
基于集成生成对抗网络的视频异常事件检测方法
2022-11-24 06:56顾嘉城龙英文吉明明
液晶与显示 2022年12期
顾嘉城,龙英文,吉明明
(上海工程技术大学 电子电气工程学院 上海 201620)
1 引 言
监控视频中的异常检测是一项基本的计算机视觉任务,在视频分析和潜在的应用如事故预测、城市交通分析、证据调查中起着至关重要的作用。尽管近年来该问题已引起了强烈的关注,但由于正常样本与异常样本严重不平衡、缺乏细致的异常标记数据以及异常行为概念的模糊性,视频异常检测仍然是一个非常具有挑战性的问题。
为了解决这个问题,研究人员提出了大量的解决方法。根据文献[1],现有的异常检测方法可以分为基于密度估计和概率模型的方法、基于单类分类的方法以及基于重构的方法。基于密度估计和概率模型的方法[2-3]首先计算样本的概率密度函数,然后通过测试样本距离密度函数中心的距离来进行判断。经典非参数密度估计器的方法虽然在处理低维问题时表现相当好,但它们获得固定精度水平所需的样本大小在特征空间的维数上呈指数增长。基于单类分类的方法[4-5]试图避免将密度的完全估计作为异常检测的中间步骤。这些方法旨在直接学习与正例样本相对应的决策边界,通过测试待测样本是否属于决策边界内判断其是否属于异常。基于重建的方法[6-7]学习一个模型,该模型经过优化可以很好地重建正常数据实例,从而通过未能在学习的模型下准确地重建异常来检测异常。
近年来,深度学习通过训练灵活的多层深度神经网络从数据本身学习有效表示,并在许多涉及复杂数据类型的应用中取得了突破性进展,如计算机视觉[8-9]、语音识别[10-11]和自然语言处理[12-13]等领域。基于深度神经网络的方法能够通过其多层分布式特征表示来利用数据通常固有的分层或潜在结构。此外,并行计算、随机梯度下降优化和自动微分方面的进步使得在大型数据集大规模应用深度学习成为可能。针对异常检测问题,深度学习方法可以对整个异常检测模型进行端到端优化,并且还可以学习专门为异常检测问题的表示。此外,深度学习方法对于大型数据集的能力有助于大幅提高标记正常数据或一些标记异常数据的利用率。
在深度学习的框架下,本文提出了一种基于单类分类的异常检测方法。这种方法是生成对抗网络(Generative Adversarial Networks,GAN)[14]的改进形式,称为集成生成对抗网络(GAN en⁃sembles)。GAN利用生成器和判别器之间的竞争,生成器学习样本的分布,判别器则学习如何检测异常。集成GAN由多个编码器-解码器和鉴别器组成,它们随机配对并通过对抗性训练进行训练。在这个过程中,编码器-解码器从多个判别器获得反馈,而判别器从多个生成器获取“训练样本”。与单个GAN相比,集成GAN可以更好地对正常数据的分布进行建模,从而更好地检测异常。最后,通过从所有编码器-解码器、鉴别器对计算出的异常分数的平均值获取总异常分数以进行判别。在几个公共基准数据集上的实验结果表明,集成GAN在一系列异常检测任务中明显优于现有方法。
2 算法原理
2.1 问题描述
假设正常样本训练集X={xi∈Rd:i=1,…,N}包含N个数据,来自未知分布D,待测样本x′∈Rd可能不属于未知分布D。那么,异常检测的问题是通过X训练模型,使模型可以将x′归类为分布D,为正常样本;反之,如果x′来自不同的分布,则为异常。通常,用模型计算x′的异常分布y′∈Rd并通过对y′设定阈值处理来判断x′的标签。
2.2 生成对抗网络
GAN包含有两个神经网络,分别是生成器和判别器。其中,生成器包含一个编码器Ge(⋅;ϕ)和一个解码器Gd()⋅;ψ,编码器将样本x编码成一个向量z,解码器将其重建成x͂,即有
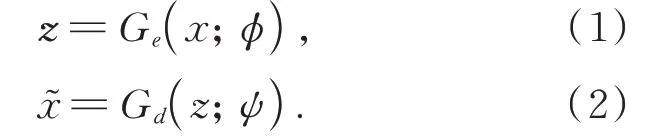
而判别器D(⋅;γ)则判断测试样本是来自数据集X而不是生成器生成样本的概率。那么,判别器应该提供比正常样本更高的重构误差值。由于模型由编码器-解码器和判别器组成,因此训练过程通常会考虑从两个模型继承的损失函数。对抗性损失来自GAN训练,损失定义如式(3)所示:
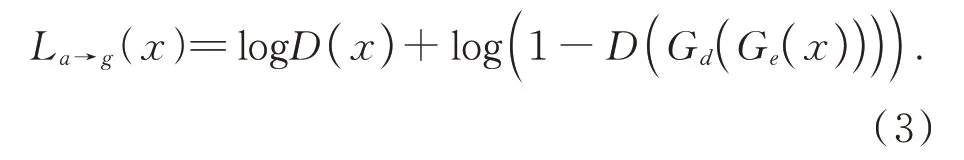
另一个是重构损失,用于训练编码器和解码器。实际上原始样本和重构结果的差异往往通过l-范数进行计算:
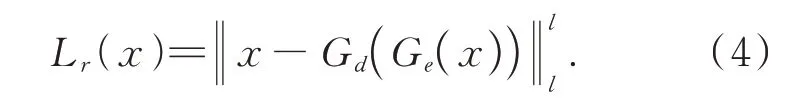
先前研究表明,鉴别器D(⋅;γ)最后一个隐藏层中一个样本的隐藏向量h对于区分正常样本和异常样本很有效。定义h=D(x;γ)为D(⋅;γ)中的隐向量,那么基于h的判别损失可以表示为:
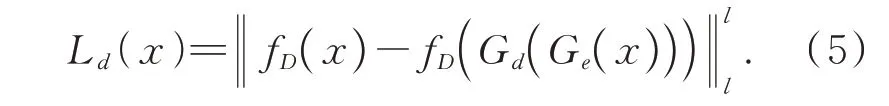
此外,GAN还考虑了正常样本x的编码向量与其重构͂之间的差异。特别地,它使用单独的编码器对重构͂进行编码。那么编码损失为:
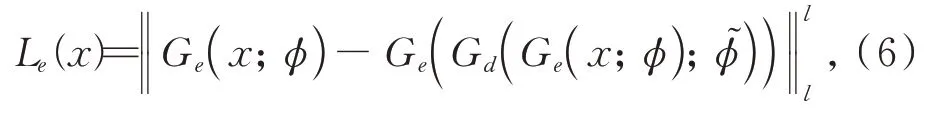
其中,编码器参数ϕ和͂明显不同。为了训练鉴别器,GAN模型需要最大化对抗性损失,即

在GAN参数训练完后,需要对测试样本x′计算异常得分A(x′),那么异常分数是通过重建损失和判别损失的加权和计算获得:
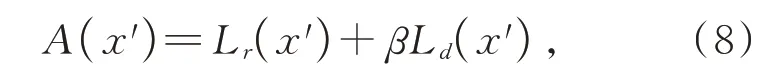
其中,权值β通过经验选择获得。较高的异常得分表明高异常概率。
2.3 基于集成GAN的异常检测方法
本文提出了一个基于集成GAN的异常检测方法。该方法有多个生成器和鉴别器,具有不同的参数化。假设定义I个生成器{Ge(⋅;ϕi),Gd(⋅;ψi):i=1,…,I}和J个判别器{De(⋅;γi),:j=1,…,J},单个生成器或判别器与基本模型相同。在对抗训练过程中,将每个生成器与每个鉴别器匹配,然后每个判别器对生成器进行评价,判别器从每个生成器接收合成样本。
对于多对生成器和判别器,对抗性损失和判别性损失都是从所有生成器-判别器对计算的。每个生成器-鉴别器对之间的损失如式(9)和式(10)所示:
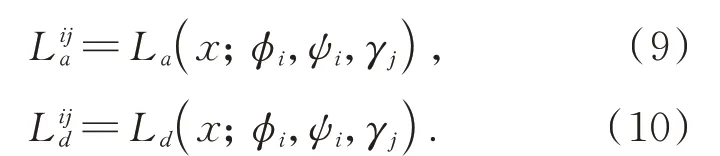
类似地,单个生成器i的重构损失和编码损失为如式(11)和式(12)所示:
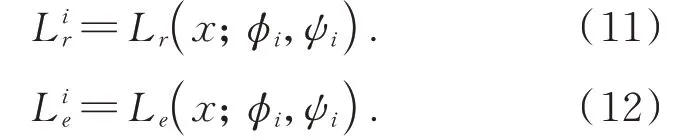
然后通过最大化对抗性损失的总和来训练鉴别器,同时最小化所有损失的总和训练生成器。目标函数如式(13)和式(14)所示:
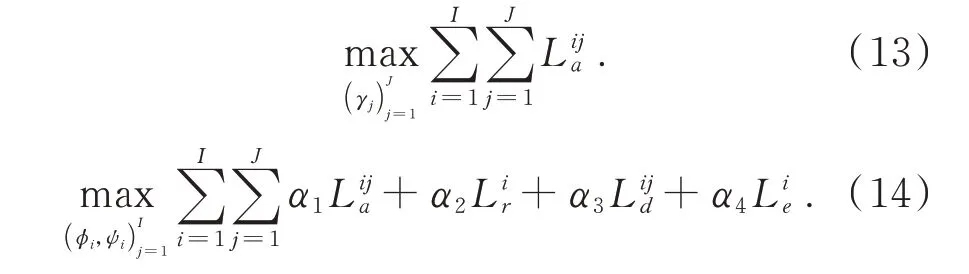
在一次训练迭代中,只更新一对生成器-鉴别器,而不是所有生成器和鉴别器。特别是,可以随机选择一个生成器和一个鉴别器,并用随机一批训练数据计算损失。
对于多个生成器和判别器,待测样本x′集成GAN的异常得分为:
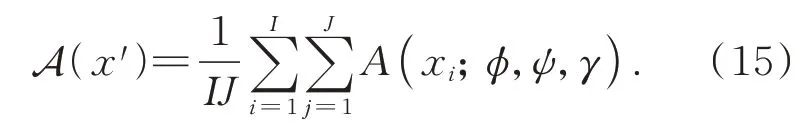
如果模型在特定测试实例中没有得到很好的训练,则异常分数的平均值有助于消除虚假分数,并设定门限值θ判断其是否为异常:

图1为本文方法的基本原理框架,通过具有不同参数的多个GAN,实现对视频中异常行为的高精度检测。

图1 基于集成生成对抗网络的异常检测方法框架Fig.1 Methodology of abnormal event detection based on GAN ensembles
3 实验与分析
3.1 实验数据
为了评估所提出的GAN ensemble异常方法的定性和定量结果并将其与最新的算法进行比较,本文选取两个公共视频异常检测数据集进行了实 验:CUHK Avenue[15]和ShanghaiTech[16]。CUHK Avenue数据集拍摄于香港中文大学街道,包括16个训练和21个测试视频,从固定场景收集。训练正常数据仅包含行人步行,异常事件包括跑步、丢包等共47个。相比于CUHK Ave⁃nue数据集,ShanghaiTech数据集非常具有挑战性,包含来自13个场景的视频,具有复杂的光照条件和摄像机角度,训练和测试的总帧数分别达到27.4万帧和4.2万帧。测试集中包括追逐、争吵、突然动作等130个异常事件,分散在1.7万帧中。
根据先前的工作[15-16],本文采用受试者工作特征曲线(ROC)下面积(AUC)来评估性能。ROC曲线是通过改变阈值并计算每个帧级预测的异常分数来获得的。
3.2 实验设置
对于两个数据集,每帧视频被调整到286×286,并在每次迭代过程中随机裁剪大小为256×256的视频块。生成器的结构采用C64×(4×4)-C128×(4×4)-C256×(4×4)-C512×(4×4)-C512×(4×4)-DC256×(4×4)-DC128×(4×4)-DC64×(4×4)的结构。前半部分为编码器,后半部分为解码器。编码器首先为64个大小为4×4卷积核的卷积层,接下来采用128个大小为4×4卷积核的卷积层,然后采用256个大小为4×4卷积核的卷积层和512个大小为4×4卷积核的卷积层。解码器和编码器结构完全相反,包含了大小相同的反卷积层。每层后都连接了BatchNorm层和ReLU激活函数。判别器共包括5层卷积层,卷积核大小也是4×4,结构采用C64×(4×4)-Pooling-C128×(4×4)-Pooling-C256×(4×4)-Pooling-C512×(4×4),最后输出一维数据。本文采用Tensorflow2.0来实现GAN ensembles方法,并采用Adam优 化 器ρ1=0.9,ρ2=0.999对 其 进 行优化。初始学习率设置为1e−4,每50个epoch后衰减0.8,共训练300 epoch。
3.3 实验结果
为了验证本文提出方法的优势,本文将所提出的方法同现有的方法进行比较;(1)基于密度估计和概率模型的方法Frame-Pred.[17]、VEC[18]、Conv-VRNN[19];(2)基于单类分类的方法MNAD-P[20]、AMDN[21];(3)基 于 重构 的 方法Conv2D-AE[6]、Conv3D-AE[6]、StackRNN[22]。表1给出了对比结果,其他方法的结果从相关论文中获得。
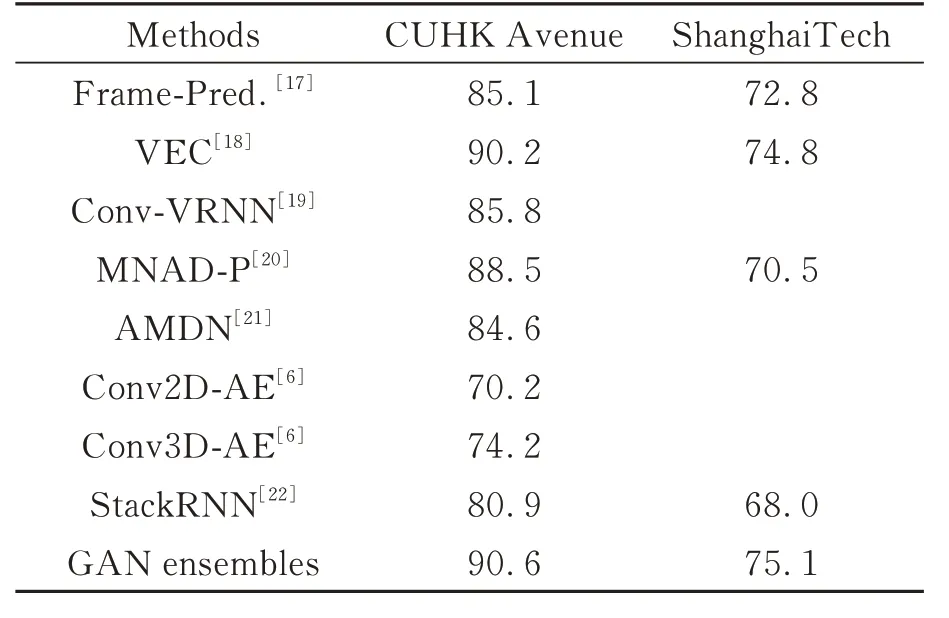
表1 帧级异常检测结果与最先进方法的比较Tab.1 Comparison of frame-level anomaly detection per⁃formance with state-of-the-art methods(AUC%)
通过表1可以观察到,本文提出的GAN en⁃sembles模型在这两个数据集上都比其他最先进的方法取得了更好的结果,这证明了本文提出方法的有效性。特别是在CUHK Avenue数据集上达到了91.1%的AUC,远超过除了VEC[18]方法的其他方法。值得注意的是,这些方法在CUHKAvenue上的表现优于在ShanghaiTech上的表现,这是由于ShanghaiTech是新提出的数据集,帧数较多,而且不同样本分辨率变化较大。即便如此,本文提出方法在ShanghaiTech数据集上取得了75.1%帧级AUC,也超过其他方法中最优的VEC 0.3%。此外,本文还在ShanghaiTech数据集上对比了几类方法的相同异常场景所需要的平均时间,其中VEC、MNAD-P、和AMDN的时间分别为30.4,26.3,21.9 ms,本文方法为20.1 ms。对比可见,本文方法的运行效率更高。综合检测精度和运行效率,本文方法的优势更为显著。
图2展示了本文提出方法的两个测试数据集的异常示例。异常曲线依次显示了视频所有帧的异常分数,通过它可以更直观地观测方法的性能。绿色区域表示真实标注的异常部分,蓝色区域表示方法检测出的异常区域。可以看出,蓝色区域能够和绿色区域相对应。在正常帧部分,本文提出的GAN ensembles异常分数低且非常稳定。而当异常出现时,如人行道上出现自行车、小车,打架推搡,异常得分突然增加。图中得分值与这些场景的出现能够完全相符。

图2 两个数据集的部分检测结果示例Fig.2 Anomaly detection comparison on CUHK Avenue Dataset and ShanghaiTech Dataset
在接下来的实验中,为了评估集合个数I、J对视频异常检测事件性能的影响,通过改变集合个数I,J∈{1,3,5,7}并保持相同数量的生成器和判别器来进行检测。图3展示了在两个数据集上的检测结果随着集合个数变化的曲线。可以观测到,集合个数从1~3,检测结果有明显的改进,AUC在所有模型中的平均增长为14.2%。然而,当集合个数从3~7变化时,性能提升不明显。在本实验中,采用I=J=3的集合个数时,训练时间是集合个数为1时的3倍。值得注意的是,这还是在每个生成器或判别器每3次迭代更新一次的情况下获得。那么,综合计算代价和性能,集合个数为3时实验效果最好。

图3 不同集合个数对于数据集实验结果的影响Fig.3 Difference detection performances with different ensemble sizes
4 结 论
本文将集成学习引入基于GAN的异常模型以进行异常检测。GAN的鉴别器对异常检测非常有效,而且集成学习可以进一步改进鉴别器的训练,这意味着本文提出的方法不是集成学习和GAN的简单组合,而是集成学习可以有效地影响预测质量。在两个数据集上的实验证明,本文提出的方法超过了现有技术发展水平。大量实验表明,与单个模型相比,集成方法在两个数据集中都取得了更优异的结果。
猜你喜欢
通信学报(2022年10期)2023-01-09
北京工业大学学报(2022年9期)2022-09-15
网络安全与数据管理(2022年1期)2022-08-29
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
家庭影院技术(2019年8期)2019-12-04
制造技术与机床(2017年7期)2018-01-19
西安工程大学学报(2016年6期)2017-01-15
系统工程与电子技术(2016年5期)2016-11-02
