
柴油十六烷值预测模型研究
2022-11-16 06:53王鹏飞孙悦超刘顺涛李少玉
石油炼制与化工 2022年11期
李 琳,王鹏飞,孙悦超,刘顺涛,李少玉
(中石化石油化工科学研究院有限公司,北京 100083)
柴油是目前使用最多的燃料之一[1-2],而十六烷值是衡量柴油在压燃式发动机中着火性能的重要指标。柴油的十六烷值可按照国家推荐的标准GB/T 386—2010在规定操作条件下用单缸柴油机来测定。但由于该标准方法中的十六烷值试验机昂贵,所以很多小型炼油厂较难配备该试验机;而在一些大型炼油厂中,虽然具备该试验机,但因操作难度大,需要大量的油样和较长的试验时间,且维护成本很高,导致试验机的利用率较低。
炼油厂多使用十六烷指数来评价柴油的燃烧性能。但由于十六烷指数[3-4]的影响因素较多,它与十六烷值的对应关系往往随着柴油组成的改变而改变[5],不能满足当前炼油厂柴油生产中在线调合的需要,阻碍了柴油质量升级。因此,亟需一种快速简便的模型来预测柴油十六烷值。基于柴油的理化性质[6]或烃族组成与十六烷值的相关度高,本课题建立柴油十六烷值预测模型,并对其进行验证。
1 实 验
1.1 柴油样本
基于柴油十六烷值的性质设计柴油采样矩阵,并制定计划,采集相关柴油样本。
为了提高柴油十六烷值预测模型的精度,需采集不同领域的柴油样本。在生产领域,采集广州石化、西安石化等10家企业生产的共计车用柴油250个样本;在销售领域,采集22个地区销售的共计200个车用柴油样本。总计450个样本。
柴油样本包括直馏柴油、催化裂化柴油、焦化柴油、加氢裂化柴油等,其十六烷值最小为42.7,最大为60,均值为51.68,标准差为3.24。
为了评估450个柴油样本是否具有代表性,考察其十六烷值的样本数分布情况,如图1所示。从图1可知,柴油样本十六烷值近似服从正态分布。基于Kolmogorov-Smirnov检验[7],考察柴油样本的十六烷值正态分布检验的渐进显著性,所得显著性结果为0.20,大于0.05(显著性水平),说明柴油样本十六烷值服从正态分布,证明这450个柴油样本具备代表性。
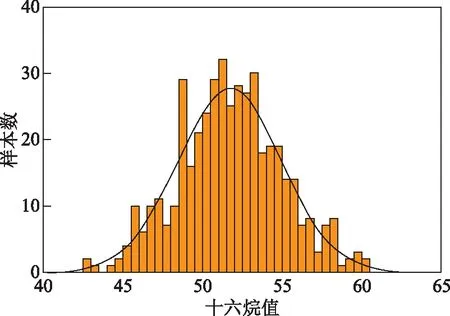
图1 柴油样本十六烷值统计分布
1.2 柴油样本数据库
按照《车用柴油》(GB 19147—2016)标准,共测定450个柴油样本的理化性质,建立柴油样本理化性质数据库。其中,硫含量、酸度(以KOH计)、润滑性校正磨痕直径(60 ℃)、多环芳烃质量分数、运动黏度(20 ℃)、凝点、冷滤点、闪点(闭口)、馏程、密度(20 ℃)共12项理化性质统计结果见表1。450个柴油样本的氧化安定性(以总不溶物计)、蒸余物残炭(w,10%)、灰分、铜片腐蚀(50 ℃,3 h)、水体积分数、脂肪酸甲酯体积分数均符合GB 19147—2016的限值要求。
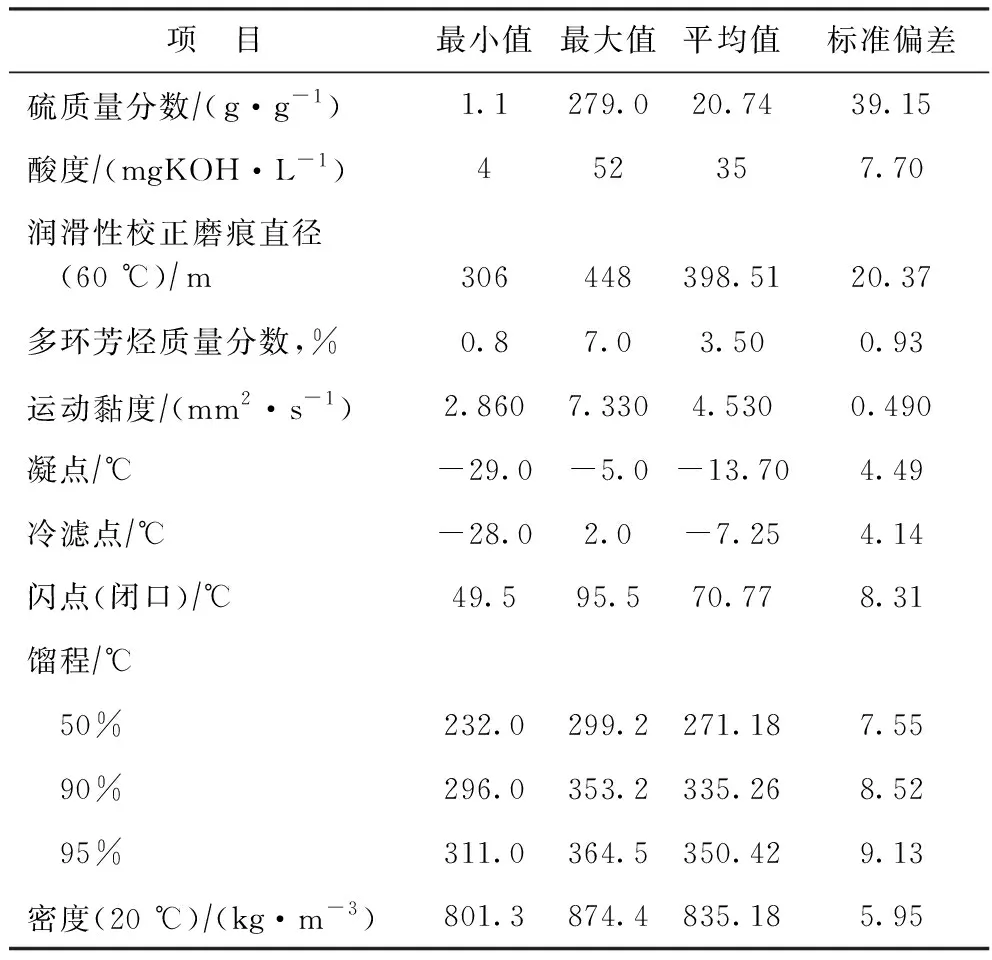
表1 柴油样本理化性质统计结果
按照SH/T 0606—2005《中间馏分烃类组成测定法(质谱法)》的要求,利用GC-MS测量柴油样本的链烷烃、一环环烷烃、二环环烷烃、三环环烷烃、烷基苯、茚满或四氢萘、茚类、萘、萘类、苊类、苊烯类、三环芳烃、胶质的质量分数,建立柴油烃族组成与十六烷值数据库。柴油样本部分烃族组成统计结果见表2。

表2 柴油样本部分烃族组成统计结果
1.3 建模软件
本研究采用的建模软件为IBM公司开发的SPSS 软件。该软件提供了高级统计分析、大量机器学习算法、文本分析方法,具备开源可扩展性,可与大数据集成,并能够无缝部署到应用程序中。SPSS使用Windows方式展示各种分析数据,使用对话框展示出各种功能选择项。在建模过程中,使用SPSS的回归分析模块。
2 结果与讨论
2.1 基于理化性质的柴油十六烷值预测模型
基于蒙特卡洛随机模拟思想,假设所得到的柴油样本数据为抽样总体,在抽样总体中进行不同抽样率下的分层随机抽样。将450个柴油样本按照7∶3的比例,随机抽样分为训练集和测试集,即315个样本为训练集,135个样本为测试集。
在建立柴油十六烷值预测模型时,采用逐步回归的方法。逐步回归分析是一种建立“最优回归方程”的技术,其在每一次引入变量时,将概率p最小的变量引入回归方程。如果引入变量后,回归方程的F检验值大于设定值,则该变量会被剔除出回归方程;当无变量被引入或剔除时,终止回归过程。经过计算,F检验统计量服从自由度为(k,n-k-1)的F分布,见式(1)。
(1)

经过逐步回归分析后,引入6项理化性质变量,剔除另外6项。基于理化性质的柴油十六烷值预测模型见式(2)。
(2)
式中:β0=291.784,β1=-0.421,β2=1.643,β3=-0.258,β4=0.072,β5=0.094,β6=0.038;x1为密度(20 ℃),(kg·m-3);x2为运动黏度(20 ℃),(mm2·s-1);x3为90%馏出温度,℃;x4为50%馏出温度,℃;x5为95%馏出温度,℃;x6为闪点(闭口),℃。
R2表示拟合优度,是指预测模型对观测值的拟合程度。R2最大值为1。R2越接近1,说明预测模型对观测值的拟合程度越好;反之,R2越小,说明预测模型对观测值的拟合程度越差。R2计算式见式(3)。基于理化性质的柴油十六烷值预测模型的R2结果见表3。由表3可知,基于理化性质的柴油十六烷值预测模型的R2为0.781,说明该预测模型的拟合效果较好。
(3)

表3 拟合优度计算结果
建立柴油十六烷值预测模型后,需要对预测模型的线性关系进行检验,包括回归模型的显著性检验、回归系数的显著性检验以及残差分析等,以验证预测模型的有效性。
柴油十六烷值预测模型的F统计量为171.870,概率p为0.000,在显著性水平为0.05的情况下,认为柴油十六烷值与密度、馏程等理化性质之间有线性关系。
对回归模型进行T检验,见式(4),该模型回归系数的概率p依次为0.000,0.000,0.000,0.000,0.000,0.004,0.044。在给定的显著性水平(0.05)下,均有显著意义。
(4)
式中,βk是xk的回归系数。
对回归模型的残差进行分析,结果见表4。标准化残差的绝对值最大为2.948,没有超过默认值3,没有出现异常值,说明该预测模型有效。
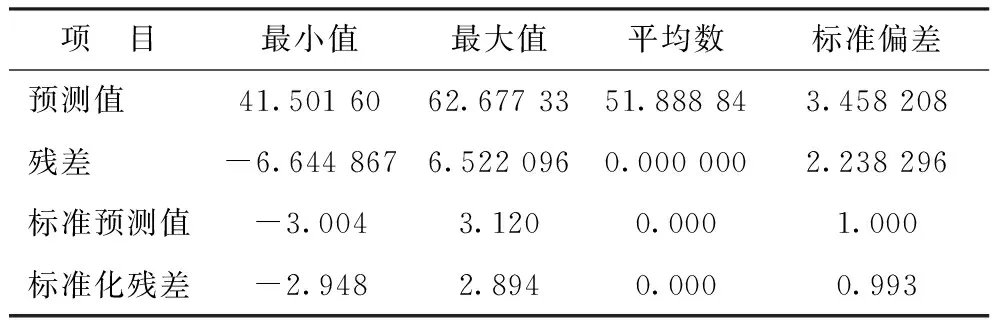
表4 残差分析结果
使用测试集验证柴油十六烷值预测模型,结果见图2。由图2可知,柴油十六烷值的模型预测值与实际值吻合。经计算可得,其均方根误差(RMSE)为0.86。
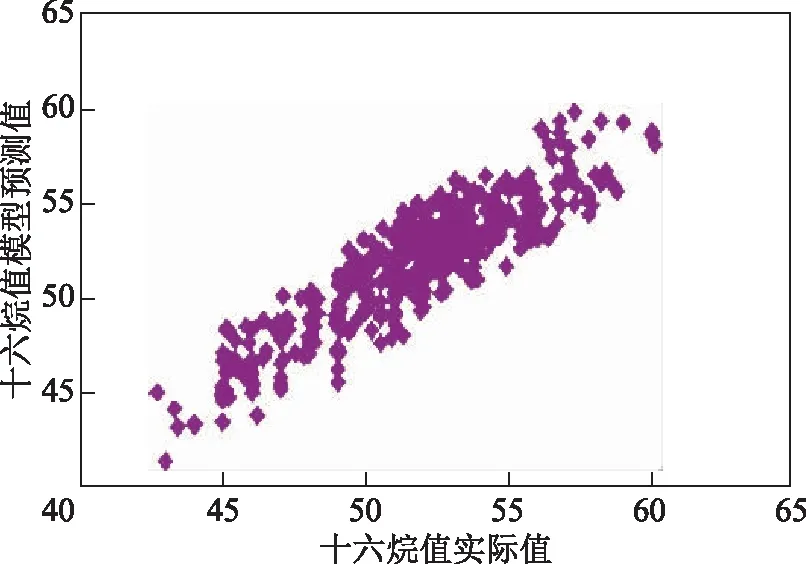
图2 基于理化性质的柴油十六烷值预测模型验证结果
2.2 基于烃族组成的柴油十六烷值预测模型
采用逐步回归的方法建立基于烃族组成[8]的柴油十六烷值预测模型,见式(5)。
(5)
式中:α0=57.258,α1=-0.735,α2=0.289,α3=0.378,α4=-1.072,α5=-0.484;X1,X2,X3,X4,X5分别为烷基苯、链烷烃、三环环烷烃、萘类和二环环烷烃的质量分数。
基于烃族组成的柴油十六烷值预测模型的F统计量为89.133,概率p为0.000,在显著性水平为0.05的情况下,认为柴油十六烷值与链烷烃质量分数、二环环烷烃质量分数等烃族组成之间有线性关系。
对回归模型进行T检验,该模型回归系数的概率p依次为0.000,0.000,0.001,0.000,0.000,0.001,在给定的显著性水平(0.05)下,均有显著意义。
对回归模型的残差进行分析,标准化残差的绝对值最大为2.876,小于默认值3,且没有出现异常值,说明该十六烷值预测模型有效。
经计算可得,基于烃族组成的柴油十六烷值预测模型的RMSE为1.60。
综上所述,基于理化性质的柴油十六烷值预测模型的预测精度优于基于烃族组成的柴油十六烷值预测模型。
3 结 论
采集并分析了450个柴油样本的理化性质和烃族组成,采用逐步回归的方法,开发了分别基于理化性质和烃族组成的柴油十六烷值预测模型。经验证,两种模型均有效且预测精度高,可提高柴油十六烷值分析效率,节省试验费用,为进一步升级柴油质量奠定了基础。
猜你喜欢
上海师范大学学报·自然科学版(2022年3期)2022-07-11
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
初中生学习指导·提升版(2022年4期)2022-05-11
中学生数理化(高中版.高二数学)(2021年5期)2021-07-21
北京航空航天大学学报(2020年10期)2020-11-14
北京航空航天大学学报(2019年9期)2019-10-26
消费导刊(2018年8期)2018-05-25
汽车与新动力(2014年5期)2014-02-27
汽车与新动力(2013年1期)2013-03-11
