
一种基于目标函数的局部离群点检测方法
2022-11-08 11:18朱文豪孙红玉
东北大学学报(自然科学版) 2022年10期
周 玉, 朱文豪, 孙红玉
(华北水利水电大学 电力学院,河南 郑州 450011)
离群点是偏离大部分数据较远的点,它常被怀疑由不同的机制产生[1].根据数据对象的数量可以分为单独离群点和集体离群点;根据数据类型可以分为矢量离群点、序列离群点、轨迹离群点和图形离群点等[2].离群点检测在数据处理中占有重要地位,它旨在找出数据集中的偏远数据,是当下研究的热点.其在欺诈检测[3]、入侵检测[4]、公共安全[5]、图像处理[6]和目标跟踪[7]等方面已经有了广泛应用,其检测方法大致为基于统计、基于距离、基于密度和基于聚类等方法[8-9].
Breuing等提出了局部离群因子的概念LOF(local outlier factor)[10-11],这种方法基于密度给离群点赋予了离群因子,定量地描述了离群点的离群程度,其不再将离群点看作一个二值属性.在没有明确数据分布的情况下依然能准确发现离群点,由于其需要逐个查找数据点的邻域,计算数据点的离群因子,这就使得此方法的计算量巨大.随后,在此基础上出现了很多改进的方法,例如文献[12]提出的NLOF(new LOF)算法,通过聚类算法DBSCAN(density-based spatial clustering of applications with noise)对数据集进行剪枝处理,得到初步的异常数据集,然后利用LOF算法计算初步异常数据集中对象的局部异常程度,提高了离群点检测精度.但此算法中DBSCAN聚类需要人为输入的参数过多且敏感度较大,面对未知数据集时,在参数设置方面存在较大问题.同样,文献[13]也提出了类似的用DBSCAN对数据集进行预处理的检测方法,这种方法分为两个阶段.第一阶段,为了减少参数输入,用k近邻的个数代替Minpts并通过k近邻确定聚类半径,通过改进的DBSCAN对混合数据进行初步筛选,一定程度减小了计算量;然后利用新构造的LAOF(LOF based on the area density)计算筛选后数据的离群程度,为了表征不同属性的贡献度,在距离度量中采用除一化信息熵差对属性加权,并在第二阶段进行二次权重确定,提高了检测精度,但这种方法和NLOF存在同样的问题.文献[14]使用EWT(empirical wavelet transform)方法对原始热工过程时间序列的运行趋势进行去除后,使用LOF算法得到该序列中的异常值点,避免了判断阈值不易直接给出的问题,在动态和稳态过程中均具有适用性,但是,k距离和箱型图截断点系数β的选择对结果的敏感度较大,并且此方法只适用于一维数据的检测.文献[15]从定义出发,提出基于聚类的局部离群点的概念,解释了局部的定义,即小聚类在宏观上可以看作离它最近的大聚类的局部,给出倍数β作为大小聚类的判别.通过新的局部概念,提出了CBLOF(cluster-based local outlier factor)的计算公式,计算得到每一个数据点的局部离群因子来表征离群程度,但这种方法对数据集并未进行预处理,计算复杂度十分高,面对大规模数据集不具备处理能力且用参数β来判别大小聚类并不精确.
针对上述问题,本文提出了一种新的基于目标函数的局部离群点检测方法.①在进行检测之前,对数据集进行预处理,由于使用FCM(fuzzy C-means),为了有较好的聚类效果,因此使用肘部法则确定最佳聚类个数;②FCM的目标函数是根据距离求和的,拿走一个点,它的值必然会减小,而拿走离聚类中心较远的点,它的值减小幅度就会更大,通过减小的幅度来大概判断一个点的离群可能性,将大部分正常数据去除,剪枝得到初步的离群点集,这是本文最大的贡献,相比于其他剪枝方法更精确;③每一维特征对数据集的贡献度不同,采用属性熵来表征每一维特征的离散程度,熵越大,离散程度越大,此维特征所占的权值越大,用传统的LOF方法得出每一维的异常值得分,加权得到每个数据最终的异常得分,将其顺序排列,值越大的离群程度越大.经过实验对比验证,结果显示该方法能提高检测精度,改善聚类效果,实现有效的离群点检测.
1 预备知识
1.1 FCM算法
FCM算法属于划分聚类算法,聚类之后相同簇对象之间相似度最大,不同簇对象之间相似度最小是FCM的主要思想[16].FCM已成为聚类分析的主流[17],其在图像处理[18]、海水深度预测[19]、故障诊断[20]等方面有广泛应用.
设有样本集X={x1,x2,…,xn},c为聚类中心个数,m为模糊权重指数,隶属度为uij(i=1,2,…,c;j=1,2,…,n).其中uij∈[0,1],聚类中心为V={V1,V2,…,Vc},算法目标函数为
(1)
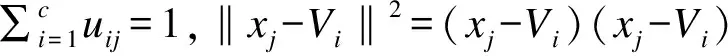
步骤1 参数初始化,输入聚类中心个数c(2≤c≤n),停止阈值ε,模糊权重指数m,选取初始聚类中心.V(b)={V1,V2,…,Vc},迭代计数器b=0.
步骤2 用式(2)计算并更新划分矩阵U(b):
(2)

步骤3 用式(3)更新聚类中心矩阵V(b+1):
(3)
步骤4 如果‖V(b)-V(b+1)‖<ε,则聚类停止,输出U和V,否则b=b+1,转向步骤2.该算法迭代终止后,数据对象的模糊划分由模糊隶属度矩阵U体现.
1.2 局部离群点检测算法LOF
LOF算法用离群因子定量地描述每一个数据对象的离群程度,其没有全局计算数据点的密度,而是通过k邻域计算得到数据点的局部可达密度,因此其中表征离群程度的量被称为 “局部”异常因子[21].传统LOF算法需要明确以下几个定义.
1)d(p,o):点p与点o之间的距离.
2)第k距离(k-distance):p的第k距离为p到其周围第k远的点的距离,但不包括p.
3)第k距离邻域(k-distance neighborhood ofp):与点p的距离不超过其第k距离的所有点,包括第k距离上的点所组成的点集为p的第k距离邻域Nk(p).因此p的第k邻域点的个数Nk(p)≥k.
4)可达距离(reach-distance):点o到点p的第k可达距离为
reach-distancek(p,o)=max{k-distance(o),d(p,o)}.
(4)
即点o到点p的第k可达距离为o的第k距离和op间真实距离的最大值.
5)局部可达密度(local reachability density):点p的局部可达密度表示为
(5)
6)局部离群因子(local outlier factor):点p的局部离群因子表示为
(6)
LOF检测算法有较大的缺点,它需要计算每一个数据的离群因子,包括数据集中的正常数据,因此产生了很多无效计算,增加了计算量,并且其对未知数据集检测效果一般,直接用其进行离群点检测不可取.因此,本文提出了一种基于目标函数的局部离群点检测方法,用于改进传统LOF检测算法的性能.
1.3 肘部法则
聚类算法对聚类个数c的选取将直接影响算法的聚类效果.肘部法则将不同c值的成本函数值刻画出来,每个簇包含的样本数会随着c值的增大而减少,样本会更靠近其聚类中心,代价函数(式(7))随之减小.但随着c继续增大,代价函数的减小幅度不断下降,直至代价函数曲线趋于平稳.在c值增大过程中,代价函数减小幅度最大的位置就是肘部,使用这个c值一般可以取得很好的效果.
定义代价函数:
(7)
其中:c是聚类个数;N(i)是第i簇中的数据个数;Ci为第i个聚类中心.
2 基于目标函数的局部离群点检测方法
2.1 基于FCM目标函数的剪枝算法
在1.1和文献[22]的基础上,提出了一种新的剪枝方法,即基于FCM目标函数的剪枝算法.首先,执行FCM算法,生成一个目标函数和几个簇;然后,将数据个数少于簇平均个数的小簇视为离群簇,将其加入离群候选集;由式(1)得知,从数据集中移除某个点,必然会导致目标函数的减小,若移除的点偏离正常数据较远,也就是离群程度较高的话,目标函数值的减小程度会更大,由此判断数据的离群程度.
基于FCM目标函数的剪枝算法推导过程:
令式(1)中的xj-Vi=dij,表示第j个点到第i个聚类中心的距离,n表示数据集D的样本个数,若移除数据集D中的某个点,样本个数变为n-1,且某个点的移除对整个数据集的聚类中心几乎不产生影响,此时,FCM的目标函数变为
(8)
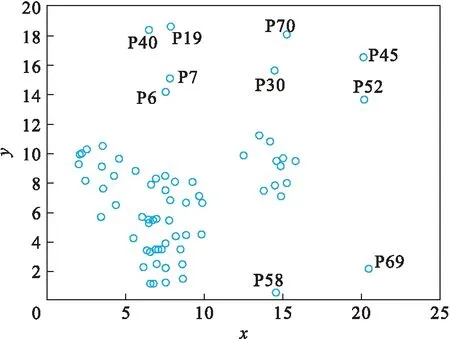
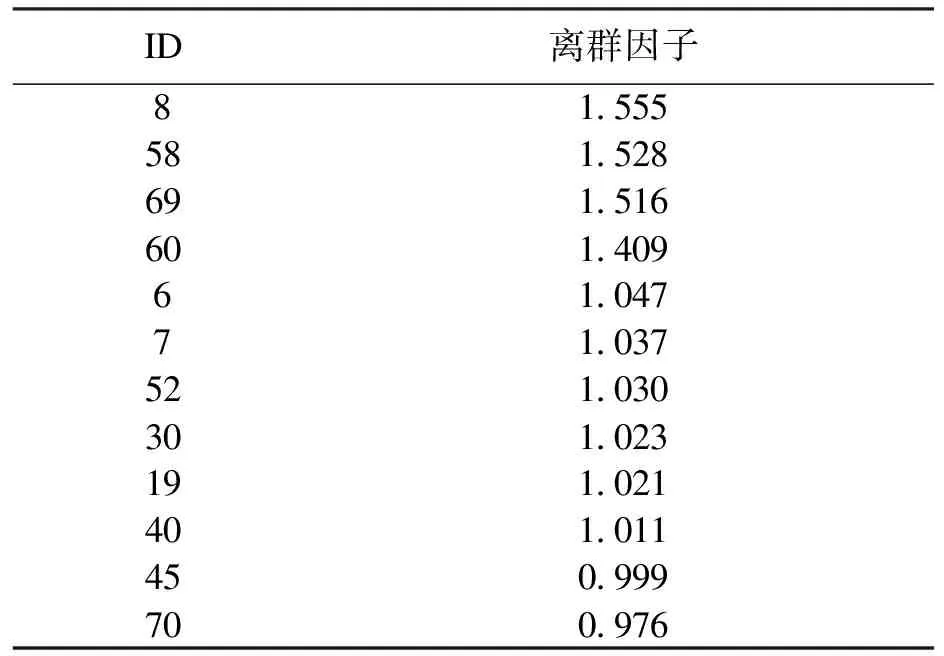
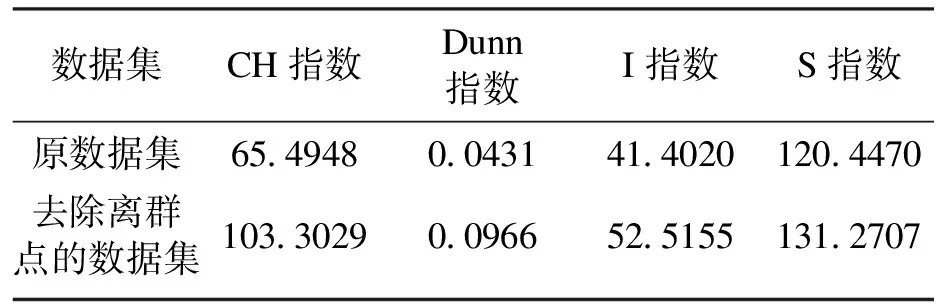
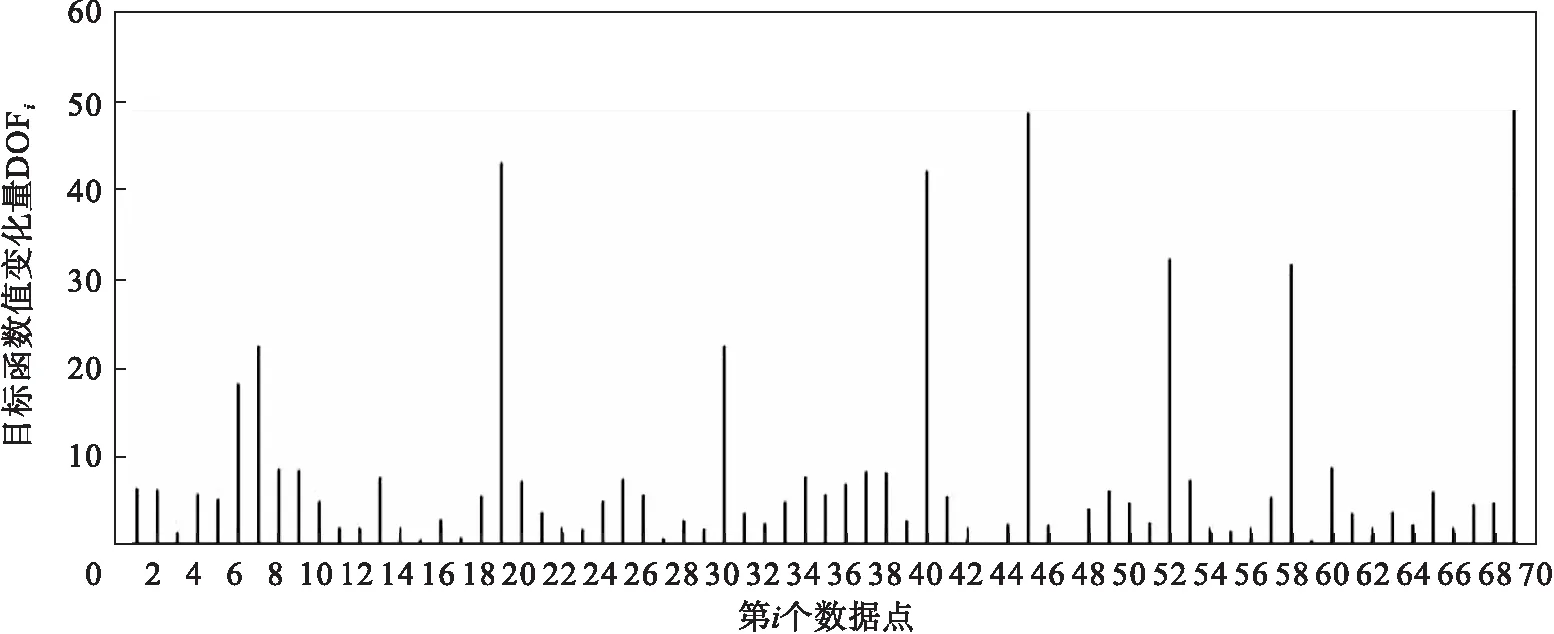
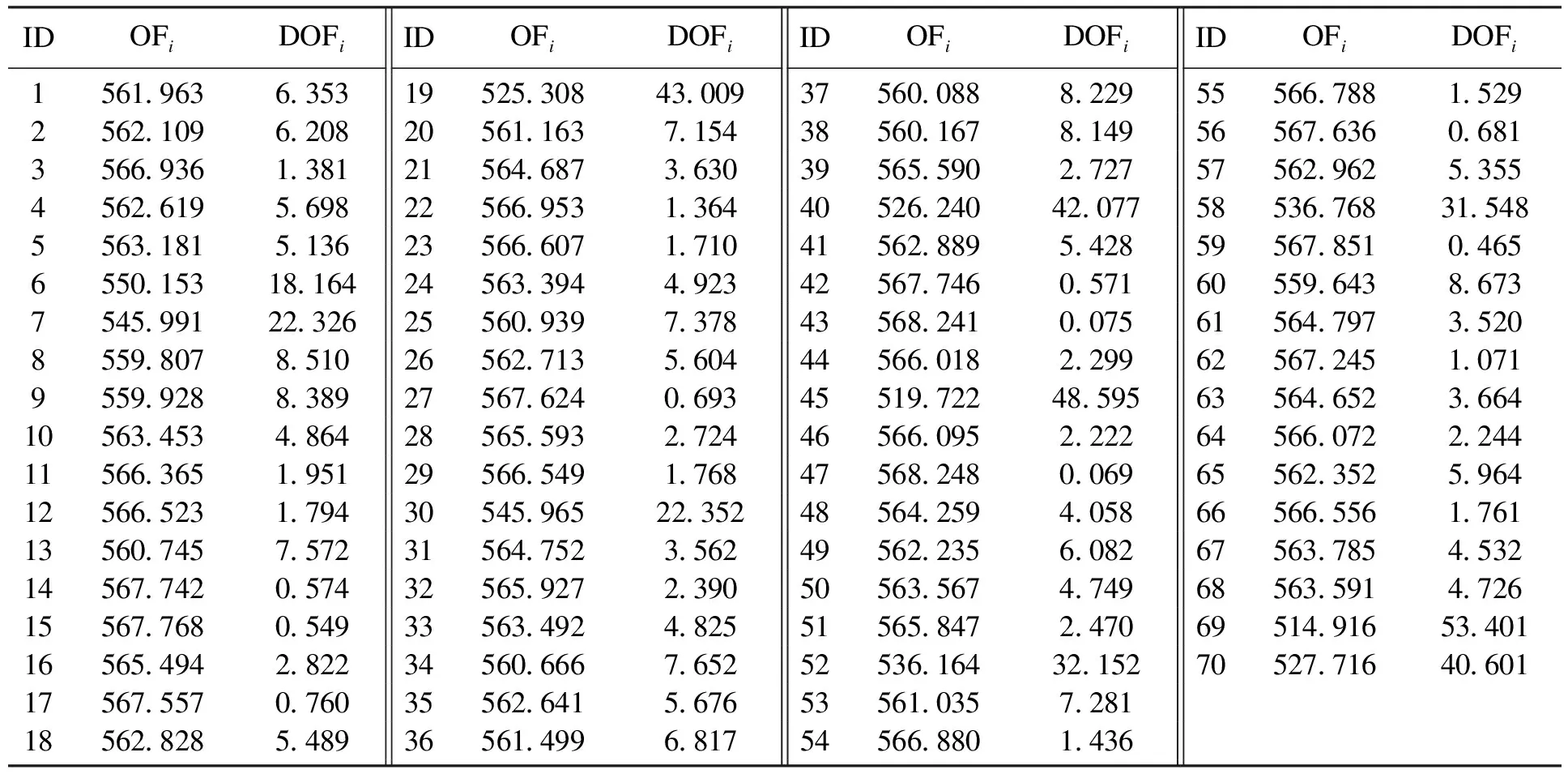
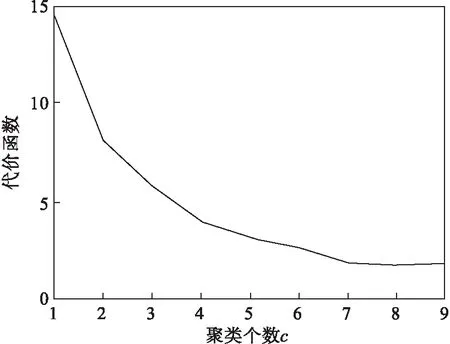
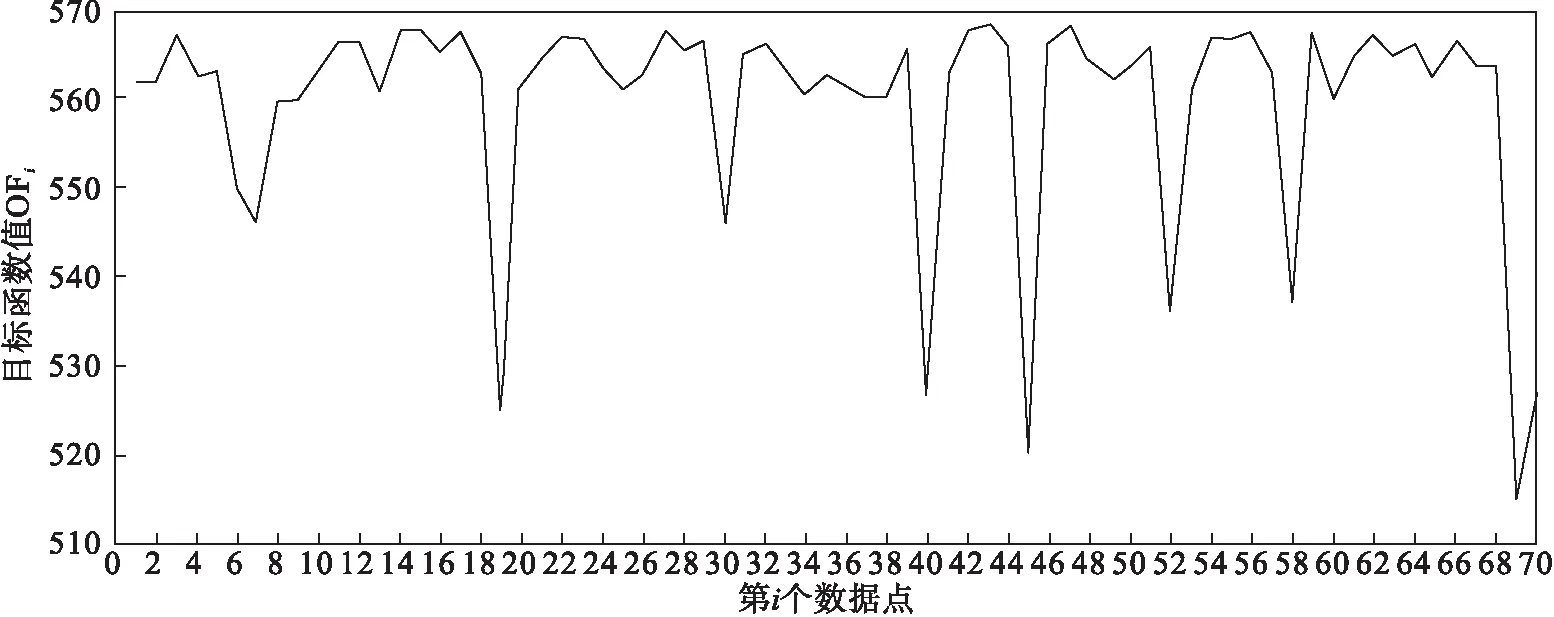
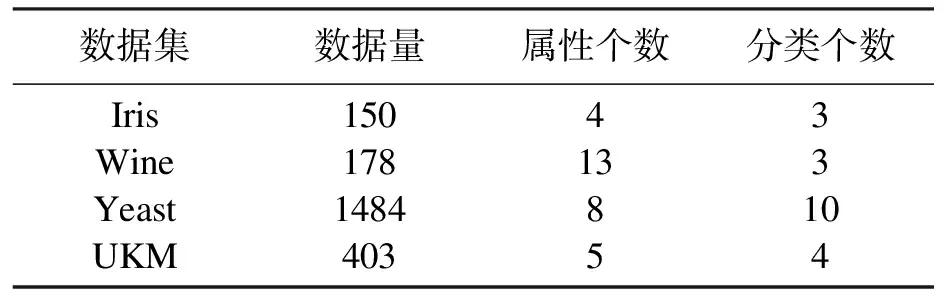
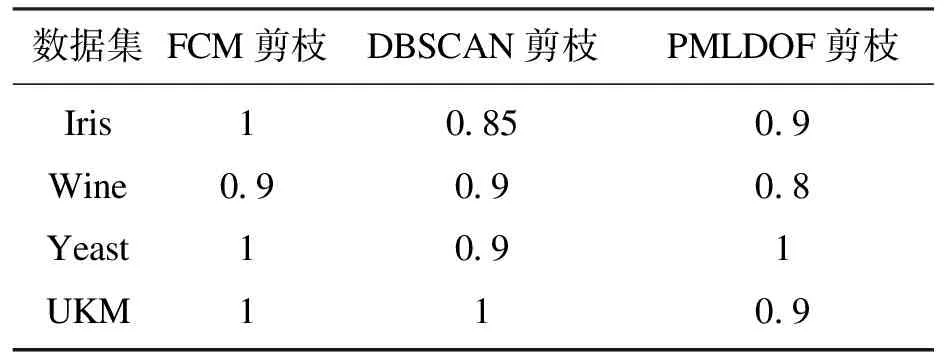
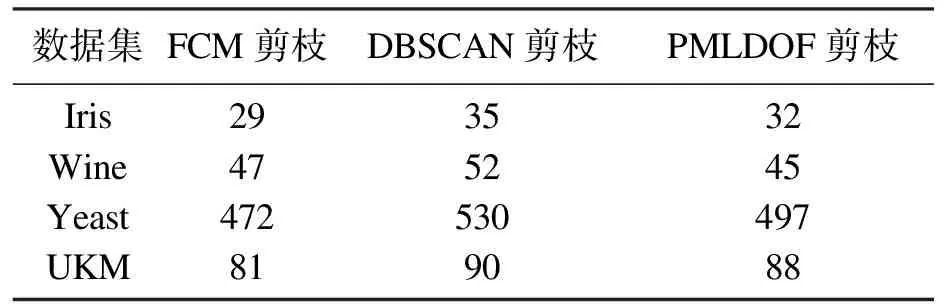
对比公式(1),只要移除数据集中的点,J0(u,c) 假设: (9) (10) 由于: Δ∑dij(outlier)≫Δ∑dij(normal). (11) 则 J1(u,c)≪J2(u,c). (12) 即 J-J1(u,c)≫J-J2(u,c). (13) 令: (14) 则 ΔJ(outlier)≫ΔJ(normal). (15) 即移除的点如果离群程度较大,其目标函数减少量会比正常数据大得多,运用此规律对数据集进行初步离群点筛选. 算法1 基于目标函数值剪枝算法. 输入:数据集D; 输出:离群候选集D0. 步骤1 对完整的数据集执行FCM算法,得到OF,并将小簇放入离群候选集; 步骤2 逐次移除剩余的点,得到所有的OFi,计算得到每一个DOFi和平均减少量AvgDOF; 步骤3 比较DOFi和T(AvgDOF),若DOF>T(AvgDOF),则将第i个点放入离群候选集. 信息熵常被用于表征数据的离散程度,熵值越大代表变量的离散程度越大,其提供的信息越少;熵值越小代表变量的离散程度越小,其提供的信息越多.因此数据不同维的特征提供的信息量不同,需要相应赋予不同的权值.对于熵大的属性,所占权重应该较高,这样可以将其离散程度更明显地体现出来. 算法2 加权LOF算法. 输入:数据集D; 输出:权值集合W={ω1,ω2,…,ωm},每个数据的异常值得分LOFi. 步骤1 对数据集D执行Z-score标准化得到D′,通过式(16)计算得到数据集D′中第i个数据的第j维属性的比重Pij: (16) 步骤2 用式(17)计算数据集D′中第j维属性的信息熵Ej: (17) 其中,p=1/lnn; 步骤3 用式(18)计算第j维属性的权值ωj: (18) 步骤4 利用熵权法对每一维属性赋权之后,再对每一维属性单独执行传统LOF算法,根据式(19)对其加权,获取最终的LOF值作为整体数据的异常得分. (19) 式中,LOFij表示第i个数据的第j维度LOF值. 算法3 基于目标函数的局部离群点检测算法. 输入:数据集D,邻域查询个数k,剪枝阈值T,离群点个数p; 输出:Topp个离群点. 步骤1 运用肘部法则确定数据集D的最佳聚类个数c; 步骤2 输入参数c,使用FCM算法对数据集D聚类,列出每一个数据移除后的目标函数值变化量并进行对比,依据剪枝阈值T(AvgDOFi),对数据集D剪枝得到离群候选集D0; 步骤3 在离群候选集D0中,利用式(16)~式(18)对每一维属性进行加权,之后用式(19)计算得到每一个数据的异常值得分LOF; 步骤4 将每个数据的LOF值按从大到小的顺序排列,输出前p个数据对象,组成数据集D的离群点集合. 传统的LOF算法在面对未知数据集,即不知道其数据分布,聚类个数等特征时检测效果十分不理想,并且由于其必须计算每一个数据点的离群程度,这又导致算法的计算量大大增加,FOLOF算法在这两方面做出了一定的改进. 在人工数据集和UCI数据库中选取Iris,Wine,Yeast和User Knowledge Modeling四个数据集,从聚类效果(CH指数,Dunn指数,I指数,S指数)[23]、准确度、误检率[24]等方面来验证所提出算法的可行性.前面部分提到的所有参数在下面实验中统一设置,剪枝时用到的阈值T取1,LOF算法和FOLOF算法中的邻域个数k取5. 为了可视化离群点检测的整个过程,首先利用人工数据集Dataset1来进行实验.该数据集共有70个数据点,包含10个离群点,分别是第6,7,19,30,40,45,52,58,69,70等点,如图1所示.先使用肘部法则确定最佳聚类个数,再剪枝得到离群候选集,运行加权LOF算法,将得出的离群值顺序排列. 图1 Dataset1数据集 如图2所示,当聚类个数从3变到4时,代价函数逐渐趋于平缓,所以最佳聚类个数c为3,运行剪枝算法,得到OF的值为568.317,Avg(DOFi)的值为8.431,将每一个DOFi都列于表1中,图3为移除第i个点后的目标函数值图,图4为移除第i个点后的目标函数值变化量针状图,与Avg(DOFi)进行对比,最终剪枝剩下第6,7,8,19,30,40,45,52,58,60,69,70等12个点将其放入离群候选集,候选集中包含所有离群点,剪枝精度为100%,运行加权LOF算法,将各点离群因子列于表2中,输出离群值最大的前10个点,分别为第8,58,69,60,6,7,52,30,19,40等10个点,其中有8个为真实离群点,移除所检测出来的离群点后,重新对数据集进行聚类,聚类效果提升,如表3所示. 表2 Dataset1离群候选集中各点离群因子(降序排列) 表3 Dataset1聚类指标对比 图4 移除第i个点后的目标函数值变化量 表1 目标函数值减少量对比 图2 代价函数衰减 图3 移除第i个点后的目标函数值 为了评估离群点检测的性能,采用准确度(precision,Pr)和误检率(noise factor,Nf)两个指标,分别用Pr和Nf表示.用TP表示算法检测到的真实离群点数量,用FP表示算法错将真实数据检测为离群点的数量,则 (20) 其中,Pr和Nf的最大值取1,最小值取0,Pr的取值越大,Nf的取值越小,算法性能越好.对于Dataset1的检测结果来说,TP=8,FP=2,计算得到,Pr=0.8,Nf=0.2,效果很好. 通过对比本文算法和LOF离群点检测算法在实际数据集中的运行结果来验证本文算法的性能,实验数据集如表4所示. 表4 实验数据统计 对每个数据集运行肘部法则确定最佳聚类个数,分别是3,3,10,4,最佳聚类个数与实际分类个数基本一致,提出的方法对未知数据集具有可行性. Iris数据集选取前两类数据作为正常数据,第三类中取10个数据作为离群数据.选取Wine数据集的前两类共130个数据点作为正常数据,第三类中随机选取8个数据作为离群数据.对于Yeast数据集,没有必要用到全部数据,选取CYT,NUC和MIT三个大类共1 136个数据作为正常数据,选取POX类共20个数据作为离群数据,另外,由于其第6维属性含有0值,在运行属性赋权算法计算比重时,不允许有0值的存在,则删除第6维属性,剩下其余7维属性进行离群点检测.对于UKM数据集,由于very_low中含有0值,则选取High,Middle两类共224个数据做为正常数据,Low中随机选取5个数据作为离群数据. 由剪枝精度,即剪枝后得到的离群候选集中真实离群点数量与整个数据集中的离群点数量的比值与剪枝后剩余数据量对比,结果证明FCM剪枝方法相比于DBSCAN剪枝方法、PMLDOF剪枝[25]方法具有比较明显的优势,如表5和表6所示. 表5 剪枝精度对比 表6 剪枝后剩余数据量对比 通过对比检测结果和移除所检测出的离群点之后的聚类效果,证明所提出的方法相比于LOF算法具有优势,实验结果如表7和表8所示,运行时间为t,单位s.算法采用MatlabR2016a编写,实验环境为:酷睿i5 2.90 GHz CPU,8.00 GB内存,Windows7操作系统. 表7 四种数据集检测结果对比 表8 四种数据集去除离群点前后聚类效果对比 经过仿真实验验证,本文提出的算法对未知数据集具有一定的处理能力,与传统的LOF算法相比在检测结果方面有明显提升.去除所检测出来的离群点后,重新对数据集聚类,聚类效果有明显改善,在进行检测之前先通过FCM进行了数据剪枝,减少了很大一部分计算量,相比于LOF算法,运行时间明显减少. 1)FOLOF算法通过肘部法则确定数据集的最佳聚类个数以达到最好的聚类效果,这使得其在面对未知数据集时具备更好的处理能力,而LOF算法在面对所有数据集时的处理方法全部一致即逐个计算离群因子,对不同的数据集缺乏针对性. 2)FOLOF算法通过FCM的目标函数变化量对数据集进行剪枝,得到初步的离群点集,这就在数据量方面大大降低了计算复杂度,而LOF算法并未对数据集进行预处理,会导致较大的计算量和较长的运行时间. 3)在输入参数方面,FOLOF算法只需要人为输入邻域查询个数k,剪枝阈值T和需要输出的离群点个数p,并且这些参数的设定不需要经过繁琐的实验过程,一般都采用经验值就能得到不错的检测效果. 4)在检测精度方面,FOLOF算法的检测精度高于LOF算法,其综合检测性能得到了提高. 本文提出一种基于目标函数的离群点检测方法FOLOF,首先,根据肘部法则确定最佳聚类个数;然后,利用目标函数对数据集进行剪枝;最后,采用加权LOF算法确定数据点的离群程度.相比于传统的LOF离群点检测算法,本文所提的方法在检测精度、检测效果以及检测速度等方面的性能均有明显提升.然而,该方法还需要在以下2个方面进行深入研究:阈值T的敏感度分析以及基于阈值T的离群点分类的研究,即研究出相应的方法实现强弱离群点的辨别;在FCM算法之外,其他聚类算法的目标函数是否可以用于剪枝及对剪枝结果有何种影响.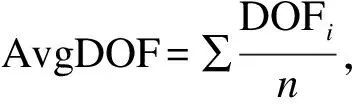
2.2 加权LOF算法
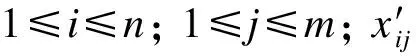
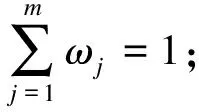
2.3 基于目标函数的局部离群点检测算法描述
3 实验对比
3.1 人工数据集
3.2 UCI数据集


3.3 分析讨论
4 结 语
猜你喜欢
计算机与现代化(2022年10期)2022-10-18
保健医苑(2022年5期)2022-06-10
小学生学习指导(低年级)(2021年9期)2021-10-14
成都信息工程大学学报(2021年6期)2021-02-12
计算机应用(2020年5期)2020-06-07
小学生学习指导(低年级)(2019年9期)2019-09-25
学生导报·东方少年(2019年27期)2019-01-14
小学生学习指导(低年级)(2018年9期)2018-09-26
诗选刊(2018年7期)2018-07-09
环球市场信息导报(2017年36期)2017-12-24
