
基于方面和胶囊网络的跨域评分预测模型
2022-11-09 07:13梁顺攀郑智中原福永
电子学报 2022年9期
梁顺攀,刘 伟,郑智中,原福永
(燕山大学信息科学与工程学院,河北秦皇岛 066004)
1 引言
数据稀疏问题一直是推荐系统的挑战之一,数据稀疏会导致推荐系统的推荐结果精度不高等问题,文献[1]针对推荐系统中的高维稀疏矩阵提出了一种无约束非负潜在因子分析算法UNLFA(Unconstrained Non-negative Latent Factor Analysis).文献[2]研究了八种扩展的随机梯度下降算法,提出八种新的潜在因子模型.文献[3]提出了一种基于高维稀疏矩阵的深度潜在因子模型DLFM(Deep Latent Factor Model),通过一个非线性激活函数将多个潜在因子模型依次连接起来.上述几种方法利用矩阵分解有效的缓解了推荐系统中高维稀疏矩阵的数据稀疏问题,但没有考虑到其他的辅助信息.使用评论文档作为辅助信息可以缓解仅使用评分矩阵时产生的数据稀疏问题,但用户在目标域冷启动[4]时,就无法从目标域中提取相关用户的偏好.
跨域推荐能够缓解用户在目标域冷启动问题.基于集合矩阵分解的关系学习模型CMF(Collective Matrix Factorization)[5]将矩阵分解应用到跨域推荐中,并且在多个源域的因子之间共享参数来实现跨域知识集成;跨域推荐的嵌入映射框架EMCDR(Embedding and Mapping framework for Cross-Domain Recommendation)[6]通过多层感知机捕捉域间的非线性映射函数,得到来自不同领域的用户表示;跨域和跨系统的深度推荐框架DCDCSR(Deep framework for both Cross-Domain and Cross-System Recommendations)[7]先使用矩阵分解模型生成用户和项目的潜在因子,然后使用深度神经网络来映射跨域的潜在因子,进一步扩展了EMCDR.基于共享知识模型的跨域推荐算法SKP(Sharing Knowledge Pattern)[4],通过分解用户-项目评分矩阵得到用户分组对项目分组的评分知识模型,并利用目标域的个性知识模型和各个领域共性知识模型得到推荐结果.知识聚合和迁移相结合的跨领域推荐算法ATCF(Aggregation and Transfer Collaborative Filtering algorithm)[8],通过基于矩阵分解的矩阵拼接和矩阵填充方法,有效避免了负迁移.上述方法考虑了用户对源域项目评分,忽略了评论文档可以更好的挖掘偏好信息这一特性.
多视角深度神经网络学习方法MVDNN(Multi-View Deep Neural Network)[9]将用户和项目的评论信息映射到一个潜在空间,最大化了用户和喜欢的项目之间的相似度;基于联合张量因子分解的评论跨域推荐模型RB-JTF(Review-Based cross-domain recommendation through Joint Tensor Factorization)[10]提出了一个辅助域和目标域的联合张量分解模型,利用评论文本中提取的方面因子来提高跨域推荐的性能;基于内容的深度融合模型R-DFM(Review and content based Deep Fusion Model)[11]使用融合评论的堆叠式去噪自动编码器来训练源域和目标域中的用户或项目因素,然后利用多层感知器将其在两个域之间传递,从而提高冷启动用户推荐性能;通过方面转换为冷启动用户提供跨域推荐模型CATN(Cross-domain recommendation framework via Aspect Transfer Network)[12]使用Aspects[13]以及注意力[14,15]机制提取用户和项目的方面,并且增加了相似用户的评论作为辅助文档增强推荐的准确率.以上这些方法虽然使用了评论文档作为辅助信息,提高了推荐的准确度,但其使用的深度模型不能准确地区分出用户的细粒度偏好,并且只使用了单一源域,故这些方法的推荐准确度不高.
用户对项目的评论信息可以反映出用户对项目多个层面的评价,项目表现出的多个层面即“方面”[13].方面能反映用户评论对项目属性的情感程度,将“方面”引入跨域推荐模型能够更好的进行知识迁移.胶囊网络[16~18]将神经网络中的神经元扩展成神经向量,并用胶囊来表示,胶囊的长度代表属性的概率,而胶囊的方向代表了这个属性的具体描述,通过这一特性就可以保存评论文档中的用户和项目方面.胶囊网络的动态路由机制可以选择性的聚集一些低层的胶囊(属性),进而生成高层的胶囊(属性),这些特性都使胶囊网络比其他神经网络对空间和语序更加敏感.此外,胶囊网络的动态路由机制与神经网络的反向传播机制不同,仅通过少量迭代就可以获得较好的结果.以上这些特性说明,胶囊网络可以更好地挖掘文本的细粒度特征.
基于以上背景,本文提出了一个基于方面和胶囊网络的跨域评分预测模型:ACN.为了更好的学习跨域知识,本文将一对相关数据集设定互为源域和目标域,交替进行学习训练.本文主要贡献总结如下:
(1)基于胶囊网络可以挖掘细粒度偏好这一特性,本文使用胶囊网络挖掘评论文档、提取用户和项目的方面,并且通过基于方面的自注意力机制,获取对于用户和项目表示中更重要的方面.
(2)本文将胶囊网络的映射矩阵修改为共享矩阵,使路由过程输出的每个偏好胶囊都位于同一个向量空间中,保证迁移到目标域的方面处在同一向量空间.
(3)本文使用不同类型的源域输入模型进行实验,证明了在数据稀疏和冷启动的前提下,ACN可以学习并迁移不同源域、多源域的知识.
2 模型结构
本文提出的ACN模型结构如图1所示.ACN设置为一个双塔结构网络,分别用来处理用户评论文档和项目评论文档,最后通过知识迁移层将从源域中获取的偏好迁移到目标域,从而预测用户对项目的评分.

图1 ACN模型结构
ACN模型分为四层:(1)初始胶囊层:将评论文档嵌入表示,经过一次卷积操作初步提取文本特征,将评论向量转化为初始化胶囊.(2)主胶囊层:将初始化的胶囊输入胶囊网络,通过迭代路由过程挖掘用户或项目的方面.(3)方面注意力层:将输出胶囊进行方面注意力表示,针对不同源域的侧重点筛选出不同的方面.(4)知识迁移层:将两个域的方面表示匹配,进行最终的评分预测.由于用户网络与项目网络结构相同,故下文主要以用户网络为例进行详细介绍.
ACN模型中主要用到的符号及其含义如表1所示.
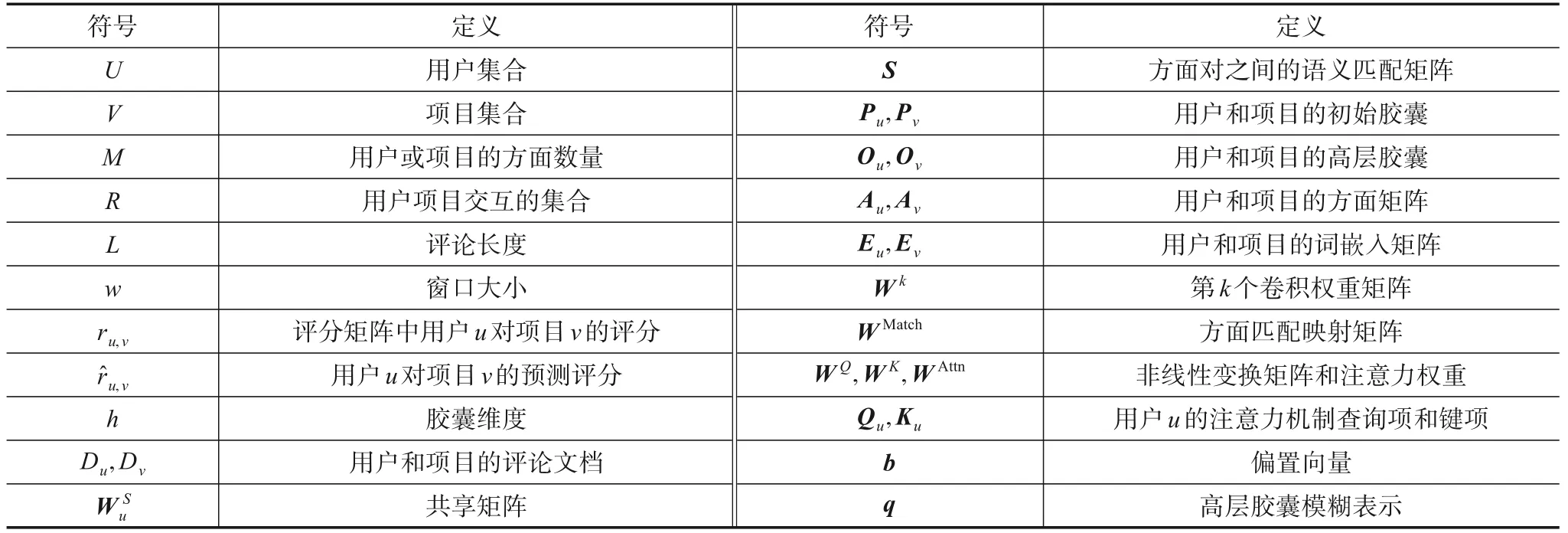
表1 模型符号定义
2.1 初始胶囊层
以用户u为例,将u在源域的评论文档定义为Du∈RL,其中每一项代表用户评论文档中的单词索引,L是评论长度.将Du进行词嵌入后得到词嵌入矩阵Eu=[e1…eg…eL],其中eg∈Rd代表第g个词的维度为d的嵌入向量.将Eu经过一次一维卷积,并初始化为胶囊网络的输入胶囊矩阵.
选用n个宽度为d,窗口大小为w1的卷积核来提取文本特征,构成初始化胶囊,则第k个卷积核对Eu的卷积操作定义为:

其中*代表一维卷积,Wk是第k个卷积权重矩阵,bk是第k个卷积偏置.将n个卷积核卷积结果进行拼接,得到L-w1+1个维度为n的初始化胶囊Pu=[p1…pk…pL-w1+1],其中pk∈Rn代表第k个初始化胶囊.
2.2 主胶囊层
将初始化胶囊输入到胶囊网络作为低层胶囊,首先对低层胶囊进行特征映射,预测高层胶囊在偏好空间的位置.由于使用不同的映射矩阵会将胶囊映射到不同的偏好空间,导致高层胶囊存在于不同空间,影响最终的知识迁移过程,当使用的源域与目标域不相关或者使用多个源域时,这种影响尤为严重.本文在每对低层胶囊和高层胶囊之间使用路由全局共享的映射矩阵,将用户或项目的每个低层胶囊映射到相同的向量空间,得到高层胶囊的模糊表示qi.

其中pi代表第i个低层胶囊,W S u是共享映射矩阵,代表低层胶囊和高层胶囊的联系.
得到qi后,对其进行动态路由过程.首先通过低层胶囊和高层胶囊之间的连接权重cij加权计算高层胶囊的候选向量sj,连接权重cij可以在动态路由过程通过bij计算得出.
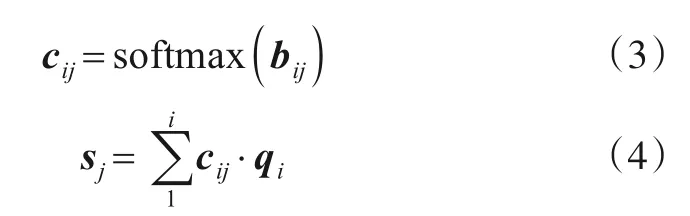
其中bij表示每对低层胶囊和高层胶囊之间的一致性分数,初始值为0.
将高层胶囊的候选向量sj经过非线性squash函数,得到标准化的高层胶囊.
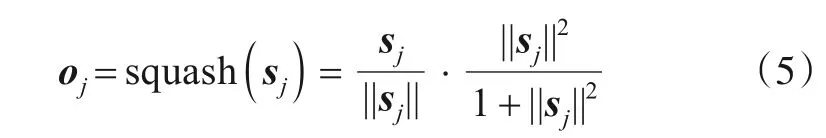
squash函数第一项的作用是将sj单位化,即将sj压缩到[0,1],第二项是一个大于0小于1的值,分母中的数字代表函数的挤压程度,当||sj||2大于挤压程度时,第二项则会大于0.5,表示该胶囊代表的特征存在几率大,而当||sj||2小于挤压程度时,第二项则会小于0.5,表示该胶囊代表的特征存在几率小.这样可以放大sj的重要部分,缩小sj的不重要部分.
最后,在动态路由的每次迭代中,bij通过以下公式进行更新:
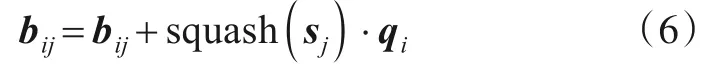
动态路由过程收敛后,胶囊网络输出M个高层胶囊ok∈Re,k∈{1,2,…,M},它们组成了用户u的胶囊矩阵Ou,代表了用户u的M个方面的偏好特征.

2.3 方面注意力层
用户在不同的领域会关注不同的方面,只有突出用户在源域中更加关注的方面才能对模型的学习更有帮助,因此需要将用户更加关注的方面赋予更高权重.
以用户u为例,使用缩放点积注意力计算每个胶囊对每个方面的注意力权重,并对胶囊进行自注意力加权.通过共享参数非线性变换矩阵将胶囊矩阵投影到同一空间,得到注意力机制查询项Qu和键项Ku.其中WQ,WK∈Rd×d为非线性变换矩阵,ReLU是非线性映射激活函数.
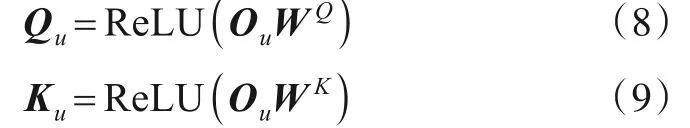
然后,通过查询项和键项计算胶囊的注意力权重WAttn,使用胶囊维度开方对注意力进行缩放,可以避免查询项和键项之间产生较高的匹配分数,影响结果.

最后,通过注意力权重对胶囊矩阵Ou进行加权,计算出用户u对应的方面矩阵Au.

同理,将项目ν在目标域的评论文档输入模型的前三层,可以获得项目ν对应的方面矩阵Aν.
2.4 知识迁移层
评论文档经过模型的前三层,就得到了用户u和项目ν的方面矩阵Au和Aν,在知识迁移层中,将Au和Aν中两个方面之间进行语义匹配来计算用户u对项目ν的预测评分.
首先计算Au和Aν之间每个方面对之间的语义匹配,公式如下:

其中WMatch是方面匹配映射矩阵,它编码了源域中每个方面和目标域中每个方面之间偏好迁移的重要性.Sp,q反映了相应方面对(p,q)之间的匹配程度.
最后,将S中每一对语义匹配求和并取其平均值,考虑到用户和项目偏置,计算最终的预测评分,公式定义如下:
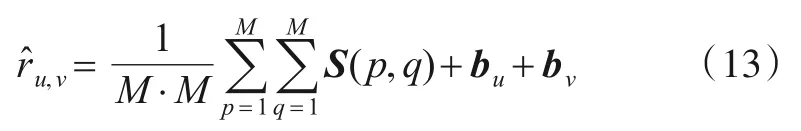
其中,bu是用户偏置项,bν是项目偏置项.
2.5 训练及优化
本文将ACN模型训练过程的损失函数定义为:
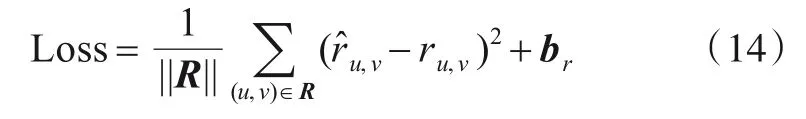
其中br是评分偏置项.为了更好地学习跨域迁移知识,本文设置一对相关领域互为源域和目标域,在训练过程中依次执行两个学习流程.本文采用Adam[19]优化器对损失函数进行优化,Adam优化器可以在训练过程中自动调整各个参数的学习速率,并且比普通的SGD优化器更准确、收敛更快.
3 实验
3.1 数据集和评估标准
在 本 文 的 实 验 中,使 用Amazon5-cores[20]中 的Book、Movie(Movies and TV)和Music(CDs and Vinyl)三个彼此相关以及Toy(Toys and Games)、Tool(Tools and Improvement)和Beauty三个彼此不相关的数据集.每个数据集中包含用户编号、项目编号、用户对项目的评分、用户对项目的评论、评论投票等9种数据类型,本文使用用户编号、项目编号、评论和评分4种数据类型.各个数据集统计如表2所示.
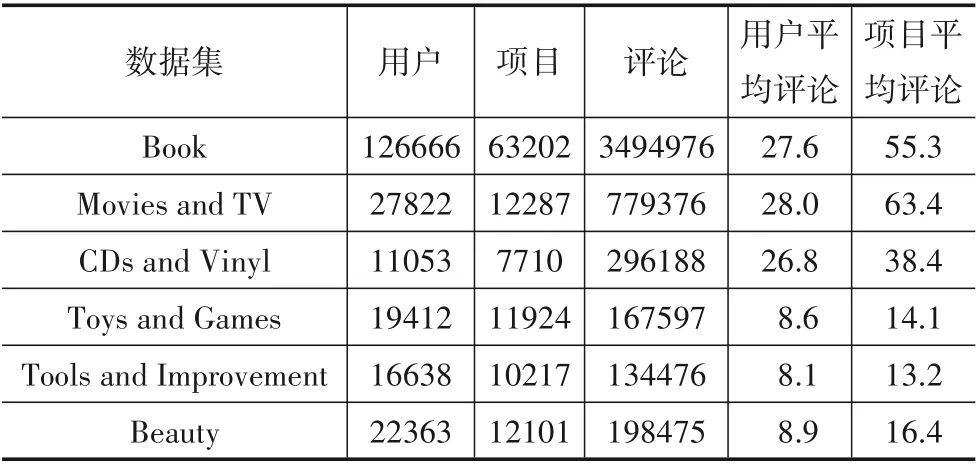
表2 数据集统计
由于跨域推荐模型能够缓解数据稀疏所引起的冷启动问题,本节在源域和目标域的重叠用户中,随机选择50%的用户作为推荐系统的冷启动用户,在模型验证和测试过程均不需要他们在目标域中的交互历史(测试集包含30%,验证集包含20%),并将剩下的50%的重叠用户用于模型训练过程,实验中训练集、测试集和验证集的比值为5:3:2.
本文除了将ACN模型与基准模型进行纵向对比,还将重叠用户以η∈{100%,50%,20%,10%,5%}的比例构建训练集,将本文模型和基准模型同时在这五种比例的数据集中进行训练,并将结果进行横向对比,证明ACN缓解数据稀疏引起冷启动问题的有效性.
在实验过程中以MSE(均方误差)作为模型实验效果的评判标准,MSE越低,模型性能越高.MSE的公式定义如下:
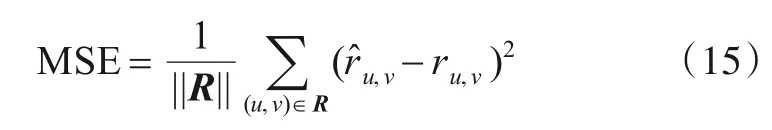
为了验证模型的有效性,实验选取以下5个基准模型与ACN进行对比:
(1)CMF[5]:对源域和目标域均进行因子分解,在因子之间共享参数来实现跨域推荐.
(2)EMCDR[6]:使用多层感知机学习不同域间的非线性映射函数,并且将源域知识迁移给目标域来生成推荐.
(3)R-DFM[11]:使用堆叠式去噪自动编码器来挖掘源域和目标域的特征,然后利用多层感知器将其在两个域之间传递.
(4)CATN[12]:通过方面门机制提取用户和项目的方面,并且增加用户辅助文档的最新跨域推荐模型.
(5)ANR[21]:挖掘用户和项目方面的最新单域推荐模型.本文使其直接在目标域中参与实验.
3.2 模型对比
本文将Book、Movie和Music三个数据集两两组合,分别组成三对源域和目标域(分别是Book->Movie、Movie->Music和Book->Music),对应三个跨域推荐任务.本节在这三个跨域推荐任务中对本文模型ACN以及基准模型进行了对照试验,实验结果如表3所示.

表3 各模型实验结果对比
基于矩阵分解方面建模方法(如CMF),CMF通过对源域和目标域中的评分矩阵进行矩阵分解来学习用户和项目的特征,但忽略了其他有用的信息,故其迁移给目标域的知识不够完整,所以在基准模型中性能是最差的.ACN模型在知识迁移层也是矩阵相乘,但这两个矩阵并非原始矩阵分解而来,而是通过胶囊网络分别对卷积得到的用户和项目这两个矩阵进行处理,而且在ACN模型中矩阵相乘的目的并非为了还原原始矩阵并得到原始矩阵中的丢失值,而是为了迁移到目标域进行评分预测,这与矩阵分解本质上是不同的.EMCDR使用了多层感知机捕获源域和目标域之间的非线性映射,效果比CMF使用的矩阵分解要好,但还是没有利用到其他辅助信息,故与其他模型相比性能较差;R-DFM扩展了堆叠式降噪自动编码器,并且将评论文本和项目描述内容与评分矩阵相融合,在学习到的用户和项目的潜在因素中保留了更多的语义信息,但自动编码器并不能准确地提取出文本中的细粒度特征,故在一些数据集上甚至不如仅使用评分矩阵的两个模型,在其他数据集中的表现也并不是最好的;ANR(Aspect-based Neural Recommender)使用注意力机制对评论文档进行方面表示学习,在目标域的评论文档中可以挖掘到对推荐有重要作用的信息,在单域和跨域模型中均有较好的效果,但其挖掘到的特征并不完整,且当用户在目标域冷启动时,就无法从目标域中提取出相关用户的偏好;CATN是目前最新的跨域推荐模型,它使用方面门以及注意力机制提取用户和项目的方面,并且为冷启动用户额外增加了辅助文档,挖掘出的偏好更加完整,性能在本文选取的基准模型中最好,但CATN方面提取的方法是通过反向传播对模型进行更新,没有引入其他监督信息,导致挖掘出的偏好容易产生过拟合,并且CATN没有考虑到多源域评论文档对目标域推荐的影响;ACN在三个推荐任务中的性能均高于其他模型,且在三个推荐任务中相对于性能最高的基准模型获得了2.3%、0.8%和2.2%的提升.
仅通过纵向与基准模型对比不能充分体现出ACN缓解数据稀疏引起冷启动问题的能力,因此本节将模型在每个推荐任务上的效果进行横向对比.如图2所示.
通过图2可以看出,在数据逐渐稀疏的情况下,基准模型EMCDR、R-DFM和CATN的MSE大幅上升,而本 文 模 型ACN在Book->Movie和Book->Music上 的MSE涨幅明显小于以上三个基准模型,并且涨幅与基准模型CMF以及ANR基本一致.产生这样效果的原因是CMF仅使用评分数据作为模型输入,而ANR则是单域推荐模型,其效果与重叠用户的稀疏度无关.证明了ACN缓解冷启动问题的有效性.

图2 推荐性能随用户数的变化
综上表明ACN可以更准确地挖掘用户和项目的方面,并且可以将在源域中学习到的知识迁移到目标域,能更有效地提高冷启动用户在目标域预测评分的准确率.
3.3 不相关源域对模型效果的影响
本节将Toy、Tool和Beauty这3个不相关的数据集组成三对源域和目标域(Toy->Tool、Toy->Beauty和Tool->Beauty),对应于三个跨域推荐任务.将本文模型ACN、CATN以及ANR依次在三个跨域推荐任务中进行对照试验,证明ACN使用不相关的源域和目标域进行迁移信息的有效性.实验结果统计如图3所示.
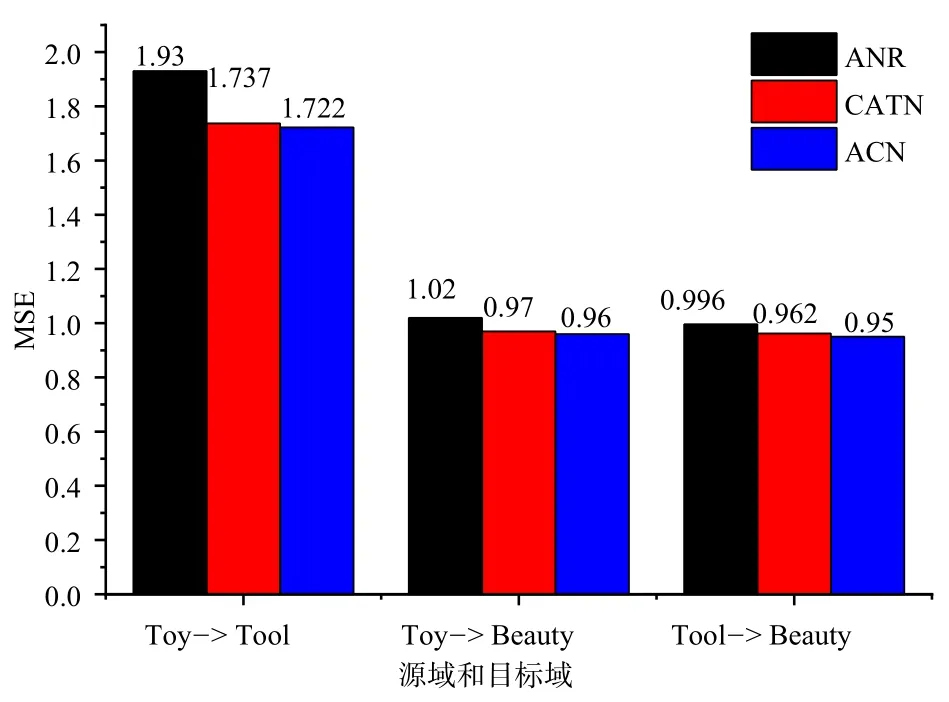
图3 使用与目标域不相关源域时模型的性能
ACN使用与目标域不相关的数据集作为源域时,在三个推荐任务上的性能均高于单域推荐模型ANR,并且性能表现略强于跨域推荐模型CATN.实验结果一方面证明ACN在使用不相关源域评论文档时,仍然可以挖掘出有用的信息并迁移给目标域,提升推荐的准确度.另一方面通过与ANR的性能对比,证明ACN可以有效缓解用户在目标域冷启动的问题.
3.4 多源域ACN
本节对ACN在单一源域和多个源域进行训练时的性能差异进行比较.本节将三个相关的数据集(Book、Music和Movie)和三个不相关的数据集(Toy、Tool和Beauty)进行组合,形成两个跨域推荐任务:Book+Movie->Music和Toy+Tool->Beauty,并在这两个推荐任务上对ACN模型进行训练,将实验结果与ACN使用单一源域时的性能进行对比,实验结果如图4和图5所示.
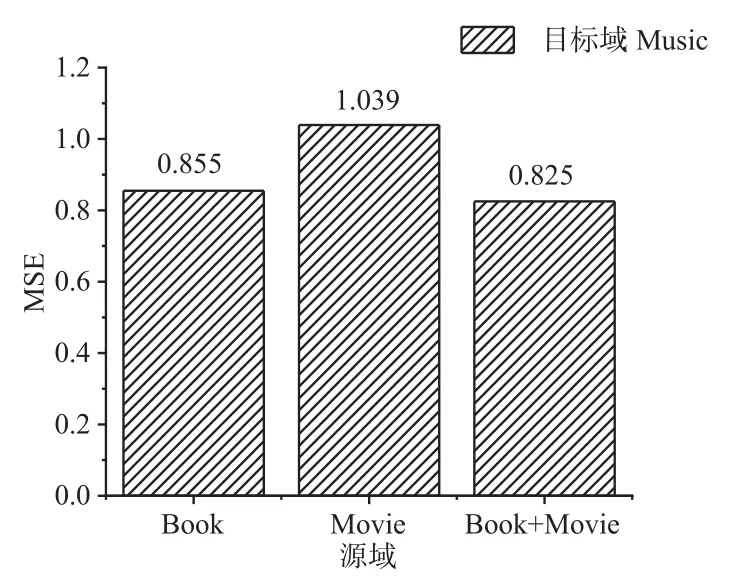
图4 相关多源域和单源域实验结果对比
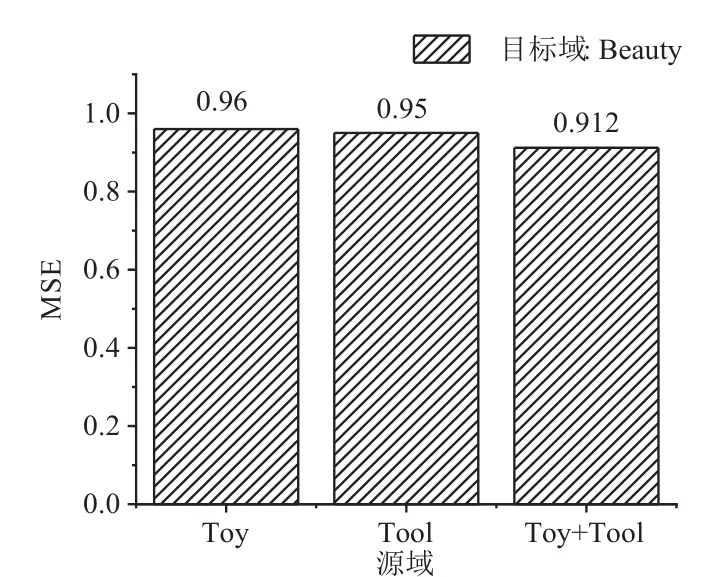
图5 不相关多源域和单源域实验结果对比
从图4可以看出,ACN使用多个源域进行跨域推荐的效果远远好于使用单个源域的效果.当目标域是Music时,ACN使用Book与Movie的多源域比使用单源域的性能提高了3.5%和20.6%;当目标域是Beauty时,ACN使用Toy和Tool的多源域比使用单源域的性能提高了5.0%和4.0%.这说明无论源域与目标域的类别相关或是不相关,使用多个源域都可以大幅度提升模型的性能.与3.2节的实验对比,使用多源域的ACN比使用单源域的CATN性能提高了4.3%和20.8%.本节实验证明了ACN不仅可以迁移多个相关源域的知识到目标域,增强用户偏好的偏好信息,当源域与目标域不相关时,还可以通过整合从多个源域中学习到的知识,提高目标域推荐的准确度.
3.5 消融实验
为了验证ACN模型使用胶囊网络挖掘评论文档多个方面以及通过自注意力机制筛选特征的合理性,使用ACN的两个子模型进行消融试验,两个子模型定义如下:
ACN-cnn:将ACN模型的卷积胶囊层替换为一次卷积和池化操作的CNN,用于证明胶囊网络可以更有效的挖掘评论文档的多个方面.
ACN-noattn:去掉ACN的自注意力机制,注意力权重用维度相同数值全是1的矩阵代替,用于证明自注意力机制能够更好的筛选出对目标领域最重要的特征.
将ACN-cnn和ACN-noattn在Movie->Music数据集上,重叠用户以100%,50%,20%,10%,5%的比例进行实验,并与ACN模型进行对比,实验结果如表4所示.
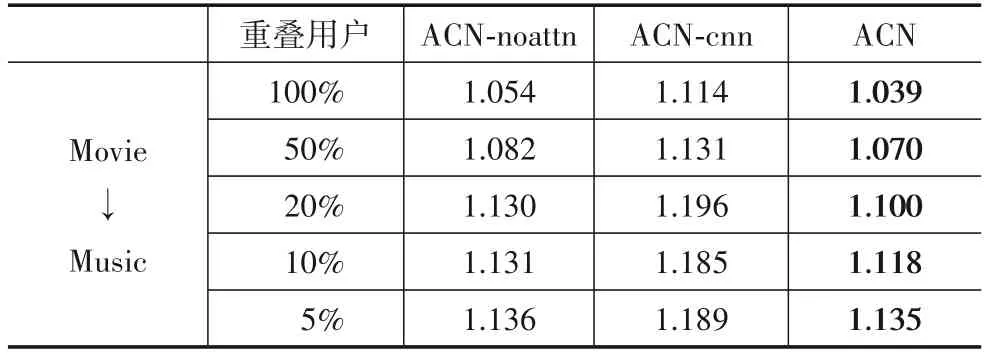
表4 各模型实验结果对比
首先,使用胶囊网络和自注意机制的ACN模型的性能高于使用CNN和自注意力机制的ACN-cnn模型,说明胶囊网络能够更好地挖掘评论文档的多个方面,而且ACN模型的性能也要优于使用胶囊网络的ACNnoattn模型,这说明自注意力机制能够更好的筛选出对目标领域最重要的特征.其次,使用胶囊网络的ACNnoattn模型明显要好于使用自注意力机制的ACN-cnn模型,即不使用胶囊网络模型效果下降的更多,说明ACN模型中胶囊网络比自注意力机制更为重要.纵向来看,在数据逐渐稀疏的情况下,ACN-noattn的MSE要明显低于ACN-cnn的MSE,这说明胶囊网络能够更好的应对数据稀疏引起的冷启动问题,从而我们模型在面对冷启动问题上表现得更好.
4 结论
本文提出了一个基于方面和胶囊网络的跨域评分预测模型ACN,使用胶囊网络挖掘源域和目标域中的用户或项目方面.为了更好地契合跨域推荐任务,本文设置了全局共享映射矩阵来表示低层胶囊和高层胶囊之间的映射关系,使模型能更准确地迁移并融合从源域和目标域挖掘出的方面.经过与各种基准模型的实验对比,证明了本文的ACN模型可以更准确地提取并迁移评论文档中的特征,并且提升评分预测的准确率.此外,通过ACN使用不相关源域与其他基准模型的对比实验,证明ACN使用与目标域不相关的源域,仍可以学习到有用的信息.本文还将多个源域进行组合并对照试验,证明了与单个源域相比,多个源域可以提升模型的性能.
在未来的工作中考虑通过其他上下文信息完善模型对推荐结果的可解释性.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
重庆大学学报(2022年6期)2022-06-23
客联(2022年3期)2022-05-31
读报参考(2022年1期)2022-04-25
汽车实用技术(2021年17期)2021-09-23
客联(2021年2期)2021-09-10
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2021年9期)2021-05-12
科学家(2021年24期)2021-04-25
