
面向巡检机器人的指针式仪表读数识别方法
2022-11-21 04:38莫明飞高阿朋周明哲
电力大数据 2022年4期
莫明飞,高阿朋,周明哲
(国网内蒙古东部电力有限公司,内蒙古 呼和浩特 010010)
变电站内由于高低压回路设备操作、雷电浪涌、输电线路辐射等会产生大量的电磁干扰,而指针式仪表具有构造简单、抗干扰性强的特点,被广泛地部署在变电站内,常见的有SF6压力表、避雷器泄漏电流表、油温表、液压表、绕组温度表等。变电站巡检中一项重要的工作是获得大量仪表的读数,用于判断各类电力设备是否正常工作。由于人工巡检的效率较低,且对于巡检员来说具有一定的危险性,近年来已逐渐采用巡检机器人替代人工进行巡检[1-2]。面对巡检机器人采集的大量的变电站指针式仪表的图片,研发一种高效准确获得仪表读数的算法,对于提升变电站巡检效率、保障电网系统稳定运行有着十分重要的理论意义和应用价值[3-5]。
现阶段已有一些针对不同类型指针仪表读数识别的研究成果[6-9],传统方法是首先利用基于模板匹配[10]、基于特征点检测匹配[11-12]等方法进行仪表定位,然后二值化仪表的表盘图像,再利用基于霍夫变换、快速直线检测、Canny边缘检测[13]等方法检测指针及刻度,最终完成自动读数。这类方法在检测仪表时,大多会选择尺度不变特征变换(scale-invariant feature transform, SIFT)、ORB等特征点检测匹配算法,但复杂场景中仪表图像存在较多遮挡、形变等情况,会使角点检测产生大量误匹配。而且这类方法对图像中仪表的位置、仪表图像的清晰度、是否有遮挡等都有较高要求,如果仪表表盘存在干扰条纹,则会对指针、刻度线段的识别造成很大影响。除传统方法外,文献[14]提出了最大类间方差算法来提取仪表指针区域,然后通过增加约束条件来提升基于霍夫变换进行指针角度识别的精度。文献[15]利用二进制描述器获取表盘区域,再利用圆周区域累积直方图(circle based regional cumulative histogram, CRH)方法确定指针位置。文献[16]采用区域增长和中心投影的方法来定位表盘刻度区域及刻度,然后利用霍夫变化方法通过指针轮廓拟合得到指针方向。随着深度学习技术的广泛应用,也有研究人员利用基于深度学习的目标检测方法进行仪表定位,如文献[17-19]分别利用CNN、Mask-RCNN、改进的YOLOv3来检测复杂背景中的仪表,相对于传统方法来说,在仪表检测的准确率上有了较大的提高。但上述方法在检测指针及刻度时,多数仍采用传统方法,限制了其实用性。
但是现有的研究多数都是针对高质量的仪表图像进行检测和识别,即输入的图像中表盘区域较大、表盘图像非常清晰、拍摄时相机基本与表盘无夹角。若让巡检机器人拍摄的仪表图像满足上述要求,需要人工提前进行大量的测量、标定和调试工作,这在实际操作过程中很难完成,而且变电站内仪表的安装位置、盘表的朝向等条件未必能够满足高质量图像的采集要求。所以,利用巡检机器人拍摄的原始图像通常都具有以下特点:(1)具有较为复杂的背景;(2)仪表盘表面通常会附有污浊物;(3)仪表表盘与图像平面存在夹角。在这种情况下,这些方法则很难满足巡检机器人场景中的实际使用要求。
针对巡检机器人采集的仪表图像,本文首先通过基于深度学习的目标检测网络(YOLOv5)准确定位复杂背景中的仪表位置,排除画面中其他物体对后续处理的影响。然后通过轮廓拟合、透视变换的方法对表盘倾斜进行校准。针对矫正后的仪表表盘图像,利用改进后的Deeplabv3+模型对表盘图像进行图像分割,获得表针及刻度。最后通过极坐标转换的方法将表盘展开成矩形,在矩形表盘上定位刻度与指针后计算获得仪表的读数。本文研究的内容一方面分析了巡检机器人拍摄的仪表照片的特点,并针对这些特点在关键步骤上引入了基于深度学习的方法,解决了传统方法处理这些问题时的不足,有效地提升了仪表读数计算的准确性;另一方面通过对Deeplabv3+模型的改进,提供了更细粒度的高维空间语义分割能力,实现密集性目标的定位分割,提高了分割表盘刻度和指针的准确率。
1 指针式仪表读数自动识别方法
针对巡检机器人获取图像数据的特点及传统识别方法的不足,本文采用了基于深度学习的仪表检测和仪表刻度指针分割方法,通过准确定位表盘图像并精准分割刻度线和指针,实现自动准确的识别仪表读数。
本文提出的方法思路如下:首先,利用基于深度学习的目标检测模型(YOLOv5),检测巡检机器人拍摄的图像中的仪表,同时获得仪表的类型,使得后续处理只用分析仪表本体的图像,不用考虑背景干扰,达到减轻后续分析计算量的目的;其次,针对获取到的仪表表盘图像,通过透视变换算法对其进行校准,使得图像中的表盘恢复为圆形且仪表刻度分布均匀,有利于提升后续分割处理的精准度;再次,针对仪表刻度和指针的特点(目标密集、刻度和指针尺寸相差较大),利用本文改进后的Deeplabv3+图像分割技术,对表盘中的刻度和指针进行精准分割,获得只包含刻度和指针像素的分割图像;最后,利用图像极坐标转换等方法,结合仪表类型信息,对分割结果图像进行分析,最终得到仪表的读数信息。基本过程如图1所示。

图1 指针仪表读数自动识别过程Fig.1 Automatic recognition process of pointer instrument reading
2 基于YOLOv5的仪表检测
2.1 YOLOv5网络结构简述
基于深度学习的目标检测算法主要可以分为两类:两阶段检测算法和单阶段检测算法[20-23]。前一种类型首先是找到目标出现位置的众多候选区域,再使用卷积神经网络对候选区域进行分类,在每个类别中使用非极大值抑制来得到目标的最终位置,主要代表就是R-CNN(regions with CNN features)系列[24],其中以Faster-RCNN性能最优[25];后一种类型将目标检测视为回归问题,省去了生成候选区域阶段,直接由网络产生目标的位置坐标和类别概率,主要代表模型有SSD系列[26]和YOLO系列。
最新的YOLOv5于2020年推出,属于目前非常优秀的检测网络。YOLOv5共分为YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x四个模型,在网络复杂程度上和准确率依次递增、处理速度依次下降,可以适用于不同要求的应用场景。虽然四个模型在网络规模上有所不同,但都包含输入模块(input)、主干网络(backbone)、特征融合模块(neck)和预测模块(prediction),具体如图2所示。

图2 YOLOv5网络结构Fig.2 YOLOv5 networkstructure
为了丰富输入的数据集,YOLOv5在输入模块中加入了Mosaic方法,对输入的图像进行多种随机操作以实现数据增强的目的,包括随机的缩放、裁剪、排布等,让网络能够更好地学习和识别小目标。YOLOv5还加入了自适应计算初始锚框的能力,在训练阶段时,可以自动计算不同训练集的最佳初始锚框,不断迭代更新,使网络在训练阶段具有更好的适应性,而不必像YOLOv3或者YOLOv4那样还需要单独运行相应的计算程序,并且在训练过程中无法更新。此外,YOLOv5还改进了自适应缩放的算法,以增加网络的推理速度。
主干网络采用了Focus结构和CSP结构。其中,Focus结构的关键是进行切片操作,例如输入图像的分辨率为608×608×3,经过切片操作和32个卷积核的卷积操作后,最终变成304×304×32的特征图。YOLOv5中包含了两种CSP结构:CSP1_X结构和CSP2_X结构,前者应用在主干网络中,后者应用在特征融合模块中。
特征融合模块使用了特征金字塔网络(FPN)和金字塔注意力网络(PAN)融合的结构。特征金字塔网络采用自顶向下的方法,利用上采样融合、传递高层特征信息。金字塔注意力网络则采用自底向上的方式传递强定位特征。两者同时使用以加强网络特征融合能力。
在YOLOv5的预测模块中,候选框的损失函数未采用传统的IOU_Loss,而是采用了改进后的CIOU_Loss,考虑了真实框和候选框高宽比的尺度信息,提高了候选框的回归效率和准确率。在后处理阶段,针对目标遮挡的情况,YOLOv5采用了加权后的非极大值抑制,使其对于被遮挡目标的检测性能有所提升。
2.2 YOLOv5在仪表检测中的应用
在巡检机器人拍摄的图像中,仪表表盘区域占比通常较小,需要采用高准确率的检测模型。在YOLOv5的四个模型中,YOLOv5x拥有最大的网络深度,如表1所示。

表1 YOLOv5残差组件列表Tab.1 YOLOv5 residual components list
YOLOv5x在CSP1和CSP2结构中都拥有最多的残差组件,如在第一个CSP1结构中使用了4个残差组件,即CSP1_4,其他类似。随着网络的不断加深,图像的特征可以更有效的被提取出来,并进行融合。同时,YOLOv5结构在不同阶段的卷积核的数量也是不一样的,例如在第一个Focus结构中,YOLOv5x拥有80个卷积核,最轻量的YOLOv5s只有32个卷积核,YOLOv5x的卷积核是YOLOv5s的2.5倍。卷积核的数量越多,网络提取图像特征的学习能力也越强。所以,在保证准确率的前提下,本文选择YOLOv5x模型检测巡检图像中的仪表表盘区域。
针对巡检机器人拍摄的各类仪表图像,本文使用开源的图像数据标注工具制作训练集:在巡检图像中框选仪表表盘,并输入仪表类型的标签。同时,为了保证模型的泛化性和准确率,训练集由不同时间、天气、光照、角度的图像组成,并加入占总量约1%的背景图像(即图像中没有仪表)来减少误报。训练的过程中为了加快训练速度,通过weights标志加载了预训练的权重。图3展示了训练后的YOLOv5x模型的检测效果,从检测的结果可以发现,在不同的条件下,YOLOv5x模型均可以准确地检测到图像中的仪表表盘,并正确的给出仪表的类型,说明训练的模型达到预期的效果。

图3 YOLOv5x仪表表盘检测结果Fig.3 Instrument dial detection result by YOLOv5x
3 透视变换仪表图像校准
由于巡检机器人的摄像头在拍摄图像时很难与仪表完全保持平行,所以通过YOLOv5x检测和提取到的仪表表盘图像多数会存在一定的倾斜,导致表盘形状不规则、刻度不均匀等问题,对后续的处理产生影响。所以,本文利用透视变换算法对表盘图像进行校准。
透视变换的基本原理是将原图片平面投影到三维空间,然后再映射到一个新的视平面。假设原图像上点的坐标是(x,y,z),通常设置z=1,在三维投影空间中的坐标为(X,Y,Z),在新视平面的坐标为(x′,y′,z′),投影变换矩阵为T,则有:
(1)
(2)
(3)
针对每类仪表,提前获取该类仪表的模板图像,即摄像头与仪表表盘平行时拍摄的图像。对于巡检机器人拍摄的仪表图像,根据YOLOv5x的分类结果选取相应类别的模板图像,获取仪表图像和模板图像上匹配的特征点对及其坐标,利用公式(1)计算得到投影变换矩阵T,然后根据投影变换矩阵T以及公式(2)和公式(3)对提取到的仪表图像进行校准。图4为利用上述方法校准表盘图像的样例。

(a)原仪表图像 (b)校准后图像(a)Original (b)After calibration图4 仪表表盘校准结果Fig.4 Instrument dial calibration result
4 基于DeepLabv3+的仪表刻度及指针分割
4.1 Deeplabv3+在仪表图像分割应用中存在的不足
Deeplabv3+的网络结构采用Encoder+Decoder的编解码方式,很好地解决了以往图像分割边界定位不准确的问题。所采用的空洞卷积金字塔池化的方式,有效地降低了参数数列,提高了网路推理计算效率。Deeplabv3+优点具体表现两点:(1)在Encoder端,采用不同rate的空洞卷积来实现空洞卷积的空间金字塔池化ASPP(atrous spatial pyramid pooling)模块,进一步扩展了网络模型的高层多尺度信息。空洞卷积是DeepLabv3+模型的关键,其感受野更大,可以在保持运算量的同时不减小特征尺寸,从而获得更密集的特征信息。(2)在Decoder端,模型结构融合了DCNN(depth CNN)的浅层特征(low-level features)信息来提升图像分割的边界精度。
由于仪表的刻度通常都较为密集、刻度和指针的体积相差也较大,且表盘上多数情况下会有污浊物。直接将Deeplabv3+应用于仪表刻度和指针分割时时会碰到以下不足:(1)DCNN中的高层特征具有局部图像变换的内在不变性,使得网络结构可以Decoder阶段学习越来越抽象的特征表示。但DCNN中的池化操作或者下采样方法,都会引起的特征分辨率的下降,DeepLabv3系列解决这一问题的方法是使用空洞卷积,它使得模型结构在保持参数量和计算量的同时提升计算特征响应的分辨率,从而获得更多的上下文。但对图像中密集性目标的定位预测任务时,需要更为丰富的高层空间信息。(2)Decoder阶段仅仅融合了网络Encoder的单个浅层信息,其有效信息具有一定的局限性,导致在多尺度目标分割时信息损失较多,会造成精度下降。
4.2 Deeplabv3+在仪表图像分割中的改进
针对上述不足,本文对Deeplabv3+进行了如下改进。
(1)在Encoder端使用了基于Jigsaw Patches的渐进式多粒度编码学习
渐进式训练方法最初是针对生成式高级网络提出的,它从低分辨率图像开始,然后通过向网络中添加层来逐步提高分辨率。这种策略不需要学习所有尺度的信息,而是允许网络发现图像分布的大规模结构,然后将注意力转移到尺度越来越小的细节上。
本文针对仪表刻度的特点,提出以拼图补丁(jigsaw patches)的数据输入方式,进行阶梯式渐进特征编码的训练学习方法,改进后的网络结构如图5所示。
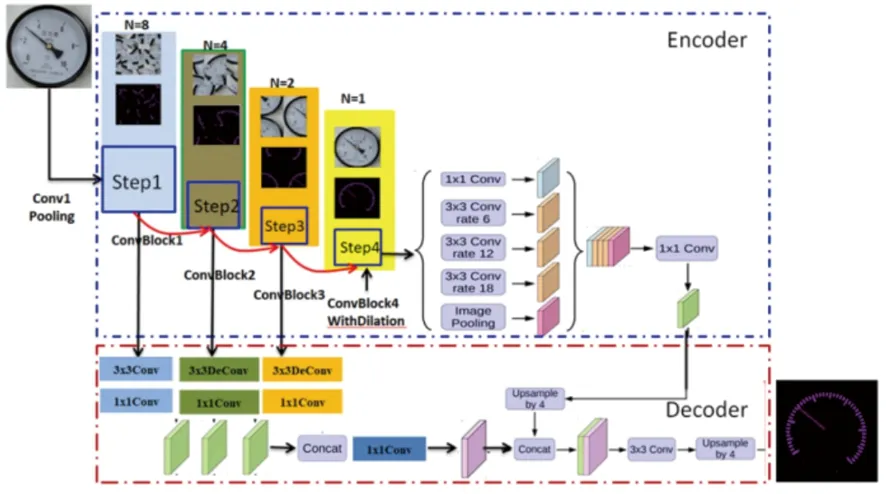
图5 基于Jigsaw-Patches的渐进式编、解码结构Fig.5 Progressive encoding and decoding structure based on Jigsaw-Patches
在Encoder表征学习中,使用拼图的方法为渐进式训练的不同步骤生成输入原始图像和标签图像,实现密集性目标的定位分割预测,提供更为细粒的高维空间语义分割能力,同时针对类间距微小的不同分割对象,提供更精细粒度的特征。同时,该方法可有效地解决数据源单一的问题,提高模型的泛化能。基于Jigsaw-Patches的渐进式编码结构参数表如下所示。

表2 基于Jigsaw-Patches的渐进式编码结构参数表Tab.2 Progressive encoding and decoding structure parameters

续表2
(2)在Decoder端改进了多尺度特征融合解码方式
深层网络的感受野比较大,语义信息表征能力强,但是下采样会导致特征图尺寸越来越小,使得特征图缺乏几何特征细节;相反,低层网络的感受野比较小,但由于特征图的分辨率较高,拥有较多的几何特征细节,但是缺乏语义特征信息。在本文的Decoder端中,采用了低维与浅高层特征融合增强的方式,其目的在于增大尺度空间上的感受视野,保留不同层级的语义信息,防止关键的细微特征丢失。也就是在保留空间信息的同时,使得语义信息保持不变,提升分割边界准确度,一定程度上解决了表盘污浊时的分割问题。
本文以Step1、Step2、Step3的Jigsaw Patches输出特征分别作为ConvBlock1、ConvBlock2、ConvBlock3的输入,然后将ConvBlock1、ConvBlock2、ConvBlock3输出的浅层特征(low features)进行融合拼接,实现改进的多尺度浅层特征融合,具体如图6所示。

图6 改进的多尺度浅层特征融合结构Fig.6 Improved multi-scale shallow feature fusion structure
基于改进后的Deeplabv3+进行仪表刻度和表针分割的结果如图7所示,测试结果显示刻度和指针的像素分类结果基本正确,说明文本改进的Deeplabv3+网络能够准确地从表盘背景中分离刻度和指针。在获得分割图像后,还可以对分割图进行腐蚀操作,进一步消除分割图像中的噪声。

(a)仪表表盘原图 (b)分割图 (c)腐蚀后的分割图(a)Original (b)Segmentation (c)Segmentation after corrosion图7 仪表刻度和指针分割效果图Fig.7 Example of instrument scale and pointer segmentation
5 仪表读数识别
巡检机器人拍摄的图像通过仪表检测、图像校准、仪表刻度指针分割的处理后,可以得到表盘的最小外接矩形框,以及刻度线和指针线在图像中的位置。以目标检测结果矩形框的中心点为基点,利用图像极坐标转换方法,将圆弧状的表盘刻度展开为矩形,具体如图8所示。

(a)展开前 (b)展开后(a)Before streching (b)After streching图8 仪表刻度展开处理示例Fig.8 Example of instrument scale expansion
利用图像投影法对仪表刻度展开后的结果图进行处理,将所有像素投影到x轴方向,包括刻度像素与指针像素。经投影计算后,二维的展开图转换成为一维数组。其中,一维数组的长度为原展开图像的图像长度。局部投影结果如图9所示。

图9 仪表刻度展开图局部投影结果Fig.9 Local projection of instrument scale expansion
得到一维数组后,对一维数组中非零的区域做均值处理,具体的计算方法是,将每个局部非零区域的最小下标与最大下标相加求均值,得出所有刻度和指针的位置,即可以定位指针在刻度中的哪个区间内。然后根据目标检测结果给出的仪表类型,获得预设的仪表的测量上限值和测量下限值,利用仪表量程(量程=测量上限值-测量下限值)除以刻度数量得到每一格代表的数值。对于测量下限值为正数的仪表,其读数为指针相对位置与每一格代表数值的乘积;对于最小值为负数的仪表(如SF6压力表,最小值为-0.1),其读数为指针相对位置与每一格代表数值的乘积,然后加上测量下限值。
6 实验结果与分析
为了验证面向巡检机器人的指针式仪表读数自动识别方法的有效性和准确性,本节实验分为三个部分:第一部分对仪表检测的方法进行对比和分析,选取两阶段目标检测算法(faster-RCNN)和传统机器学习算法(SVM)作为对照,对比三种方法的误检率(将非仪表目标检测为仪表的错误次数与总检测次数之比)、漏检率(为未识别图像中仪表的错误次数与总检测次数之比)和耗时;第二部分对仪表刻度和指针分割的方法进行对比和分析,选取未改进的Deeplabv3+和U-Net作为对照,对比三种模型的精确率(precision)、召回率(recall)和准确率(accuracy);第三部分对最终的仪表读数结果进行统计,将读数相对误差在[-1.5%, +1.5%]区间内的结果认为是正确结果,读数相对误差在[-5%, -1.5%)或者(+1.5%,+5%]区间内的结果认为是有偏差的结果,读数在(-∞,-5%)或者(5%,∞)区间内的结果认为是错误结果,并对统计结果进行分析。
实验选取巡检机器人拍摄的2316张仪表图像作为实验数据集,按照7:3的比例随机选取图片作为训练集和测试集。测试主机的硬件配置为Intel i5-8400,GeForce GTX 1060(6GB显存),16G内存。
6.1 仪表检测结果及分析
本文采用的模型(YOLOv5x)、Faster-RCNN和SVM三种模型检测图像中仪表的统计结果如表3所示。

表3 仪表检测模型测试结果数据Tab.3 Instrument detection model test results
可以看出,由于本文采用的模型(YOLOv5x)和Faster-RCNN是基于深度学习的模型,在各项指标上均大幅超过传统机器学习算法SVM。本文模型和Faster-RCNN模型相比,均能非常准确的检测出图像中的仪表,且极少有漏检的情况发生,但本文模型在耗时方面大幅领先Faster-RCNN模型,为实时识别仪表读数提供了可能性。对于漏检的仪表,均是由于图像中的仪表有部分被遮挡造成的,对于这种情况,可以在后期通过增加被遮挡仪表的数据来降低漏检率。
6.2 仪表刻度及指针分割结果及分析
本文模型(改进后的Deeplabv3+)、原始Deeplabv3+和U-Net三种模型分割图像中刻度和指针的统计结果如表4所示。
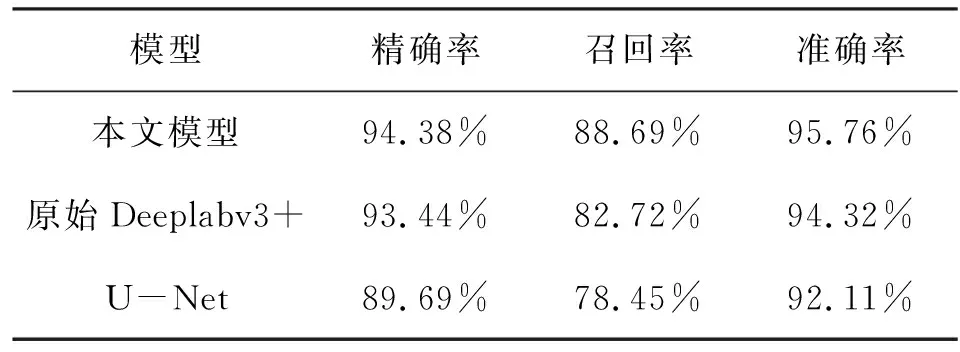
表4 图像分割模型测试结果数据Tab.4 Image segmentation model test results
从上表中可以看出,Deeplabv3+模型在精确率、召回率和准确率方面均优于U-Net模型。由于本文改进的Deeplabv3+模型可以提供更精细粒度的特征,避免关键细微特征的丢失。从实验结果来看,改进后的Deeplabv3+图像分割结果的精确率和准确率均有一定的提升,同时召回率也有较大的提升,而提升召回率会降低模型把刻度或者指针像素识别为背景像素的错误概率,进一步提升了改后进的Deeplabv3+模型在实际场景应用时的有效性。
6.3仪表刻度及指针分割结果及分析
以目标检测算法检测到的仪表图像为输入,利用本文提出的仪表读数识别方法识别仪表的读数情况如表5所示。

表5 仪表读数识别结果分布Tab.5 Instrument reading recognition result distribution
可以看出,本文提出的仪表读数识别方法能准确地识别96.74%的仪表读数,仅有3.26%的读数结果有一定偏差,没有错误识别的仪表读数。其中,有偏差的结果多数是因为仪表表面或者观察窗表面附着有较多的污浊物,但整体的准确率较高,能够符合变电站巡检的实际应用要求。
7 结束语
本文在分析了巡检机器人拍摄图像特点和传统方法不足的基础上,提出了基于深度学习的指针式仪表读数自动识别方法,在指针式仪表读数识别的关键步骤上首先利用YOLOv5进行仪表检测,能够在具有复杂背景的图片中检测出仪表位置,有效的排除了复杂背景对读数识别的干扰并减轻了后续分析的计算量;针对仪表刻度较为密集且刻度和指针尺度相差较大的特点,对Deeplabv3+的Encoder端和Decoder端分别进行了改进,可以提供更细粒度的图像特征,可以更好地针对仪表刻度和指针进行分割。实验表明,对于巡检机器人实际拍摄的仪表图像,本文提出的仪表读数识别方法的准确为96.74%,符合实际应用的要求。
猜你喜欢
小学生学习指导·低年级(2021年6期)2021-09-10
学苑创造·A版(2019年9期)2019-11-07
娃娃画报(2019年4期)2019-05-14
广东第二课堂·小学(2017年9期)2017-09-28
学苑创造·B版(2017年1期)2017-02-21
学苑创造·B版(2017年1期)2017-02-21
小天使·二年级语数英综合(2016年9期)2016-05-14
理科考试研究·高中(2016年7期)2016-05-14
物理教学探讨(2014年2期)2014-05-22
软件工程(2014年3期)2014-03-15
