
基于NIR结合化学计量法牛肉糜掺假检测
2022-11-18 02:25唐丽君
南昌大学学报(理科版) 2022年5期
李 锋,冷 拓,唐丽君,甘 蓓,陈 奕*
(1.南昌大学食品学院,江西 南昌 330031;2.江西省食品检验检测研究院,江西 南昌 330001;3.江西省产品质量监督检测院,江西 南昌 330052)
牛肉是世界上食用最广泛的肉类之一。与其他肉类相比,牛肉丰富的蛋白质和较少的脂肪为日常生活提供了良好的营养[1]。此外,目前世界上大部分的肉类供应来自猪肉(36%)、家禽(35%)、牛肉(22%)和其他动物(7%)。美国、巴西和中国是世界上牛肉消费量前三位的国家。由于其受到消费者的欢迎,牛肉价格相对较高,因此产生了巨大的利润。一些不良商人总是在牛肉中掺入价格较低的物质[2],比如用猪肉腌制上色后冒充牛肉,一些用肉眼很难分辨的干制品,例如牛肉干等产品也是由其他较廉价的肉掺和制成的,在冬季,火锅成了中国人的最爱,而一些不道德商家用廉价的肉添加牛肉香精制成假的牛肉丸在火锅店里销售。肉类掺假会严重影响消费者的利益,也会引发一些与公共卫生和宗教有关的问题(例如,清真食品中没有猪肉,印度教饮食中没有牛肉)。一些肉类质量问题已引起广泛关注。例如,几年前发生在欧洲的马肉丑闻成为全球肉类掺假的经典案例,引发了大规模的公众信任危机。因此,随着经济全球化的推进,肉类及肉制品掺假的检测变得越来越重要。
近年来,检测肉类掺假的方法有很多,主要有色谱技术、电子鼻技术,热学技术和基于DNA的技术。但是这些方法存在一些缺点,检测结果取决于操作人员的技术水平与熟练程度,同时存在分析时间长、分析过程复杂、对样品有不同程度破坏等弊端[3]。因此,迫切需要开发新的、快速的、无损和准确的方法来检测肉类掺假。
近红外光谱技术具有快速、灵敏、样品制备量少的优点,能够用定性和定量信息提供完整的化学成分信息[4]。在以前的研究中,近红外光谱与化学计量学相结合被证明是检测肉类掺假最有效的技术之一。例如,NohaMorsy等[5]利用近红外光谱技术结合线性判别分析(Linear Discriminant Analysis,LDA)对掺入猪肉、鱼油的新鲜牛肉样品进行分类。同年,Cristina Alamprese等[6]使用NIR(942-2667 nm)光谱对掺有火鸡的牛肉碎末进行了研究,并获得了最佳分类率。同样Mohammed Kamruzzaman等[7]研究了近红外高光谱成像检测牛肉碎肉中马肉的可行性。次年,他们还研究了近红外高光谱成像技术检测牛肉碎肉中的鸡肉掺假。先前的研究证明,近红外光谱法与化学计量学技术相结合可对肉进行掺假检测。但是,关于如何快速无损且灵敏度高地对牛肉掺假进行定性和定量分析的信息仍然有限。本研究的目的是以牛肉糜为实验对象,通过NIR结合判别分析(DA)和主成分回归(PCR)来建立一种简单、快速、无损、灵敏度高的方法来实现对假牛肉定性和定量的分析,为了提高DA和PCR模型的性能,比较了不同的预处理方法,并在模型构建过程中对波长进行了筛选。
1 材料与方法
1.1 样品采集
所有猪肉,牛肉的新鲜样品(包括腿肉和胸肉)均购自中国江西省南昌市的当地市场。为了提高肉类的代表性,在不同的商店和市场上收集了不同批次的新鲜样品(包括六批次的猪肉,牛肉)。首先将样品修剪以去除可能干扰分析的成分(例如脂肪),然后用刀将其切成小块,最后用绞肉机(30s)分别切开以使其均匀。对该掺假模型(牛肉掺入猪肉)随机选择三批不同的猪肉和牛肉来制备掺假样品。将不同比例(10%,20%,30%,40%,50%,60%,70%和 80%)的牛肉掺入猪肉中,总共获得72个(3×3×8,即3种牛肉与3种猪肉互配的8种比例)混合样品,其次还包括纯牛肉和纯猪肉,总共获得了 78 个样品。在进一步分析之前,所有这些样品都储存在4 ℃下。
1.2 仪器与设备
Thermo Nicolet 5700 FT-IR 光谱仪(美国 Thermo Scientific);JYL-CO12绞肉机(中国九阳有限公司);ME104E型电子天平(上海梅特勒托利多仪器有限公司);DHG-9246A型电热鼓风干燥箱(上海精宏试验设备有限公司);KQ5200E型超声波清洗器(昆山超声仪器有限公司);Milli-Q Academic 超纯水系统(美国Millipore公司);TQ Analyst Pro Edition(赛默飞世尔科技有限公司)。
1.3 光谱采集
使用BaselineTM漫反射附件,氟化钙分束器和InGaAs 检测器在光谱仪上收集NIR光谱。每个样品取2g转移到石英瓶中进行测试。光谱在12 500~5400 cm-1范围内获得,平均扫描64次,分辨率为16 cm-1。在每次样品测量之前,使用相同的仪器条件扫描背景去离子水光谱[8]。每种样品约2 g分别填充在石英瓶中(直径1.2 mm,壁厚2.0 mm)并紧密包装,光谱收集一式3份。3个光谱的平均值用于进一步分析。所有光谱记录为log(1/R),其中R是相对反射率。
1.4 光谱预处理
所有光谱均采用TQ analyst 8.6.12[9]进行处理。为了提高模型的精度,通常采用光谱预处理的方法来减少光散射或系统噪声的干扰。近红外光谱预处理方法主要包括:光谱归一化和光谱导数[10]。
1.4.1 分类分析
DA是一种统计分析方法,用于在样本多元统计量中区分样本类型。这是一种多变量分析技术,当通过某种方法将已知的研究对象划分为几个类别时,它可以确定新样品属于哪个类别。
在该项研究中,通过计算新样本与已知群体之间的距离,使用DA判别分析方法对纯肉和掺假肉进行了分类。
1.4.2 定量分析
在本文中,使用PCR模型对牛肉中的猪肉进行了定量分析。PCR是指回归分析的一种,当自变量存在复共线性刚,用于改进最小二乘回归的统计分析方法。通过线性变换,将原来的多个指标组合成相互独立的少数几个能充分反映总体信息的指标,从而在不丢掉重要信息的前提下避开变量间共线性问题,便于进一步分析。在主成分分析中提取出的每个主成分都是原来多个指标的线性组合。
1.4.3 模型的性能评估
将所有样品随机分为两个子集。3/4的样本构成了用于构建模型的校准集,其余的则用作测试模型的鲁棒性预测集。对于DA模型,通过计算正确分类(%CC)样本的百分比来评估 DA 模型性能。建立的用于预测的 PCR 模型的性能是基于Rp和Rc因子,RMSEP 和 RMSEC 等指标。
2 结果与讨论
2.1 NIR光谱
纯肉和掺假肉的NIR光谱图如图1所示。在波数为10 200,9 600,8 300,6 900和6 000~5 700 cm-1附近出现了峰。10 200和6 900 cm-1附近的光谱峰与水中的O-H伸缩振动有关[11]。9 600,8 300和6 000~5 700附近的光谱区域分别与脂质C-H的伸缩和弯曲振动相关。蛋白质的主要吸收带(C-N伸缩组合,N-H平面内弯曲和C-O伸缩振动;C=O伸缩和C-H伸缩的组合;N-H弯曲振动)是在4 653~4 527cm-1之间。可以看到,所有光谱的峰轮廓相似,但峰强度不同。牛肉的吸收峰在8 300 cm-1附近,但是随着猪肉的加入,其吸收强度下降。另外,在牛肉中观察到在6 000~5 700附近有一个很强的吸收峰,而猪肉、牛肉-猪肉的吸收峰吸收较弱。由于NIR光谱中的峰重叠,很难仅依靠NIR光谱来量化所有差异。因此,有必要使用化学计量学方法从近红外光谱中进一步全面挖掘出有效的差异信息。
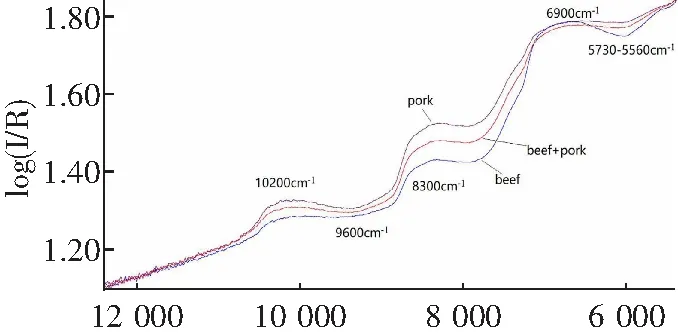
λ/cm-1图1 牛肉、猪肉和牛肉-猪肉混合样品的近红外光谱Fig.1 Near infrared spectroscopy of beef,pork and beef pork mixed samples
2.2 DA结果
2.2.1 基于全波长的判别结果
在这项研究中,变量标准化(Standard Normal Variate,SNV),多元散射校正(Multiple Scatter Correlation,MSC)和卷积平滑算法(Savitzky-Golay,S-G)作为预处理方法。SNV是校正标度和基线效应的有效方法之一,主要用来消除固体颗粒大小、表面散射以及光程变化对漫反射光谱的影响,MSC作用与SNV类似,主要用于消除由于颗粒分布和粒径不均匀而引起的散射现象[12]。对于光谱导数法,在数据采集过程中,由于背景色以及其他因素引起的误差不能减小到零,但光谱导数算法可以做到消除基线漂移以及背景柔和引起的干扰,进而区分出重叠峰,提高了模型的分辨率和灵敏度。然而目前最常使用的推导算法是S-G滤波方法,在基于时域多项式的前提下使用最小二乘法通过移动窗口进行最接近拟合。通过选择不同的多项式和次数,选择了性能更高的产量模型。S-G滤波器在数据流平滑和降噪方面有广泛的运用。
对于该掺假体系,表1显示了DA使用不同的预处理技术建立的模型鉴别能力。可以观察到,在不使用任何预处理方法或使用S-G的情况下对模型进行预处理时,鉴别率可以达到100%。但是,采用其他预处理方法的模型的分类结效果很差,因为一些有用的信息可能会在预处理过程中随着噪声或散射效应而从光谱中删除。图2显示了基于全波长原始光谱的DA模型鉴别牛肉掺假效果。从该图中可出看出,掺假样本(正方形)集中分布在坐标轴左上方,且随着掺假比例的增加,掺假样本越靠近猪肉,纯猪肉(圆形)分布在中间,纯牛肉分布在右下方。

表1 基于全波长和选择波长的近红外光谱得到二元体系的DA结果Tab.1 DA results of binary system were obtained based on the near infrared spectra of full wavelength and selective wavelength

图2 基于全波长原始光谱的DA模型鉴别牛肉糜掺假效果Fig.2 Identification of adulterated beef by DA model based on full wavelength original spectrum
因此可以得出结论,对于牛肉的掺假,均使用SG作为预处理方法获得了最佳模型。针对先前研究产生的掺假牛肉糜,DA模型显示出比NIR模型更好的性能。
2.2.2 基于选择波长的判别结果
使用全光谱结构建立的DA模型的统计参数显示了近红外光谱技术预测牛肉中猪肉的潜力。然而,基于整个光谱的回归模型可能包含非必要信息(噪声,共线性和过度拟合),有时准确性不如预测变量少的模型[13]。为了减少数据处理时间,并使之适用于实际的在线系统,必须进行必要波长的选择。如图1所示,在10 600 cm-1之后的波长中存在明显的噪声,因此本文仅选择的波长为10 600~5 400 cm-1,并将其用于建立数学模型。
对于该掺假体系,基于波长选择后的DA模型的结果如表1所示。与全波长模型相比,选择波长较少的简化模型显示了更好的分类结果以及更佳的校准和验证统计参数。消除噪声的同时也一并消除了冗余的可变波长。个别而言,预处理方法与原始数据相比,分类率没有改善。与全波长模型相同,在简化模型中,利用原始光谱或S-G预处理光谱建立的模型仍然是最好的,分类率达到100%。然而用于执行简化模型的变量数量减少了。因此,基于全波长原始光谱的模型不如由有效波长建立的模型好,且分类率低于有效波长的模型,表明该模型的识别能力不如有效波长下模型的识别能力。
在本研究中,针对已有结果可知用选定波长的原始光谱建立的DA模型可以作为系统中区分掺假牛肉的首选方法。
2.3 PCR处理结果
2.3.1 基于全波长的掺假水平预测
对于用猪肉掺假的牛肉,使用PCR模型预测了掺假水平。基于不同光谱预处理的全光谱模型的性能如表2所示。对于主成分分析法,为了避免建立的校准模型过度拟合或拟合不足,在校准模型的遗漏交叉验证过程中,使用最小均方根误差来确定因子的数量。如表2所示,对原始光谱的全波长进行拟合,得到了最佳的PCR模型,显示了出色的预测性能(Rc=90.30%,Rp=92.21%,RMSEC= 11.2和RMSEP=9.80)。本文获得的结果略低于先前的研究结果[14](Rc2=97%,Rv2=96%,RMSEC=0.15,RMSEP=0.24)。图3中显示了二元掺假体系中真实值与预测值之间的关系,以图形方式更直观地显示了模型的鲁棒性。因此得出结论基于全波长的无预处理方法获得了最佳的预测模型。

表2 不同预处理技术和波长筛选对PCR模型的影响Tab.2 Effects of different pretreatment techniques and wavelength screening on PCR model

图3 基于NONE处理(即未处理的原始光谱)的PCR模型散点图Fig.3 Scatter plot of PCR model based on none processing
2.3.2 基于所选波长的掺假水平预测
对于本研究,表2显示出了使用波长筛选后构建的PCR模型的结果,相比之下,基于NONE技术的模型是最好的,具有最高的校准和预测相关系数(Rc=86.24%,Rp=91.26%)以及较小的RMSEC和RMSEP值。此外,与全波长模型相比,简化后的PCR模型,其结果不佳,因为有相对较高的RMSEP(13.1 vs.11.2)和较低的Rc(86.41% vs 90.30%)。造成这个结果可能是因为去除的波长含有对建立PCR模型有用的信息。因此可以得出结论,基于全波长而不是原始光谱的选择性波长的模型的预测能力是预测牛肉中猪肉掺假水平的有用工具。
3 结论
结果表明,近红外光谱结合化学计量学方法(包括DA和PCR)对牛肉与猪肉的掺假进行定性和定量表征是可行的。分类和定量模型的性能可能会受到光谱预处理和波长范围的影响。结果表明,利用选定重要波长(cm-1)的原始光谱建立的DA模型可以对牛肉,猪肉和掺假牛肉进行识别和分类,对该掺假系统来说,其准确度为100%。此外,使用全波长原始光谱执行的PCR模型具有出色的预测能力,可预测牛肉样品中猪肉的掺假水平。当前的研究成功地证明了NIR作为一种无损分析方法[15],可以被视为肉末产品掺假检测的传统方法的快速且高度可靠的替代方法。然而,需要作出更大的努力来提高检测牛肉掺假物的准确性。
猜你喜欢
特产研究(2022年6期)2023-01-17
乳业科学与技术(2021年4期)2021-08-10
乳业科学与技术(2021年3期)2021-08-09
趣味(语文)(2021年11期)2021-03-09
海峡姐妹(2020年4期)2020-05-30
海峡姐妹(2019年4期)2019-06-18
红领巾·探索(2018年11期)2018-12-10
实用口腔医学杂志(2017年6期)2017-09-19
中国照明(2016年4期)2016-05-17
作文与考试·小学低年级版(2015年20期)2015-12-07
