑对数据集进行扩充,同时将算法嵌入硬件设备,在实际驾驶过程中进行试验测试。
猜你喜欢
教育研究与评论(中学教育教学)(2023年9期)2023-10-31 17:28:46
信号处理(2022年11期)2022-12-26 13:22:06
计算机与生活(2022年11期)2022-11-15 16:17:48
计算机工程与科学(2022年8期)2022-08-20 01:39:22
中南民族大学学报(自然科学版)(2022年3期)2022-05-08 03:51:12
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
广东第二课堂·小学(2017年9期)2017-09-28 06:23:46
琴童(2017年4期)2017-06-14 22:56:12
