
融合标签信息的裁判文书证据抽取方法研究*
2022-11-09 02:34:52周裕林鹿安琪周雯童刘林红
计算机与数字工程 2022年9期
周裕林 鹿安琪 周雯童 刘林红
(1.公共大数据国家重点实验室 贵阳 550025)(2.贵州大学计算机科学与技术学院 贵阳 550025)
1 引言
近年来,人工智能技术在司法审判案件中受到日益关注,相继提出了许多法律人工智能任务,例如,司法摘要自动生成[1]、案件多标签分类[2]和法律智能问答[3]等。而证据作为了解案件事实的依据,在司法审判过程中起着至关重要的作用。从裁判文书中抽取证据实体有利于支撑证据链的自动构建,从而支持“智慧法院”的建设。因此,抽取证据实体成为法律人工智能中极为重要的任务。
当前证据抽取模型主要基于神经网络的命名实体识别(NER)方法,NER在过去数十年以及取得了飞速进步。NER方法采用序列标注形式,而传统的序列标注模型有CRF[4]、LSTM[5]、CNN-CRF[6]、LSTM-CRF[7]以及杨健等[8]提出基于边界组合的证据抽取模型,它们在信息抽取上都取得了不错的性能。近几年来,随着大规模语言模型BERT[9]以及ELMo[10]等面世,自然语言处理的信息抽取任务上进一步刷新了性能。由于证据实体在不同案件环境下存在判别的不同,传统的序列标注模型很难捕获句子的长距离语义而导致输入特征使用不充分,使得在裁判文书中的证据实体抽取上性能较差。Levy等[11]将关系抽取任务转换成智能问答任务。Li等[12]将Levy等[11]的方法应用于命名实体识别任务中,他将每一个实体类型转换成带有问题及答案的形式。此外,由于问题编码了丰富的先验知识,实验结果表明它能丰富输入特征。McCann等[13]也将情感分析任务转换成智能问答任务。
本文在以上研究的基础上,面向传统的序列标注模型很难捕获句子的长距离语义而导致输入特征使用不充分,使得在裁判文书中的证据实体抽取上性能较差的问题,提出融合标签信息的的裁判文书证据抽取方法。在2293篇裁判文书数据集上进行验证,实验结果表明了本文提出方法的有效性。本文的主要贡献如下:
1)采用基于机器阅读理解模型的方法,通过融合证据的标签信息作为先验知识输入模型,来解决序列标注模型特征使用不充分问题。
2)本文首次将融合标签信息的方法应用于裁判文书证据抽取任务中,为证据抽取任务提供一种新思路。
2 融合标签信息的证据抽取模型
2.1 BERT预训练模型
Transformer架构最早是由Vaswani等[14]提出的。它通过利用注意力机制,学习句子中词与词之间的关联程度,从而增强上下文特征的学习能力。其注意力机制公式为
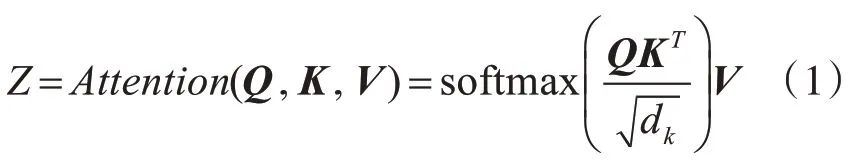
其中,Q、K、V表示3个矩阵向量;d为Q向量的维度;通过softmax对得到的分数归一化。由于此部分不是本文的重点,这里不作过多的叙述。
BERT预训练模型是在Transformer的基础上进行改进的。它由3层Embedding拼接而成,分别为Token Embeddings、Segment Embeddings和Position Embeddings。它们分别表示为词向量、句向量和位置向量。通过拼接3层向量,增强了模型学习文本语义特征的能力。
2.2 标签信息标注
本文是在BERT预训练模型的基础上构建融合标签信息的证据抽取模型。给定一个句子X={x1,x2,…,xn},其中xn代表在句子X中的第n个字。为解决序列标注模型格式在拼接标签信息上存在困难的特点,首先,需要将序列标注格式转换为(LABEL_INFO,ANSWER,CONTENT)三元组的格式,其中,LABEL_INFO表示为标签信息,ANSWER表示为答案对应的下标索引,CONTENT表示为输入的文本。由于标签信息定义的不同,会产生不同的特征输入,从而影响最终证据抽取的性能。在本文中,采用问句式、定义式和标注指南来构建标签信息。3种标签信息构建内容如表1所示。

表1 标签信息构建内容
2.3 融合标签信息的证据抽取模型
融合标签信息的证据抽取模型结构如图1所示。在BERT预训练模型的基础上,融合证据实体的标签信息,输入到BERT编码器中得到隐藏层向量,最后通过解析输出结果。
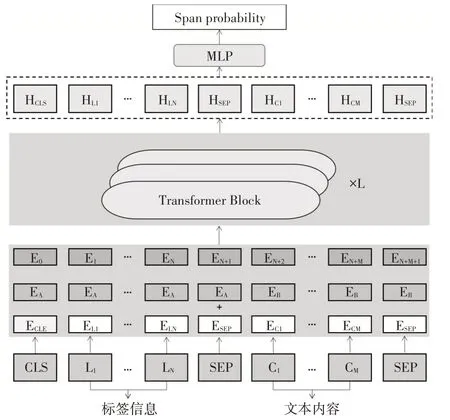
图1 融合标签信息的证据抽取模型
输入包含了标签信息以及文本内容,通过BERT预训练模型,通过Embedding的拼接输出隐藏表征矩阵:
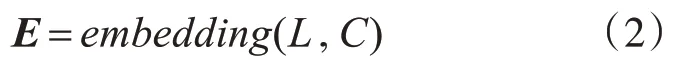
其中,L为标签信息;C为文本内容;E为模型输出的表征矩阵。
通过多层感知机(MLP)[15]解析表征矩阵得到预测的证据实体的下标索引。在MLP中,获得句子中每个字是证据开始和结束下标的概率公式为
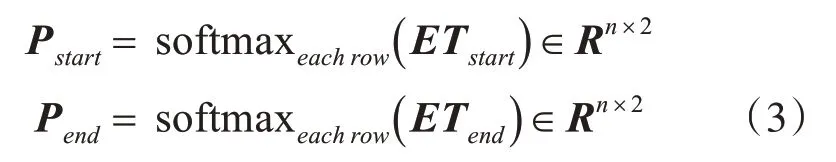
其中,Tstart和Tend是学习权重。对Pstart和Pend每一行使用argmax函数,得到预测的每个证据实体的开始和结束索引,公式为
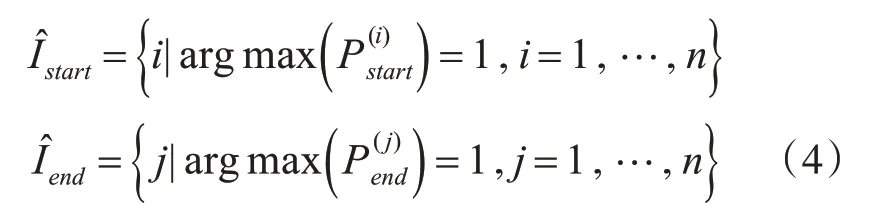
最后,训练一个二元分类器来预测句中每一个证据实体匹配的概率来组成范围概率矩阵,并定义一个学习权重m,公式为
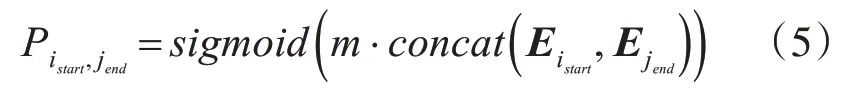
3 实验结果及分析
3.1 数据集
本次实验数据集均来自贵州省人民法院提供的2293篇裁判文书。其中,包括刑事裁判文书1696篇和民事裁判文书597篇,并将数据集按8:2划分为训练集和测试集。通过人工标注的方式对2293篇裁判文书进行标注得到本文所用数据集,如表2所示。
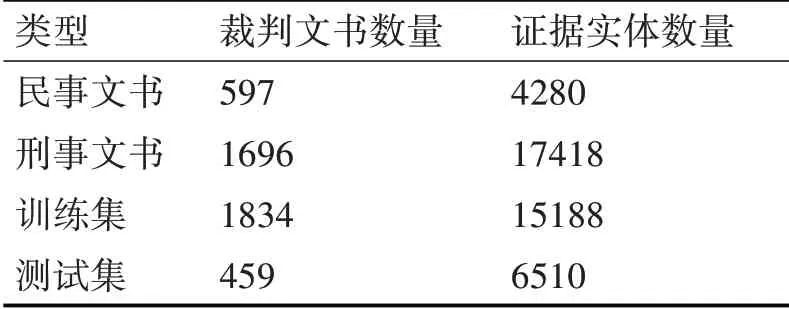
表2 数据集统计信息
3.2 评测指标
所有实验所用指标均为精准率(P)、召回率(R)和F1值。计算公式如下所示:

其中,TP是预测结果为正,样本也为正;FP是预测结果为正,样本为负;FN是预测结果为负,样本为正。
3.3 超参数设置
超参数选择的不同,对模型结果会产生较大的影响。本文优化算法使用Adam,初始学习率为5e-5,以0.05速度进行衰减。设置每个batch_size为32,迭代10轮。最后获得的span概率分布矩阵阈值threshold设置为0.5。选择BERT中的base版本。如表3所示。
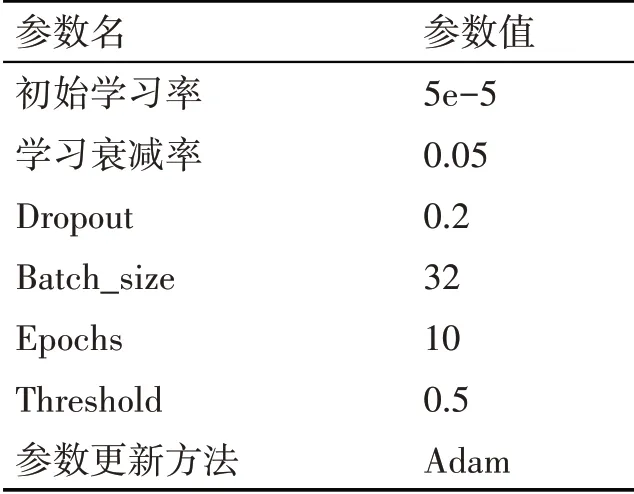
表3 超参数设置
3.4 实验结果及分析
在本文实验中,比较了5个传统的序列标注模型,分别为CRF、BiLSTM、BiLSTM-CRF、ATT-BiLSTM-CRF、BERT。实验结果如表4所示。
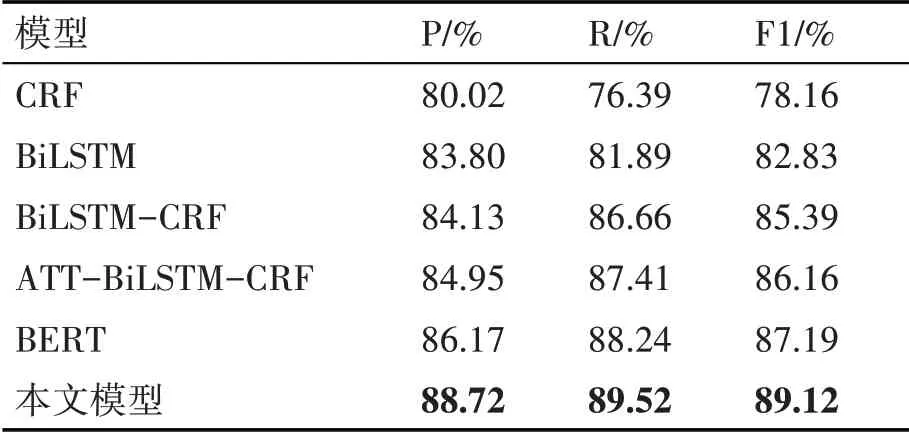
表4 模型对比实验结果
实验结果表明,5个传统序列标注模型CRF、BiLSTM、BiLSTM-CRF、ATT-BiLSTM-CRF、BERT的F1值分别为78.16%、82.83%、85.39%、86.16%、87.19%,而本文模型取得的F1值为89.12%,为所有实验中最高。比CRF模型的F1值高了10.96%,比BiLSTM模 型 的F1值 高 了6.29%,比BiLSTM-CRF模型的F1值高了3.73%,比ATT-BiLSTM-CRF模型的F1值高了2.96%,比BERT模型的F1值高了1.93%。其原因在于:1)本文模型是基于BERT大规模预训练,它区别于传统词向量模型,能够更好地理解文本语义信息;2)本文模型是在BERT模型的基础上,融合证据实体的标签信息,丰富了模型的输入特征,使得模型能更好地识别证据实体;3)对数据集格式转换的有效预处理。
在进一步实验中发现,如何定义标签信息,成为影响模型在证据抽取性能上的关键。本文根据表1提出的3种标签信息定义方式进行实验对比,如表5所示。
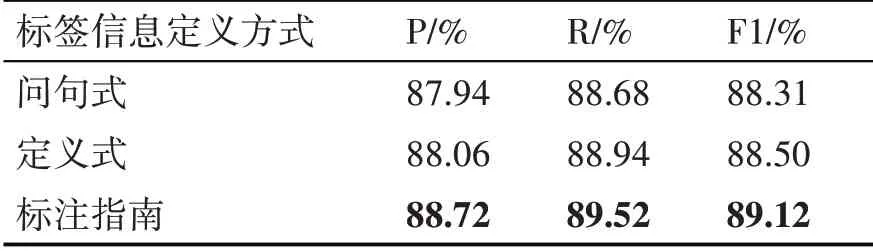
表5 标签信息对模型实验结果影响
从表5中可以看出,标注指南的标签信息定义方式取得了最高的F1值。比问句式的F1值高了0.81%,比定义式的F1值高了0.62%。原因在于:标注指南的方式相较于问句式和定义式,具有更为丰富的语义信息,能为模型的输入带来更多的标签信息特征,从而提高了模型在证据抽取上的性能。
由于融合了标签信息从而丰富了模型的输入特征,本文在训练集样本数量少的情况下进行了实验对比,实验结果证明了本文方法的有效性。本文将训练集按10%、20%、40%、80%的比例划分,测试集保持不变,如表6所示。
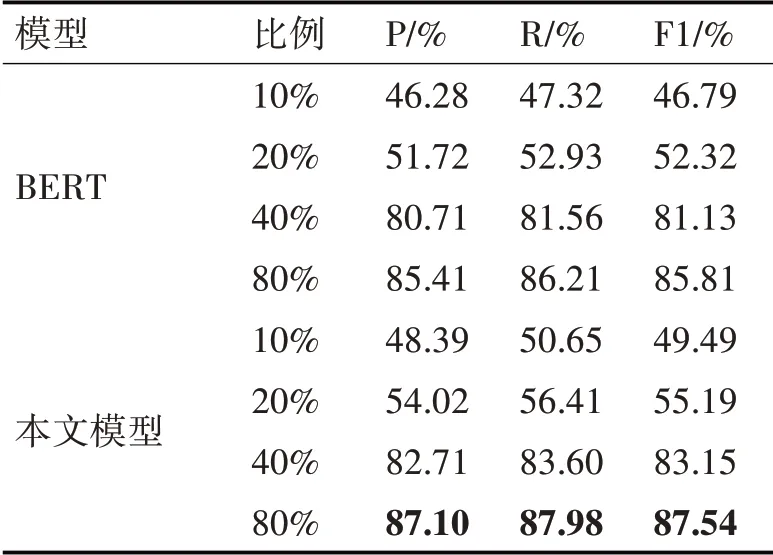
表6 小样本下标签信息对模型的影响结果
从表6中可以看出,在训练集比例10%、20%、40%和80%情况下,本文模型相较于BERT的序列标注模型,分别提高了2.70%、2.87%、2.02%和1.73%。充分证明了本文方法在BERT基础上融合标签信息的有效性,也为小样本学习提供了一种新思路。
4 结语
本文提出了一种融合标签信息的证据抽取方法,解决了序列标注模型很难捕获句子的长距离语义而导致输入特征使用不充分,使得抽取裁判文书中的证据实体性能较差的问题。本文通过定义证据实体的标签信息,与文本想融合来增强输入特征,进而提高证据实体的抽取性能。实验结果表明本文的方法相比于传统的序列标注抽取模型更具优势。
本文方法还有进一步改进的空间。在未来工作中,可以设计新的模型架构来更好捕捉文本间的语义信息,进一步提升模型在证据抽取上的性能。
猜你喜欢
邯郸学院学报(2022年2期)2022-07-05 07:26:30
民主与法制(2020年19期)2020-08-24 06:56:00
民主与法制(2020年16期)2020-08-24 06:54:48
安徽警官职业学院学报(2020年6期)2020-07-21 01:38:56
中国外汇(2019年18期)2019-11-25 01:41:54
法律方法(2019年4期)2019-11-16 01:07:10
西夏学(2019年1期)2019-02-10 06:22:40
法律史评论(2018年0期)2018-12-06 09:22:28
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
