
结合姿态估计和时序分段网络分析的羽毛球视频动作识别
2022-11-18 05:34陶树王美丽
中国图象图形学报 2022年11期
陶树,王美丽,2,3*
1. 西北农林科技大学信息工程学院,杨凌 712100; 2. 农业农村部农业物联网重点实验室,杨凌 712100;3. 陕西省农业信息与智能服务重点实验室,杨凌 712100
0 引 言
球类体育项目依据胜负规则可分为时间类型和比分类型两类(杨静,2018)。对于比分类型中的羽毛球项目,球员需要运用各种击球技术和步法,在场地上移动、跳跃、转体和挥拍(Phomsoupha和Laffaye,2015)。本文在羽毛球单打比赛视频片段(Tao等,2020)上进行击球动作的时域定位与分类,包括基于姿态估计的动作时域定位和基于时序分段网络的动作分类,能够使观众对比赛视频中的击球动作类型有更直观的了解与学习。
在羽毛球比赛转播视角下,羽毛球的运动轨迹和落点与球员击球姿态有关。Chu和Situmeang(2017)根据羽毛球单打比赛视频主球员的击球姿态,将击球动作分为高远球、挑球、平抽和杀球等类型,但基于单幅比赛视频击球动作图像的梯度特征HOG(histogram of oriented gradients)进行分类,缺乏击球的运动信息。Ramasinghe等人(2014)将主球员击球动作分为正手击球、反手击球、杀球和其他类型,但未对击球动作进行时域定位。本文对羽毛球单打比赛视频中的主球员(背向镜头、占据视频主要区域的球员)进行击球动作定位,并将其分为正手击球、反手击球、头顶击球和挑球等4种类型,同时基于图像形态学处理方法将头顶击球判别为高远球或杀球。每种击球动作的视频帧序列采样如图1所示。

图1 羽毛球动作元视频帧采样序列Fig.1 Frame sequence sampling of badminton strokes ((a) forehand;(b) backhand;(c) clear;(d) smash;(e) lob)
羽毛球击球动作分类的本质属于视频动作识别问题。视频动作识别主要分为裁剪视频的动作识别和长时视频动作识别。裁剪视频中只包括单一的完整动作,长时视频包括多个连续动作。对长时视频动作识别,动作时域分割是极为重要的一步,且这些视频不同动作具有明确的动作切换边界(熊成鑫 等,2020;沈晴 等,2015;Lei和Todorovic,2018;Farha和Gall,2019),前景或背景特征具有较大差别,如行为视频数据集50Salads(Farha和Gall,2019)和Breakfast(Farha和Gall,2019)等。但羽毛球比赛视频中相邻击球动作的前景与背景特征一致,且无明显边界信息,在击球动作序列较短暂的情况下,时间序列的弯曲度量分割算法TS-WMS(time series-warp metric segmentation)(冯林 等,2013)不能充分对击球动作序列进行学习,易出现多余的动作分割边界。基于长时视频动作识别的方法并不适用于羽毛球击球动作的定位,因此采用裁剪的视频动作识别方法对羽毛球击球动作进行分类。本文以羽毛球比赛视频片段(Tao等,2020)为研究对象,基于多人姿态估计的方法,提出一种对主球员击球动作进行时域定位并提取元视频的方法,如图2所示。其中元视频为只包含主球员一次完整击球动作的视频片段。
本文整体技术路线如图3所示,针对羽毛球视频片段,首先基于姿态估计方法进行球员击球动作的定位,定位出只包括一次击球动作的视频片段构成一个元视频;然后将通道—空间注意力机制引入时序分段网络,并通过网络训练实现对羽毛球动作的分类。

图2 羽毛球动作元视频提取示意Fig.2 The meta videos extraction of badminton strokes

图3 技术路线图Fig.3 Research technical route
1 击球动作定位与元视频提取
1.1 基于姿态估计的主球员手臂检测
在羽毛球比赛视频中,主球员执拍手臂在击球过程中挥动幅度较大,而在非击球状态时挥动幅度较小。因此可通过执拍手臂挥动幅度的变化状态定位球员的击球瞬间,以进一步提取元视频,即只包含主球员一次完整击球动作的视频片段。
为了计算羽毛球视频片段中主球员执拍手臂的实时挥动幅度,首先需较准确地检测其执拍手臂骨骼姿态。羽毛球比赛视频中存在多个人物对象,包括球员、裁判以及观众等,通过单人姿态提取算法并不能直接定位至主球员骨骼姿态,因此本文在多人姿态提取模型基础上通过添加置信度、位置和关节点约束来定位主球员的双臂。采用RMPE(regional multi-person pose estimation)(Fang等,2017)模型估计出视频片段中所有的人体骨骼姿态,如图4(a)所示。提取人体骨骼姿态后,需要定位至主球员的执拍手臂。在所有估计出的人体姿态中,两名球员的姿态置信度大小最高,可取置信度最高的两个人体姿态定位至两名球员的姿态,然后添加纵坐标约束定位至主球员姿态,最终定位如图4(b)所示。由于单人骨骼姿态中每个关节点具有固定且唯一的索引值,可添加肩部、肘部、手腕3个关节点的索引约束来定位至主球员的两支手臂,如图4(c)所示。
1.2 羽毛球动作定位与元视频提取
执拍手臂的挥动幅度与球员整体位置的移动速度无关,因此并不能直接根据前后帧中手臂关节点的欧氏距离计算手臂挥动幅度。本文通过手臂上下肢的挥动矢量计算手臂挥动幅度,避免了球员整体位置的变化对手臂挥动的干扰。


图4 RMPE骨骼姿态提取示意图Fig.4 Schematic diagram of pose extraction based on RMPE((a)human pose estimation;(b)pose locating of major player;(c)arm estimation of major player)
(1)
(2)
则上臂和下臂在第f帧的挥动矢量分别为uf-uf-1和df-df-1,如图5中指向ef和wf的虚线向量所示。

图5 相邻帧执拍手臂挥动矢量示意Fig.5 Holding arm swinging vector in adjacent frames
本文将f帧执拍手臂的挥动幅度定义为上臂和下臂挥动矢量的模的平方的线性加权之和,即
(3)
式中,参数λ(0≤λ≤1)和1-λ分别代表肘部和腕部挥动矢量的权重,且模的平方可强化手臂击球时与未击球时挥动幅度的差距。

若手臂ζi各振荡点的挥动幅度的平均值小于另一只手臂,说明该手臂在视频片段中普遍不如另一只手臂运动的剧烈,则该手臂未持球拍,另一只手臂为执拍手臂。最终可检测定位至主球员的执拍手臂,示例如图6所示。

图6 主球员的执拍手臂检测效果Fig.6 Holding arm detections of major player
针对视频中球员手臂的遮挡问题,RMPE仍可参照存在遮挡问题的帧中躯体的可视部分对手臂进行合理的经验估计,如图6第2行所示,可在视频片段中保持球员手臂定位的连续性,避免了手臂检测在时序上的中断。定位至球员的执拍手臂后,本文将视频片段中相邻两段元视频的初始帧和末尾帧称为元视频的时域界限。在遍历帧的过程中,访问至帧fm(fm满足φ(fm)≥φτ,φ(fm-1)<φτ)时,因手臂挥拍动作具有一定延时性,帧fm的后续邻近帧的挥动幅度仍可能高于φτ,因此需跳过fm与fm+t之间的帧,避免出现冗余的挥动帧。继续检测fm+t+1,直至遍历结束。其中,参数t为fm两侧的帧范围,最终决定元视频的时长。手臂ζi的挥动帧构成挥动集合Si。对于集合ST中每一帧,当帧fm-t和fm+t未超出视频片段的帧索引范围时,前后各取t帧合成以fm为时域中心的元视频,其中,帧fm-t和fm+t为元视频的时域界限,最终提取的每段元视频的帧数为2t+1,可参照帧率大小对帧范围t进行赋值。
2 羽毛球击球动作识别
2.1 基于时序分段网络的羽毛球动作识别
元视频中时间间隔很小的帧之间具有高度冗余性,若将元视频每一帧都输入网络,则会消耗过多的计算时间和内存资源。时序分段网络使用的随机采样策略可减小时间和内存消耗,且在训练样本不十分充足的情况下仍具有较高的鲁棒性,因此本文基于时序分段网络(temporal segment network,TSN)展开对羽毛球动作的分类识别研究。


图7 光流提取Fig.7 Optical flow extraction ((a)
羽毛球动作元视频中,动作识别的对象主球员占据了元视频各帧的部分区域,具有空间局部性。CBAM能够加强网络,使其关注重要特征并抑制无关特征,可嵌入目前主流CNN网络结构, 包括空间注意机制和通道注意机制两大核心模块。通道注意机制和空间注意机制两个模块可以以并行或顺序的方式组合在一起,但以往研究表明,顺序组合并且将通道注意力放在前面可以取得更好的效果(Woo等,2018),因此本文将通道注意机制和空间注意机制按顺序方式引入。在TSN网络中,本文采用的空间卷积和时序卷积主体结构为BN-Inception(Szegedy等,2015)。为更好地提升模型性能,Hu等人(2020)将注意力机制SE(squeeze-and-excitation networks)置于Inception结构之后,取得了更理想的效果。SE使神经网络重点关注对分类任务有意义的特征通道,抑制作用不大的特征通道,但缺乏对空间位置信息的重点关注。基于这一思想,本文在BN-Inception结构后引入注意力机制CBAM (convolutional block attention module)(Woo等,2018),将原始TSN网络改进为CBAM-TSN网络,如图8所示。
TSN通过分段采样策略,将一段元视频分割为连续k个分段T1,…,Tk,再从每个分段的帧中随机稀疏采样得到一系列帧样本,每个片段都将给出其本身对于行为类别的初步预测,然后对这些片段聚合得到针对整个元视频的预测结果。时序卷积和空间卷积的聚合结果采用多分类线性支持向量机(Simonyan和Zisserman,2014)进行融合。

图8 CBAM-TSN网络结构Fig.8 The framework of CBAM-TSN
在网络训练中,通过迭代更新模型参数使模型的损失值收敛。TSN结构对一系列分段进行建模,具体为
TSN(T1,T2,…,Tk)=
H(g(F(T1;W),F(T2;W),…,F(Tk;W)))
(4)
式中,H为预测函数,W为训练参数。段共识函数g融合每个分段的预测结果,获得整段元视频的类别预测聚合,F(Tj;W)为分段Tj(1≤j≤k)对各类击球动作的预测向量。本文采用平均池化(Wang等,2019)作为段共识函数,具体为
(5)

(6)

2.2 基于图像形态学处理的高远球与杀球区分
高远球和杀球动作在比赛视频中的姿态特点具有高度一致性,皆属于头顶击球型。但在实际比赛中为两种明显不同的类别,二者区别在于羽毛球的轨迹在运动后期与运动方向呈相反的趋势,且训练集中不同击球动作的元视频的差异表现在主球员的姿态特征中。为了使训练集中不同类别元视频的特征差异集中于主球员的姿态特征,在训练集中,将高远球和杀球归为头顶击球类别。在元视频为高远球类型时,视频尾部帧区域的上部区域会出现羽毛球的掩膜信息,而杀球类型元视频帧的上部区域则不存在羽毛球掩膜信息。
对于图像形态学处理方法,本文以Fi±Fi-1表示第i帧和第i-1帧之间的像素的和差,以F⊗Wn×n表示用算子Wn×n对帧F进行平滑线性滤波,F⊕Sr表示图像F用半径为r的结构元Sr做膨胀操作。e(w,h)为图像形态学处理中长轴和短轴长度分别为w和h的椭圆形结构元。当CBAM-TSN将一段元视频预测为头顶击球类别时,通过图像形态学处理算法将该元视频区分为高远球或杀球类型。高远球和杀球元视频区分方法的具体步骤如下:
输入:头顶击球元视频。
返回值:判别结果。
1)获取元视频的帧数目N;
2)初始化返回判别结果的布尔控制变量IsSmash= True,将判别结果默认为杀球;
3)初始化存储每帧羽毛球掩膜外接矩形框原点纵坐标的列表PL= [ ];
4)读取元视频第1帧,并对该帧的G通道按阈值125分割,得到通道分割图BGR_G;
5)删除BGR_G中面积小于1E+4的连通域,并对其余连通域进行孔洞填充,得到BGR_GF;
6)FG_CL=[BGR_GF·S50]⊗W5×5;

8)fori∶1 toN,do
(1) 读取当前帧Fi及其前一帧Fi-1;
(2)Fi-1,i=(Fi-1-Fi)+(Fi-Fi-1);



(9) 将列表CT中面积最大的连通域Bmax删除;
(10) ifCT删除Bmax后为空,则PL[i]=-1;
continue;
(11) end if;
(12) 定义存储局部连通域面积的列表CPA;
(13) forj∶0 to length(CT)-1,do
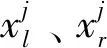
将Bj的面积S(Bj)存入列表CPA;
end if;
(14) end for;
(15) ifCPA非空:获取CPA中最大面积对应的连通域外接矩形框的原点纵坐标yi,令PL[i]=yi;
(16) elsePL[i]=-1;
(17) end if;
9) end for;
10) if 列表PL的末尾10个元素中存在至少2个为正且大小递减的元素:IsSmash= False;
11) end if;
12) returnIsSmash。
算法通过定义并返回布尔变量IsSmash来控制预测结果,其中步骤1)— 7)获取羽毛球视频中球场前景左右边缘横坐标和上边缘的纵坐标;步骤8)— 9)判断视频中的每一帧的背景区域是否出现羽毛球掩膜,若某一帧中出现羽毛球掩膜,保存其外接框的原点纵坐标,近似为掩膜纵坐标;步骤10)—12)判断视频的末尾帧中是否存在至少两个纵坐标为正且大小递减的掩膜,并根据判断结果为IsSmash赋值,最终返回IsSmash。


图9 高远球与杀球元视频中羽毛球掩膜高度变化Fig.9 The change of badminton mask height in meta videos of clear and smash((a)clear;(b)smash)
3 实验结果与分析
本文实验环境配置为Intel Xeon Platinum 8160Ts CPU,GeForce GTX 1080 Ti GPU,以CUDA10、CUDNN7.6为GPU加速库,在Ubuntu18.0系统中使用深度学习框架PyTorch1.1完成,训练参数配置如表1所示。

表1 训练参数配置Table 1 Training parameter configuration
(7)
式中,TP为真正例,FN和FP分别为假反例和假正例,N表示击球动作的类别总数。
本文收集的羽毛球视频来源于互联网,赛事主要为2012年伦敦奥运会和2016年里约奥运会羽毛球比赛以及2018年和2019年世界羽联巡回赛。
针对元视频中主球员击球动作的分类,为了使数据集中的元视频击球动作达到最大完整性,本文通过人工方式制作数据集。对前期收集并提取的足量羽毛球比赛视频片段,使用视频合并分割软件分割出5 160段羽毛球元视频,进行人工标记击球动作类别作为数据集,标签包括正手击球、反手击球、头顶击球与挑球。
3.1 羽毛球动作定位与元视频提取
针对视频片段击球动作定位,对式(3)中参数λ赋值为0.35,挥动幅度阈值φτ赋值为500,fm两侧的帧数范围t取值为15。若提取的一段元视频Vp和真实元视频VT包含的是同一个击球动作,则Vp与VT相同。对于一个视频片段,将实验测试提取出的元视频集合表示为P,真实的元视频集合表示为T,以IoU表示集合P与T的交并比。IoU越高,说明性能越好。实验测得6段视频片段中主球员的执拍手臂挥动幅度变化状态曲线如图10所示。其中,与横坐标轴垂直相交的虚线对应的帧为实际上主球员击球瞬间的帧,这些帧的邻域内挥动幅度呈现剧烈起伏且其他范围帧的挥动幅度趋于平稳。对6段视频片段击球动作定位IoU进行度量,分别为85.7%、91.7%、77.8%、75.0%、87.5%和77.8%,平均达到82.6%。视频片段击球动作定位的IoU指标与挥动幅度阈值的选取和主球员的运动特点有关。有时球员未处于击球瞬间,其执拍手臂挥动幅度仍会过大,或者球员在击球时肘部或腕部的挥动不够剧烈,出现定位的击球动作并非真正击球动作的情况,则上述情况下提取出的元视频为假元视频,若将其输入神经网络进行训练,一定程度上会干扰网络模型的训练和测试。实验结果表明,通过执拍手臂挥动幅度判别方法定位击球动作总体上具有较好的性能。

图10 视频片段中主球员执拍手臂挥动幅度的变化状态Fig.10 The swing amplitude variation state of main player’s holding arm in highlights((a) IoU = 85.7%;(b) IoU = 91.7%;(c) IoU = 77.8%;(d) IoU = 75.0%;(e) IoU = 87.5%;(f) IoU = 77.8%)
3.2 羽毛球视频动作识别
本文对CBAM-TSN的测试采用留出法,并按照分层采样方法,即在抽样时将总体数据分成互不相交的几类,然后按照一定的比例从各类数据独立地抽取一定比例的样本,将抽取的样本合在一起作为一个样本集合。实验从元视频数据集的每一类抽取10%的样本归为测试集,其余样本归为训练集。在训练集上训练网络得到模型后,使用测试集来评估模型的性能。在训练过程中,采用分层10折交叉验证,在每次验证之前的训练阶段开始时,将训练集中每种类别的元视频数据各划分为10折,轮流取其中1折归为验证集,其余9折参与网络训练。当训练至30 epoch和40 epoch时,将学习率缩减为原来的10%。将K分别赋值为1~5,K取不同值时模型的训练损失变化趋势如图11所示,每训练20次(iteration)输出一次训练损失。可以看出,当K从1~2时,训练损失(loss)的收敛趋向值下降明显,从2~5时,训练损失曲线几乎呈黏着状态,性能并未取得明显提升。迭代至35轮次左右时,训练损失整体变化趋势不再降低,已趋于收敛。
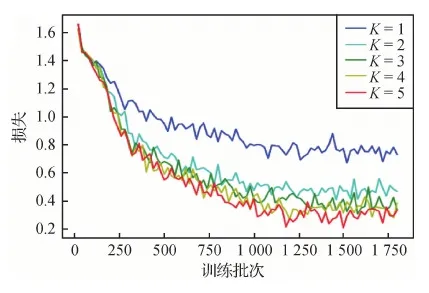
图11 分段数K取不同值时验证集的损失变化Fig.11 Loss variation of validation set with different values of parameter K
分段数K取值为3时,识别速率和准确率达到相对平衡状态,训练得到的分类器模型对正手击球、反手击球、头顶击球和挑球等4种类别识别性能的受试者工作特征曲线ROC(receiver operating characteristic)如图12所示,其中TPR(true positive rate)为真正例率,FPR(false positive rate)为假正例率。4种动作类别的AUC度量皆达到0.98以上,微平均(micro-AUC)和宏平均(macro-AUC)皆约为0.99,说明本文将CBAM引入TSN网络并通过迁移学习训练出来的分类器可达到较良好的性能。

图12 击球动作识别ROC-AUC度量Fig.12 ROC-AUC measurement of stroke recognition
为了验证引入注意力机制CBAM的时序分段网络对羽毛球视频动作识别的有效性,与基于深度学习的另外3种动作识别方法进行测试对比。对比方法为基于骨骼提取的ST-GCN(spatial temporal graph convolutional networks)(Yan等,2018)、基于3维卷积网络的P3D ResNet(Qiu等,2017)和基于RGB与光流的MM-SADA(multi-modal self-supervised adversarial domain adaptation) (Munro和Damen,2020)。为了公平,实验用适合各方法的预训练模型,实验结果如表2所示。可以看出,P3D ResNet取得了最高的召回率, MM-SADA取得了最高的宏平均,其他指标稍低于CBAN-TSN。本文引入注意力机制CBAM的时序分段网络取得了最高的查准率和微平均AUC。ST-GCN采用的骨骼模型是一种启发式的预先定义,只代表人体的物理结构,缺乏对所有层中包含的多级语义信息进行建模的灵活性和能力。实验结果表明,本文方法充分结合了视频的时空特征和通道—空间注意力机制,具有一定的优越性。

表2 不同方法的识别性能对比Table 2 Comparisons between our method and other methods
为了进一步评测模型对每种类别样本的识别性能,将测试集中属于头顶击球的元视频样本继续分为高远球和杀球类别。测试集预测结果的混淆矩阵如表3所示,各类别的召回率和查准率如表4所示。
从表3可以看出,每种类别所有预测正确的元视频样本数目总计467个,占比91.6%,达到了良好的识别精度,但正手击球与挑球混淆、高远球与杀球混淆的情况相对较多,因正手击球和挑球偶尔会存在一定的动作相似性,且当高远球元视频末尾部分羽毛球目标过小或过于模糊时,本文的形态学方法易将高远球误判为杀球。当杀球元视频末尾部分的背景区域出现多个较强的动态噪声时,也会导致杀球易被误判为高远球。

表3 击球动作识别混淆矩阵Table 3 Confusion matrix of stroke recognition
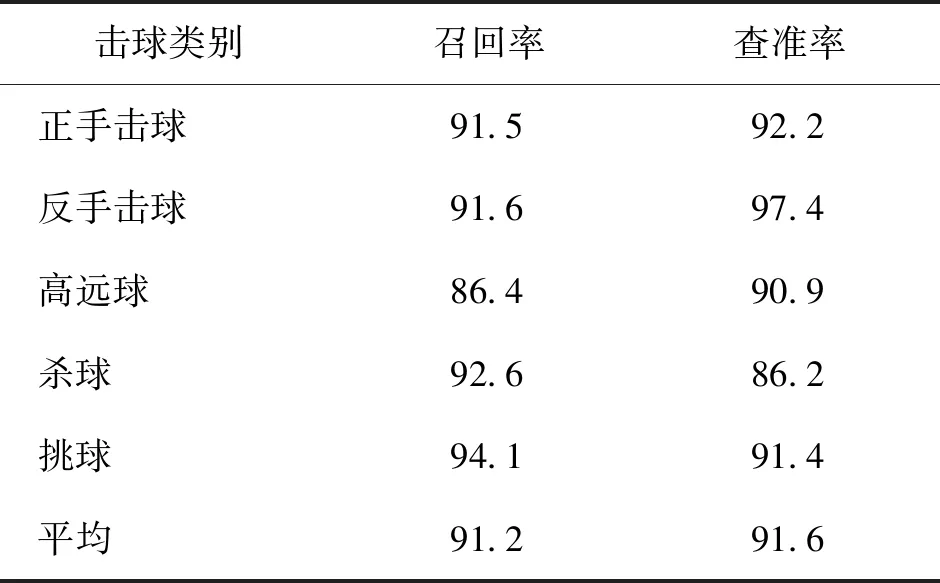
表4 羽毛球动作识别召回率与查准率统计Table 4 The recall and precision statistics of badminton stroke recognition /%
从表4可以看出,各类击球动作的识别精确率均达到86%以上,召回率达到86%以上,平均召回率和准确率分别为91.2%和91.6%,说明基于时序分段网络的方法可较大限度接近人类判断水平,能有效完成羽毛球视频击球动作的识别任务。
3.3 消融实验
使用本文测试集对原始TSN模型和分别引入SE、CBAM的TSN模型进行消融实验,结果如表5所示。可以看出,CBAM-TSN取得了相对最高的平均查准率和AUC,表明基于TSN网络引入CBAM可使羽毛球视频动作识别性能达到更好效果,故采用CBAM-TSN作为最终的羽毛球动作识别模型。

表5 消融实验对比Table 5 Comparisons of ablation experiment
4 结 论
针对体育视频处理领域羽毛球比赛视频动作识别任务,本文从运动特征分析角度出发,提出基于姿态估计的执拍手臂挥动幅度计算方法,对羽毛球击球动作通过时域定位来实现元视频提取。在训练中引入轻量级注意力机制CBAM的时序分段网络,将元视频中主球员的击球动作识别为正手击球、反手击球、头顶击球和挑球4种类型,并基于图像形态学处理方法,将头顶击球动作元视频按照羽毛球的运动轨迹进一步区分为高远球和杀球。实验结果表明了本文方法在羽毛球击球动作定位和识别方面的有效性。1)基于姿态估计模型RMPE,提出通过计算手臂挥动幅度的方法来定位击球动作时域,从而有效提取出羽毛球动作元视频。2)在时序分段网络TSN中引入CBAM注意力机制,构成的CBAM-TSN网络通过训练可较好地对羽毛球动作进行分类识别,且提出的基于图像形态学处理的方法能够较有效地对高远球和杀球元视频进行区分。
然而,本文对于羽毛球员动作的识别仅限于单打比赛视频转播视角,识别角度受限,且CBAM-TSN暂未能同时对多个元视频进行分类识别。今后工作中,将研究考虑不受视角限制的羽毛球视频动作识别方法,同时考虑进行CBAM-TSN网络的并行分类识别,以便达到较好的实时效果。
猜你喜欢
中国学校体育(2022年6期)2022-10-12
少年体育训练(2021年8期)2021-12-15
体育科技文献通报(2021年1期)2021-01-18
今日农业(2020年14期)2020-12-14
灌篮(2020年7期)2020-11-24
体育科技文献通报(2019年9期)2019-09-16
当代体育科技(2017年25期)2017-10-10
运动(2017年17期)2017-07-12
少年体育训练(2017年5期)2017-06-26
少儿科学周刊·少年版(2015年4期)2015-07-07
