
基于At-LSTM的产品创新特征识别
2022-11-08 10:48黄训江
东北大学学报(自然科学版) 2022年10期
闫 康,黄训江,张 强,王 登
(1.东北大学 工商管理学院,辽宁 沈阳 110169;2.安徽美芝制冷设备有限公司,安徽 合肥 230088)
海量在线评论数据中蕴含了丰富的有关用户对产品特征的情感偏好、产品质量等信息,识别和挖掘用户对产品的需求偏好信息,并据此改进和创新产品,成为生产企业的核心竞争力所在.已有众多学者从语法关联[1]、情感偏好[2-3]等方面对在线评论中产品特征需求挖掘进行了研究,但由于在线评论数据冗余并且数据集成质量较低,同时CNN(convolutional neural network),RNN(recurrent neural network)等深度学习方法多存在上下文信息缺乏、梯度消失或爆炸等缺点[4-5],在利用在线评论研究消费者需求偏好上存在诸多不足,并且针对整条评论的情感分类不能有效分析某一方面属性的情感倾向.基于此,本文构建了基于注意力机制的LSTM(long short term mamery)用户产品特征偏好识别模型,更加有效、精准地提取用户对产品各项特征粒度更细的需求偏好信息.针对用户需求特点,对传统Kano模型添加特征覆盖程度指标,更好地融合蕴含用户细粒度情感偏好的产品特征,进一步对所识别出的用户需求信息进行层次化处理.
1 相关研究
基于在线评论的产品特征提取研究主要有两类.一是基于统计方法的产品特征提取:Wang等[6]应用启发式规则和语义词典分析产品特征之间的近似关系,Li等[7]使用点互信息提取产品特征,但基于统计方法的产品特征提取效果不佳且可移植性较差.二是基于机器学习的产品特征提取:Jin等[8]在隐马尔可夫模型框架下提出将词性信息与词汇化技术相结合的混合标注方法,Wan等[9]根据中文在线评论语法结构,归纳特征与观点的关联,作为先验知识添加到LDA(latent dirichlet allocation)中,在特征词和观点词的提取上取得了更好的准确率和召回率.基于机器学习的产品特征提取,在一定程度上克服了基于统计方法的不足,提高了特征提取的效率.
用户对产品特征存在着不同的情感偏好,Sharma等[10]基于SentiWordNet词典计算评价词的情感倾向,Viegas等[11]进一步提出了基于嵌入词语义关系的词典扩展策略,在很大程度上克服了词汇覆盖的主要问题,但仍然存在无法考虑上下文语境、结果稳健性不好等缺陷.基于机器学习的情感分类弥补了情感词典的缺陷,Giachanou等[12]基于点互信息(pointwise mutual information,PMI)判定互联网网络信息对利益实体的正负面影响.深度学习是在机器学习基础上延伸出来的算法模型,在文本处理等诸多领域取得了优异的效果.Yang等[13]通过词嵌入实现了基于卷积神经网络的微博评论句子级情感分类.Song等[14]将注意力机制与RNN相融合,通过多通道卷积网络的设计提取局部语义特征来实现文本分类.Mohammed等[15]将CNN,LSTM和RCNN(region-CNN)用于阿拉伯语语言情景下的情感分析,结果表明LSTM的分类效果优于CNN和RCNN.Yu等[16]提出了面向目标的多模态BERT(TomBERT)体系结构,在Twitter数据集上验证了该方法在检测目标情绪上的有效性.
既有研究尚存在粒度粗以致不能明确特征的情感倾向等问题,且所识别的产品特征未予考虑其对用户需求满足程度的不同.本文通过基于注意力机制的LSTM模型的构建,尝试从细粒度情感分类角度提取在线评论中的产品特征及其用户情感偏好,结合Kano模型[17]对所提取的产品特征用户需求层次类型进行划分,将在线评论所蕴含的用户需求信息转入产品的改进与创新过程之中,推动企业产品更有效地满足市场需求,提升企业的市场竞争能力.
2 模型设计
本文构建了一个基于At-LSTM的产品创新特征识别流程框架模型,从在线评论语句中准确识别出不同用户偏好的产品特征,为产品创新改进提供决策支持.该框架模型主要由数据采集处理、评论筛选及产品特征识别、情感分类及基于Kano模型的需求分析和优化四部分组成,如图1所示.

图1 基于At-LSTM的产品创新特征识别流程
首先,利用网络爬虫获取评论数据并剔除噪音数据.对评论文本进行分句、分词、词性标注、词频统计及剔除不相关词汇.其次,结合产品文档及情感词典计算语料集词语与种子词语义相似度,合并相关同义词汇形成产品特征词库与情感词库.通过词库对有用性评论进行筛选,以增强产品特征需求识别的精准程度.再次,在对注意力机制、LSTM神经网络既有研究分析的基础上,构建了基于注意力机制的LSTM情感识别模型,用以预测在线评论数据集中产品特征的情感倾向,整理并形成各品牌特征的细粒度情感数据.最后,在对Kano模型重新定义和改进的基础上,将相关产品特征指标及模型预测结果与Kano模型相关联,分析各特征对用户需求的满足程度,进而提出具体详尽的产品创新改进建议.
2.1 模型基础结构
2.1.1 注意力机制
注意力机制通过学习参数赋予句子中重要信息更多的权重,旨在学习单词与特定任务的关联程度.其基本思想是计算每个标记的注意力分数并相应地调整输入向量,主要分为三个阶段:第一阶段,引入向量点积、余弦相似性等函数方法计算查询(q)和键(k)之间的相关性;第二阶段,引入Softmax函数以归一化第一阶段生成的数值w,见式(1),并将其转换为概率分布,以凸显重要成分的权重,第i个位置元素的权重系数用ai表示,见式(2);第三阶段将权重系数和相应位置的值进行加权求和,计算结果即为注意力值,见式(3).
wi=f(ki,qi),
(1)
(2)
Attention=∑iαivi.
(3)
2.1.2 LSTM神经网络
LSTM采用多个细胞单元从嵌入向量中提取情感信息,每个单元分别由输入门、遗忘门和输出门组成,通过Sigmoid函数和逐点相乘的操作来控制和更新信息.对于任一词向量xt∈Rm,m为向量空间维度,X={x1,x2,…,xn}为评论文本向量集合,则LSTM用于文本情感分类流程为:第一步信息通过遗忘门,然后决定需要保留哪些信息,决定上一时刻输出st-1和细胞单元状态ct-1是否会存储到当前的细胞单元状态ct中;第二步输入门将决定进入单元状态ct的信息量,从而更新当前时刻的输入xt,首先让信息经过Sigmoid层决定哪些需要更新,然后让其经过tanh层生成一个向量,作为下一步需要更新的内容,实现细胞单元状态的更新;第三步输出门控制细胞单元状态ct的输出量,通过Sigmoid层进行信息过滤处理,以筛选出细胞单元状态中部分信息输出,将输出的细胞状态ct经过tanh层处理,并与Sigmoid层输出相乘,得到有选择性的部分输出st.
2.2 基于注意力机制的LSTM情感模型构建
LSTM在情感分类中已有诸多应用[18-21],但粒度较粗.LSTM根据时间序列按顺序计算文本特征,远程相互依赖的特征则需要多次积累信息才能进行关联,依赖特征间距越远捕获的概率越小,而注意力机制不仅能考虑句子的不同方面,还能捕捉句子的重要部分,通过计算将句子中的任何两个单词关联起来,可以更为有效地利用文本中的重要信息特征来实现文本分类.基于此,本文提出一种面向句子中词语结构的自我注意力机制,以捕获句子中相互关联且间距较长的特征.
1)输入层.假设评论文本中包含n个词汇,用[w1,w2,…,wn]表示.将词汇转换成数值向量,从而得到文本输入矩阵Rn×d,n为词汇数量,d为词向量维度.
2)注意力机制层.得到词向量后输入到注意力机制层,利用注意力编码器使词向量与随机初始化的权重相乘创建查询向量(q)、键向量(k)和值向量(v).通过查询向量与键向量的点积来计算词注意力分数,分数决定了一个句子对某个位置词语进行编码时,在输入句子其他部分上需要投入的关注程度为
(4)
其中:αi为注意力分数;d为向量的维度.最后将注意力机制分数与值向量v加权得到各单词的输出值zi.
3)LSTM层.输入向量zi,LSTM层生成了一系列的隐藏状态hi∈Rn×dh,n为任意一条语句中单词个数,dh是隐藏状态的向量维度,来学习句子和目标词的隐含语义.
4)Dropout层.在全连接层之前,神经网络的学习能力随着神经元数量的增加而增加,同时,学习率越高,机器学习能力越强,但网络易于发生过拟合现象,故随机剔除神经网络中部分神经元以解决过拟合问题,提高模型的泛化能力.
5)全连接层.全连接层连接LSTM层输出的隐藏状态hi,根据LSTM神经网络分类原理,得到si作为文本语句特征向量表示,则任意一条文本特征向量表示为si=[h1,h2,…,hn].
6)输出层.将特征向量si输入到Softmax分类器中,输出对该文本情感分类的预测概率,得到模型文本情感分类的结果为
y=Softmax(wlsi+bl).
(5)
其中:wl∈Rc×d和bl∈Rc×d分别为相应的权重和偏置向量;c和d分别代表情感分类的类别和LSTM层中隐藏状态的向量维度.LSTM以最小化交叉熵损失为训练目标,利用L2正则化函数训练模型,如式(6)所示:
(6)
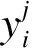
2.3 基于Kano模型的产品需求分类与优化
为充分挖掘用户需求层次信息,在已有产品特征频率、情感系数等需求分类指标的基础上,添加特征覆盖程度指标,把产品特征需求划分为魅力需求、期望需求、基本需求、无变化需求和反向需求这五类.产品特征频率(Fi)、特征覆盖程度(Ci)及产品特征情感系数(Ei)计算公式分别为
(7)
(8)
(9)
(10)

表1 基于Kano模型的需求分类
魅力需求是指超过消费者预期的产品特征,具有较低的产品特征频率和特征覆盖度,得以满足时,正向情感系数远大于负向情感系数.期望需求具有较高的产品特征频率和特征覆盖度,其情感系数随产品特征满足消费者预期程度而变化.基本需求一般具有较低的特征频率和较高的特征覆盖度,其情感系数亦随产品特征对用户期望的满足程度而变化.无变化需求是指具备与否都不会引起消费者情绪变化的产品特征,具有较低的产品特征频率和特征覆盖度,负向情感系数与正向情感系数近似相等.反向需求是其性能提升会引起用户强烈不满的产品特征,故其负向情感系数远大于正向情感系数,具有较低的特征覆盖度和特征频率.根据上述指标将产品特征分类到不同的需求类别中,分析消费者不同需求满足程度,并通过鱼骨图排查问题的原因,为产品创新改进提供参考.
3 实验结果及分析
综合考虑产品上市时间、价格、以及销量等因素,选择华为、Vivo、Oppo、小米四大品牌手机作为研究对象,在淘宝和京东平台上爬取评论共14 493条.
3.1 有用评论筛选
分句后共获得短文本评论108 013条,进行分词、去停用词、词性标注等工作.词频统计后选取词频大于20的名词及名词短语进行剪枝处理,构成初始产品特征词库,剪枝策略为:①不具有属性特征的名词;②人工识别难以特征分类的名词.通过相似度扩充产品特征词集,结合手机技术参数及Zhang等[22]的研究,确定出消费者最关注的网络、电池、价格、外观、音质、系统、配件、屏幕、像素、性能及服务11个产品属性维度,聚类整合后构成最终特征词库,依据此方法构建情感词库.对评论数据进行筛选后得到有效评论20 716条,标注筛选后的评论6 248条,以7∶3的比例随机分为训练集和测试集对模型进行训练.选择CBOW算法,向量维度为100,上下文窗口为5,最小词频为10,采样阈值为1×10-3,迭代次数为5,Workers数量为4.
3.2 At-LSTM模型实验结果及分析
3.2.1 参数选择及性能评价
经过迭代训练,选择了以下几种不同结构类型的模型分类器,各个参数具体数值如表2所示.使用网格搜索方法来确定最优参数组合,以测试集准确率为评判标准,获得各个参数值组合下模型分类的准确率,对结果进行比对,当参数Batch_size=9,Epoch=16,Dropout=0.090时,测试集准确率最高,模型的分类效果最好.

表2 参数及数值
选择K近邻(KNN)、支持向量机(SVM)、朴素贝叶斯(NB)以及长短时记忆网络(LSTM)四种较为典型的学习算法,利用准确率、精确率和召回率三个指标作对比分析,结果如表3所示.

表3 不同模型性能比较
3.2.2 情感分类
利用训练好的At-LSTM模型,预测未标注的数据集的情感倾向.结合产品特征词表,计算出各个品牌中包含各个特征的正负情感语句数量.设定阈值10,筛选出包含特征情感倾向数量较少的语句,最后整理得到各品牌中细粒度情感倾向语句数量.以oppo手机为例,各特征情感语句数如表4所示,整体上的情感更倾向于负向情感,仅网速、待机时间、外观三个特征呈现出正向趋势.

表4 特征情感文本数量
3.3 基于Kano模型的需求分析与优化
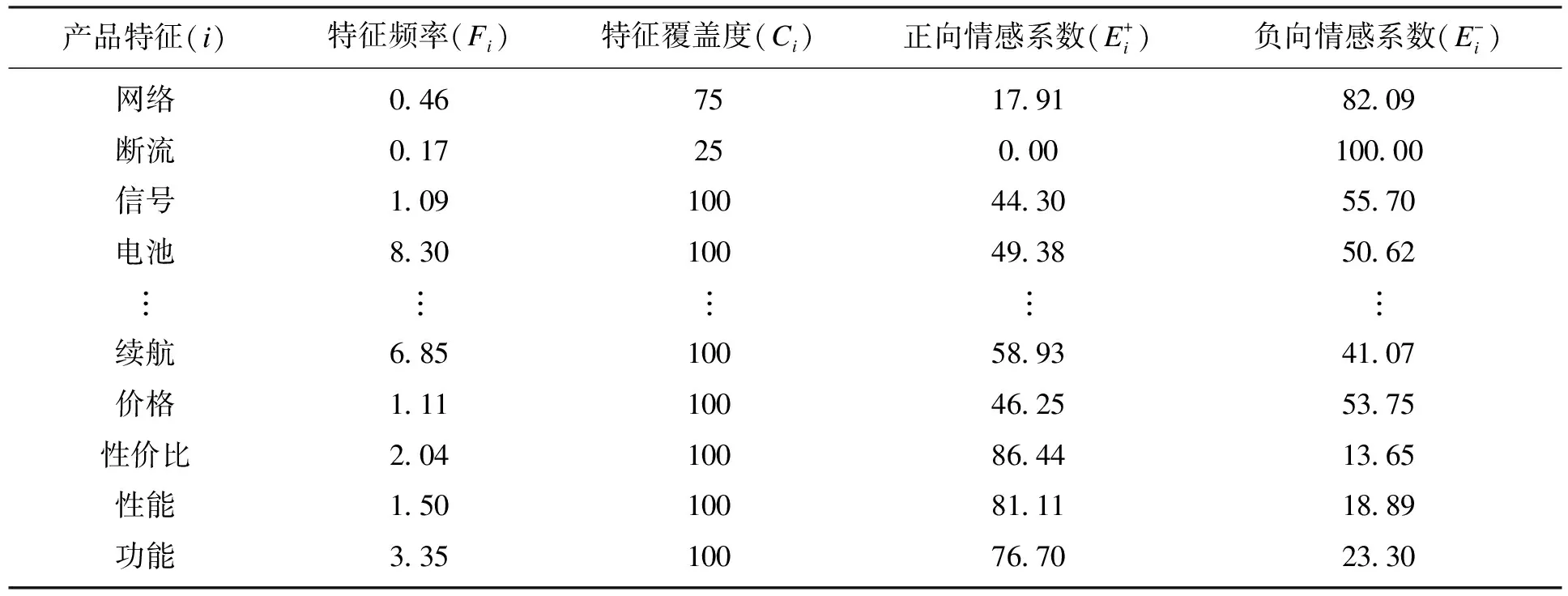
表5 产品特征需求分类系数表


图2 期望需求、魅力需求中产品特征问题
手机在线评论数据的实验结果表明了本文所构建的At-LSTM模型对细粒度产品创新特征识别的有效性.能够以较高的性能实现在线评论细粒度特征情感分类,同时在Kano模型中添加了特征覆盖程度指标,能够将特征属性匹配到不同的需求类别,进而能够分析其对用户预期的满足程度.与鱼骨图的结合便利了对用户需求问题根源的探寻,为产品的优化设计提供了具体的改进方向.
4 结 语
为从海量的购物评论中精准地挖掘出人们对商品某一特征方面的需求偏好,本文构建了基于At-LSTM模型的产品创新特征识别流程框架模型,改良了评论有用性筛选方法.构建的基于注意力机制的LSTM情感分类模型的准确率、精确率和召回率分别为91.52%,91.73%,91.53%,相较KNN,NB,SVM等模型均有所提升.进一步结合Kano模型,将产品特征划分为不同的需求类别,据此分析出没有满足消费预期的产品特征,并列出鱼骨图分析具体相关原因,为产品创新优化指明方向.本文在虚假评论筛选、Kano模型阈值设置等方面尚有待改进之处,未来,在对虚假评论予以剔除的同时,应考虑阈值设定对产品特征用户需求分类的影响,以便提供一种更广泛和稳健的方法.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
甘肃教育(2020年22期)2020-04-13
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
