
基于多尺度特征递归卷积的稠密点云重建网络
2022-11-02 11:24:52王江安庞大为秦林珍
图学学报 2022年5期
王江安,庞大为,黄 乐,秦林珍
基于多尺度特征递归卷积的稠密点云重建网络
王江安,庞大为,黄 乐,秦林珍
(长安大学信息工程学院,陕西 西安 710064)
针对在三维重建任务中,由于弱纹理区域的光度一致性测量误差较大,使得传统的多视图立体算法难以处理的问题,提出了一种多尺度特征聚合的递归卷积网络(MARDC-MVSNet),用于弱纹理区域的稠密点云重建。为了使输入图像分辨率更高,该方法使用一个轻量级的多尺度聚合模块自适应地提取图像特征,以解决弱纹理甚至无纹理区域的问题。在代价体正则化方面,采用具有递归结构的分层处理网络代替传统的三维卷积神经网络(CNN),极大程度地降低了显存占用,同时实现高分辨率重建。在网络的末端添加一个深度残差网络模块,以原始图像为指导对正则化网络生成的初始深度图进行优化,使深度图表述更准确。实验结果表明,在DTU数据集上取得了优异的结果,该网络在拥有较高深度图估计精度的同时还节约了硬件资源,且能扩展到航拍影像的实际工程之中。
深度学习;计算机视觉;遥感测绘;三维重建;多视图立体;递归神经网络
基于多视图立体(multi-view stereo,MVS)信息的稠密点云重建是计算机视觉的经典研究课题,是虚拟现实、智能驾驶和考古研究等多个领域中的关键技术[1]。传统的稠密重建方法[2-4]利用计算相似性来衡量多视图的一致性,尽管该方法已经应用多年,近年来随着深度学习[5-10]的不断深入拓展了更多思路,在最近的研究中,通过引入深度神经网络提升了特征提取和代价体正则的速度和准确性。
传统的三维重建方法是建立在尺度不变特征的基础上,通过提取并匹配所有图像的特征,找到不同视图和相机姿势之间的成对关系[11]。根据输出场景可将传统的稠密重建方法分为:基于体素的方法[12-13]、基于特征点扩散的方法[14]和基于深度图融合的方法[15]。基于体素的方法将整个三维空间离散为规则的立方体,使用光度一致性度量来确定体素是否属于曲面。该方法需消耗大量计算资源,其精度主要取决于体素的分辨率[6],因此不能适应大规模场景。特征点扩散方法从匹配关键点的稀疏点集开始,使用传播策略来加密点云。由于传播是按顺序进行的,因此该方法限制了并行数据的处理能力。基于深度图融合的方法,也是目前主流的方法,其核心思想为先对每张图像进行深度估计并得到深度图,然后将所有深度图融合到一起形成最终的点云。典型的有COLMAP[1],该算法引入迭代的捆绑调整和几何验证策略,通过计算特征选择视图、估计深度图和表面法线,显著提高重建完整性和准确性。
自机器学习被广泛应用,稠密重建的研究也受到深度学习的影响。基于学习的方法能够在重建过程中考虑全局语义信息,因此可以提高重建的准确性和完整性。学术界首先提出了基于体素的SurfaceNet[6],该方法使用多视图图像扭曲到3D空间构建代价体,并使用三维卷积神经网络( convolutional neural networks,CNN)来正则化和聚合体素,但由于体积表示的常见缺点,SurfaceNet仅限于小规模重建。YAO等[16]提出了一种基于深度图的端到端架构MVSNet。该方法将代价体用于3D CNN正则化进而深度回归,大大提高了稠密重建的性能。
基于深度学习的稠密重建存在如下问题:如早期的MVSNet[16]方法使用具有下采样模块为主干网络来提取特征,这种直连的卷积层网络具有固定的感受野,提取特征时在处理弱纹理或无纹理表面处存在困难,这限制了三维重建的鲁棒性和完整性。另代价体正则部分使用3D CNN结构,其占用的GPU内存消耗随图片分辨率增加呈立方体增长,因此MVSNet无法处理大分辨率的图像。R-MVSNet[17]中不再使用消耗高额显存的3D CNN,网络将代价体正则部分更换为堆叠式的GRU模块,进一步提高了对大规模场景深度估计的可能性,但重建的完整性和准确性仍有不足。
近年来发布的网络,大多数有监督网络舍弃了深度图优化部分,这并不利于完整的重建。为了进一步提高估计深度图的质量,M3VSNet中[18]深度图优化使用基于法线深度一致性的算法,结合了世界坐标空间中的法线深度一致性,以约束从估计深度图获得的局部表面切线与计算出的法线正交,这种正交化可提高估计深度图的准确性和连续性。此外,高斯-牛顿修正算法[19]简单而快速地将粗略的高分辨率深度图细化为密集的高分辨率深度图。
为了解决上述问题,本文提出了一种基于深度学习的具有动态一致性检验的多尺度递归卷积多视图立体网络(multi-scale aggregation recursive multi view stereo net with dynamic consistency,MARDC-MVSNet),该网络包含视图之间的多尺度自适应聚合模块A2MDCNN,递归结构的分层正则化网络模块和引入残差思想的深度图优化模块。本文方法可以解决诸如弱纹理区域重建和大场景建模之类的问题,可实现准确和高完整度的稠密重建。
1 MARDC-MVSNet网络原理
1.1 MARDC-MVSNet网络结构设计
图1为本文设计的一款新颖的分层式多尺度特征递归卷积网络MARDC-MVSNet。其吸收了MVSNet中3D CNN和R-MVSNet中GRU递归单元的优点,充分利用了3D CNN聚合局部上下文信息能力和堆栈式递归网络的效率。本文输入图像分为1个参考图像和–1个源图像,所谓的参考图像就是需要得到深度图的图像,源图像则是与参考图像有特征联系的相邻图像。通过卷积网络得到个图像的特征图,再将源图像的特征图通过可微单应性变换扭曲到参考图像的主光轴上聚合成代价体,然后对代价体进行正则化得到用于预测深度图的概率体,最后对所有深度图进行融合生成场景稠密点云。MARDC-MVSNet通过在多尺度特征提取、代价体正则化和深度图优化上改进重建体系结构。
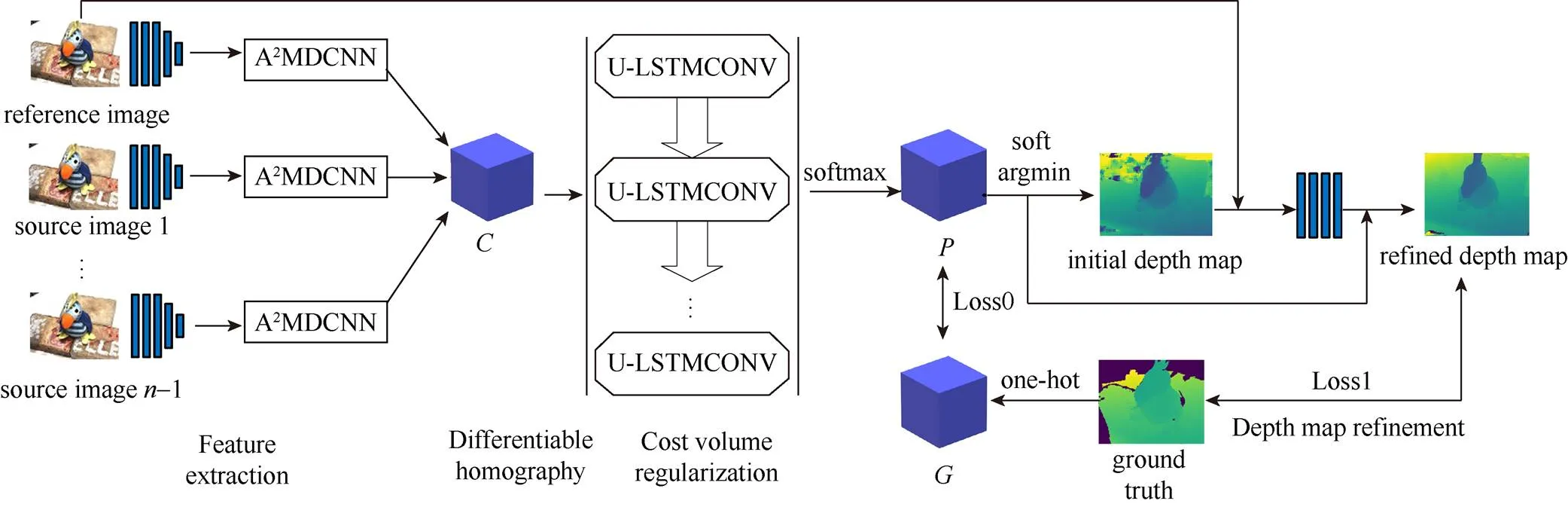
图1 MARDC-MVSNet网络架构
1.2 特征提取模块
反射面和弱纹理或无纹理区域是造成完整性和准确性低的重要原因。这是常规的卷积处理所产生的问题,一般卷积网络在固定规格的网格上进行运算。从某种意义上讲,应同等地对待正常纹理和弱纹理区域,因此在弱纹理情况下,常规的卷积无法获得足够的图像特征。对于那些缺乏纹理的区域,卷积的感受野应该更大,而对于纹理丰富的区域,卷积的感受野则应较小。为实现上述思路,本文运用可变形卷积构建一个多尺度聚合模块A2MDCNN以实现感受野的变化。
可变形卷积定义为
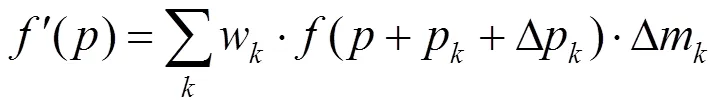
其中,()为像素的特征值;w和p为在普通卷积运算中定义的卷积核参数和固定偏移量;Dp和Dm是可变形卷积经过学习产生的偏移量和权重。

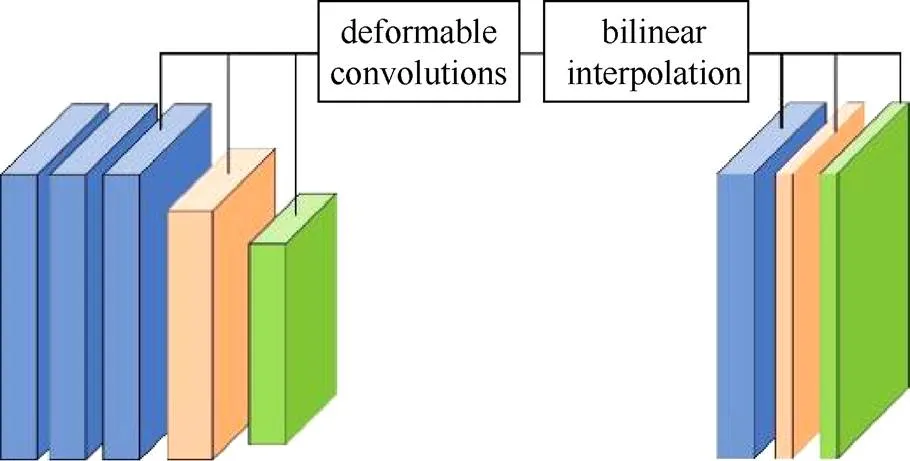
图2 A2MDCNN特征聚合模块
1.3 构造代价体
每个参考图像对应的代价体是通过匹配对应源图像的特征来计算的。通过平面扫描法[20]对参考图像以其主光轴为扫面方向,以相同间距构造一个锥形体,再根据单应性变换,将每一张源图像投影到每一层深度上构成特征体,最后利用插值法使每张投影尺寸相同。其中单应性变换定义为
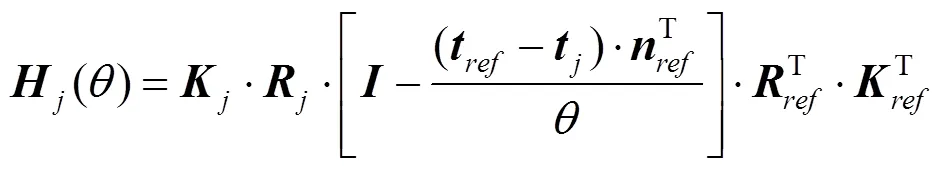
其中,{,,}为内部参数,代表旋转和平移;为参考图像的主光轴;为深度值;为单位矩阵;为该参考图像对应多个源图像的索引。
假定源图像个数为,理论上每一张参考图像有个对应的特征体,将这些特征体基于方差的形式构建一个代价体为
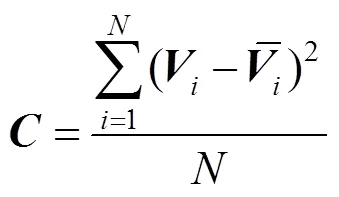
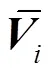
使用方差计算出不同角度的各个图像在同一深度位置特征的差异大小,差异的大小表明了特征的匹配程度,若无差异,则说明此深度位置的点为多个角度投影的交点,即深度确定。
1.4 分层式正则化网络
代价体正则化是利用空间上下文信息将匹配的代价体转化为深度概率分布,学术界提出了2种方案:多阶段方法和递归处理方法。多阶段方法,如CasMVSNet[21],AA-CVP[22],Vis-MVSNet[23]和Point MVSNet[9],此类使用由粗到精策略,首先预测大深度间隔的低分辨率深度图,然后多次迭代上采样细化具有窄深度范围的深度图。尽管由粗到细的体系结构成功地减少了显存消耗,但由于在较大的深度间隔下粗阶段的深度预测可能是错误的,同时正则化网络大多还是用U型结构的3D CNN,因此不适合高分辨率的深度估计。另一种思路是递归方法,如R-MVSNet和D2HC-RMVSNet[24]。此类使用递归网络沿深度方向顺序的正则化代价图,以代替内存密集型3D CNN。R-MVSNet使用堆栈式GRU卷积门控递归单元以顺序方式处理代价体,D2HC-RMVSNet通过更强大的LSTM递归卷积单元LSTMConvCell[25],同时使用动态一致性检查策略来改善深度图融合。
本文使用递归思想,具体采用分层式递归卷积(CNN_RNN)作为代价体的正则网络,如图3所示,在水平方向上网络为2D的U-Net结构,其各层均是LSTMConvCell[25],其不仅具有LSTM的时序性,还能像CNN一样刻画局部特征;在垂直方向上有5个平行递归模块,每个模块将前一个递归卷积的中间结果传送到后一个。这个堆栈式模块可以很好地吸收多尺度上下文信息又能高效地处理代价体。考虑到训练存在收敛难的问题,在网络末端添加一个残差块,加速网络训练。
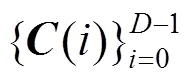

图3 U型堆栈式LSTMConv模块
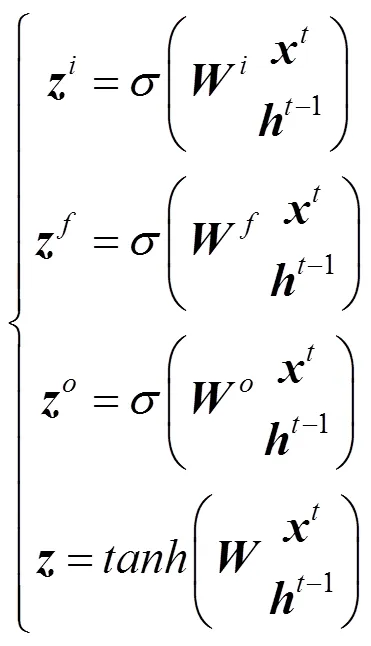

表1 正则网络形式构成
深度图的生成遵循赢者通吃原则,但赢者通吃原则会造成深度突变、不平滑情况,无法在亚像素级别上估计深度。借鉴argmax思想,沿着概率体的深度方向,以深度期望值作为该像素的深度估计值,使得整个深度图中的不同部分内部更加平滑。
1.5 深度图优化
概率体得到的初始深度图存在一些问题,即在正则化过程中会出现深度图边界过平滑现象。深度图优化的方法有多种,M3VSNet[18]考虑到法线与局部表面切线之间的正交性,引入了新的法线深度一致性来细化得到优化的深度图。为了减少训练时间和简化网络,本文借鉴图像引导思想,由于参考图像包含了边界信息,因此可用参考图像引导优化初始深度图。受抠图算法的启发,在网络末端添加一个残差网络。即将初始深度图和参考图像连接成一个4通道的张量,与MVSNet不同在于,该深度图和参考图像的宽高相同。将该张量送入3个32通道的卷积层和一个1通道的卷积层可得到学习的深度差值,最后加到初始深度图以得到最终的深度图。
1.6 损失函数
在深度图估计时,该网络可分为初始深度图和深度图优化2部分。在进行初始深度图估计时,视其为多重分类任务,而非回归任务。在概率体和真实深度图的one-hot编码体之间使用交叉熵损失函数,即
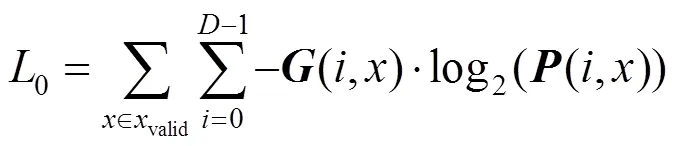
其中,valid为有效的像素集;(,)为真实深度图在像素的第个深度处one-hot编码生成;(,)为概率体中的像素。
深度图优化部分将真实深度图到优化深度图的距离作为损失,即
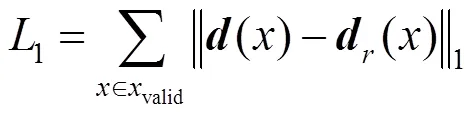
其中,()为真实像素深度值;()为优化的深度值。
因此,本文训练时的损失函数定义为
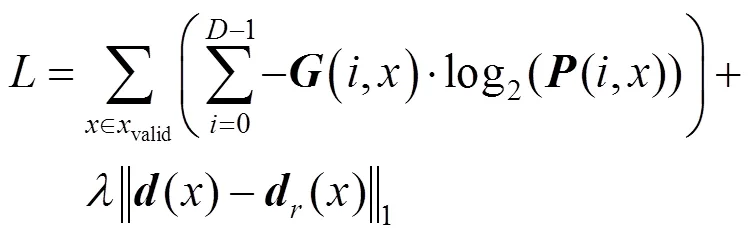
其中,决定网络是否开启深度图优化模块。
2 实验与结果分析
2.1 实验数据集
本文使用DTU[26]数据集训练和测试MARDC- MVSNet网络。DTU数据集是在实验室条件下收集的室内MVS数据集,其具有固定的摄像机轨迹,一共包含128次扫描,分为79次训练扫描、18次验证扫描和22次测试扫描。其中包括124种不同场景,并在7种不同的照明条件下显示49个或64个视图。除此之外,该数据集提供了由精密的结构光扫描仪获取的参考模型以及高分辨率图像,这些数据可生成真实的深度图。为了证明网络的可扩展性,在Blended_MVS[27]数据集上使用DTU数据集训练得到的模型可直接进行测试。Blended_MVS是一个新型的大规模MVS数据集,该数据集包含具有各种不同相机轨迹的113个不同场景,每个场景由20到1 000个输入图像组成,包括建筑、雕塑和小物体。最后,为了进一步说明本文方法适用于复杂场景,网络在自采集的数据下进行测试。
2.2 实验实施细节
2.2.1 网络训练
本文在由79个不同场景组成的DTU训练集上进行网络训练。DTU数据集仅提供真实的点云模型,通过屏蔽泊松曲面重建算法和深度渲染生成粗糙的参考图像的真实深度图。再与相邻的源图像进行交叉过滤来细化真实深度图。在训练时图像大小设置为160×128,输入图像的数量设置为=7,在深度方向上均匀采样,将深度层假设为=192。本文使用PyTorch实现了网络模型,并使用Adam对网络进行端到端的训练,初始学习率为0.001,并设定每个epoch学习率衰减0.9,共训练12个epoch。网络在一个NVIDIA RTX 3090显卡上训练,批大小batch size设置为1,整个训练阶段至少需要20 GB内存。
2.2.2 网络测试
本文通过DTU训练集得到模型,用于DTU数据测试、Blended_MVS数据测试及自采集数据测试。使用=7个视图作为输入,并将深度平面假设为=512,以获得具有更精细细节的深度图。为了配合网络的设计,测试样本输入图像的尺寸必须是8的倍数,因此使用800×600大小的输入图像进行测试。同时也在Blended_MVS数据集进行测试,其输入的大小设置为768×576的图像。其生成的深度图如图4所示,图中清晰地显示了MVSNet生成的深度图在细节处理上劣于本文,如图4(a)所示,本文能更好地描述盒子的边缘;如图4(d)所示,本文除了能刻画更准确的边缘外,还能描述一些更为细小物品的深度图,如路灯。

图4 DTU数据在本文MARDC-MVSNet网络和MVSNet网络上测试结果对比((a),(d)原图;(b),(e) MVSNet网络结果;(c),(f)本文网络结果)
与之前的MVS方法类似,网络为每个输入多视图图像生成稠密的深度图。本网络为深度图引入了光度和几何约束,在融合所有估计的深度图之前,需要过滤掉不匹配的错误并存储正确可靠的深度,在实验中丢弃了估计深度概率低于0.3的像素。遵循D2HC中提出的动态几何一致性检查方法交叉过滤原始深度图,并融合以生成相应的三维稠密点云,其中参数设置为=200,=1.8。
2.3 点云重建结果
首先在DTU测试数据集上评估了本文提出的MARDC-MVSNet网络。所有扫描设置深度范围为[425 mm,905 mm],并使用通用评估指标[16-17]。将本文方法与传统方法和一些基于学习的方法进行了比较,定量结果见表2,其中准确度和完整性是由官方MATLAB评估代码计算的2个绝对距离[26],Overall是2个指标的平均值。表中Gipuma[15]在准确性方面取得了最佳,CasMVSNet在综合数值上取得了最好效果,由于本网络的深度推断使用的是递归算法,可能会失去一些上下文信息,因此仅在完整性上取得了最优的成果。但针对三维重建,点云的完整性在实际应用上更为重要。对比Gipuma本网络在完整性及综合指标上已弥补了准确性略显不足的问题。虽然CasMVSNet综合数值较好,但该值为平均所得,在完整性上本文网络具有优势。综上,本文方法在完整性和整体质量方面均优于所有竞争方法。本文方法得益于多尺度特征聚合模块和CNN-RNN正则网络,由于能处理弱纹理,与经典的MVSNet和R-MVSNet相比,本文可以显著提高准确性和完整性。图5显示了与其他方法相比的定性结果,图5(a)为建筑物,本文在刻画窗户上更具完整性,同样在图5(d)的人像上也有体现,图中人物的手和肩膀在R-MVSNet网络重建下有太多的细节丢失,造成了空洞现象,本文网络有效地改善了这一情况;在图5(g)的蛋糕边缘部分本文刻画的更清晰,字母细节的描绘更真实。这是因为本文网络所生成的特征图尺度较大,图像保存的细节信息较多,这得益于高效的正则网络实现了大尺寸特征图的网络重建。因此,该方法获得了更完整、更精细的三维稠密点云,以此来证明该网络的有效性。
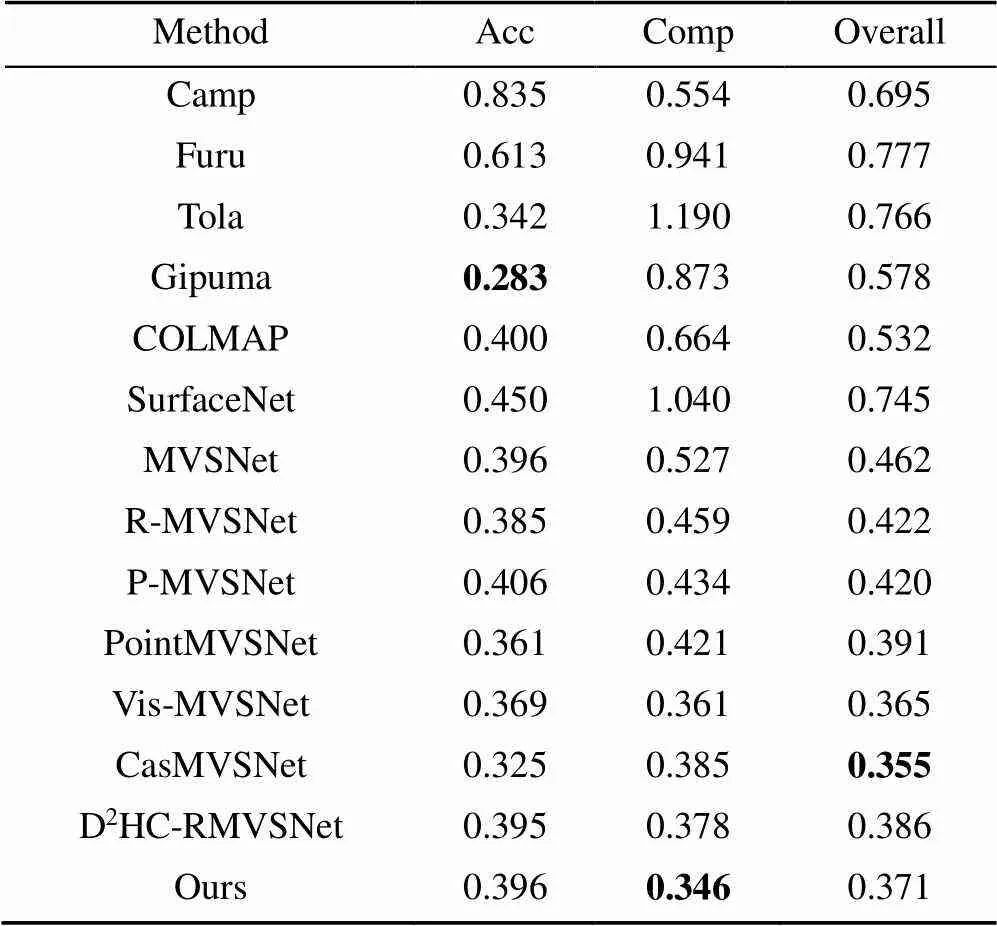
表2 DTU测试数据集上的定量结果(mm)
注:加粗数据为最优值
本实验还在BlendedMVS测试集上进行了测试。所用模型为DTU数据集训练得出,只需要在数据集预处理上做一些改动。如图6所示,本文方法可以很好地重建整个大型场景并能清晰地展示其细节,而经典R-MVSNet因正则模块的缺点无法在有限的资源下重建,因此在Blended_MVS数据集上表现的效果并不好。本文在处理教堂、房屋和村庄场景时能够准确地描绘建筑的小细节并在完整性上有更大的优势;在处理博物馆场景时,本网络可还原完整的场景,点云模型的空洞更少。本文方法通过多尺度聚合模块和基于LSTM的CNN_RNN模块做到了在兼顾上下文信息的同时进行高效的稠密深度估计,并得到更健壮和完整的稠密三维点云。
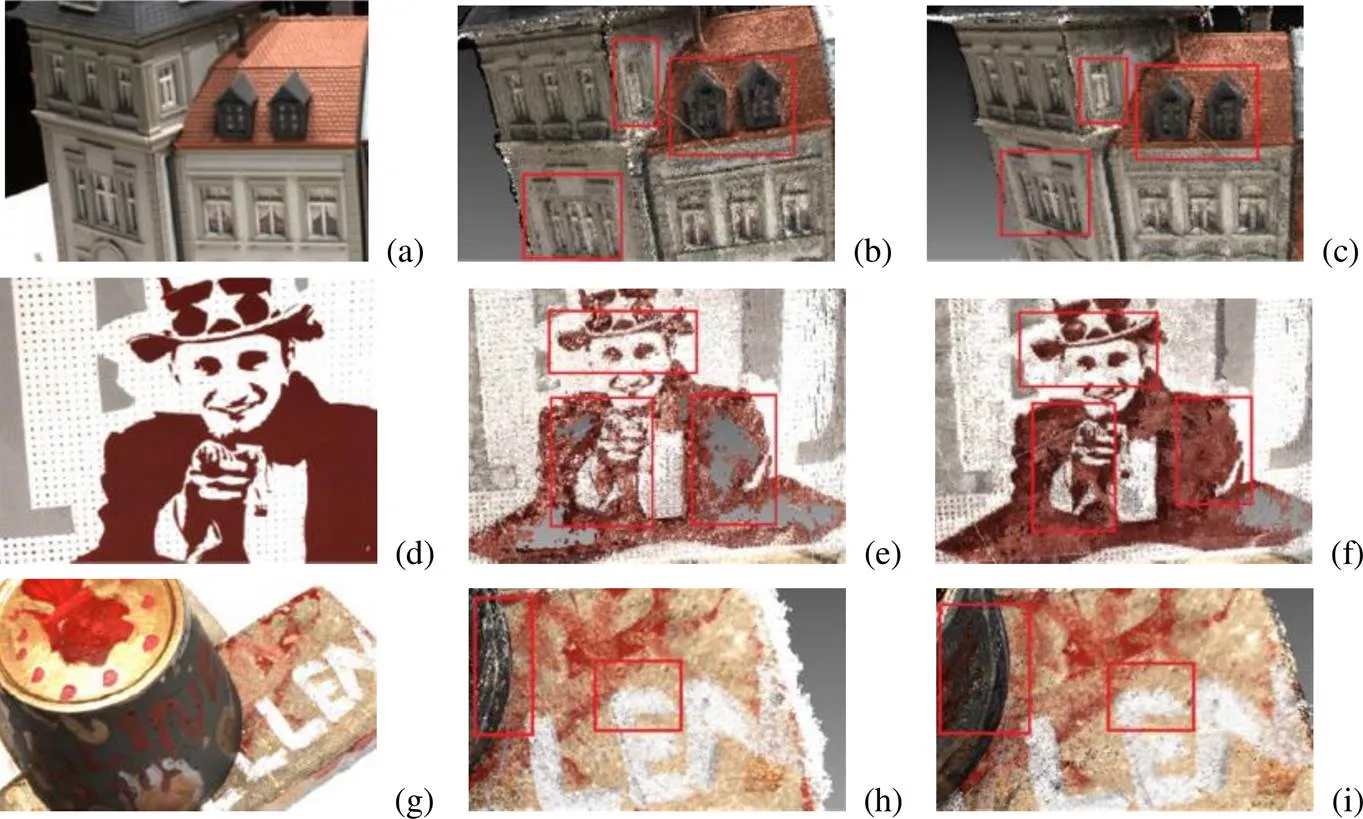
图5 本文与R-MVSNet在DTU测试数据集上定性结果比较((a),(d),(g)原图测试集;(b),(e),(h) R-MVSNet测试效果;(c),(f),(i) 本文测试效果)

图6 本文与R-MVSNet在Blended_MVS测试集上定性结果比较((a),(c),(e),(g)本文在教堂、房屋、博物馆、村庄的测试效果;(b),(d),(f),(h) R-MVSNet在教堂、房屋、博物馆、村庄的测试效果)
最后在自采集数据上进行测试并对比本文与R-MVSNet的重建效果,数据由五目相机进行拍摄,经过空三得到相机位姿作为输入数据集,在DTU数据集训练得出的模型下测试得到稠密重建效果。自采集数据包含2个场景工地和操场,如图7所示。图中对比了2个网络在自采集数据集上的效果,可以看出本文网络在细节和场景完整性上更有优势,即能够清楚地重建操场跑道的数字;也能够更完整地重建房屋,在建筑边缘上描述更准确;对于建筑材料和汽车能够更精细地描述。而R-MVSNet无法完成较准确的大场景重建。
2.4 消融实验
本节用消融实验来分析本文体系结构关键组件的效果,并与不同的网络体系结构进行比较,除自适应的深度图聚合模块,本次仅讨论从输入图像到深度图生成的过程。实验设置以Baseline,MVSNet,R-MVSNet,AACVP-MVSNet和本文作对比,并对照讨论各个网络在测试时的显存占用与生成稠密深度图的准确度与完整性(Acc,Comp),实验结果见表3。讨论了多尺度特征聚合模块和CNN_RNN正则模块带来的增益,各个网络分别代表不同组件的组合见表4,本网络的多尺度特征聚合模块相对于单纯的卷积特征提取在运行占用显存方面额外占用1.75 G,在完整性与准确度上也有提高。本文网络在测试时,在DTU数据集上800×600分辨率背景下仅占用显存4.16 G,作为对照组的R-MVSNet与MVSNet其测试运行时占用的显存分别为6.9 G和15.9 G,在准确度与完整性指标上本文也拥有优势。AACVP-MVSNet是目前排名靠前的多阶段方法,并使用由粗到细的深度推断结合自注意机制得到深度图,该网络虽然在准确性与完整性指标上略高于本文,但在显存占用上本网络有极大的优势,考虑到目前硬件限制是实际应用的门槛,本文网络综合表现良好。

图7 本文与R-MVSNet在自采集数据集上定性结果比较((a),(c),(e),(g)本文在跑道、房屋、建筑材料、停车场的测试效果;(b),(d),(f),(h)R-MVSNet在跑道、房屋、建筑材料、停车场的测试效果)
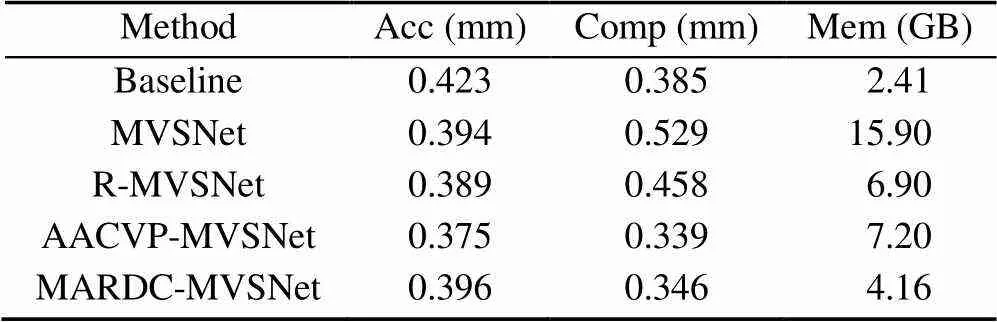
表3 DTU测试数据集上不同网络的指标效果和占用显存
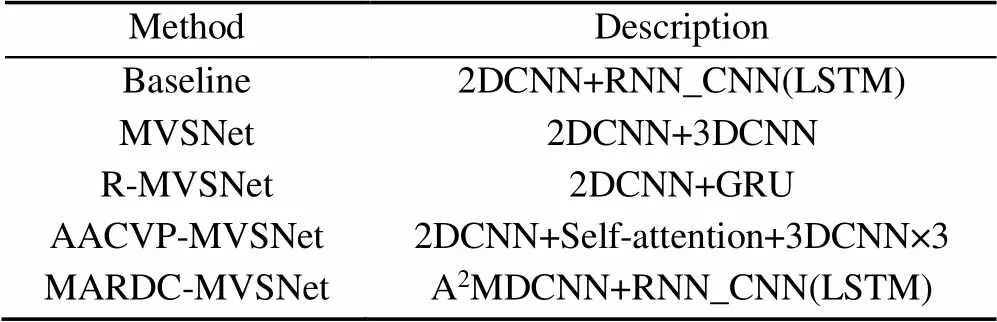
表4 网络的组件构成
其次,本文网络使用一种更节约显存的方式正则代价体,因此能够使用更高分辨率的图像进行重建。在设定=7和=512情况下,将重建结果与1600×1200和800×600的图像分辨率进行比较。由表5可知,指标越低越好,更大的分辨率会增加重建占用显存和运行时间,但在完整性和准确度上则有利于重建。对比同分辨率输入下的R-MVSNet和AACVP-MVSNet,本文网络的损耗和指标比R-MVSNet皆有所提升;与AACVP-MVSNet相比,本文网络在显存占用上具有优势,且拥有相近的完整性。这说明本文网络在DTU数据集上已超越经典的MVSNet,构建的三维模型更加完整。

表5 不同分辨率下的重建结果
3 结 论
本文提出了一种新型的MARDC-MVSNet网络。轻量级的多尺度特征聚合模块通过使用可变形卷积自适应的提取图像稠密特征,解决了传统的CNN无法有效处理反射面、弱纹理和无纹理区域的问题。在深度图生成的代价体正则过程中,不再使用3D CNN与GRU模块,而是使用一种融合了LSTM的卷积在深度方向上分层地处理代价图,这大大地降低了重建所需显存。以参考图像为引导使用深度残差学习网络优化初始深度图解决边界过平滑现象,使深度图表述更准确。本文方法与其他先进方法相比,实现了相当或更好地重建结果,同时更加高效和节省内存消耗。实验证明,本文方法在DTU数据集上有效地提高了重建场景的完整性,特别的,其显存消耗只有R-MVSNet的60%,并能扩展到Blended_MVS数据集与自采样数据集上,有很强的通用性。
本文网络的不足之处为运行时间较长,当数据量庞大时无法实时运行。因此接下来的研究方向为结合多阶段思想加速深度图的生成。
[1] SCHÖNBERGER J, ZHENG E, FRAHM J. Pixelwise view selection for unstructured multi-view stereo[C]//European Conference on Computer Vision. Cham: Springer International Publishin, 2016: 501-518.
[2] CAMPBELL N, VOGIATZIS G, HERNÁNDEZ C. Using multiple hypotheses to improve depth-maps for multi-view stereo[C]//European Conference on Computer Vision. Heidelbeg: Springer, 2008: 766-779.
[3] FURUKAWA Y, PONCE J. Accurate, dense, and robust multiview stereopsis[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 32(8): 1362-1376.
[4] BARNES C, SHECHTMAN E, FINKELSTEIN A, et al. PatchMatch: a randomized correspondence algorithm for structural image editing[J]. ACM Transactions on Graphics, 2009, 28(3): 24l.
[5] FLYNN J, NEULANDER I, PHILBIN J. Deepstereo: Learning to predict new views from the world's imagery[C]// The IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 5515-5524.
[6] JI M, GALL J, ZHENG H, et al. Surfacenet: an end-to-end 3d neural network for multiview stereopsis[C]//The IEEE International Conference on Computer Vision. New York: IEEE Press, 2017: 2307-2315.
[7] HUANG P, MATZEN K, KOPF J. Deepmvs: learning multi-view stereopsis[C]//The IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 2821-2830.
[8] IM S, JEON H, LIN S, et al. Dpsnet: end-to-end deep plane sweep stereo[EB/OL]. [2022-02-10]. https://arxiv.org/pdf/ 1905.00538.pdf.
[9] CHEN R, HAN S, XU J, et al. Point-based multi-view stereo network[C]//The IEEE/CVF International Conference on Computer Vision. New York: IEEE Press, 2019: 1538-1547.
[10] LUO K, GUAN T, JU L, et al. P-mvsnet: learning patch-wise matching confidence aggregation for multi-view stereo[C]//The IEEE/CVF International Conference on Computer Vision. New York: IEEE Press, 2019: 10452-10461.
[11] SCHÖNBERGER J L, FRAHM J M. Structure-from-motion revisited[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 4104-4113.
[12] KUTULAKOS K, SEITZ S. A theory of shape by space carving[J]. International Journal of Computer Vision, 2000, 38(3): 199-218.
[13] SEITZ S, DYER C. Photorealistic scene reconstruction by voxel coloring[J]. International Journal of Computer Vision, 1999, 35(2): 151-173.
[14] LHUILLIER M, QUAN L. A quasi-dense approach to surface reconstruction from uncalibrated images[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(3): 418-433.
[15] GALLIANI S, LASINGER K, SCHINDLER K. Massively parallel multiview stereopsis by surface normal diffusion[C]// 2015 IEEE International Conference on Computer Vision. New York: IEEE Press, 2015: 873-881.
[16] YAO Y, LUO Z X, LI S W, et al. MVSNet: depth inference for unstructured multi-view stereo[M]//Computer Vision - ECCV 2018. Cham: Springer International Publishing, 2018: 785-801.
[17] YAO Y, LUO Z X, LI S W, et al. Recurrent MVSNet for high-resolution multi-view stereo depth inference[C]//The IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2019: 5520-5529.
[18] HUANG B, YI H, HUANG C, et al. M3VSNet: Unsupervised multi-metric multi-view stereo network[C]//2021 IEEE International Conference on Image Processing. New York: IEEE Press, 2021: 3163-3167.
[19] YU Z, GAO S. Fast-mvsnet: sparse-to-dense multi-view stereo with learned propagation and Gauss-Newton refinement[C]// The IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 1949-1958.
[20] COLLINS R T. A space-sweep approach to true multi-image matching[C]//The CVPR IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 1996: 358-363.
[21] GU X, FAN Z, ZHU S, et al. Cascade cost volume for high-resolution multi-view stereo and stereo matching[C]//The IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 2495-2504.
[22] YU A Z, GUO W Y, LIU B, et al. Attention aware cost volume pyramid based multi-view stereo network for 3D reconstruction[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2021, 175: 448-460.
[23] ZHANG J, YAO Y, LI S, et al. Visibility-aware multi-view stereo network[EB/OL]. [2022-02-10]. https://arxiv.org/pdf/ 2008.07928.pdf.
[24] YAN J F, WEI Z Z, YI H W, et al. Dense hybrid recurrent multi-view stereo net with dynamic consistency checking[M]// Computer Vision - ECCV 2020. Cham: Springer International Publishing, 2020: 674-689.
[25] SHI X J, CHEN Z R, WANG H, et al. Convolutional LSTM network: a machine learning approach for precipitation nowcasting[EB/OL]. [2022-02-10]. https://arxiv.org/pdf/1506. 04214.pdf.
[26] AANÆS H, JENSEN R R, VOGIATZIS G, et al. Large-scale data for multiple-view stereopsis[J]. International Journal of Computer Vision, 2016, 120(2): 153-168.
[27] YAO Y, LUO Z X, LI S W, et al. BlendedMVS: a large-scale dataset for generalized multi-view stereo networks[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 1787-1796.
Dense point cloud reconstruction network using multi-scale feature recursive convolution
WANG Jiang-an, PANG Da-wei, HUANG Le, QING Lin-zhen
(School of Information Engineering, Chang’an University, Xi’an Shaanxi 710064, China)
In the task of 3D reconstruction, it is difficult to deal with the traditional multi view stereo algorithm because of the large photometric consistency measurement error in the weak texture region. To solve this problem, a recursive convolution network of multi-scale feature aggregation was proposed, named MARDC-MVSNet (multi-scale aggregation recursive multi view stereo net with dynamic consistency), which was utilized for dense point cloud reconstruction in weak texture areas. In order to boost the resolution of the input image, this method used a lightweight multi-scale aggregation module to adaptively extract image features, thereby addressing the problem of weak texture or even no texture region. In terms of cost volume regularization, a hierarchical processing network with recursive structure was used to replace the traditional 3D CNN (convolutional neural networks), greatly reducing the occupation of video memory and realizing high-resolution reconstruction at the same time. A depth residual network module was added at the end of the network to optimize the initial depth map generated by the regularized network under the guidance of the original image, so as to produce more accurate expressions of the depth map. The experimental results show that excellent results were achieved on the DTU data set. The proposed network can not only achieve high accuracy in depth map estimation, but also save hardware resources, and it can be extended to aerial images for practical engineering.
deep learning; computer vision; remote sensing mapping; 3D reconstruction; multi view stereo; recurrent neural network
TP 391
10.11996/JG.j.2095-302X.2022050875
A
2095-302X(2022)05-0875-09
2022-04-15;
2022-06-29
15 April,2022;
29 June,2022
国家自然科学基金面上项目(61771075);陕西省自然科学基金项目(2017JQ6048);广西精密导航技术与应用重点实验室项目(DH201711)
National Natural Science Foundation of China (61771075); Natural Science Foundation of Shaanxi Province (2017JQ6048); Guangxi Key Laboratory of Precision Navigation Technology and Application, Guilin University of Electronic Technology (DH201711)
王江安(1981-),男,副教授,博士。主要研究方向为计算机视觉与三维建模。E-mail:wangjiangan@126.com
WANG Jiang-an (1981-), associate professor, Ph.D. His main research interests cover computer vision and 3D modeling. E-mail:wangjiangan@126.com
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
计算机应用(2019年3期)2019-07-31 12:14:01
数学年刊A辑(中文版)(2019年1期)2019-01-31 02:35:44
数学杂志(2018年5期)2018-09-19 08:13:48
数学物理学报(2017年5期)2017-11-23 07:51:31
软件导刊(2016年9期)2016-11-07 22:22:57
科技视界(2016年2期)2016-03-30 11:17:03
数学年刊A辑(中文版)(2014年5期)2014-11-01 05:43:38
新课程学习·中(2013年3期)2013-06-14 05:55:20
