
域名滥用行为检测技术综述
2022-11-11 10:49樊昭杉刘俊荣崔泽林刘玉岭
计算机研究与发展 2022年11期
樊昭杉 王 青 刘俊荣 崔泽林 刘玉岭 刘 松
1(中国科学院信息工程研究所 北京 100093) 2(中国科学院大学网络空间安全学院 北京 100049)
随着信息技术的发展,互联网已经成为人们生活中不可或缺的重要组成部分.域名系统(domain name system, DNS)是互联网的重要技术支撑,可以为用户提供便捷和灵活的网络服务,但同时也是网络攻击者的攻击目标和恶意活动的支撑资源,被广泛地滥用在多种网络攻击中.例如,恶意软件利用域名来定位其命令和控制(command and control, C&C)服务器,垃圾邮件包含的恶意链接通过DNS将用户重定向到漏洞利用或网络钓鱼页面[1-2].
近年来,域名滥用日趋严重,对网络空间安全产生巨大威胁,大量检测工作随之涌现.学术界将散布恶意软件、操控僵尸网络、分发垃圾邮件、网络钓鱼和欺诈作为典型域名滥用方式进行研究[1,3-4].其中不乏一些总结性工作,文献[5-8]分别从数据来源、检测特征、检测算法、评估策略以及检测对抗技术等角度对现有工作进行梳理,分析域名滥用检测的纵向技术演进.然而,尚未有工作针对具体的域名滥用行为总结现有检测方法、提供全面的横向和纵向对比分析.
本文从典型的滥用行为出发,定义并分类不同的域名滥用检测场景,提供现有域名滥用行为检测方法的系统概述,有助于更好地理解当前域名滥用检测技术的应用场景、局限性和发展方向.
1 背景介绍
1.1 DNS简介
DNS提供将域名映射到IP地址空间的服务,由域名空间和资源记录、名称服务器和解析器构成.
1) 域名空间和资源记录.DNS具有层次化的树状名称空间,称为域名空间,域名空间中的每个结点具有标签和一组资源记录.域名是当前结点到根结点路径上标签的组合,如图1所示.
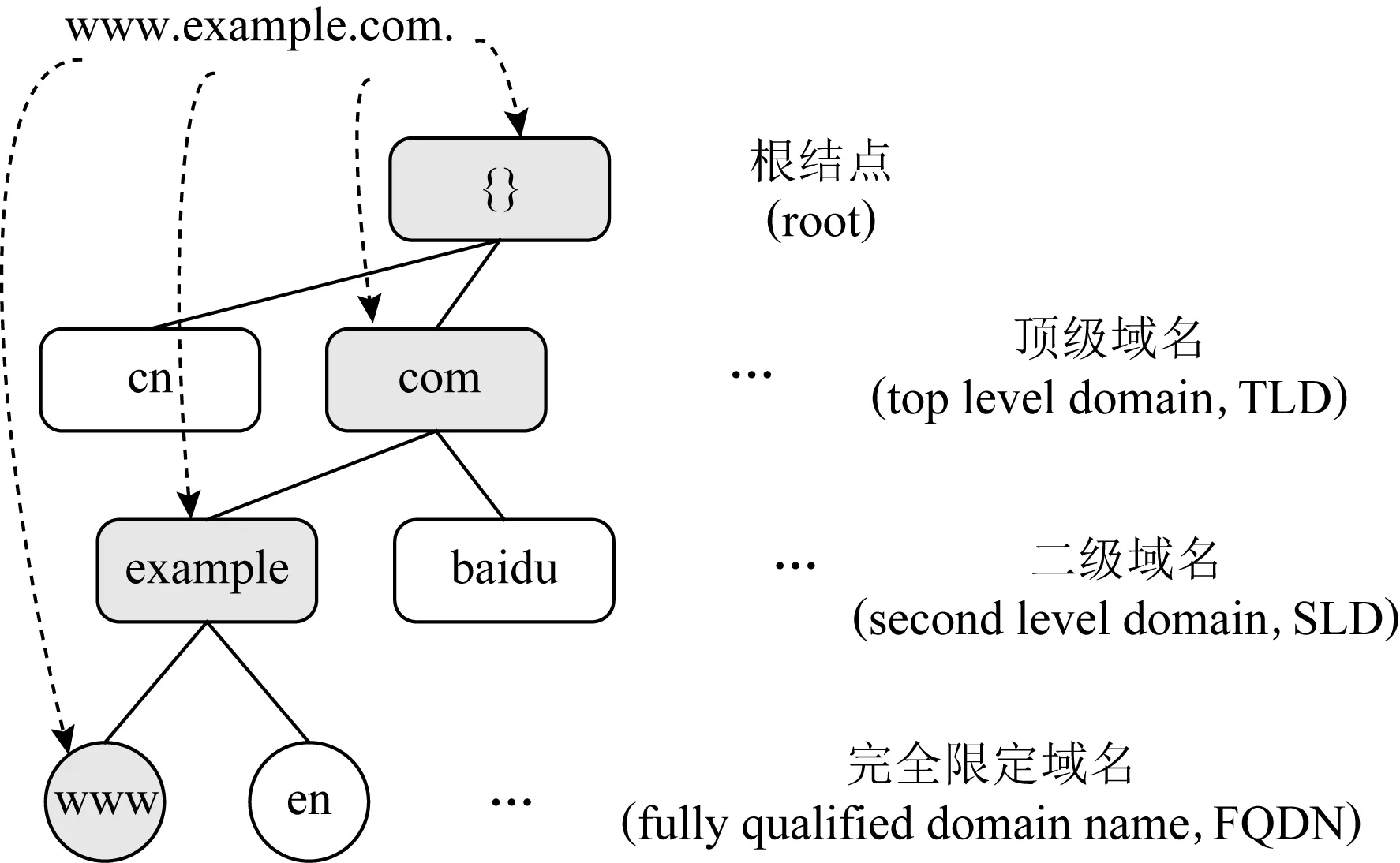
Fig. 1 DNS domain name space图1 DNS域名空间
2) 名称服务器.DNS分布式数据库由多台名称服务器构成.每台名称服务器负责保存域名空间部分结点的信息,同时提供域名解析服务.根据解析范围可划分为4类:根、顶级、权威和本地名称服务器.
3) 解析器.解析器是请求资源记录的DNS客户端程序.DNS支持2种解析方式:递归解析和迭代解析.递归解析发生在客户机向本地名称服务器发起解析请求阶段;迭代解析发生在本地名称服务器与其他名称服务器通信的过程中,图2展示DNS解析过程:
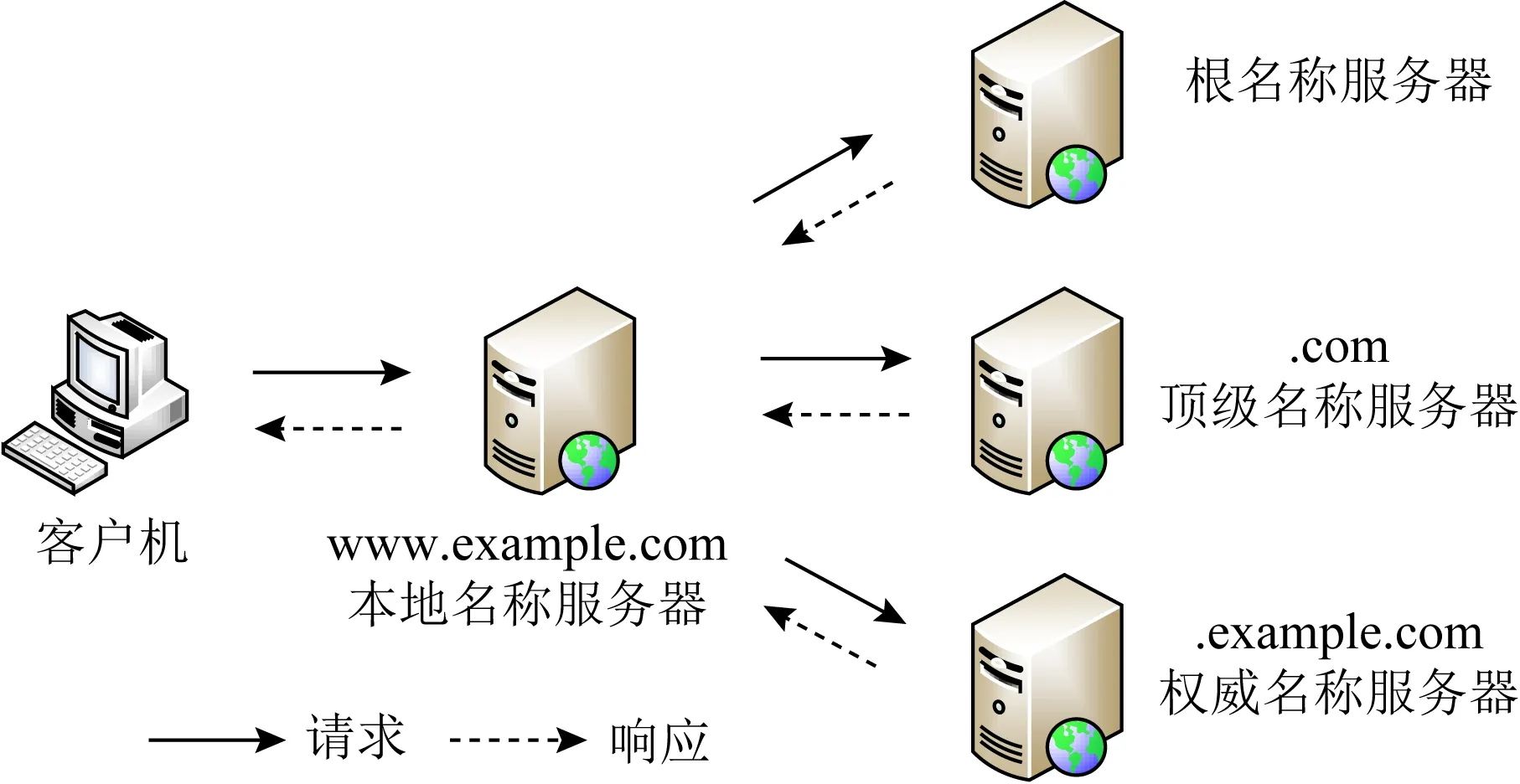
Fig. 2 DNS resolution process图2 DNS解析过程
DNS提高了网络的易用性,推动了互联网的发展进程,以DNS服务为基础的技术也不断涌现,例如泛域名解析和内容分发网络(content delivery network, CDN).这些技术在为互联网提供高可用性和高性能的同时,也被攻击者广泛应用以提高滥用域名的可用性和对黑名单的抵抗能力,这些技术给域名滥用的甄别和检测带来极大的挑战[5,9].
1.2 域名滥用检测场景分类
学术界和工业界尚未给出域名滥用的分类标准.本节通过调研现有域名滥用检测方案,对现存多种域名滥用行为进行汇总和归并,提出本文的域名滥用检测场景分类体系,如图3所示:
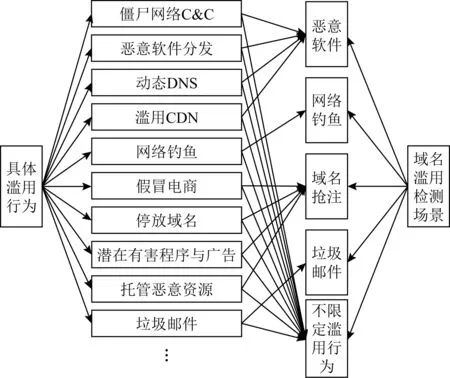
Fig. 3 Taxonomy of domain name abuse detection scenarios based on specific behaviors图3 基于具体行为的域名滥用检测场景分类体系
1.2.1 域名滥用行为调研分析
本文首先调研学术界和工业界有关发现、解释或缓解DNS生态系统中域名滥用情况的工作,抽取典型域名滥用行为,汇总得到表1.值得注意的是,本文仅关注2类域名滥用行为:解析到受控恶意资源、服务于恶意活动.典型例子有恶意软件C&C通信、网络钓鱼.而诸如DNS隧道、DNS放大和拒绝服务攻击、DNS劫持等对DNS通讯协议或DNS基础架构发动攻击的DNS威胁,均不在本文的讨论范围内,在总结表1的过程中有针对性地予以剔除.
进一步根据表1中列举的域名滥用行为关键词,从Web of Science核心数据库中筛选出近10年(2010—2020年)领域相关文献446篇.使用Citespace工具对域名滥用行为检测领域的高频术语进行共现分析,得到图4共现关键词聚类时间轴图.

Table 1 Summary of the Work Related to Domain Name Abuse
图4中,时间轴图以关键词出现年份为X轴(顶部年份)、关键词类簇标签为Y轴(右侧标签),反映该领域的热点主题.每个类簇的关键词共享一条时间轴线,轴线上的同心圆表示一个关键词,同心圆的大小代表出现频率,同心圆的颜色深浅代表时间跨度,同心圆间的连线代表关键词共现情况.
从图4中可以看到,去除掉安全领域、通用领域关键词类簇标签,可以得到本领域的研究重点包括:恶意软件、僵尸网络、网络钓鱼、域名抢注、垃圾邮件.从同心圆连线的紧密程度分析,恶意软件和僵尸网络的共现关系较为紧密,典型共现关键词包括“Domain-Flux”“Fast-Flux”等,可将面向僵尸网络的域名滥用作为恶意软件的一个子类别进行概述.
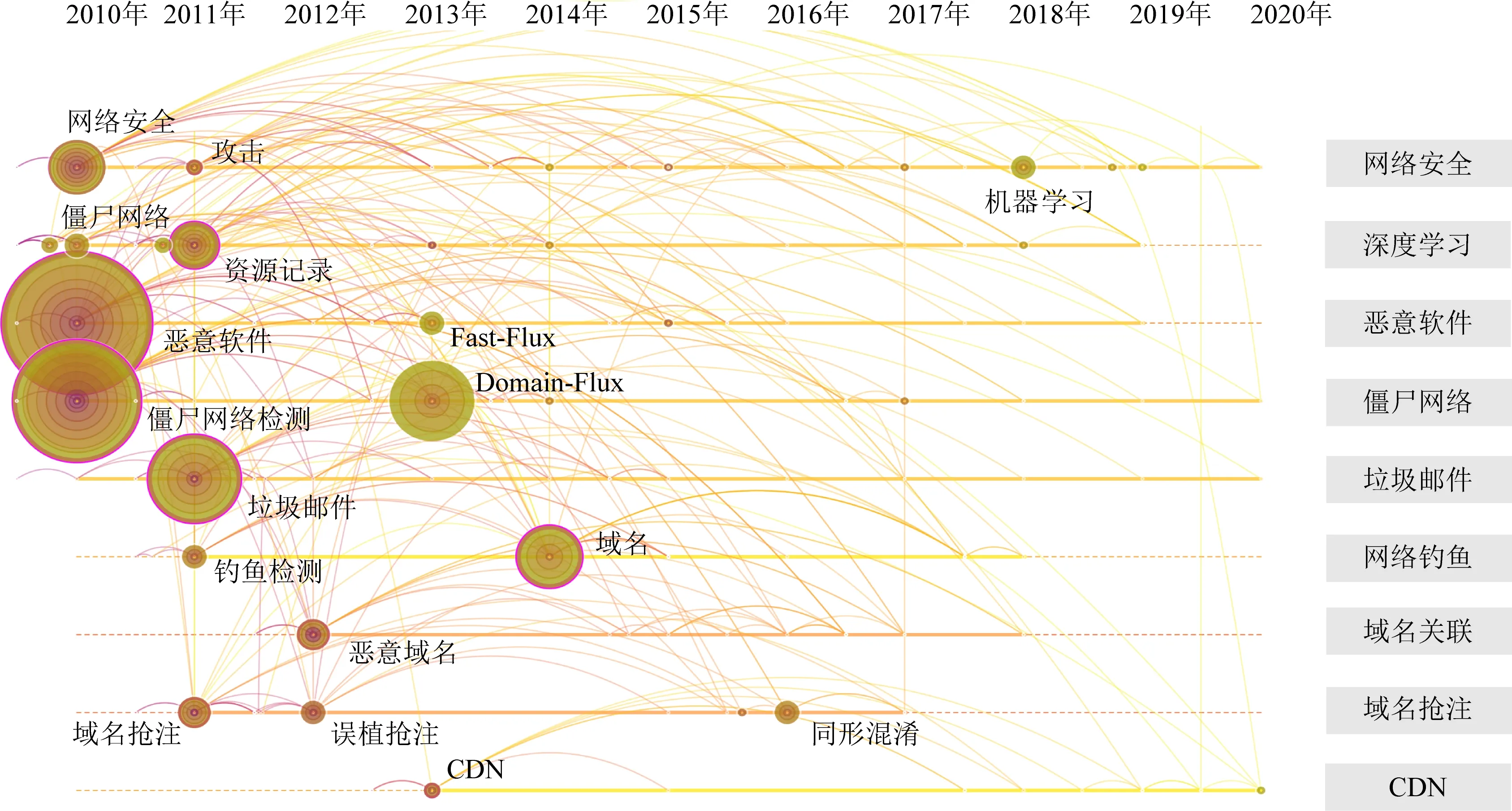
Fig. 4 Timeline view of domain name abuse detection co-occurrence keyword clustering图4 域名滥用行为检测领域的共现关键词聚类时间轴图
1.2.2 构建域名滥用检测场景分类体系
本文以图4的类簇标签为指导,对表1中存在重叠检测方案的域名滥用行为,面向检测场景进行合并:例如,僵尸网络C&C、恶意软件分发、动态DNS和滥用CDN都依托于Fast-Flux或Domain-Flux等恶意软件常用的DNS动态解析技术实现,可归并为恶意软件场景下的检测目标;假冒电商、影子域名、托管恶意资源、欺诈域等滥用行为,常常通过抢注与流行域相似的域名诱导受害者访问,可归并为域名抢注检测场景下的检测目标;此外,本文增加不限定滥用行为检测场景,广泛捕获多种域名滥用行为,作为其他场景检测方案的补充.最终确定恶意软件、网络钓鱼、域名抢注、垃圾邮件、不限定滥用行为5类典型检测场景,作为本文的主要研究对象,如图3所示.
值得注意的是,在本文的分类体系中域名滥用行为存在交叉,例如,垃圾邮件可能包含钓鱼链接或恶意软件附件;域名滥用检测方法往往融合多领域知识,例如,恶意软件域的检测可通过逆向工程、监听DNS通信流量等技术手段实现.本文在梳理域名滥用检测方法时,考虑仅适用于当前场景的检测方法,且仅关注使用DNS相关特征的域名滥用检测技术.
1.3 域名滥用检测特征及检测方法概述
当前阶段,域名滥用检测的主流技术方案大多采用机器学习方法,关键在于特征工程,即提取区分滥用域和良性域的检测特征.本文将滥用域检测特征归为6个大类,下面分别进行简要介绍.
1) 域名字符级特征.从域名字符级组成的角度区分良性域名与滥用域名.结构特征关注域名的结构属性;语言特征捕获语言模式的偏差;统计特征分析字符构成的随机性;相似度特征考察字符级的相似度.
2) 域名解析特征.从DNS通信流量及应答记录中捕获异常.记录特征关注滥用域资源记录频繁改变和资源重用的特点;空间特征考虑滥用域的地理空间分布较为松散的特点;时间特征分析域名的活跃时段、生存时间(time to live, TTL)等与时间相关的特征.
3) 域名关联特征.基于与已知滥用域有强关联的域很可能是滥用域的假设,通过分析主机、域名和IP之间的查询、解析关系,捕获潜在滥用域.主要包括主机-域名的查询关联和域名-IP的解析关联特征.
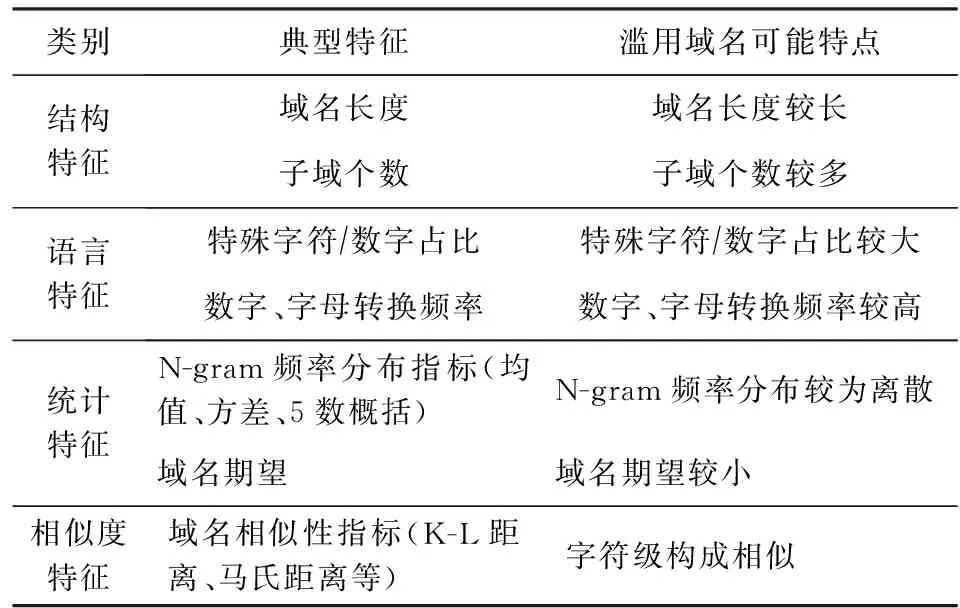
Table 2 Character Level Features of Domain Name
4) 统一资源定位符(uniform resource locator, URL)特征.常用于网络钓鱼域名的检测.字符级特征分析URL的字符组成;访问特征关注用户访问URL的特点;页面特征考察域名托管页面的特点;相似度特征关注钓鱼链接与官方链接的相似性.
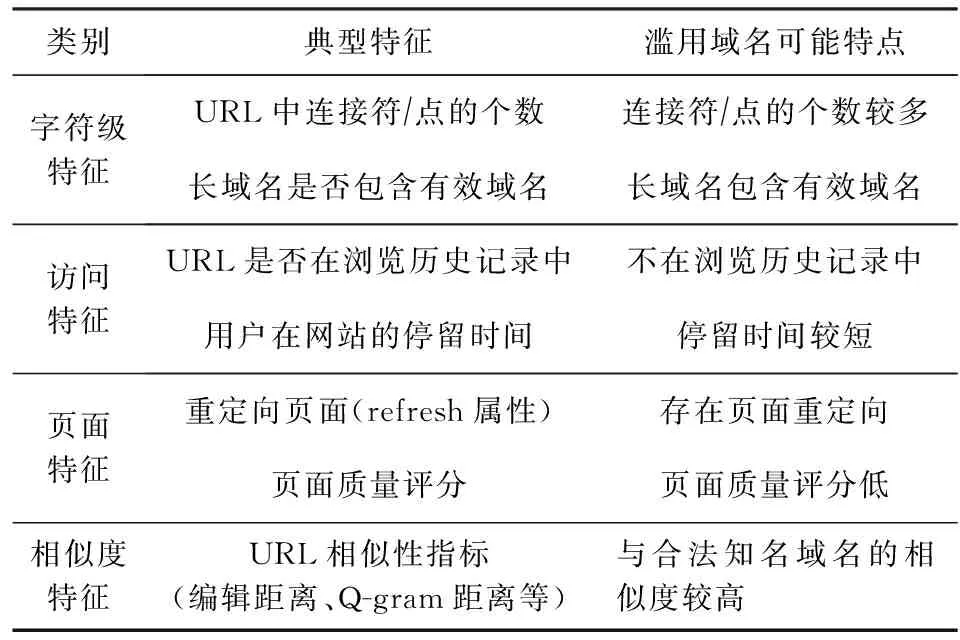
Table 4 URL Features表4 URL特征
5) 域名抢注特征.域名抢注特征主要关注5类抢注域的典型构造方式,包括误植抢注构造特征(替换、增加、删减流行域名的字符)、字符比特翻转特征、同音字符替换特征、同形字符替换特征、组合抢注构造特征(拼接流行域名和常见短语).
6) 辅助信息特征.部分检测方案借助辅助信息判别滥用域,常用的辅助信息包括:公共情报数据、whois信息、域名区域文件信息等,挖掘这些信息可以辅助域名判别.
基于前述的特征分类,表5汇总5类典型域名滥用检测场景涉及的主要检测方法及其检测特征.以恶意软件检测场景为例进行介绍,主要检测方法可划分为基于IP-Flux和基于Domain-Flux这2类,其中,基于IP-Flux的具体检测方案使用的典型特征包括域名字符级特征、域名解析特征、域名关联特征和辅助信息特征四大类别,并列出相应的参考文献.本文将在第2节进一步梳理各域名滥用检测场景下的典型检测方案.

Table 5 Summary of Detection Methods and Typical Features of Domain Name Abuse Detection Scenarios表5 域名滥用检测场景的检测方法及典型特征汇总
2 不同场景下的域名滥用检测
本节分别针对恶意软件、网络钓鱼、域名抢注、垃圾邮件以及不限定滥用行为5类场景下的域名滥用检测工作进行梳理.其中,每一场景下的检测工作都依次按照检测方法、具体检测方案进行归并.本节聚焦检测技术的演进过程,提供一个以检测场景为导向的域名滥用行为检测工作概述.
2.1 面向恶意软件的域名滥用检测
恶意软件包括蠕虫、木马、僵尸程序或其他具有恶意意图的程序,旨在破坏计算机系统的运行,窃取专有信息或获得访问控制权限.据AV-Test发布的最新数据显示,截至2020年底,全球范围内统计到的恶意软件总数已超11亿,约为2011年的17倍[92].
恶意软件大多滥用DNS协议,利用动态DNS解析技术(IP-Flux或Domain-Flux)实现受感染主机与C&C服务器之间的通信.考虑到逆向工程成本较高,许多工作通过分析DNS流量、挖掘恶意通信域名来实现感染主机的检测以及C&C通道阻断.下面将恶意软件检测场景的研究划分为两大类:基于IP-Flux的检测和基于Domain-Flux的检测.表6列举典型检测工作在面向恶意软件的域名滥用检测领域的贡献及其局限性.
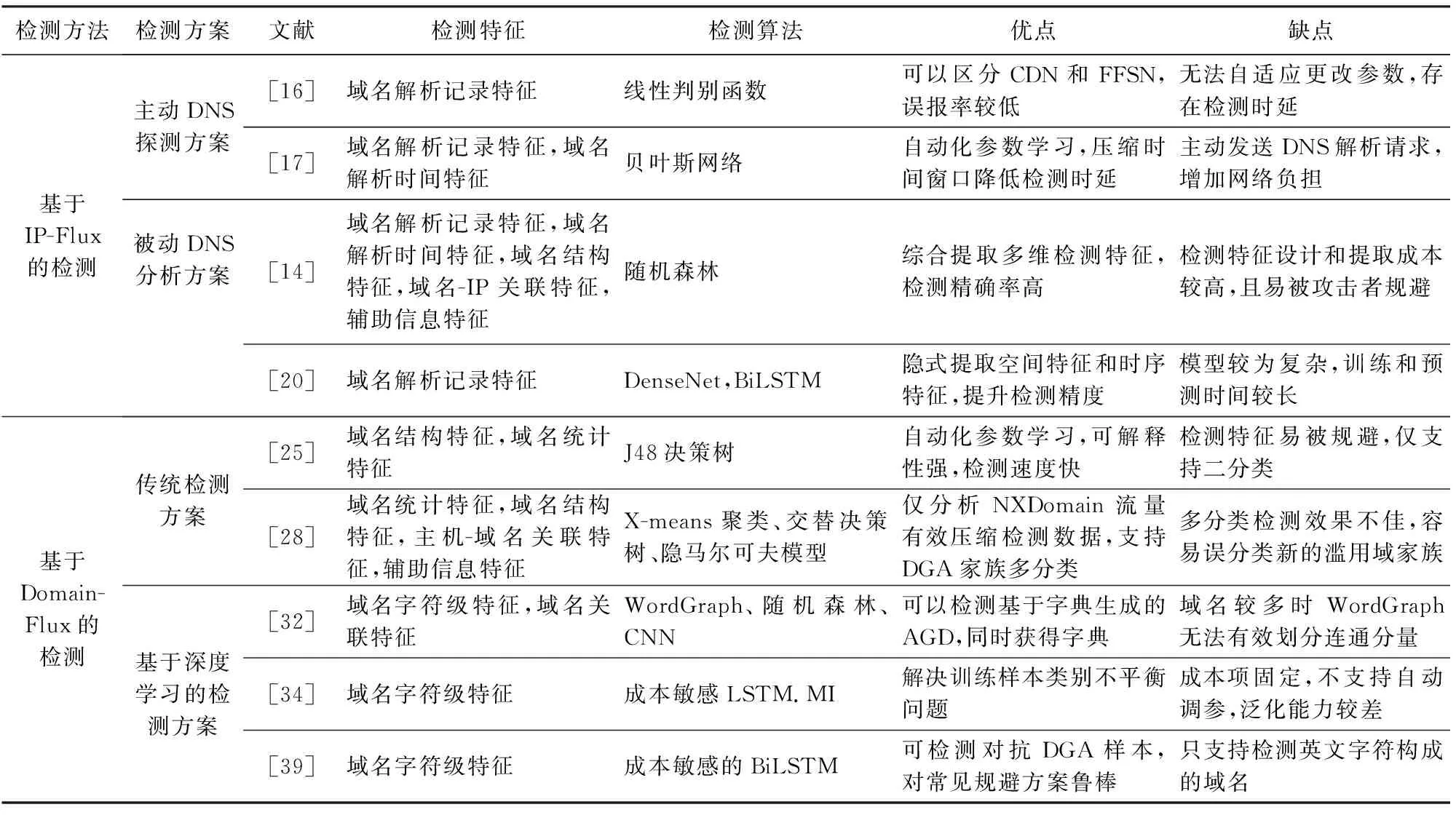
Table 6 Comparison of Typical Domain Abuse Detection Works Oriented to Malware Software表6 面向恶意软件的典型域名滥用检测工作的比较
2.1.1 基于IP-Flux的检测
互联网名称与数字地址分配机构(Internet Corporation for Assigned Names and Numbers, ICANN)将IP-Flux(Fast-Flux)描述为“对主机和(或)名称服务器资源记录快速且反复地更改,使得域名解析为动态变化的IP地址”.使用IP-Flux技术构建的网络,被称为速变服务网络(fast flux service networks, FFSN).长期以来,IP-Flux技术被多种恶意软件滥用,同时也是滥用域名的有力检测指征.
基于IP-Flux的检测技术演进过程概述:早期采用主动DNS探测方案,提取DNS解析特征进行检测,随后发展为被动DNS分析技术,研究重点在于区分FFSN和CDN.在持续的攻防博弈中,攻击者不断提高IP-Flux技术的隐蔽性,检测算法也相应地引入多类检测特征.现阶段,考虑到传统检测方案的局限性,学术界将深度学习算法应用于IP-Flux域名检测.
1) 主动DNS探测方案
主动DNS探测方案通过在固定时间窗口内向待检测域名发起多次DNS解析请求,提取DNS响应特征,构造分类器,实现滥用域名的判别.
最早的一篇具有指导性意义的工作是Salusky等人[93]发表的Honeynet项目论文,他们给出基于IP-Flux的滥用域名检测问题的实验建议,提出在固定时间窗口内,对域名的DNS解析结果集进行评分的方案,为后续主动DNS探测方案奠定基础.2008年Holz等人[16]发表有关FFSN的首个实证研究,他们对所有域执行2次DNS查询,从域解析结果集中提取检测特征,计算待检测域的flux分数.该方案借助阈值判定滥用域,无法自适应检测不断变化的FFSN架构.
主动探测方案的时间窗口大小对检测效果影响较大:过小的时间窗口无法获得足够的信息,过大的时间窗口则会造成检测延迟,这种延迟可能会导致攻击扩散.针对这一问题,Caglayan等人[17]同时使用主动DNS探测和被动DNS监听技术,利用历史解析数据有效压缩时间窗口,实现分钟级别的FFSN检测.该篇工作引入被动DNS数据,具有开创性意义,但本质仍属于主动DNS探测方案.
主动DNS探测方案的优点是数据收集的灵活性和易用性,可以有针对性地获取待检测域名的解析信息;局限性在于会产生过多的网络传输流量,增加网络负担,密集的DNS请求易被攻击者发现.
2) 被动DNS分析方案
被动DNS分析方案主要通过在网络中部署被动DNS传感器或访问DNS服务器日志以获取真实的DNS查询和响应,被动地收集DNS数据,相较主动DNS探测方案检测成本低且较为隐蔽.目前大多数研究都采用被动分析方案,具体的研究方向包括检测特征的设计和检测算法的改进:
① 检测特征设计.许多工作根据IP-Flux技术的典型特点进行检测特征构造.文献[18]关注到FFSN具有地理分布更均匀和空间服务关系更松散的特点,使用空间快照机制取代基于时间的特征,提出一种无延迟的检测系统SSFD(spatial snapshot Fast-Flux detection),图5展示该系统的工作流程.
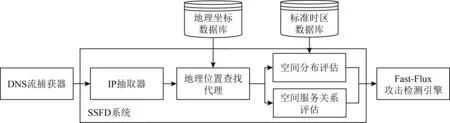
Fig. 5 System workflow of spatial snapshot Fast-Flux detection (SSFD)图5 SSFD系统的工作流程
恶意软件逐渐引入Domain-Flux技术,Stalmans等人[13]将域名字符级特征融入IP-Flux检测方案,分析域名的字母数字分布频率,计算总变异距离和概率分布来检测滥用域.此外,随着IP-Flux隐匿技术的不断发展,常用检测特征被有针对性地规避,文献[14]关注到攻击者难以隐藏域名和IP的解析关联,从多样性、时间性、增长性和相关性等角度提取多个鲁棒检测特征,在真实DNS流量上检测准确率达90%.
考虑到传统检测方法的检测成本较高,Yang等人[19]在特征设计上抛弃依赖外部资源和不稳定的特征,从DNS响应中提取检测特征,训练轻量级检测模型.并加入自动更新模块,实时反馈当前流量情况,调整模型参数适应流量变化,从而提高检测精度.
② 检测算法改进.随着IP-Flux技术的发展,一些攻击者通过精心设计恶意网络通信架构,可以对一些传统检测特征进行有效规避,例如TTL值、域名字符级组成特点.此外,传统检测方案对检测特征的精确性要求很高,需要领域知识进行指导.针对上述问题,研究人员将深度学习算法应用到滥用域名检测中,神经网络模型可以自动实现隐式检测特征提取并捕获深层次的异常模式,有效识别滥用域.
文献[15]直接将域名字符、经验信息、地理和时间相关特征进行编码,输入到长短期记忆(long short-term memory, LSTM)模型中,有效检测IP-Flux域名.2020年,牛伟纳等人[20]则结合DenseNet模型和BiLSTM模型,同时捕获IP-Flux域名的空间特征和时序特征,进一步提升检测精度.此外,Almomani[21]提出一种基于自适应演化模糊神经网络(evolving fuzzy neural network, EFuNN)算法的Fast-Flux追踪系统,采用有监督和无监督的混合在线学习方案,支持实时在线检测IP-Flux域名.
深度学习方案的性能受限于训练样本集的大小,在样本量不够庞大且人工提取特征已经具有较强表征能力的情况下,深度学习方案的检测能力可能弱于传统机器学习方案.文献[22-23]对比了常见传统机器学习算法以及不同层数的深度神经网络(deep neural network, DNN),实验证明DNN检测精度并未随着隐层层数的增加而提升,且弱于传统机器学习方案的检测性能.上述工作说明对于IP-Flux检测算法的选取,需要依据检测特征、样本集规模进行灵活选择.
被动DNS分析方案解决主动探测方案中大量发送DNS请求导致的网络负担加重和易被攻击者发现的问题;此外,被动收集数据可以获取时间跨度较大的历史数据,支持长期分析.但由于数据收集的被动性,无法检测尚未使用的潜在滥用域.
2.1.2 基于Domain-Flux的检测
Domain-Flux使用域生成算法(domain generation algorithm, DGA)定期生成大量伪随机的算法生成域(algorithmically generated domains, AGD),并将多个AGD映射到单个IP地址,有效规避静态黑名单的检测.Domain-Flux策略常被滥用在分发垃圾邮件或实施网络钓鱼的僵尸网络基础架构中,用于标识受害者,或对反垃圾邮件技术进行绕过.
基于Domain-Flux的检测技术演进过程:早期滥用域名的检测主要使用传统检测方案,利用域名字符级特征,以及典型流量特征对滥用域名加以识别;现阶段的研究方案主要使用面向无特征的深度学习算法,针对检测模型的输入和结构进行改进,并关注到攻击者精心设计的AGD的针对性检测方案.
1) 传统检测方案
早期Domain-Flux域名的检测主要依赖于统计算法、传统机器学习算法,根据检测特征可划分为基于域名字符级特征和基于典型流量特征2种方案.
① 基于域名字符级特征的检测方案.考虑到AGD通常较长且无语义信息等特点,抽取DNS流量中的域名信息,构造字符级特征,实现滥用域的检测.
文献[24]计算待检测域名在N-gram空间上与良性域和滥用域的相似性,实现滥用域的检测.该方案需要收集足够数量的域名,以准确估算N-gram分布,检测成本较高且存在较大的检测延迟.此外,该方案仅能检测已知恶意软件家族的滥用域名.文献[25]则主要使用域名的长度和域名的期望值2个特征,支持未知AGD家族滥用域的挖掘.
除上述二分类AGD检测方案外,部分工作支持对AGD域按照具体DGA算法进行多分类.文献[26]提出的Phoenix系统,使用有意义的字符比率和N-gram正态分数2类特征,根据马氏距离对检测域进行分类,进一步构建DGA域-IP二部图,利用DBSCAN算法实现多分类AGD域的检测.文献[27]对Phoenix的工作进行了扩展,使用了信息熵、N-gram出现频率等域名字符级特征,并使用改进的马氏距离实现域的多分类,图6给出该检测系统的整体架构.

Fig. 6 Structure of the DGA botnet detection system图6 DGA僵尸网络检测系统的结构
基于域名字符级特征的检测方案易于被攻击者绕过:由于DGA的实现方案各有不同,AGD的字符级特征表现也不尽相同,基于Domain-Flux的滥用域通过特征变化可以逃避有针对性的检测.
② 基于典型流量特征的检测方案.部分工作通过分析DNS流中的不成功解析域名(NXDomain)响应,引入典型流量特征,检测基于Domain-Flux的恶意软件类域名.这是由于攻击者只会注册DGA算法生成的一小部分域名,用于与被感染机器通信,因此当恶意软件发起DNS查询时,会产生大量NXDomain响应,以最终定位C&C服务器.
文献[28]通过从NXDomain流中提取域名字符级特征以及关联特征,聚类待检测域名,进一步训练隐马尔可夫模型(hidden Markov models, HMM)和多分类器,识别滥用域及其所属家族.该工作采用无需特征工程的HMM模型进行检测,然而后续工作[29]证实该方案在多分类检测中表现不佳.
此外,Zhou等人[40]观察到使用Domain-Flux技术的域在子域数量、域的生存周期以及域的访问模式方面与合法域存在显著差异,进一步提出一个仅依赖于流量特征的检测系统,如图7所示.该检测方案不使用域名字符级特征,可以提高检测方法的鲁棒性,但需要更长的时间来确定可疑域列表.

Fig. 7 Structure of detection system based on traditional traffic features图7 基于典型流量特征的检测系统架构
基于典型流量特征的方案通过检测NXDomain流,可以压缩待分析数据、有效提高检测准确率;该方案的局限性在于提取流量特征会增加检测时延,此外,多数方法仍需构造字符级特征辅助检测.
2) 深度学习检测方案
随着Domain-Flux技术的不断发展,许多DGA算法通过模拟合法域的字符级组成规避检测,使得人工设计的域名字符级检测特征失效.此外,特征提取和表示工程通常十分繁琐,无法自适应检测多种DGA算法生成的滥用域名.面对这一挑战,研究学者将深度学习的方法应用到滥用域名检测中,实现无人工特征提取的检测方案.这是由于DGA域名的检测主要依托于对域名字符组成进行分析,可以作为自然语言处理(natural language process, NLP)领域的一个子问题,目前多数NLP问题都适用于深度学习的解决方案.同时互联网中存在海量的域名,庞大的数据集为深度学习模型的训练提供有力的支撑.通过深层神经网络,可以有效捕获域名字符的语言模式异常,从而有效判别DGA域名.
最早应用深度学习的检测工作是Woodbridge等人[29]利用LSTM模型检测DGA及其所属家族,将域名的每个字符作为模型输入,经过嵌入层、LSTM层和逻辑回归3层处理,得到分类结果,基于循环神经网络(recurrent neural network, RNN)的DGA检测方案大多采用类似的网络结构.该方案无需人工提取特征,对比以往的工作具有较好的检测效果.文献[30]对比随机森林、LSTM、卷积神经网络(recurrent neural network, CNN)这3种算法的检测效果,实验表明深度学习算法相对传统机器学习算法在检测准确率上有较大提升,可以更好地处理数据中的噪声.
后续的检测工作主要针对模型输入及模型结构进行相应改进,并关注到攻击者精心设计的AGD.
① 模型输入改进.仅将域名字符序列作为深度学习模型的输入,对基于字典生成的AGD检测效果不佳.例如,Suppobox家族使用基于字典的伪随机域名,通过拼接2个字典的单词创建AGD,这使得域名在字符级别与合法域的差别很小,不足以支撑检测.针对这一问题,Curtin等人[31]提出了一种名为smashword评分的机制,用于评估域名与英语单词的相似程度.进一步引入WHOIS信息辅助检测,可以有效捕获基于字典的AGD域.此外,Pereira等人[32]使用WordGraph方法获取DGA的检测词典.该方案首先对域名进行分词预处理,构建WordGraph抽取连通分量,捕获域名字符级关联信息,得到检测词典,进一步训练随机森林和CNN分类器检测AGD域.
此外,考虑到感染恶意软件的主机会查询大量NXDomain的行为特点,Tong等人[33]将NXDomain作为模型输入,提出基于CNN模型的检测系统D3N.在二分类的DGA检测中,D3N各项指标的性能相对传统机器学习方案都有明显能提升.
② 模型结构改进.受限于样本标注的成本,数据集中良性域以及各DGA家族样本的数目相差很大.考虑到原始LSTM模型均等对待所有样本和对样本类别失衡敏感的问题,文献[34]提出一种改进的成本敏感算法LSTM.MI,将成本项引入反向传播机制,给样本数多的类别赋予较低的权值,提升检测精度.
此外,考虑到现有检测特征提取思路的单一性,文献[35-36]均采用CNN和LSTM的混合结构,支持从不同维度提取域名的字符级特征:CNN提取域名的N-gram空间特征、LSTM学习N-gram的序列上下文特征.实验证明混合结构优于单一结构的检测精度,图8给出文献[35]的网络架构示意图.
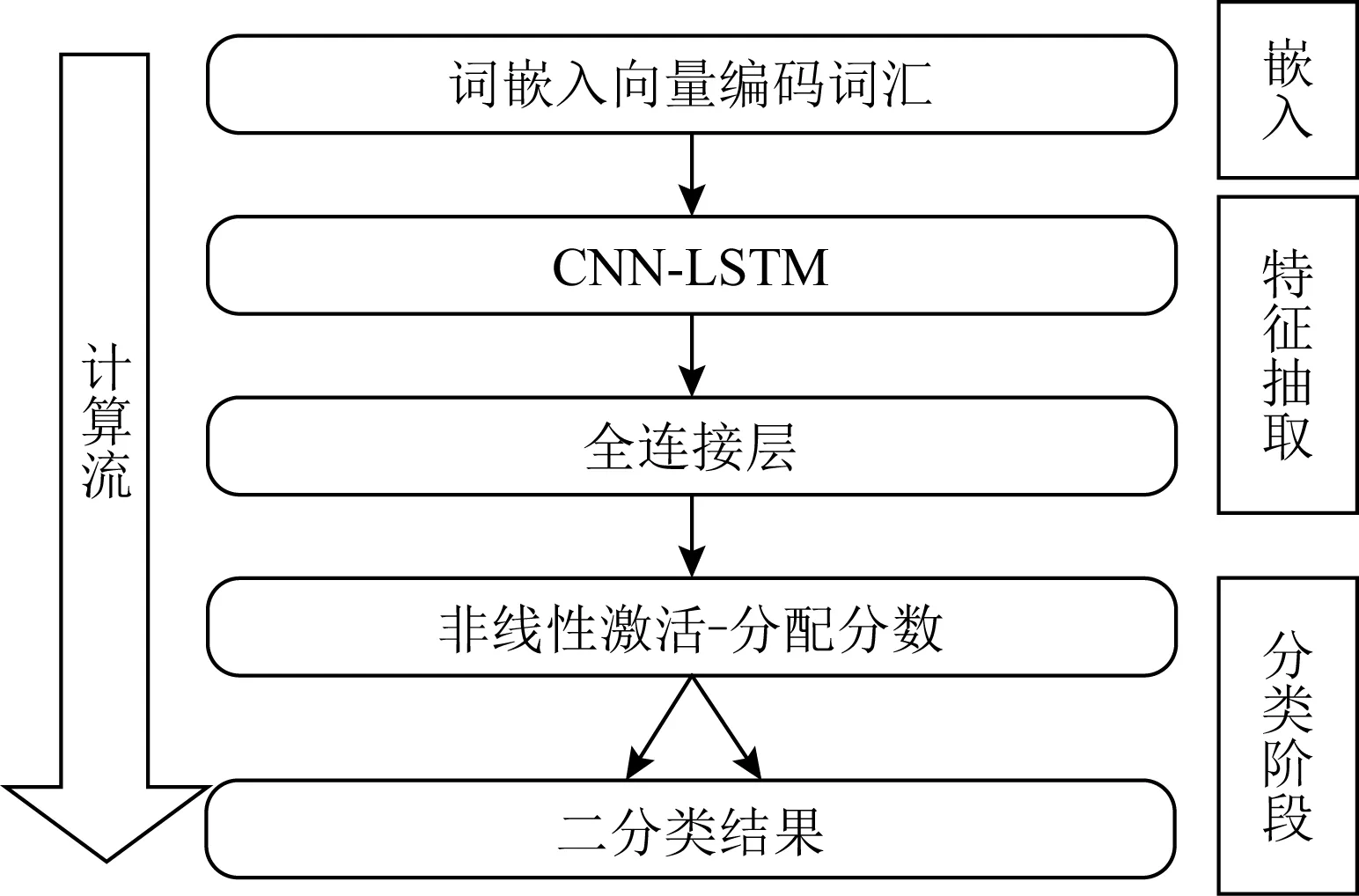
Fig. 8 CNN-LSTM based DGA detection network architecture图8 基于CNN-LSTM的DGA检测网络架构
③ 检测攻击者精心设计的AGD.在长期的攻防博弈中,攻击者通过精心设计DGA算法生成高隐蔽性、高对抗性的AGD,绕过普通检测方案,典型的有隐身域生成算法(stealthy domain generation algorithms, SDGA)和对抗DGA样本.
SDGA由Fu等人[94]提出,他们基于HMM和概率上下文无关文法(probabilistic context-free grammars, PCFG)从字典中选择字符,生成模仿良性域名字符分布的SDGA.大多数传统的基于熵的方法,或基础的LSTM,CNN等深度学习方案不能有效地检测SDGA.Yang等人[37]提出一种异构深度神经网络(heterogeneous deep neural network, HDNN)框架.HDNN采用具有多尺寸卷积核的并行CNN架构,以及基于自注意力机制的双向LSTM结构,同时支持提取多尺度局部特征和双向全局特征,挖掘待检测域名的深层语义信息,可以有效捕获SDGA.
一些攻击者采用对抗性机器学习(adversarial machine learning, AML)思想,基于生成对抗网络(generative adversarial network, GAN)算法生成对抗DGA样本.GAN框架包括生成模型和判别模型,生成模型接收随机噪声用于生成对抗样本,判别模型判别给定样本来自真实数据还是对抗样本,构成一个动态博弈过程.训练收敛时,生成模型可以生成和真实数据高度相似的对抗样本.Anderson等人[38]提出DeepDGA框架,将GAN引入DGA算法.该框架首先在Alexa Top 1M域名上预训练自动编码器(编码器+解码器),随后将编码器和解码器在GAN中竞争性重新组装,最后使用GAN生成器优化域名的伪随机生成,实验证明DeepDGA得到的对抗DGA样本可以有效绕过深度学习和传统机器学习检测方案.CharBot[95],MaskDGA[96],ShadowDGA[97]等方案也相继被提出,这些方案生成的对抗DGA样本既可以被攻击者作为绕过现有检测方案的AGD,也可以被防守方作为数据增强加入到检测模型的训练集中,提高对抗未知DGA样本的检测能力和模型的泛化能力.2021年,Ravi等人[39]提出一种对抗性防御方案,采用集成深度学习模型对NXDomain流量进行检测,可以有效捕获DeepDGA,CharBot,MaskDGA这3类对抗DGA样本,检测准确率可达99%以上.
2.2 面向网络钓鱼的域名滥用检测
美国计算机应急准备小组将网络钓鱼定义为一种社会工程形式,通过伪装成可信赖的组织或实体,使用电子邮件或伪造的网站收集敏感信息并开展恶意活动.根据反网络钓鱼工作组(Anti-Phishing Working Group, APWG)2020年第3季度报告[98],全球范围内的网络钓鱼站点数量共计199 133个,仍是网络攻击和诈骗的重要手段之一.
域名滥用与钓鱼攻击联系较为紧密,网络钓鱼者通常会注册与官方网站相似的域名,或将钓鱼页面挂载在权威域名下,增加钓鱼成功率;此外,DNS也是网络钓鱼者的攻击目标之一,例如DNS缓存投毒攻击、DNS劫持等,通过攻击DNS将用户引导至攻击者布置好的钓鱼界面.因此,从域名处着手是防范和阻止钓鱼攻击的有效方案.
网络钓鱼网站的检测按照技术手段可划分为基于黑白名单的检测技术、基于URL的检测技术、基于内容的检测技术、以及基于视觉相似性的检测技术.由于本文仅关注网络钓鱼类域名的检测方案,因此着重对涉及域名检测的黑白名单技术和URL检测技术进行介绍,诸如基于内容、视觉相似性等检测方案,而网页内容的比对不在本文的讨论范围内.表7列举了典型检测工作在面向网络钓鱼的域名滥用检测领域的贡献及其局限性.
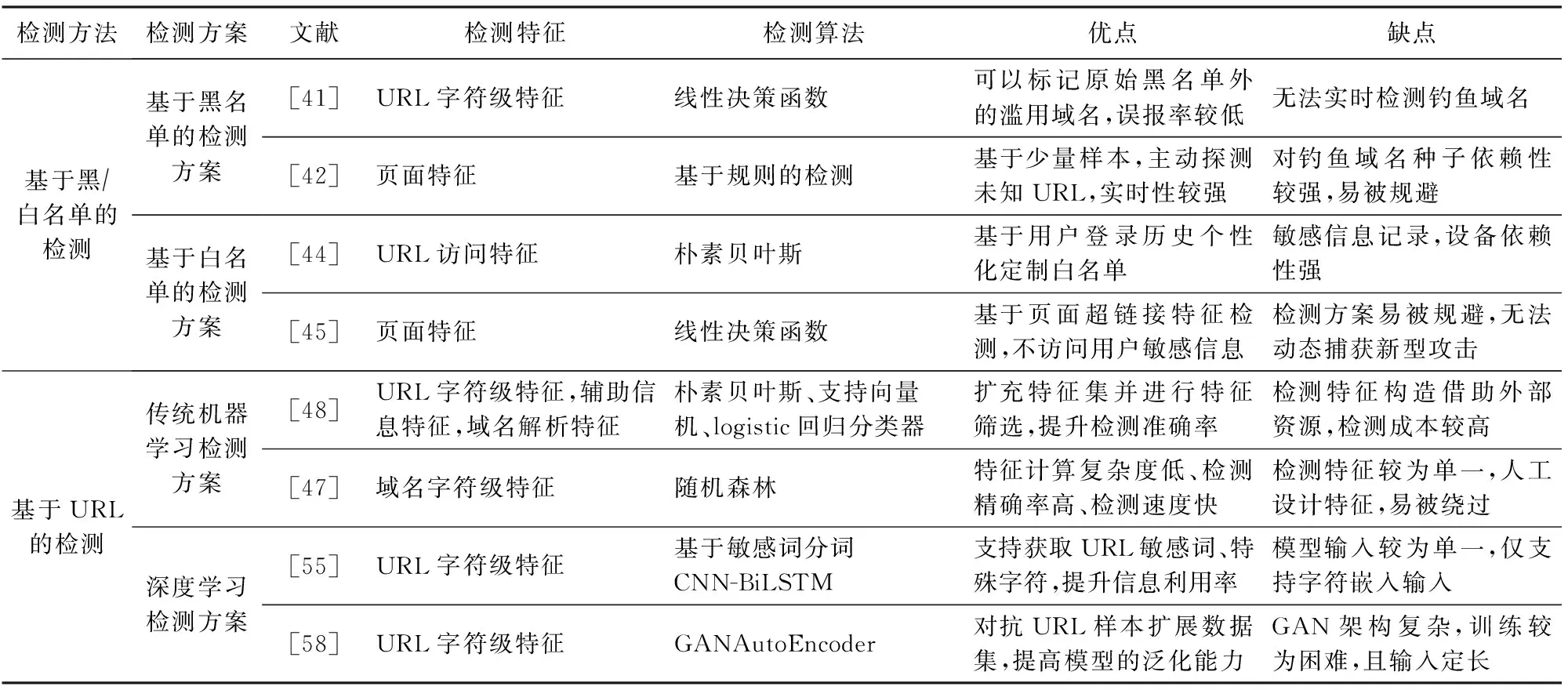
Table 7 Comparison of Typical Domain Abuse Detection Works Oriented to Phishing表7 面向网络钓鱼的典型域名滥用检测工作的比较
2.2.1 基于黑白名单的检测
黑白名单技术是钓鱼类域名检测的早期方案,同时也是部署与应用最广泛的反钓鱼技术.
1) 基于黑名单的检测方案
基于黑名单的检测方案普遍被各大安全厂商、浏览器厂商使用,根据已知的黑名单对请求的URL进行检查,如果存在条目匹配,则将该URL标注为网络钓鱼站点,进而限制访问或生成警告.黑名单一般通过手动报告、链接分析或网络爬虫等手段构建,因此不可避免地存在遗漏的情况,同时缺乏检测新钓鱼网站的能力.黑名单维护者仅在钓鱼网站变为活动状态时,才能将域名加入黑名单中,因此会存在一个攻击窗口,在这个窗口内滥用域名尚未被黑名单记录,用户可能会遭受钓鱼攻击.为了缓解黑名单的滞后检测问题,Prakash等人[41]于2010年提出了PhishNet,该方案可以基于现有黑名单预测新的恶意URL,并实现给定URL与黑名单中条目的近似匹配.尽管PhishNet无法实时检测网络钓鱼站点,但是它在大型数据集上的误报率较低,并且在标记不属于原始黑名单的新URL方面非常有效.除检测速度外,覆盖范围也是黑名单性能的重要评估指标,有助于跟踪短时间内网络钓鱼威胁的变化轨迹.2014年,Lee等人[42]提出一种主动网络钓鱼检测框架PhishTrack,包括重定向跟踪和表单跟踪2个组件,主动更新网络钓鱼黑名单,以提高黑名单覆盖率,是反网络钓鱼黑名单技术的有效补充.
除反网络钓鱼黑名单更新方案外,还有一些工作对黑名单的防护能力进行了定量的评估,旨在发掘反网络钓鱼黑名单技术的现存问题,为未来的研究方向提供指导.2020年,Bell等人[99]调查了谷歌安全浏览(Google safe browsing, GSB)、OpenPhish、PhishTank这3个网络钓鱼黑名单的钓鱼链接添加、删除、持续时间和重叠情况,并统计每个黑名单中涉及的域名总数.测量实验发现,钓鱼链接平均持续时间非常短暂,且频繁出现删除1天后重新添加的情况,表明钓鱼链接被过早删除或存在重新上线的行为,可以作为未来钓鱼黑名单构筑的一个研究点.Oest等人[100]提出一个识别复杂网络钓鱼攻击的检测框架PhishTime.PhishTime检测使用复杂规避技术钓鱼站点,并在受控环境中大量复制它们作为测试样本,报告给GSB,SmartScreen,Opera这3个黑名单,通过测量黑名单对测试样本的平均响应时间,分析黑名单的检测速度和覆盖范围.PhishTime进一步讨论黑名单对复用域名进行持续钓鱼攻击的检测能力.实验证实,现有黑名单允许网络钓鱼者重用域名进行多次攻击,可以作为优化黑名单防御能力的突破点.
2) 基于白名单的检测方案
考虑到黑名单的检测延迟导致的攻击窗口问题,部分工作使用白名单对钓鱼网站进行检测,维护受信任站点的白名单列表,对未知站点请求弹出警示.
文献[43]提出了一种基于白名单的钓鱼网站防护方案,可以阻止用户访问已知的钓鱼站点,并通过执行URL相似性检查,警示用户疑似钓鱼站点的访问.该方案是典型的基于静态、通用白名单的钓鱼检测方案,局限性在于对外部信任站点列表具有较强依赖性,外部信任站点的准确性和完整性将会极大影响该类检测方案的性能.考虑到上述方案的局限性,2008年,Cao等人[44]提出了一种动态、定制化的白名单方法,根据用户的历史登录信息创建用户个人白名单,当用户尝试提交机密信息到白名单外的网站时发出警示.相似地,Dong等人[46]提出基于用户行为的网络钓鱼检测系统,将用户访问过3遍以上的网站加入个人白名单,并存储域和用户凭证的对应关系,进一步使用线性决策函数判别钓鱼域.
考虑到上述自动化白名单构建方案存在用户敏感信息访问的问题,Azeez等人[45]提出一个基于页面超链接校验的白名单自动更新方案,当用户访问未知站点时,抽取未知站点的页面超链接,通过分析是否存在空链接、超链接总数以及外部链接个数,判断站点的性质,并将良性站点加入白名单中.
白名单方案提供严格、全面的钓鱼网站防护能力,但在获取合法网站方面有很大的局限性.此外,定制化白名单需要与数据库同步更新、集中维护.
基于黑/白名单的检测方案存在一个共性缺点,即它们都需要时间来更新列表,存在检测延迟,同时难以全面覆盖互联网中每日新增的海量链接.
2.2.2 基于URL的检测
基于黑/白名单检测方案是静态的,难以甄别海量新增域名.专家学者引入机器学习的方案,动态识别潜在钓鱼域名:从经验数据中总结规律,构建网络钓鱼域的检测模型,实现对未知样本的有效检测,典型方案是基于URL的检测方案.
基于URL的检测主要通过分析URL的结构以及词汇特征来检测网络钓鱼站点.URL用于标识因特网上资源的全球地址,由2个主要部分组成[50]:1)协议标识符,指示要使用的协议;2)资源名称,指定资源所在的域名、文件路径和查询字符串.如图9所示:
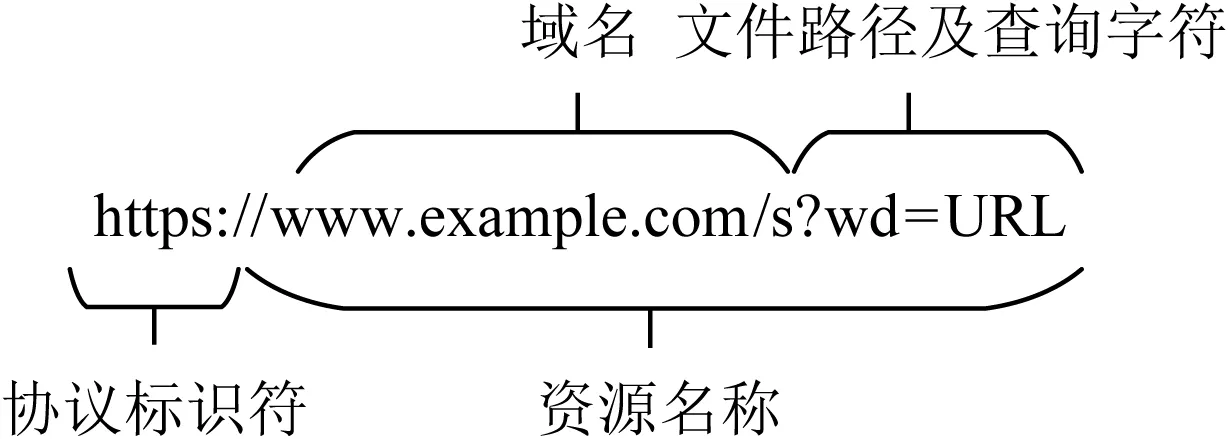
Fig. 9 Example of URL图9 URL示例
1) 传统机器学习检测方案
基于URL的传统机器学习检测方案,主要是在特征工程上进行创新,通过分析钓鱼URL的特性,人工提取鉴别钓鱼域的典型特征,提升检测精度.
早期基于URL的钓鱼域检测方案沿用黑/白名单信息作为证据特征,并加入有关域名注册和DNS解析信息等相关特征.典型工作有2007年Garera等人[50]使用URL的域名是否属于白名单,作为鉴别钓鱼域的一个显著特征.文献[48]则主要使用了URL词汇特征、域名辅助信息特征和DNS解析特征对钓鱼域进行检测.Garera等人在后续工作[49]中采用在线学习方法,支持检测模型的自动更新.
早期检测方案的检测特征抽取都需要借助外部资源信息,例如黑/白名单或域名的注册及解析信息,检测成本较高且存在检测时延.一些专家学者仿照域名字符级特征的构造方式,直接分析URL字符级组成,常见的检测特征则包括有意义字符的长度、URL中点的数量、URL的长度、URL域名中抽取品牌名、多子域、字符熵等特征.典型工作有Zouina等人[51]提出的基于支持向量机和相似度索引的轻量型URL检测系统,他们主要关注URL中的域名部分,从中提取出6种特征,检测精度可达到95.80%,证实URL的字符级特征可以有效鉴别钓鱼域.2019年,王雨琪等人[47]定义基元和敏感度描述钓鱼URL的语言特征,通过计算主级域名基元的相似性和利用随机森林算法学习子域名的语言特征,对URL进行检测,在降低误判率的同时有效减小时间开销.
为进一步提升检测精度,HTML特征、文本特征被引入到基于URL的检测方案中,在保证实时检测能力和较低检测成本的同时,提供更精准的钓鱼域鉴别能力.2019年,杨鹏等人[52]提出一种基于Logistic回归和XGBoost的钓鱼域名检测方案.除URL的字符级特征,他们从站点源码中提取24个HTML特征,并利用Logisitc回归训练基于TF-IDF的网页文本特征,极大压缩融合特征的维度,最终使用XGBoost算法对钓鱼URL进行分类.通过对比不同的特征融合方案和分类算法,证实该检测方案的优越性,在高准确率的同时兼顾检测速度.
2) 深度学习检测方案
考虑URL的构成比域名更为复杂,且文件路径和查询字符部分完全受控于攻击者,具有高度动态变化、生命周期较短和指数爆炸式增长的特点.传统机器学习方案对检测特征的依赖性较大、人工构造特征的成本较高,且容易被攻击者绕过,深度学习方案被引入到URL检测领域中.迄今为止,深度学习方案在海量数据集上表现出强大的学习能力,并在多分类问题中取得了最先进的结果.通过端到端的深度学习方案,模型可以自动抽取URL深层次的语义特征,攻击者难以有效绕过.现阶段基于URL的钓鱼域检测方案,主要是在检测算法上进行改进.
文献[53]分别在2个数据集上测试了基于Bigram特征的Logistic回归、CNN和CNN-LSTM这3种模型的检测效果,实验证明深度学习能够自动提取较好的特征表示,检测效果优于传统机器学习方案.2020年,Wei等人[54]提出一个基于CNN的钓鱼URL检测方案,将URL进行独热编码,通过嵌入层映射为低维稠密向量并输入到CNN中进行分类,检测精度高达99.68%.相较于LSTM,基于CNN的方案训练时长压缩近50%,检测模型体积小速度快,支持应用于内存和计算能力有限的移动设备.对URL直接进行独热编码处理会得到高维稀疏向量,不利于高层语义信息的获取.一些方案尝试对待检测URL进行分词处理,典型方案有2021年卜佑军等人[55]提出一种基于敏感词的URL分词方案,成分利用URL数据信息,并提出一种基于CNN-BiLSTM的检测方案,可以同时获取URL的空间特征和长距离依赖特征,捕获更全面的语义信息.此外,Ozcan等人[56]提出一种新颖的混合深度学习模型,结合基于URL词法分析的DNN模型和LSTM模型的强大功能,同时支持人工设计和字符嵌入2类特征的输入.
近年来,部分工作研究钓鱼URL的自动生成方案,用于改善现有检测方案的性能.Anand等人[57]将基于字符的LSTM作为GAN的基础结构,生成对抗URL样本,用于解决典型数据集中存在的类不平衡问题.此外,Burns等人[58]在OpenPhish,PhishTank,DNS-BH等黑名单上训练GAN,使用对抗URL样本扩展训练集,增强模型的泛化能力.实验证实数据增强模型始终比原始分类器的检测精度高.
2.3 面向域名抢注的域名滥用检测
域名抢注(cybersquatting)是域名滥用的一种常见方式,攻击者通过注册与权威域名相似的抢注域名,骗取点击流量或开展网络诈骗活动.根据Proofpoint公布的域名欺诈报告[101]显示,2018年的第1季度和第4季度之间,抢注域名的季度注册量增加11%.此外,在Proofpoint提供数字风险保护的客户中有76%的公司存在抢注域名.本节首先简介抢注域名的分类,随后梳理各类抢注域名的检测方案.
2.3.1 抢注域名的分类
抢注域名可划分为5个大类,包括误植抢注、比特抢注、同音抢注、同形抢注和组合抢注[73].表8以“www.example.com”为例,给出抢注域名的示例.

Table 8 Examples of Cybersquatting Domain Name表8 抢注域名示例
1) 误植抢注(typosquatting).该抢注指攻击者注册常见键盘误操作导致的错误域名.误植域名可以借助原域名的影响力获取大量的偶然流量,攻击者通过发布广告、网络钓鱼获取不法收益.Wang等人[102]给出较为全面的误植域名构造方式,如表8所示.当前误植抢注现象仍然较普遍,也是当前研究的热点.
2) 比特抢注(bitsquatting).如表8所示(将“m”最后1b翻转,可得到“o”),利用环境或制造缺陷导致的计算机内存随机单比特位翻转错误.在2011年,安全研究人员Dinaburg[64]在黑帽大会上介绍了比特抢注攻击,他针对8个合法域的31个比特抢注域进行为期8个月的监测,统计到12 949个唯一IP地址的共52 317次比特抢注域请求.实验结果证明比特抢注域需要引起安全人员重视.
3) 同音抢注(soundsquatting).用同音字符构造的抢注域名,依赖于发音相似的字母或字符串可能彼此混淆的假设,典型例子如表8中示意的同音词组[idle,idol].该抢注于2014年由Nikiforakis等人[66]提出,他们将同音抢注定义为字典词的同音替换,从而与误植抢注区分开来.概括来说,同音抢注不依赖于键入错误,而且并非所有域都可以被同音抢注.
4) 同形抢注(homograph).用同形字符构造的抢注域名,依赖于视觉相似的字母或字符串可能彼此混淆的假设,典型如表8中示意的小写字母‘l’和大写字母‘I’,在san-serif字体下,2个字母看起来非常相似.此外,随着国际化域名(internationalized domain names, IDN)的广泛使用,不同文字体系下的字母存在视觉一致性,例如,西里尔字母和拉丁字母中的“o”虽然是同形的,却具有不同的字符编码,比一般的近形字符更具迷惑性[67].
5) 组合抢注(combosquatting).通过向域名添加几个短语构造抢注域名(表8中示例,在“example”后追加“login”).从理论上分析,组合抢注域的构造空间是无限的,这是由于可拼接的短语是不可枚举的.此外,组合抢注域最大程度地利用了原始域名的声誉:首先,组合抢注域名不会破坏被抢注商标在字符结构层面的完整性;其次,一些企业会主动注册组合域名,以扩大其服务范围,使得良性的组合域和滥用的组合抢注域难以区分.上述2个原因使得组合抢注域较其他4种抢注域名更加难以进行判定[72].
2.3.2 抢注域名的检测方案
当前学术界对于抢注域名的检测,主要是将Alexa排名靠前的站点作为种子,根据不同类型的抢注域名构造方案,生成抢注域名的候选集合.进一步通过主动探测或被动追踪的方案,确定是否为抢注域名.表9总结典型检测工作在面向域名抢注的域名滥用检测领域的贡献及其局限性.
1) 误植抢注的检测
误植抢注的检测方案可划分为两大类:一类是基于编辑距离的主动探测方案;另一类是基于编辑距离、时间相关性以及词汇相似性的被动检测方案.
① 主动探测方案.除Wang等人[102]提出的5种误植域名构造方式,文献[60]提出了相似的方案,即基于编辑距离的3种典型构造方案:1 B替换、1 B增加和1 B删减.文献[60]的工作选取3个顶级域名(.com,.org,.biz)下的900个知名站点作为原始域名集合,进行误植域构造,最终得到300万个原始域名变体的候选集.通过主动探测确定原始集合中超过半数的域名,有35%以上的变体存在于网络中,表明现存误植抢注攻击的规模较大.
此外,文献[61]采用Wang等人[102]的构造方案,针对500个流行站点共生成大小为28 179的误植域名候选集,通过聚类算法结合人工分析的方案,对候选集中的域名进行合法和滥用性质的判别,将品牌商主动注册的域名标注为合法,将存在投放广告、实施钓鱼等滥用行为的域名标注为误植域名.实验数据显示超过79%的候选域名存在滥用行为,其中投放广告的误植域名比例最高.
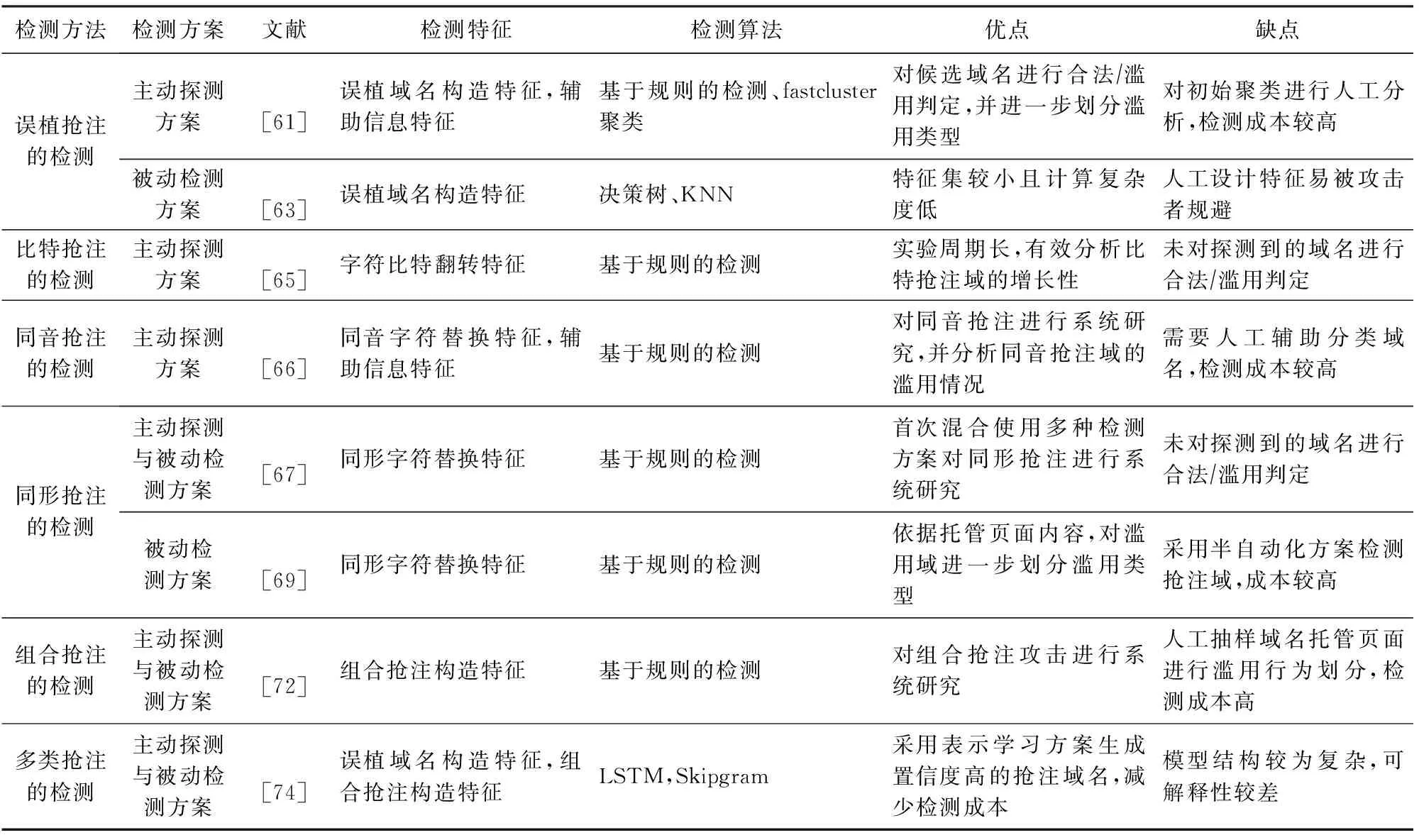
Table 9 Comparison of Typical Domain Abuse Detection Works Oriented to Cybersquatting表9 面向域名抢注的典型域名滥用检测工作的比较
② 被动检测方案.基于编辑距离的主动探测方案存在误报率较高的问题,例如nhl.com和nfl.com都是良性域,且内容都与体育相关,在基于编辑距离的主动探测中,非常有可能会被划分为彼此的误植域名.考虑到上述方案的局限性,Khan等人[59]提出基于条件概率模型的被动检测方案,使用被动收集的DNS和HTTP流量数据挖掘误植域名,主要关注用户访问某些域名后短时间内跳出,随后访问名称相似(域名的编辑距离为1)的更具知名度的域名的流量,从而精准获取符合误植抢注定义的域名,过滤掉良性的相似域名.此外,考虑到基于编辑距离的方案不能充分关联域名的上下文信息的问题,Ya等人[62]提出了TypoEval,利用暹罗神经网络来学习每个域的词嵌入,进一步使用RNN充分利用域名的上下文信息,并通过计算欧几里得空间中向量之间的距离来评估误植域,取得较好的分类效果.考虑到TypoEval模型的复杂性,Moubayed等人[63]提出一种集成的特征选择和分类模型来有效鉴别误植抢注域名.实验结果证明,该方案在保证较高检测精度的同时,特征集大小缩减了50%,且具有较低的计算复杂度.
2) 比特抢注的检测
除Dinaburg[64]的工作外,Nikiforakis等人[65]也对比特抢注域进行实验测量,具体针对Alexa排名前500的站点执行任一比特的翻转,生成比特抢注域的候选集,通过爬虫程序尝试解析候选域名集中的IP地址.在9个月的实验中,共记录了5 366个比特抢注域名,相比于实验第1天的解析记录增加了46%,表明比特抢注已经逐渐成为域名抢注者的攻击手段.
3) 同音抢注的检测
最经典的检测方案是Nikiforakis等人[66]针对Alexa排名前10 000个站点生成8 476个同音域名,通过主动探测和whois信息查询确定已注册1 823个同音域(占总域的21.5%),并对已注册同音域进行分类,整体划分为权威域和抢注域,进一步按照滥用行为细分同音抢注域.实验结果表明,用于投放广告的滥用域占现有同音抢注域的最大部分,共有954个(占已注册同音域的52.3%).
4) 同形抢注的检测
早期主要是浏览器供应商和域名注册商主导研究,重点探讨缓解同形抢注的方案.2006年Holgers等人[67]采用被动网络跟踪和主动DNS探测的方案,量化同形抢注攻击的危害程度.他们追踪科研机构的网站访问记录,在为期9天的实验中没有实际检测到同形抢注域的访问,一定程度上表明同形抢注在2006年的危害程度较低.进一步通过DNS探测发现Alexa排名前500个站点的399个同形注册域名,近60%的站点具有一个或多个同形抢注域,表明同形抢注域仍有较大的研究价值.
随着IDN的广泛使用,后续的工作主要针对同形IDN域名进行研究,Sawabe等人[68]利用光学字符识别(optical character recognition, OCR)技术进行同形IDN的检测,使用目标IDN和流行域名列表作为输入,通过将目标IDN转换为图像,应用OCR以检测该IDN与流行域名的相似程度,从而实现同形IDN域名的判定.文献[69]主要针对技术公司和金融机构的域名进行了为期8个月的追踪分析,检测到2 984个IDN同形候选域,并通过半自动化的方案对候选域进一步标注,图10给出生成候选域流程:
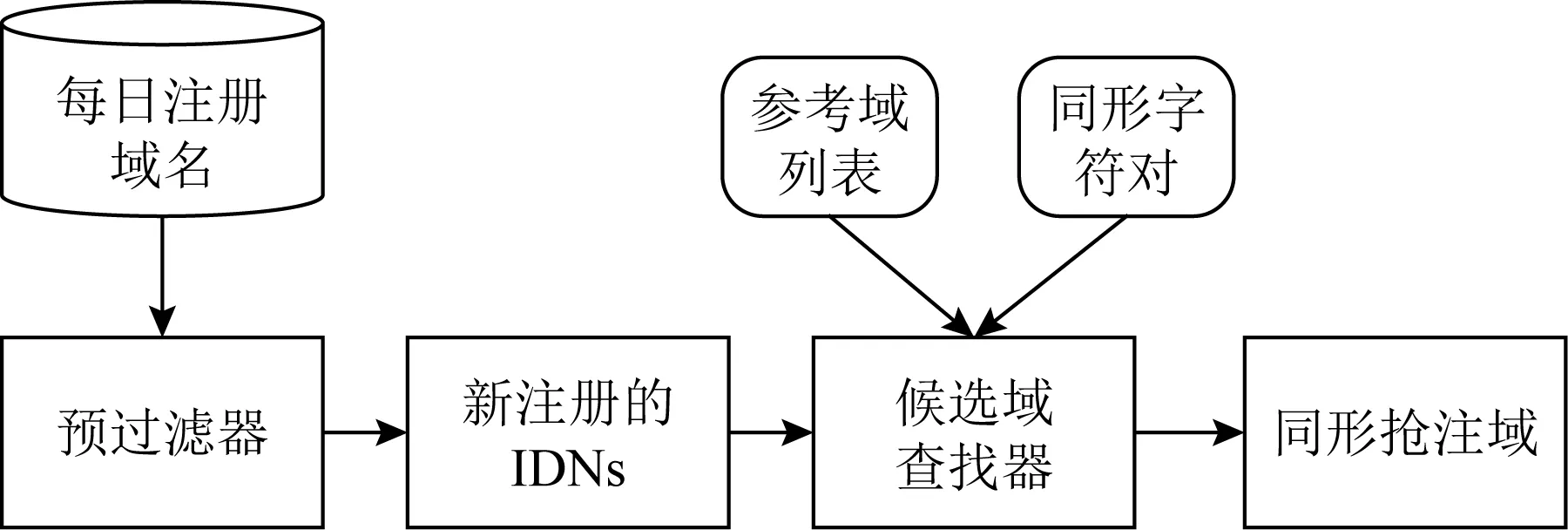
Fig. 10 Schematic diagram of the process of generating IDN homograph candidate domains图10 生成IDN同形候选域流程
考虑到基于编辑距离、OCR技术的同形抢注域名的检测方案会出现较多的误报,Yu等人[70]提出一种具有最小散列(MinHash)和局部敏感散列(locality-sensitive hashing, LSH)检索算法的双通道CNN分类器,进一步应用在实际的DNS数据中,实验证明MinHash和LSH算法在减少数据量方面表现优异.Thao等人[71]则通过融合单字符结构相似性特征以及从N-gram模型中提取的199个语言特征,并采用集成学习算法提升同形抢注域名的检测精度.
5) 组合抢注的检测
一项经典的工作是Kintis等人[72]发表的组合抢注域名的测量研究,针对组合抢注域进行系统性研究,通过分析从被动和主动DNS数据源收集的超过4 680亿条DNS记录,检测到270万个针对268个流行商标的组合抢注域,并在此基础上进一步分析组合抢注域在现实世界中的滥用情况.实验结果表明,60%的组合抢注域生命周期超过1 000天,与组合抢注域相关的恶意活动逐年增加,需要引起商标拥有者和域名注册商的广泛重视.
6) 多类抢注的检测
除了针对特定类型的抢注域名进行研究,Zeng等人[73]提出了一个全面的抢注域名研究,他们选取786个流行域名,在ISP级的DNS流量中检测5类抢注域名.实验结果显示尽管误植抢注占比较大,但组合抢注却更容易获得访问流量.2020年,Loyola等人[74]提出一种面向误植抢注和组合抢注域名的主动防御方案.首先从检测到的抢注域名样本中学习其分布规律,然后自动生成相似的抢注域名候选域,通过主动探测进一步验证候选域的真实性,发掘尚未检测到的恶意抢注域名.此外,Hu等人[75]将域名抢注的研究扩展到移动应用生态系统中,关注移动客户端市场中的抢注行为.
2.4 面向垃圾邮件的域名滥用检测
垃圾邮件泛指未经请求而发送的邮件,支撑的典型恶意行为包括:垃圾广告、网络钓鱼以及分发恶意附件等.根据Cisco的数据[103],2020年9月全球每日平均垃圾邮件数量达2 916.7亿,占全部电子邮件的84.61%.此外,Verizon的《2019年数据泄露调查报告》显示垃圾邮件是恶意软件分发的第一大媒介.
近年来,由于僵尸程序的成本低,相对容易传播且难以检测,垃圾邮件的分发逐渐迁移到僵尸网络上,将该类僵尸网络统称为垃圾邮件僵尸网络(spam botnet).通过算法对现有垃圾邮件域和处于注册阶段的新域进行检测,可以破坏spam botnet的基础结构,有效阻断垃圾邮件的传播.
本文主要关注基于DNS的垃圾邮件域检测工作,通过监测异常的僵尸网络DNS流量或计算邮件域的信誉值等方案捕获垃圾邮件域.按照是否需要利用僵尸网络的DNS活动特征对现有检测工作进行划分,得到基于spam botnet的检测和基于注册信息的检测2类方案.表10总结了典型检测工作在面向垃圾邮件的域名滥用检测领域的贡献及其局限性.
2.4.1 基于spam botnet的检测
基于spam botnet的检测方案主要通过分析网络流量以及攻击者行为等特征,实现spam botnet的僵尸主机以及C&C服务器域名的检测.该类方案的技术演进过程:早期主要使用被动DNS分析技术,实现DNS黑名单日志或监控网络等有限范围内的垃圾邮件域的检测;后期逐渐引入主动DNS查询数据,有效扩大垃圾邮件域的检测范围并缩小检测时延.
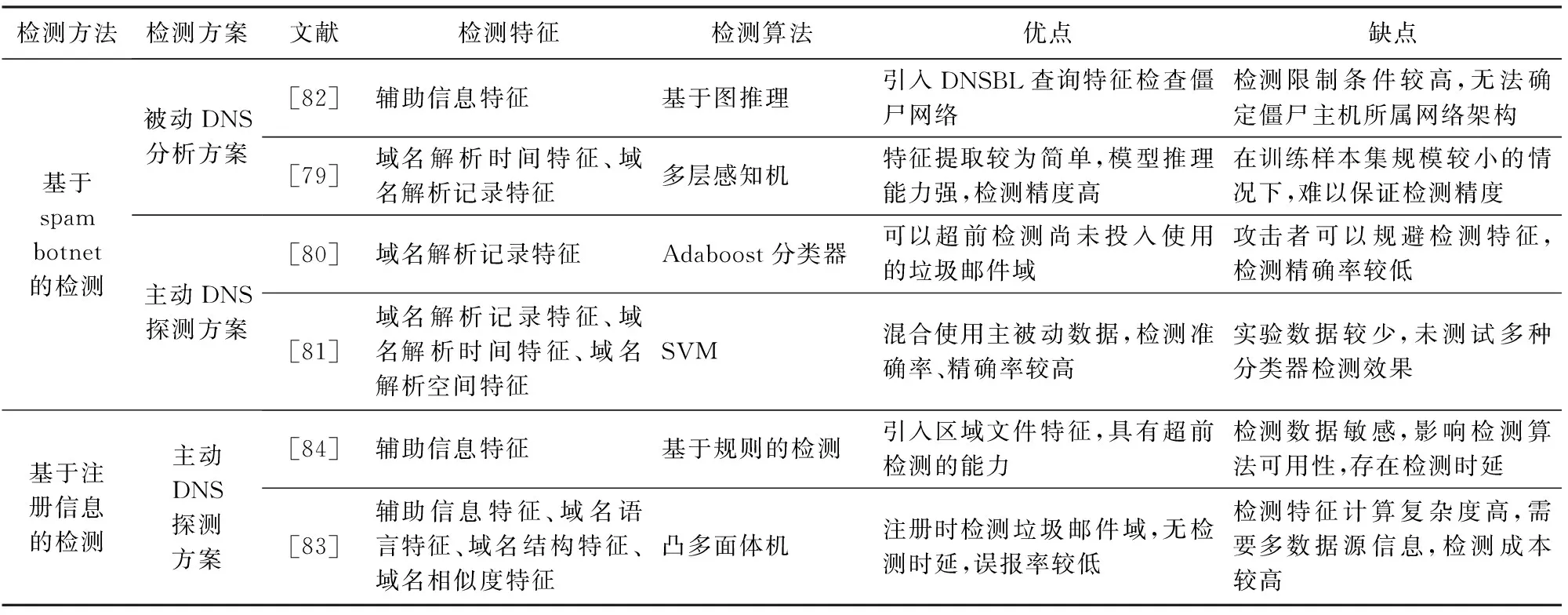
Table 10 Comparison of Typical Domain Abuse Detection Works Oriented to Spam
1) 被动DNS分析方案
早期的被动DNS分析方案主要从DNS黑名单、被动DNS数据库及其他被动侦听到的数据中,抽取攻击者行为特征或spam botnet的异常DNS特征,识别有限范围内的垃圾邮件域.
较早的一篇工作是2006年Ramachandran等人[82]通过分析DNS黑名单(DNSBL)的查询记录,挖掘僵尸网络成员的方案.攻击者通常会执行DNSBL查找以确定僵尸主机是否被列入黑名单,通过分析DNSBL的日志记录,可以确定分发垃圾邮件的域及其规模.该方案的缺点在于不能确定发现的僵尸主机是否属于同一僵尸网络,此外限制条件较高,将攻击者执行DNSBL查找作为检测前提.
考虑到上述方案的局限性,文献[76]提出一种使用网络流数据和DNS元数据来检测垃圾邮件域的方法.他们使用被动DNS数据库来分析可疑垃圾邮件主机的流记录以及可疑控制器的DNS元数据,提取多种域名解析特征.经实验证明DNS元数据分析可以大幅提升检测精度.该方案的局限性在于攻击者可通过多种方案,诸如合法化信誉和流量统计信息,或更改通信协议来规避检测特征.此外,该检测方案需要综合构造多类检测特征,检测成本较高.
Vlaszaty等人[77]提出一种简化方案,即仅通过分析DNS MX(mail exchange)请求,实现监控网络中垃圾邮件僵尸主机的识别.他们分别通过分析DNS MX的请求频率、请求周期性、请求熵以及宿主机活跃时段内MX流量4种方案捕获垃圾邮件域.实验结果证明仅通过分析DNS MX请求可以识别感染垃圾邮件恶意软件的主机.然而这项研究的数据集中,仅有一个已确认的spam botnet主机,有必要在更大的数据集上进一步评估该方案的有效性.2020年,Yoshida等人[78]关注到垃圾邮件受害者的异常DNS查询模式:一组FQDN经常被一个公共客户端查询,以及客户端出现重复查询失败的情况.他们进一步基于基数分析,提取客户端可疑查询特征,识别多个客户端对不同域的访问模式,构建决策树分类模型,实现较低的漏报率和较高的检测精度.
考虑到前述传统机器学习方案对检测特征的依赖性较强,需要人工设计精确有效的检测特征.此外,传统机器学习方案,例如贝叶斯分类器和决策树,只能进行浅层次的模型推理,难以拟合现实情况中复杂多变的spam botnet的行为特点.2020年,Sharma等人[79]引入深度学习方案,训练基于前馈多层感知机的垃圾邮件域名检测模型.他们基于电子邮件日志和权威DNS记录抽取检测特征,输入到多层感知机中训练分类器模型,最终检测准确率高达97%.
被动DNS分析方案的优点在于可以获取监控网络内部真实的DNS流量,支持监控网络内部的垃圾邮件域的挖掘;其局限性在于检测范围有限,且需要借助DNS活动特征进行检测,存在检测时延.
2) 主动DNS探测方案
spam botnet的规模一般较大,被动DNS分析的有限检测范围无法满足大型垃圾邮件域的检测需要,部分工作逐渐引入主动DNS探测方案,有针对性地发起DNS查询,实现垃圾邮件域的检测.
2018年van der Toorn等人[80]使用主动DNS测量来检测垃圾邮件域.整体检测框架如图11所示,他们从OpenINTEL平台获取全球60%以上已注册域名的资源记录,通过长尾分析提取候选域,进一步使用分类器对候选域进行二分类,将垃圾邮件域添加到实时黑名单列表(RBL)中.实验证明该检测方案具有超前检测未知垃圾邮件域的能力.该方案的缺点在于长尾分析会导致部分垃圾邮件域的漏检,同时也为攻击者规避检测制造机会.
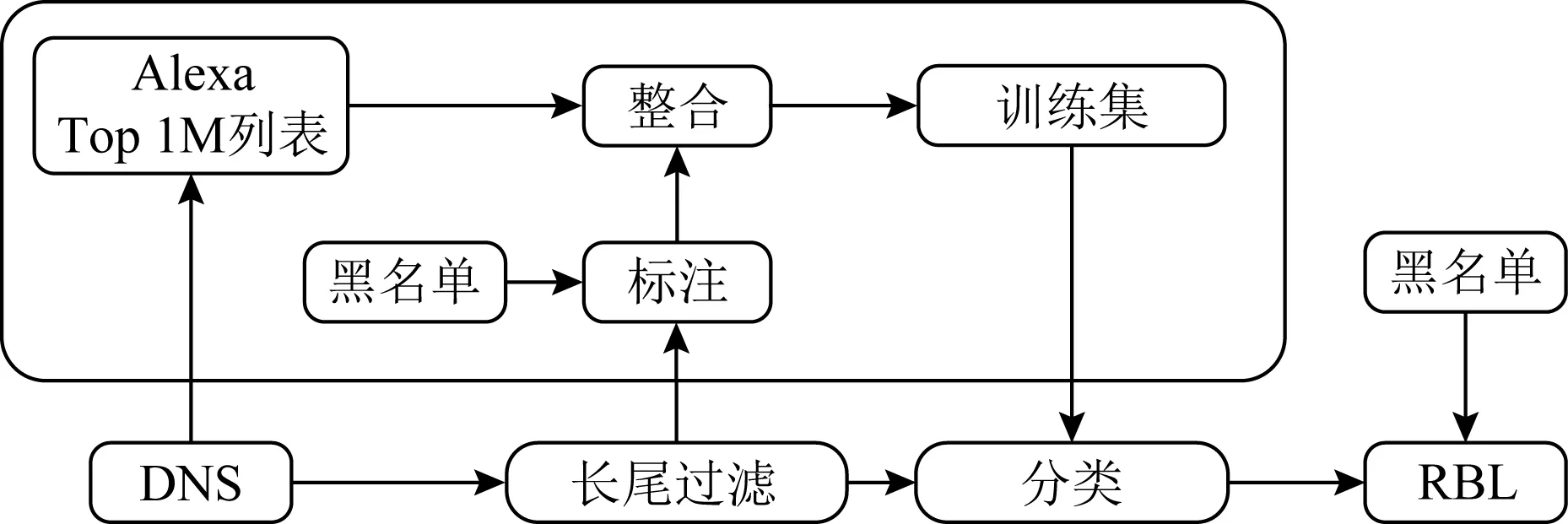
Fig. 11 Block diagram of spam domain detection图11 垃圾邮件域检测框图
Dan等人[81]考虑到仅使用主动DNS数据造成的检测精度不高的问题,提出一种混合使用主被动数据的检测方案.利用从电子邮件接收日志和主动DNS数据中提取的特征,使用SVM分类器对候选域进行二分类,实验可达到88.09%的准确率和97.11%精确率,高于van der Toorn等人[80]的方案.此外,他们对重要性排名前10的特征进行分析,发现有5个是从电子邮件接收日志中提取的特征,进一步证明混合使用主被动数据对垃圾邮件域检测具有较高的研究价值.
主动DNS探测方案的优点在于可以有针对性地获取特定域的动态解析或资源记录信息,支持大规模垃圾邮件域的检测,可以提前发现尚未进行垃圾邮件活动的滥用域;其缺点在于无法获得完整的通信流量,造成检测精确度的损失,此外,需要预先构造候选域集合进行检测,容易导致漏检.
2.4.2 基于注册信息的检测
与基于spam botnet的检测方案不同,基于注册信息的检测不使用通信流量特征,而是通过主动DNS探测的手段获取域名的whois信息或区域文件中有关域名注册的信息以及与已知滥用域的关联,构造多维判别特征,实现垃圾邮件域的检测.
Felegyhazi等人[84]使用来自注册服务商和注册管理机构的信息以及公共黑名单中的滥用域,来推断未被列入黑名单的垃圾邮件域.实验表明该检测方案可以比研究中使用的黑名单更早地标记垃圾邮件域.其局限性在于区域文件和whois数据库并不完全开放,或不支持批量访问,使得检测方案的可用性受到较大影响.此外,该检测方案需要预先观察到一些相关域的滥用行为,这意味着该方案仅能减小域名滥用的时间窗口,仍存在检测时延.
考虑到上述方案的局限性,文献[83]提出了一种名为PREDATOR的无时延的垃圾邮件域检测器,可以利用域名注册时的特征建立域名信誉,实现潜在垃圾邮件域的检测.文献[83]的作者具体关注滥用域名的异常的注册行为(例如突发注册、文本相似的名称),从域名注册信息中抽取并编码22种有助于区分垃圾邮件域名与合法域名注册行为的特征,使用凸多面体机分类待检测域.实验证明PREDATOR可以达到70%的精确率,而误报率仅为0.35%,可以有效阻止DNS域滥用.该方案的局限性在于特征计算较为复杂,需要多种信息源构造检测特征.
2.5 面向不限定滥用行为的域名滥用检测
在实际的工作中,只有极少数黑名单报告特定类型的滥用域,大部分黑名单不区分具体滥用行为;此外,大部分滥用域的基础架构相似,滥用行为也不唯一,例如僵尸网络可同时用于分发垃圾邮件或布置钓鱼站点.基于上述原因考虑,部分工作使用与滥用行为无关的方法检测滥用域名,基于域之间不同类型的关联,实现滥用域的检测,这种技术也被称为“关联有罪(guilty by association)”,按照具体的关联方案可划分为信誉评分和图推理2类检测方法.表11总结了典型检测工作在面向不限定恶意行为的域名滥用检测领域的贡献及其局限性.
2.5.1 基于信誉评分的检测
基于信誉评分的检测方案通过为参与恶意活动(例如恶意软件传播、网络钓鱼和垃圾邮件活动)的域分配低信誉分数,实现滥用域的检测.
2005年Weimer等人[104]发表了一篇基础性工作,提出使用被动DNS记录来检测多种滥用域的观点.文献[85]率先使用被动DNS数据,构建名为Notos的DNS动态信誉系统,从被动数据中提取域名字符级特征和解析特征,并通过已有威胁情报提取证据特征,采用离线训练-在线检测的模型架构、离线训练信誉评分系统、在线计算新域名的信誉得分,实现滥用域检测.文献[9]进一步提出EXPOSURE系统,该系统支持从大规模被动DNS记录中提取域名解析和字符级特征,构建J48决策树检测滥用域名.实验结果表明,EXPOSURE可以自动识别未知的滥用域,比Notos所需的训练时间和训练数据更少,具有更高的检测精度.
2.5.2 基于图推理的检测
信誉评分的可靠性严重依赖于检测特征提取的有效性,需要专家信息作为指导,同时需要不断动态调整检测特征以适应于复杂多变的域名滥用技术.考虑到上述局限性,部分专家学者从图结构中受到启发,尝试通过对域名进行关联,根据已知结点推导出未知结点的性质,被称为基于图推理的检测方案.这类检测方案主要关注域名的结构关联信息,通过主机查询域名或域名解析IP构建有效的域名关联.具体而言,基于图推理的检测倾向于从DNS流量中提取图模型,利用全局关联挖掘潜在的滥用域,按照图模型中使用的结点可划分为:主机-域二部图、域-IP二部图以及主机-域-IP异构图三大类.
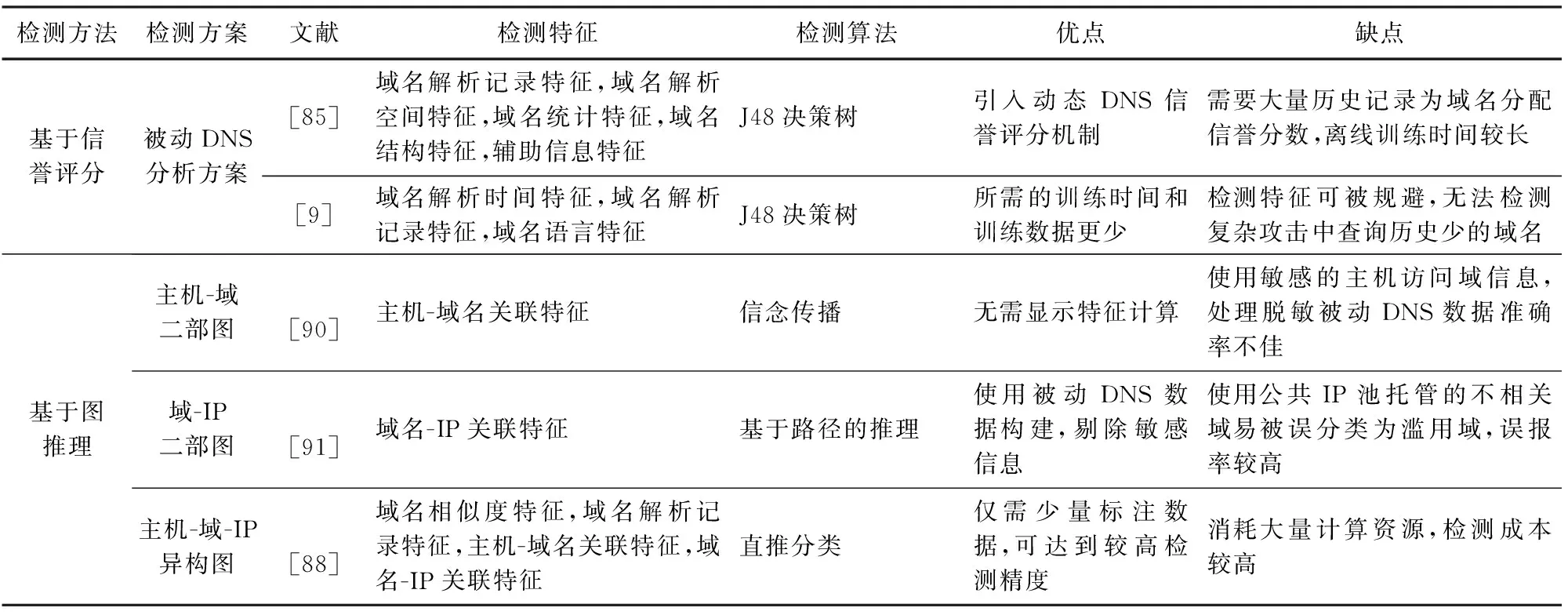
Table 11 Comparison of Typical Domain Abuse Detection Works Oriented to Unrestricted Abuse Behaviors
1) 主机-域二部图
文献[90]将滥用域名检测问题建模为图推理问题,通过分析DNS查询日志,构建主机-域的二部图(如图12所示),进一步应用信念传播评估图中未知域为滥用域的边际概率,实现滥用域的检测.该方案需要使用主机查询域的访问请求信息,涉及到用户隐私无法大规模部署.

Fig. 12 Example of host-domain graph图12 主机-域二部图示例
2) 域-IP二部图
考虑资源有限情况下,攻击者会进行资源重用,Khalil等人[91]从被动DNS数据中提取域名-IP解析关联特征,构建无向域解析二部图表示域和IP的解析关系,随后依据二部图构建一个无向加权域图,结点是二部图中的域,边的权重由域解析到同一IP地址的次数决定,并基于与已知滥用域具有强关联的域很可能是恶意的假设,在关联域上使用基于图推理技术,从而实现滥用域的检测,如图13所示:
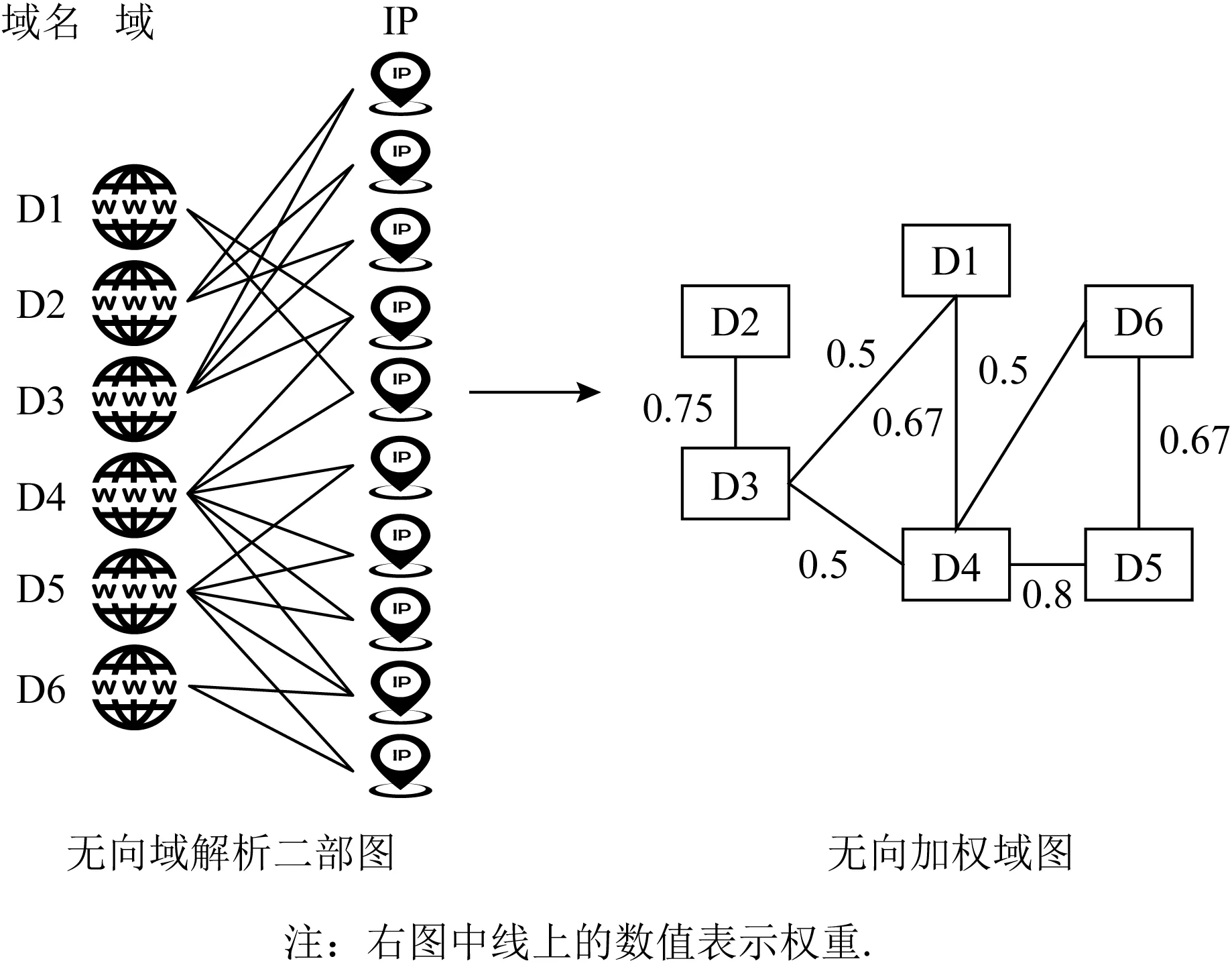
Fig. 13 Example of domain-IP graph and its corresponding domain graph图13 域-IP二部图及相应域图示例
域解析为相同的IP,即co-IP关联,是一种弱关联,没有考虑互联网中域名部署的复杂方式,尤其是公共网络托管和代理服务可能会导致毫不相关的域名被托管在同一个IP池中,导致检测精度较低.为了克服co-IP关联的弱点,2020年Nabeel等人[86]通过构建分类器区分专用托管IP和公共托管IP,并提出一种基于IP的域名强关联方案:①共享一个专用IP;②共享来自不同托管服务提供商的多个公共IP.实验证明,该检测方案可以有效提升检测精度.
此外,Liang等人[87]考虑到现有域图构建方案无法处理孤立域名结点,提出一种结合单个域名特征(域名字符级特征、域名解析记录特征)和域名-IP关联特征的检测方案MalPortrait.MalPortrait相较于普通方案增加全局关联信息,弥补数据缺乏导致域名信息量不足的缺点,且对被动数据时间跨度的依赖性较小.对比其他基于域图的方案,MalPortrait可以有效解决孤立域名结点难以分类的问题.
3) 主机-域-IP异构图
Sun等人[88]于2019年提出的HinDom系统,将DNS场景建模为一个异构信息网络(HIN),该网络由主机、域、IP地址及它们之间的6种关系组成,HinDom采用基于元路径的直推分类,能够仅使用一小部分标记样本来检测滥用域,图14给出异构图的示例(图14(a))以及图模式说明(图14(b)).将HinDom系统与朴素贝叶斯、支持向量机和随机森林3种归纳分类方法进行比较,实验证明直推分类在初始标签信息的比例降低时,仍能保持较为稳定的检测精度,较归纳分类方案性能优异.

Fig. 14 Example of host-domain-IP HIN and graph pattern[88]图14 主机-域-IP异构图示例及图模式[88]
考虑到HinDom系统仅使用全局关联信息,而忽略对单个域名结点的属性特征提取的问题,Liu等人[89]提出一种基于动态图卷积网络(dynamic graph convolutional network, DGCN)的检测方案Ringer. Ringer充分利用主机-域名的查询关联和域名-IP的解析关联构建域图,并采用DGCN方案在域图上学习集成结点特征和图结构信息的结点表示,送入全连接神经网络中进行域名分类.实验证实,在服务提供商的真实DNS数据上,Ringer在检测精度和检测速度上都有优异的表现.
3 讨论与展望
近年来涌现出大量工作旨在阻止或消除域名滥用行为,对改善DNS系统的生态环境做出了明显的贡献,但当前的检测能力与互联网上的域名滥用情况之间仍存在差距.本节将进一步讨论多检测场景下域名滥用行为检测研究面临的挑战与未来的研究方向:
1) 研究高动态、强对抗场景下的检测技术,应对滥用技术的演进
攻击者为提高滥用域名的可用性和对黑名单的抵抗能力,各检测场景下的域名滥用技术均呈现出高度动态发展的趋势,旨在规避现有检测技术.攻防博弈日趋激烈,呈现出强对抗的形态.当前各场景下的域名滥用检测难点主要包括:面向恶意软件的域名滥用检测场景下,攻击者提出基于字典词构造低随机性、高可读性域名的方案,并引入对抗样本生成技术规避检测[31-32,38-39,95-97];在面向网络钓鱼的域名滥用检测场景下,攻击者尝试多种高对抗性的URL混淆技术规避检测[57-58],或通过Blackhat SEO技术提高钓鱼链接在搜索引擎结果中的页面排名[10];在面向域名抢注的域名滥用检测场景下,攻击者针对国际化域名进行同形抢注攻击,浏览器防御规则或一些OCR技术无法抵御这类抢注攻击[68-70];在面向垃圾邮件的域名滥用检测场景下,攻击者使用不同的注册模式,并通过匿名注册服务提供商模糊其注册信息,这类混淆方案会对基于注册信息的检测造成较大影响[83-84];在面向不限定滥用行为的域名滥用检测场景下,对于在大量通信流量中潜伏期较长、少通信关联的滥用域尚缺乏检测能力[86-88,91].此外,考虑到未来DNS通信技术的发展,恶意攻击者的攻击目标和手法不断变化,对传统检测和防护方案提出新挑战,域名滥用行为检测需要引入新的技术方案.
2) 研究跨检测场景的域名滥用检测技术,应对检测场景的融合
随着网络恶意攻击的日趋体系化,域名作为重要的支撑资源,通常会贯穿整个恶意活动的始终,呈现出域名滥用行为检测场景融合的趋势.在载荷投递、安装植入和命令与控制阶段,都可以通过多类域名滥用达成实施攻击或建立通信的恶意目标.例如,一个鱼叉式钓鱼攻击活动,可能涉及垃圾邮件域、网络钓鱼域、恶意资源下载域,以及恶意软件C&C通信域的协同.面对跨检测场景的域名滥用行为,如何有效针对多种滥用行为建立相对统一的检测模型,或根据一些捕获的滥用域,迅速定位其他潜在域名滥用行为,提出行之有效的复合性检测方案,是学术界和工业界亟待解决的问题.
3) 研究新基建场景的域名滥用检测技术,应对滥用模式的迁移
随着国家对于新基建的日益重视,域名DNS作为一类基础设施已经部署到各种新基建场景中,同时也面临恶意软件、钓鱼站点、域名抢注、垃圾邮件等各类域名滥用行为的威胁.域名滥用行为检测场景应全方位覆盖移动端、物联网终端、云平台等基础设施.同时,研究人员需要针对新基建下的滥用行为特点、不同网络环境中的DNS通信流量特征、计算资源分配情况进行针对性地调整现有域名检测技术.目前已有检测方案通过捕获DNS流量异常检测基于物联网的僵尸网络[105]、移动终端的恶意软件[106];此外,还有一些解决方案关注软件定义网络(software defined network, SDN)架构下基于DNS的拒绝服务攻击防御、检测和缓解技术[107-108].
4 总 结
随着互联网上恶意活动的兴起,网络攻击者将DNS系统纳入其攻击活动的支撑资源,域名滥用行为已经得到学术界和工业界的广泛关注.本文对域名系统的工作方式及其扩展技术进行概述,并从具体行为出发构建本文的域名滥用检测场景分类体系,梳理恶意软件、网络钓鱼、抢注域名、垃圾邮件以及不限定滥用行为5种典型场景下的域名滥用检测工作,重点阐述了各类域名滥用检测方案的演进过程,为域名滥用行为检测提供了一个以检测场景为导向的总结性工作.
作者贡献声明:樊昭杉调研整理文献,统计分析数据,设计论文框架,撰写和修订文章;王青调研文献,修订、审查及讨论文章;刘俊荣对文章的知识性内容进行审阅;崔泽林调研文献,核对校稿;刘玉岭对文章的知识性内容进行审阅,提出指导意见;刘松对文章的知识性内容进行审阅.所有作者都审阅并批准了最终稿件.
猜你喜欢
英语文摘(2021年10期)2021-11-22
汉字汉语研究(2020年2期)2020-08-13
计算机与网络(2020年4期)2020-04-20
江苏教育研究(2020年2期)2020-04-10
江苏教育研究(2020年1期)2020-04-10
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
计算机世界(2009年35期)2009-11-17
IT时代周刊(2008年8期)2008-04-28
