
长江流域斜坡地质灾害易发性评价
2022-11-23 06:41刘宇涛陈振炜陈伟涛张艳军王舜瑶徐子兴
中国防汛抗旱 2022年11期
刘宇涛 张 过 陈振炜 陈伟涛 张艳军 王舜瑶 徐子兴
(1.武汉大学测绘遥感信息工程国家重点实验室,武汉 430079;2.中国地质大学(北京)地球科学与资源学院,北京 100083;3.中国地质大学(武汉)计算机学院&地质探测与评估教育部重点实验室,武汉 430074;4.武汉大学水资源与水电工程科学国家重点实验室,武汉 430072)
0 引 言
长江流域人口约5.99亿人,占全国的42.9%,生产总值约40.3 万亿元,占全国的44.1%,有3 个国家级的城市群,分别是成渝城市群、长江中游城市群、长三角城市群。但长江流域是我国受地质灾害影响较严重的区域,区域内地形陡峭、气候复杂,每年都会因地质灾害造成人员伤亡和经济损失。如2019年7月23日,贵州水城县发生特大山体滑坡事件,造成近1 600人受灾,43人死亡,9人失踪,直接经济损失1.9 亿元;2019 年8 月20 日0-7 时,四川汶川县累计降雨量最大达到65 mm,导致汶川县多处发生泥石流,致10人遇难和28人失联,直接经济损失达14亿元;2020年8 月21 日,四川雅安市发生山体滑坡,滑坡破坏量约80万m3,造成7人死亡,2人失踪。
由于长江流域地质灾害频发,国内很多学者在长江流域内不同区域开展了大量研究工作,吴润泽等[1]以三峡库区湖北段为研究区,以滑坡灾害为研究对象绘制了地质灾害易发性分区图;毕鸿基等[2]以汶川县为研究区,选取坡度、坡向、地层岩性、距断层距离、植被覆盖率及距水系距离6 项影响因子,以幂次相乘、线性累加、幂次累加这3 种不同模型分别得到了研究区地质灾害易发性分区图;温鑫等[3]以川东南古蔺县为研究区,采用信息量模型分别对滑坡和崩塌灾害进行易发性评价后,绘制了研究区地质灾害易发性分区图,评价精度达到81.2%;胡燕等[4]采用证据权法对湖北巴东县进行了地质灾害易发性评价,生成地质灾害易发性分区图,结果显示86%的地质灾害点位于高易发区和极高易发区。以上学者基本都在长江流域内较小的研究区采用不同的模型取得了较好的结果,而针对大区域,研究较少。2020 年中国地质调查局中国地质环境监测院发布了《中国崩塌滑坡泥石流易发程度图》[5],结合了地形、地貌、岩土体类型、地质构造、地震、降水、植被、水系等影响因素,反映崩塌、滑坡、泥石流易发程度,但是该数据运用了确定系数方法,主观性较强,而且仅考虑了自然影响因素,未考虑人类活动和地质灾害动力学特征,精度不足。
本文以长江流域为研究区,以斜坡地质灾害(本文特指发育于天然斜坡和人工切坡之上的崩塌、滑坡、泥石流等地质灾害[6],以下简称斜坡地灾)为研究对象,在考虑自然因素因子的基础上,将道路和地表形变加入评价因子,分别表示人类活动因素和地质灾害动力学特征,结合孕灾环境和诱发因素进行了综合分析,采用随机森林构建评价模型,计算得出长江流域斜坡地灾易发性评价结果,分析了核心致灾因子,并与中国地质调查局发布的《中国崩塌滑坡泥石流易发程度图》进行对比。
1 研究区概况与数据源
长江是亚洲第一大河,流经青藏高原、横断山脉、云贵高原、四川盆地、江南丘陵、长江中下游平原,流经地区资源丰富,支流和湖泊众多。长江流域,跨越11个纬距,32个经距,呈东西长,南北短的流域形状,流域总面积达180万km2,涉及中国19个省(自治区、直辖市),约占中国陆地总面积的1/5[7-8],流域内地形呈多级阶梯状分布,地形地貌复杂。
长江流域地跨扬子准地台、三江褶皱系、松潘甘孜褶皱系、秦岭褶皱系和华南褶皱系5个地质大构造单元,下游处于横贯中国的秦岭东西向构造带与南岭东西向构造带之间。地质构造复杂多样,太古宇至第四系均有出露,并有不同时期的岩浆岩分布[9-10]。新构造运动和地震活动西强东弱。长江流域中西部地区以山地为主,地形破碎而起伏变化大,区域稳定性较差,地质灾害大量发育,东部地区地势较低,以丘陵、平原为主,地质灾害较西部发育较少。
通过美国太空总署(NASA)官方网站下载研究区30 m分辨率数字高程模型数据(DEM),用来提取研究区高程、坡度、坡向等地形信息;通过中国地质调查局地质科学数据出版中心网站发布的中国地质环境图系数据库下载《中国工程地质图》和《中国及毗邻海区活动断裂分布图》[5],提取研究区工程岩组信息、活动断裂分布信息和1900年至今震级大于5 级的783 次地震分布信息;通过OSM 开源数据网站下载中国水系和道路数据,提取到长江干流及1~5级支流的水系和长江流域道路分布信息;通过中国气象局国家气象信息中心提供的长江流域202 个气象观测站2015-2019年的逐12 h降水数据,插值计算得到年平均降水数据;通过国家地球系统科学数据中心提供的全国不透水面数据[11]提取城市范围;通过武汉大学测绘遥感信息工程国家重点实验室获取全国地表形变数据[12];通过地理科学数据网站收集研究区内的历史地质灾害编录数据。各类数据获取渠道和用途如表1所示。

表1 用于长江流域斜坡地灾易发性评价数据源信息
2 斜坡地灾易发性评价因子
斜坡地灾是孕灾环境和诱发因素共同作用的结果。考虑研究区斜坡地灾的形成机理、诱发因素、承灾体的基本特征,本文选取高程、坡度、坡向、工程岩组和断层距离作为孕灾环境[13]因子,选取水系距离、震源距离、年均降水量、道路距离作为诱发因素因子,选取地表形变作为斜坡地灾动力学特征因子,共10个因子作为斜坡地灾易发性评价因子。
2.1 孕灾环境
(1)高程。控制边坡的应力、温度、植被覆盖,影响斜坡地灾发育程度。研究区高程分布跨度较大,分布区间为0~6 481 m,如图1(a)所示。
(2)坡度。坡度为斜坡提供势能,随着地形坡度的增加,斜坡提供的势能也会逐渐增大,重力作用下,势能逐渐转变为动能,导致斜坡地灾的发生。研究区坡度分布区间为0°~88.3°,如图1(b)所示。
(3)坡向。坡向会影响太阳辐射强度、植被覆盖率、蒸发量等因素,进而影响坡体的稳定性。坡向分为北、东北、东、东南、南、西南、西、西北向和平地,如图1(c)所示。
(4)工程岩组。工程岩组类型是斜坡地灾发生的物质基础和重要内因,为斜坡地灾的发生提供物质来源,岩土体的物理性质(硬度、抗风化能力)决定着其是否容易遭受破坏,决定斜坡地灾易发程度。研究区内工程岩组按照坚硬程度可分为砂砾质土体、坚硬块状岩浆岩和变质岩、坚硬层状喷出岩、坚硬层状碳酸盐岩、较坚硬层状碎屑岩、碳酸盐岩夹碎屑岩、坚硬-软弱相间的片状和板状变质岩、软弱层状碎屑岩,共8类,如图1(d)所示。
(5)断层距离。沿断层构造带上软弱构造面发育,岩石极为破碎,风化程度较高,使得地下水富集,易发生斜坡地灾[14]。断层对于地质灾害的影响与距离相关,研究区的活动断层分布和断层距离,如图1(e)所示。

图1 长江流域斜坡地灾易发性孕灾环境评价因子
2.2 诱发因素
(1)水系距离。通过侵蚀作用水系沿岸边坡临空面积增大,使得上部斜坡易发岩土体超过自身承载力向下滑动而导致斜坡地灾的发生[14]。研究区的水系分布和水系距离,如图2(a)所示。
(2)震源距离。地震的强烈作用使岩土体的内部结构发生破坏和变化,使原有的结构面张裂、松弛,加上地震会使地下水突然升高或降低,更容易导致斜坡地灾发生。研究区的震源分布和震源距离,如图2(b)所示。
(3)年均降水量。降雨,尤其暴雨经常是诱发斜坡地灾的重要条件。降雨过程中,大量地表水进入坡体,增加其下滑动力;同时,雨水随着岩石裂隙或破裂面进行渗透作用,使得层面的黏聚力和内摩擦角减小,降低抗剪强度,影响坡体稳定性。研究区的年平均降水分布区间为241.7~2 416.5 mm,如图2(c)所示。
(4)道路距离。山区道路修建时会对坡体进行开挖或填补,改变坡体原有的应力状态,稳定性降低;道路修好后,过往车辆的行驶,加剧了坡体的形变速度,进而提高了斜坡地灾发生的可能性。而城市道路并不影响灾害的发生,因此通过不透水面数据提取城区范围,去除城区道路。道路对于斜坡地灾的影响与距离有关,研究区非城区道路距离如图2(d)所示。
2.3 动力学特征
斜坡地灾的动力学特征由地表形变数据体现。地表形变数据可以表现地震形变、地面沉降、山体滑坡、冰川流动、活火山隆起或者下沉、地壳断层运动等,因此地表形变数据与斜坡地灾的发生有一定的相关性。研究区地表形变数据如图2(e)所示。

图2 长江流域斜坡地灾易发性诱发因素和动力学特征评价因子
3 方法与精度分析
3.1 评价方法
地质灾害易发性是指一个地区内现有或潜在崩塌、滑坡、泥石流的类型、体积(或面积)和空间分布的定性或定量评价[15]。目前,常用的地质灾害易发性评价方法主要包括统计分析法和数学模型法,统计分析法包括信息量法[16-17]、层次分析法[18-19]、证据权法[20]等;数学模型法包括随机森林[21-22]、神经网络[23]、支持向量机[24]等。各种方法受模型本身限制各有优缺点。统计分析法效果直观,但易受主观因素影响,适用于环境单一、评价因子长期不变的区域,数学模型法自适应、自学习、非线性映射能力强,但受制于样本数据质量,适用于环境复杂,评价因子非线性的区域[25]。
长江流域面积大,地形地貌、地质条件复杂,更适合运用数学模型法,而随机森林模型在评价过程中无需对评价因子去量纲规范化处理,可直接进行运算,处理高维度和大数据量的数据集能力强。因此,本文将选取随机森林模型用于长江流域斜坡地灾易发性评价。
随机森林是一种集成机器学习方法[26],它利用随机重采样技术和节点随机分裂技术构建多棵决策树[27],通过投票得到最终分类结果,如图3所示。
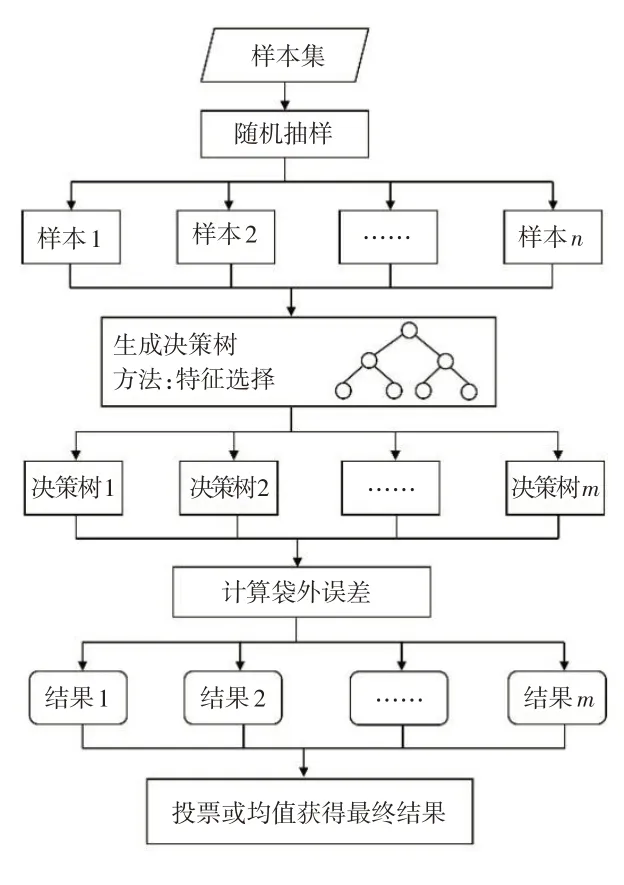
图3 随机森林流程示意图
构建随机森林模型的步骤如下:
①以历史斜坡地灾点和非斜坡地灾点作为样本集,从中通过随机抽样的方式产生n个样本;②将评价因子作为特征,对n个样本选择其中的k个特征,建立决策树;③重复m次,产生m棵决策树;④多数投票机制进行预测。
其中每棵树具有相同的分布,分类误差取决于每一棵树的分类能力和他们之间的相关性。而袋外数据的误差是一种无偏估计,可以用来验证模型的性能好坏以防止过拟合。
随机森林的泛化误差定义:

式中:P*为随机森林的泛化误差;ρˉ为决策树间的相关度平均值;s为决策树平均强度。
泛化误差是衡量模型在未知数据上的准确率的指标,从式(1)可知要增强模型的准确度,可减弱决策树间的相关度或增强决策树的强度。对于随机森林这种集成算法来说,模型中的每颗决策树结构是不同,因此可以通过增加决策树的数量来减弱整体的相关性,或者通过增加模型中每棵决策树的叶子节点和深度调整决策树的复杂程度来增加决策树的强度。当模型过于复杂时,模型会过拟合,泛化误差也会增加,因此需要寻找到最佳模型复杂度,使得泛化误差最小,模型准确度最高。
3.2 评价流程与评价结果
根据研究区的资料收集情况及数据的分辨率,本文将以100 m×100 m的网格单元作为斜坡地灾易发性分区图的空间尺度,共将研究区划分为180 854 800个评价单元。在研究区内选取一定的正、负样本数据作为数据集,正样本数据为历史斜坡地灾编录中筛选的近十年的斜坡地灾点数据,共覆盖14 070 个栅格单元,负样本数据为随机选取研究区未发生斜坡地灾的栅格单元,数量与正样本数据相同。将数据集按照7∶3的比例分为训练集和测试集,训练集用来训练模型的参数,测试集用来测试模型精度。
本文运用Python 中的scikit-learn 模块构建随机森林模型,构建模型的过程中有两个参数对模型精度影响较高,分别是n_estimators(模型中决策树的个数)和max_depth(模型中决策树的深度),通过设置不同的参数值可以得到模型准确度的得分曲线,进而得到最优参数值,随机森林模型参数准确度曲线见图4。

图4 随机森林模型参数准确度曲线
图4中,橙色和蓝色曲线分别表示训练集和测试集中模型的准确度,图4(a)中可以看出,当n_estimators 值升至180时,模型准确度收敛到最高值并趋于稳定,n_estimators值为460 时,训练集和测试集的准确度均达到最高。图4(b)中可以看出当max_depth值升至15时,模型准确度收敛到最高值,max_depth值为19时,训练集和测试集的准确度均达到最高,将n_estimators 和max_dept 值分别设为460和19,构建随机森林模型。
运用随机森林模型实现斜坡地灾易发性评价本质是一个二分类问题,通过模型可以计算出研究区的每一个栅格单元发生斜坡地灾的概率值,介于0~1。概率值越大,指示该地区越脆弱,越容易发生斜坡地灾,按照等间距法以0.2、0.4、0.6和0.8作为断点将概率值划分为5个区间,由低到高分别赋予极低、低、中、高、极高斜坡地灾易发区,见图5。

图5 长江流域斜坡地灾易发性分区图
3.3 精度评价与分析
通过随机森林模型得到长江流域斜坡地灾易发性评价因子的贡献程度图(图6),可以看出,高程在本次评价中贡献度值为0.33,坡度贡献度值为0.29,年均降水量贡献度值为0.28,地表形变贡献度值为0.24,坡向贡献度值仅为0.06,由此可见,高程和坡度所占权重较大、年均降水量和地表形变次之,坡向和道路距离对斜坡地灾的发生贡献较小。

图6 斜坡地灾易发性评价因子贡献程度图
模型的性能可以通过ROC(Receiver Operating Characteristics)曲线体现,ROC曲线分析的是二元分类模型,也就是给定阈值,大于该阈值的认为斜坡地灾容易发生,小于该阈值则认为斜坡地灾不容易发生。对易发性分区图划定不同阈值,分别算出每个阈值下的混淆矩阵,如表2所示。

表2 混淆矩阵
表中TP表示根据阈值判断发生斜坡地灾,实际确实发生的点数;EP表示根据阈值判断发生斜坡地灾,实际却未发生的点数;FN表示根据阈值判断未发生斜坡地灾,实际确实未发生的点数;TN表示根据阈值判断未发生斜坡地灾,实际却发生的点数。而ROC 曲线是以伪阳性率FPR为横坐标、真阳性率TPR为纵坐标所绘制的曲线,FPR、TPR如式(2),式(3)所示。
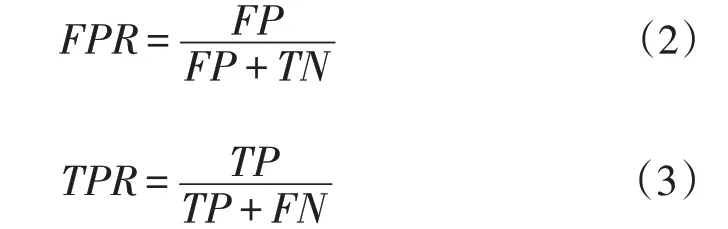
而模型精度可以根据ROC 曲线下方面积AUC(Area Under ROC)值评估,在曲线下方的区域对应的面积则为AUC 值,该数值介于0~1,一般大于0.5,越接近1,模型精度越高。本次斜坡地灾易发性评价模型的AUC 值为0.95,表明该模型精度较高,如图7所示。

图7 随机森林模型的ROC曲线和AUC值
虽然ROC曲线结果表现较好,但是不能反映出斜坡地灾易发性评价结果的空间分布是否合理。因此,为了验证结果的合理性,将实际分布的斜坡地灾位置作为验证数据,统计各个易发性分区下的面积、面积占比、斜坡地灾数、斜坡地灾百分比、斜坡地灾密度,如表3所示,研究区内超过一半的面积为斜坡地灾极低或低易发区,占研究区面积的68.9%,其中极低易发区面积94.2 万km2,区内斜坡地灾密度为0.001个/km2;研究区内仅有14.9%的区域斜坡地灾易发程度为高或极高,而位于区域内的斜坡地灾数量为9 704个,占研究区斜坡地灾总数的69%,其中极高易发区内面积占比4%,却包含了研究区41%的斜坡地灾点,斜坡地灾密度达到0.08个/km2,远远高于其他分级区域。由此可见,运用随机森林模型绘制的斜坡地灾易发分区图符合实际情况。
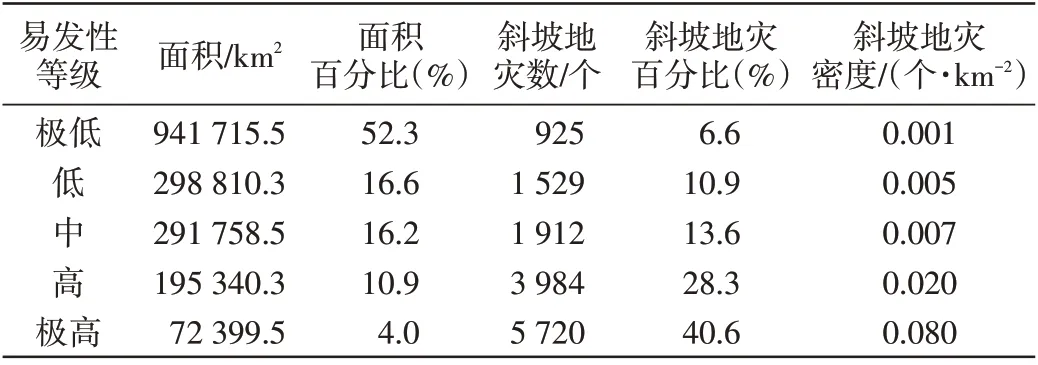
表3 长江流域斜坡地灾易发性评价分区统计表
对比中国地质调查局发布的《中国崩塌滑坡泥石流易发程度图》[5],长江流域斜坡地灾低易发区面积占比从30%升至68.9%,斜坡地灾中高易发区面积占比从70%降低至31.1%。本次研究在大幅度降低斜坡地灾中高易发区面积占比的基础上,仍有82.5%的斜坡地灾位于中高易发区上,具有较高的准确性。
结合长江流域斜坡地灾易发性分区图可以看出,斜坡地灾低易发区和极低易发区主要位于研究区西部的青藏高原和东部的长江中下游平原,成片状分布;斜坡地灾高易发区和极高易发区集中分布于研究区中部四川盆地周围和研究区东南部的丘陵地带,高易发区主要沿河流和构造带成线状集群分布,符合地质灾害发育特点。按照分布特点可以在研究区内划分4个斜坡地灾高易发区,如图5所示。
(1)四川盆地西斜坡地灾高易发区。位于四川盆地西的雅安,向南延伸至贵州南部边界,向北延伸至广元市,呈C形分布,全区海拔基本在1 500~2 000 m,自北向南逐渐降低。该区地质构造复杂,地震频发,地形陡峭,松散碎屑物质丰富,降雨充沛,滑坡、泥石流沿河流密集发育,威胁区内的水利水电工程区。
(2)秦岭-大巴山斜坡地灾高易发区。主要由秦岭、大巴山组成,南为大巴山,北为秦岭,海拔多在1 000~3 000 m,区内峰峦重叠,山岭陡峻,河谷深切。第四系坡残积层在区内广泛分布,沿江岸以片岩、板岩、千枚岩等软质易滑岩组为主。
(3)重庆-宜昌沿江斜坡地灾高易发区。位于重庆至宜昌段长江干流沿岸地区,海拔主要在0~1 000 m,区域内地理环境复杂多样,地质构造较为发育,地形陡峭,受长江干支流水系侵蚀作用影响,使得区域内承灾体稳定性变差,易发生斜坡地灾。
(4)于山-武夷山斜坡地灾高易发区。位于江西东部低山丘陵区。地形上山岭连绵,丘陵广布,气候受海洋影响很深,年降水量1 400~1 900 mm。区内以构造侵蚀中低山为主,山高坡陡,地形地貌复杂,台风暴雨为本区斜坡地灾的最直接诱发因素。
4 结 论
(1)本文以斜坡地灾孕灾环境、诱发因素和动力学特征为依据,选取高程、坡度、坡向、工程岩组、断层距离、水系距离、震源距离、年均降水量、道路距离和地表形变10个因素作为评价因子,采用随机森林模型完成了长江流域斜坡地灾易发性评价,绘制了长江流域斜坡地灾易发性分区图,通过ROC曲线评估,模型AUC值为0.95,评价结果准确度较高。
(2)通过随机森林模型对评价因子重要性排序,可以看出高程和坡度对于长江流域斜坡地灾发生的贡献程度较高,年均降水量和地表形变贡献程度次之,坡向和道路距离对斜坡地灾的发生贡献较小。
(3)与中国地质调查局中国地质环境监测院发布的《中国崩塌滑坡泥石流易发程度图》对比,本次研究大幅度降低斜坡地灾中高易发区面积占比,提高了长江流域斜坡地灾中高易发区的精度。
(4)通过斜坡灾害易发性分区图,划分了4个斜坡地灾高易发区域,分别是四川盆地西斜坡地灾高易发区、秦岭-大巴山斜坡地灾高易发区、重庆-宜昌沿江斜坡地灾高易发区和于山-武夷山斜坡地灾高易发区。划分的区域内历史斜坡地灾点分布集中,可以为长江流域斜坡地灾防治和水利工程建设提供支持。
猜你喜欢
中国药学药品知识仓库(2022年9期)2022-05-23
大众科学(2022年5期)2022-05-18
今日农业(2021年10期)2021-11-27
今日农业(2021年1期)2021-03-19
疯狂英语·新悦读(2019年12期)2020-01-06
当代陕西(2019年6期)2019-04-17
中国环境监察(2018年10期)2018-11-14
天津诗人(2017年2期)2017-11-29
学习月刊(2016年14期)2016-07-11
有色金属设计(2014年4期)2014-03-11
