
Spark任务间消息传递方法研究
2022-11-16 02:24夏立斌刘晓宇姜晓巍孙功星
计算机工程与应用 2022年21期
夏立斌,刘晓宇,孙 玮,姜晓巍,孙功星
1.中国科学院 高能物理研究所,北京 100049
2.中国科学院大学,北京 100049
为了对自然现象进行更深层次的理解分析,诸多科学研究正面临着高性能计算、大数据分析与机器学习带来的挑战,如粒子物理实验、气候预测、生物数据分析、天文图像处理等。这些科学计算问题不仅数据量大,并且其计算任务通常是以数值线性代数(numerical linear algebra)为核心的多维参数拟合、线性方程组求解等问题,具有很高的灵活性,不易被并行实现。因此,完善的科学计算系统需兼顾大数据处理和高性能计算的特点和优势,以保证计算任务的执行效率。
近年来内存计算(in-memory computing)技术是互联网行业的研究热点,随着内存容量和性能的提升,可以将计算时需要的数据尽量放在内存中实现本地化计算,避免与网络、磁盘等低速设备进行频繁的I/O 操作而损耗性能,其拥有“一次加载,多次使用”的特点,可以大大提升迭代计算的执行效率。分布式处理框架Spark 借助该技术,利用存放在内存中的弹性分布式数据集(resilient distributed datasets,RDDs)和DataSet、DataFrame 构建了一套MapReduce-like 的编程模型,并提供诸多通用的数据操作算子,方便用户简单地实现复杂数据处理任务;同时允许将可重用的数据缓存到内存中,通过构建任务依赖关系构成的DAG(directed acyclic graph)对任务进行分发,以提升迭代和交互任务的性能[1]。
由于Spark 编程模型的限制,其针对的应用特点多为易并行(embarrassingly parallel)且相互独立的任务,可以方便地进行大规模横向扩展实现并行计算(图1(a))。而科学计算和机器学习任务间往往彼此相关,表现出具有通信性的特征,如基础线性代数子程序(basic linear algebra subprograms,BLAS)中的矩阵向量运算。Spark 由于任务间无法相互通信,在其机器学习库Spark MLlib中实现的BLAS只能通过Shuffle方式进行任务间的数据交换,会产生大量中间数据,对内存、网络等带来极大的负担,导致性能下降;在科学计算领域,通常使用MPI(message passing interface)进行任务间的消息传递(图1(b)),其高效的点对点和集合通信机制,可以使得算法进行灵活高效的实现,并且对高带宽、低延迟的RDMA(remote direct memory access)网络,如InfiniBand、RoCE(RDMA over converged ethernet)等有良好的支持。
针对科学计算的特点,本文研究了Spark 内存计算和MPI消息传递模型的无缝融合解决方案,通过MPI的多种通信编程机制对Spark编程模型的表达能力进行扩充,以实现大数据分析和数值计算的高效率执行。本文的主要贡献为:(1)利用MPI增加了Spark任务间的通信机制,使得Spark 能够高效处理科学计算算法及迭代密集型应用。(2)通过更改Spark任务DAG的划分方式,添加MPI Stage在Spark框架中对MPI任务进行统一调度执行。(3)实现MPI在分布式内存数据集之中执行,对任务进行函数化、算子化,减轻开发难度,减少数据移动开销,同时提升了任务的容错性。
1 相关研究情况介绍
近年来已有一些对高性能计算和大数据技术融合的研究。早期的研究主要利用高性能计算中优异的网络通信性能对大数据处理框架进行优化,如通过扩展MPI 键值对的支持以实现Hadoop/Spark 中的通信原语[2],利 用RDMA 提 升Spark Shuffle 的 性 能[3]。随 后Anderson、Gittens 等人通过Linux 共享内存和TCP/IP sockets 的方式对Spark 和MPI 进行连接,并在内存中对两种框架的数据格式副本进行转换[4-5]。 Malitsky利用PMI Server 和Spark Driver 分别对Spark 应用程序中的Spark任务与MPI任务进行管理[6]。除了对Spark与MPI结合的研究尝试以外,SparkNet[7]、TensorFlowOnSpark[8]、RayDP[9]等项目都在探索基于不同工作负载的计算框架之间的结合,以实现端到端的计算流程。
上述工作的设计思想可以总结为两点:利用高性能计算对框架本身的通信模块进行修改;对不同的计算框架进行连接。前者无法解决Spark编程模型带来的局限性;后者需要用户编写两套不同的代码,在执行过程中存在数据格式转换的开销,且Spark 与MPI 计算任务在相互独立的上下文中管理,本质上依然需要对两套集群分别进行维护和资源分配。文献[4-6]中的解决方案,均停留在Spark 与MPI 连接调用的层面上,未能从Spark的编程和计算模型的角度出发进行思考。在对统一资源管理方法的研究中,GERBIL[10]和MPICH-yarn[11]基于Yarn对MPI任务的申请分配方式做出了探索,但仅涉及到资源管理器的层面,使得MPI可以根据获取到的资源信息分配进程,仍未解决Spark与MPI间的无缝融合。
在HPC 应用中广泛使用的MPI 库相比于Spark/Hadoop 有着极高的性能优势,但无法在生产率和容错(fault-tolerant)等方面得到保证。在最新的MPI-4.0[12]标准中,MPI 本身仍然不提供错误处理机制,一旦MPI 作业中的某个进程出现错误,需要对作业进行重新运行。现有对容错的研究,主要通过Checkpoint/Restart(CPR)、Global-Restart、MPI Stage 等方式对作业的运行状态进行记录,并尽可能地减少作业启动时间的开销[13]。在大数据领域,Spark 计算框架和Alluxio 分布式内存系统[14]的核心是以数据为中心,通过DAG对计算/数据的执行流程进行记录,从而可以很方便地使作业从错误中恢复。
2 Spark消息通信设计与实现
2.1 编程和计算模型
2.1.1 编程模型
Spark的编程模型是基于分布式数据集的函数式编程思想,即将一系列算子作用在分布式数据集(RDD)之上,进行MapReduce-like 操作,然后根据依赖关系生成DAG 执行。对于任务之间可以完全并行的操作,能够利用多线程技术提升性能,其提供的诸多算子和编程库使得用户能便捷地开发出并行应用。MPI 则是基于计算资源(如处理器、缓存)和缓冲区的编程模型,核心为进程间通信,通过使用OpenMP 可以实现混合编程(hybrid programming),由于用户可以直接结合物理资源和算法特性进行细粒度的优化,因此被广泛地应用到高性能计算领域中。具体的MPI与Spark编程模型和框架软件生态的对比如表1所示。
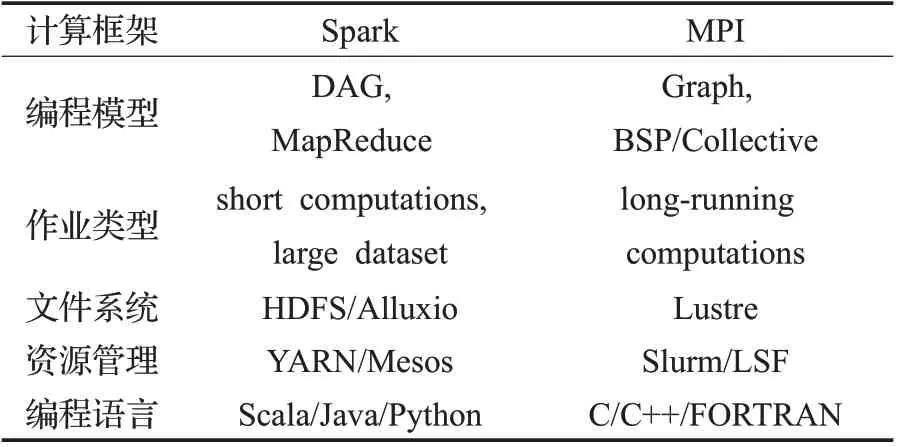
表1 Spark与MPI对比Table 1 Comparison of Spark and MPI
为弥补Spark 编程模型表达能力的局限性,同时为MPI 添加了基于数据的DAG 执行能力,本文将两种编程模型进行了融合,使得MPI可以充分利用大数据生态内的内存计算能力和分布式文件系统等组件,将大数据处理和高性能计算结合在一起。如代码1所示,编程模型的核心为多个分区构成的分布式数据集。通过借鉴Spark编程模型中的map操作,使用mpimap将MPI函数映射到数据集的不同分区上进行计算。此时的数据分区单位,同时也是MPI进程单位,数据分区集合RDD也代表着同一个Communicator下的MPI进程集合。基于以上编程概念,使得Spark 的map 任务间可以通过MPI通信原语进行交互,弥补了Spark 编程模型中map 任务间不能交互的不足。并且每个mpimap操作产生的计算中间数据都会存放在内存中,可供后续算子复用。因此,编程时可以将复杂的MPI逻辑解耦,并与Spark计算中便捷的数据处理方法结合,在统一的应用中通过数据流的形式进行串联。在实际使用的过程中,用户可以根据性能需求灵活地实现算法,而不必局限于Spark 原生算子及MapReduce编程模型的限制。
基于上述编程模型,底层的计算框架可根据数据分区信息,采用数据本地性及网络拓扑结构的算法进行任务(进程)分配。通过使用以数据为中心的模型,取代了传统mpirun 命令行启动MPI 进程的方式,加强数据和计算之间的联系,降低了编程的复杂度,同时也方便用户进行代码复用。
2.1.2 消息通信DAG计算模型
为了将编程模型中提出的概念设计与实际任务的物理分配建立起有效的联系,Spark利用不同RDD之间的依赖(Dependency)关系,生成出计算DAG 以供任务调度。如图2 所示,Spark 默认提供的依赖关系包括NarrowDependency 和ShuffleDependency 两种。为了减少重复计算,同时提升任务的并行度,Spark 通过ShuffleDependency划分出Stage,同一个Stage中的任务作用在单独的Partition 之上,不需要与其他任务的Partition数据进行交换,在不同的Stage 间通过Shuffle 进行数据交换。
在对Spark 中加入消息通信机制后,低效的Shuffle数据交换方式已被MPI 取代。为了实现二者的无缝融合,必须对原有的DAG 构建策略进行修改。本文添加了与MPI 相关的RDD、Dependency 和Stage,并对DAG 的划分策略进行了修改。如图3 所示,对RDD 进行mpimap 函数计算会产生新的MPIMapPartitionRDD,以及相对应的MPIDependency 依赖,并在DAG 生成的过程中划分出MPI Stage。鉴于MPI 通信模型的要求,该Stage 中的任务在Barrier mode 下执行,即必须获取到所有对应的进程资源,否则计算不会被执行。不同于Spark 自身实现的ShuffleMapStage,MPI Stage 在任务间利用消息传递进行通信,从而扩充Spark的局限性,以提升计算效率。
2.1.3 MPI计算容错
根据以上规则生成出的DAG,每个作用在RDD 分区上的MPI 函数都会在一个Stage 中执行,并在函数执行成功之后产生一个新的RDD。由于对MPI程序进行了算子化操作,在一个作业中会有多个MPI函数被分配到相互独立的Stage中,根据数据的依赖关系并行执行。上述的编程模型和计算模型,不仅仅对Spark 自身的表达能力进行了扩充,同时也使得MPI可以实现以数据为中心的内存计算。MPI 与Spark 的无缝融合,为使用HDFS,Alluxio等分布式文件系统也提供了便利。在对于容错技术的研究上,围绕MPI进行的相关工作都集中在Checkpoint和减少作业恢复的启动时间上,对于某一个进程产生的错误是不可避免的。Spark、Alluxio 则是从计算/数据的DAG出发,根据中间计算执行流和中间数据缓存,保证作业从错误中快速恢复。因此,在对MPI函数算子化后,作业的执行过程变成了诸多作用在分布式内存数据集上的变换,相当于对一个大的MPI作业进行了分割,并可以对中间计算结果进行保存。当部分任务出现错误时,可以基于DAG 和RDD 进行恢复,而无需重启整个作业。以上容错的处理方式,尤其是对运行在大规模数据集上的作业,能够减轻大量状态恢复所需的计算和I/O开销。
2.2 Blaze架构设计
根据2.1 节阐述的编程和计算模型,基于Spark 和OpenMPI 构建了一套计算系统Blaze,其总体设计和工作流程如下所示。
2.2.1 OpenMPI组件设计
基于MPI 标准的实现有多种,其中OpenMPI 的采用模块-组件的架构设计(modular component architecture,MCA),如图4 所示,能够便捷地进行模块插件开发,实现自定义功能[15]。为了实现MPI与Spark的融合,OpenMPI端的主要任务为接收Spark调度器中产生的进程分配信息,从而启动MPI Executor(Process)执行具体任务。传统的MPI 程序主要使用mpirun 命令行执行,即通过OpenMPI 的Run-Time 层(PRTE)产生资源分配信息,并实现进程启动。因此,Blaze需要对上述执行过程进行修改以完成对Spark的结合。
Blaze 在设计上并未改变OpenMPI 执行的逻辑,而是充分利用MCA 架构的灵活性,编写了自定义的功能模块进行替换。按照OpenMPI 模块调用的顺序,主要包括进程生命周期管理模块(PLM)、资源分配模块(RAS)、进程映射模块(RMAPS)、启动模块(ODLS)及存储上述信息的数据库。使用JNI的方式将PRTE集成在Master中提供服务,并通过对上述与进程启动相关模块的改写,使得MPI资源分配与调度所需的信息完全由Spark提供。
具体的实现方法为:(1)PRTE根据PLM管理的作业生命周期维护了一个有限状态机,在Blaze 中由Master进行管理。(2)Master 中记录着系统整体的资源使用情况,以及提交的应用信息,RAS 被Master 中的作业资源申请功能所替代。(3)RMAPS 进程映射规则由Blaze 任务调度器根据2.1.2小节的DAG 计算模型产生,目前使用数据本地性算法进行调度。(4)ODLS 在OpenMPI 中负责本地进程的启动,但在Blaze 中将此过程改为Worker根据调度信息产生Executor。
至此,相对于传统MPI 进程启动的关键组件已在Blaze 中实现。MPI 进程与Spark Executor 的概念建立起来了连接,MPI_Init 可直接利用Executor 中包含的Namespace 及Rank 信息完成进程间的感知,进而实现Spark任务间的消息通信。
2.2.2 Blaze处理流程
Blaze处理作业的总体过程如图5所示,架构设计和执行逻辑在主体上与Spark保持一致。不同之处主要在于,本文2.1.2 小节设计的DAG 计算模型通过DAG Scheduler 进行了实现,并由Task Scheduler 根据数据本地性原则完成MPI 任务的分配;同时在Master 中添加了2.2.1 小节介绍的MPI RTE,通过与Spark 提供的信息进行交互以完成任务调度;最终的计算任务在MPI Executor中执行。
Blaze 完整的作业处理流程为,Master 接受客户端提交的作业,并将其调度到Worker 节点中启动App Driver,此处保存着应用程序运行时的上下文BlazeContext,代表与Spark 和MPI 之间的连接。用户提交的应用程序代码在Driver 中执行,调度器根据编程模型的规则生成DAG 计算图,并按照依赖关系将Stage 转换成TaskSet 按顺序发送到Executor 执行。对于一个MPIStage,在任务调度的过程中,需要根据RDD Partition的存储位置等信息做出决策,与Master中的MPI RTE通信,生成MPI Namespace 和Rank。每一个MPIStage 拥有一个Namespace,其生命周期由TasksetManager管理,使得被传送到Executor 的Task 闭包能够完成MPI 的初始化。因此由Worker产生的MPI Executor为单线程模式,即每个Executor分配一个CPU core。同时为了对科学计算中的C/C++ MPI程序进行支持,可将Spark执行中传送的Closure替换为待执行的二进制文件或动态链接库在MPI Executor中执行。
3 实验测试及结果分析
在科学计算及机器学习领域,分布式稠密矩阵(dense matrix)和稀疏矩阵(sparse matrix)的运算,以及迭代算法是各种计算作业的基础。例如在高能物理领域,分波分析(partial wave analysis,PWA)需要在高统计量样本数据上进行数值拟合的计算,其核心过程为使用最大似然法估计待定参数,需要反复迭代以求得最优参数[16];格点QCD(lattice quantum chromodynamics,LQCD)从第一性原理出发将连续的量子场离散化为时间-空间格点,计算热点为大规模线性方程组的求解[17]。因此,本文对实际物理分析中的计算特征进行提取,选取分布式稠密矩阵乘法,线性方程组求解作为性能测试的用例,并与Spark的原生实现进行对比。
本文的实验环境是一个8 节点组成的集群,包括1个BlazeMaster和8个Worker节点。各个节点的软硬件情况如表2所示。
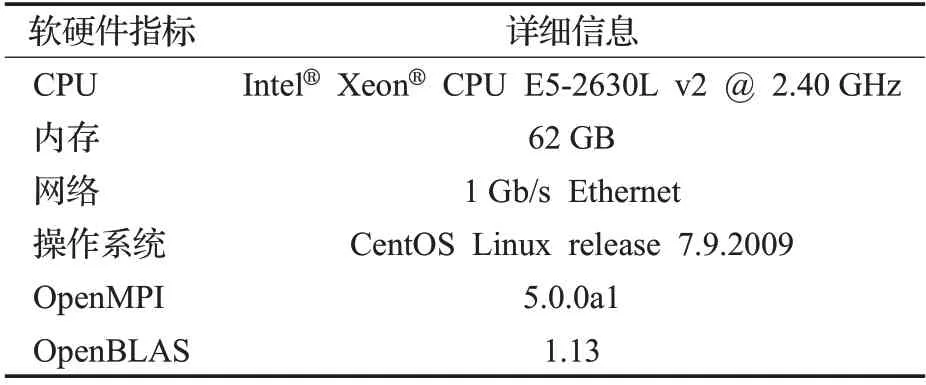
表2 测试集群软硬件环境Table 2 Software and hardware environment of cluster
3.1 矩阵乘法测试
对于稠密矩阵的乘法测试,本文选取BLAS的第三层次矩阵-矩阵乘(matrix-matrix multiplication)进行实验。Spark在其机器学习库Spark MLlib中基于MapReduce实现了分布式分块矩阵(BlockMatrix)的乘法运算,而本文则利用Blaze 中添加的消息传递机制,基于MPI和Spark 的RDD-based BlockMatrix 实 现 了Cannon 算法,与Spark MLlib中默认的稠密矩阵乘法进行对比。
Cannon 算法将待乘矩阵A和B按处理器数量p分成p×p的矩阵Aij和Bij,(0<i,j <p-1),分布在虚拟的方阵格点之上。在完成每轮结果Cij的计算后,对A矩阵沿着i方向循环左移,B矩阵沿着j循环上移,共执行p次循环移位后输出结果C。常规的n×n矩阵乘法的复杂度为O(n3),Cannon算法将计算复杂度降低到了O(n3/p)。但由于其在计算的过程中存在大量的分块矩阵数据传递过程,无法在Spark 中高效实现,而在本文设计的Blaze中则可以借助MPI对Cannon算法进行实现,其中本地矩阵向量运算使用OpenBLAS处理。
实验结果对比的基准为矩阵计算部分的性能,即矩阵已被加载到Spark 中的DenseMatrix 分布式内存数据后的计算过程。 图6(a)是一组在20 160×20 160 大小上的矩阵乘法测试,并根据Cannon 算法要求选择了n2数量的CPU 核心。结果显示,基于消息传递方法的矩阵乘法相比于Spark MLlib 中的实现有57%~68%的性能提升,与C++实现的矩阵乘法性能十分接近,额外的开销在于序列化反序列化过程及编程语言层面。同时随着CPU 核心数目的增长,消息传递方法的加速曲线逐渐变缓,是由于进程数目增加导致的通信开销不断增长。图6(b)则展示了随着矩阵维数的增长在相同CPU核心数目(64 核)情况下的性能对比,消息传递相比于Spark MLlib 有50%~69%的提升。并且当矩阵维度增大到64 000时,Spark会由于OOM无法得到计算结果。
由上述测试可以看出,矩阵维度及CPU 核心数目等参数的变化都会对程序的执行效率造成影响,但在相同的软硬件配置下,同样基于BlockMatrix 和MLlib BLAS 实现的消息传递方式的矩阵乘法在性能测试中的表现均优于Spark MLlib。同时本文提出的Spark 消息传递方法,相比于文献[5]中提出的Alchemist有10%~27%的性能提升,原因在于Alchemist 并未将MPI 融合在Spark中,而是充当MPI与Spark交互的连接器,因此存在额外的数据传递及格式转换开销。并且用户需使用Alchemist 提供的API 编写程序,在程序运行时调用MPI 实现的编程库进行计算,相比于在Spark 中直接实现的任务间消息传递,在易用性、灵活性及性能表现上均存在不足。
3.2 迭代计算测试
共轭梯度下降法(conjugate gradient method)是一种在Krylov子空间中迭代的算法,被广泛应用在线性系统的求解中,如Ax=b。其实现如算法1 所示,计算的热点为矩阵-向量乘和向量-向量乘,当结果小于规定的残差值或迭代到达最大轮次后输出结果。
由于Spark Mllib 中未包含CG 算法,本文对Spark-CG进行了实现,其核心思想为,对迭代中需复用的分布式矩阵A进行Cache,而每轮迭代更新的参数通过Broadcast 发送到Worker 中使用,在每个任务内完成分布式矩阵向量乘法及向量内积运算。基于消息传递方式的实现则通过MPI_Allreduce 完成参数更新,并令所有的计算过程在同一个Stage中完成。
图7 分别展示了在不同CPU 核心数量(32 000×32 000 矩阵)及不同维度矩阵(32 核)下通过CG 求解线性方程组的平均迭代耗时,结果显示消息传递方式的实现相比于Spark 分别有51%~94%和58%~92%的性能提升,相比于Alchemist 有7%~17%的性能提升。在对Spark的测试过程中,随着CPU核心数目的提升,并没有带来执行时间上的显著缩短,原因在于随着节点增加带来的调度和网络开销以及不同任务的执行时间差异影响了整体性能,实际上每一个任务内的计算时间仍然在下降,与此同时,消息传递方式则表现出了与预期相符的性能表现。故采用消息传递的方式可以大量减少冗余任务的分发调度过程,同时能够更高效地实现分布式环境下的矩阵向量运算。因此对于迭代密集型应用,均可选择使用消息传递的方式替换Spark 中的Broadcast及Reduce等操作,从而获得极大的性能提升。
4 结束语
本文针对Spark不能满足科学计算场景下对编程模型灵活性的需求,以及计算性能低下的问题,深入研究了Spark 及OpenMPI 框架的设计思想,提出了一种在Spark 任务间进行消息传递的方法。通过修改Spark 与OpenMPI的资源管理和任务调度的运行逻辑,实现了大数据和高性能计算框架的融合,有效提升了Spark 执行数值计算任务的性能。因此,本文提出的Spark 任务间消息传递方法,可适用于大规模数据量环境下的科学计算与数据处理任务,如迭代密集型计算或具有任务通信特征的算法与应用等。
为了便于移植历史程序,或出于性能考虑需使用基于C/C++编写的MPI程序时,会存在大量的数据转换和序列化/反序列化开销。在Executor 内执行的MPI 计算任务也存在类似的问题,同时会面临JVM 的内存压力。因此,除计算引擎和调度系统之外,高效统一的数据格式以及内存管理系统也是需要关注的重点。RDD虽然提供了良好的分布式内存计算抽象,但无法满足复杂数据类型的高效使用与管理。本文下一步的工作会专注于分布式内存管理相关技术的优化研究,以最终实现可以高效率执行多种作业任务的统一计算系统。
猜你喜欢
煤气与热力(2021年9期)2021-11-06
军民两用技术与产品(2021年5期)2021-07-28
少先队活动(2021年2期)2021-03-29
汽车维修与保养(2021年8期)2021-02-16
学生天地(2020年17期)2020-08-25
数学大王·低年级(2020年3期)2020-03-12
电子制作(2019年22期)2020-01-14
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
燕山大学学报(2015年4期)2015-12-25
