
基于多尺度融合增强的服装图像解析方法
2022-11-07 05:39陈丽芳余恩婷
同济大学学报(自然科学版) 2022年10期
陈丽芳,余恩婷
(江南大学人工智能与计算机学院,江苏 无锡 214000)
随着服装和互联网行业的快速发展,服装图像解析作为图像处理的一个重要应用有着巨大的发展前景。服装图像解析的目标是对服装图像各个部分的组成进行像素级别的识别,将服装图像按照若干个类别划分为若干个区域。服装图像解析是计算机视觉中一项特定形式的细粒度分割。因此,服装图像解析研究对服装检索[1]、服装推荐[2]和服装合成[3]等领域的发展有着重要意义。Liu等[4]通过深度卷积网络来学习丰富的语义信息以克服不同的身体部位和服装间的语义模糊,同时采用不进行下采样的网络为小尺度对象保留分辨率和局部细节信息,并设计了一个桥梁模块在2个并行的网络间交换互补信息,从而提升网络解析性能。Luo等[5]利用对抗网络解决低级局部和高级语义的不一致性,该网络采用2个鉴别器,分别作用于低分辨率标签图和高分辨率标签映射的多个像素块,强制实现语义和局部的一致性,而且避免了处理高分辨率图像时对抗网络收敛性差的问题。Wang等[6]将以人体为中心的服装图像解析定义为一个基于人体结构的神经信息融合过程,并建立了结合直接推理、自顶向下推理和自底向上推理的3个层次推理的网络结构,可以明确地捕获人体的组成和分解关系,进而提高服装图像解析精度。Gong等[7]首先通过图内推理在一个数据集内的标签之间学习和传播特征信息,然后通过图间转移在多个数据集之间传输语义信息,分析和编码不同数据集之间全局语义一致性以增强图传递能力,实现多层次的解析任务。现有解析方法没有很好地解决服装类别丰富且尺度差异大等问题,导致服装图像解析效果有待提升。因此,提出一种多尺度融合增强网络,在充分发挥深度卷积网络中各个层次特征优势的基础上,利用通道注意力机制增强特征表达,从而提高服装图像解析效果。
1 相关工作
1.1 服装图像解析
服装图像解析在人工智能等领域具有广阔的应用前景。Chen等[8]将深度卷积网络提取到的多尺度特征输入到注意力模块,分别学习各个尺度特征在每个位置上的权重,输出不同信息重要性差异的权值图,然后将不同尺度的权值图分别乘以原始特征,调整不同像素对于不同类别的重要性。Zhao等[9]在利用金字塔结构获取多尺度特征的基础上,提出语义感知模块和边界感知模块,其中语义感知模块选择与类别相关的有区分性的特征,防止不相关的特征被合并到一起,而边界感知模块将多尺度特征与对象边界有效结合,实现精确的局部定位和部分区域间的准确识别。Luo等[10]设计了金字塔残留池结构以捕获全局和局部的上下文信息,利用一种可信指导多尺度监督方法,有效地整合和监督不同尺度的上下文信息,从而解决了人为误标标签时导致的标签解析混乱问题。
1.2 注意力机制
深度学习中的注意力机制源于人类视觉特性,当人类观察事物时,选择性地获取所观察事物的重要特征,忽略不重要特征。深度学习中的注意力机制借鉴了人类的视觉机制,旨在自适应地聚集有相关性的特征,帮助深度学习模型对输入的信息赋予不同的权重,获取更有用的特征,所以注意力机制被广泛应用于语义分割、目标识别和图像分类等计算机视觉领域。Hu等[11]提出通道注意力模块,从通道的维度学习特征的重要程度,选择性地提升对当前任务有用的特征并抑制对当前任务用处不大的特征。由于在特征提取时卷积操作经常把通道和空间信息混合在一起,因此模型效果仍然不够好。Woo等[12]在Hu等[11]提出的通道维度注意力机制的基础上,又提出了同时考虑通道和空间位置维度的混合注意力机制,进而有效地整合全局的上下文特征表达。与其他注意力机制不同的是,Wang等[13]通过自注意力模块Non-local计算任意2个位置之间的相互作用,直接捕获远距离依赖关系,然后将相关性作为权重表征其他位置和当前待计算位置的相似度。Hu等[14]定义了一个聚集算子,有效地聚合给定空间范围上的特征响应,同时设计一个激发算子调整聚合后的特征大小,并将其作为注意力特征重新分发给原始特征,从而以更轻量级的方式提升网络性能。
2 网络设计
2.1 网络结构
提出的多尺度融合增强网络结构如图1所示。首先,以步长为16的ResNet101[14]作为编码网络,提取多个层次的特征图,同时将Conv-1、Res-2、Res-3、Res-4和Res-5的输出依次表示为L4、L3、L2、L1和H1;其次,在解码网络中根据分辨率大小分为4个阶段进行解码,并且每个阶段都使用了如图2所示的融合增强模块(FEM),融合不同层次的语义和不同尺度的特征,从而提升预测结果精度;然后,将4个融合增强模块输出的特征图H5、H4、H3和H2串联拼接在一起,进一步细化特征对各个类别的感知能力;最后,通过线性插值、1×1卷积和argmax操作得到服装图像各个对象的解析结果。
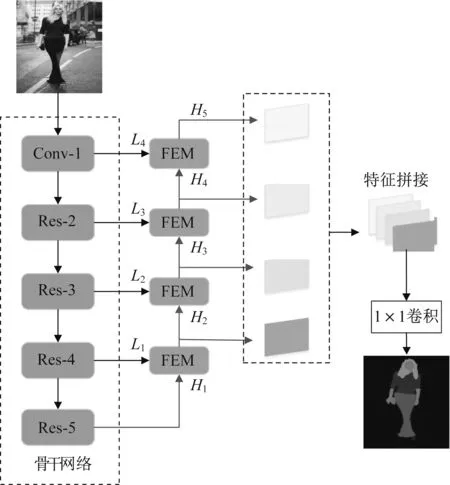
图1 多尺度融合增强网络结构Fig.1 Structure of multi-scale fusion enhanced network
2.2 融合增强模块
如图2所示,融合增强模块的输入来自编码网络跳跃连接的低层特征Li和解码网络的深层特征Hi。考虑到显存(2块8 GB显卡)的有限性,用1×1卷积将低层特征Li和深层特征Hi的通道维度均降低为256。为了融合不同层次的低层特征Li和深层特征Hi,先将深层特征Hi通过线性插值得到与低层特征Li相同的分辨率,然后将两者串联在一起。受文献[15]中用不同大小的感受野提取不同尺度特征信息的启发,用3×3、5×5和7×7卷积提取串联后的特征,分别得到特征图F33、F55和F77。将特征图F33、F55和F77串联在一起,并应用1×1卷积对其进行融合,进而增强网络对不同尺度服装对象的感知。虽然这种网络结构很好地提取了多尺度上下文信息,但是没有考虑全局信息,因此结合Hu等[11]提出的通道注意力机制,从全局角度对特征图进行优化。首先,对特征图F357进行全局池化和Sigmoid激活,形成大小为256×1×1的全局信息图;然后,通过乘法对全局信息图中3个不同尺度的特征图F33、F55和F77分别加权,从而起到强调重要信息、抑制无用信息的作用;最后,将3个加权后的不同尺度特征图进行串联拼接得到最终的输出特征Hi+1。

图2 融合增强模块Fig.2 Fusion enhancement module
3 实验结果与分析
3.1 实验设置
所有实验均是在2个NVIDIA GTX1070 GPU服 务 器 上 利 用Ubuntu18.04、Python3.6和Pytorch0.4.1搭建的深度学习框架。使用步长为16的预训练好的ResNet101[16]作为骨干网络。在训练和测试时采用的图像大小为320×320。初始学习率设置为0.003,并使用“Poly”学习率策略对学习率进行调整。在训练过程中采用随机梯度下降方法对网络进行训练,动量和权重衰减分别设置为0.9和0.000 5,同时采用随机的图像缩放(从0.5到1.5)、裁剪和左右翻转对数据进行增强。提出的多尺度融合增强网络采用标准的多类的交叉熵损失函数监督网络的学习,使网络预测结果不断接近真实值,在网络参数不断迭代更新过程中实现端到端的学习。
3.2 数据集
实验中使用的数据集是公共数据集Fashion Clothing数据集和LIP(Look Into Person)数据集。Fashion Clothing数 据 集 由Clothing Co-Parsing[17]、Fashionista[18]和Colorful Fashion Parsing Data[19]3个服装数据集组成。由于这些数据集有一些细微的差异,因此现有算法通常把这3个数据集的标签统一为18个类别,最后得到4 371幅像素级别标注的图像。LIP数据集[20]是包含20个类别50 462张图像的大型数据集,其中训练集包含30 462张图像,验证集包含10 000张图像,测试集包含10 000张图像。
在Fashion Clothing数据集中使用像素准确率、前景准确率、平均精确率、平均召回率和平均F1分数5个评价指标对网络性能进行评估。在LIP数据集中使用像素准确率、平均准确率、每个类别的交并比和平均交并比4个评价指标对网络性能进行评估。
3.3 消融实验
表1为各模块消融实验对比结果。√表示在多尺度融合增强网络中加入了此部分,×表示在多尺度融合增强网络中没有加入此部分。F357表示利用3×3、5×5和7×7卷积提取的多尺度特征图,GP表示加入了全局池化结构对特征图进行优化,C表示将4个融合增强模块(FEM)输出的特征图H2、H3、H4和H5串联在一起。从表1可以看出,在加入3×3、5×5和7×7卷积后卷积感受野变大,从而提取到更丰富的上下文信息,有效地解决服装图像目标尺度差异较大的问题。多尺度融合增强网络在加入全局池化结构后提高了模型的特征表达能力,使得解析准确率明显提升。最后,将4个融合增强模块输出的特征图H2、H3、H4和H5串联拼接在一起,进一步增强融合后的特征信息。同时,为了验证融合增强模块个数对网络性能的影响,在解码网络中从左到右使用了不同数量的融合增强模块并在表2中列出了实验结果。由表2可见,随着解码网络中使用的融合增强模块数量的增加,像素准确率、前景准确率、平均精确率、平均召回率和平均F1分数5个评价指标都有明显的提升,进一步验证了融合增强模块在增强模型特征表达和提升网络性能的有效性。

表1 各模块消融实验结果Tab.1 Results of ablation experiments for each module

表2 不同融合增强模块个数下实验结果Tab.2 Experimental results under different fusion enhancement modules
3.4 Fashion Clothing数据集上的性能对比
表3给出了多尺度融合增强网络与其他先进方法在Fashion Clothing数据集上的性能对比。从表3可以看出,多尺度融合增强网络与TGPNet(trusted guidance pyramid network)[10]和TPRR(typed partrelation reasoning)[21]相比,像素准确率、前景准确率、平均精确率、平均召回率和平均F1分数都有明显的提升。这主要是由于多尺度融合增强网络充分利用了编码过程中提取到的所有特征,增强了不同层次特征的信息表达,更适合纹理复杂、目标差异大的服装图像,因此提高了服装图像解析各个评价指标的值。为更清晰地展示多尺度融合增强网络在服装图像分割效果上的提升,在图3可视化了不同方法在Fashion Clothing数据集上的解析结果。从图3c可以看出,TGPNet[10]和TPRR[21]等方法都将半身裙错误地分割为连衣裙,只有本方法准确地解析出半身裙的整个轮廓,表明本方法可以更精准地区分易混淆的类别。从图3a和图3b可以看出,其他方法均没有关注到眼镜和腰带这种类别较小的目标,本方法却精确地分辩出小尺度的眼镜和腰带。因此,相比其他方法本方法可以给予尺度差异较大的目标对象均衡的关注,从而提升服装图像解析效果。

图3 不同方法在Fashion Clothing数据集上的解析结果对比Fig.3 Comparison of parsing results between different methods on Fashion Clothing dataset

表3 不同方法在Fashion Clothing数据集上的性能对比Tab.3 Comparison of performance between different methods on Fashion Clothing dataset
3.5 LIP数据集上的性能对比
为了进一步验证本方法的有效性和泛化性,表4给出了多尺度融合增强网络与其他方法在LIP数据集上的解析结果。从表4可以看出,多尺度融合增强网络与PGECNet相比,像素准确率、平均准确率和平均交并比3个评价指标分别提升了0.15%、1.14%和0.63%。表5给出了不同方法在LIP数据集上每个类别的交并比。从表5可以看出,多尺度融合增强网络对大部分服装类别的解析都得到了较高的精度,也表明本方法对于不同尺度的目标类别都是有效的。本方法的解析效果不仅在连衣裙、外套和连衣裤等较大的服装类别上有明显的提升,还在帽子、手套和眼镜等较小的服装类别上有明显的改善。因此,验证了多尺度融合增强网络在融合低层特征、深层特征以及增强特征表达方面的有效性。

表4 不同方法在LIP数据集上的性能对比Tab.4 Comparison of performance between different methods on LIP dataset
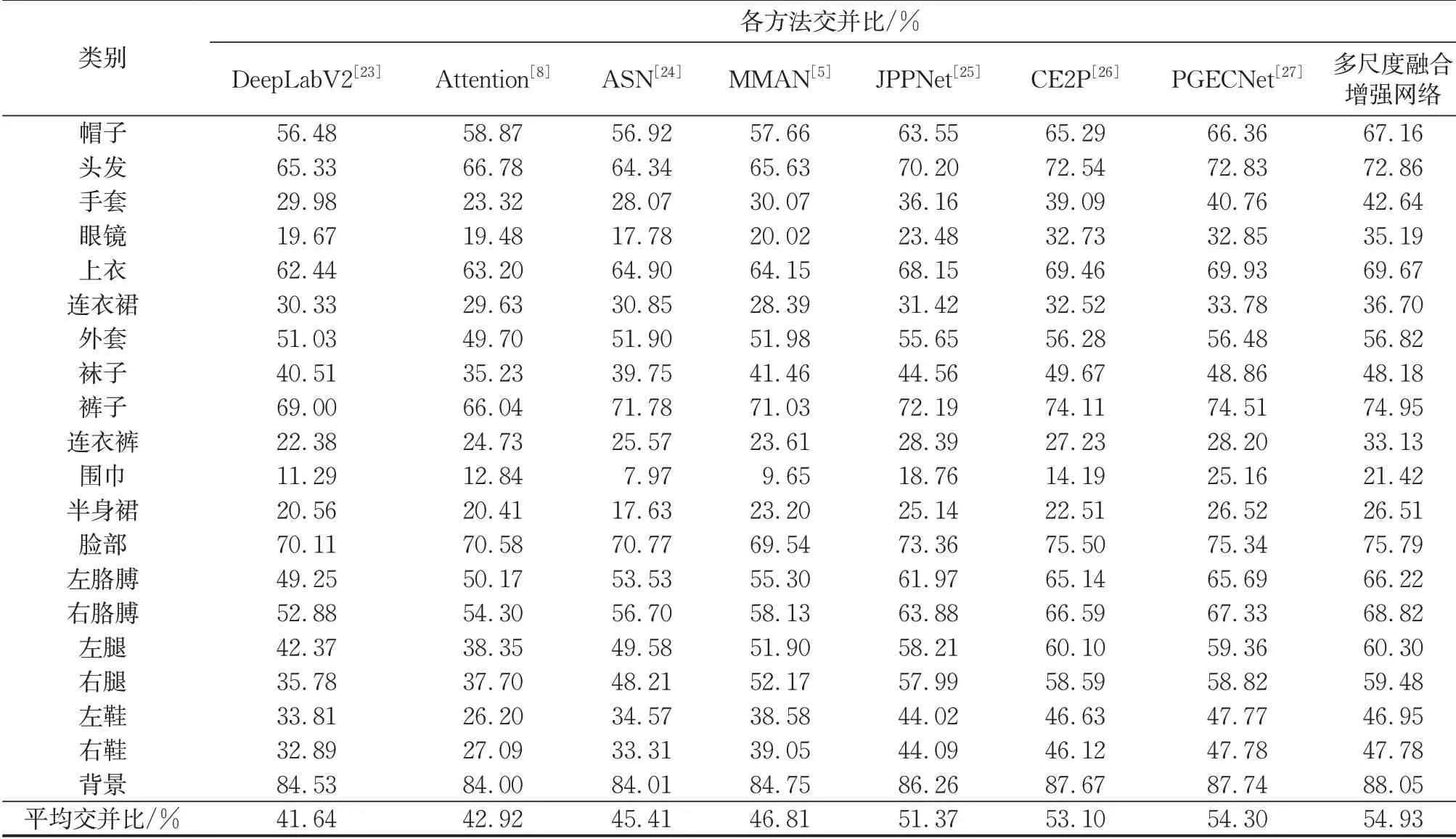
表5 不同方法在LIP数据集上每个类别的交并比Tab.5 Comparison of per-class IoU between different methods on LIP dataset
4 结语
提出了一种基于多尺度融合增强的服装图像解析方法。通过融合增强模块设计,在提取不同尺度特征的基础上,利用通道注意力机制优先考虑全局特征,增强多尺度特征信息,达到获取更多细节特征的目的。实验结果表明,本方法不仅可以提升较大目标的解析效果,还对帽子、腰带和眼镜等小物体的解析效果有明显改善。虽然本方法对较小对象的解析结果有所改善,但是与其他类别相比,小目标对象的解析精度仍然较低。在未来的研究中,将考虑利用目标检测技术定位小目标对象,从而提升小目标对象的解析精度。
作者贡献声明:
陈丽芳:模型网络结构构思、设计、分析,论文修改与校对。
余恩婷:模型网络结构程序与实验设计,论文撰写与修改。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
马克思主义哲学研究(2020年1期)2020-11-26
少儿画王(3-6岁)(2020年4期)2020-09-13
电子制作(2019年11期)2019-07-04
东方教育(2018年20期)2018-08-22
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
微型计算机(2009年4期)2009-12-23
