
儿童医疗数据智能分类分级体系研究与设计
2022-11-11 11:02李竞齐国强俞刚
电子技术与软件工程 2022年15期
李竞 齐国强 俞刚
(浙江大学医学院附属儿童医院数据信息部 浙江省杭州市 310052)
我国已将大数据战略上升为国家战略[1,2],旨在全面推进我国大数据发展和应用,推动数据资源开放共享。当前,我省正在全面推进数字化改革,数据资源合理利用是其重要目标。我省卫生健康行业也在加快实施“1314”卫生健康数字化改革[3],在合规的前提下充分挖掘医疗数据价值,激活医疗大数据产业潜能,从而促进我省数字经济高速健康发展。然而在实际应用场景中,医疗数据规范使用仍面临诸多挑战[4-6]。
互联网端患者数据的归属与利用、多中心科研中临床数据的共享开放、社会第三方机构使用数据合规性等风险层出不穷,患者隐私保护难度大、医疗数据分级效率低、医疗数据分级标准缺失等问题亟待解决。其中,儿童个人信息较成人更为敏感,导致上述问题在儿童医疗数据分级管理中更加凸显。如何在保证数据安全的前提下,为医疗数据开发利用提供技术支撑和标准规范成为摆在医疗数据管理者与医疗政策制定者面前的紧迫任务。
与国外相比[7-9],我国虽拥有海量的医疗数据,但是可真正用于医疗数据智能化分类分级的产品屈指可数,尤其在儿童医疗数据分类分级方面尚无落地应用。本文依托浙江省自然科学基金项目,研究设计儿童医疗数据智能分类分级系统。
1 系统设计
1.1 设计依据
近年来我国在数据安全领域密集发布了多项政策和法律法规,提出强化数据资源管理,要推动数据的分类分级管理。《健康中国2030规划纲要》提出国家工程实验室开始针对政府数据分类与分级的需求,构建“政务数据知识图谱智能管理平台”原型系统,完成该原型系统的编码实现[10]。全国信息安全标准化技术委员会发布的《信息安全技术大数据安全管理指南》提出了建立大数据安全管理基本原则,规定了大数据安全需求、数据分类分级、大数据活动的安全要求、评估大数据安全风险[12]。2021年颁布的《中华人民共和国数据安全法》更是强调要建立数据分类分级制度,并对敏感数据进行重点保护[16]。如表1所示。

表1:医疗数据分级依据文件
1.2 分类分级定义
通过建立的规则引擎,实现敏感数据发现(客观数据),方案(标准)的组合执行规则、指标判定规则等。综合上节的标准规范,按照数据的重要程度、风险级别、影响范围和影响程度,可将儿童医疗数据分为5级:
第1级:不敏感数据,可公开使用数据。依法公开和披露的数据,例如医院基本属性、医院人员信息、医院设备信息等,可直接面向公众开放。
第2级:一般敏感的数据。例如儿童科研进展数据,可穿戴设备自采数据等,可以提供科室用于研究分析,需要使用数据的部门提交申请,并且通过授权后方可在限定范围内使用。
第3级:较敏感数据。没有通过授权,可能对儿童或监护人健康医疗数据主体造成损害,损害程度为中级。需要使用数据的项目提交申请,并且通过授权后方可在限定项目范围内使用。
第4级:高度敏感数据。没有通过授权,可能会对儿童或监护人健康医疗数据主体造成损害,损害程度为较高。例如医生用药选择、医生建议、APP医生诊疗信息等,数据的使用权限只限于给与儿童疾病诊疗相关的活动人员使用。
第5级:极度敏感数据。没有通过授权,可能会对儿童或监护人健康医疗数据主体造成损害,损害程度为严重。例如儿童疾病史、儿童患者基本信息、影响检测信息等,数据的使用权限只限于主治医护人员使用,并且要求严格管控。
1.3 数据资源目录
构建数据智能应用的全流程支撑平台,通过对数据资源的统一编目、统一服务、统一共享、统一管理,达到对数据资源的有效管控,并在管好数据的基础上实现对数据的标准化管理、常态化质检、专题化分析、价值化运营,从而推进以数据资源目录为核心的数据资源运营管理体系建设。
数据资源目录技术特点如下:
(1)元数据:元数据通过数据资源目录实现数据的价值挖掘,可实现快速查找数据、精确定位数据、准确地理解数据和快速使用数据。帮助用户降低数据管理人工成本、提升数据服务效率。
(2)SOA架构:本系统采用面向服务架构技术进行开发,它将应用的不同服务通过定义好的契约以一种通用和统一的方式进行交互。随着应用系统的集成及规模不断增长,SOA架构凭借其解耦特性,使得系统可以按照模块化来进行扩张更新。
(3)并发技术:本系统设计时采用多线程并发设计,通过分层做隔离,通过微服务解耦、削峰、异步、消息分发等技术提高了运行效率,增强了系统的灵活性。
(4)轮询技术:本系统运行时服务端会接收到客户端发送的请求,为了降低无效的服务响应,当客户端没有更新数据的时候,可以将大量请求缓存,分散开处理,通过这种机制减少资源的消耗。
1.4 模型构建
通过建立规则引擎机制,实现对客观类数据进行分级分类。通过机器学习针对主观数据分级分类,形成初步的分级分类方案,最终需要人员介入,提高准确性。给一个字段打分级分类标签,即可以快速给数据中心内所有相同分类的字段打标签。并不断学习分级分类标签特征,对新增数据进行分类标签推荐。如图1所示。

图1:智能分级分类标签架构
1.4.1 医疗数据特征向量提取
如图2所示,对医疗数据特征数据提取,针对数据特征进行统计分析,通过数据计算得出数据特征的中心分布情况,并且对分布数据进行量化处理,再是通过多次非线性计算计算,针对海量数据迭代式非线性计算,得出高纬度的特征空间信息,再通过数据模糊关联技术,针对数据特征间的关系进行重构,得出具有自适应性的特征聚类中心,建立特征聚类中心数据库,围绕数据特征建立特征分布的重构。

图2:医疗数据特征向量提取图
1.4.2 医疗数据分类分级模型
如图3所示,分级分类模型技术我们采用了欧式距离和字符串相似度两种算法,在特征向量矩阵的基础上,对数值型数据采用了欧式距离算法,对字符型数据采用编辑距离的字符串相似度算法,计算数据集中样本间的距离;再确定数据集的样本间距离后,对机器学习算法的eps、minPts进行估计,其中,eps是扫描半径,minPts是最小包含点数,DBSCAN是具有噪声的基于密度的聚类;将计算的eps和minPts值作为机器学习参数值,对待清洗的数据集进行密度聚类;
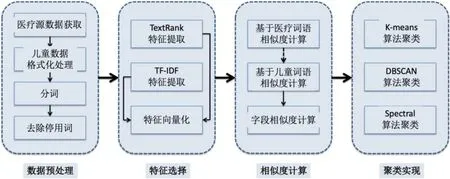
图3:医疗数据分类分级建模图
评估方法——轮廓系数(Silhouette Coeきcient):

计算样本i到同簇其它样本到平均距离ai。ai越小,说明样本i越应该被聚类到该簇(将ai称为样本i到簇内不相似度)。
计算样本i到其它某簇Cj的所有样本的平均距离bij,称为样本i与簇Cj的不相似度。定义为样本i的簇间不相似度:bi=min(bi1,bi2,…..,bik2);
si接近1,则说明样本i聚类合理;
si接近-1,则说明样本i更应该分类到另外的簇;
若si近似为0,则说明样本i在两个簇的边界上。
1.4.3 智能分级分类标签推荐
读取数据库表字段名称形成数据源,然后通过内置的算法提取数据特征,并读取字段内容自动提取该字段的数据特征,其次对相同数据类型的字段进行聚类,出现聚类出错情况需要进行手工校正,用户手动将数据字段集关联到分级分类清单的数据项上,为聚类后的数据字段集统一打签,最后通过AI算法学习已标识数据特征模型,自动为新字段关联数据标签,出现自动关联出错时可人工进行干预,从而提高自动关联的准确率。
2 结果
建成儿童医疗数据智能分类分级系统,其技术特点如下:
(1)展示字段类型、长度、字段样例数据,方便进行字段标签确定。
(2)给一个字段打完标签后,自动推荐相似字段,支持批量给多个相似字段打标签。
(3)基于已进行分级分类标签的字段学习,自动推荐相关标签(相似度推荐)。
(4)通过人工智能解决分级分类效率慢、识别准确率低的问题。
(5)定时生成分级分类报告。
3 结论
构建儿童医疗数据智能分类分级体系是必要且可行的,制定儿童医疗数据分类分级标准,形成示范应用,从而更好地保护儿童医疗数据安全,保护患儿及其家庭隐私,全面提升儿童医疗数据分类分级效率,规范儿童医疗数据使用,促进儿童医疗大数据产业健康发展。
猜你喜欢
江苏科技信息(2022年16期)2022-07-17
黑龙江省人民政府公报(2022年3期)2022-06-01
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
知识经济·中国直销(2017年12期)2018-01-03
公民与法治(2016年10期)2016-05-17
计算机工程(2015年8期)2015-07-03
图书馆建设(2015年10期)2015-02-13
新世纪图书馆(2014年7期)2014-09-19
图书馆建设(2014年3期)2014-02-12
