
图书馆书目知识地图的构建研究
2022-11-07 12:03胡朝明陈小众隋秀芝
图书馆学刊 2022年9期
胡朝明 陈小众 隋秀芝
(浙江理工大学图书馆,浙江 杭州 310018)
纸质图书营造了图书馆浓厚的学习氛围和良好的学习环境,读者可随时到图书馆借阅他们最需要的图书。但是,图书资源丰富多样,种类繁多,读者面对浩如烟海的图书往往会无所适从,大海捞针似地寻找图书,从浏览、挑选到最后借阅,要浪费大量的时间,结果还往往不甚满意。主要存在两个问题:一是读者不了解某个行业、某个学科或某个领域的图书分布情况,不知道在现有馆藏中有哪些图书可供选择;二是在圈定了择书范围的情况下,不能确定哪本书是最优选择,特别是当读者接触到新的学科或陌生的研究领域,不知道借阅的顺序。除非读者有明确的借阅目标,否则很难从海量图书中选择适合的图书。
1 OPAC系统与书目数据关联化的现状
目前国内OPAC系统中图书的呈现形式主要有两种:第一种是以《中国图书馆分类法》(简称中图法)为基础,严格按照学科进行分类。中图法主要用于各图书馆,其设计思想倾向于图书馆的业务流程,读者对中图法比较陌生或者模糊,因此采用中图法进行分类展示显得比较抽象,读者很难将自己的需求用中图法分类号表述出来。第二种是以《中国分类主题词表》为基础,根据各自的理解和用户的实际需求来设计图书主题分类体系,没有严格的分类标准,主要从用户理解的角度进行书目分类展示,多用于各书店和电子书门户网站如当当网、亚马逊、超星图书、京东图书等。
图书作为知识的载体,每本图书的书目信息和内容与其他图书其实是有关联的。书目数据采用分类呈现的方式,切断了图书之间的内容关联,OPAC的检索结果基于文本的线性列表显示,无法揭示书目之间的关联信息。OPAC系统不应再是单一的书目检索系统,它理应成为用户进行信息检索和知识挖掘的可视化工具[1]。书目信息的线性分类和线性列表显示正向网络化发展,文本格式数据正向图形化发展,保留书目信息原有关联关系,挖掘书目信息新的语义关联,推动书目数据关联化,是新一代OPAC系统的发展方向。
书目数据的关联化研究大致可分为3类:第一类研究以国际图联(International Federation of Library Associations and Institutions,IFLA)主持的FRBR模型为代表,将IFLA标准与模型置于语义网环境下,借助FRBR模型让编目实践迈向语义网时代[2]。FRBR模型以作品为核心创建书目记录,每条记录以“作品-内容表达-载体表现-单件”逐层显示,作品之间可建立关联关系,形成一个以作品为核心的树状网络[3]。第二类研究以美国国会图书馆提出的BIBFRAME为代表,该模型以网络为基础架构,重构MARC21格式,书目记录以“作品-实例-单件”分层显示,作品与作品之间通过作品和实例的属性建立关联,形成一个以作品为核心的交叉网络[4]。第三类研究以W3C图书馆关联数据孵化小组为代表,采用资源描述框架(Resource Description Framework,RDF)将传统MARC数据改造成为富含语义的RDF三元组形式,实现书目记录之间的关联[5]。W3C的关联方案以关键词为核心,采用简单知识组织系统(Simple Knowledge Organization System,SKOS)和关联开放数据云图(Linked Open Data Cloud,LODCloud)组织和发布书目数据,其目标是使书目数据能够在图书馆内部和外部发挥最大的价值。
2 书目知识地图的构建方案
书目知识地图的目标是导航清晰、显示直观、结果准确、易于理解,书目知识地图需要建立在书目关联关系基础上,才能更好地揭示书目和发现知识。主流的做法是使用关联数据思想建立书目关联关系,关联数据将一条MARC记录按特定规则拆分成若干条小数据,小数据之间的关联关系非常庞大,这些关联关系中仍然以显性关系为主,用来揭示图书与图书在内容方面的联系仍存在困难。同时,现成的关联数据方案和OPAC系统非常复杂,开发难度大,购买价格昂贵。鉴于这两方面的情况,笔者提出以书目特征关键词为核心建立书目关联关系,以图数据库为基础存储和揭示书目关联关系的方案。
2.1 构建词向量词典
2.1.1 书目数据预处理
馆藏书目数据为MARC格式,不能直接阅读和使用,笔者使用自主开发工具MARC forMySQL将书目MARC记录转换为关系数据表记录,存入MySQL数据库。实现MARC数据转换的基本原理和流程是[6]:读取MARC数据,每次读取一行;计算地址目录区中目次项的数量;获取地址目次区中所有目次项的字段标识符,按顺序存储;获取数据字段区的每一个数据字段,按顺序存储;按需求提取字段内容;存储字段内容到MySQL数据库。实验中以浙江理工大学图书馆馆藏书目为数据来源,根据MARC控制号随机抽取10万条书目记录作为实验数据。
2.1.2 内容抽取和分词标注
一条MARC数据全面地记录了一本图书的著录核心信息,从描述图书内容的角度看,主要包括以下字段和信息:图书的书名(题名200$a、副标题200$e、合订本题名200$c、分卷题名200$i、丛书名225$i)、作者(200$f、译者200$g)、ISBN 010$a、出版社210$c、出版年210$d、主题词(605$a、606$a、607$a)、副主题词(605$x、606$x、607$x)、内容简介330$a等。其中,图书的书名、主题词和内容简介包含了图书的主要内容信息,在没有阅读具体内容的情况下,我们可以通过书名、主题词和简介来描述和了解一本书或者一类书。实验中我们抽取了 200$a、200$e、605$a、606$a、607$a、605$x、606$x、607$x和330$a共9个字段内容,每条书目信息的抽取内容作为一条书目描述记录。
中文句子的语法结构松散,词语组合灵活多变,一词多义现象普遍存在,这给自动分词带来较大困难。较常用的中文分词工具主要有中科院计算所NLPIR、哈工大LTP、清华大学THULAC、复旦NLP、斯坦福分词器、HanLP分词器、jieba分词、IKAnalyzer等,有些工具不能进行词性标注,不符合实际需要。实验中选择分词较为规范,且有词性标注和句子成分分析功能的哈工大LTP分词工具[7],对书名和内容简介字段进行分词和词标注后存回MySQL数据库。分词示例:
分词前:数字图书馆发展趋势研究报告
分词后:数字/n图书馆/n发展/v趋势/n研究/v报告/n
抽取的书目描述记录经LTP分词并进行词性标注以后,根据词性过滤掉在语义分析中作用不大的功能词,如关联词、副词、助词等。笔者结合实际经验,主要保留了名词(含人名、地名、专有名词等)、动词和形容词相关词性的词语,这是后续建立关键词网络需要重点关注的词汇。
2.1.3 生成词典和Word2Vec词向量
书目描述记录经LTP分词、去重后,得到683627个关键词,存入词典库。然后采用Word2Vec模式训练词向量。Word2Vec是Google在2013年开源的一款将词表征为实数值向量的高效工具,利用深度学习思想,通过训练把对文本内容的处理简化为多维向量空间中的向量运算,而向量空间上的相似度可以用来表示文本语义上的相似度[8]。调用Python的第三方模块gensim提供的函数gensim.models.Word2Vec对处理好的书目描述记录进行学习,训练窗口设置为5,词向量维度设置为100,选择Skip-Gram模型进行词向量训练,最终得到683627个Word2Vec词向量。词典中包含多义词、同义词、歧义词等语义复杂的关键词,这是自然语言处理中的难点,在后续检索、建立关键词关联关系的过程中,可通过计算Word2Vec词向量的余弦相似度[9],来判断两个关键词的语义相关度。
2.2 提取书目描述记录的特征词
2.2.1 词典的词频分析
书目信息中的标题和内容简介被切分为一元词或二元词,这些词显得很零散,并且严重重复,不利于筛选特征词表征书目的语义信息。有些词出现频率很高称为超高频词(见表1),有些词出现频率很低称为超低频词(见表2),超高频词和超低频词都不利于表征书目语义信息[10],需要选择合适的标准去除。
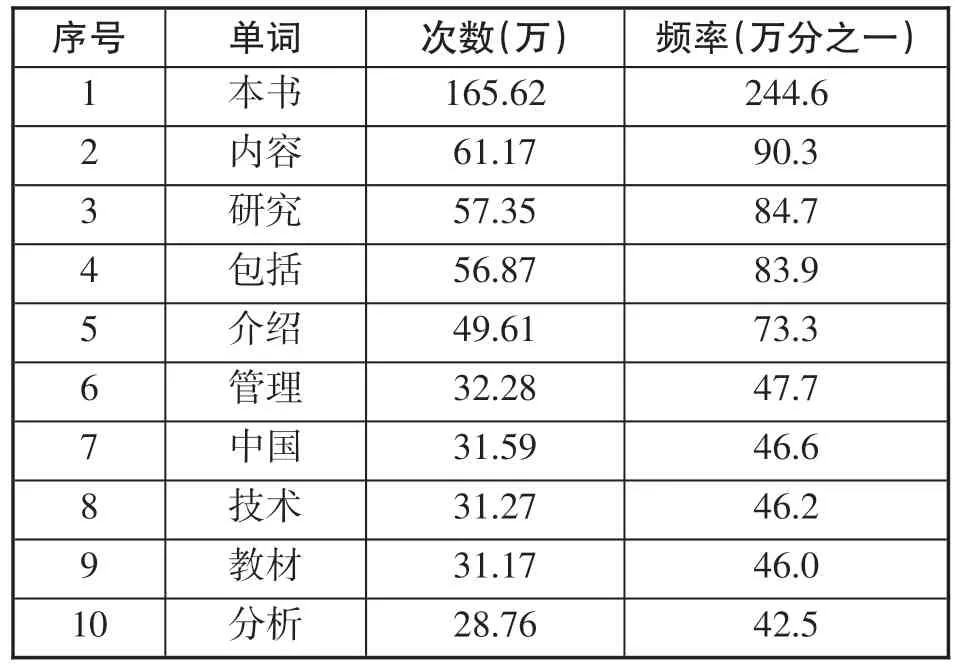
表1 超高频词示例
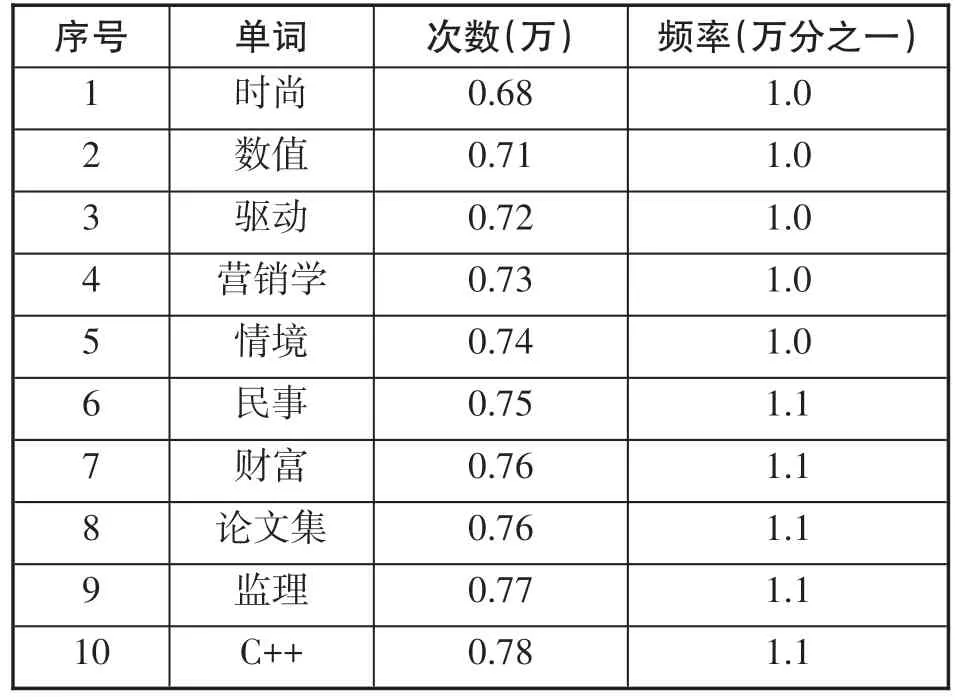
表2 超低频词示例
分词统计结果显示,分词后出现次数大于10万次的词共有53个,平均每条书目描述记录出现一次,这是典型的超高频词,超高频词大多具有通用语义,表征书目特征的作用小。出现次数小于10次(平均1万条书目信息出现一次)的词共有52.4万,占总词数的77%。由此可以看出书目描述记录的分词结果非常稀疏,如果进一步用词向量表征书目的特征将非常困难,这是由书目信息的超短文本形式决定的。超高频词和超低频词占极小部分,中频词占绝大部分,实验中过滤掉53个高频词,保留全部中低频词。
2.2.2 提取书目语义特征词
由于词典中的关键词在书目描述记录中出现频率不同,关键词的语义信息含量也不同,每个关键词在书目描述记录的重要程度也就不同,为此,采用TF-IDF值来衡量关键词在书目描述记录中的重要程度。
TF-IDF的主要思想是[11],如果某个单词在某篇文档中出现的次数越多,并且在其他文档中出现的次数越少,则可认为此单词越能代表该篇文档,可理解为此单词越能代表某条书目描述记录的内容。其中,TF称为术语频率,表示某一文档中某单词出现的频率;IDF称为逆文档频率,表示该单词在整个语料库中重要程度的度量。
根据TF和IDF的定义,TF和IDF的计算方法为:

由前面的词频分析可知,书目描述记录中的关键词出现频率都比较低,在短文本中如果单纯采用上述公式计算TF和IDF值,将会降低某一类集中出现在部分书目中单词的区别能力[12],所以笔者提出如下改进算法:

关键词的TF-IDF值为:TF×IDF,TF-IDF值计算出来以后,取每条书目描述记录中TF-IDF值为前5的关键词作为该条书目特征词的备用词,然后取这5个关键词的Word2Vec词向量,计算每两个关键词之间的余弦相似度,如果余弦相似度大于0.8,说明两个词的语义非常接近,去掉TF-IDF值较低那一个词。这样就用少数关键词作为书目描述记录的特征词来表征该条书目的语义信息。
2.3 建立书目地图的关联网络
2.3.1 建立特征词与特征词的关联网络
书目数据的标题、内容简介等短文本经自动分词、词性标注后,可使用依存句法分析抽取关键词与关键词之间的关联关系,关联词对的关联就构成了书目地图中词与词的关联关系。短文本经依存句法分析后形成句法分析关系树,树中节点特征项之间的关联关系由句子中词语间的距离决定。语言学表明,句子中成分间存在句法结构,因此由依存句法分析确定关联词对符合实际情况。关联词对间的关系主要包括:主谓关系SBV、动宾关系VOB、定中关系ATT、状中结构ADV、并列关系COO等[13]。实验中发现,书目数据的特征词由以上5类关系组合而成的二元复合词,能很好地表达书目数据原有语义信息,还能拓展语义检索的范围。
采用LTP的Python包实现依存句法分析,示例见图1。
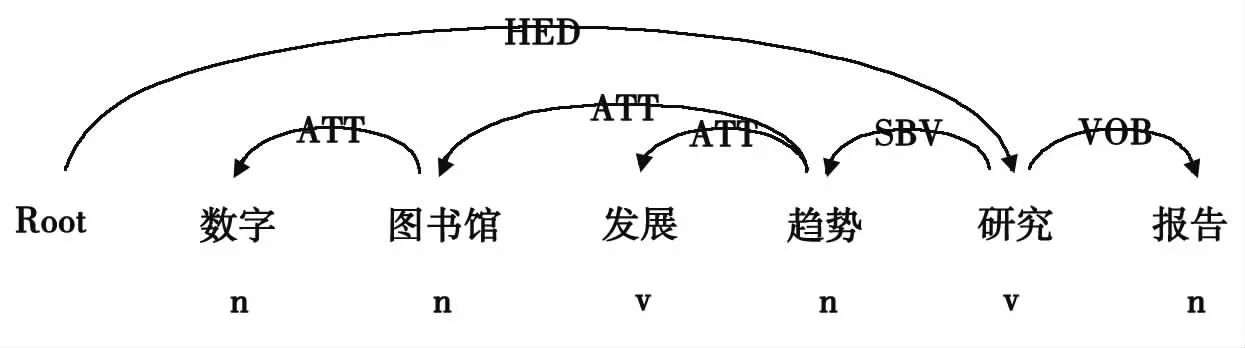
图1 依存句法分析示例
原句:数字图书馆发展趋势研究报告
分词并标注:数字/n图书馆/n发展/v趋势/n研究/v报告/n
在这个例子中,ATT、SBV、VOB这3种关系是我们需要关注的,分别构成数字-图书馆、图书馆-趋势、发展-趋势、趋势-研究、研究-报告5对关系。这5对关系的重要程度不同,可通过单词的TF-IDF值来衡量。10万条书目数据的特征词通过SBV、VOB、ATT、ADV、COO等这5种关系相互连接,形成特征关键词网络,这是书目地图的主干网络。用户检索书目地图的节点和关系时,关键词是检索的入口,所有的检索匹配都是在这5对关键词中进行,原始书目信息仅供浏览地图使用,不再参与内容检索。根据这样的架构构建的关键词网络,结构比较清晰且不失灵活性。
2.3.2 建立关键词与书目的关联网络
每条书目描述记录用5个特征关键词表征以后,书目信息与相应的关键词就建立了关联关系。一条书目与多个关键词相关联,一个关键词与多条书目相关联,关键词与书目之间形成多对多的网络关系(见图2)。从整个书目信息看,若干条书目聚集在几个相关性较强的关键词周围,相当于书目信息以关键词为中心形成一个个聚类族。这些聚类族构成书目地图的分支网络,通过关键词主干网实现全连接。

图2 书目知识地图的关联网络
3 书目知识地图的实现与应用
3.1 构造节点、关系和属性
书目知识地图由书目、书目的特征词及其之间的网络关系构成,可使用图数据库Neo4j实现存储和检索。Neo4j是一个流行的图数据库,它以节点、关系和属性的形式存储数据,Neo4j的速度比传统的关系型数据库提升约1000倍[14]。在Neo4j中,关键词和书目作为节点,关键词与关键词间的关系、关键词与书目间的关系作为关系,书目的字段信息(如书名、作者、出版社、出版年等)作为书目的属性,ATT、SBV、VOB、FOB、COO作为关键词与关键词关系的属性。节点、节点的属性,关系、关系的属性用Python批量定义和生成,所有的节点、关系和属性都是一条条描述记录,存入Neo4j数据库后,书目知识地图的基础数据也就完成了,但还没有直观显示出来。
3.2 书目知识地图可视化实例
从Neo4j中检索出节点和关系,然后对检索结果进行可视化展示,生成书目知识地图,这一步的工作主要集中在Neo4j数据库的可视化。现有3种可视化途径:一是使用Neo4j自带的查询工具Neo4j Browser和Neo4j Bloom。Neo4j Browser是面向开发人员的工具,允许开发人员执行Cypher查询并可视化结果,Cypher相当于关系数据库中的SQL查询语言,能够按照节点和关系进行语义查询。Neo4j Bloom是一款收费工具,允许用户使用自然语言浏览图数据。二是使用D3.js。D3.js是当前网页前端数据可视化领域应用比较广泛的开源可视化实现库,基于JavaScript语言开发,允许在前端的DOM结构中绑定多种类型的数据,并通过使用HTML、SVG和CSS等语言编写逻辑将数据实现前端可视化展示。三是使用Cytoscape.js。Cytoscape.js是一个用JavaScript编写的开源图库,它允许用户与图形交互,把Cytoscape.js集成到应用程序中,可以实现在Web端显示Nneo4j图形数据库的数据。实验中使用了Neo4j Browser和Cytoscape对Neo4j数据库的书目关联数据进行可视化,下面以4个实验举例说明。
实验1,查询所有节点和关系。图3为使用查询语句“match(n:Word)-[r]-(m:Book)return n,m,r limit300;”在Neo4j Browser中的查询结果,n代表源节点,m代表目标节点,r代表源节点与目标节点间的关系,查询输出关键词节点、书目节点及其关系的网络关系图,由于电脑性能限制,图3的查询限制为节点和关系书目最大为300,小圆点为关键词节点,大圆点为书目节点。由图3看出,部分节点还未形成关联关系,这是受样本数据量限制所致。

图3 Neo4jBrowser可视化Neo4j中的节点和关系
实验2,根据关键词查询图书。图4为使用查询语句“match(n:Word{name:'图书馆'})-[r]-(m:Book)return n,m,r limit20;”在Neo4jBrowser中的查询结果,返回与关键词“图书馆”节点相关联的书目节点及关系。中间节点为关键词节点“图书馆”,周边节点为根据关键词节点检索到的相关图书。单击任意书目节点,将会展开与该书目节点相关联的关键词节点和书目节点,可根据需要一步一步“按图索书”,与传统OPAC系统相比检索过程和检索结果更为直观。

图4 Neo4jBrowser可视化书目查询结果
实验3,根据条件查询节点和关系。图5为使用 Cytoscape插件可视化展示“match(n:Word{name:‘纺织’})-[*1..3]-(p)return n,p;”的查询结果,查询语句的含义是“检索与名为‘纺织’关键词节点相关联、且关联节点数为1-3的所有关键词节点和关系”,输出与关键词“纺织”相关联的节点及相互关系。箭头为修饰方向,比如“纺织→工业”组合成“纺织工业”,点击节点“工业”将会展示出与“纺织工业”相关的图书。使用Cytoscape插件并进行二次开发,还可根据需要灵活展示查询结果。

图5 Cytoscape可视化Neo4j中的节点和关系
实验4,查询节点的路径。图6为使用Cypher查询语句“MATCH(m:Word{name:‘杭州’}),(n:Word{name:‘ 贵 州 ’}),p=shortestpath((m)-[*..10]->(n))RETURN p;”在 Neo4j Browser中的查询结果,输出为节点“杭州”到节点“贵州”之间的最短路径关系,示例中依次经过:杭州金融、金融企业、企业开发、开发贵州4个组合词找到了杭州到贵州的联系。如果书目数据足够丰富,这为读者“按图索书”提供了一种参考。

图6 Neo4jBrowser查询Neo4j节点的路径
4 结语
运用自然语言处理技术,建立书目信息的内容关联,将零散的书目信息形成有机整体,揭示书目之间的隐含关系,挖掘书目的隐性知识,便于读者从全局来明晰所属领域的图书,快速了解目标领域的知识脉络。运用Neo4j图数据库的存储和可视化技术,直观展示书目信息,形成可浏览、可检索的书目知识地图,便于读者进行可视化查找和选择图书。
在理论研究方面主要有以下3点贡献:一是特征关键词表征书目信息。使用改进的TF-IDF算法计算关键词的TF-IDF值,并结合Word2vec词向量确定每条书目信息的特征关键词。二是用句法分析建立特征关键词的关联网络,实现书目信息的内容关联,比采用关联数据的方式更简洁高效,而且适用于本地图书馆。三是完整定义特征关键词节点和书目节点,以及它们的关系和属性,用图的形式构造书目关联数据。
在实践研究方面,笔者选取10万条原始书目MARC记录作为实验数据,完成了数据转换、关键词提取、建立关键词网络、生成网络节点、关系和属性、Neo4j存取数据、Neo4j检索和可视化的算法和程序,实现了本地书目知识地图的实验系统,可为开发新一代OPAC系统提供借鉴。
猜你喜欢
都市人(2022年3期)2022-04-27
校园英语·月末(2021年13期)2021-03-15
当代陕西(2019年15期)2019-09-02
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
棋艺(2014年7期)2014-09-09
全国新书目(2009年1期)2009-04-13
家庭医学·下半月(2009年2期)2009-03-27
