
基于LSTM的辐射源个体识别技术分析
2022-11-25 03:34张文君张正位
舰船电子对抗 2022年5期
张文君,张正位
(1.中国船舶集团有限公司第八研究院,江苏 扬州 225101;2.苏州中材建设有限公司,江苏 苏州 215300)
0 引 言
随着科学技术的飞速发展,现代战争已经从冷热兵器时代跨入了信息化时代,战争的形态也就由现实可见的自然空间拓展到了不可被直接感知的电磁网络空间。因此,在电磁网络空间的战争中,电子侦察一直是研究的重点,它一方面是为了获取更多更全面的信息,另一方面是为了能从获得的信息中分析出敌方的威胁程度。而这其中涉及到的辐射源的个体识别问题,成为了研究者们的重点研究对象[1-3]。所以,如何从复杂的数据中获取并识别出准确的信息是最终目标,也是目前该领域亟待解决的难题。
辐射源个体识别在电子对抗领域起着非常重要的作用,也是雷达侦察系统的重要组成部分。其数据的获取主要是针对特定频段的某一段特定信号进行采集,而采集到的数据也只是目标的一部分,并不能完全反映目标的特性,所以采用单一技术手段对其进行分析是不全面的。
传统的辐射源个体识别是将采集到的信息与己方已有的辐射源个体进行匹配的技术。即首先必须有一个特征库,当采集到信息之后,经过处理,与已有的特征库进行比较、匹配,判断其属于哪一个辐射源个体,并尽可能判断其属于哪一类设备,分析该设备所具有的特点、功能、威胁程度等参数。但随着雷达技术的迅猛发展,电磁空间环境越来越复杂,新功能的雷达以及多类型的雷达信号样式也越来越丰富,各雷达设备的信号源个体调制方式也更加灵活,参数变化多样,其发射的信号各有特点,对于某一类同种设备其本身之间所发出的信号也有差异,同时这些多样的信号充斥在周围空间中,形成了数量巨大的混合信号,也就增加了信号采集和个体识别的难度。所以,构建一种可以从复杂环境中准确识别辐射源个体的模型是现阶段非常重要的任务。本文将从雷达辐射源个体识别的特征参数提取和雷达辐射源的个体识别分类进行分析讨论,并针对目前所拥有的技术缺点进行补充改进,提高雷达辐射源个体识别效率。
1 辐射源特征参数提取
传统的辐射源识别是提前对不同信号进行收集分类,形成一个完整的标准库。在实际应用中,对于采集的信息先进行预处理,将其通过时频变化,提取人为设定的一些特征与标准库进行对比匹配,则可以判断其属于哪一类型的辐射源,流程如图1所示。其中一个主要的环节是特征提取,与生物学中的指纹相似,因此也可称为指纹特征。而一般辐射源特征提取的都是信号物理层特征,又称为物理层识别[4]。在提取过程中,选择哪种特征来区分不同个体是非常重要的,传统上主要是通过提取暂态特征和稳态特征进行工作。

图1 传统辐射源识别流程
1.1 辐射源指纹特征分类
稳态特征一般容易获取并且稳定,实用性较强。它是指系统在稳定的工作状态下,信号自身所携带的特征。通常这类特征提取方法有:基于频率源的特征提取[5];基于噪声的特征提取[6];基于调制参数的特征提取[7];基于杂散特性的提取[8]等。在这些已成熟的方法中,基于杂散特征提取的方法性能较其他方法的性能更好,更具有普适性。针对杂散识别一般会用到高阶统计量、谱相关和小波变换等方法,但是在具体应用中,一般都是尽可能多地提取特征,目的是更好、更精准地识别出个体类别。总的来说,一般提取的指纹特征可以总结为以下3类[9]:信号统计参数、信号变换域、辐射源非线性的特征,其具体特征如图2所示。

图2 辐射源特征提取分类
暂态特征是指系统在工作中非稳定状态下的非线性特征,因其出现的条件不稳定,持续时间短,因此,对于完整信号的获取比较困难,外部噪声干扰、环境等因素也会导致提取特征出错,所以在工程领域利用暂态特征来进行个体识别的要求较高,很多研究者会放弃对该方向的研究。
1.2 辐射源特征提取方法
在上述辐射源特征提取分类中采用的特征提取方法,其大概可以总结为两大类:一类是传统的基于确定特性的统计特性的特征提取方法;一类是基于目前机器学习和深度学习等技术为主的自动特征提取方法。
基于统计特性的提取方法主要是人为标注所需要的具体特征,然后采用不同算法对其进行处理来获得。常用的性能较好的算法有基于信号的高阶谱、双谱、小波包分解等变换域方法。比如高阶统计量中的双谱,其能够在信号处理中消除高斯白噪声对源信号的影响,同时能够对辐射源个体的细微特征进行有效表征,但它也会造成数据的“维数灾难”,因此需要对其进行降维处理。常用的降维方法有:轴向积分双谱法[10-11](AIB)、主成份分析[11](PCA)、矩形积分双谱[12](SIB)和选择双谱[13]等,每种降维方法都有着各自的优缺点,在实际应用中,一般会根据实际需求来选择最适合的降维方法。
基于统计特性提取特征方法的缺点是部分算法需要提前知道信号的先验概率,单一特征的使用不能反应整个辐射源个体的信息,某些特征在实际应用中会受到外界环境或者其他噪声的影响,对于相似度非常高的辐射源个体可能会提取不到其异常特征,或某些算法只是针对某一个或者部分特征,不具有普适性,也不适用于如今复杂环境中的多辐射源个体识别,也就导致不能准确地识别出辐射源个体。所以为了解决这些问题,研究者们逐渐采用机器学习和深度学习技术来解决辐射源个体识别问题,并取得了一定的成绩。
随着机器学习技术的发展,很多研究者将其应用在辐射源个体识别中[14],可以提高工作效率,并在处理非线性数据上有一定的优势。传统的机器学习有决策树、k近邻法(KNN)、支持向量机(SVM)等等。如对于线性问题,采用SVM算法可以构建1个超平面对数据进行划分,若遇到非线性问题,则可以采用核函数将数据映射到高维空间再进行分类识别。在此基础上,将传统的特征提取与机器学习相结合,如通过小波变换提取特征与SVM相结合来实现辐射源的个体识别[15],其结果表明在有噪声的环境中模型间差异较小的情况下,通过SVM计算类间分离度,选出最优的小波组构成特征向量,获得了较优的效果。
机器学习一般也是配合常用的特征提取技术使用,未曾真正做到自动特征的提取;而深度学习则是完全可以根据其源数据自动提取特征,不需要人为的标注特征,正是因为其方便性和处理结果的高识别率,所以在各领域倍受欢迎,如图像识别[16]、语音识别[17]和机器翻译[18]等领域均有重大突破。现如今也有研究者将深度学习应用于辐射源个体识别,通过其自动提取辐射源的特征来构建相应的模型进行个体识别。如文献[19]采用了深度置信网络(DBN)训练个体识别模型,然后对载频特征、调制参数以及互调干扰特征进行了分类识别,验证了模型的可行性;如采用卷积神经网络[20](CNN)自动提取特征,通过反向传播修正网络模型的参数,实现对信号特征的智能化提取。
所以,基于机器学习的辐射源个体识别方法又可以总结为以下几类[21]:基于传统机器学习的辐射源识别方法,包括决策树、SVM等;基于神经网络的辐射源识别方法,主要包括有BP神经网络、RBF神经网络和向量神经网络等;基于集成学习的辐射源识别方法,包括基于并行方式的Bagging方法和基于串行方式的Boosting方法;基于深度学习的辐射源识别方法,主要有CNN、DBN、稀疏自动编码(SAE)[22]和长短时记忆(LSTM)等[23]方法。应用深度学习技术来进行辐射源个体识别是一种趋势,可以解放劳动力,并能实现个体细微特征的提取,容易在个体识别上获得比传统方法更优的结果,同时其训练好的识别模型可以适用于其他设备,具有良好的普适性。
2 基于LSTM的辐射源个体识别
基于传统的辐射源个体识别技术主要分为2个步骤:一个是特征提取;一个是针对提取的特征进行识别分类。但是这种方法未能考虑到辐射源数据的时序性,其数据在产生过程中具有时序性,因此在被采集的过程中也具有时序性。正是考虑到数据的时序特性,所以当其被分段研究时,数据间的时序特性就会被破坏,导致个体识别时缺少了部分特征,丢失了数据之间的关联特性,降低了个体识别的准确率。因此分阶段讨论的方法已经很难准确解决现阶段复杂环境中的辐射源个体识别问题,需要找寻一种可以从整体上解决该问题并具有普适性和高准确率的方法。
在近些年的研究中,深度学习技术逐渐应用到该领域,如最基本的深度置信网络和卷积神经网络都在该领域有所应用,并取得了不错的成绩。这些深度学习模型的使用采取了自动提取特征并进行识别分类的方法,同时考虑到数据的时序性,决定采用处理时序性问题较好的模型循环神经网络(RNN)和长短时记忆(LSTM)神经网络[24-26],在序列预测和标记任务中已经证实了该方法的优势。RNN是一种输入为序列数据的结构模型,并且其所有的节点单元都是按照链式连接的一种递归神经网络,该模型具有记忆功能,并可以共享参数,能非常高效地对非线性时序特征进行学习,这可以很好地处理具有时序关系的问题。但因为RNN是基于BP神经网络的,所以在每次反馈时都有信息损失,当反馈时间过长,损失信息达到一定量时,初始状态的信息就会退化,出现梯度消失[27],因此有了LSTM模型,其可以解决RNN出现的梯度消失问题。
2.1 LSTM算法
LSTM使用了特殊的神经元来保存并传递长时间的信息,主要是在RNN的基础上加入了“门单元(gate)”,来控制特征信息的流通或阻隔。比如在t时刻需要判断1条雷达信息的所属类型,这时刚好t-n时刻有1个与之对应的特性,此时就可以将该t-n时刻的符号特征传递过来,做出有效判断。整个LSTM由一系列的LSTM单元构成,有4个神经网络层,其以一种非常特殊的方式进行交互,链式结构如图3所示。

图3 LSTM结构图
图3中,ft叫做遗忘门,表示1条雷达目标信号序列中上一个状态Ct-1的哪些特征被用来计算当前的状态Ct。其中ft是一个向量,向量的每一个元素都位于[0,1]之间:
ft=σ(Wf·[ht-1,xt]+bf)
(1)
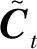
it=σ(Wi·[ht-1,xt]+bi)
(2)
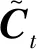
(3)
该候选值向量会被加入到当前状态中,it决定候选值向量的更新,ft确定需要保留或丢弃的信息,得到最终信息:
(4)
最后,输出门决定了最终输出的是哪些信息:
Ot=σ(W0·[ht-1,xt]+b0)
(5)
将通过的数据输入到tanh层中进行处理,输出一个[-1,1]的数值,并将其与输出门进行点乘,得到隐节点的输出ht:
ht=Ot·tanh(Ct)
(6)
当训练好LSTM时,发现门的值绝大多数都非常接近于0和1,其中⊗是LSTM重要的门机制,表示ft和Ct-1之间的单位乘的关系。通常会采用sigmoid函数作为激活函数,它的输出是一个介于[0,1]之间的值,但是也可以采用其他的激活函数如relu,softmax等,不同的激活函数输出范围不同。
信号处理和特征提取可分为时域、频域、联合时频域等其他脉内信息。因此,从以上这些维度或其他维度中尽可能获取信号本身的特征,可以更深地挖掘到信号之间的内在信息,使得辐射源的个体识别更加精准。
由于辐射源数据的采集过程和数据本身之间都是具有时序关系的,所以在对部分数据进行分析时需要考虑其数据前后的关联关系。因此,采集数据必须要尽量完整,其次对采集完的数据进行预处理,包括清洗、补充、归一化等等,基于LSTM的辐射源个体识别的算法流程如图4所示。
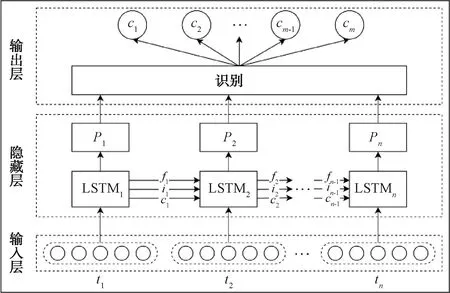
图4 基于LSTM的辐射源个体识别算法流图
2.2 基于LSTM的辐射源个体识别模型
该网络模型由输入层、隐藏层和输出层三部分组成。首先是将采集到并预处理好的雷达目标数据进行特征提取构建行为链,用N元组(X,T,A,W,F,…,C,O)来描述和分析不同属性特征之间的关系,元组中的每个属性元素就是1个行为,所有的行为构成1条行为链。其中X表示某一条特定的信号,T表示脉冲到达的时间集合,A表示目标信号到达角度的集合,W表示脉冲宽度的集合,F表示目标载频信息的集合,C设定为该目标信号可能产生的结果集合,O是与该信号相关的属性的集合,等。可以获得但不限于如下的特征:脉冲到达时间(TOA)、脉冲幅度(PA)、脉冲宽度(PW)、载频(RF)、到达角(DOA)、脉冲重复周期(PRI)、天线扫描周期(ASP)、最大强度值数量(NI)、3 dB峰值数量(NP)、角度对应最大幅度(AMM)、中值滤波瞬时频率分布的标准偏差(WMF)、最大谱变化(MSV)等。将构建好的每一条行为链按时间顺序输入到LSTM网络中的输入层,然后到隐藏层经过多个单元LSTM结构对其进行特征提取,提取到的信息不断向后流动,经过多个隐藏层的特征提取最后到达输出层,输出层根据内部关联将其分类得到最后的识别个体。在整个训练过程中,不断通过学习更新每个单元的参数,使其在下一个阶段得到的数据更为准确,最后当到达输出层时可以得到最好的分类结果。
这种LSTM深度学习结构模型具有很强的学习泛化能力和预测能力,所以在实际应用中检测辐射源个体时,可以根据部分数据推断出所属类型,即使遇到未在训练过程中出现的数据,也能根据训练好的模型给出较为合理的结果,所以也具有良好的普适性。
3 试验及分析
实验数据集采用仿真数据,总共8组,仿真总时间为1 s,其具体参数如表1所示,包含频率、脉冲重复间隔、幅度、脉宽、方位和俯仰等特征的具体参数值以及每一类别数据仿真得到的数据量,仿真得到共31 331条数据,其中每组数据的数量分布如图5所示。同时选取了前350条数据对7个类型参数分别可视化,如图6所示。
表1 仿真参数设置
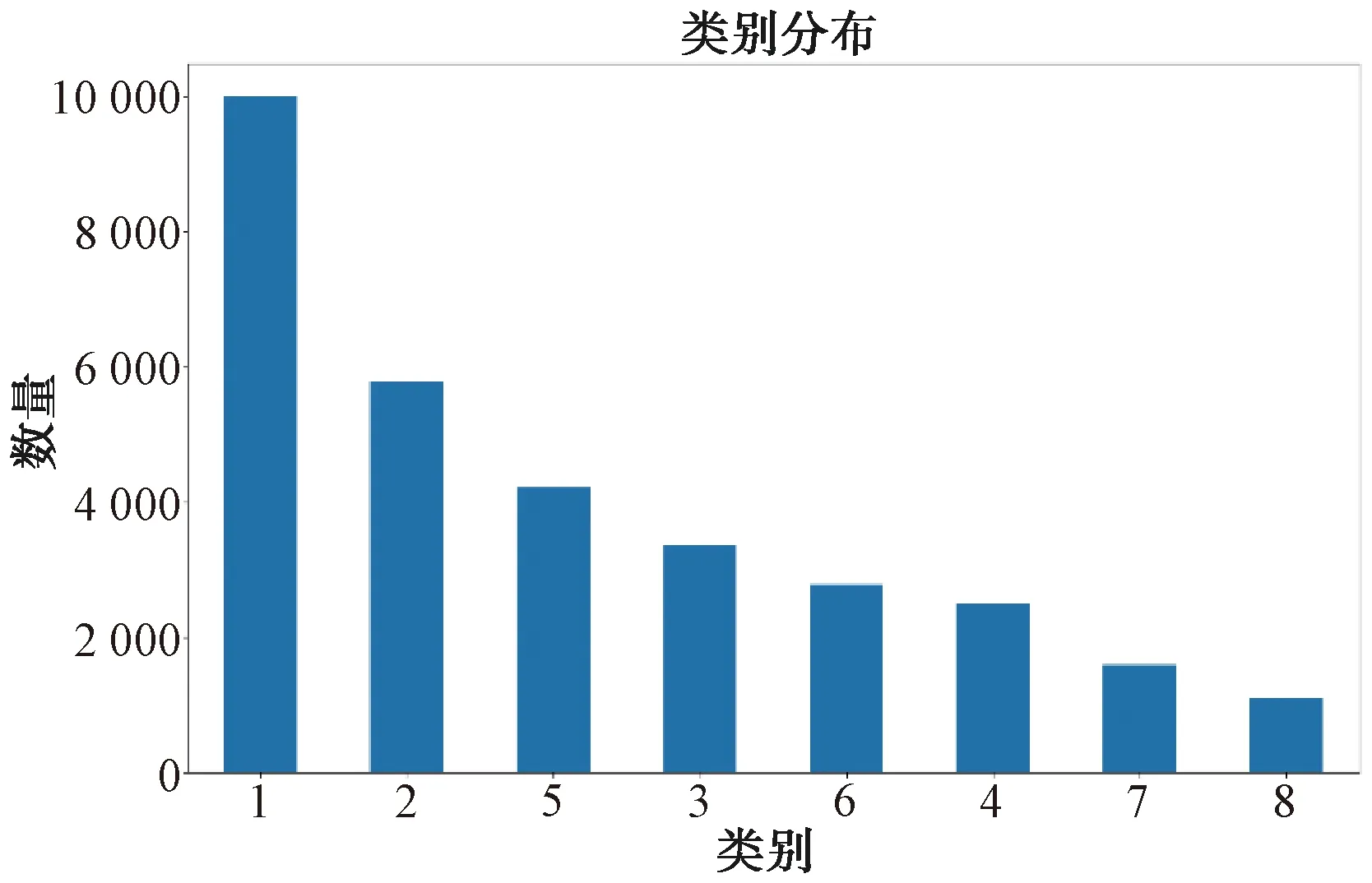
图5 8组数据的数量分布图
将31 331条数据按照6∶4的比例进行划分,将其中18 798条数据作为训练集进行模型训练,12 533条数据作为测试集来测试模型的准确度。

图6 仿真参数可视化
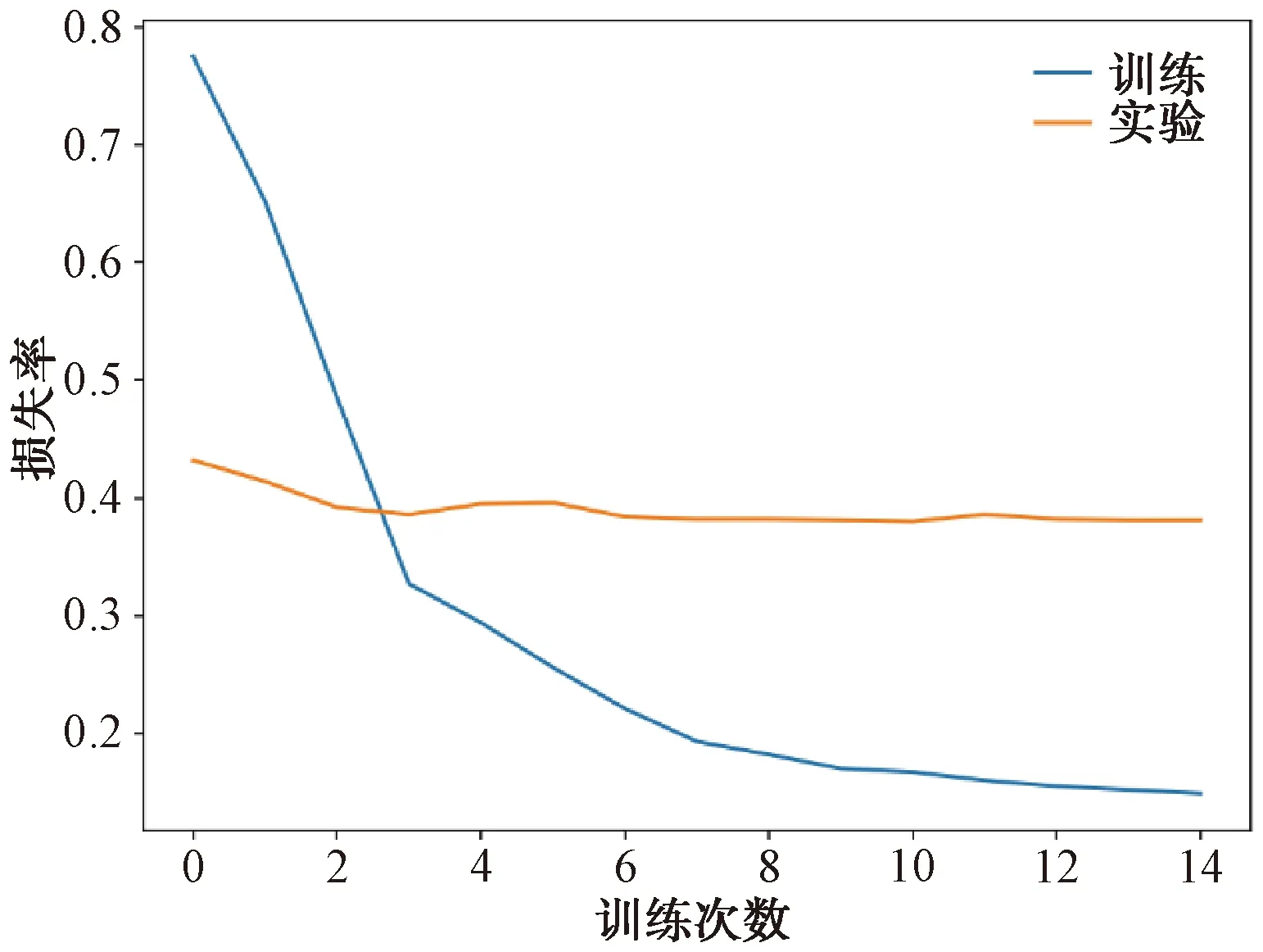
图7 损失函数变化趋势图
仿真采用了3层神经网络模型,第1层为输入层,输入维度为7,第2层为隐藏层,包含100个神经单元,输出层为包含8个分类的全连接层,由于是8批目标,所以采用了softmax作为激活函数,损失函数采用了分类交叉熵categorical_crossentropy,训练次数设置为15次。
模型在训练过程中,从损失函数的变化趋势来看,如图7所示。随着训练次数的增加,模型在训练集中的损失越来越小,而在测试集中,损失从一开始较大逐渐减小后又逐渐增大并趋于平稳,这说明了模型的过拟合。同样在准确率的变化图中可以看出,如图8所示,随着模型训练次数的增加,训练集中的准确率随之增大,并逐渐趋于平稳,而测试集的准确率随着训练周期的增加,从最开始的较小逐渐变大后又变小并趋于平稳,也反映了模型过拟合。

图8 准确率变化趋势图
由于训练数据的不平衡,某些类别数据量多,如第1类数据有10 000条,而有的数据量太少,如第7类和第8类数据只有不到2 000,这种数据量之间的差别会造成模型准确率的不同,同时训练数据只有1万多条,数据量太少会造成模型的过拟合现象。但也从该实验中验证了该方法的可行性,后续可以增加数据量和平衡各类别的数据来进一步验证。
4 结束语
本文讨论了辐射源个体识别技术的发展情况,从传统的辐射源个体识别方法到现阶段复杂环境中对复杂辐射源个体识别的方法,了解了从传统的特征提取和分类器设计两步骤到机器学习、深度学习技术应用中的一体化个体识别,最后讨论了对具有时序特性的辐射源数据采用LSTM模型来处理的可行性,介绍了数据输入到输出的算法流程,并通过仿真验证了该方法的可行性。接下来会继续讨论时序模型的应用,同时考虑采用多个深度学习模型组合的方式(如CNN+LSTM)进行分析实验,通过CNN的卷积进行特征提取,并将这些特征输入到LSTM序列模型中,挖掘其之间的关联关系,可以得到较高的准确率;或通过采用CNN+BLSTM+CTC的架构进行建模,CNN用来提取特征,BLSTM进行不定长数据的处理,然后用CTC进行去重定向,该类模型在处理序列问题上有很好的效果。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
舰船电子工程(2022年7期)2022-09-06
小猕猴智力画刊(2022年3期)2022-03-28
意林·作文素材(2021年23期)2021-01-22
北京航空航天大学学报(2020年10期)2020-11-14
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
雷达学报(2018年5期)2018-12-05
电子制作(2018年19期)2018-11-14
