
基于3D-NAND 的神经形态计算
2022-11-14 08:06陈阳洋何毓辉缪向水杨道虹
物理学报 2022年21期
陈阳洋 何毓辉 缪向水 杨道虹†
1)(华中科技大学,博士后流动站,武汉 430074)
2)(武汉新芯集成电路制造有限公司,博士后工作站,武汉 430205)
3)(江城实验室,武汉 430205)
4)(华中科技大学集成电路学院,武汉 430074)
神经形态芯片是一种新兴的AI 芯片.神经形态芯片基于非冯·诺依曼架构,模拟人脑的结构和工作方式,相比冯·诺依曼架构的AI 芯片,神经形态芯片在效率和能耗上有显著的优势.3D-NAND 闪存工艺成熟并且存储密度极高,基于3D-NAND 的神经形态芯片受到许多研究者的关注.然而由于该技术的专利性质,少有基于3D-NAND 神经形态计算的硬件实现.本文综述了用3D-NAND 实现神经形态计算的工作,介绍了其中前向传播和反向传播的机制,并提出了目前3D NAND 在器件、结构和架构上需要的改进以适用于未来的神经形态计算.
1 研究背景
1.1 神经形态计算是未来通用人工智能的重要路径
数据、算法和算力是人工智能(artificial intelligence,AI)的三大要素,未来AI 的发展将面临算力不足的瓶颈(如图1 所示[1]).一方面,云端计算中的通用AI 模型性能强大,但参数庞大,通常采用CPU/GPU 硬件平台进行训练,训练成本高昂且难以普及.另一方面,随着5G、物联网与工业4.0 的发展,越来越多的AI 应用在边缘端设备中设计和部署,需要定制化AI 芯片满足功耗和成本限制下的计算需求,例如阿里的“含光”、华为的“昇腾”和寒武纪的“思源”等.通用CPU/GPU 以及AI 加速芯片,均基于传统的冯·诺依曼计算架构,计算和存储单元分离,“冯·诺依曼瓶颈”不可避免(如图2 所示[2-4]): 第一,数据在计算和存储单元之间不停来回传输,消耗大部分的计算时间和功耗;第二,处理器和存储器之间运算速度的明显差异限制了整体系统的计算效率.面对这一问题,存储和计算融合是未来的发展趋势,新型的计算架构逐渐兴起,其中包括近存计算(near-memory computing)、存内计算(in-memory computing)以及神经形态计算(neuromorphic computing).受人脑智能启发的神经形态芯片引起了学术和工业界的极大兴趣.

图1 AI 模型训练的算力需求和单芯片运算性能[1]Fig.1.Total amount of computing in AI training and single-core chip performance[1].
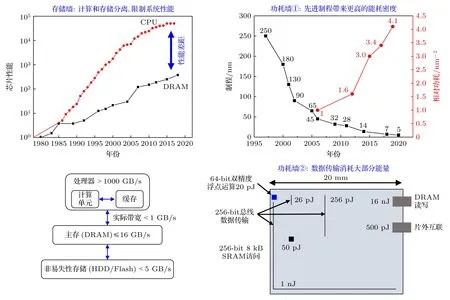
图2 限制芯片性能提升的冯·诺依曼瓶颈[2-4]Fig.2.The von Neumann bottleneck limits chip performance promotion[2-4].
人脑在复杂和陌生场景下的学习、推理和决策能力远超过传统计算机.人脑有超过1011个神经元和1015个突触,功耗只有20 W[5].神经形态芯片模拟人脑的结构和工作方式(如图3 所示[6]): 在结构上,用互补金属氧化物半导体(complementary metal-oxide-semiconductor,CMOS)或新型器件模拟神经元和突触,并将神经网络映射到突触阵列中;在工作方式上,用基于权重模拟值计算的人工神经网络(artificial neural network,ANN)或基于脉冲计算的脉冲神经网络(spiking neural network,SNN)作为算法模型,输入的事件用电压脉冲编码,经过突触后转化为电流输入到后级神经元进行积分,后级神经元达到阈值电压后便向下一级神经元发放电压脉冲.相比冯·诺依曼架构芯片,神经形态芯片高并行、低功耗和存算融合的特性,有望成为未来通用AI 的理想硬件方案.

图3 神经形态计算的原理与芯片架构[6]Fig.3.Neuromorphic computing architectures and paradigms[6].
1.2 基于存储器的神经形态芯片
神经形态芯片根据实现的器件方案可分为基于传统CMOS 的神经形态芯片和基于存储器的神经形态芯片两种类型.基于CMOS 的神经形态芯片代表性成果包括TrueNorth,SpiNNaker,Brain-ScaleS,Loihi,天机芯和达尔文等.这些芯片的突触和神经元采用基于CMOS 的数字电路或者数模混合电路来搭建,模拟单个神经元或突触行为需要靠多个CMOS 晶体管组成的电路模块来实现,集成度和功耗受到限制,并且断电后信息无法保存.基于存储器的神经形态芯片从底层器件仿生的角度出发,用存储器件模拟神经元和突触,在功耗和硬件代价上有明显的优势.近几年,国内外研究机构展示了众多基于存储器的神经形态计算成果,硬件方案包括主流的闪存(NOR/NAND Flash),以及阻变存储器(ReRAM)、相变存储器(PCM)、自旋转移矩磁存储器(STT-MRAM)、铁电存储器(FeRAM)和铁电晶体管存储器(FeFET)等新型存储器.这些存储器的结构和工作原理如图4 所示[7].表1 列出这几类存储器的性能指标,其中参数源于已有阵列或芯片实现的研究工作.

图4 基于非易失存储器的神经形态计算硬件方案[7](a)几种作为突触的非易失性存储器件,其中包括PCM,ReRAM,STTMRAM,FeRAM 和FeFET;(b)突触和神经元构成crossbar 阵列结构用于神经形态计算;(c)神经形态计算芯片的架构Fig.4.Use of non-volatile memory devices as synaptic storage[7]:(a)Non-volatile memory cell as artificial synapse including PCM,ReRAM,STT-MRAM,FeRAM,and FeFET;(b)the implementation of neuromorphic computation on crossbar array consists of artificial synapses and neurons;(c)typical architecture of the neuromorphic chip.

表1 几种非易失性存储器的性能参数Table 1. Benchmark table of performance of emerging memories and typical memories.
1.3 NAND 用于神经形态计算的优点与局限性
突触器件需要具有高集成度、低能耗、耐擦写、CMOS 工艺兼容以及模拟权重调制的特性.其中模拟权重调制特性需要突触有多个权重、并且权重对称线性变化.从图5 可以看到,新型存储器ReRAM,PCM,STT-MRAM,FeRAM 和FeFET在读写速度、读写电压、擦写次数和功耗方面具有突出的优势.然而NAND/NOR Flash 的器件特性使得其在众多硬件方案中有不可替代的优势: 1)ReRAM,PCM,FeRAM 等二端结构器件为了防止潜行通路(sneak path)的产生需要集成用于选通的晶体管,NAND/NOR 的基本存储单元是三端的MOSFET,栅电极自带选通功能,硬件代价小;2)NOR/NAND flash 工艺成熟,器件的阈值电压分布稳定,即权重的分布稳定,并且单元之间的性能高度一致,适合高精度的数值运算;3)得益于NAND/NOR 存储单元的栅控机制,即阈值电压由器件单元俘获层中俘获电荷数量决定,通过增量步进脉冲写入技术(incremental step pulse program,ISPP)可获得稳定的阈值电压分布,权重(电导率)的模拟权重调制特性更容易实现.

图5 各种存储器的性能参数对比(数据来源于表 1)Fig.5.Performance comparison of various memories(data was extracted from Table 1 and plotted into a radar diagram).
NOR 和NAND 的存储单元分别为浮栅型闪存(floating gate flash,FGF)和电荷俘获型闪存(charge trapping flash,CTF),二者均利用栅介质中的存储电荷调控阈值电压,主要区别在于电荷存储层的材料、电荷俘获机制和阵列的结构,如图6所示.FGF 的浮栅层通常为掺杂的多晶硅,利用热电子注入效应实现电荷的存储: 在源、漏电极和栅、源电极之间施加高电压,电子在沟道中被源漏电场加速后,被栅源之间的电场吸引,穿过隧穿氧化层注入到浮栅层中.CTF 的电荷俘获层通常采用氮化硅材料,利用F-N 隧穿效应(Fowler-Nordheim tunneling)实现电荷的存储: 源、漏接地,栅极施加高电压,源极电子通过F-N 隧穿效应穿过隧穿氧化层进入浮栅.在阵列结构方面,NOR 的布局采用并行结构,每个存储单元均有源线(source line,SL)和字线(word line,WL)引出,随机读写的速度快,但过多的布线和较大的器件尺寸(10F2)使得其存储密度难以进一步提升.相比之下NAND采用串行结构,每个存储单元的源极无需单独引线,因此具有更小的单元特征尺寸(4F2)和更高的存储密度.利用三维集成技术,NAND 的存储密度提高至TB 量级.2022 年5 月,国内厂商长江存储量产的3D-NAND 已达到192 层,2022 年8 月SK Hynix 已宣布量产238 层3D-NAND,如此高的集成密度碾压NOR 以及其他新型存储器.

图6 NOR 和NAND 的电路结构Fig.6.Circuit structure diagram of NOR flash and NAND flash.
NAND 的高存储密度为神经形态计算提供了充足的硬件资源、更高的存储密度,意味着芯片能分配更多的硬件资源用于映射更大规模、更多数量和种类的神经网络,芯片性能也越强.然而3DNAND 的存储单元,电荷俘获型晶体管(transistor with charge trap layer,CTL)的擦写次数不高(如表1 所示,次数<105),因此基于3D-NAND 的AI 芯片适用于权重更新不太频繁的场景.
AI 系统通常涉及训练(training)和推断(inference)过程,训练过程中需要输入大量的样本数据,并且根据输出反馈不断调节芯片中权重的分布直至输出达到预期的精度,使芯片具备学习能力,这个过程涉及频繁的权重更新.而推断过程是在已训练好的芯片上输入新的数据,完成指定任务的过程,权重更新频率低.因此,3D-NAND 芯片在执行推断任务的场景中,得益于其超高的存储密度,相对其他种类的存储器芯片具有显著的优势.
2 基于3D-NAND 神经形态计算的研究进展
2.1 3D-NAND 的结构和突触特性
随着2D-NAND 工艺微缩到14 nm 节点,每个单元只能容纳少量的电子,并且单元之间电子的串扰问题使得尺寸继续微缩变得愈加困难且不够经济.在不降低工艺节点的前提下提高存储密度和降低成本,3D-NAND 技术成为了必然的选择.铠侠(原东芝)、镁光、海力士和旺宏均提出了各自的3D-NAND 技术方案,如图7 所示[40].这些技术方案从3D 堆叠方式上可分为两种: 一种是栅极堆叠(gate stack)结构,沟道为垂直方向;另一种是沟道堆叠(channel stack)结构,栅极为垂直方向,如图8 所示[41,42].

图7 各种3D-NAND 的技术方案[40]Fig.7.A summary of 3D-NAND technologies[40].

图8 (a)栅极堆叠的TCAT 技术[41];(b)沟道堆叠的VG-NAND 技术[42]Fig.8.(a)TCAT technology with gate stack architecture[41];(b)VG-NAND technology with channel stack architecture[42].
其中存储层一般采用浮栅(floating gate,FG)或者电荷俘获层(charge trap layer,CTL).一般来说,FG 采用掺杂的多晶硅,存储单元尺寸较大,存储电荷量较多,阈值电压窗口较大,保持特性较好.CTL 材料为氮化硅,存储电荷量相对较少,存储单元的阈值电压窗口和保持特性略差,但CTL器件的尺寸小,集成度更高.目前三星量产的96层V-NAND 技术便是基于栅极堆叠和CTL 层的TCAT 结构.
神经形态计算芯片中突触是基本的结构单元,在3D-NAND 中用CTL 器件作为突触(图9(a))[43].突触的权重(电导)非易失且连续可调,即模拟权重调制特性.存储用3D-NAND 中CTL 器件的阈值电压通过增量步进脉冲写入(incremental step pulse program,ISPP)机制进行调节(图9(b))[44].用于神经形态计算的3D-NAND 中,CTL 不仅可用ISPP 机制进行调节,而且可用多次同脉冲写入(multiple identical pulses program,MIPP)机制进行调节以模拟权重调制特性(图9(c))[45].

图9 (a)CTL 单元的结构示意图(以栅极堆叠结构为例)[43];(b)采用ISPP 机制调控3D-NAND 中CTL 器件的阈值电压[44];(c)3D-NAND 中CTL 器件的模拟电导特性,即模拟权重调制特性[45]Fig.9.(a)Illustration of typical gate-stack type 3D-NAND[43];(b)ISPP modulation of threshold voltage in CTL device[44];(c)analog conductivity characteristics of CTL devices in 3D-NAND[45].
2.2 基于3D-NAND 神经形态计算的相关工作
神经形态计算包含3 个过程: 前向传播、反向传播和权重更新.前向传播,即前级神经元发放的电压脉冲经过突触阵列转化为电流脉冲传递给后级神经元.把前级神经元发放的输入电压脉冲和输入到后级神经元的电流脉冲视为向量,突触的权重构成矩阵,那么前向传播过程等价为输入信号和突触权重进行乘加运算(multiply-and-accumulation,MAC)的累计,即向量矩阵相乘(vector matrix multiplication,VMM).反向传播过程中计算各层突触的误差: 对输出神经元的结果与目标结果进行比对,从输出神经元往输入神经元方向逐层计算各层突触权重的误差.最后根据计算结果更新各层突触的权重.由于最近几年才被学术界关注,3DNAND 用于神经形态计算的相关报道并不多,应用多集中在前向传播和反向传播方面.
2.2.1 3D-NAND 用于前向传播
3D NAND 是多层2D NAND 的堆叠.用于神经形态计算时,3D NAND 比2D NAND 多了层间选通的操作.为了使读者更方便地理解输入编码、器件选通、差分对突触和权重转置的概念,首先介绍Lee 等[45,46]基于2D NAND 的神经形态计算的工作,如图10 所示.图10(a)为2D NAND 的神经形态计算法则,具体地:
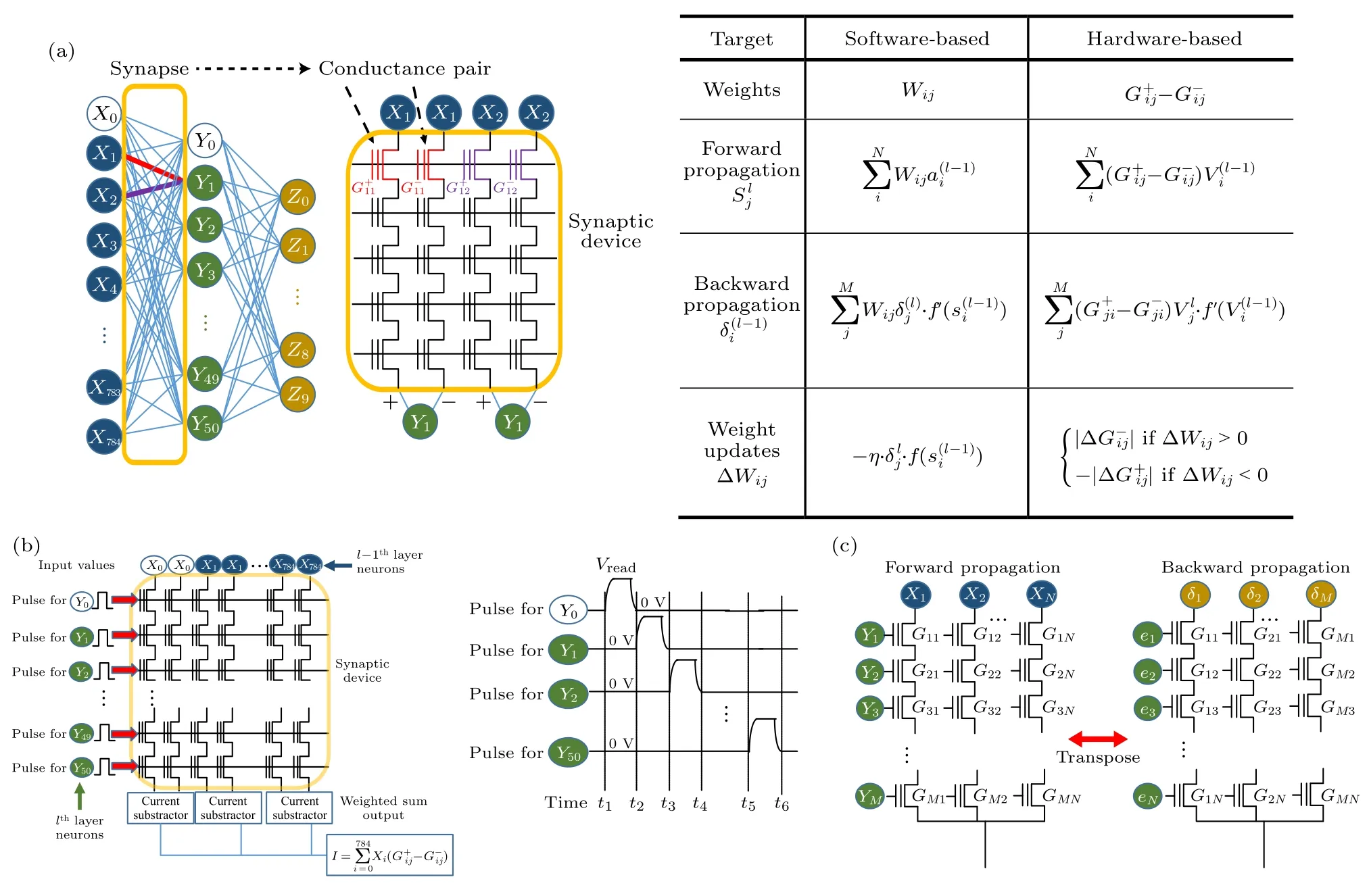
图10 (a)基于NAND 的神经形态计算法则[46];(b),(c)前向传播和反向传播过程中NAND 的操作方法[45]Fig.10.(a)Learning rule of software-based and NAND-based neural network[46];2D-NAND operation method in(b)forward and(c)backward propagation[45].

3)反向传播.前向传播中得到的输出与预期的输出之间往往存在误差,为了使神经网络达到预期的识别率,需要计算出每层突触的误差然后进行权重更新.反向传播中将误差信号从最后一层神经元往第一层神经元传递,实现每层突触误差的计算.第l -1 层中神经元Xi接收的误差信号为

前向传播和反向传播的具体操作方法如图10(b)和图10(c)所示.前向传播: 1)输入Xi采用幅值编码,施加在BL 上.2)NAND 的每个page 等同于神经元(X0,X1,···,X785)对一个后级神经元(Yi)进行全连接的突触.对目标page 施加Vread,其他page 施加Vpass.其中Vread<Vpass<Vprogram,施加Vpass的CTL 器件处于导通状态,可视为导线.输入的电压脉冲,经过目标page 后转化为电流在SL 上相加,完成一次VMM 过程.3)重复上述操作,依次读取每个page 的电流,完成一次前向传播过程.前向传播中,page 中CTL 器件为785×2 个,一共有51 个page.由于NAND 的串行结构无法将误差信号从SL 端输入,反向传播过程中误差信号(δ1,δ2,···,δ51)仍从BL 端输入,但此时一个page 中的CTL 器件数为51×2 个,共有785 个page.因此反向传播过程要另外选取硬件资源,映射权重时突触阵列的配置与前向传播时的阵列互为转置,如图10(c)所示.
2019 年佐治亚理工的余诗孟和清华大学的钱鹤等[47]提出了一种基于3D-NAND 的VMM 方案,如图11(a)所示.需要指出的是,通常情况下3DNAND 中一个WL 控制一个平面的器件,但图11(a)中每一层器件沿Y方向均有独立的WL 作为输入端.具体的VMM 的过程为: 1)输入信号采用二值编码,通过地址解码器和传输门电路实现不同层的选通(如图11(b)所示).左侧传输门的输入端施加导通电压Vpass,地址解码器连接在传输门的PMOS栅上.右侧传输门的输入端施加选通电压Vsel,地址解码器连接在传输门的NMOS 栅上.当输入信号为0 时,左侧传输门开启,右侧传输门关闭,WL 上施加Vpass电压.当输入信号为1 时,左侧传输门关闭,右侧传输门打开,WL 上施加Vsel电压.2)SL 上施加读电压Vread,经过目标层突触转化为电流在BL 上读取.从XY平面上看,CTL 器件以经典的crossbar 形式排列.

图11 一种基于3D-NAND 的VMM 方案[47](a)3D-NAND 的电路结构和VMM 的操作方法;(b)用于3D-NAND 层间选通的外围电路结构Fig.11.A case of using 3D-NAND for VMM operation[47]:(a)Circuit diagram and bias scheme of 3D-NAND array architecture for VMM;(b)peripheral circuitry for layer-to-layer selection.
余诗孟、钱鹤等[47]提出的基于3D-NAND 的VMM 方案,并未用于神经形态计算.如果沿用此方案进行神经形态计算,其优势在于同一平面内的CTL 单元为crossbar 结构,反向传播可采用相同的操作方法,误差信号δi从WL 输入,SL 上施加Vread,BL 上读取电流,无需另外选用硬件资源.并且后续的权重更新可通过WL 上施加电压脉冲实现.但进一步的工作需要考虑两个方面: 1)目前不存在这种结构的3D-NAND.同一平面上制备独立的WL 将大大增加工艺难度、单元尺寸和引线的复杂度,硬件实现难度大;2)栅压有无作为输入(二值编码),那么所选通的器件必须工作在饱和区,CTL 只能有1 bit 的存储态,如果用一个CTL 代表一个突触,那么神经网络的精度只有1 bit.要进一步提高神经网络的精度,可以用多个器件等效为一个具有多比特精度的突触,虽然硬件代价成倍增加,但3D-NAND 的大容量可轻松满足其需求.
2019 年Lee 等[48]研究了如何用2D NAND 实现二值神经网络(binary neural network,BNN)的前向传播,如图12 所示.二值神经网络的输入、权重和输出均只有两种状态,运算过程较为简单,适合对精度要求不高的推断(inference)过程.BNN的运行只需要器件有两个稳定可区分的阻态,对硬件要求不高.图12(a)展示了用SLC NAND 进行二值运算的原理(single level cell,SLC 即存储态为1 bit 的CTL 器件),输入信号施加在源端用于开关的晶体管的WL 上(即bit line selector,BLS 或者select gate at drain side,SGD).同一个page 上两个相邻的SLC 器件构成一个突触对,两个器件中有且只有一个为写入状态.左侧的string 上的BLS 有电压,右侧无电压时,输入标记为+1,反之标记为-1.突触对左侧SLC 器件为未写入状态(Vth,low),右侧为写入状态(Vth,high)时,突触权重标记为W=+1,反之W=-1.输入信号为+1,当W=+1 时,SL 端输出电流ISL,如果将Iref设为0.5×ISL时,电流经过差分放大器,输出+0.5×ISL,转化为正电压,标记为+1.反之当W=-1 时,SL 端无电流输出,电路输出-0.5×ISL,读出负电压,标记为-1.同理,当输入信号为-1 时,权重分别为+1 和-1 时,输出分别为-1 和+1.这种输入和权重状态相同才有电流输出的过程等效为XNOR 逻辑运算.
BNN 前向传播的原理如图12(b)所示.其中一个SLC 器件依次对应一个前级神经元对后级多个神经元的突触.前级神经元的输入视为一组向量,同时输入到NAND 的BLS 上,如图12(c)所示.基于这种硬件方案,Lee 等[48]设计了二值全连接神经网络以及二值卷积神经网络分别用于MNIST 和CIFAR-10 图片数据的识别,网络的训练次数与识别率的关系如图12(d)所示,识别率分别达到98.12%和87.11%.
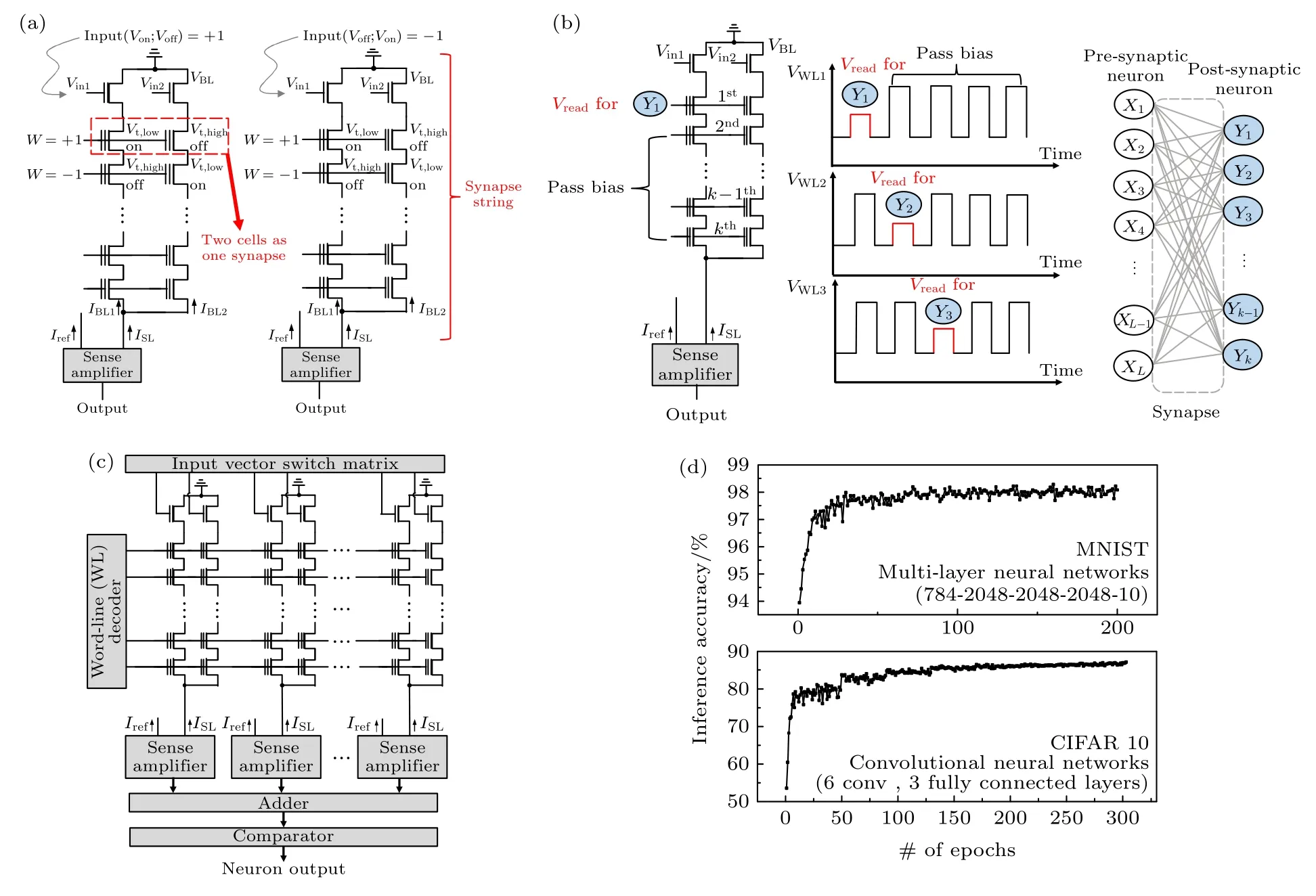
图12 基于2D NAND 的二值神经网络BNN[48](a)相邻的两个CTL 器件组成差分对形式的突触,与输入的信号进行同或运算(XNOR);(b),(c)BNN 前向传播中NAND 的操作方法以及NAND 电路示意图;(d)采用二值全连接神经网络和二值卷积神经网络分别用于MNIST 和CIFAR-10 图像库的识别性能Fig.12.A synaptic architecture based on 2D NAND for binary neural network(BNN)[48]:(a)NAND string structure for XNOR operation,in which two neighboring CTL device constructs a differential pair as one synapse;(b)operation scheme for forward propagation;(c)schematic diagram of synaptic array architecture;(d)the performance of binarized multi-layer and convolutional neural networks for MNIST and CIFAR-10 database recognition task respectively.
2019 年Lue 等[49]提出一种用基于SLC 3DNAND 的卷积核映射和前向传播方案,用多个BL 输入和SLC 器件实现4 bit 精度的输入和4 bit精度的权重,如图13 所示.卷积神经网络CNN 往往采用多个卷积核,对图片进行卷积操作需要进行大量的MAC 运算,原理如图13(a)所示.图片中每个像素对应一个输入信号,一次卷积的过程等同于像素输入与卷积核中对应的权重进行MAC 运算(即前向传播).卷积核中的权重具有多bit 精度,可以将权重拆分为高位和低位,存放在多个SLC中,例如2 个SLC 可以实现2 bit 存储状态.2 bit精度的输入和2 bit 精度的权重的MAC 过程(2 bit input &2 bit weight,2I2W)如图13(b)所示.输入信号的两位X1〈0〉和X1〈1〉先后施加在BL1上,权重的两位分别存储在2 个SLC 器件上,即W(1-1,j)和W(1-2,j).MAC 过程的得到的总电流为X1〈0〉×[W(1-1,j)+2×W(1-2,j)]+2X1×[W(1-1,j)+2×W(1-2,j)],分4 次相乘后移位相加获得.依次类推,4 bit 精度的MAC 过程(4I4W)可拆分为2 组2 bit 的输入和2 组2 bit 的权重进行相乘后移位相加,工作原理如图13(c)所示.图13(d)展示了卷积核电路的工作原理.图中沿BL 方向划分了M个block,每个block 代表不同的通道,每个block 中的每一层代表一个卷积核.输入信号从BL 进入,3 根BL 构成一个2 bit的输入,一个4 bit 精度的输入信号需要6 根BL(图中只绘出一根).3 个SLC 器件构成一个2 bit 精度的权重,4 bit 精度的权重需要6 个SLC,对应地需要6 根SSL(图中只绘出2 根),因此4I4W 过程需要36 个SLC.对于更高精度的输入和权重,以及更多的图片像素(文中不考虑输入端口复用),需要更多的BL 和SSL,阵列具有相当的规模.Lue 等[49]并未从硬件上实现卷积核功能,他们测试了64 GB SGVC NAND 中单元的电性能.最后基于4 bit 精度的3D-NAND 卷积核电路,运行VGG-16 卷积神经网络对CIFAR-10 数据库进行识别,识别率达到90%.

图13 采用SLC 3D-NAND 实现4 bit 精度的卷积神经网络方案[49](a)卷积神经网络的工作原理示意图(上),涉及大量的MAC 过程(下);(b)对于多bit 权重 的MAC 过程,用多个SLC 器件构成 一个多bit 权重;(c)4 bit 精度输入与4 bit 精度权 重的MAC 原理;(d)卷积核电路的工作原理;(e)VGG 16 神经网络的结构图以及用所设计的3D-NAND 加速VGG 16 的性能Fig.13.A case of SLC 3D-NAND for convolution neural network(CNN)with 4-bit resolution[49]:(a)Flow schematic of CNN;(b)in a MAC array,plural SSLs to stand for multi-bit weight;(c)the arithmetic principle of MAC with 4-bit input and 4-bit weight(4I4W);(d)convolutional core circuit and working principle diagram;(e)schematic diagram of VGG 16 CNN and the simulated performance of 3D-NAND hardware implementation.
2019 年,Kim 等[50]提出了一种基于3D-NAND的卷积核映射方案,用4 个MLC(multi-level cell,2 bit 存储态的CTL 器件)构成了8 bit 存储态的突触,并实现了8 bit 精度的CNN 卷积运算,如图14 所示.图14(a)中将BiCS 结构的3D-NAND中的每个block 按BL 方向展开成2D-NAND,每个SGD 线(select gate at drain side,SGD)连接一个前级神经元接收输入信号.具体的卷积核映射方法如图14(b)所示.一个8 bit 的权重映射到一个string 上相邻的4 个MLC 中(P15/N15,P14/N14,P13/N13,P12/N12).两个相邻的block 中同一个SGD 线控制的两个string 上的权重分别标记为正、负,构成差分对.差分对中权重为正时,负权重设为0,反之权重为负时,正权重设为0.Kim 等[50]在2021 年的报道中增加了对卷积运算具体过程的阐述,如图14(c)所示.其过程为: 1)两个输入信号的第一位和权重的前两位进行乘加运算后得到4,下一步两个输入信号的第一位和权重的下两位进行乘加运算得到结果3,两次运算结果进行移位相加,即3×22+4×20;2)图中有24 根SGG线,支持24 个神经元信号同时输入进行乘加运算,乘加运算32 次后移位相加,得到24 个前级神经元对同一个后级神经元的输出.同一个string 上有16 个MLC,可存储4 个8 bit 权重,图14(b)的电路可以映射24 个前级神经元和4 个后级神经元之间全连接的突触.

图14 基于MLC 3D-NAND 的8-bit 精度卷积方案[50,51](a)基于BiCS 结构的3D-NAND 电路图[51];(b)权重的映射方式,正、负权重存储在相邻的两个block 中[51];(c)2 个8 bit 精度的输入信号和2 个8 bit 精度的权重的乘加运算过程[51];(d)基于eNAND 的卷积核电路,有7 个block,28 个输入端口,满足5×5 卷积核的功能[51];(e)卷积过程的信号时序图[51]Fig.14.A case of MLC 3D-NAND for CNN with 8-bit resolution[50,51]:(a)Circuit diagram of BiCS type 3D-NAND,the 3D structure can be flattened into a 2D structure[51];(b)weight mapping method,positive and negative weight stored in two neighboring blocks[51];(c)MAC operation principle of 2 inputs and two weights with 8-bit resolution[51];(d)convolutional core circuit diagram with 7 blocks and 28 input ports can be used for 5×5 convolution operation[51];(e)timing diagram of 5×5 convolution operation with 8-bit data and 8-bit weights[51].
由于NAND 厂商禁止开放WL 和SGD 端口的控制,Kim 等[50]用自研的16 层die 堆叠的eNAND等效3D-NAND(具体的eNAND 结构和工作原理不在此赘述).图14(d)中展示了基于eNAND 的卷积核电路,有7 个卷积用的Block 和一个用于修复的Block.此电路具有28 个输入端口,可以映射5×5 大小的卷积核,卷积的脉冲时序如图14(e)所示.基于此硬件方案,Kim 等[50]设计了LetNet-5进行MNIST 手写数字识别,识别率达到98.5%.
2021 年,Kim 课题组[52]提出了一种基于3D NAND 的卷积核映射方案,用1 bit 的MAC 算子进行分部相乘(partial multiplication)并采用Booth编码映射正负权重,显著地降低了VMM 过程中的电流,提高了芯片的能效,文中将这种芯片架构命名为S-Flash.图15(a)为卷积运算的过程,一个卷积层由k个尺寸为K×K×N大小的卷积核构成.输入信号和卷积核的精度通常为8 bit,那么卷积核在图像上进行一次滑动将产生k×K2×N(8 bit×8 bit)次MAC 运算.如何优化8 bit×8 bit计算过程是文献[52]研究的重点.文中将输入信号和权重拆分为低比特的算子进行分部相乘.将输入信号和权重的比特分别记为(Ba,Bw),当(Ba,Bw)=(1,1)时,进行64 次乘法运算.当(Ba,Bw)=(1,2)或(2,1)时,进行32 次乘法运算.图15(b)展示了(Ba,Bw)对乘法和积分对电路延时的影响,随(Ba,Bw)增大,乘法运算的延时略有降低,但电流积分的延时显著增大.这是因为MAC 运算的速率受限于ADC 精度,ADC 精度越高,外围电路的开销、延时和能耗越大.采用一般精度的ADC(如3-bit/4-bit),(Ba,Bw)越大,电流积分的次数越多,电流积分时间显著延长.文中采用(Ba,Bw)=(1,1)作为MAC 运算的基本操作单位.图15(c)展示了S-Flash 的架构,神经网络的每一层突触映射到沿WL 的每一层SLC 中,输入信号A1-An的8 位信号依次施加在BL 上,MAC 电流用SSL 收集,n为卷积核的通道数,用一个block 映射一个卷积核的一个通道,n个block 构成一个array 映射一个卷积核,多个array 映射一个卷积层.图15(d)展示了卷积核的映射过程,其中突触权重的精度为8 bit,16 个SLC 构成一个具有正、负权重的突触对.图15(e)展示了通过用Booth 编码正、负权重,以增加权重中的“0”位,提高MAC 过程中的稀疏性,从而降低MAC 过程中的总电流.为了进一步提高计算效率,将Ak×Wk对应的SLC 阵列中BL 和SSL 增大一倍,SLC 单元增大2 倍,原先8 bit ×8 bit 的MAC 次数从64 缩减为16,如图15(f)和图15(g)所示,将MAC 过程中具有4 倍SLC 规模但权重未经过Booth 编码的S-Flash 定义为S-Flash*,具有4 倍SLC 规模并且权重经过Booth 编码的S-Flash 定义为S-Flash**.

图15 基于3D NAND 的S-Flash 芯片用于卷积神经网络加速[52](a)卷积过程示意图;(b)MAC 算子的比特对乘、加运算延迟时间的影响(左)和MAC 算子的比特对累加运算延迟时间的影响(右);(c)S-Flash 芯片的架构;(d)S-Flash 中权重分布的示意图,用16 个SLC 构成一个差分结构的突触;(e)通过Booth 编码分配权重;(f),(g)同时操作的SSL 和BL 增大1 倍,MAC 次数缩减了1/4Fig.15.3D NAND-based CNN accelerator named as S-Flash[52]:(a)Convolutional operation of CNN;(b)normalized latency for multiplication,accumulation(left)and MAC operation in various multiplication units(right);(c)overall S-FLASH architecture;(d)overall weight data layout,in which a differential synapse constructed with 16 SLC;(e)weight allocation by Booth coding;(f),(g)double the concurrently operated BLs and SSLs,4 times faster the MAC operation speed.
最后通过电路仿真研究了S-Flash 芯片在运行卷积神经网络时的性能参数.分别用S-Flash,SFlash*和S-Flash**运行VGG-16 神经网络,计算了前向传播中每层神经网络的能效,并以GPU 方案时的能效为标准进行归一化,结果如图16(a)所示.从图16(a)可以看出,S-Flash,S-Flash*和S-Flash**的能效分别是GPU 的1.64,6.43 和13.49 倍,SFlash*和S-Flash**的能效分别是S-Flash 的3.9 倍和8.2 倍,所以正、负权重的分配对芯片能效的影响最大.S-Flash**中各电路模块的面积和能耗对比如图16(b)所示,可以看到ADC 面积占芯片面积的0.61%,但能耗占90.67%.图16(c)中表格列出了S-Flash**和其他芯片的性能参数,包括存储密度、单位面积的峰值吞吐量和能效,可以看到SFlash**在这3 个方面均有明显优势.

图16 S-Flash 电路仿真的结果[52](a)S-Flash/S-Flash*/S-Flash**运行VGG-16 卷积神经网络时的能效;(b)S-Flash**电路模块的面积对比和运行VGG-16 时各电路模块的能耗对比;(c)S-Flash**与其他芯片的性能参数对比Fig.16.Simulation result of S-Flash[52]:(a)Energy efficiency evaluation result of each VGG-16 layer accelerated by S-Flash/S-Flash*/S-Flash**;(b)area and energy breakdown of S-FLASH**;(c)comparison with the other platform.
2021 年,余诗孟课题组[53]提出了一种基于3D NAND 的神经形态芯片架构,用于卷积神经网络加速.图17(a)所示为在3D NAND 的一个block 中进行VMM 操作的方法: 沿WL 方向的每一层SLC 器件对应神经网络的每一层突触,输入信号XN施加在BL 上,权重Wi精度为2 bit,用3 个SLC 代表一个Wi,3 根SSL 用于突触选通.XN采用十进制编码,即精度为nbit 的XN,可用2n-1 根BL 来表示.用十进制编码的优势在于block 中所有string 上的电流可直接相加后进行模数转换,而无需移位操作.图17(b)中展示了2 bit 权重精度的卷积核映射方案,卷积核尺寸为K=KC×KW×KH,XN精度为nbit,卷积核中一个单元的权重映射到3×(2n-1)个SLC 中.图17(c)为多个block 构成的subarray,用于映射一个卷积层.VGG-8 卷积神经网络中,最大的卷积层中有16 个卷积核,Wi精度为2 bit,XN精度为8 bit.用一个block 映射精度为2 bit 的卷积核,block 的大小为521×3×3×(22-1)×(22-1)×32 WL=1.27 Mb.考虑到VGG-8 中权重的精度为8 bit,采用4 个2 bit 精度的block 通过分部相乘实现,那么1 个subarray 的大小为16×4×1.27 Mb=81 Mb.图17(d)为芯片架构的示意图,芯片中有4 个tile,每个tile 有4 个PE(process element),每个PE 有4 个subarray.VGG-8 神经网络需要110 Mb SLC,所设计的芯片容量完全满足需求.用HSPICE 计算了3D NAND 运行VGG-8网络用于CIFAR-10 图像识别任务的性能,电路中各模块的能耗占比如图17(e)所示.图17(f)列出了3D NAND 的性能参数,并与RRAM 和SRAM做比较,可以看到所设计的3D NAND 在各项性能指标上均有明显的优势.

图17 输入信号采用十进制编码的3D NAND 芯片用于卷积神经网络加速[53](a)用3D NAND 做VMM 的操作方法;(b)卷积核映射的方案;(c)subarray的结构示意图;(d)芯片的架构示意 图;(e)用3D NAND 芯片运行VGG-8 神经网络用于CIFAR-10 图片库识别时,各电路模块的能耗对比;(f)3D NAND 与其他芯片的性能对比Fig.17.A 3D NAND CNN accelerator with decimal input coding[53](a)VMM operation method by using 3D NAND;(b)the mapping method of a CNN kernel;(c)designed subarray configuration;(d)hierarchy of the 3D NAND-based neuromorphic chip architecture;(e)energy breakdown of 3D NAND-based chip on VGG-8 network for the CIFAR-10 dataset;(f)comparison with other chips.
2022 年,霍宗亮课题组[54]利用3D NAND 中CTL 的模拟权重调制特性,设计了两层全连接神经网络,用Winner-takes-all(WTA)非监督学习算法实现ZVN 图像的识别.图18(a)为3D NAND的操作示意图,不同于其他文献,文中阵列的输入信号施加在WL 上,输入信号为Vread和Vpass,分别代表输入像素点的明暗两种状态,即1 和0.突触映射在WL 平面的CTL 阵列中,采用差分对结构,输出电流在BL 端收集并通过TSG(top select gate transistor)控制.图18(b)中为CTL 器件的模拟权重调制特性,可以看到CTL 器件的长时程增强(long term potentiation,LTP)和长时程抑制(long term depression,LTD)过程具有良好的线性度.图18(c)展示了用3D NAND 实现非监督学习的训练过程.首先以相同的概率输入标准的Z,V,N 图像然后以WTA 法则进行权重更新.WTA 的权重更新法则: 以图像“Z”为例,当输入Xi为1 时,增强对应的3 个权重Gi, j=1,2,3,即增大值,减小值.然后将输出最大的后级神经元标记为winner,增强连接在winner 神经元的突触权重,即增大值,减小值,其他突触权重不变.在训练了标准图像后,训练带有噪声的Z,V,N 图像,即有一个像素点反转的图片,以提高神经网络的容错率.测试时用一组随机图像做推断,评估神经网络的性能.图18(d)中展示了训练之前和训练之后,3 个神经元的响应情况以及权重的分部.经过42 个训练周期后,3 个神经元能准确识别Z,V,N 图像,并且输入像素的权重随训练次数的增大,往正确的预测方向增大/减小.

图18 基于3D NAND 的WTA 神经网络用于非监督学习[54](a)具有差分对结构的3D NAND;(b)CTL 器件的模拟权重调制特性;(c)用3D NAND 训练WTA 神经网络的过程;(d)WTA 神经网络的训练结果Fig.18.A 3D NAND-based WTA neural network for unsupervised learning[54]:(a)Schematic of the differential pair in 3D NAND flash array;(b)analog weight modulation of measured CTL device;(c)the training procedure of WTA neural network using 3D NAND array;(d)stylized letter clustering results before and after training.
上述关于用于前向传播的3D NAND 均采用二值或者幅值编码.2020 年Lee 等[55]设计了一种基于脉宽编码的操作方案,在3D-NAND 中实现了前向传播过程,如图19 所示.图19(a)展示了前向传播的原理和操作方式: 1)前级神经元发放的脉冲输入信号采用脉宽编码,通过脉宽调制电路(pulse width modulation,PWM)发放施加在SSL,神经网络中每一层突触映射到3D-NAND 中每一层CTL 器件上,并且采用差分对结构用两个CTL器件分别存储正、负权重;2)SL 上施加驱动电压VBL,选通层的WL 上加较小的选通电压Vread,未选通层的WL 上加较大的导通电压Vpass,VBL经过选通层的正、负权重转化为电流进入后级神经元电路;3)神经元电路的结构如图19(b)所示,输出的电流经过电流镜构成的差分电路,相减后对电容进行充电得到后级神经元的电压Vc,其中SSL 上输入信号的脉宽决定了SSL 上晶体管的开启时间,即电流的积分时间.Lee 等[55]根据3D-NAND 的硬件方案设计了3 层全连接的卷积神经网络,对CIFAR-10 图片数据库进行识别任务,并且比较了权重精度为1 bit 和4 bit 时网络的性能表现,如图19(c)所示.

图19 3D-NAND 中采用脉宽编码实现前向传播[55](a)前向传播的操作方式、神经网络示意图和WL 上读电压的时序图;(b)左: 前向传播的工作原理示示意图,即两个标记为正、负权重的突触对构成一个突触,输出电流相减后通过电容积分转化为电压Vc;右: 读电压Vread、SSL 上输入脉冲VSSL 和Vc 的时序图;(c)3 层全连接CNN 网络在权重精度为4 bit(QNN)和1 bit(BNN)条件下对CIFAR-10 图片数据库的识别性能Fig.19.Forward propagation using 3D-NAND with pulse width modulation(PWM)scheme[55]:(a)Operation scheme of forward propagation,schematic diagram of neural networks,the timing diagram of pulses applied to WLs;(b)Left: schematic diagram of synaptic string array consisting of synapses with positive weight(G+)and synapses with negative weight(G-);Right: timing diagram of Vread,VSSL,and Vc;(c)simulated classification accuracy of 4-bit QNN and BNN for CIFAR-10 images.
2.2.2 3D-NAND 用于反向传播
由于CTL 器件擦写次数有限,因此3D-NAND通常用于权重更新不太频繁的应用场景.通常将已训练好的权重映射到3D-NAND 中,执行推断任务,2.2.1 节中介绍的工作均基于此应用场景.但在硬件上直接训练权重,显然更智能且经济.除了有限的器件擦写次数,在3D-NAND 中做反向传播面临两方面的挑战.第一,反向传播中突触矩阵和前向传播中互为转置,另选硬件资源映射转置后的突触矩阵做反向传播(如图10(c)所示),训练时间代价较高,也容易出错.第二,突触往往采用差分对结构,NAND 的串行结构天然不适合反向传播.因此如何设计反向传播的操作方案是关键.
2021 年,Lee 等[56]在2020 年报道的方案上[55]做出改进,可以在3D-NAND 同一个CTL 阵列中同时实现神经形态计算中的前向传播和反向传播过程,如图20 所示.根据神经网络的工作原理,反向传播过程中误差信号从最后一层神经元输入并依次向前级神经元传递.对于crossbar 结构的突触阵列,反向传播时误差信号从原输出端输入,从矩阵相乘角度看,前向传播和反向传播过程中突触阵列的矩阵互为转置的关系,如图20(a)所示.但如果硬件采用差分对结构,相邻的器件分别为正、负权重,前向传播和反向传播时突触的矩阵则为非转置关系,如图20(b)所示.为了实现反向传播,Lee等[56]将所有突触的正、负权重用两个阵列分开配置,如图20(c)所示.
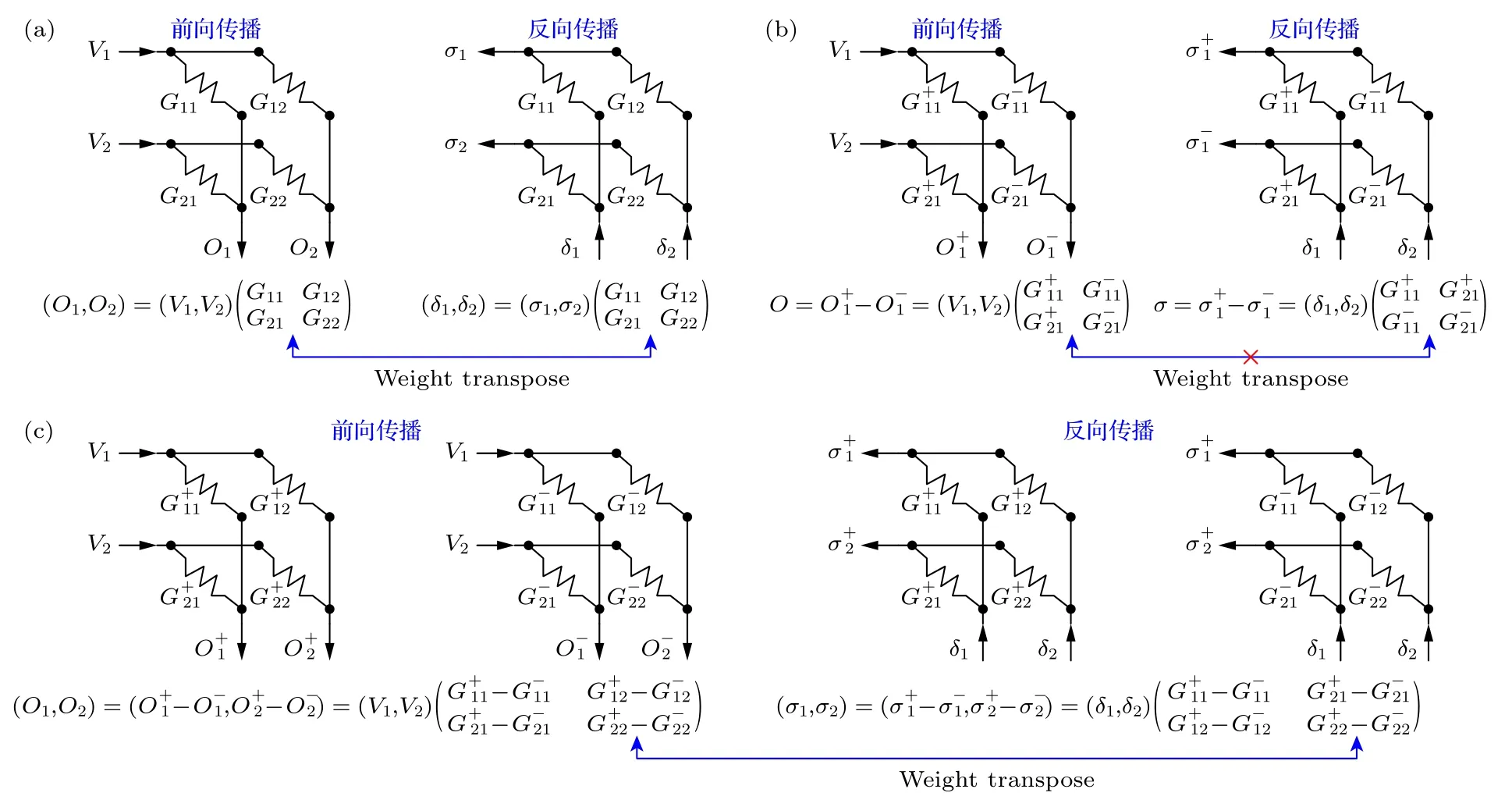
图20 差分对突触阵列中将正、负权重分开放置可实现反向传播[56](a)前向传播和反向传播过程中对应的突触阵列,从矩阵运算角度上看互为转置结构;(b)通常情况下,差分对结构中的正、负权重在同一个阵列中,突触阵列与前向传播过程中并非转置的关系,无法实现反向传播功能;(c)将正、负权重分开置于不同的阵列中,可以实现反向传播过程Fig.20.Backward propagation can be implemented using a differential synaptic array where positive and negative weights are separated[56]:(a)The matrix of synapse weight in forward and backward propagation are transposed;(b)synaptic array architecture consisting of two adjacent cells representing G+ and G-,the weights cannot be transposed;(c)synaptic array architecture where G+and G- weights are separated in different arrays.
Lee 等[56]用3D-NAND 实现前向和反向传播的原理如图21 所示.前向传播过程如图21(a)所示: 1)前级神经元的输入信号用脉宽编码,通过PWM 模块发生并施加到BL 上,SSL 控制NAND string 的开关,即控制流入到对应的各个后级神经元的电流.2)3D-NAND 中每一层突触器件对应神经元中的每一层全连接突触,如图21(c)所示,信号前向传播到第i层时,在3D-NAND 第i层的WL 上施加选通电压Vread,在其他层施加导通电压Vpass;3)所有前级神经元输入的脉冲信号分别经过正、负权重,转化为电流在输出神经元电路中进行差分后积分转化为输出电压.反向传播的过程如图21(b)所示: 1)反向传播的误差信号同样采用脉宽编码,通过PWM 电路发生并施加在SSL 上.由于读操作中CTL 单元的电流受栅-源电压控制,即Vread减去CTL 单元源端的电位,而源极的电位与pass 状态的CTL 单元的分布情况有关.如果反向传播过程的误差信号施加在SL 端,那么CTL的源极电位与前向传播时不一致,即CTL 栅源电压不一致,读电流将会产生较大的误差.因此Lee等[56]将误差信号从SSL 端输入,既能保证权重的转置也能避免pass 单元造成的读误差.2)Vread和Vpass依次施加各层WL 上,施加的顺序与前向传播相反.3)BL 连接前级神经元电路,SL 上施加驱动电压VBL,每个NAND string 上的产生电流在神经元电路中做差分后积分得到输出电压,通过SSL 上误差信号的脉宽决定了电流在神经元电路中的积分时间得到对应的电压.

图21 基于3D-NAND 的前向传播和反向传播的工作原理[56](a)前向传播中3D-NAND 的操作方法;(b)反向传播中3DNAND 的操作方法;(c)具有n 层全连接突触的神经网络结构;(d)前向传播和反向传播中WL 上选通电压Vread 和导通电压Vpass 的时序Fig.21.Forward and backward propagation using 3D-NAND with PWM scheme[56]:(a)Synaptic array architecture based on NAND flash memory for forwarding propagation operation;(b)synaptic array architecture based on NAND flash memory for backward propagation operation;(c)schematic of neural networks consisting of n weight layers;(d)timing diagram of Vread and Vpass in forwarding propagation and backward propagation.
CTL 器件通过写脉冲可具有32 个不同的Vth,即5 bit 的权重态,如图22(a)所示.图22(b)中用不同的读电压V1-V5可得到不同的权重态分布,其中读电压越大,权重变化范围越小,但分布越线性.Vpass对Vth基本没有影响,如图22(c)所示.写/擦脉冲循环对权重态的分布也基本无影响,如图22(d)所示.CLT 器件权重的精度为5 bit,差分对构成的突触精度达到6 bit.基于测试得到的几种权重态分布和单元之间的权重误差分布,Lee 等[56]设计了全连接神经网络用于MNIST 图片识别任务,网络的性能表现如图22(e)所示.其中权重态分布越线性,网络识别率越高.将网络中隐藏层数量增加到3 层,可以略微提高网络识别率,如图22(f)所示.

图22 器件特性和神经网络性能[56](a)器件的IBL-VBL 特性随写入脉冲数量的变化;(b)图(a)中器件的归一化电导随写脉冲数量的变化;(c)导通电压Vpass 和写电压VPGM 对阈值电压的影响;(d)初始状态的器件和经历过擦写循环的器件对写入脉冲的响应;(e)三层全连接神经网络的识别率;(f)隐藏层数量对识别率的影响Fig.22.Device characteristics and neural network performance[56]:(a)IBL-VBL curves with an increasing number of program pulses;(b)normalized conductance responses measured in(a);(c)IBL-VWL curves measured in a fresh,Vpass disturbed,and programmed cell;(d)conductance response of fresh and cycled cell;(e)recognition accuracy of 3-layer neural network;(f)recognition accuracy with the number of hidden layers.
2.2.3 各项工作的比对
基于3D-NAND 的神经形态计算的各项工作比对如表2 所列.
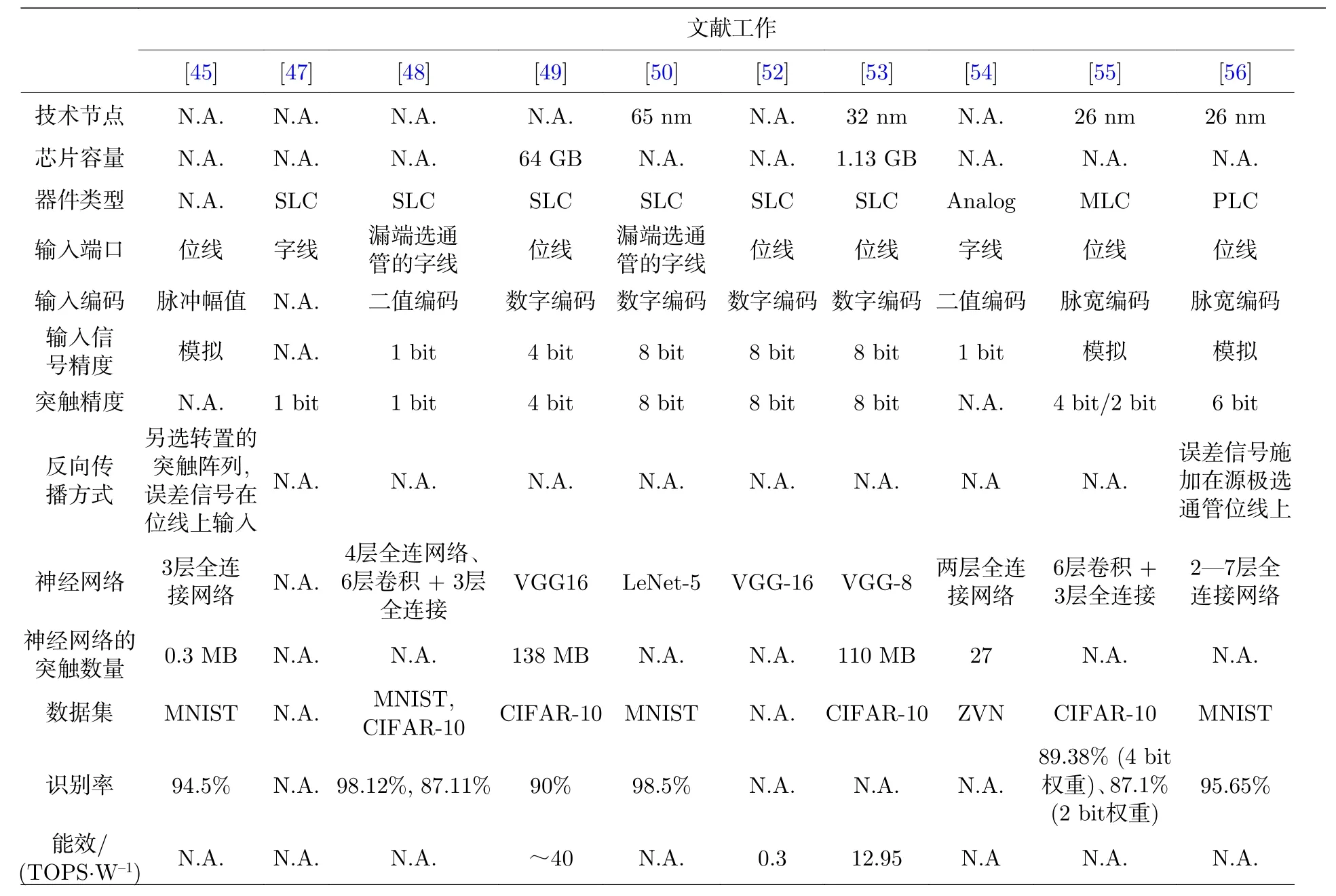
表2 基于3 D-NAND 的神经形态计算的各项工作比对Table 2. A comparison of reviewed works.
3 总结与展望
过去几年,具有存算一体特性的AI 芯片不断涌现,工艺节点涵盖了14-180 nm,计算架构包括了近存计算、存内计算和神经形态计算,应用场景覆盖了边缘端到云端设备.在各种硬件方案中,基于3D-NAND 的神经形态芯片在芯片容量,CMOS工艺兼容性和成本方面极具优势.本文首先介绍了3D-NAND 的基本结构和原理,以及用于神经形态计算的优势和不足.然后详细梳理了近几年关于NAND 和3D-NAND 用于神经形态计算的代表性工作,重点介绍了其中的编码方式、前向传播原理和反向传播过程.
基于现有的工作,考虑到3D-NAND 的优势与不足,如用于未来的神经形态计算,3D-NAND需要做的调整如下:
1)器件层面.用于数据存储的3D NAND,器件采用电荷俘获型晶体管(CTL),通过在栅极施加高幅值和长时程的脉宽(>10 V,>100 µs),利用Fowler-Nordheim 隧穿效应,在电荷俘获层中注入或擦除电子以改变阈值电压(Vth),实现存储功能.随擦写次数的增加,隧穿绝缘层的晶格会被破坏甚至失效,因此CTL 的擦写次数有限.低功耗是神经形态计算的特点,CTL 器件的操作功耗需要进一步优化.目前国内外的一些研究机构,探索了将氧化铪基铁电材料替代传统的氮化硅电荷俘获层[57,58],利用铁电效应实现了器件的存储功能.如果能将铁电技术成功地应用到3D NAND 中,能大幅提高器件的擦写次数,并且降低操作功耗.
2)结构层面.1)CTL 晶体管是3D NAND 的基本单元,多个CTL 器件组成一个NAND string,多个string 组成一个block,多个block 组成3D NAND 结构.在神经形态计算中,突触和神经元是神经网络的基本单元.2)突触可由一个或多个CTL 器件构成.对于低精度的计算,可采用幅值或者脉宽编码,输入/输出均为模拟信号,单个CTL突触即可满足模拟计算的需求,电路结构简单原理直观.对于高精度的计算,则采用二值编码,用多个SLC 构建一个多bit 精度的突触,采用二进制计算方式.3)突触多采用差分对结构G=G+-G-,为了避免正、负突触阈值电压达到最大而无法进一步更新权重,3D NAND 中通常需要定期进行块擦除并重新赋予突触权重值.2021 年,首尔大学和SK Hynix 合作开发了适用于神经形态计算的单个CTL 器件的擦除方案,避免了定期的块擦除[59].
3)架构层面.存储用途的3D NAND 只涉及读、写、擦操作,计算由外部的CPU 负责.读写按block→string→CTL 的顺序串行操作.区别于存储用途,在用于神经形态计算的3D NAND 中,读操作增加了MAC 运算,外围电路需要配置大量的ADC/DAC 和移位加法器等单元.并且读写操作按神经网络的映射规则执行,不一定按block→string→CTL 的顺序.
最后,由于3D-NAND 的专利特性,厂商并未开放用户对芯片颗粒端口的权限.目前的工作中,前向传播过程和反向传播过程并未做硬件实现,多数是基于厂商样片测得的存储单元特性以及读误差分布,通过电路和软件层面上仿真得到的结果.未来的工作应该考虑与厂商有更深入的交流合作,在硬件层面执行前向传播、反向传播和权重更新,更直接地展示3D-NAND 在神经形态计算方面的应用潜力.
猜你喜欢
心理学报(2022年5期)2022-05-16
电子产品世界(2021年8期)2021-01-16
考试与评价·高一版(2020年2期)2020-10-29
当代陕西(2020年17期)2020-10-28
中国计算机报(2019年49期)2019-02-07
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
中国新闻周刊(2017年36期)2017-10-21
创新时代(2016年8期)2016-10-21
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
