
基于随机游走的进化计算社区发现
2022-11-25 01:59韩存鸽陈展鸿吴俊杰郭昆
福州大学学报(自然科学版) 2022年6期
韩存鸽,陈展鸿,吴俊杰,郭昆
(1武夷学院数学与计算机学院,福建 南平 354300;2.武夷学院福建省茶产业大数据应用与智能化重点实验室,福建 南平 354300;3.福州大学计算机与大数据学院,福建 福州 350108 )
0 引言
现实生活中的许多复杂系统都可以建模为复杂网络,如社交关系、广告营销、蛋白质交互等.社区发现的目的就是将复杂网络中诸多节点划分为若干社区,使得同社区内的节点间连接较为紧密,而不同社区间的节点连接相对稀疏[1].社区发现技术现已应用在疾病预测、异常检测、商品推荐等各领域.
在复杂网络中找到最优划分已经被证明是一个NP-Hard问题,进化计算被认为是解决这类问题的有效方案.早期基于进化计算的社区发现方法Ga-net[2]、Meme-Net[3]都基于遗传算法,优化目标单一.2009年,Pizzuti提出的MOGA-Net[4]首次将多目标用于社区发现,随后多目标优化算法相继出现,2018年,Zhang等[5]提出RMOEA算法,将一致性较高的同社区节点规约成超级节点.2020年,Liu等[6]提出NE-PSO算法,采用多目标粒子群优化在嵌入空间搜索社区结构取得了不错的效果.但这些算法仅考虑了网络的结构,忽略了节点的属性信息.
在属性网络上,Li 等[7]同时优化属性余弦相似度与模块度,采用邻域修复策略提高社区划分的准确度.Pizzuti等[8]探讨了余弦相似度、模块度、社区分数等属性与结构指标的优化效果,给出 NSGA-II[9]在属性网络社区发现上较为优越的结论.Teng等[10]将社区标签视为节点基因,基于NSGA-II框架优化社区结构.Sun等[11]将进化计算与神经网络结合,采用神经网络解码出社区的邻位编码形式,并转换为社区划分.以上算法在社区评价阶段考虑属性,但现有工作都直接或间接基于邻位编码,导致进化过程中无法有效利用属性信息.
随机游走因具有较好地处理稀疏网络、提取高低阶结构信息的优点,在网络表示学习(network representation learning,NRL)中被广泛应用于获得节点的多阶近邻继而得到节点的嵌入向量.Perozzi 等[12]提出Deep Walk算法,通过与聚类算法结合进行社区发现.Node2vec算法[13]在DeepWalk的基础上对节点进行倾向性采样.Zhang等[14]提出ANRL模型,利用深层神经网络来获取结构信息和属性信息之间的复杂关系.Hou等[15]提出RoSANE模型采用概率转移矩阵进行随机游走.其中DeepWalk、Node2vec算法仅考虑拓扑结构,ANRL、RoSANE算法考虑了节点属性,但缺少对社区边缘度较小的节点的游走,造成社区边界识别较低,社区发现的精度不高.
针对上述问题,提出一种基于随机游走的进化计算社区发现算法(random-walk-based evolutionary community detection,RWECD).RWECD算法设计考虑了拓扑和属性随机游走的社区初始化策略,策略中重新定义游走概率,获取一组有偏随机游走序列;设计考虑拓扑和属性的节点嵌入向量更新策略,使得种群在每一代更新过程中充分利用结构和属性信息来进行启发式更新.并通过在真实和人工数据集上实验,验证了RWECD算法能够有效提高社区发现的精度.
1 RWECD算法
1.1 基本概念
定义1网络嵌入.复杂网络可以被建模为图G=(V,E,A),其中V={v1,v2,…,vn}表示n个节点的集合,E表示网络中边的集合,E={(vi,vj)|vi∈V,vj∈V,且i≠j}.A=[a1,a2,…,an]T∈R|v|×m为节点的属性信息矩阵,用来描述节点的属性信息.
定义2属性相似度矩阵.SA用于记录两个节点间属性相似度.对于单属性网络,如果节点vi和节点vj具有相同的属性,则SA中第i行和第j列的元素(i,j)设置为1,否则为0.对于多属性网络,SA中的元素(i,j)定义为节点vi和节点vj的属性向量的余弦相似度.


(1)

(2)
定义3嵌入空间的属性相似度.嵌入空间中的属性相似度矩阵SNE定义如下:

(3)

定义4社区属性相似度Sim.在嵌入空间,通过最大化如下函数保留二阶相似性.采用社区属性相似度作为社区的第一个目标函数,其值越大社区划分越好.定义如下:

(4)

定义5模块度函数Q.采用模块度作为社区的第二个目标函数,模块度定义如下:

(5)
其中:m为网络边数,A为邻接矩阵,节点i和j存在连接,Aij值为1;否则为 0.ki和kj表示节点i和j的度;函数δ(Ci,Cj)中,节点i和j同属一个社区,其值为 1,否则为 0.Q值越接近1,社区结构越显著.
1.2 RWECD算法框架
RWECD算法的框架如图1所示,整体可以分为编码表示及初始化、向量更新、输出社区划分3个阶段.在阶段1中,设计一种结合属性相似度的随机游走策略,基于该策略生成一组游走序列,采用邻位编码方式对游走序列进行编码,为每个节点选择一个合适的基因值,接着把其解码为基于社区标签的嵌入表示,执行随机初始化.在阶段2中,设计综合考虑拓扑和属性的节点嵌入向量更新策略,经过多次更新后,对更新的社区采用目标函数进行评价.在阶段3中,获取融合属性结构与属性的社区划分.

图1 RWECD算法框架Fig.1 RWECD algorithm framework
1.3 编码表示与初始化
在RWECD算法中,每个个体均由两部分构成,嵌入向量表示I={I1,I2,…,In∈Rn×d}和节点的社区标签L={C1,C2,…,Cn},其中d为嵌入维数,Ci表示节点Vi的社区标签.在进化计算的社区发现中,通常有邻位编码和标签编码两种方式.邻位编码根据网络拓扑结构对节点编码,节点的基因值必然是其结构邻居中的某个节点.假设网络中有三个节点1、2、3,节点1的基因值为2(1与2必须在结构上存在连接),那么节点1和节点2一定属于同一个社区.标签编码直接将社区标签作为节点的编码,如节点1、2的基因值为1,节点6、7的基因值为2,将基因值看作他们的社区标签,那么解码后节点1、2被分配到一个社区,节点6、7被分配到另一个社区.图2表示邻位编码和标签编码过程,其中图2(a)为邻位编码,图2(b)为标签编码.RWECD采用邻位编码与标签编码相结合的编码方式.

图2 邻位编码与标签编码表示法Fig.2 Adjacency coding and label coded representation
在RWECD中,为了得到相对较好的初始种群,在初始化过程中设计了一种结合属性相似度的随机游走方案,首先采用公式(6)获取游走概率生成游走序列Dwalki,接着根据游走序列Dwalki产生节点的邻位编码,最后对邻位编码进行编码转换得到每个节点的社区标签.在获取社区标签后,执行随机初始化,使得具有相同社区标签的节点在嵌入空间中距离更近.游走概率公式如下:

(6)

图3给出了一个基于上述随机游走方案生成游走序列的示例.

图3 初始化过程示例Fig.3 Example of the initialization process
图3(a)表示相似度矩阵,图3(b)表示利用随机游走生成的个体编码及编码转换,图3(c)和图3(d)表示初始化节点的嵌入表示.以节点2为例,此处游走步长为3.从得到的属性相似度矩阵可以看出,对于至少一维属性值相同的节点共有5个,即节点1、3、4、5和8.通过公式(6)得到的游走概率,这5个节点被选择的概率分别为0.097 5、0.235、0.215、0.078、0.08,最终确定节点2的下一个游走节点为节点3,依次计算最终游走序列为2→3→4→1,再取节点5,按照游走概率最后确定的游走序列为5→8→7→6.获取游走序列后根据基于节点的邻位编码确定每个节点的等位基因值.接着对个体进行编码转换,得到节点的社区标签.执行随机初始化,使得I的值在0到1之间随机初始化,从而使相同社区标签的节点在嵌入空间中距离更近,随后计算每个社区内所有节点表示向量的平均值,接着计算两两社区表示向量平均值的余弦相似度,对比预先设置的阈值,若余弦相似度大于这个阈值,则对这两社区进行合并.这种方式有效地利用了节点的属性信息,生成的初始化种群的质量相对较高.
1.4 向量更新
① 交叉及变异.在设计算法中应用了经典的模拟二进制交叉SBX算子[16].SBX特别适用于存在多个最优解的问题.对于变异算子,传统的算子如随机变异、高斯变异和多项式变异算子都适用于多目标进化计算.在本研究中,选择随机变异算子.
② 向量更新.若相应适应度函数值增加,合格节点将相继加入对应社区.因而,嵌入空间中每个合格节点的位置需要稍微向其所属的新社区偏移.从属性和拓扑两部分综合考虑更新向量,设计思想源于一个节点倾向于移动到距社区中心点近的社区,一个节点也更倾向于移动到新社区中度大的节点处,如社交网络中,一些度大的节点可以认为是较成功的人,其具有的影响力也较高.嵌入向量的更新如下式所示:

(7)
式中:Icenter是新社区中心节点的表示;Imax是社区中度最大的节点表示;β是控制移动范围的正参数.在本研究中设定β为0.3,嵌入向量更新可以看做节点在搜索空间做了一次位移.对生成社区划分使用公式(4)、(5)评价,Q值越接近1,社区属性相似度越大,搜索到的社区结构在拓扑结构和属性上越显著.
1.5 输出社区划分
节点社区划分经过编码表示及初始化、向量更新、社区划分3个阶段,社区划分如图4所示,图4(a)为网络空间嵌入表示,4(b)为社区标签.

图4 社区划分Fig.4 The community divided
1.6 算法伪代码
RWECD算法是在NSGA-II框架下实现的,其伪代码如下所示.

RWECD算法伪代码输入:G=(V,E,A);//属性网络,d:嵌入空间的维度,Genmax:最大迭代次数,Popsize:种群规模Pc:交叉概率,Pm:变异概率输出:社区划分L,网络表示I,//阶段1:基于随机游走的社区初始化(1)SA←Getsimilarity(G)//Getsimilarity()函数用于获取属性相似度矩阵SA(2)P←Initialpopu(SA,Popsize,d)//Initialpopu()函数用于创建初始种群//阶段2:向量更新(3)while(t 为了检验RWECD的性能,在人工和真实网络上进行实验,实验选取6个对比算法,DeepWalk、Node2vec是基于随机游走算法,BAGC[17]、SCI[18]、vGraph[19]是基于模型的算法,RMOEA是基于进化计算的算法. 采用LFR基准网络生成人工数据集,基于LFR 生成1组参数不同的网络D1来验证所提算法的性能.人工网络参数具体含义为:n、k、μ分别代表节点数、节点平均度、混合参数,kmax、Cmin、Cmax分别代表节点最大度、最小社区内节点数、最大社区内节点数,其余未说明参数设置为LFR工具默认值.D1网络参数为:n=1 000~5 000、k=20、μ=0.2和0.5、kmax=50、Cmin=10、Cmax=100. 表1 真实网络Tab.1 Real-world networks 实验选取6个真实数据集验证所提算法性能,具体包括:WebKB[20]中4个美国大学的计算机系交流网络Cornell、Texas、Washington、Wisconsin,以及两个不同领域的科学引文网络Cora[21]、Citeseer[22].表1给出了这些属性网络的具体信息: 采用标准互信息NMI和平均F1指标评价RWECD算法的性能.NMI定义如下所示: (8) 其中:CA、CB分别表示真实社区划分与算法检测社区划分;Nij表示同时被分配到CA中第i个社区与CB中第j个社区的节点数量;真实社区划分和检测的社区划分越相似,NMI的值越接近1,否则就越低. F1定义如下式所示: (9) 图5 向量更新参数β实验Fig.5 Vector update parameter β experiment RWECD算法中有一个重要的向量更新参数β,其对算法精度的影响结果如图5所示,实验采用 D1网络进行.结果表明,在不同网络规模上,RWECD精度相对稳定,当β=0.3时,在不同的网络上都取得最好的效果,随着β继续增大,精度开始下降.因此,后面实验中将参数β值设置为0.3. 图6~7显示了RWECD与对比算法在D1网络上的精度实验,其中图6为NMI精度实验,图7为F1精度实验.结果表明,在多数网络上RWECD算法精度优于对比算法,这是因为RWECD通过嵌入向量的更新策略,使得节点属性信息在进化过程中被有效利用,进而得到准确的社区划分.DeepWalk、Node2vec算法的精度也较高,这是因为虽然DeepWalk、Node2vec算法都是利用随机游走序列来捕捉网络中的结构,但其都有考虑高阶拓扑信息,所以在不同规模的网络上精度都较高.SCI算法采用社区成员矩阵和社区属性矩阵进行非负矩阵分解,因此其精度随网络规模的增大变化不大.RMOEA 采用节点规约策略将同社区的节点合并成超级节点以提高收敛速度,然而,在μ值较大的网络上,由于社区边界较模糊,这种策略可能会错误地合并不同社区的节点,从而导致算法精度较低. 图6 人工数据集上的NMI实验Fig.6 NMI experiments on artificial datasets 图7 人工数据集上的F1实验Fig.7 F1 experiments on artificial datasets 图8~9显示了RWECD算法与对比算法在各个真实网络上的精度实验,其中图8为NMI精度实验,图9为F1精度实验. 图8 真实数据集上的NMI实验Fig.8 NMI experiments on real datasets 图9 真实数据集上的F1实验Fig.9 F1 experiments on real data sets 结果表明,RWECD算法在多数网络中的精度效果明显,这是因为RWECD通过基于随机游走的初始化策略,获取初始种群的质量较高,因此能够更好地识别社区边界,提高社区发现的精度.从实验结果发现,虽然DeepWalk、Node2vec、RMOEA算法仅考虑拓扑结构,但在Cora、Citeseer网络上,RWECD算法精度低于DeepWalk、Node2vec、RMOEA算法,这是因为对于网络Cora、Citeseer,其拓扑结构对社区分辨的影响要强于属性,且属性相似度与拓扑相似度存在一定程度的背离. 在网络Cora、Texas及D1上进行RWECD迭代实验,实验结果为一组非支配解.实验过程如图10所示.图 10(a)、(b)、(c)、(d)分别表示在网络Cora、Texas、D1(μ=0.2与μ=0.5)上的迭代进化结果.图中不同颜色点代表不同子代的帕累托解集.由图10可以看出,每隔10代,在网络Cora、Texas上迭代至40代之前,优化指标Q和Sim都有明显提高,同时,帕累托前沿分散均匀,表明RWECD算法优化效果较明显.但在40~50代的迭代过程中,RWECD算法优化效果不太明显.这是因为当种群迭代至40代时,帕累托解集开始逐渐收敛并接近最优值.在模块度Q上,Cora结果优于Texas,表明Cora网络的拓扑信息较为明显,而在属性Sim上,Texas网络上的结果优于Cora,则表明Texas网络的属性信息较为明显.在D1网络上结果与网络Cora和Texas结果类似.不同之处在于,当μ=0.2时,RWECD在模块度Q上的结果优于μ=0.5.原因在于μ控制网络的复杂程度,值越小拓扑结构越简单,优化模块度Q值较高.在属性上,D1网络实验结果没有明显区别. 图10 迭代进化实验结果 针对属性网络社区发现问题,提出一种基于随机游走的进化计算社区发现算法.为了更好地识别社区边界,设计一种基于拓扑结构及属性信息随机游走的社区初始化策略,使游走方向偏向度小且属性相似度高的节点,可以获得相对较好的初始种群,能够准确地识别社区边界,从而提高社区发现的精度.为了在进化过程中有效利用属性信息,设计了考虑拓扑和属性的节点嵌入向量的更新策略,使得节点的属性信息能够在进化过程中被有效利用,节点在嵌入空间更新可理解为节点在搜索空间进行位移,在一定程度上扩大搜索的范围,提高社区发现的质量.通过在真实和人工数据集上实验,验证了提出的RWECD算法能够提高社区发现的精度.未来,将在现有工作的基础上设计一种新的解码策略来有效地表示重叠社区和相应的嵌入表示,尝试在没有任何先验知识的情况下自动确定社区的数量.2 实验结果与分析
2.1 实验数据集2.1.1 人工数据集
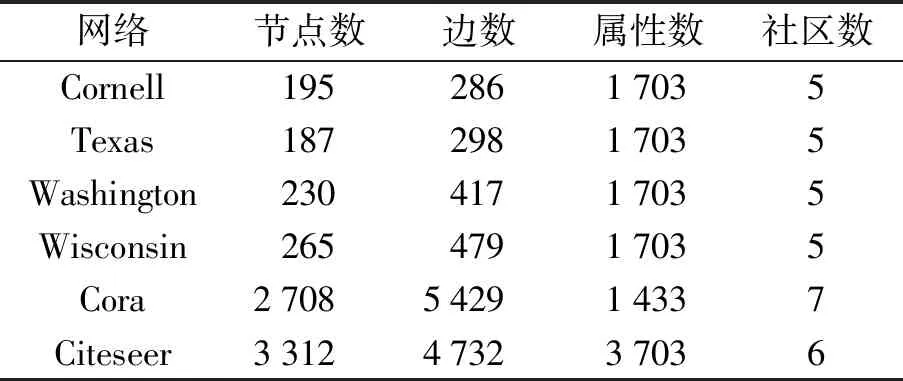
2.1.2 真实数据集
2.2 评价指标




2.3 参数实验
2.4 精度实验2.4.1 人工数据集实验结果


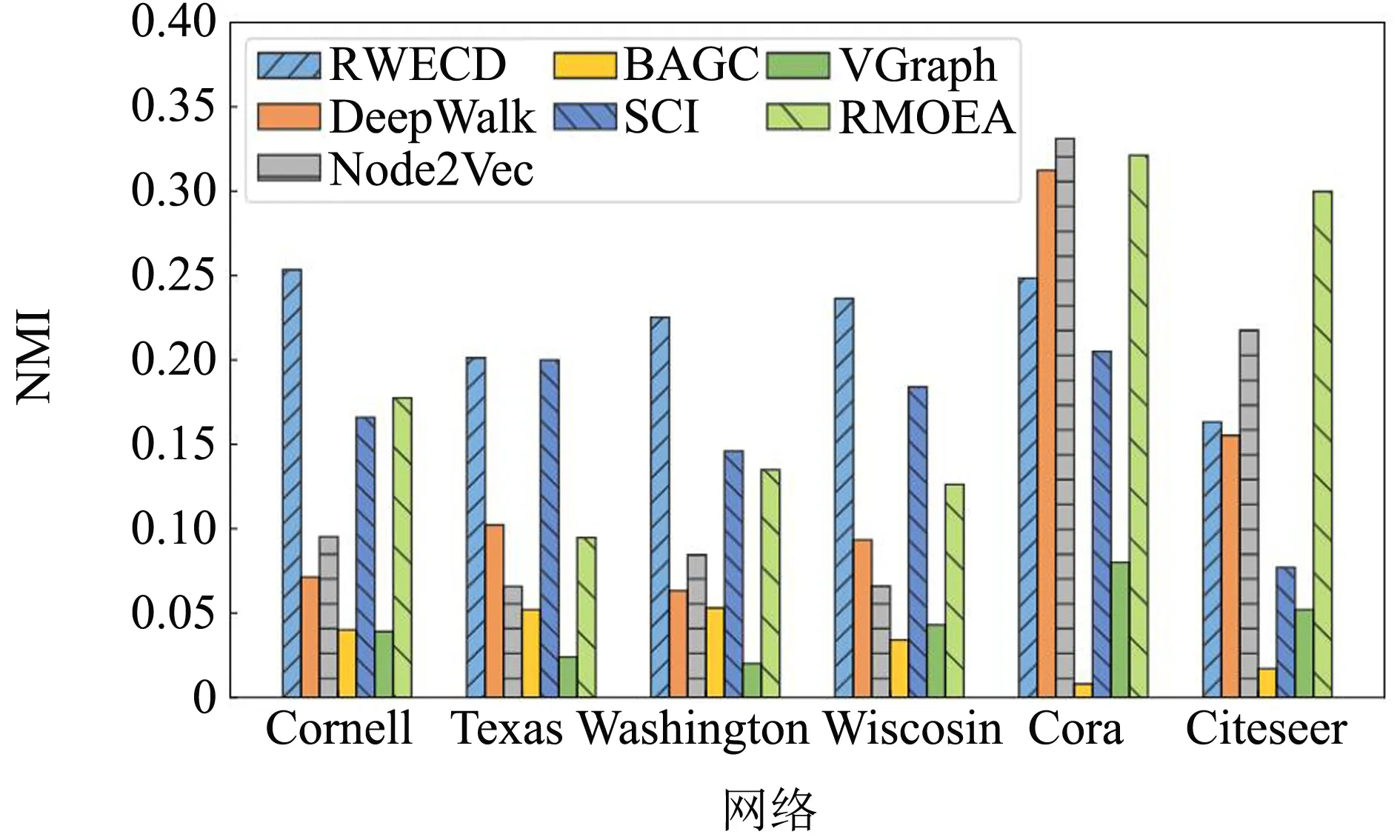
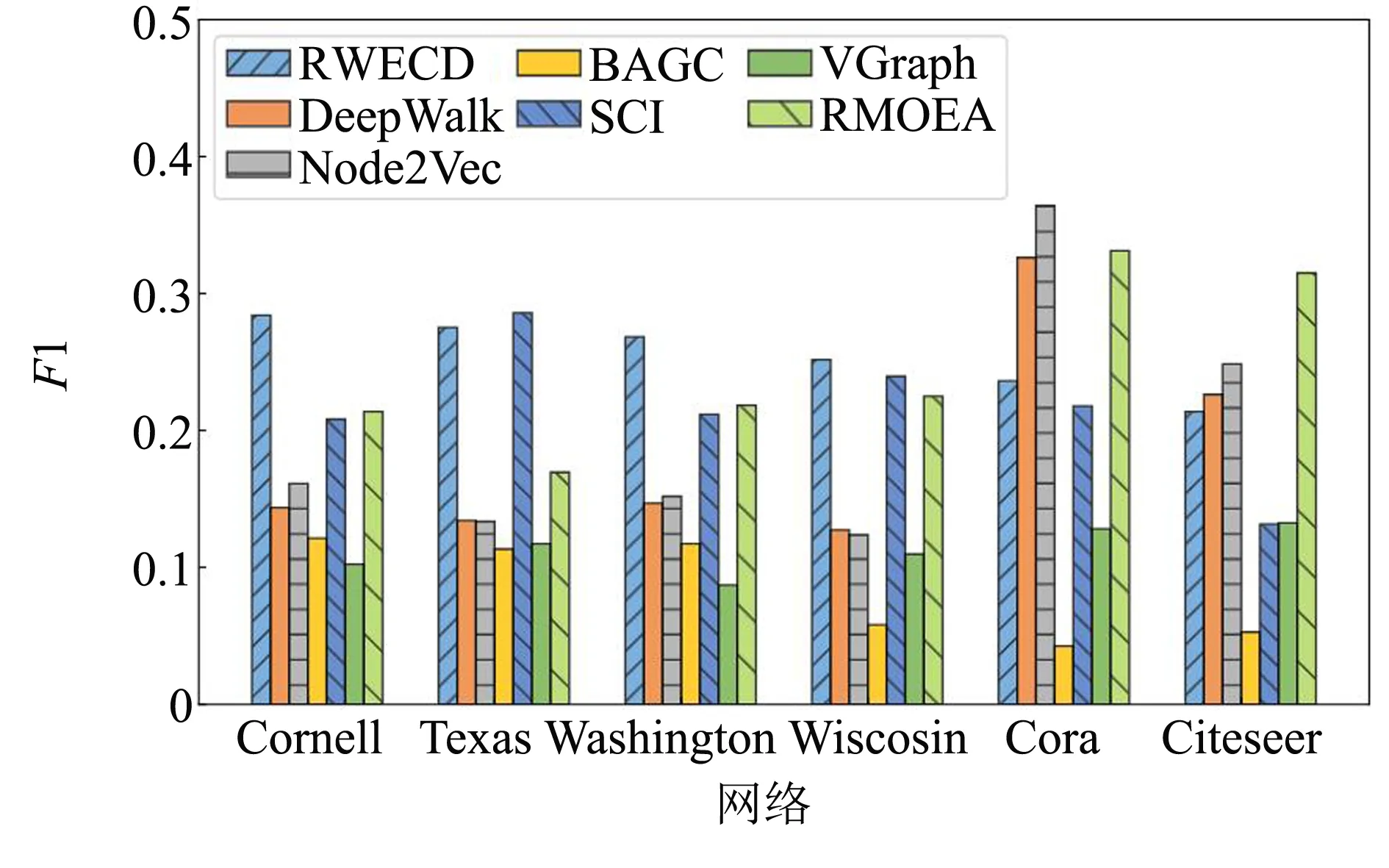
2.4.2 真实数据集实验结果
2.5 迭代进化实验


3 结论
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
疯狂英语·新读写(2018年3期)2018-11-29
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
