
基于改进主动学习的异常检测算法
2022-11-25 07:26陈伟荣
计算机工程与设计 2022年11期
蔡 颖,陈伟荣
(中国电子科技集团第二十八研究所 第一研究部,江苏 南京 210001)
0 引 言
异常检测作为入侵检测技术中的一个重要分支,基本思想是先建立正常的行为模式,再通过计算待检测行为与正常行为模式之间的偏离程度,来判断待检测行为是否异常。其优点是能够有效地检测出新的异常类型,缺点是较难建立精确描述正常行为的模型。目前,异常检测算法主要分为基于统计[1-3]的异常检测算法、基于特征选择[4-6]的异常检测算法、基于神经网络[7-9]的异常检测算法和基于数据挖掘技术[10-12]的异常检测算法4类。这些传统的异常检测算法往往需要大量的训练数据集,且训练数据集的质量对算法的效率也具有很大的影响[13]。
支持向量机(support vector machine,SVM)是研究小样本情况下,结构风险最小化的一类新型机器学习方法。传统的SVM作为有监督的学习方法通常用于解决分类和预测问题,但在实际应用中,对数据进行标签化需要耗费大量的时间和经济成本,此外,庞大的训练数据集也会导致算法消耗更多时间来建立模型。而主动学习则能有效减少所需的已标记样本的数量[14,15]。传统的主动学习在选择策略上,采用了与分类边界距离最小原则。通常而言,与分类边界距离越小的样本,越能影响分类边界的位置,因此包含的信息量越大。但仅考虑样本与分类边界间的距离,而忽视样本间的冗余,以及候选样本的代表性,会降低算法运行效率,从而增加不必要的时间和经济开销。
基于上述问题,在异常检测的应用背景下,本文考虑将主动学习加入到传统SVM算法中,同时对算法的选择策略进行优化,进而提出了一种基于改进主动学习的异常检测算法。该算法在采样过程中,综合考虑了样本与分类边界的距离,以及样本间的冗余情况,从而使得选取出来的样本更加合理。同时,通过调整样本选择数量,有效地减少了算法的迭代次数,进一步提高了算法效率。
1 主动学习
传统的SVM算法通过已标记样本,计算出能够将不同样本集合分隔的最优超平面,从而获得分类模型。基于传统SVM的异常检测算法,其效果和效率在很大程度上依赖于已标记样本的质量和数量。虽然在机器学习中,往往默认更多的数据将会带来更高精度的模型,但事实上,从数据质量的角度出发,可以认为所有数据并不都是平等的,即样本所包含的信息量并非都是相等的,因此并不是所有的样本都是对训练有价值的。与此同时,通过一定的人工验证和干预过程,则可以使得算法兼顾机器学习的速度,和人工分类的准确度。而主动学习就是这样一种思想下的机器学习框架。主动学习是指通过一定的选择策略,从候选样本集中选择信息量较大的未标记样本,经由专家标记后,作为训练样本来训练分类模型的过程。主动学习使得模型训练成为一个交互的过程,从而有效提高了已标记样本的质量。
主动学习的模型可以表示为:A=(C,Q,S,L,U), 其中C为分类器,Q为选择策略,S为专家,L为已标记样本集,U为未标记样本集。在主动学习流程中,首先按照选择策略Q, 从未标记样本集U中选择样本,经由专家S标记后,加入到已标记样本集L中,然后重新训练分类器C, 并迭代上述过程直到分类器C的准确度达到阈值。主动学习流程如图1所示。

图1 主动学习流程
由上可知,主动学习和被动学习的最大区别在于选择策略Q的加入,它允许从未标注的候选样本集U中选择下一个应标注的样本。基于传统主动学习的异常检测算法,充分利用了SVM的分类超平面仅与支持向量有关,而与其它向量无关的特质。因此,虽然在机器学习中,用于训练模型的数量规模越大,得到的模型精度越高,但引入主动学习后,则可以使用更少的数据即达到与随机抽样相同的精度。而在分类器一致的情况下,采用何种选择策略是主动学习效果的关键,即如何选择新的训练样本,将直接影响到算法整体的性能。
2 基于改进主动学习的异常检测
2.1 样本冗余度
基于传统主动学习的异常检测算法,其选择策略采用了与分类边界距离最小原则,即每次选择与分类边界距离最近的样本交由专家标记。这是因为样本距离分类边界越近,其类别不确定性越大,在机器学习的前提下,越容易被算法分错类别。而一旦分错,则可能会导致模型过拟合或算法收敛变慢。由此可见,与分类边界距离越近的样本,其包含的信息量越大,越可能改变分类边界的位置。因此,采用与分类边界距离最小原则作为选择策略,可以使得每次选取出来的样本,都是候选样本集U中对SVM的分类超平面影响最大的样本。但基于传统主动学习的异常检测算法,仅以样本与分类边界的距离作为选择策略,在计算简单的同时,也存在着样本信息冗余和收敛缓慢的问题。
主动学习在每一轮的迭代中,均选择了与分类边界距离最近的样本,作为待标记样本交由专家标记,因此存在相邻两次迭代过程中,选择的样本均为同一类别,并且彼此间距离极其相近的情况。在这种情况下,这两个样本虽然均为当前迭代轮次中,蕴含信息量最大的样本,但实际上,两者间却极为相似,后者则对分类边界的确定影响较小,这会导致专家待标记样本数量和算法迭代次数增多,造成人力和算力的浪费。
因此,为解决相邻两次样本选择过程中,相似样本所带来的冗余问题,本文引入了冗余度p的概念。对于未标记样本集U中的每一个样本xi, 定义其在算法的第k次迭代过程中,样本的冗余度pk(xi) 为
(1)
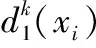
(2)
式中:Xi,Yi分别表示n维样本a,b第i维的值。
通过理论分析可得,未标记样本xi与分类器C分类边界的距离越小,xi包含的信息量越大,越应该被选取。同时,未标记样本xi在与已标记训练样本集L所含样本间余弦相似度的平均值越小,xi与L所含样本的冗余就越小,越应该被选取。而由式(1)可知,样本的冗余度和待选样本与分类边界的距离,以及待选样本与已标记样本间的相似度成正比,符合理论分析结果。综上可得,样本的冗余度越小,样本的价值越大,越应该被选取。
此外,传统主动学习中,每次仅选择一个样本进行标记和训练,导致了迭代收敛速度较慢。同时,如果当前迭代中仅选择的一个样本存在异常,并不具备当前数据集的代表性,则会使得分类边界偏离预期,丢失了候选样本的总体特征。此外,在实际应用过程中,要求专家逐次对按照选择策略Q,从未标记样本集U中选择出的仅单个样本进行标记,也是难以实现的。从算法时间开销和经济开销的角度考虑,应该尽可能减少标记轮数和迭代次数。因此,本文所提算法将按照样本的冗余度从低到高,在合适的范围内,适当增加每轮迭代过程中样本的选择数量。
2.2 算法描述
本文对基于传统主动学习的异常检测算法进行了选择策略上的优化。传统算法的选择策略采用了与分类边界距离最小原则,而如果相邻两轮迭代所选择的样本属于同一类别,并且特征相似,将会导致分类边界变化较小,徒增迭代次数。因此,本文引入了冗余度的概念,以冗余度最小原则作为选择策略,在计算样本与分类边界距离的前提下,通过选择与已训练样本间相似度更低的样本,作为待标记样本,并且适当增加样本选择数量,以达到减少算法迭代次数,提高算法运行效率的目的。基于改进主动学习的异常检测算法描述如算法1所示。
算法1:基于改进主动学习的异常检测算法
输入:未标记样本集U, 测试样本集T, 分类准确率P, 分类准确率阈值ω
输出:满足P≥ω的分类器C
(1)从未标记样本集U中选择一定量的样本,并正确标记,构造初始的已标记样本集L, 且L中正负样本至少各含一个
(2)利用L训练SVM分类器C
(3)基于C对测试样本集T进行分类,得到分类准确率P, 若P≥ω, 则跳转到(6),否则跳转到(4)
(4)计算U中样本的冗余度p, 并按p升序选取topN样本{α1,α2,…,αN}
(5) 正确标注 {α1,α2,…,αN} 后加入L, 跳转到(2)
(6) 返回C
3 实验数据处理
3.1 数据源
本文实验部分采用的数据集为KDD 99,它是1999年美国国防部高级规划署(defense advanced research projects age-ncy,DARPA)为知识发现与挖掘(knowledge discovery in database,KDD)竞赛提供的一个异常检测的标准数据集。美国林肯实验室模拟了一个典型的美国空军网络环境,期间通过仿真各种用户类型,以及各类网络流量和攻击手段,收集了9周时间的TCPdump网络连接和系统审计数据,从而创建了该数据集。这些采集的原始数据被分为7周时间的训练数据以及2周时间的测试数据两个部分,其中前者包含约500万条网络连接记录,即TCP数据包序列,而后者包含约300万条测试数据[16,17]。
KDD 99数据集中的每一条网络连接记录由41个特征组成,这41项特征可以分成4大类。其中TCP连接基本特征9种,包含了一些连接的基本属性,如连接持续时间、协议类型、连接状态和传送的字节数等;TCP连接的内容特征13种,包含例如登录失败次数、root用户访问次数和访问文件次数等,此类特征包含了网络攻击的内容特征;基于时间的网络流量统计特征9种,包含了当前连接记录与之前一段时间内的连接记录之间存在的关系,潜在反映出网络攻击在时间上的关联性;基于主机的网络流量统计特征10种,作为基于时间无法统计出的网络流量特征的补充。数据集的每条网络连接记录具有一个类别标签,表明该条数据是正常(normal)数据或攻击(attack)数据[18]。
为弥补传统算法的不足,基于改进主动学习的异常检测算法综合了样本与分类边界的距离以及样本间的相似度,从而引入了冗余度的概念,对传统算法的选择策略进行了优化。而为了计算样本冗余度,首先需要对实验数据进行数值化和向量化等预处理,此外,将基于卡方检验的思想,对数据集中的数据进行特征选取,以进一步提高算法效率。
3.2 数据预处理
3.2.1 数值化处理
由于KDD 99数据集中存在着非数值型数据,因此需要对非数值型数据进行数值化处理。本文的做法是先确定非数值型数据的取值空间,然后将取值空间中的每一个取值用互不相同的数值表示,最后将非数值型数据用对应的数值进行替换。例如:特征protocol_type表示的是连接的协议类型,它的取值空间为 {TCP,UDP,ICMP} 共3种,则将TCP赋值1、UDP赋值2、ICMP赋值3,最后在原始数据中进行替换。
3.2.2 标准化处理
经过数值化处理之后的数据,往往还不能直接用来进行实验操作。由于数据不同特征之间的数量级别不同,还需要对不同量纲的数据进行标准化和归一化处理。标准化处理是改变一个变量取值的表示方法,使得变量的变化范围变换到一个指定的量程内。标准化处理使得不同量纲的特征对数据的影响因素对等,消除了大数量级特征掩盖小数量级特征作用的隐患。
若AVG表示各特征值的平均值,STAD表示各特征值的平均绝对误差,xi表示当前特征值,n表示KDD 99数据集数据量,则数据标准化处理步骤如下:
(1)计算特征值的平均值
(3)
(2)计算特征值的平均绝对误差
(4)
(3)计算标准化后的特征值
(5)
3.2.3 归一化处理
此处归一化的目的是让数据压缩在 [0,1] 范围内。数据归一化处理步骤如下:
(1)将数据的变化范围限制在 [0,1] 之间,设定特征值取值上限为Vup=1, 取值下限为Vlow=0;
(2)将同类特征的特征值归为同一组;
(3)确定同一组中特征值取值的最大值Vmax与最小值Vmin;
(4)对每一个取值进行归一化操作
(6)
代入数据变化范围设定,式(6)可以化简为
(7)
其中,valuei是标准化后的特征值,value′i是经过归一化处理之后得到的特征值。
3.2.4 特征选取
模型的构建依赖于数据集的特征,但训练集特征维度越高,训练模型的时间开销也会随之增大。此外,高维度特征可能包含的无关特征及冗余特征,也会使得分类器的性能下降。因此通过特征选取去除无关特征及冗余特征,可以有效提高分类器的训练效率。
本文基于卡方检验的思想,对KDD 99数据集中的数据进行特征选取。卡方检验应用在数据特征选取当中,可以检验数据的特征与数据的类别之间的独立性。即,首先假定某数据特征与数据类别之间是无关的,然后对样本数据进行统计计算,得到理论值与实际值的偏差。如果偏差的值小于设定的阈值,则认定该数据特征与数据所属类别之间是相互独立的,那么在进行模型训练时,则可以将该特征删除;反之,偏差的值大于设定的阈值,则认定该数据特征与数据所属类别之间是相关的,应予以保留。本文实验中,通过设定偏差阈值为10,经过特征提取之后,从41个特征中筛选得到了21个相关度和差异性更高的特征,包含连接状态(flag)、误分段数量(wrong_fragment)、超级用户权限设置(root_shell)、过去两秒内目标主机相同的连接中出现SYN错误的百分比(serror_rate)和前100个目标主机相同的连接中出现SYN错误的百分比(dst_host_serror_rate)等,并且保留的21个特征也已涵盖了KDD 99数据集的4大类特征。
4 实验结果及分析
4.1 实验设计
本文从KDD 99数据样本集中选取了10 000条数据作为训练样本集,311 029条数据作为测试样本集。为了更加真实地模拟网络的实验环境,实验中采用了随机选取的方法,且样本集均经过相同的数据预处理步骤进行处理。样本集的数据组成情况见表1。

表1 两种候选集样本的组成情况
为了分析算法的有效性,实验中分别用基于传统SVM、基于传统主动学习以及本文提出的基于改进主动学习的异常检测算法,在相同条件下进行实验,观察并比较不同算法结果。其中,基于传统SVM的异常检测算法称为T-SVM,基于传统主动学习的异常检测算法称为AL-SVM,基于改进主动学习的异常检测算法称为PAL-SVM,并且,在选择样本时,T-SVM采用随机选取策略,AL-SVM采用传统选择策略,本文提出的PAL-SVM采用冗余度策略。实验中,SVM使用RBF函数作为核函数,其中设定参数gamma=0.5, 参数C=1000, 初始化时使用相同的已标记训练样本集L, 并且L中已包含一定量的正常样本和异常样本。
4.2 实验结果分析
在样本选择数量为1的前提下,基于传统SVM的异常检测算法、基于传统主动学习的异常检测算法、基于改进主动学习的异常检测算法的分类准确率随已标记样本数量变化情况的折线如图2所示。

图2 分类准确率随选择策略的变化
由图2中可知,在分类准确率达90%时,基于传统SVM的异常检测算法需要已标记样本约3580个,基于传统主动学习的异常检测算法需要已标记样本约530个,而本文所提的基于改进主动学习的异常检测算法仅需要已标记样本约20个即可达到相同的分类准确率。此外,在达到收敛后,本文所提的基于改进主动学习的异常检测算法的准确率约为92.04%,基于传统SVM的异常检测算法的准确率约为90.88%,基于传统主动学习的异常检测算法的准确率约为90.89%,由此可见,本文所提算法的准确率也为三者最优。
结合实验结果分析可得,基于改进主动学习的异常检测算法通过引入冗余度概念,所选取的样本相较于传统算法,所含信息量更大,对确定分类边界影响更为显著,因此在与传统算法取得相同分类准确率的前提下,需要的已标记样本数量更少,可以更好地适用于小样本情况下的分类问题。
为了验证样本选择数量对本文所提的基于改进主动学习的异常检测算法性能的影响,在相同样本集上进行了进一步实验。分类准确率随样本选择数量的变化结果见表2。

表2 分类准确率随样本选择数量的变化/%
以N表示样本选择数量,由表2可知,当模型分类准确率达90%以上时,若N∈{1,2,3}, 则需要3次迭代,而当N∈{4,5,10,20} 时,仅需要2次迭代。由此可知,每次迭代时样本选择数量越多,模型可以获得的数据特征越多,对分类边界的确定越有益。而当模型分类准确率稳定在92%以上时,N=5和N=10时算法所需的迭代次数最少,均约3次迭代,并且算法的准确率也均高于其它样本选择数量下的算法准确率。
进一步,在N=5和N=10时样本冗余度随迭代次数的变化结果如图3所示,其中横坐标表示迭代次数,纵坐标表示样本的冗余度。

图3 冗余度随样本选择数量的变化
由图3可知,在算法初期随着迭代次数增加,选择的待标记样本与已标记样本冗余度逐渐减小,表明此时选择的待标记样本越具有差异性,对分类边界的确定越有价值。而当算法趋于收敛时,样本冗余度逐渐增大,表明此时模型的分类边界已经趋于稳定,符合理论知识。同时,当N=5时,算法从训练至收敛的过程中,样本冗余度随着迭代次数增加而逐渐增加。而当N=10时,在训练中,其选择的待标记样本与已标记样本冗余度基本均高于N=5时的冗余度,表明当样本选择数量持续增大超过一定的范围后,待标记样本数量过多,并非其中的每一个样本都具备差异性,因此导致了样本冗余度增大。并且当N=10时,随着迭代次数增加,其样本冗余度存在忽大忽小的情况,表明此时选取的待标记样本近乎随机抽取的效果。综上所述,综合考虑算法的准确率和训练开销,当样本选择数量设置为5时,本文所提的基于改进主动学习的异常检测算法性能最优。
结合实验结果分析可得,样本选择数量越多,模型稳定需要的迭代次数越少,但当样本选择数量过多时,模型训练的无用数据变多,分类准确率达到稳定的速度反而变慢。由此可知,在一定范围内增加样本选择数量,能够有效减少算法迭代次数,提高收敛速度。而当样本选择数量超过一定阈值后,冗余样本数量增多,在迭代次数相差无几的情况下,反而会降低每轮迭代中算法的训练速度,降低算法运行效率。
综上所述,本文提出基于改进主动学习的异常检测算法,综合考虑了样本与分类边界的距离,通过定义样本间的冗余度和调整样本选择数量,提升了样本选择的有效性,减少了迭代次数,并且实验结果表明,相较于传统算法,本文所提算法收敛更快,在达到相同分类准确率的前提下,需要的样本数量更少,而在算法收敛后,达到的分类准确率也更高,因此性能更佳,效果更优。
5 结束语
本文提出的基于改进主动学习的异常检测算法,在传统SVM的基础上结合了主动学习的思想,针对传统的选择策略仅考虑样本与分类边界间距离,而导致运行效率较低的问题,通过综合定义样本间的冗余度和调整样本选择数量,对传统的选择策略进行了改进优化。实验结果表明,本文提出的基于改进主动学习的异常检测算法相较于传统算法所需样本数量更少,算法准确率更高,适当增加样本选择数量减少了算法迭代次数,有效地提高了算法的运行效率。而针对本文尚未对不同大小样本集的样本选择数量进行定量分析的不足,将在后续研究中进一步探明。
猜你喜欢
运输经理世界(2022年1期)2022-09-20
儿童时代·幸福宝宝(2021年11期)2021-12-21
小学科学(学生版)(2021年4期)2021-07-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
建材发展导向(2020年23期)2020-12-31
现代装饰(2020年4期)2020-05-20
证券法律评论(2018年0期)2018-08-31
中国交通信息化(2018年5期)2018-08-21
