
引入注意力机制的JDE多目标跟踪方法
2022-11-16 02:24曾凤彩贺宇哲
计算机工程与应用 2022年21期
晏 康,曾凤彩,何 宁,贺宇哲,张 人
1.北京联合大学 智慧城市学院,北京 100101
2.北京联合大学 北京市信息服务工程重点实验室,北京 100101
多目标跟踪(multi-object tracking,MOT)是计算机视觉中的基本任务之一,是指在不需要事先知道目标的外观和数量的情况下,对视频中的多个物体进行识别和跟踪[1]。与目标检测算法不同,目标检测算法的输出是一些包含有目标的矩形边界框,而MOT 算法还要将目标的ID 与这些边界框进行关联,不同的目标应该分配不同的ID,以区分类内对象。多目标跟踪仍然存在一些挑战,目前先进的解决方案[2-5]大多属于基于检测的跟踪(tracking by detection)方法,它们将多目标跟踪分为两个步骤:(1)检测出单独帧中的所有感兴趣目标;(2)将这些目标按照边界框裁剪下来分别输入到一个嵌入模型中,并提取它们的表观特征,将目标根据表观特征和边界框的交并比关联到已有轨迹上。这类MOT模型需要两个计算量非常大的组件,即目标检测器和嵌入模型(通常是重识别模型,即Re-ID模型)。由于目标检测和Re-ID技术发展迅速,产生了许多优秀的目标检测方法和Re-ID方法,基于这两种算法的多目标跟踪算法具有很高的准确率。但是,这类算法的推理耗时通常都很长,这是因为它们需要经历两个提取特征的过程:提取目标检测特征和目标的表观特征,并且这两个过程中提取的特征是无法共享的,因此也就会带来过长的推理时间,导致跟踪速度过慢,无法实时应用。
随着多目标跟踪技术的发展,一类针对现有多目标跟踪模型推理速度过慢的问题所提出方法正引起关注,这类方法将表观嵌入和目标检测集成到单一网络中并行地完成目标检测和表观特征的提取,将多目标跟踪转化为多任务学习,即同时完成目标的分类、定位和跟踪三项任务,让目标检测和重识别能够共享同一组特征,不再需要一个单独的Re-ID模块,二者分担了大部分的计算,使得这类方法能够达到接近实时的推理速度。Wang等人[6]提出了JDE(joint detection and embedding)方法,Zhan等人提出了FairMOT方法[7]并将这类模型称为one-shot方法。
本文在JDE算法的基础上,提出基于注意力机制的Attention-JDE算法,针对目标尺度小以及目标重叠的问题,设计了一种基于注意力机制的特征增强模块,使得模型更加关注视频中的重要特征且能够扩大模型感受野,通过添加特征增强模块并引入Mish 激活函数能够提升模型对于小目标以及重叠目标的跟踪效果,最终Attention-JDE 算法在MOT16 数据集[8]取得了比原JDE方法更高的跟踪精度(MOTA)并且能够保持较高的推理速度。
1 相关工作
1.1 JDE模型
Zhan等人提出的FairMOT中将多目标跟踪方法分为两种类型:two-step 方法和one-shot 方法,two-step 方法也就是基于检测的跟踪方法,虽然这类方法通常有较高的准确率,但速度通常很慢。比较具有代表性的oneshot 方法有Track-RCNN[9]和JDE 方法,Track-RCNN 在Mask-RCNN[10]网络的顶部添加一个全连接层提取一个128维表观特征用于后续的轨迹关联,不仅通过检测边界框进行跟踪,而且能够在像素级层面进行目标跟踪,但是由于Track-RCNN是在两阶段目标检测方法上进行扩展,因此速度仍然很慢。针对这一问题,Wang等人提出了JDE方法,通过扩展单阶段目标检测方法YOLOv3[11],在YOLOv3 的yolo 层额外提取一段特征作为表观特征,能够并行提取目标检测特征和表观特征,随后利用卡尔曼滤波和匈牙利算法完成目标的跟踪和匹配,将原YOLOv3 方法转化为分类、定位、嵌入的多任务学习网络模型,具体地说,JDE方法基于特征金字塔[12]构建,将Darknet-53作为骨干网络,通过骨干网络后三个尺度的特征图构建特征金字塔,再将三个尺度的特征图分别利用跳跃连接将YOLOv3的yolo层加深512维,最后将加深后的特征图用于目标检测和轨迹关联,JDE 相比two-step 方法节省了一个Re-ID 模块的计算量,最终准确率接近领先的two-step方法,同时可以获得接近实时的推理速度。
1.2 注意力机制
注意力机制可以用人类的生物系统来解释,由于人体计算资源的限制,人们往往会有选择地将注意力集中在一部分信息上,同时忽略其他信息,从而有助于人的感知[13-14],而在计算机视觉任务中使用注意力机制同样能够使模型更加关注有用的信息,有助于提取视频中的复杂特征信息。注意力机制按照作用维度可分为空间域注意力机制、通道域注意力机制以及混合域注意力机制,其中混合域注意力机制是前两者的结合。空间域注意力机制的主要思想是关注特征图中更重要的像素位置,相当于关注目标“在哪里”,而通道域注意力机制的主要思想是关注特征图中更重要的通道,相当于关注目标“是什么”。Hu 等人[15]提出的SENet 通过损失函数来学习各个特征通道的权重参数,使重要的通道获得更高的权重,同时抑制重要性较低的通道对输出的影响。Woo等人[16]在SENet的基础上提出CBAM(convolutional block attention module),CBAM 方法在通道注意力的基础上结合空间注意力,能够对通道维度和空间维度的特征进行压缩和重新加权操作,使得网络模型同时关注通道和空间维度上更重要的特征,在多个计算机视觉任务中获得良好的效果。Wang等人[17]提出的ECA-Net利用自适应卷积核尺寸的一维卷积来代替SENet 中的全连接层,能够有效地减少参数量,利用这种注意力模块能够使轻量化模型在仅增加极少参数量的同时获得较高的性能提升。Jaderberg 等人[18]提出的空间变换网络(spatial transform networks)通过对图像或者特征图进行空间变换来提取图像中的关键信息,使得网络模型具有空间不变性,即在目标被缩放、旋转、平移后模型仍然能有效地对目标进行识别。Wang等人[19]提出一种残差注意力网络(residual attention network),分为主干分支和掩膜分支,主干分支是一个普通的前向网络,掩膜分支包含多次下采样和上采样,通过编码-解码的结构能够学习输入特征图上每个像素点的重要性,从而增强重要的特征,抑制无意义的特征,将这种残差注意力模块与ResNet[20]结合能够进行端到端的学习,最终该网络在ImageNet[21]数据集上表现良好。
2 Attention-JDE网络模型
Attention-JDE 网络使用改进的DarkNet-53[11]作为骨干网络,共有5 次下采样操作,利用最后三次下采样得到的特征图构建特征金字塔,在特征金字塔的三个尺度的特征图之后分别接入特征增强模块,通过特征增强模块能够进一步获得多尺度特征,增强对于小尺度目标的跟踪能力,并且能够使得网络更加关注重要的特征,增强对于重叠目标的检测能力,最后利用三个尺度下的特征图进行预测,输出最终结果,整体网络结构及计算流程如图1所示。
2.1 骨干网络
本文骨干网络根据DarkNet-53修改设计,该网络在DarkNet-19[22]的基础上加入了残差模块并且使用了大量的3×3 和1×1 卷积构成的Bottleneck 结构,使网络扩展到了53 层。如表1 所示,DarkNet-53 共包含5 次下采样卷积操作,每次下采样卷积操作使特征图大小缩小至一半,同时通道数增加一倍,网络末端的特征图比初始输入降低了32 倍,因此初始输入图像的大小应该为32 的整数倍,本文根据视频数据集的分辨率,将原网络的输入大小修改为1 088×608,网络末端输出的特征图大小为34×19,利用最后三个尺度的特征图构建特征金字塔,利用特征金字塔完成多尺度特征融合,有利于提取小尺度目标的特征。除此之外,本文将原DarkNet-53使用的Leaky Relu 激活函数替换为Mish 激活函数[23],Mish 激活函数是一个光滑的、连续的、非单调函数,并且Mish 激活函数无上界有下界,使用Mish 激活函数能够让模型的梯度传导更加平滑,保留更多的有效信息,增强模型的泛化能力,在Attention-JDE 中使用Mish 激活函数能够提升模型对于目标的检测能力,从而更有利于对重叠目标的检测与跟踪,有效地减少ID 切换的发生,Mish 激活函数的数学形式如公式(1)所示,函数图像如图2所示。
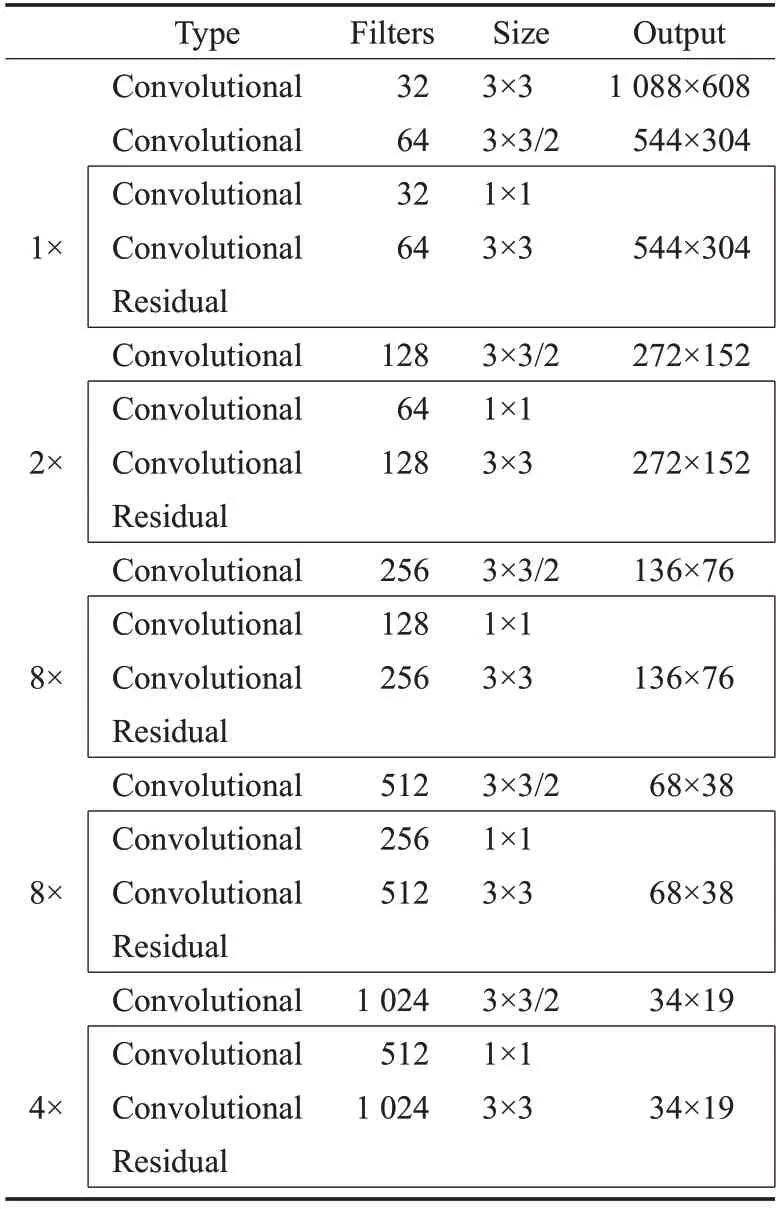
表1 DarkNet-53网络结构Table 1 Network structure of DarkNet-53
其中
2.2 特征增强模块
本文在骨干网络末端增加了特征增强模块,如图3所示。特征增强模块由通道注意力模块、空间注意力模块以及空间金字塔池化模块组成,使用该特征增强模块能够有效地提炼关键特征,同时扩大模型感受野,提高特征提取效率。
(1)通道注意力模块
通道注意力模块的输入为前一次卷积的输出,表示为F∈ℝC×H×W,如图4所示,利用最大池化和平均池化获取全局的通道特征分布信息,分别表示为FCmax∈ℝC×1×1,FCavg∈ℝC×1×1,下一步将上述两个特征向量经过含有一个隐藏层的多层感知机(MLP),再将得到的特征向量相加并经过一次sigmoid 操作(σ)得到最终的通道注意力权重MC(F),通过MC(F)与原输入特征相乘,为包含关键信息的通道分配高权值,为其他通道分配低权值,从而实现通道注意力,通道注意力的表示如公式(3)所示:
(2)空间注意力模块
其中,f7×7表示卷积核尺寸为7的卷积操作。
(3)空间金字塔池化模块
空间金字塔池化(spatial pyramid pooling,SPP)模块属于多尺度融合的一种,使用SPP能够扩大模型感受野,使特征包含更多的上下文信息,从而增加模型的目标检测精度,进而提升目标跟踪效果。SPP模块包含三次最大池化操作,将输入特征Fin∈ℝC×H×W分别进行5×5、9×9、13×13的最大值池化,均通过在特征图周围补0保持特征图大小,接着将三次池化的特征图进行通道维度的拼接完成特征融合,SPP 的计算过程如公式(5)所示:
其中,Maxpooln×n()表示核大小为n的最大池化操作,⊕表示concatenate操作。
2.3 结果预测
本文在特征增强模块之后,利用所提取的特征图完成结果预测。如图6所示,Attention-JDE的预测层可分为两个分支,分别是目标检测分支和嵌入分支,其中目标检测分支完成对目标的分类与定位,嵌入分支完成目标表观特征的提取,随后将表观特征用于后续的轨迹关联。
(1)目标检测分支
采用与YOLOv3相同的方式,本文将目标的分类与定位视为回归任务,在网络末端的三个尺度的特征图上利用预定义的Anchor box 进行回归,每一个尺度上都分配4 个尺寸的Anchor box。Anchor box 的预定义尺寸通过在基准数据集上使用k-means聚类计算获得,共聚成12类,公式(6)表示k-means的代价函数:
给定样本{x(1),x(2),…,x(m)},x(i)在本文中是二维向量,即宽和高,首先随机选取k个聚类中心{μ1,μ2,…,μk},对于每个样本点,遍历所有的k个聚类中心,计算与该样本点x(i)的欧氏距离最小的中心μj,将x(i)的类别设为μj所对应的簇ci,即:
接着在更新完所有样本的类别后,计算每个簇ci中所有样本的均值,并将这个均值作为新的聚类中心,进行下一次迭代,直到聚类中心不再变化或者达到最大迭代次数为止,将最终得到的聚类中心作为本文的Anchor box设定。
根据所设定的Anchor box尺寸以及输入图像的尺寸1 088×608,分别在图像上划分136×76、68×38、34×19个网格单元,分别对应网络末端三个尺度的特征图。当Ground Truth中目标的坐标落入的网格单元时,那么这个网格单元就负责预测这个目标,利用逻辑回归,得到na×(1+4+len(classes))维的向量作为检测结果输出,其中na对应每个网格单元上分配的anchor box 的数量,在这里设置为4,1对应目标置信度,4对应边界框的中心坐标和宽高,len(classes)对应目标种类的数量。此外,网络输出的边界框的坐标实际上是相对于网格单元的偏移量,因此根据公式(8)转换为实际图像中的位置,(tx,ty,tw,th)是模型输出的中心坐标和宽高,σ表示sigmoid 函数,cx、cy分别表示当前网格单元的行号和列号,pw、ph分别表示Anchor box的宽和高,(bx,by,bw,bh)表示边界框的实际中心坐标和宽高。
(2)嵌入分支
嵌入分支的作用是生成一段能够用于区分同类内不同目标的特征,因此,本文在网络的特征金字塔后方添加一系列卷积操作,提取一段512维的特征图作为跟踪所需的表观特征,尺寸与相应的特征尺度相同,为136×76、68×38、34×19,对于单个目标,表观特征就是特征图中的单个512 维的特征向量。随后通过多目标跟踪中常用的卡尔曼滤波[24]和匈牙利算法[25],利用前面提取的表观特征完成轨迹关联。具体做法是,首先根据视频第一帧的检测结果初始化一些轨迹,对于后续帧中检测出的目标,根据它们与现有轨迹之间的表观特征的距离和交并比计算代价矩阵,利用匈牙利算法完成匹配,除此之外还利用卡尔曼滤波预测目标在当前帧的位置,当目标位置与其被分配的轨迹距离超过设定的阈值时放弃匹配这个目标。如果某条轨迹没有被分配新的目标,就将这条轨迹标记为丢失状态,当某条轨迹丢失时间超过给定的阈值时,就放弃继续更新这条轨迹。
3 实验结果与分析
3.1 数据集与评估标准
3.1.1 数据集
本文使用的训练集为六个用于行人检测、多目标跟踪的公开数据集的整合数据集,分别是ETH 数据集[26]、CityPersons 数据集[27]、CalTech 数据集[28]、CUHK-SYSU数据集[29]、PRW 数据集[30]、MOT17 数据集[8],在MOT16数据集上进行结果验证,训练集中与测试集重复的部分已被剔除。训练集共包含54 000 张图片,270 000 个边界框标注和8 700个ID标注。
3.1.2 评估标准
评估标准采用MOT challenge评估标准进行评价,具体评价指标以及各指标含义如下,↑表示该值越高效果越好,反之亦然:
MOTA(↑):多目标跟踪准确度;
MOTP(↑):多目标跟踪精度;
MT(↑):目标跟踪轨迹占ground truth长度80%以上的轨迹总数;
ML(↓):目标跟踪轨迹占ground truth长度不超过20%的轨迹总数;
IDSw(↓):目标ID发生改变的总数;
FP(↓):false positives总数,即误检总数;
FN(↓):false negatives总数,即漏检总数;
FPS(↑):帧率。
其中除MOTA 以及MOTP 外的指标均通过对结果统计获得,MOTA的计算如公式(9)所示,其中GT表示ground truth的数量:
MOTP的计算如公式(10)所示,其中ct表示第t帧中匹配成功的数目,dt,i表示检测结果i和相应的ground truth直接的重叠率。
3.2 实验参数设置
实验基于单个NVIDIA RTX 2080Ti GPU进行,以DarkNet-53 为骨干网络,所有网络均未使用预训练权重,训练过程中,使用SGD 随机梯度下降法进行50 个epochs 的训练,动量值0.9,衰减因子为1E-4,初始学习率为0.625×1E-2,并分别在第25 个和第37 个epoch 衰减为0.625×1E-3 和0.625×1E-4,batch size 设置为4。此外使用了诸如旋转、缩放和色彩抖动等常用的数据增强技术以防止模型过拟合。
3.3 实验结果
本文首先探讨了不同类型的注意力机制对跟踪效果的影响,包括空间域注意力机制(SAM)、通道域注意力机制(CAM)和混合域注意力机制(CBAM),表2展示了上述几类注意力机制对Attention-JDE的影响,数据在MOT16 训练集上验证获得。可以看出SAM 对模型提升比CAM 大,究其原因,MOT16 数据集中的目标类别仅包含行人一类,所以对网络模型的分类能力要求较低,对定位能力要求较高,因此能够使网络更关注目标“在哪里”的空间域注意力机制能够为模型带来更大的提升。此外,本文探讨了混合域注意力机制中两种排列方式对结果的影响,可以发现,在SAM 之后添加CAM后效果反而不如单独添加SAM。为此将添加了上述几种注意力机制输出结果可视化后得到如图7 所示的结果。颜色越深代表对模型结果的影响越大,通过观察该可视化结果可以看出,图7(a)的热力图的红色区域最为弥散,包含了过多的背景信息,图7(d)则能够较为完整地覆盖整个目标并且红色区域相对集中,图7(b)、(c)则介于两者之间,由此可以得出,在SAM之后添加CAM,会对已经被SAM 提炼出的关键特征造成一定的破坏,导致网络对于关键特征的提取能力下降,影响最终的跟踪效果。

表2 不同注意力机制间的对比结果Table 2 Comparison of different attention mechanisms
表3 展示了Attention-JDE 在MOT16 测试集上与其他主流方法的对比,Attention-JDE 可以达到62.1%MOTA,同时FPS 能够达到19.5,值得注意的是,表3 中其他方法都是two-step 方法,因此表中的FPS 数据只与关联步骤有关,实际应用中检测步骤会消耗更多的时间,而Attention-JDE属于one-shot方法,推理速度与整个系统中从检测到关联所有步骤有关,可以看出Attention-JDE在跟踪精度接近的情况下,能够获得远超于其他方法的推理速度。表3所有引用数据均来自MOT challenge官方网址https://motchallenge.net/。
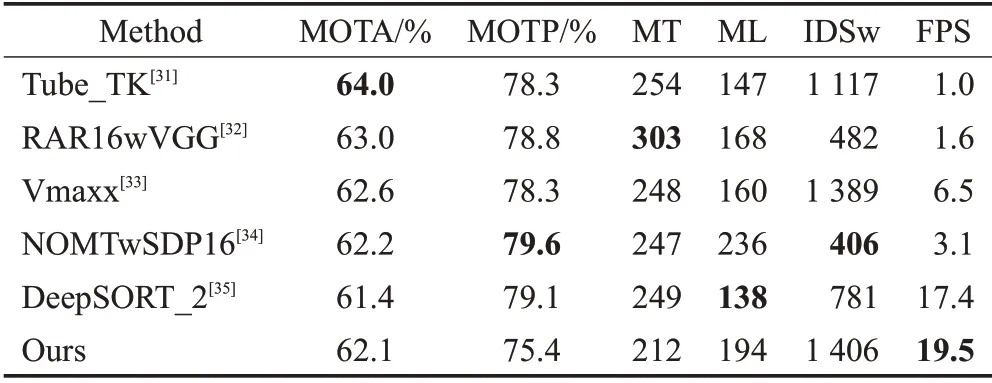
表3 不同方法在MOT16测试集上的结果对比Table 3 Comparison of different methods on MOT16 test set
同时,本文在MOT16 训练集上做了相应的消融实验,如表4 所示,展示了本文在JDE 方法基础上添加各模块以及修改骨干网络激活函数对模型的影响。结果显示,添加CBAM 后MOTA 提升了2.2 个百分点,并且能少量降低IDSw,添加SPP模块后MOTA提升了1.8个百分点,但是也会导致更多的IDSw,使用Mish 激活函数MOTA 能够提升0.7 个百分点,同时能够降低IDSw约10%。结果表明,添加特征增强模块后能够有效地提升模型性能,但是SPP的加入会导致过高的IDSw,使用Mish 激活函数则能够有效地改善跟踪过程中的ID 切换问题。由于特征增强模块会增加模型的计算量,也就会导致推理速度略微降低,而Mish 激活函数相比起Leaky Relu具有更多的负梯度传传导,因此也会略微降低推理速度。最终Attention-JDE 相比原JDE 在只降低1.8 FPS的情况下MOTA提升了2.6个百分点,同时能够减少IDSw。此外,如图8 所示,将Attenttion-JDE 与原JDE 的预测效果可视化后对比,从高亮部分可以看出,在目标遮挡或尺度较小时JDE 并不能有效地对目标检测并跟踪,而Attention-JDE 则能有效地改善这些问题,结果表明Attention-JDE在目标尺度较小、目标有重叠情况时的跟踪效果更好,具有更强的鲁棒性。
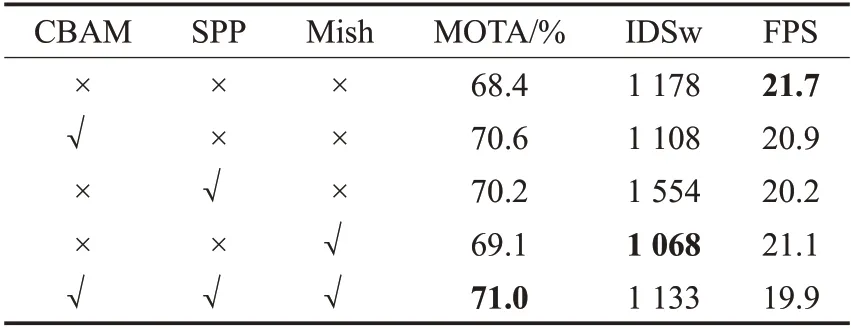
表4 各模块消融实验Table 4 Ablation experiment of each module
4 结论
本文提出了一种引入注意力机制的JDE 多目标跟踪算法:Attention-JDE,该算法使用Mish 函数作为骨干网络的激活函数,使得模型的梯度传导更加平滑。因此,保留了更多有效的特征信息,有效降低了模型跟踪时的ID切换次数。该模型使用注意力机制并结合空间金字塔池化方法,提出了一种特征增强模块,从而提升了网络提取目标关键特征的能力,增强了模型对于不同感受野下特征的提取效果。并且能够有效改善目标尺度较小、目标重叠时的跟踪能力,有效地提升了模型检测与跟踪的准确率。实验结果表明,本文提出的Attention-JDE 模型在几乎不降低推理速度的情况下能够取得较高的MOTA,在精度和速度之间做到了更好的权衡,有较强的综合性能。未来的工作针对模型在跟踪过程中的ID切换次数较多的问题进行探索研究。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
马克思主义哲学研究(2020年1期)2020-11-26
当代陕西(2019年9期)2019-05-20
文苑(2018年21期)2018-11-09
当代贵州(2018年21期)2018-08-29
第二课堂(课外活动版)(2016年2期)2016-10-21
太空探索(2016年5期)2016-07-12
Coco薇(2015年12期)2015-12-10
时代英语·高三(2014年5期)2014-08-26
中学英语之友·高一版(2008年10期)2008-12-11
