
尺度敏感损失与特征融合的快速小目标检测方法
2022-11-09 07:13琚长瑞秦晓燕袁广林
电子学报 2022年9期
琚长瑞,秦晓燕,袁广林,李 豪,朱 虹
(中国人民解放军陆军炮兵防空兵学院计算机教研室,安徽合肥 230031)
1 引言
目标检测是计算机视觉领域的一个重要研究分支,其目的是预测图像中每个感兴趣的实例的边界框位置和类别标签.目标检测在工业、农业、医学和军事等领域有着广泛的应用前景,具有较高的研究价值.近年来,随着深度学习技术的发展,深度神经网络框架下的目标检测取得了重大进展[1~5].虽然基于卷积神经网络的目标检测器在各种具有挑战性的数据库上取得了系列的成果,但是其仍然面临目标尺度小、数据不平衡和数据标注昂贵等诸多困难.小目标只有十几到几十个像素,在图像中的信息量有限,通用检测器对其检测难度较大.另外,现有目标检测数据集中包含小目标的图片数量也相对较少.因此,小目标检测一直是一个难点、热点问题.为提升小目标的检测效果,目前主要有多尺度建模以及数据增强两大类方法.
多尺度方法的基本思想是利用网络不同层特征检测不同尺度的目标.基于不同尺度目标的语义特征所在特征层次的差异性,2016年Yang[6]等人提出尺度相关池化并从不同尺度的特征层中检测目标,提升了小目标的检测精度.基于相同的思路,刘伟[7]等人提出的SSD(Single Shot MultiBox Detector)引入了多参考和多分辨率检测技术,利用浅层特征检测小目标,利用深层特征检测大的目标,其小目标检测效果有了大的提升.针对小目标检测,2016年Cai[8]等人提出在不同尺度特征图上铺设锚框(Anchor),同样实现了在不同尺度的特征图上检测不同大小的目标.由于目标检测任务同时需要物体的“语义和位置”特征,语义特征在深层特征图中,因此分层预测的网络结构难以兼顾小目标的语义和位置特征.针对该问题,2017年Lin[9]等人提出了特征金字塔网络(Feature Pyramid Networks,FPN),用自顶向下的方法将深层特征图上采样后与浅层特征图融合,利用融合后的特征图做多尺度目标检测.为了提高小目标检测的精度,2018年,Liang[10]等人提出一种两阶段的目标检测方法,该方法在区域建议阶段,采用横向连接的特征金字塔网络,使得小目标的语义特征更加突出,同时,为小目标设计了专门的Anchor,提升了小目标检测效果.2019年G.Ghiasi[11]等人基于神经网络搜索技术,利用强化学习自动搜索对当前任务最优的FPN(Feature Pyramid Networks),进一步提升了小目标检测的精度.2020年Wu[12]等人提出的多尺度正样本训练方法对小目标检测效果也有一定提升.针对小目标检测难题,在FPN的基础上,2020年Li[13]等人提出一种提取并融合多尺度特征的目标检测网络,提高了对目标尺度变化的鲁棒性.上述多尺度检测方法虽然对小目标检测精度有提升,但也存在网络结构复杂和速度较慢等不足.解决小目标检测问题的另一类思路是数据增强.对基于锚框(anchor-based)的目标检测方法而言,通过增加检测小目标的anchor数量可以达到数据增强的目的.2017年Zhang[14]等人提出的S3FD(Single Shot Scale-invariant Face Detector)通过调整候选框的生成步长产生更稠密的anchor增加小目标样本数量,使得小目标得到充分训练从而提升小目标的检测精度.2019年Kisantal[15]等人对包含小目标的图像进行过采样和对小目标随机变换后复制到新位置的方式增加小目标数量.为了解决数据集中小物体数量不足的问题,2021年Chen[16]等人使用图像拼接技术动态地生成拼接图像提升小目标数量,从而增强小目标的检测精度.
综上所述,现有针对小目标的检测方法存在网络结构复杂和速度较慢等不足.为了提高基于深度学习的目标检测方法对小目标的检测精度和速度,同时对中、大目标也有较高的检测性能,在CenterNet[18]的启发下,本文提出一种基于尺度敏感损失与特征融合的单阶段无锚框小目标检测方法(Scale-Sensitivity Loss and Feature Fusion Detector,SSLFF-Det).该方法利用尺度敏感损失训练分类热图,提高小目标对网络模型参数学习的影响,利用反卷积和可变形卷积自上而下融合特征,获得高分辨率、强语义的特征图来检测目标.在PASCAL VOC数据集上,对提出的方法进行了实验验证与分析,实验结果表明:本文方法达到了预期效果,即提升了小目标检测的精度和速度,同时对中、大目标也具有较优的性能.
2 尺度敏感损失
目前,常用的目标检测数据集有PASCAL VOC和MS COCO(Microsoft Common Objects in Context).文献[15]对MS COCO数据集进行统计分析发现:MS COCO数据集中小目标、中目标和大目标的占比分别是41.43%、34.32%和24.24%,但是只有51.82%的图像包含小目标,包含中、大目标的图像分别占70.07%和82.28%.虽然MS COCO数据集中小目标总数量较多,但包含小目标的图像占比较低.本文参考MS COCO数据集对小、中、大目标的划分标准,对PASCAL VOC数据集进行了数据统计,VOC 2007训练集中小目标、中目标和大目标的占比分别为11.20%、34.49%和54.31%,包含小目标的图像仅占12.67%,而包含中、大目标的图像分别占39.45%和90.52%.可以看出:在PASCAL VOC数据集中,小目标的数量占比以及包含小目标的图像数量占比均较低.PASCAL VOC中的部分图像样例如图1所示,其中多数图像只标注了中、大目标,而小目标未标注,这样会导致小目标训练样本较少.在现实应用中,小目标标注难度大等原因也会造成小目标训练样本较少的情况.

图1 PASCAL VOC数据图像(其中黄色框为标注目标,红色框内是未标注的小目标)
众所周知,目标检测网络的训练,是随机取一批图像计算其中标注样本的损失进行网络参数的训练.由于训练数据中包含小目标的图像较少,这会导致每一批图像中包含的小目标样本较少.这种尺度上的样本不平衡使得小目标对模型训练的影响相对中、大目标较小,导致模型对小目标的学习不充分.另外,目标在特征图上的信息量大小与目标尺度存在正相关关系,因此小目标在特征图上的信息较少,对模型训练的影响也较小.上述两个方面是导致小目标检测精度低的重要原因.为解决难易样本不平衡问题,何恺明等人提出Focal Loss[19],在分类损失中加入一种与样本难易度正相关的损失权重,有效提高了网络训练对难样本的关注度,提升了目标检测的性能.受此启发,为提高小目标对模型的影响,本文提出尺度敏感损失函数用于目标检测网络的训练,其义定义如下:
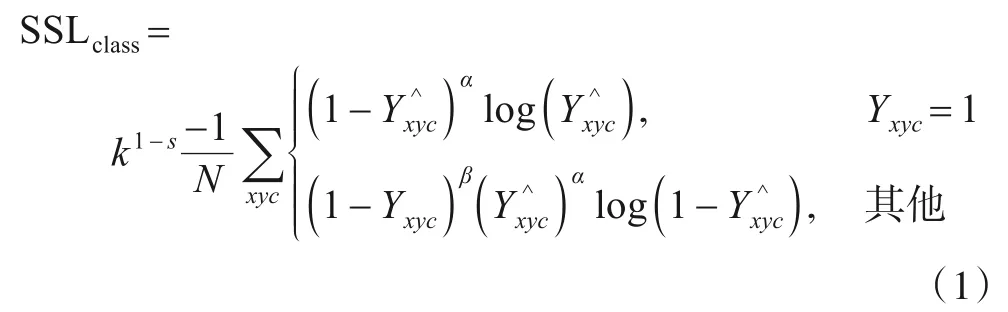
其中,Yxyc和分别表示类别热图中(x,y)处c类的标注值和预测值,N是标注的样本个数,α、β为超参数,实验中分别设置为2和4,s是与目标尺度负相关的变量.
(1)式中k1-s定义为损失权重,其中s为目标面积与图像面积的比值,即目标的相对尺度.对于s的取值,如果一张图像中包含多个目标,则取其中尺度最小的目标计算s的值,以保证每张包含小目标的图像可以有较大的训练权重,在训练中受到更多关注.k为超参数,用来调节尺度敏感权重的大小.图2给出了损失权重k1-s的函数图,从图2可以看出,s能保证k1-s的取值在1到k之间,这确保目标尺度对网络训练产生的影响在一定范围.从函数性质上看,k1-s是指数函数,它对自变量s的变化比较敏感,这使得包含不同尺度目标的损失权重产生差别.

图2 尺度敏感权重函数图像
基于上述分析,设计一批训练数据的损失计算方法,见算法1.
算法1中,woi,j和hoi,j分别是Ibatch中第i个训练图像中第j个目标的宽和高;W iI和H iI分别是Ibatch中第i个训练图像的宽和高为第i个训练图像中最小目标的面积,s2i为第i个训练图像的面积;Ni是第i个训练图像中的目标数.
3 反卷积与可变形卷积特征融合网络

算法1一批数据损失计算方法输入:一批训练图像Ibatch={I1,I2,…,IM},超参数k、α和β.输出:Lossbatch Lossbatch=0;FOR i=1 to M s1i =min(wo i,1×hoi,1,…,wo i,j×ho i,j,…,wo i,Ni×ho i,Ni); =W I i×H I i;si=s1i/s2 i;s2i SSLi class=k1-si -1 1-Ŷxyc ( )αlog()Ŷxyc, Yxyc=1 Ni∑xyc■ ■ ■■■■ ■■■;( )1-Yxyc β()Ŷxyc αlog( )1-Ŷxyc, 其他Lossbatch=Lossbatch+SSLi class;END
现有文献[6~13]表明:在特征提取网络中,深层特征感受野较大,包含丰富的语义信息,浅层特征感受野较小,具有更多边缘和纹理等细节信息.目标检测的两个核心组件是分类和回归,语义信息的分类能力强,细节信息的定位能力大.小目标的语义信息在深层特征中能量小甚至消失,其细节信息主要在浅层特征中.中大目标的语义信息在深层特征中具有较高能量,其细节信息在浅层特征中更加丰富.为了提升小目标的检测性能,根据深层和浅层特征的上述特点,本文提出一种基于反卷积与可变形卷积的特征融合模块,其结构如图3所示.该模块首先对待融合特征图f-map2进行3×3的2倍上采样反卷积,得到与融合特征图f-map1相同大小的特征图;然后再通过一个可变形卷积,来缓解上采样带来的混叠效应和棋盘效应,并增强模型的拟合能力;最后将得到的特征图与f-map1相加得到本模块的融合特征图ff-map.该模块可以根据网络深度及实际需求增加或减少,以达到最优效果.实验发现:在ResNet-18与ResNet-50上分别加入2个模块效果较好,而ResNet-101上使用3个效果更佳.
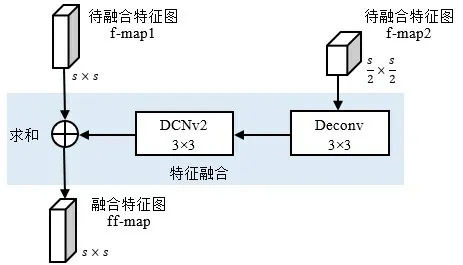
图3 特征融合模块
利用提出的特征融合网络模块设计小目标检测网络,网络结构如图4所示,包括自底向上和自顶向下两个通路.自底向上通路是骨干网络用于特征提取,本文利用ResNet-50构建自底向上通路.为获得高分辨率的特征图,删除了ResNet-50第一个池化层,利用其block1~block4得到尺度大小为原图的1/2、1/4、1/8和1/16的特征图.自顶向下通路用于特征融合,包括2个串联的特征融合模块,先将block4与block3的输出特征进行融合;然后再将得到的融合特征与block2的输出特征进行融合,从而得到高分辨率、强语义的融合特征图用于目标检测.网络的输出是目标类别、尺度和中心偏移量.
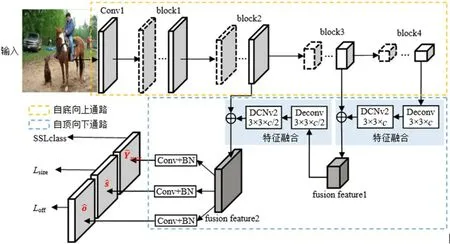
图4 征融合网络结构
图5(a)给出了PASCAL VOC数据集中一张图像,图5(b)~(e)显示了图4(a)在特征融合网络中block1~block4的输出特征图,图5(f)是其最终融合特征图.对比图5(b)~(f)各特征图可以看出:在最终融合特征图5(f)中,小鸟的融合特征既包含了深层特征的语义信息,又具有浅层的纹理边缘信息,大目标汽车的融合特征也同时包含深层语义信息和浅层纹理边缘信息.

图5 目标图像与特征图
4 网络训练与实现细节
本文用多任务损失函数训练网络,其定义如下:
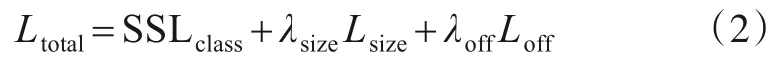
其中,SSLclass是式(1)所示的尺度敏感分类损失;λsize和λoff是超参数,本文λsize取0.1,λoff取1.0;Lsize是尺度损失,其定义如式(3)所示;Loff是中心偏移损失,其定义如式(4)所示.
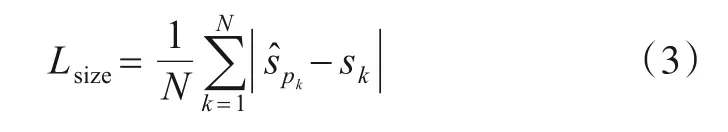
式(3)中,N是样本个数,和sk分别是目标k的尺度预测值和标注值.
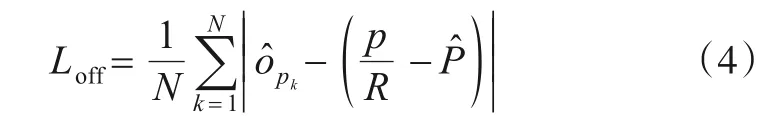
式(4)中,N是样本个数,是目标k的中心偏移预测值,p是目标k的位置标注值,R是下采样倍数,本文R=4.
网络训练时输入图像的大小归一化为512×512,因此网络输出的目标类别热图、尺度热图和偏移量热图大小均是128×128.目标类别热图的通道数与数据有关,对于PASCAL VOC数据集类别热图的通道数是20,对于MS COCO数据集其类别通道数是80,尺度热图的通道数和偏移量的热图通道数均是2.模型的初始化权重是由ResNet-50在ImageNet上预训练得到,并使用4张GPU对ResNet-50网络进行训练,训练批次大小(batchsize)设置为32,共训练100个轮次(epoch).初始学习率设置为2.5e-4,并在第50及75个轮次分别衰减至2.5e-5及2.5e-6.
5 实验结果与分析
5.1 实验环境与数据集
在SYS-7048GR-TR台式机(CPU型号为Intel Xeon(R)ES-2630v4@2.20 GHz×20,内存为64 GB,GPU为RTX2070S 8G)上实现了本文方法,软件环境是:Ubuntu 18.04、Python 3.6、torch 1.4.0、cuda10.1和cudnn7.5.为了验证本文方法的有效性,使用PASCAL VOC数据集对本文方法进行消融实验,并与现有优秀方法进行了对比分析.
5.2 消融实验
针对本文的两个改进方面进行消融实验,以验证尺度敏感损失和特征融合两方面对小目标检测性能的提升作用.
5.2.1 尺度敏感损失实验分析
首先,为验证尺度敏感损失和不同超参数对目标检测精度的影响,对取不同k值的本文方法进行实验验证与分析,实验结果如表1所示.从表1可以看出:尺度敏感损失明显提升了小目标的检测精度,表明尺度敏感损失在训练时提高了网络对小目标的关注程度,有效提高了小目标对网络学习的影响力.随着k值的增加,小目标的检测精度逐渐提升.从表1也可以看出:k值为4时,小目标的精度已经提升不大,而中、大目标的检测精度有一定的下降,导致总体精度下降.主要原因是当k值设置过大时,尺度敏感损失对网络训练的影响已经超出正常范围,对网络模型的学习有负面影响,因此尺度敏感损失对目标检测精度的提升存在上限.从表1中的实验结果可以看出:k值设置为2时,尺度敏感损失的综合性能最佳.

表1 不同k值的检测结果
5.2.2 特征融合实验分析
为验证特征融合对小目标检测的性能的影响,对使用不同深度ResNet的本文方法进行实验验证与分析,实验结果如表2所示.从表2可以看出:对不同深度的ResNet进行特征融合后,小目标的检测精度均有不同程度的提升,并且网络越深提升效果越明显.其中,轻量型网络ResNet-18提升最小,主要原因是其下采样倍数较低,它自身已能够提取丰富的细节信息,因此提升效果并不明显.ResNet-101的小目标检测精度最低,特征融合后ResNet-101的小目标检测精度提升最大,但是检测速度有较大降低,这一结果表明:当网络层数超过某一阈值时,网络越深越不利于小目标的检测,同时检测速度也会明显下降.特征融合后ResNet-50的小目标精度提升了3.4%,整体精度mAP有少许降低,但是其检测速度仍然较快.
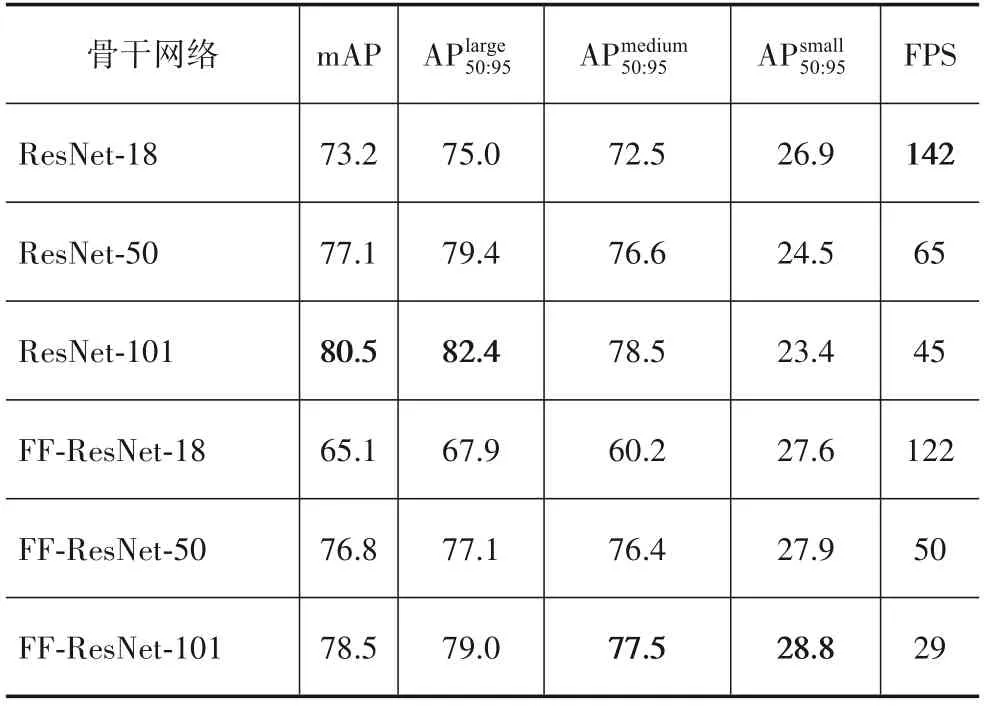
表2 不同深度ResNet网络特征融合检测结果
5.2.3 综合影响实验分析
为验证尺度敏感损失与特征融合同时加入对小目标检测性能的综合影响,同时使用尺度敏感损失与特征融合网络进行训练和测试.其中尺度敏感损失k值设置为2,并采用不同深度的ResNet作为骨干网络,实验结果如表3所示.结合表1、表2与表3可以看出,当尺度敏感损失与特征融合网络同时加入时,相比两种策略分别加入,小目标检测精度得到进一步提升,该结果表明,本文提出的两种策略能够协同工作,共同提升小目标检测精度,相互之间没有抵消及干扰.另外,两种策略同时作用时,整体精度相比单独采用特征融合网络时有所下降,其主要原因是尺度敏感损失使得网络更加关注小目标,使得中、大目标的检测精度受到一定影响,小目标精度虽有所提升,但总体精度有少许下降,但是该影响依然处于可以接受的范围.
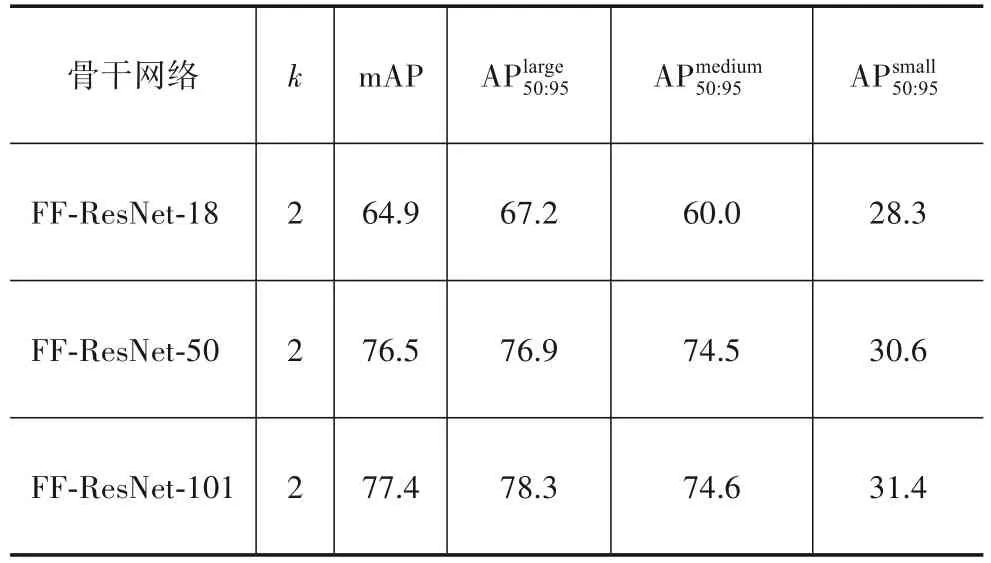
表3 综合影响实验结果
5.3 对比实验
5.3.1 定量实验
该实验将本文目标检测方法SSLFF-Det与目前先进目标检测方法进行性能对比分析,在相同软硬件环境下,利用VOC 2007与VOC 2012合成数据集进行训练、测试对比分析.为了比较的公平性,目标检测方法均采用ResNet-50或者与之深度相近的网络作为骨干网络.实验结果如表4所示.从表4结果可以看出,本文目标检测方法SSLFF-Det对小目标的检测最优,在检测速度方面,SSLFF-Det的检测速度处于较高水平,能够达到50FPS.
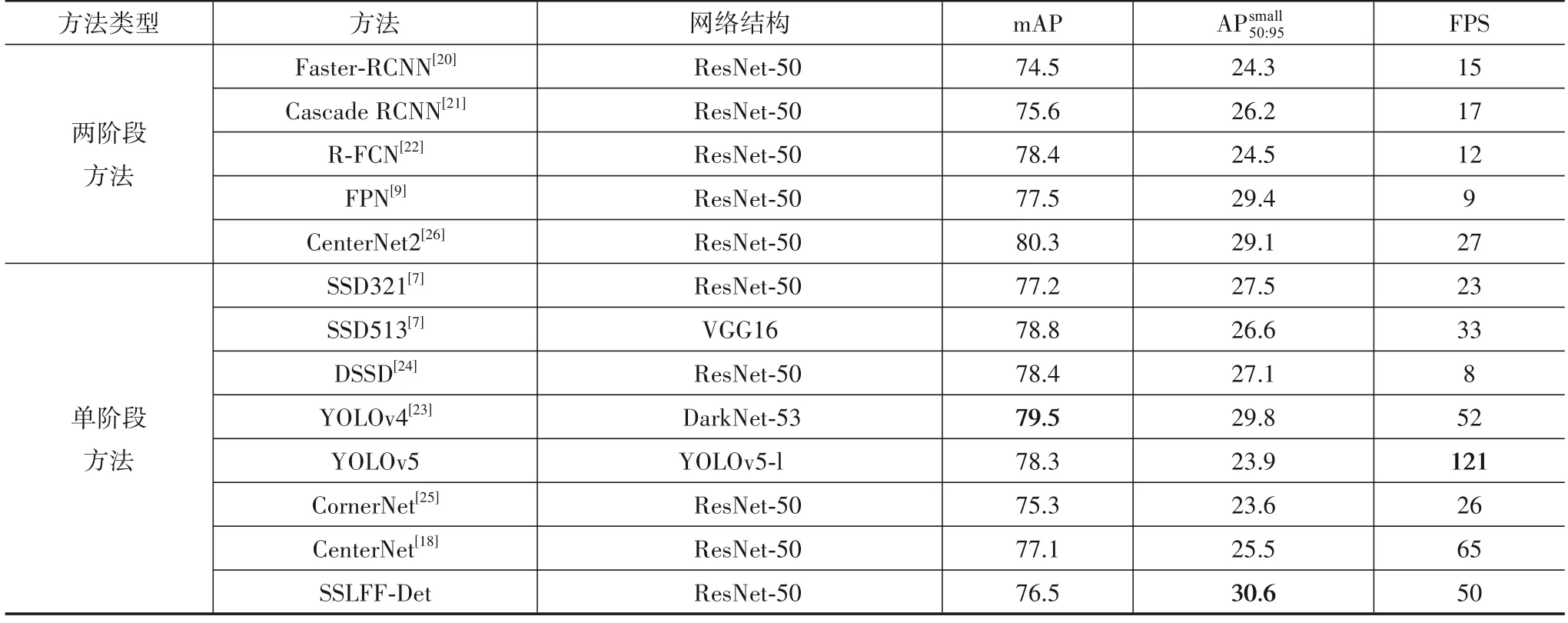
表4 本文方法与各类方法对比
5.3.2 定性实验
图6给出 了 本文 方法、CenterNet[18]、SSD513[7]和YOLOv4[23]对PASCAL VOC数据集中4张图像的检测结果,其中图6(a)是CenterNet的检测结果,图6(b)为SSD513的检测结果,图6(c)为YOLOv4的检测结果,图6(d)为本文方法的检测结果.可以看出,本文方法对小目标检测具有更高召回率.

图6 不同检测方法检测结果
6 结论
针对现有基于深度学习的目标检测方法对小目标检测的不足,本文提出一种基于尺度敏感损失与特征融合的通用快速小目标检测方法.本文方法的主要创新点有两个方面:一是提出尺度敏感分类损失,使小目标在训练中更受关注,从而提升网络对小目标的学习能力;二是在anchor-free检测框架下加入了特征融合,从而得到融合深度语义和浅层细节的特征图进行目标检测.对提出的目标检测方法进行了实验验证和分析,实验结果表明:本文提出的目标检测方法对小目标检测效果提升明显,且检测速度较快.
猜你喜欢
导航定位学报(2022年5期)2022-10-13
机械工业标准化与质量(2022年8期)2022-10-09
今日农业(2022年15期)2022-09-20
社会科学战线(2022年7期)2022-08-26
小天使·二年级语数英综合(2019年10期)2019-11-08
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
读者·校园版(2015年19期)2015-05-14
中国信息化周报(2015年1期)2015-04-09
时代英语·高三(2014年5期)2014-08-26
海外英语(2013年8期)2013-11-22
