
融合跳跃连接的全卷积汉字笔画分割算法
2022-11-17 03:44:44吴文益李镇宇
大连民族大学学报 2022年5期
吴文益, 李镇宇
(1.大连民族大学 大连市汉字计算机字库设计技术创新中心, 辽宁 大连 116600;2.大连瑞云字库科技有限公司, 辽宁 大连 116023)
汉字字形轮廓有笔画轮廓和字形轮廓2种方式如图1。每个汉字都由若干笔画组合, 笔画轮廓中一个笔画是一个封闭区域, 互相交叉的笔画组成字形, 发布的字体通常是字形轮廓而不是笔画轮廓。 在字体设计领域, 无笔画轮廓的字形轮廓字库的重构需要汉字笔画的提取和分割技术;在脱机手写体识别、手写风格分析等方面笔画分割是重要的技术环节;在基于深度学习的字体生成中笔画错误问题, 利用笔画分割得到笔画类别信息可以大幅降低错误笔画的生成概率。 因此汉字笔画分割在汉字设计及字形计算机辅助设计技术具有重要的作用。
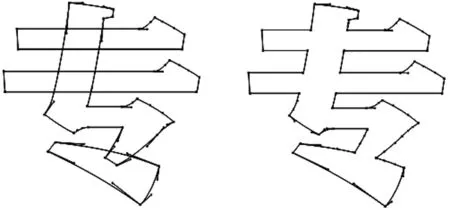
图1 “专”字的笔画轮廓与字形轮廓
汉字笔画种类的多样性和结构的复杂性使得笔画分割具有一定难度。 文献[1]中把笔画分为8个大类和36个小类见表1。
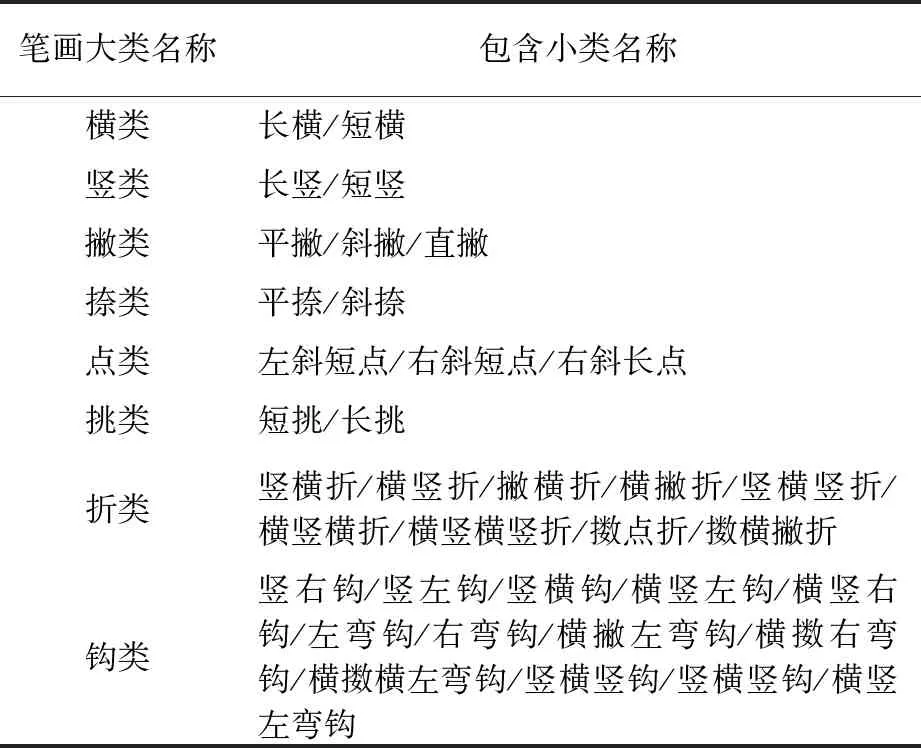
表1 笔画类别对照表
在汉字笔画分割相关研究领域中, 文献[2]通过汉字轮廓, 使用约束Delaunay三角剖分将边界内的区域转换为三角形网格, 并根据笔画连续性分析通过合成子笔画来提取目标笔画。 在文献[3~4]中, 通过分析特征点和跟踪顺序对汉字轮廓进行分割。 上述研究方法适于提取基本笔画, 但对于合成笔画分割效果较差, 常将其错误分割为几个基本笔画;为使笔画分割更为准确, 文献[5~7]引入标注数据集克服上述问题, 采用GB2312楷体字体库作为参考数据, 其中首先对字形进行骨架提取, 然后使用点集配准算法, 如相干点漂移CPD[8]方法将目标字符的骨架点与参考字符骨架点进行匹配。 此外邵宏峰等利用基于动态约束Delaunay三角割分的算法对笔画进行分割[9];阳平等提出一种从篆字骨架中分割出笔画的方法[10];熬雪峰等通过提取筛选角点来分割楷体汉字笔画[11];陈旭东等[12]构建了一个提供评测工具的笔画基准测试库。
基于深度分割模型的汉字笔画分割方法主要利用深度神经网络表示与逼近能力实现“端到端的训练”。 该类方法的核心思想是把汉字看成图像, 把汉字笔画分割任务视为一种图像语义分割任务。 在语义分割研究中, 文献[13]提出一种全卷积神经网络(fully convolutional network, FCN)来解决图像语义分割, 后续研究出现了几种基于FCN的变体网络模型, 如Segnet[14]和Unet[15]等网络;王文光等提出一种笔画提取框架[16], 通过改进的语义分割模型Deepstroke来分割笔画, 并利用禁忌搜索获取笔顺信息。
针对目前方法存在的笔画分割不清、边缘轮廓粗糙、对不同字体适应性不强等问题。 本文提出一种全卷积神经网络模型一定程度克服上述问题, 进而对笔画进行有效分割, 辅助设计师以提高字库开发效率。
1 本文方法
本文提出的融合跳跃连接的全卷积汉字笔画分割模型如图2。

图2 语义分割模型结构
提出模型中取消了池化层, 下采样部分引入resnet-34[17], resnet-34残差网络可以避免由于网络加深而导致的梯度消失和梯度爆炸问题。 模型中进行3次下采样, 每个下采样块由Residual Block[18], 并将最大池化层改为了空洞卷积, 减少了信息的丢失。 上采样部分采用3个反卷积[19]和3个跳跃结构[20]进行特征融合, 以最大限度获取浅层网络的信息, 最后采用连续的两个反卷积恢复原始尺寸。
下采样部分由resnet-34改进而来如图3。灰色部分为原来resnet-34的结构, 白色部分为删除掉的模块。 其中由多个残差块(Residual Block)和1个批标准化层(batchnorm2d)构成了1次下采样, 共计3次下采样, 并去除了最后的全连接层和全局平均池化层。 由于原网络的输出是一个归一化指数层(SoftMax)多分类器, 为使下采样的输出作为上采样部分的输入, 所以去除最后的全连接层和全局平均池化层;由于最大池化在提供更大的感受视野的同时, 分辨率降低, 会导致空间信息丢失, 数据丢失。 而空洞卷积可以避免使用下采样, 并且在相同计算量的前提下, 提供更大的感受野。 故将原模型的最大池化层改为了空洞率为2的空洞卷积层。

图3 下采样部分resnet-34修改图
模型上采样模块由3次上采样构成如图4。 每次上采样会与之前的下采样以及空洞卷积进行1次特征融合(通过1×1的卷积核将下采样块的通道数统一, 并与上采样块进行加和操作), 以便获得更多浅层信息, 如字体的边缘信息等。
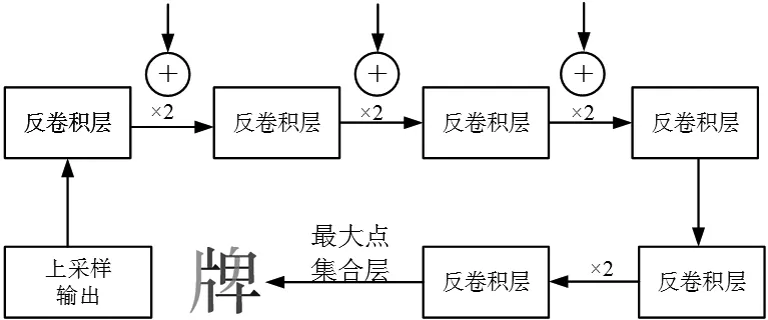
图4 上采样部分
融合完1次特征后, 利用2倍转置卷积将特征图放大, 以进行下一次融合。 当融合3次浅层特征信息后, 采用连续的两次2倍卷积将特征图恢复成原始大小。 为了避免训练不收敛问题, 转置卷积的卷积核采用双线性插值算法[21]进行参数初始化。
1.1 笔画类别信息
本文利用笔画类别信息作为笔画语义。 根据《GB13000.1字符集汉字折笔规范》[22]对笔画进行类别标记, 本文将笔画交叉部分和背景单独归为一类, 故总计34类。本文用3维张量表示一个汉字字符的语义分割图如图5。 张量大小为288×288×34, 采用One-Hot编码对笔画类标签进行表示[23]。

图5 笔画语义分割图
定义K为笔画类别数, 本文中K=34, 定义输入参考字体的二值图像X=(x1,x2,…,xn),xi为第i张图像,xi的张量大小统一为288×288×1, 目标字体笔画分割图像Y=(y1,y2,…,yn), 其中目标字体的n个字符为设计师手工分割笔画的字符,yi经过One-Hot对K种类别进行编码后的张量大小统一为288×288×K。
1.2 优化目标及损失函数
全卷积网络通常采用前馈网络直接学习参数为θ的映射函数Dθ:
(1)

(2)
式中:yi ,s,t类别为j的概率分布;yi ,s,t为类别为j的预测概率, 均由SoftMax函数计算得来。 由此可得, 对于每个像素点, 有多元交叉熵损失函数Js,t:
(3)
2 实验及结果分析
本文采用商用汉字字库作为数据集, 主要考虑汉字商用字库数据集丰富而且规范。
2.1 字体笔画分割数据集
本文选择了9种汉字简体正文字库作为数据集, 主要包括标准宋体、兰亭黑体、隶书等字体。 该数据集包含较为全面的汉字笔画和各种笔画结构组合如图6。本文从字库文件中提取汉字字符, 将矢量路径转换成288×288×1像素图像, 每字库选6 763个汉字作为样本, 其中训练集3 436个, 测试集3 350个。
2.2 评价指标
预测分割图像和原始分割图像之间的差异度量是模型训练的关键问题之一, 汉字笔画分割是以像素为单位。 故本文采用多种评价指标对分割模型进行评价。 假设i表示真实值,j表示预测值,pij表示将i预测为j, 并且该图像有K种类别(包含空类)。

图6 数据集字体样式
(1)平均像素准确率(Mean Pixel Accuracy, MPA), 其计算每个类别分类正确的像素数占所有预测为该类别像素数的比例的平均值。
(4)
(2)均交并比(Mean Intersection over Union, MIoU), 其计算每个类别像素交集和并集之比的平均值, 是语义分割常用的度量方法。
(5)
(3) 频权交并比(Frequency Weight Intersection over Union, FWloU), 其对每一类出现的频率设置权重, 权重乘以每类的IoU并进行求和。
(6)
左侧为原始图像, 右侧为网络拆分笔画后的图像如图7。经计算图7b的MIoU值为0.88, 图7c的MIoU为0.77, 从图中也可看出7b图局部的分割噪点和连贯性要比7c图分割效果好。

a)未拆分笔画原字 b)MIoU=0.88 c)MIoU=0.77图7 不同模型分割图像对比
2.3 跳跃结构消融实验
为验证跳跃结构的有效性, 本文对跳跃结构进行了消融实验。 实验结果如图8。可见有跳跃结构模型分割笔画效果更好。 这结果表明跳跃结构的引入有利于准确地分割字体笔画。

图8 跳跃结构消融实验
2.4 空洞卷积消融实验
为验证空洞卷积代替池化对于模型的有效性, 本文对空洞卷积结构进行了消融实验。 实验中, 将空洞卷积改为了最大池化,实验结果如图9。 图中可以看出具有空洞卷积的模型在分割质量上都要优于未使用空洞卷积的模型。 这结果表明空洞卷积的引入有利于准确分割字体笔画。

图9 空洞卷积消融实验
2.5 训练周期对分割字体笔画质量的影响
为研究模型较为合适的训练周期和停止条件, 本文对迭代次数与分割字体笔画质量进行了对比实验, 给出本文模型在学习率为0.000 1, 使用Adam优化器的条件下, 训练过程的Loss曲线如图10。 可以看出, 在训练次数为50次左右时, Loss值已不发生明显变化。
同时, 本文记录了实验在第50次到300次迭代后分割图像的MPA、MIoU和FWloU值见表2。在200次时, 分割的精度基本达到上限。

图10 Loss值随训练次数的变化
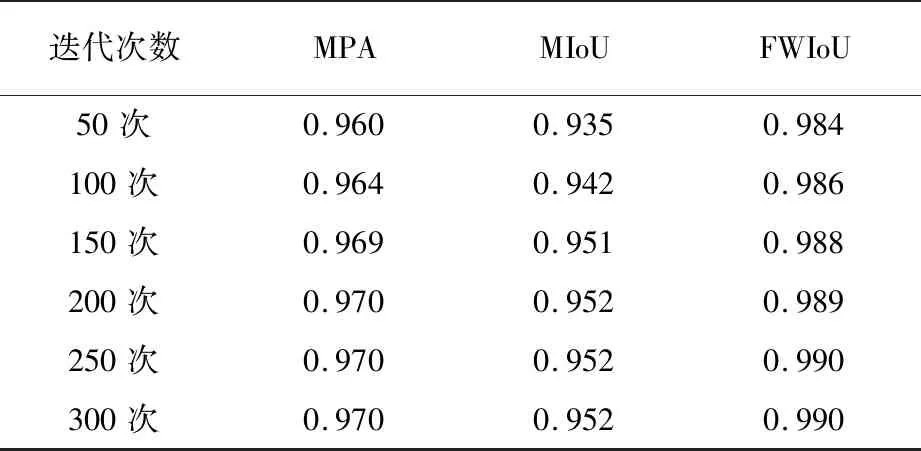
表2 训练周期的影响
2.6 实验方法对比
本文还与其他方法进行对比实验, 对比方法选取了FCN-8[13], Segnet[14]和Unet[15]三种典型语义分割网络模型。 数据集采用标准宋体、方正卡通简体和方正兰亭黑简体作为数据集进行实验, 迭代次数设置为50次, 并将分割的字符与目标字库的字体图像进行对比,见表3。 实验结果明本文方法MPA, MIoU和FWloU的全局平均值优于其它3种方法。

表3 三种语义分割方法的定量评价
本文模型在整体上分割取得良好效果, 但在一些字的字体局部, 特别是弯曲笔画分割上仍存在分割不清的问题如图11。这些不足也有待于进一步的深入研究。

a)原汉字 b)样本标签 c)分割结果图11 分割错误问题
3 结 语
本文提出融合跳跃连接的全卷积汉字笔画分割模型方法, 其中将跳跃结构与网络模型结合, 克服了笔画分割效果差等问题。 在下采样中, 为了更多保留笔画结构信息, 采用空洞卷积代替最大池化层, 实验结果表明本文方法提升了分割字体笔画的细节和结构完整性。 通过各类实验论述和对比了本文方法与其他方法的结果, 表明本文的方法具有较好应用价值, 可以辅助字体笔画分割, 提高字库开发效率。
猜你喜欢
销售与市场(营销版)(2020年9期)2020-11-25 13:38:24
娃娃乐园·综合智能(2020年2期)2020-03-12 10:30:28
电子世界(2018年7期)2018-04-26 08:51:35
故事作文·高年级(2017年2期)2017-03-01 13:03:27
新闻传播(2015年20期)2015-07-18 11:06:46
警察技术(2015年4期)2015-02-27 15:37:36
小雪花·成长指南(2014年10期)2014-10-31 18:10:08
电子知识产权(2013年5期)2013-04-14 06:18:12
世界科学(2013年11期)2013-03-11 18:09:47
移动一族(2009年3期)2009-05-12 03:14:30
