
基于文献计量学的食品掺假研究进展
2022-11-21 09:24:36韦秋玲黄丹萍
现代食品 2022年20期
◎ 陈 斌,韦秋玲,黄丹萍,李 娟
(1.南京工业大学 食品与轻工学院,江苏 南京 211816;2.国家轻工业食品质量监督检测南京站,江苏 南京 211816)
随着我国经济的快速增长、食品工业的快速发展和食品安全控制水平的不断提高,食品工业也成为我国最重要的产业。食品原料、生产和经营全环节的掺假现象越来越明显,我国已将食品掺假和欺诈纳入政府对食品安全危机的监管[1-4]。食品掺假和鉴别方法的研究,如真实性测定、品种鉴定、质量评估、可追溯性验证、地理标志、原产地保护和标签符合性等,已成为国内外食品质量和安全研究的新焦点。
本文研究结果可以较全面地反映食品掺假鉴定的最新研究动态和局限性,以便该领域研究者了解该研究领域的发展趋势,为食品掺假鉴定和追溯领域的研究者和机构提供参考,避免重复研究浪费研究资源,为相关管理部门提供决策支持。
1 材料与方法
1.1 数据来源
以CNKI全文数据库为基础,以核心期刊为检索数据源,以“食品”为主题词,“掺假”“肉类掺假”“蜂蜜掺假”等相似词为关键词进行检索。经过人工审核和初步评估,排除了不含关键词或与食品掺假研究无关的文献,并排除了政府工作文件和报告等非研究性文献,最终获得了789篇有关食品掺假研究的文献。
1.2 主要研究方法和工具
应用文献计量学方法并利用Cite Space分析筛选得出的789篇文献。Cite Space应用程序是一种动态的、多功能的、有时间差异的信息可视化方法,用于复杂的网络分析,已经成为文献计量学中广泛使用的新方法,被广泛应用于各个领域。因此,通过应用文献计量学方法对科技期刊的出版物进行统计和分析,可以有效地分析学科发展脉络,识别学科知识基础,捕捉到研究的焦点及研究前沿,探索该领域的动态方向。该分析包括一般情况和具体鉴别技术,总体情况分析是对食品掺假领域的所有数据按时间顺序、作者、机构的发文量进行分析;具体技术分析的重点是不同阶段的关键词即不同时间段的研究前沿以及作者合作发表文章情况。
2 结果与分析
2.1 发文量分析
发表文章的数量和变化可作为衡量一个学科发展水平的重要指标,因此对发文量进行分析有助于研究人员在一定程度上了解食品掺假研究的范围和速度。2000—2021年期间发表的有关食品掺假的研究文章数量如图1所示。我国发表的有关食品掺假的文章数量在2000—2021年总体呈现增长态势,在2000—2007年发文量增加趋于平缓,在2008—2011年缓慢增长,2012—2021年增长迅速,特别是2018—2021年发文量呈快速上升趋势。2008年后文章数量增长迅速可能与2008年的三聚氰胺奶粉事件有关,三聚氰胺事件的发生使消费者更加关注食品安全问题,也将我国的食品掺假研究推向高峰。2011年双汇“瘦肉精”事件和2012老酸奶“工业明胶”事件,让我国消费者再次对食品安全失去信任,再次将我国的食品掺假研究引入高潮,2014年国家部署建设“国家食品安全示范城市”也使我国在食品掺假相关方面的研究更加深入。
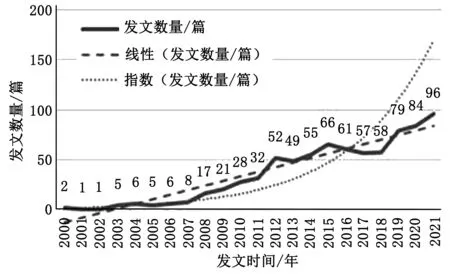
图1 发文量折线图
对食品掺假相关文献的发文数量进行拟合,建立线性方程为y=4.560 7x-16.584,指数函数为y=1.581 2e0.2126x,R²分别为0.931 8和0.814,说明食品掺假文献的数量遵循线性关系,即研究数量呈线性增长,对学术研究领域的持久影响小于指数型。
2.2 关键词分析
关键词是文献的精华,是高度的概括和文字总结,也是文献计量指标之一。一个关键词出现的频率越高,它就越有可能与其他关键词一起共现,在共现网络的知识图谱中的影响力也就越大。在知识存储方面,中心度高的关键词通常是该时期研究领域的热点话题,这意味着它是一个研究热点。
关键词分析可以通过突出使用频率最高的关键词来分析和解释研究热点,基于Cite Space软件,来自789篇食品掺假研究文献的关键词被作为分析的数据。主控界面的节点类型被设置为关键词,Selection Criteria区域选择g-index,结果有452个有效节点,808条连线。每个节点代表一个关键词,节点越大,出现的频率越高,节点之间的连接线代表关键词之间关系的密切程度。
选用对数似然率(Log Likelihood Ratio,LLR)算法对关键词进行聚类,形成食品掺假的聚类图。聚类模块化指数Q的值为0.662 8,高于0.3,表明得到的聚类结构是显著的;聚类平均轮廓性指数S值为0.894 5,大于0.5,表明聚类效果是合理可信的。从聚类图(图2)和聚类列表(表1)可以看出,根据2000—2021年相关文献的关键词,可以得到12个聚类,每个聚类由多个密切相关的词组成。聚类值在10以下的关键词不具有研究价值,因此排除#11近红外、#12拉曼光谱;聚类轮廓值均在0.9以上(表1),表明研究主题的区分是显著和有用的。对各组的标签和标识词进行了分析,发现有重叠之处,因此将这12个组分为以下3类,并在结合文献分析加以讨论。
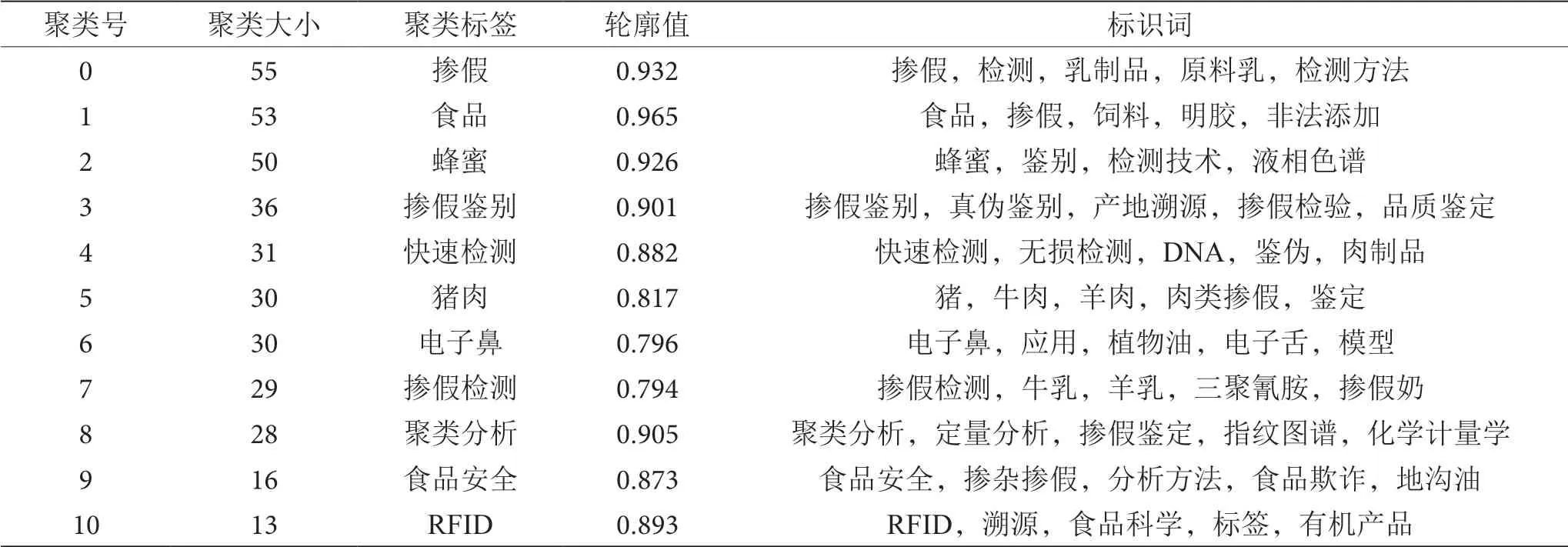
表1 关键词聚类信息表
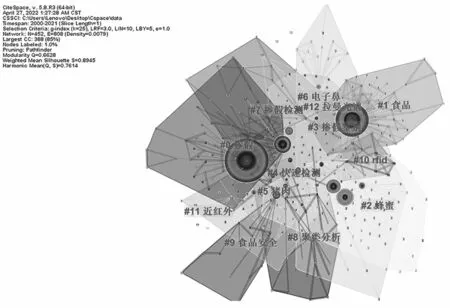
图2 关键词聚类图
第一类:聚类#0掺假、#3掺假鉴别、#4快速检测、#7掺假检测均着重于检测这一主题,因此归为一类进行论述。
第二类:聚类#1食品、#2蜂蜜、#5猪肉分为一类,介绍我国目前发现食品种类掺假的研究现状。
第三类:聚类#6电子鼻、#10 RFID、#11近红外、#12拉曼光谱并为一类,论述食品检测技术研究进展。
2.3 作者分析
对作者合作网络进行分析,能够获知食品掺假领域代表学者和核心研究力量。在Cite Space将关键词的最小出现次数设定为5,这意味着作者的出现次数大于或等于5。节点越大,频率越高,节点之间的线表示作者曾经共同发表文章和紧密程度,作者姓名的字体大小与论文数量之间存在正相关。经统计,789篇文献共来自574位作者。
由图3可知,作者合作团体主要有以陈颖、张九凯、张舒亚为中心的学术团队合作,以冼燕萍、罗海英、郭新东为中心的团队合作,以丁涛、吴斌、费晓庆为中心的学术团队合作,以王晓伟、乔晓玲为中心的合作团队,还有以张慧为中心的学术合作。其中,陈颖与张九凯、吴亚君、葛毅强和刑冉冉4人均有2次或以上合作,由此可见陈颖、张九凯、吴亚君、葛毅强和邢冉冉5位学者合作密切,其余作者大部分发文较少或独立发文。

图3 作者合作图
2.4 食品种类分析
陈颖等[2]分析发现,最开始研究食品掺假的食品是食用油、牛奶及奶制品。随着生活水平的提高和人们饮食模式的多样化,食品的种类随之增加,食品掺假方式也更多样化,对食品类型的分析将逐步扩展到谷类产品、肉类产品、水产品、酒类、果汁[5]、饮料和蜂蜜等产品。
经Cite Space对关键词可视化分析,依据食品种类相关数据绘制图4。由图4可知,2000—2021年肉类产品占掺假领域研究的32%,奶乳制品次之,对于酒、饮料的掺假研究较少。张伟等[6]对植源性食品掺假进行研究,发现对果汁和葡萄酒以外植源性食品的掺假鉴定研究较少,提出建立更完整的数据库,以促使食品掺假鉴定更加规范化和标准化,并认为未来稳定同位素是一个发展方向。
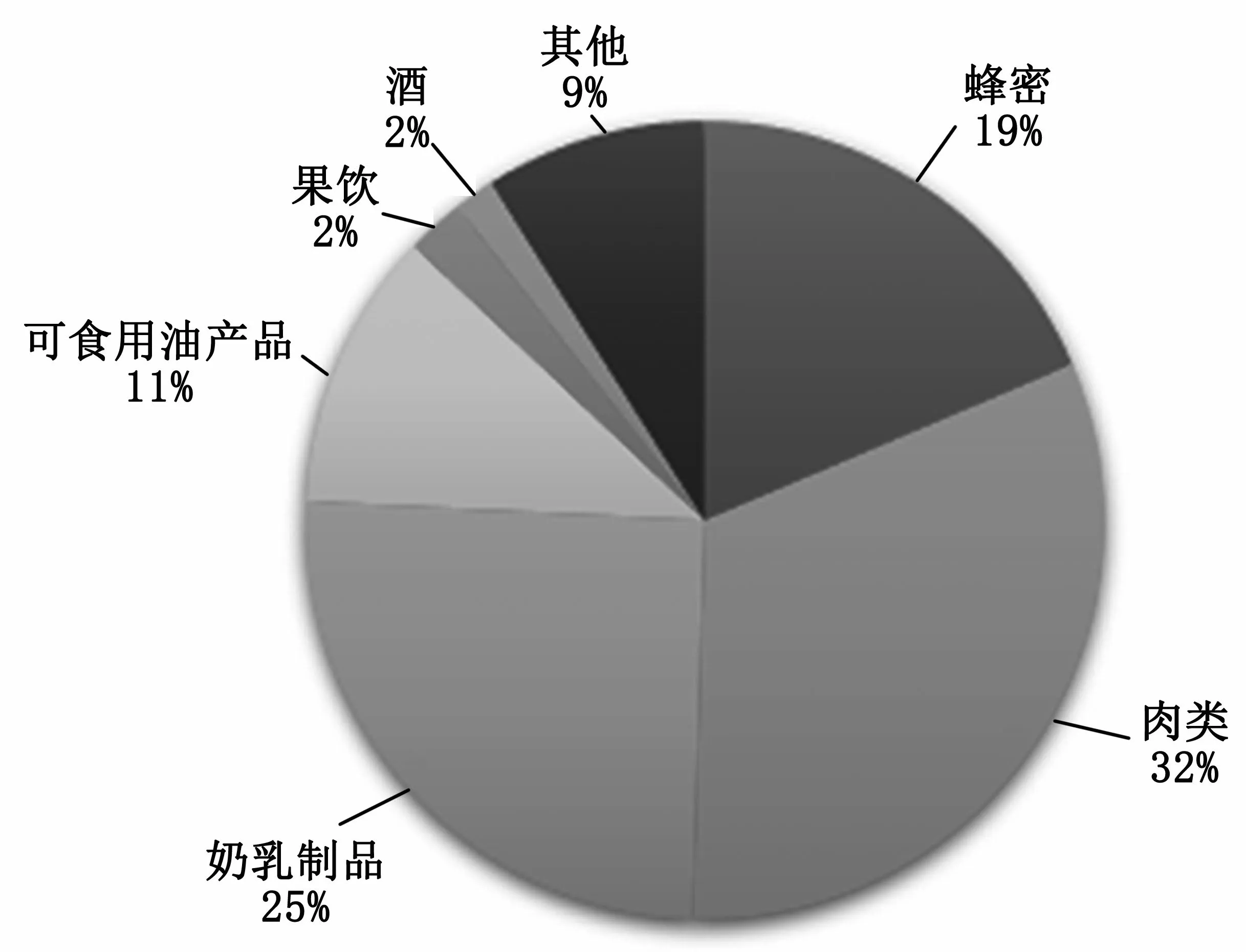
图4 研究食品种类饼状图
3 结语
本文对CNKI数据库中关于食品掺假的研究文献进行检索,并从发文量、关键词、高产作者等方面对2000—2021年的相关文献进行了可视化分析。近年来,我国的食品掺假发文数量不断增加,今后还将继续增加,这主要是由于食品安全事件的频繁发生和现代社会对食品安全问题的持续关注,这将促进食品掺假研究的不断深入和发展[7]。在实践中,食品安全掺假是一个动态变化的过程,不同的发展阶段,食品掺假监管的困境也大不相同[8-9]。只有保持不断发现、分析和解决与社会发展水平相关问题的态度,才能明确食品掺假监管研究的方向,从而为食品掺假监管提出有效 对策。
猜你喜欢
保健医苑(2022年6期)2022-07-08 01:26:00
今日农业(2020年14期)2020-08-14 01:10:16
少儿美术(快乐历史地理)(2018年3期)2018-09-25 02:49:42
阅读(低年级)(2018年10期)2018-05-14 20:42:01
阅读(低年级)(2018年11期)2018-05-14 09:37:53
阅读(低年级)(2018年12期)2018-03-23 11:39:02
电子测试(2017年15期)2017-12-18 07:19:27
Coco薇(2016年7期)2016-06-28 19:07:36
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
