
基于Hadoop的NetCDF数据存储研究
2022-11-23 14:24:20任晓鸽
信息记录材料 2022年9期
任晓鸽
(许昌电气职业学院信息工程系 河南 许昌 461000)
0 引言
近年来,计算机技术的快速发展以及互联互通的网络普及,数据采集和传输变得越来越快速、便捷,从而形成了日益庞大而复杂的数据集。网络通用数据格式是面向海量矩阵数据的一种数据存储格式,能够存储高维监测数据,但NetCDF格式数据不便共享及移植。Hadoop可实现对数据的分布式存储,避免了传统服务器的高成本、低共享等弊端。然而Hadoop不能直接存储NetCDF格式数据[1]。
鉴于大数据系统缺乏对科学数据格式的支持,是数据驱动科学进一步采用大数据技术、进一步提高科学生产力的严重障碍。因此,本文基于Hadoop大数据框架,深入分析HDFS数据存写、分块架构,增加了Hadoop对NetCDF数据读写接口,提高了数据的可移植性和访问效率,使HDFS能够支持对NetCDF数据的存储。
1 基于Hadoop的数据存储框架
1.1 Hadoop架构
Hadoop是一个由Apache基金会开发维护的开源分布式计算与存储框架[2],可以支持Java等程序设计语言二次开发。Hadoop框架主要应用于对海量数据的存储与计算分析中,广义上的Hadoop是一个完整的生态系统,包括HDFS、Map Reduce、Hive、HBase等,架构如图1所示。而核心是HDFS文件存储及Map Reduce分布式计算[3]。

图1 Hadoop架构
1.2 HDFS文件系统
HDFS全称Hadoop Distributed File System,是大数据文件系统,主要负责存储和管理文件,帮助解决文件在底层的存储问题[4]。HDFS支持对海量数据的存储,并可以扩充节点以增加存储能力。HDFS开发需求源自对流数据模式的访问及对超大文件的处理,是分布式存储的基础,可在廉价的商用服务器上运行,并具有强大的容错能力,集群中的节点出现故障不会对系统使用产生影响。HDFS具有高容错、高效率、高可靠、高吞吐、高可伸缩、高获得性等特点。HDFS采用主从架构,集群中包含一个NameNode节点及若干DataNode节点。NameNode作为master,负责管理文件系统命名及客户端对文件操作,DataNode作为slave,负责管理节点数据存储,通常一个物理节点对应一个DataNode。其架构图如图2所示。

图2 HDFS系统架构
1.3 Map Reduce
Map Reduce是处理大规模数据的一种并行计算模型,由Google公司提出。该编程框架可由众多普通服务器构成集群,把大规模的数据集分发到单个节点,采用“分而治之、化繁为简”的思想[5],集群分节点并行处理所分发计算任务,主节点管理分节点并汇总任务结果。简而言之,Map Reduce由Map和Reduce两个阶段组成,Map服务任务分发,Reduce服务任务汇总,即可实现分布式并行计算[6]。
1.4 Zookeeper
Zookeeper是一个分布式协调服务框架,该框架可实现对分布式应用配置项管理,提供状态同步、集群管理等服务。Zookeeper是基于观察者的设计模式,主要负责对数据状态的监管,一旦变化,则通知已注册观察者。Zookeeper集群中节点数目往往是大于等于3的奇数,若主节点出现故障,剩余节点大于一半时,则产生新的主节点,继续提供服务。
1.5 Hive
Hive是基于Hadoop体系的一个数据仓库工具,是Facebook公司管理海量社交数据所研发的仓库工具。HDFS可存储结构化和非结构化数据,Hive处理其中的结构化数据文件,可将结构化的数据文件映射为一张数据表。另外,Hive提供有SQL查询功能,该功能可将SQL语句转化为Map Reduce任务进行并行计算。
1.6 HBase
HBase是面向分布式、面向列的一个开源数据库。HBase源于Fay Chang的一篇名为《Bigtable:一个结构化数据的分布式存储系统》论文。如Bigtable使用Google File System所提供分布式存储,HBase在Hadoop上提供了类似Bigtable的功能。不同于一般关系型数据库,HBase是基于列模式适用于非结构化数据存储的数据库。
2 基于Hadoop的NetCDF数据存储方案
2.1 地表径流数据应用于分布式存储的设计分析
随着计算机技术的快速发展以及互联互通的网络普及,数据采集和传输变得越来越快速、便捷,从而形成了日益庞大而复杂的数据集。面对海量数据,我们需要从中挖掘出一般信息来指导各种各样决策。气象卫星、水文监测站等数据监测设备种类繁多,因每个设备的数据采集系统接收和存储的数据格式不一致,所以采集的数据在共享上存在相互不兼容的现象。地表径流等科学数据为解决多源数据格式差异问题,避免因生成的数据文件格式类型不同造成的差异,以方便科研数据共享、提高研发效率,使用在国内外科研领域有一定执行标准的规范格式作为数据格式转换的目标格式。网络通用数据格式,全称Network Common Data Form(NetCDF),就是面向海量矩阵数据的一种数据存储格式,能够存储高维科研监测数据。现已成为气象、海洋等科学研究领域广泛采用的一种通用的数据存储格式。本文测试数据集为地表径流数据集,就是基于NetCDF格式存储。
地表径流数据往往是多维的,包含时间、空间及变量等信息,数据存储以单文件为单位。NetCDF中的维、变量、属性需要用标准的语法结构来进行说明,数据文件结构包含如下内容:

NetCDF的数学意义相当于具有多个自变量的单值函数。该单值函数的数学表达式可描述为f(x,y,z)=value。其中,f函数中的自变量x,y,z在NetCDF中叫作维,函数值value在NetCDF中叫作变量。函数值和自变量的性质,如单位等,在NetCDF中就叫作属性。
地表径流数据集是由大量传感器等观测设备采集汇聚而成,除了具备高维度、高规模、高增速、高实时等特点外,还具备一些其他特点。首先,地表径流数据集具有高访问性,写入数据后,系统要多次访问,修改删除操作较少,事务性要求低,而Hadoop分布式存储框架具有较高的读取效率,符合对该类数据的存储。其次,地表径流数据内容中,具有时空信息属性。地理空间信息以经纬度来体现,时间以数据观测采集时间点来体现。数据满足散列性原则,可以提高多机负载均衡,降低同时空数据的热点集中。将地表径流数据进行分布式存储也面临一些问题,如对非结构化的小文件存储,每一个文件都会在HDFS中占据一个block,这些block会在NameNode中占据一定的内存空间以便映射到DataNode,一定程度增加了NameNode的高负载,影响集群性能。因此,需要对数据文件进行预处理,以提高集群性能。
综上所述,对于地表径流数据的分布式存储,Hadoop分布式存储具有较高的效率。
2.2 地表径流数据分布式存储系统搭建
对于NetCDF格式的地表径流数据,本文采用HDFS分布式存储架构,将地表径流数据分块存储于集群中的节点上,通过设置分块大小及数据副本,提高系统容错性,以实现对数据的高效存储及安全维护。Unidata提供了针对NetCDF的Java库,本文基于Java库改进了接口对于NetCDF数据的读取,写入数据到HDFS集群上,如图3所示。

图3 NetCDF写入HDFS
集群主客户端对地表径流数据集进行分片,由于地表径流数据的时空紧密性,因此很难对一个完整的NetCDF分片时保证完整性。本文编写自定义映射程序来分析NetCDF数据属性等信息,依赖索引使Hadoop可以按键进行数据解析。首先,创建HDFSClient的实例,即Distributed File System,调用create方法创建文件;其次,Distributed File System实例对象在NameNode节点创建新文件;再次,当文件检查通过后,返回一个FSDataOutputStream写入数据的输出流对象,调用create方法,就可写入NetCDF数据到DataNode节点。
2.3 地表径流数据分布式存储接口设计
对于NetCDF格式的地表径流数据,Unidata提供的NetCDF的Java库只适用于读取本地文件。本文在深入分析接口读写逻辑基础上,复写了函数库的读写接口,该接口可以方便地对HDFS存储文件进行读取操作,设计流程图如图4所示。

图4 HDFS下NetCDF读取
2.4 地表径流数据分布式存储性能优化
分布式文件系统的存储性能可由文件操作响应速度及可靠性来体现。对于Hadoop分布式框架来讲,其节点是可扩展的,因此分布式存储节点的拓展性可保证数据的安全可靠。而响应速度依赖于Hadoop框架的启动时间、单节点的耗时及集群的并发数。而并发数依赖于并发任务极值数和数据分块极值数,并发任务极值数和服务器性能呈正相关,数据分块极值数和写入HDFS分块大小值呈负相关。

其中,T总为响应总时长;THadoop为Hadoop框架启动时长;T单节点为单节点响应时长;CPU为服务器核心数;H阈值为HDFS分布式存储框架存放文件分块大小,相对其他影响因素,分块大小成为可调参数。因此,可通过调整分块大小测试其效率。通过设置分块大小依次为32 M、64 M、128 M、256 M,并执行3次实验,其响应速度如表1所示。

表1 HDFS数据块参数调优实验
对比实验结果,数据响应时间受数据块大小影响明显。如果数据块阈值设置过小,则会产生大量数据文件,从而产生大量任务,增加了任务开销。如果数据块阈值设置过大,则数据文件降低,任务数随之降低,但单节点数据处理时间递增,会耗费集群资源,降低响应速度。本实验结果表明,将集群数据块阈值设置为64 M时,对地表径流数据的响应速度最快。
3 实验分析
通过上文对该架构的需求分析、架构设计与功能实现,完成了基于Hadoop的NetCDF数据存储架构。借助3台16G内存、6核12线程、2T硬盘服务器搭建Hadoop集群。数据集为2012年黄河某段地表径流数据,大小为45G。如表2所示。
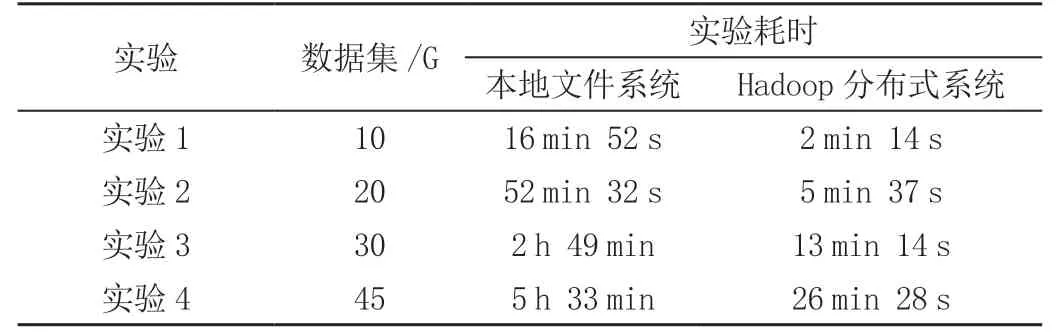
表2 Hadoop分布式框架与本地文件系统效率对比
对比实验结果,采用Hadoop分布式存储框架处理地表径流数据,相比传统的本地文件存储系统速度要快,并在数据集越大时,效率越高。如在数据集为45 G时,Hadoop分布式存储仅仅需要26 min就可完成数据的写入处理,而本地文件系统需要5~6 min才能完成。实验表明,Hadoop分布式存储框架在对地表径流数据存储方面效率更高,为后续科学计算提供了基础。
4 结语
综上所述,Hadoop分布式架构自身具有的高容错、高效率、高可靠、高吞吐量、高可伸缩、高获得性等优点,对于解决海量数据分布式存储、计算具有重要意义。本文基于Hadoop的NetCDF数据存储研究,设计了HDFS针对NetCDF数据的读写访问接口,实现了NetCDF格式数据的共享及移植和用Hadoop存储NetCDF数据。通过该方法避免了Hadoop读写NetCDF时预先转换NetCDF数据所产生的大量中间数据集问题,降低了存储开销,提高了读取操作响应效率,为NetCDF的分布式计算奠定了一定基础。
猜你喜欢
山东农业工程学院学报(2020年12期)2020-03-19 01:58:44
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
电子制作(2018年11期)2018-08-04 03:25:40
中国交通信息化(2017年3期)2017-06-08 06:09:28
知识就是力量(2017年2期)2017-01-21 18:29:36
湖州师范学院学报(2016年2期)2016-08-21 13:50:52
水利科技与经济(2016年9期)2016-04-22 01:07:12
山西大同大学学报(自然科学版)(2016年6期)2016-01-30 08:29:19
地理与地理信息科学(2015年4期)2015-10-13 08:29:16
交通建设与管理(2015年15期)2015-03-20 15:19:31
