
基于组件特征与多注意力融合的车辆重识别方法
2022-11-11 10:49陈小波梁书荣
计算机研究与发展 2022年11期
胡 煜 陈小波,2 梁 军 陈 玲 梁书荣
1(江苏大学汽车工程研究院 江苏镇江 212013) 2(山东工商学院计算机科学与技术学院 山东烟台 264005)
近年来,随着机动车保有量的持续增加,使用计算机技术辅助人工进行交通管理的需要已十分紧迫,作为一种能够对城市内车辆进行定位、跟踪、监管的重要手段,车辆重识别受到学术界的广泛关注.车辆重识别即给定目标车辆在特定区域内的一张图像,找出目标车辆被其他摄像头拍摄的图像.车辆重识别是一种特殊的图像检索问题,只能使用车辆的外观信息和辅助信息(如车辆编号、拍摄时间和地点等信息),检索图像的视角、拍摄时间和天气等因素都可以和给定的图像不一致[1].由于不同摄像头的位置、视角、光照、分辨率等因素,同一辆车的不同图像可能看上去存在较大差异,而不同的车辆可能由于相同的视角和车辆型号产生相似的图像,这些都对车辆重识别问题造成了挑战.
为了解决不同图像中车辆视角不同的问题,一种直接的方法是在不同的车辆图像中抽取与视角无关的特征,再利用这些特征度量车辆图像的相似度.随着深度神经网络,尤其是卷积神经网络的快速发展,一些基于人工设计和提取的视角无关特征[2-5],如颜色、车型、尺寸等的方法已逐渐被基于深度学习的方法所取代.目前,基于深度学习的车辆重识别方法主要分为基于多特征融合的方法和基于度量学习的方法.
在多特征融合方法中,Liu等人[6]将深度学习得到的特征与车辆的颜色信息等多种特征进行加权求和,得到车辆图像之间的相似性得分,再以此为依据进行车辆重识别排序;He等人[7]将车辆的一些组件作为约束引入了车辆的重识别过程,增强了深度神经网络对相似车型之间细微差异的辨别能力;Wang等人[8]利用堆叠式沙漏网络(stacked hourglass network)对车身表面具有辨识性的20个特征点进行预测,并根据这些关键点所属的面对这些关键点的特征进行累加,得到用于相似性判断的特征向量.总的来说,基于特征融合的方法通过合理地选取车辆的关键点或关键部位与损失函数,使网络更加关注车辆的辨识性特征,具有较高的准确率.但这些方法选取的车辆部件很多仍需人工指定,不具有较好的鲁棒性.
在度量学习方法中,Liu等人[9]提出了深度相关性距离学习,在进行车辆重识别任务的同时对车辆型号进行判别;Guo等人[10]进一步提出一种由粗到精的特征嵌入方法,使网络能够学习到敏感的辨识性特征;Zhang等人[11]提取了车辆图像的关键部位,将其输入到注意力模块中,提高神经网络寻找具有辨识性部分的能力,降低非辨识性区域对重识别的负面影响;Zhou等人[12]设计了一个根据单视角特征生成车辆各种视角特征向量的网络,从而实现对不同视角的车辆图像进行相同视角的特征向量的对比;Chu等人[13]将图像对中2张图像视角之间的关系分为相似视角或不同视角,并分别在不同的特征空间中对这2种关系进行优化.Meng等人[14]提出一种基于语义分割的方法,将车辆图像划分为不同组件并对各组件的特征进行对齐(align)以消除视角变化的影响.这些基于度量学习的方法大多较为简单,具有训练时间短且解释性较强的优点.
针对车辆重识别中存在的一些问题,本文提出一种基于组件特征与多注意力融合的车辆重识别方法(parsing-based vehicle part multi-attention adaptive fusion network, PPAAF).首先,利用语义分割网络,将车辆图像分割为背景区域和1个或多个车辆组件,包括车辆的正面、背面、顶面和侧面,并利用修改后的深度残差网络分别从不同的车辆组件中提取不同的特征,比较不同车辆相同组件的特征以消除车辆图像视角变化对外观的影响.然后,提出一种基于多注意力的特征融合机制,同时考虑不同组件在图像中所占的面积及组件特征包含的鉴别信息,实现组件特征的自适应融合.最后,在多任务学习框架下,优化车辆重识别与多个辅助任务的联合损失函数,对网络参数进行优化,进一步提升网络性能.
1 网络框架
本文提出的车辆重识别网络由车辆组件语义分割模块、骨干网络、特征提取模块组成,网络结构如图1所示:

Fig. 1 Architecture of the proposed network图1 网络结构图

2 骨干网络与特征抽取模块
首先对深度残差网络进行修改作为本文方法的骨干网络.深度残差网络是计算机视觉中用于图像分类的经典网络之一,对于给定的输入图像,网络输出该图像所属的类别.由于图像中物体的分类任务对车辆重识别并无明显帮助,移除了深度残差网络最末端的图像分类器,即残差网络中最末端的全局平均池化层与全连接层,而将其应用于提取图像的特征.同时,为了提高输出特征图的分辨率,本文移除了深度残差网络顶端的步长为2的3×3最大池化层,这使得骨干网络最终输出的特征图宽和高均为原始残差网络输出特征图的2倍,从而包含更丰富的信息.
通常情况下,可将车辆分为5个面,分别是正面、背面、顶面、左侧面及右侧面.考虑到车辆的对称性及车辆的左右2个侧面往往不能在一张车辆图像中同时出现,因此将车辆定义为4个组件:正面、背面、顶面和侧面.利用Meng等人[14]提供的车辆组件语义分割模块,对车辆图像P进行语义分割,输出车辆的语义分割图M,其尺寸与车辆图像一致.具体而言,对一张高为H、宽为W的车辆图像P上的一点Phw(1≤h≤H,1≤w≤W)有B(Phw)∈{0,1,2,3,4},其中,B(Phw)表示Phw所属的类别,0表示该点为图像背景(不属于车辆),1,2,3,4分别表示该点属于车辆的正面、背面、顶面或侧面.本文所提出方法中,车辆组件的划分实例如图2所示:

Fig. 2 Examples of vehicle parts partition图2 车辆组件划分示例
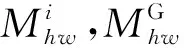

(1)

(2)
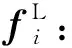

(3)
(4)

3 组件注意力模块
3.1 面积注意力
在一张车辆图像中,构成车辆的4个组件在图像中所占的面积一般是各不相同的.通常来说,某个组件的面积越大,该组件更可能包含更多鉴别信息,从而在车辆重识别时应该更受关注.因此,首先定义车辆组件i的面积注意力Hi:
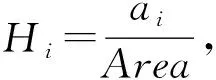
(5)
其中ai为图像中车辆组件i∈{1,2,3,4}所占的面积,Area为图像中车辆整体所占的面积,这里以组件所包含的像素个数作为面积度量,即
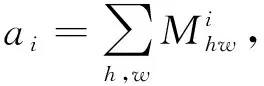
(6)
(7)
3.2 特征注意力
虽然车辆各个组件所占面积的大小在一定程度上能反映该组件在重识别任务中的重要程度,但组件对重识别任务的重要性并不能完全依赖于其在图像中所占的面积大小.例如,大部分车辆的车顶缺少图案和装饰,除颜色外几乎相同;而大部分车辆的正面,尤其是前挡风玻璃处,则因为车主的个人喜好等因素,会有较为明显的差异.对从俯视角度获取的车辆图像,车顶与车辆正面所占面积大小可能几乎相同,而车辆正面更可能包含丰富的鉴别特征.因此,为反映车辆各组件的特征向量对其在车辆重识别任务中的重要程度,本文引入一个可学习的车辆组件注意力编码向量E∈C(C为组件特征的通道数)对各组件的特征向量进行编码.组件i的特征注意力Ui可以表示为
(8)
其中
(9)
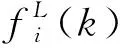
注意力编码向量的初始化为EO=(1/C,…,1/C),不包含特定的语义信息,但经过学习后,该编码向量呈现出相当丰富的语义信息.图3为一个通过网络优化后的编码向量的可视化示例,图4为该编码向量各通道的数值分布.
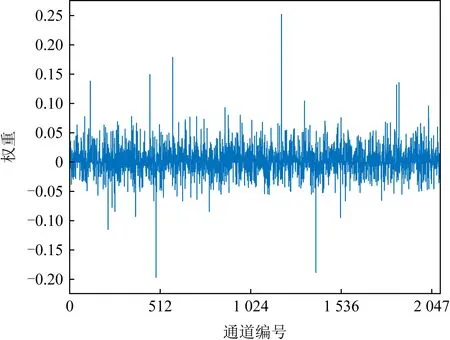
Fig. 3 Weights of attention embedding vector图3 注意力编码向量的权重
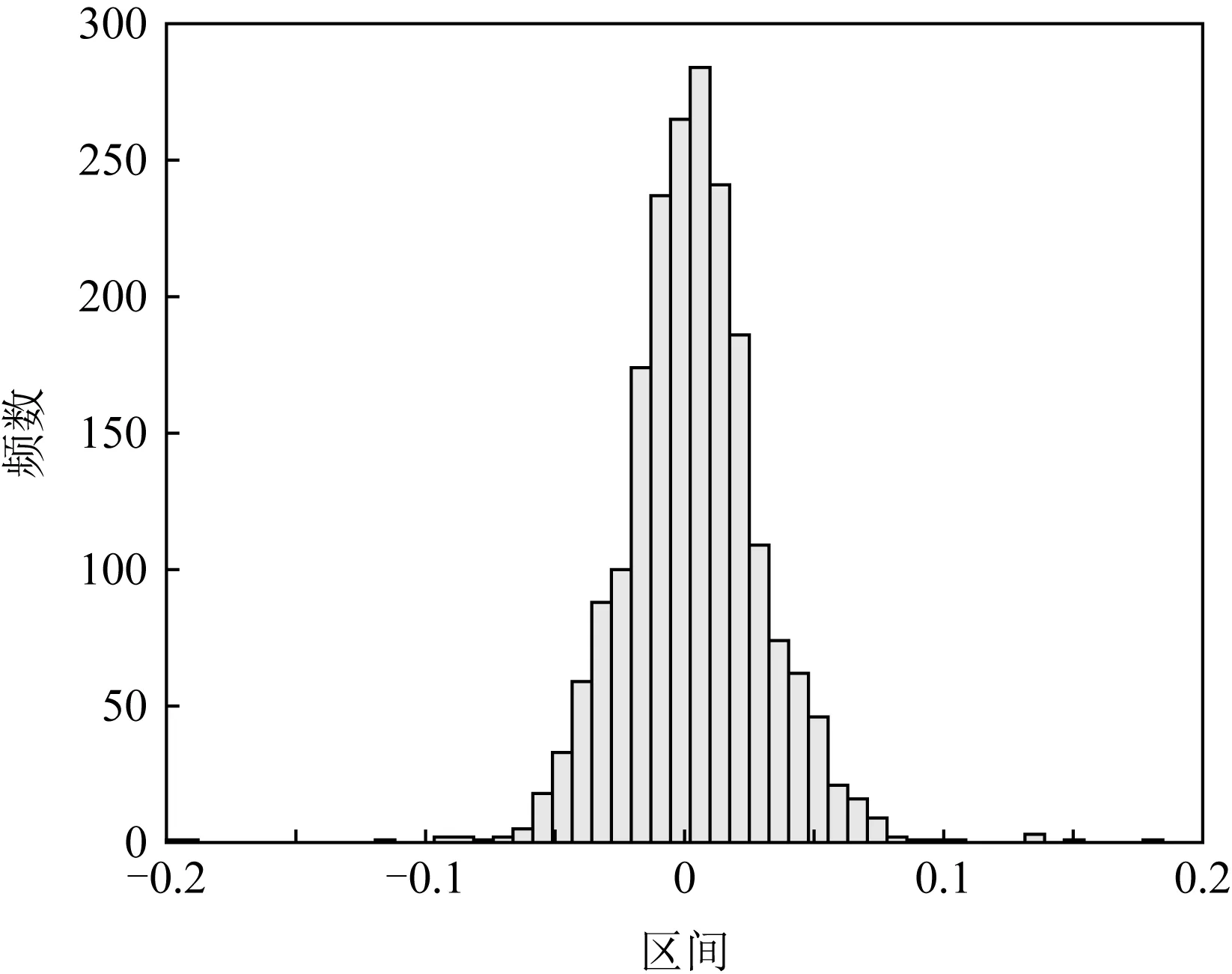
Fig. 4 Distribution of weights in attention embedding vector图4 注意力编码向量的权重分布
3.3 多注意力融合
最终的车辆组件注意力为面积注意力H和特征注意力U的加权之和:
A=λHH+λUU.
(10)
为了更好地确定2种注意力各自的权重,本文引入了一种门控机制Q,使2种注意力在融合时的权重λH与λU由网络学习得到:
λH,λU=Q(LH(H)+bH,LU(U)+bU),
(11)
其中,LH与LU均为全连接层,bH与bU为可学习的偏差,Q为softmax函数.
4 网络训练
针对车辆重识别问题,本文应用三元组损失函数对网络进行优化;同时,为提高重识别性能,还分别设计了使用车辆整体特征与组件特征的分类任务,用于辅助车辆重识别网络的训练.实验结果表明采用分类任务确实有助于提升网络的性能.
4.1 损失函数
针对车辆重识别问题,本文采用三元组损失函数[16].首先,对于车辆整体特征fG,应用三元组损失函数,即

(12)
其中,Dap=dis(fG,a,fG,p)表示车辆图像a与相应的正样本p的整体特征fG,a与fG,p之间的欧氏距离;Dan=dis(fG,a,fG,n)表示车辆图像a与相应的负样本n的整体特征fG,a与fG,n之间的欧氏距离;α表示正负样本间的最小距离.

(13)
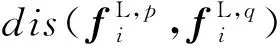
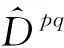
(14)

(15)
在此基础上应用三元组损失,即

(16)
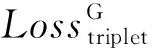
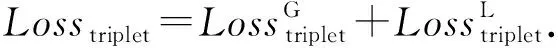
(17)
针对辅助网络训练的分类问题,分为基于车辆整体特征的分类与基于车辆组件特征的分类.对于车辆各组件特征的分类,首先由组件注意力模块得到车辆各组件的权重A∈N,N=4,对车辆各组件特征进行加权求和,得到
(18)
将加权后得到的特征fL与车辆整体特征fG分别输入全连接分类器,激活函数采用softmax,预测车辆图像所属的类别,然后对车辆整体特征fG的预测应用交叉熵损失LossCE,对特征fL的预测应用focal损失[17]Lossfocal,其调节因子α=0.25,γ=2.
最终用于训练网络的损失函数为以上各部分之和,即
Loss=LossCE+Lossfocal+Losstriplet.
(19)
4.2 网络训练与推理
本文方法基于Pytorch[18]实现,对在ImageNet上进行预训练的ResNet-50[15]进行修改作为车辆重识别的骨干网络,利用Adam[19]优化器对网络进行优化,批大小(batch size)为72,设置权重衰减(weight decay)为4×10-5,网络的最大学习率为4×10-4,并且进行学习率预热(warm-up)[15],在初始的10个训练轮次中学习率从4×10-5逐渐线性增大至最大.网络共训练120轮,且在第40,70轮连续对学习率乘以0.1.对输入的图像,首先在图像边缘增加10个像素的空白,同时还对训练图片使用随机擦除(random erasing)[20]、水平翻转(horizonal flipping)[21]等数据增强手段以丰富训练数据.
在推理阶段,本文所设计的网络对所有输入的图像提取全局特征向量与各组件特征向量,分别根据车辆的全局特征向量与各组件特征向量计算出车辆图像间的全局特征距离DG和组件特征距离DL,最终进行车辆重识别计算的图像间距离D=DG+λDL,其中λ为平衡参数,λ=1.
5 实验与分析
5.1 实验环境
本文所有代码均基于Pytorch1.7.1,CUDA10.2,Python3.7,实验平台的硬件配置为i7-6950x+3×GTX1080ti,内存为64 GB,操作系统为Ubuntu 18.04 LTS.在该平台上,训练本文所提出的网络(120轮)需要大约13 h进行推理时,每批样本耗时约618 ms,平均每样本耗时85.8 ms.
5.2 数据集与评价指标
为评估所提出网络的性能,在Veri-776[22]数据集与VehicleID[9]数据集上进行实验.Veri-776数据集包括了由20个监控摄像头拍摄到的776辆车的图像,共计50 000张,并被划分为包含来自576辆车的37 778张图像作为训练集和来自200辆车的11 579张图像作为测试集.在Veri-776数据集中,保证检索图像与正确的被检索图像必须是由不同摄像头拍摄的,在进行重识别性能评价时,计算全类平均正确率(mean average precision,mAP)与累积匹配曲线(cumulative matching characteristics,CMC).VehicleID数据集使用来自13 134辆车的110 178张图像与来自13 113辆车的111 585张图像分别作为训练集与测试集.对于每辆不同的车,随机选择其中的1张图像作为检索图像,其余作为被检索图像,且重复测试10次,取这10次测试中的平均性能指标作为最终的性能评价指标,在测试重识别性能时仅计算CMC.下文及表中CMC@k表示CMC曲线在第k位的值.
5.3 实验结果
为验证本文提出的PPAAF网络的有效性,与近年来的部分优秀重识别算法进行了性能比较.比较的方法包括:1)OIFE[8].该方法提取了车辆的20种关键点的特征并随后将特征对齐进行比较,该方法还利用了时空信息.2)VAMI[12].该方法通过视角感知的注意力模型,获取多个视角的注意力映射,并利用生成对抗机制,通过单视角的特征和注意力映射生成多视角特征.3)EALN[23].该方法通过在指定的嵌入空间内生成难样本而不是从训练集中选择难样本来提高重识别任务的性能.4)AAVER[24].该方法利用一个2分支网络分别捕捉车辆的整体特征与车辆各关键点的局部特征,并结合车辆的朝向特征来进行重识别任务.5)RAM[25].该方法在抽取了车辆全局特征的基础上,将车辆图像水平均分为3部分,并分别在这3部分中抽取车辆的局部特征用于重识别任务.6)VANet[13].该方法针对方向相同的车辆图像对与方向不同的车辆图像对,将视角关系不同的图像对分别在不同的特征空间中进行度量学习.7)DFLNet[26].该方法利用生成对抗网络的思想,分别抽取出与视角有关和与视角无关的图像特征,并根据图像对的视角关系选取对应的特征进行比较.8)PRN[7].该方法主要利用车辆的车窗、车灯与车牌的特征对车辆进行区分.9)PVEN[14].该方法将车辆划分为正面、背面、顶面和侧面4部分,结合车辆的整体特征与4部分的特征进行重识别计算.在VehicleID数据集与Veri-776数据集的比较结果分别如表1、表2所示:
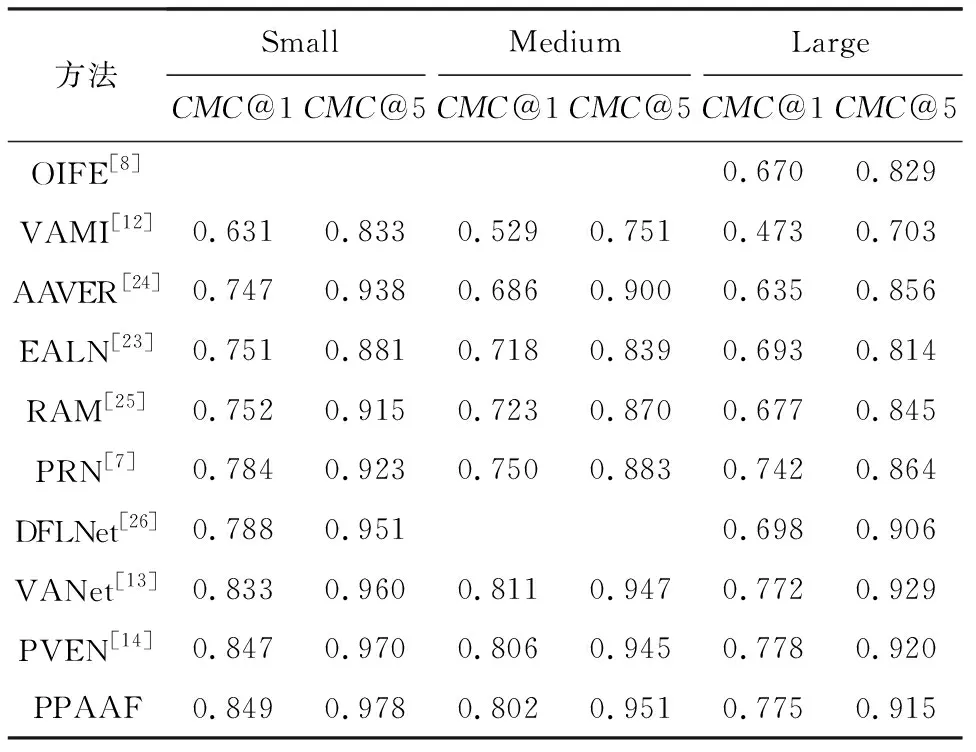
Table 1 Performance Comparison of Different Methods on VehicleID Dataset
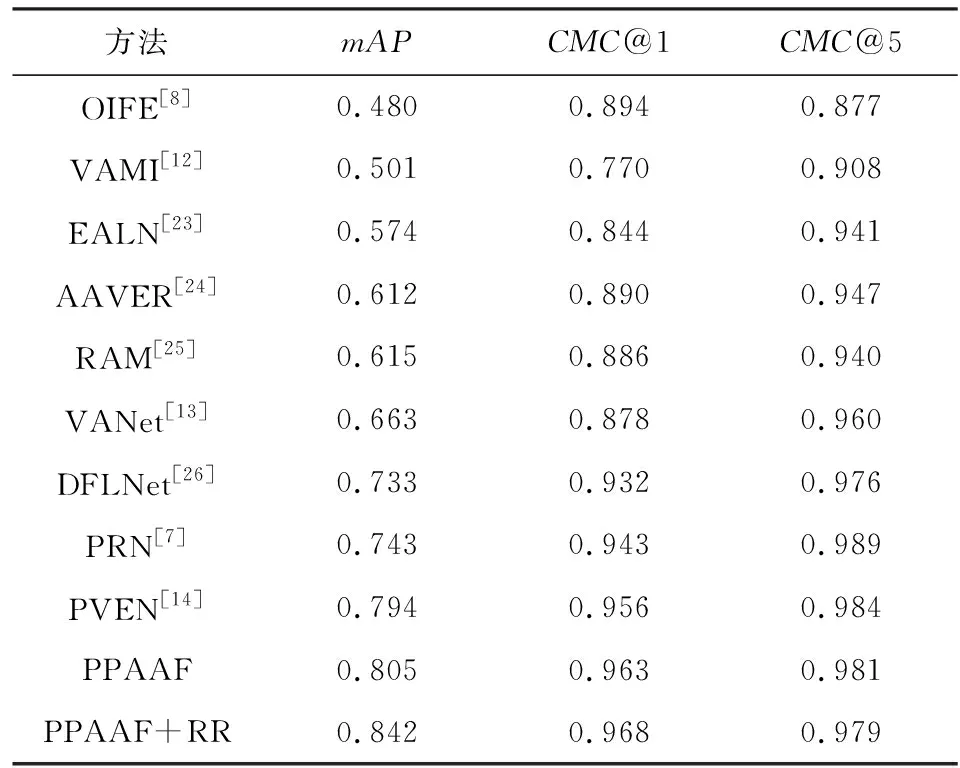
Table 2 Performance Comparison of Different Methods on Veri-776 Dataset

Fig. 5 Ranking results obtained by baseline and our method for some hard samples图5 基准与本文方法对一些难样本的排序结果
5.4 消融实验
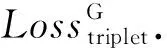

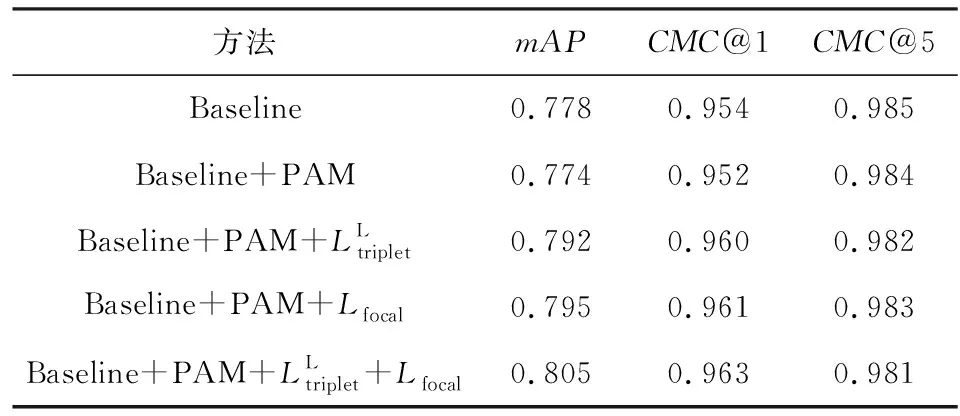
Table 3 Effects of PAM and Multi-task Loss表3 PAM与多任务损失的影响
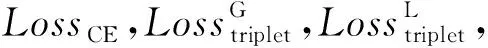
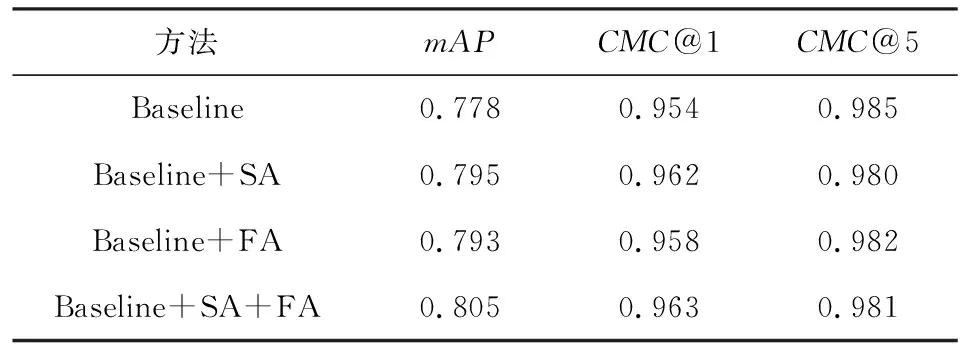
Table 4 Effects of SA, FA and Their Combinations表4 SA,FA及其融合的影响
针对利用车辆特征进行的2项分类任务,本文同样进行了实验以验证其有效性,Veri-776数据集上的实验结果如表5所示.结果表明,如果不进行分类任务(无LossCE,无Lossfocal),网络的性能受到大幅度削弱,相比基准,mAP降低了8.4%,CMC@1降低了约6.0%;不利用车辆的整体特征进行分类任务(无LCE),使网络的性能受到了较大的影响,相比基准,mAP降低了2.1%,CMC@1降低了约0.2%;不利用车辆的组件特征进行分类任务(无Lfocal),也使得网络的性能受到了一定程度的影响,相比本文方法,mAP降低了1.3%,CMC@1降低了约0.3%.
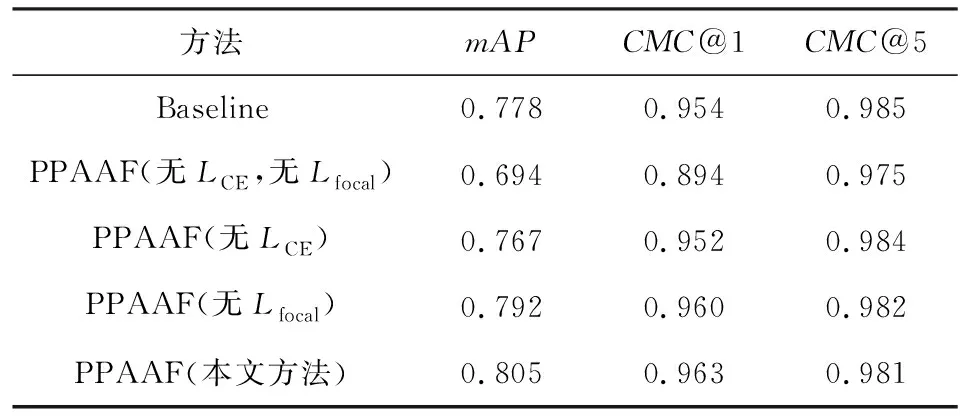
Table 5 Effects of Two Auxiliary Tasks表5 2种辅助任务的影响
5.5 参数影响分析
在推理过程中,计算车辆重识别排序需要指定超参数λ.为研究λ的取值对重识别性能的影响,分别在不使用PAM和使用PAM的情况下,调整λ的取值,并记录对应的mAP与CMC@k的值.使用PAM前后λ的取值对网络性能的影响如表6和表7所示:
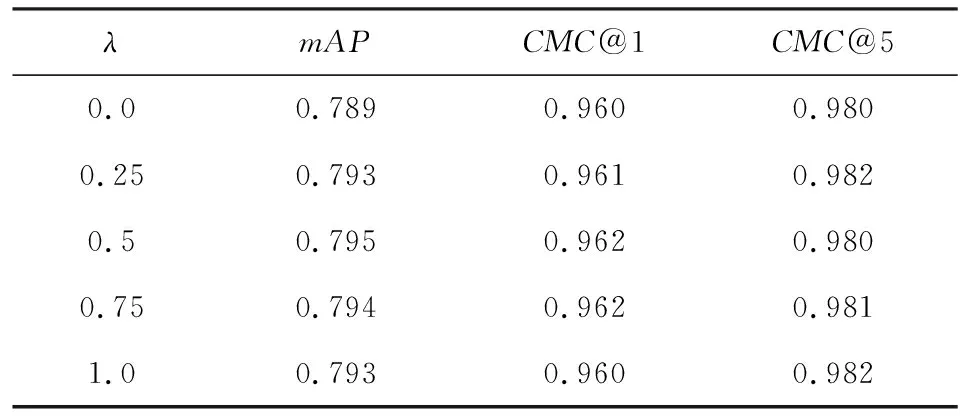
Table 6 Effect of λ Without PAM on the Performance表6 不使用PAM时λ对性能的影响

Table 7 Effect of λ with PAM on the Performance表7 使用PAM时λ对性能的影响
结果表明,不使用PAM时,当λ=0.5,网络的性能达到最优,此时mAP=0.795;使用PAM时,当λ=1.0,网络的性能达到最优,此时mAP=0.805.使用PAM使网络性能在mAP上提升了约0.01.
λ表示车辆组件特征距离在最终计算车辆重识别时对各车辆图像对间总特征距离的贡献程度,λ越大,则车辆的组件特征距离越有效.因此,本文所提出的PAM不仅提升了网络的性能,还提升了网络提取各组件特征的有效性.
6 结论与展望
本文利用修改后的深度残差网络与带掩膜的全局平均池化分别抽取了车辆的整体特征与各组件的特征,并将多种注意力机制进行融合,使得网络可以精确地计算图像对之间的总特征距离,从而给出更加准确的车辆重识别结果.实验表明,融合了多种注意力机制的方法不但能够在多个车辆重识别数据集上取得更优的性能表现,而且能够提高所抽取的车辆组件特征的有效性.然而,本文研究仍未完全摆脱依赖于独立检测器的桎梏,所采用的车辆组件语义分割模块独立于整个网络,且车辆组件的语义分割结果对重识别模块的性能表现存在一定影响.在后续的研究中将尝试解决这些问题.
作者贡献声明:胡煜负责文献调研、方法与实验设计、论文撰写和全文修订;陈小波负责提出指导意见、框架设计和全文修订;梁军负责提出指导意见和全文修订;陈玲负责内容设计和实验结果分析;梁书荣负责论文撰写和全文修订.
猜你喜欢
今日农业(2022年14期)2022-09-15
能源工程(2022年2期)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
商用汽车(2021年4期)2021-10-13
纺织科技进展(2021年5期)2021-07-22
电力设备管理(2020年4期)2020-12-05
无线互联科技(2020年10期)2020-08-14
甘肃教育(2020年22期)2020-04-13
家庭影院技术(2019年8期)2019-08-27
第二课堂(课外活动版)(2016年2期)2016-10-21
