
基于优化YOLOv5s的跌倒人物目标检测方法
2022-11-03 02:57:00武历展王夏黎王炜昊
图学学报 2022年5期
武历展,王夏黎,张 倩,王炜昊,李 超
基于优化YOLOv5s的跌倒人物目标检测方法
武历展,王夏黎,张 倩,王炜昊,李 超
(长安大学信息工程学院,陕西 西安 710064)
针对目标检测模型在人物跌倒时易漏检、鲁棒性和泛化能力差等问题,提出一种基于改进YOLOv5s的跌倒人物目标检测方法YOLOv5s-FPD。首先,对Le2i跌倒数据集使用多种方式扩充后用于模型训练,增强模型鲁棒性和泛化能力;其次,使用MobileNetV3作为主干网络来进行特征提取,协调并平衡模型的轻量化和准确性关系;然后,利用BiFPN改善模型多尺度特征融合能力,提高了融合速度和效率,并使用CBAM轻量级注意力机制实现注意力对通道和空间的双重关注,增强了注意力机制对模型准确性地提升效果;最后,引入Focal Loss损失评价从而更注重挖掘困难样本特征,改善正负样本失衡的问题。实验结果表明,在Le2i跌倒数据集上YOLOv5s-FPD模型比原YOLOv5s模型,在精确度、F1分数、检测速度分别提高了2.91%,0.03和8.7 FPS,验证了该方法的有效性。
目标检测;YOLOv5s;MobileNetV3;轻量级注意力;多尺度特征融合;焦点损失函数
医学调查表明,老年人在跌倒后得到及时救治可降低80%的死亡风险[1-2]。对于需要智能看护的老人,必然对目标检测系统的准确性、鲁棒性等有极高地要求。
传统的基于构建手工特征的目标检测方法,由于缺乏有效的图像特征表示只能设计较为复杂的表示方法,里程碑检测器有VJ Det.[3],HOG Det.[4]和DPM[5],但随着手工特征性能趋于饱和而发展缓慢。
基于卷积神经网络(convolutional neural network,CNN)的目标检测模型研究可按检测阶段分为两类,一类是基于候选框的两阶段检测方法,如R-CNN[6],Fast R-CNN[7],Faster R-CNN[8]和Mask R-CNN[9];另一类是基于免候选框的单阶段检测方法,如SSD[10]和YOLO[11]系列均为典型的基于回归思想的单阶段检测方法。
REDMON和FARHADI[12]首次提出YOLO,借鉴Faster R-CNN的设计思想将整个图像输入神经网络,直接在输出阶段预测目标位置和标签;随后YOLOv2采用了批量归一化、高分分类器和先验框等优化策略,加速网络收敛性能并移除全连接层,重新引入锚框使得网络定位更加准确。YOLOv3[13]引入了特征金字塔网络[14](feature pyramid network,FPN)和Darknet53网络,允许改变网络结构以权衡速度与精度,计算速度大幅提高,并引入残差结构将主干网络做的更深,提升语义特征丰富性。BOCHKOVSKIY等[15]基于文献[12]进行改进提出了YOLOv4目标检测模型,通过大量的调参实验,在输入网络分辨率、卷积层数和参数数量间找到最佳平衡,实现了综合性能的提升。
在基于YOLO的轻量化目标检测优化部署方案中,文献[16]使用YOLOv4作为基础优化检测老人跌倒行为;文献[17]融合运动特征提升跌倒检测算法精度;文献[18]基于ShuffleNet V2进行特征提取,并利用融合后的网络对原始YOLOv5的主干网络进行重构;文献[19]采用MobileNet轻量化网络进行快速目标检测。
经过实验发现,现有的目标检测模型在检测人物发生跌倒时,仍然存在目标检测漏检率高、模型鲁棒性和泛化能力差等问题。针对此问题,本文提出了一种基于改进YOLOv5s的跌倒人物目标检测模型YOLOv5s-FPD,并在Le2i跌倒数据集上验证,相较于用YOLOv5s检测人物目标,新模型的精确度、F1分数、检测速度分别提高了2.91%,0.03和8.7 FPS,在提升准确性的同时,具有更小的参数量、更强的鲁棒性和泛化能力。
1 YOLOv5目标检测模型
2020年由Ultralytics发布的YOLOv5在网络轻量化上贡献明显,检测速度更快也更加易于部署。与之前版本不同,YOLOv5实现了网络架构的系列化,分别是YOLOv5n,YOLOv5s,YOLOv5m,YOLOv5l和YOLOv5x。这5种模型的结构相似,通过改变宽度倍数(Depth multiple)来改变卷积过程中卷积核数量,还通过改变深度倍数(Width multiple)来改变BottleneckC3 (带3个CBS模块的BottleneckCSP结构)中C3的数量,从而实现不同网络深度和宽度之间的组合,达到精度与效率的平衡,见表1。
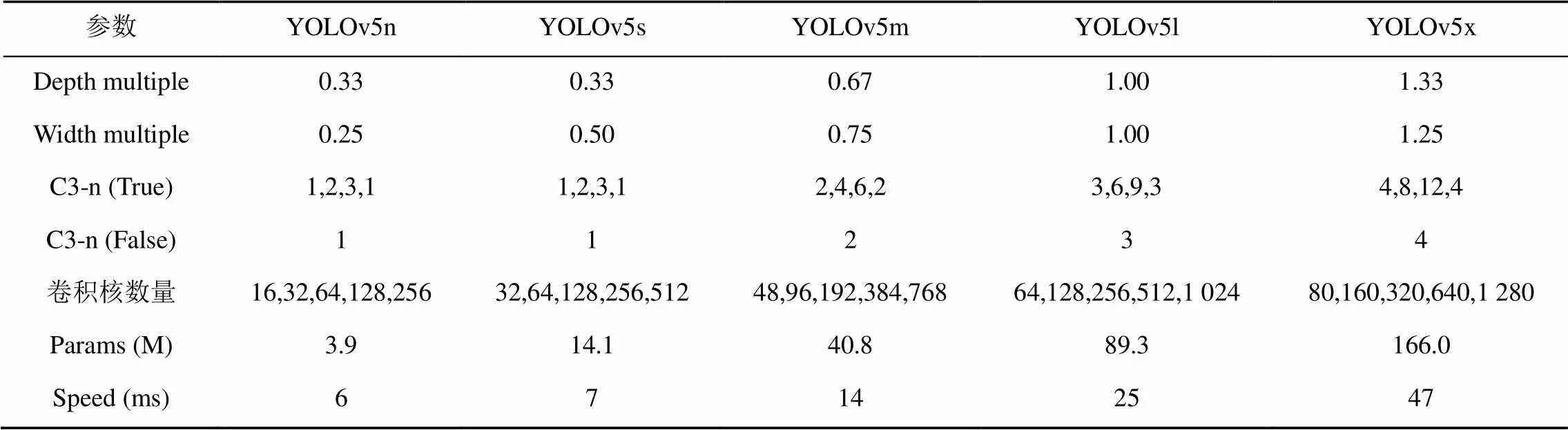
表1 YOLOv5不同版本的模型参数
在最新发布的YOLOv5模型中,YOLOv5n和YOLOv5s模型大小分别为3.87 M和14.1 M,均适合在主流移动设备或边缘设备上部署的低成本目标检测模型。本文的实验平台和环境为:640×640大小的图片,使用YOLOv5n进行目标检测,26.4%的图片出现人物漏检,平均每张图片检测耗时6 ms;使用YOLOv5s进行目标检测,13.8%的图片出现人物漏检,平均每张图片检测耗时7 ms。虽然YOLOv5n的单张图片检测耗时比YOLOv5s减少了1 ms,但目标漏检率增加了一倍,且增加的漏检主要集中在人物跌倒、下蹲等体态外形变化较大的场景,在准确性优先的智能看护系统中,会极大地降低结果可信度。综合考虑,本文选择YOLOv5s作为基础模型进行改进。
1.1 YOLOv5s模型结构
YOLOv5s模型的结构由4部分组成,如图1所示(基于YOLOv5s-6.0版本):①基于卷积网络的Backbone主干网络,主要提取图像的特征信息;②Head检测头,主要预测目标框和预测目标的类别;③主干网络和检测头之间的Neck颈部层;④预测层输出检测结果,预测出目标检测框和标签类别。

图1 YOLOv5s结构图
1.2 YOLOv5s模型算法流程和原理
YOLOv5s模型主要工作流程:
(1) 原始图像输入部分加入了图像填充、自适应锚框计算、Mosaic数据增强来对数据进行处理,以增加检测的辨识度和准确度[20]。
(2) 主干网络中采用Focus结构和CSP1_X(个残差结构,下同)结构进行特征提取。在特征生成部分,使用基于SPP[21]优化后的SPPF结构来完成。
(3) 将颈部层应用路径聚合网络[22](path- aggregation network,PANet)与CSP2_X进行特征融合。
(4) 使用GIOU_Loss作为损失函数。
2 跌倒人物目标检测模型改进
2.1 YOLOv5s主干网络优化
YOLOv5s中使用的CSPDarkNet53主干网络是在Darknet53中引入跨阶段局部网络[23](cross stage partial network,CSPNet),以提取有效的深度特征信息。但在实验中发现,只采用直接调整宽度倍数和深度倍数的方式来轻量化模型(宽度系数和深度系数小于1.0时),视频图像中的目标漏检问题较为严重,在Le2i数据集上,YOLOv5n,YOLOv5s和YOLOv5m的漏检率分别为26.4%,13.8%和10.4%。因此在考虑调整轻量化模型时,需引入特征提取能力更强的移动端轻量级主干网络MobileNet,将CSPDarkNet53替换为轻量级主干网络MobileNetV3[24],尝试达到轻量化、准确性和效率的协调平衡。
2.1.1 MobileNetV3原理
MobileNet (即MobileNetV1)是适合边缘设备中部署的轻量级CNN,可利用深度可分离卷积(depthwise separable convolution,DSC),改变卷积计算方法以降低网络参数量,平衡检测精度和检测速度。随之MobileNetV2[25]新增了2个特性:反向残差(Inverted Residuals)方法使得特征的传递能力更强,网络层数更深;线性瓶颈(Linear Bottleneck)模块取代非线性模块,降低了低层特征的损失。
2019年发布的MobileNetV3结合了V1和V2中的部分结构,整合优化并删除了V2体系结构中计算成本较高的网络层,引入SE-Net (squeeze-and- excitation networks)[26]轻量级注意力结构,资源低耗的同时精度几乎没有损失。
DSC由深度卷积(depthwise convolution,DW)和逐点卷积(pointwise convolution,PW)组成[27],如图2所示。DSC相比于传统卷积参数和计算量大为减少,二者计算量对比为
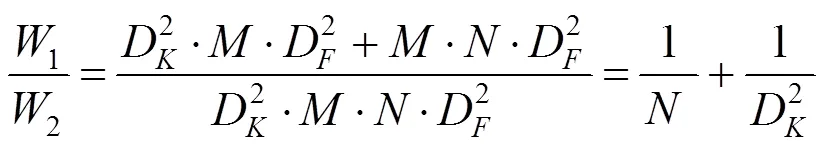
其中,W1,W2分别为DSC和传统卷积的计算成本。MobileNetV3特征提取的卷积核的尺寸主要为5×5。因此,DSC的计算成本约为传统卷积的1/25。残差结构与反向残差结构如图3所示,其中图3(a)为残差ResNet,图3(b)为反向残差。
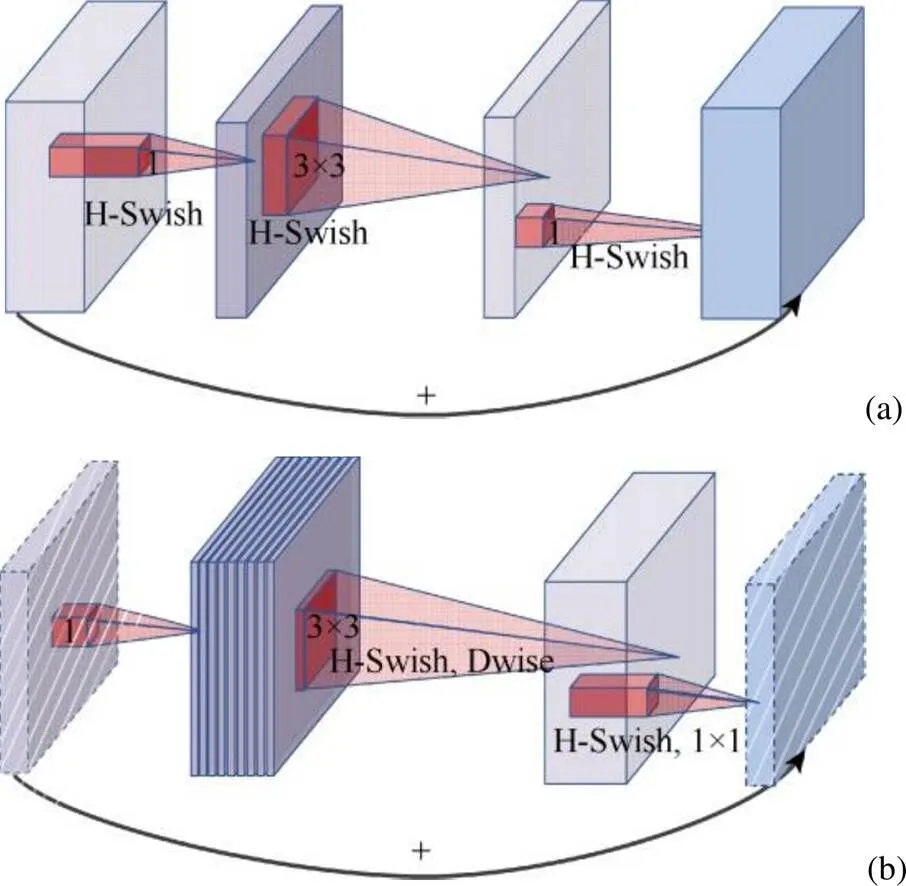
图3 残差结构和反向残差结构((a)残差结构;(b)反向残差结构)
反向残差结构利用点卷积将通道数扩增,然后在更高层中进行深度卷积,最后使用点卷积将通道缩减。反向残差网路借助于残差连接改善特征的梯度传播能力,使得网络层更深,同时网络使用更小的输入、输出维度,极大地降低网络的计算消耗和参数体积。另外反向残差网路具有高效的CPU和内存推理能力,能够构建灵活的移动端模型,从而适用于移动设备程序。
2.1.2 MobileNetV3宽度系数调整
MobileNet中提出了,2个超参数。其中作为宽度系数,可以调整卷积核的个数,将卷积核调整为原来的倍;用以控制输入图像尺寸。使用DSC调整后的计算量,即

宽度系数的调整可以直接将计算量、体积降低至1/2,极大地减少模型的参数量和计算量,而精度损失很小。本文设置=0.5。
2.2 YOLOv5s模型注意力机制的改进
实验中大部分漏检发生在目标大小突然剧烈变化时,特别是从完整的站立或行走状态的人物,突然剧烈变化为摔倒、蜷缩、下蹲的人体外形时,漏检率非常高。这也侧面说明YOLOv5s中原生的轻量级注意力机制SE-Net,在目标尺度突然剧烈变化时可能效果有限。
相比于SE-Net只注重通道像素的重要性[26],CBAM[28]作为一种轻量级的注意力模型,综合考虑了不同通道像素和同一通道不同位置像素在重要性上的区别,是一种简单、高效的注意力机制设计实现,计算消耗极小,且能与卷积网络无缝集成并用于端到端的训练。
通道注意力模块、空间注意力模块共同构成CBAM,输入特征会沿着顺序结构依次推断输入中所含的注意力特征,然后再将注意力特征向量和输入特征向量相乘来实现自适应特征优化。如图4所示。
相应的表达式为
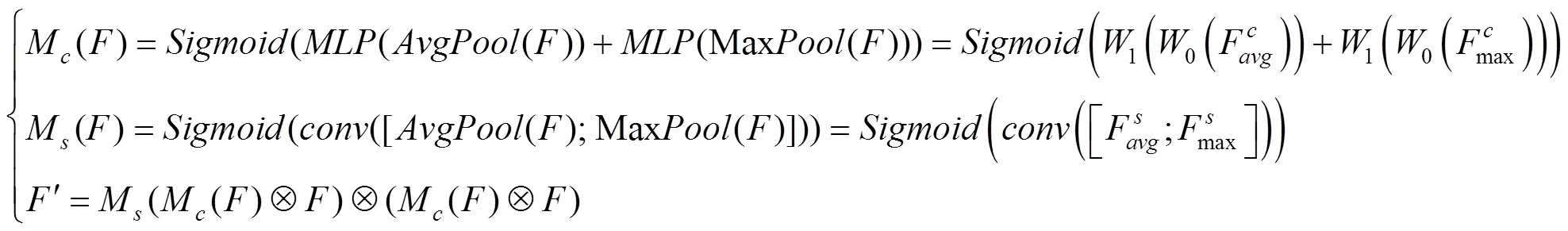
图4 通道和空间注意力机制((a)通道注意力机制;(b)空间注意力机制)
Fig. 4 Channel and spatial attention mechanisms ((a) Channel attention mechanism; (b) Spatial attention mechanism)
从图4(a)可以看出,通道注意力向量沿着空间维度运算得到特征向量,并与输入特征相乘。图4(b)表示空间注意力向量,沿着通道方向运算得到特征向量后与输入特征相乘。
在目标检测模型中用CBAM注意力机制替换SE-Net模块来优化目标检测精度,使目标特征提取更完全,从而改善人物姿势剧烈变化时出现的目标丢失问题。
2.3 YOLOv5s特征融合网络优化
颈部层可使主干网络提取的特征更充分地被利用,通常对各阶段直接增加由自底向上和自顶向下的路径,对各阶段的特征图进行再处理,实现各阶段特征图的多尺度融合,该方式主要用于生成FPN,FPN会增强模型对于不同缩放尺度对象的检测能力[14]。现常用的颈部结构有:FPN,PANet,NAS-FPN,BiFPN,且PANet比FPN和NAS-FPN更精确,但缺点是参数多和计算消耗大[29]。鉴于移动端或边缘设备上的资源约束,以优化模型大小和延迟导向来重新考虑YOLOv5s模型中的多尺度融合策略。
FPN为底层特征图提供了更多的语义信息,提高了小尺寸目标的检测效果。最近,研究人员在FPN的基础上设计实现了更多的跨尺度特征融合网络[29]。YOLOv5s的颈部结构部分采用了 PANet结构,如图5所示。
图5中FPN是普通的特征金字塔,包含自底向上和自顶向下双向通道特征提取路径,从而融合高分辨率的低层和语义信息丰富的高层[14]。
PANet 结构是在FPN的基础上引入了自底向上路径增强结构,使得高层特征直接获取低层更多的位置信息,另外从结构中也能看到其特点是反复的特征提取,因此需要更多的计算消耗,模型体积也更大。为优化YOLOv5s-FPD的结构,利用加权双向特征金字塔网络BiFPN来减少特征融合不必要的计算,其改进如图6所示。
BiFPN特征融合设计如图6(c)中所示,对应的融合计算过程(其他层类似)为
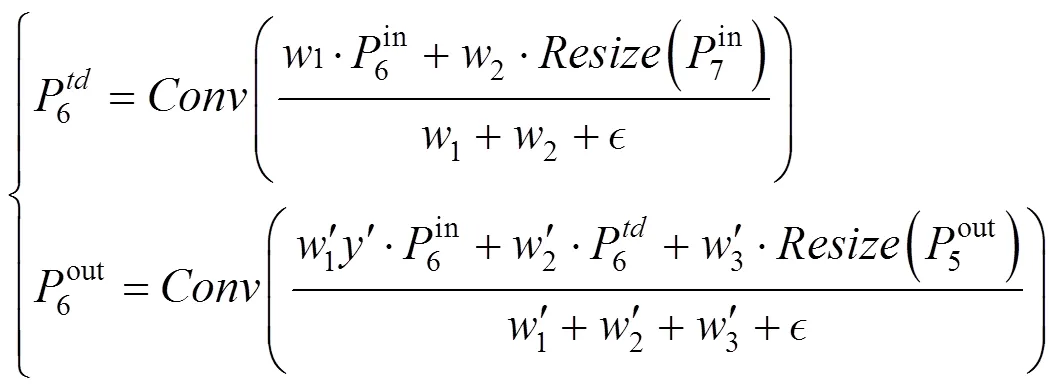
BiFPN优化跨尺度连接的思想和策略主要是:移除对融合贡献率小的结点,在同层的结点间添加跳跃连接,以实现同层和更高层次的特征融合效率[29]。
如图7所示,DSC融合特征被送入分类回归网络,网络权重在所有级别的特性之间共享,在每次卷积后进行批归一化和激活,实现BiFPN的双向跨尺度连接和快速归一化融合[29]。

图5 PANet结构图

图6 特征网络设计((a)FPN结构设计;(b)PANet结构设计;(c)BiFPN结构设计)
2.4 焦点损失函数的改进
通常情况下对目标检测而言,正样本数量要远小于负样本数量,从而造成样本失衡,可致训练过程中特征较少而影响网络模型的收敛性和准确性[30]。样本失衡问题不仅包括正负样本数量的不平衡性,同时也可以表现为难分和易分样本的数量不平衡。评估目标检测中的总损失,往往期望更关注模型在正样本和难分样本目标检测时的准确性和鲁棒性,但模型评估中负样本和易分样本的损失比例过大,从而造成损失评估偏离理想方向。另外易分样本的易收敛性也会直接导致数量不占优的难分样本的特征提取不充分。
文献[30]认为,样本失衡是导致单阶段目标检测算法准确性不如两阶段的主要原因。焦点损失函数(focal loss,FL)降低了低特征贡献率的负样本在特征提取时所占比重,是一种简单直接地提取难分样本特征的方法,用于解决样本失衡和提高目标检测算法的准确度。
在YOLOv5中使用交叉熵二分类损失评估,即

其中,为真实标记数值;ʹ为经过激活函数的检测概率值(在0~1之间)。正样本的ʹ数值与损失成反比,负样本的ʹ数值与损失成正比。这样的损失评估方式在难分样本数量占劣的迭代过程中,收敛缓慢甚至可能根本无法找到最优解[30],因此考虑使用基于二分类交叉熵的Focal Loss损失函数进行改进,即

式(6)中加入了因子,以减少易分样本的关注度,训练中用训练时间去提取难分或易错分的样本特征,以加强这些样本的特征提取能力、识别能力和鲁棒性。另外单纯依靠关注度因子去平衡样本数量比例无法解决前文中所提到的特征贡献率问题,因此增加特征贡献率因子来调节2种样本的特征权重贡献率为

关注度调整因子的影响力随着的变化而变化(=0时退化为交叉熵二分类损失函数),实验[30]采用最优,数值分别为=0.25,=2。
3 实验结果及对比分析
3.1 实验环境
本次实验均在表2的实验平台中进行。

表2 实验平台
3.2 实验所用数据集
3.2.1 数据集获取
本文实验的数据集来源见表3。
其中使用Le2i数据集(Le2i Dataset)作为训练测试验证数据集,使用UR数据集(UR Dataset)和Multiple数据集(Multiple Dataset)的部分视频图像用于评估YOLOv5s-FPD模型的泛化能力和鲁棒性。

表3 跌倒检测的数据集
3.2.2 数据集标注
对于无标注的数据集部分,本文使用LabelImg标注。
3.2.3 数据集扩充与划分
本文利用多种方式的图像转换,对所用的跌倒目标数据集进行扩充操作,分别使用表4中的对称翻转、运动模糊、高斯模糊、亮度对比度变换、图像旋转来处理原始数据集。
图8展示了Le2i数据集中选取的3种跌倒姿势图像经扩充变换处理后的效果。

表4 跌倒数据集扩充操作

图8 图像变换效果对比((a)原图;(b)对称翻转;(c)运动模糊;(d)添加高斯噪声;(e)亮度对比变换;(f)图像旋转)
Le2i数据集共包含191个视频文件合计75 911帧(其中132个跌倒视频,59个非跌倒视频),使用表4中的5种图像变换方式扩充后,共1 146个视频文件(其中792个跌倒视频,354个非跌倒视频),使用脚本将全部视频按照8∶1∶1的比例随机划分为训练集、测试集和验证集,具体视频文件数量分别为训练集917个、测试集115个和验证集114个。
3.2.4 训练过程
YOLOv5s-FPD采用了多尺度训练方式迭代300轮,初始学习率0.000 1,输入图像大小为640×640,批处理大小16。另外设交并比(intersection over union,IoU)等于0.5以区分正、负样本。
3.3 模型算法评价指标
本文选取了反映目标检测模型检测水平的6种常用评价指标,对改进后的检测网络模型进行评价。
(1) 精确度(Precision,P)、召回率(Recall,R)和1分数

其中,T为跌倒目标被正确检测出来的数量;F为被跌倒误检的目标数量;F为跌倒未被检测出的样本数量;
1分数可以看作是模型精确率和召回率的一种调和平均,同时兼顾了分类模型的精确率和召回率。
(2) 平均精度(average precision,AP)、平均精度均值(mean average precision,mAP)为

其中,N为类别个数;为不同类别的平均精度。得到每一类的值后,将其平均就得到。
(3) 帧速(frames per second,FPS):通常用来衡量目标检测模型的实时性,其表示神经网络每秒能处理图片的数量。
3.4 消融实验
YOLOv5s-FPD对YOLOv5s模型的特征提取、注意力机制和特征融合方法进行了改进,同时引入了焦点损失函数。为评估不同模块改动和不同模块组合对于算法性能优化的程度,设计了消融实验,消融实验数据见表5。
消融实验数据表明,每种改进对最终结果产生了不同程度的优化,如:
实验2表明,引入MobileNetV3降低了3.2%目标漏检率的同时帧速度提高约10 FPS;实验3和实验4表明,CBAM和BiFPN对于识别准确率的贡献相对较为明显,mAP分别提升2.1%和2.0%;实验5表明,焦点损失优化对漏检率影响较大,本文可降低5.5%的人物漏检率。
不同的组合对模型整体表现也基本呈现正向优化,对比实验12和实验16,mAP提升1.9%的同时,体积仅增加0.7 M,漏检率减少了1.3%,与实验5比较,也说明MobileNetV3和CBAM,BiFPN结合,在降低漏检率的同时,也削弱焦点损失函数对漏检率的优化程度。对比实验13和实验16,二者在帧速上的区别,也验证了BiFPN具有更强的特征融合能力和效率。对比实验14和实验16,mAP提升3.4%的同时,模型体积仅增加了0.2 M,表明了CBAM轻量级注意力模型,能以极小的代价提高模型精度。对比实验15和实验16,MobileNetV3的能力主要体现在对模型体积、速度和漏检率上,同时mAP参数仍然有1.1%的提升。
4种不同策略的组合,产生的优化结果不同,例如实验9虽然比实验16的mAP高出0.2%,但漏检率却差了近一倍,所以说明其策略组合并不理想。同时采用4种策略,虽然某种程度上可能会削弱单个策略的优化程度,但却取得了5.2%的最低漏检率,同时保持了精确度、速度和模型大小的较优值,达到了本文环境中的较为理想的平衡效果。
3.5 对比实验
使用基于Le2i数据扩充的跌倒人物数据集分别训练SSD,Faster-RCNN,YOLOv4,YOLOv5s和YOLOv5s-FPD模型,结果见表6。

表5 消融实验结果对比
注:●为采用此策略;○为不采用此策略

表6 4种算法的性能对比
通过表6可知,在相同的Le2i数据集上,YOLOv5s-FPD算法的检测精度为92.49%,相比SSD,Faster RCNN,YOLOv4 和YOLOv5s算法,精确度分别提高了3.52%,1.79%,1.61%和2.91%,以上说明YOLOv5-FPD具有更好的准确性。
在模型的体积上,YOLOv5s-FPD具有最小的体积7.9 M,远小于SSD,Faster RCNN和YOLOv4模型,并且体积只是YOLOv5s体积的56%。
同时,从检测速度上而言,YOLOv5s-FPD 的检测速率优于SSD,Faster RCNN,YOLOv4和YOLOv5s模型,YOLOv5s-FPD比Faster RCNN检测速率快了24.2倍,比YOLOv4模型快了2.22倍;YOLOv5s-FPD与SSD算法相比,虽然检测速率只快了3.2 FPS,但检测精度大幅度提升,F1分数提升了0.04。YOLOv5s-FPD与YOLOv5算法相比,F1分数提升了0.03,同时检测速率快了8.7 FPS。以上表明了YOLOv5-FPD具有更好的实时性。
实验训练得到YOLOv5s-FPD模型的P-R (Precision-Recall)曲线,如图9所示。由P-R曲线可知,绝大部分时,灰色曲线表示的falling person类别都比红色曲线表示的person类别更靠近坐标(1,1)位置,表示前者的准确性更高,同时蓝色曲线表示的全部类别平均精度,也比person类别曲线更高,YOLOv5s-FPD模型精度提升明显。

图9 YOLOv5s-FPD的P-R曲线
3.6 视频检测结果
在跌倒初期(身体有摔倒倾向时)和跌倒中期(身体开始倒向地面)漏检情况极少,漏检高频发生主要集中跌倒末期(身体基本贴近地面)和特殊视角检测时,常见的几种情况有:①待检测目标身体呈现遮挡,腿部和躯干遮挡较多,严重时只有单臂和头部可见;②躯干与地面倾斜到特殊角度;③特殊视角检测时,人体外形呈现为中小目标或倒置、旋转目标。在这些常见的跌倒漏检视频上验证YOLOv5s-FPD检测效果。
图10中2个验证视频来源于Le2i数据集中的Coffee room环境,该数据集环境只有一个摄像视角为45°斜向下近景,YOLOv5s-FPD算法解决了图10(a)中的漏检情况,并提高了图10(c)5%的检测置信度。

图10 Le2i数据集Coffee room检测结果((a)漏检问题改善前;(b)漏检问题改善后;(c)置信度提高前;(d)置信度提高后)
图11的2个验证视频来源于Multiple数据集,该数据集环境有8个摄像角度,选取2个摄像视角为45°斜向下远景,YOLOv5s-FPD算法解决了图11(a)的漏检情况,并提高了图11(c)情况中24%的检测置信度。

图11 Multiple数据集检测结果一((a)漏检改善前;(b)漏检改善后;(c)置信度提高前;(d)置信度提高后)
当人物目标动作相对缓慢,人物外形特征也较为明显,遮挡也只发生在身体的下半部分,YOLOv5s检测仍然有效,图12中的目标人物,反映了YOLOv5s-FPD只提高检测置信度的情况,如图12(b)和图12(d),分别提高了4%和6%。
训练数据集的图像绝大部分都是人体与图像的上下两部分对应,而不是相反,这也导致了特殊视角下的人物目标检测(比如摄像视角位于人物的正上方)困难,对人物检测模型提出新的挑战。图13反映了YOLOv5s-FPD解决正上方视角下的目标漏检问题,效果如图13(d),并且提高了水平视角下的人物检测置信度,效果如图13(b)。
从Le2i和UR 2个跌倒数据集中选取漏检率比较高、遮挡严重的视频,来测试模型在目标遮挡时的鲁棒性,如图14所示。肢体发生遮挡,如图14(b)为下肢遮挡时检测结果,图14(d)为部分躯干遮挡时检测结果,YOLOv5s-FPD也能够以较低的置信度来检测出人物目标。因此对于解决或改善一些典型漏检情况,如特殊视角或遮挡情况下的目标检测,YOLOv5s-FPD的鲁棒性更强。

图12 Multiple数据集检测结果二((a)置信度提高前;(b)置信度提高后;(c)置信度提高前;(d)置信度提高后)

图13 UR数据集检测结果((a)置信度提高前;(b)置信度提高后;(c)漏检改善前;(d)漏检改善后)

图14 遮挡时的检测结果((a)下肢遮挡改善前;(b)下肢遮挡改善后;(c)躯干遮挡改善前;(d)躯干遮挡改善后)
4 结束语
YOLOv5s-FPD使用MobileNetV3进行特征提取来改善原生YOLOv5s的轻量化方法对模型准确性的影响,并引入CBAM轻量化注意力机制和焦点损失函数来提升检测模型的特征提取能力。实验结果表明,使用YOLOv5s-FPD模型的目标漏检率大大降低,同时模型体积和检测速度均有了一定程度的优化,泛化能力和鲁棒性更强,更易于作为智能看护系统的基础模型部署在移动设备和边缘设备上,具有一定的实际意义和社会价值。
[1] 黄明安, 陈钰. 中国人口老龄化的现状及建议[J]. 经济研究导刊, 2018(10): 54-58, 66.
HUANG M G, CHEN Y. The status quo and advice of China’s ageing[J]. Economic Research Guide, 2018(10): 54-58, 66 (in Chinese).
[2] GE Y F, WANG L J, FENG W M. et al. The challenge and strategy selection of healthy aging in China[J]. Journal of Management World 2020, 36:86-95.
[3] VIOLA P, JONES M. Rapid object detection using a boosted cascade of simple features[OE/BL]. [2021-06-12]. https:// ieeexplore.ieee.org/document/990517.
[4] DALAL N, TRIGGS B. Histograms of oriented gradients for human detection[C]//2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2005: 886-893.
[5] FELZENSZWALB P F, GIRSHICK R B, MCALLESTER D, et al. Object detection with discriminatively trained part-based models[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(9): 1627-1645.
[6] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2014: 580-587.
[7] GIRSHICK R. Fast R-CNN[C]//2015 IEEE International Conference on Computer Vision. New York: IEEE Press, 2015: 1440-1448.
[8] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[9] HE K M, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]//2017 IEEE International Conference on Computer Vision. New York: IEEE Press, 2017: 2980-2988.
[10] LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector[M]//Computer Vision - ECCV 2016. Cham: Springer International Publishing, 2016: 21-37.
[11] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 779-788.
[12] REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 6517-6525.
[13] REDMON J, FARHADI A. YOLOv3: an incremental improvement [EB/OL]. (2018-04-08) [2021-06-04]. https:// arxiv.org/abs/1804.02767.
[14] LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 936-944.
[15] BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: optimal speed and accuracy of object detection[EB/OL]. (2020-04-23) [2021-06-04]. https://arxiv.org/abs/2004.10934.
[16] 马敬奇, 雷欢, 陈敏翼. 基于AlphaPose优化模型的老人跌倒行为检测算法[J]. 计算机应用, 2022, 42(1): 294-301.
MA J Q, LEI H, CHEN M Y. Fall behavior detection algorithm for the elderly based on AlphaPose optimization model[J]. Journal of Computer Applications, 2022, 42(1): 294-301 (in Chinese).
[17] 曹建荣, 吕俊杰, 武欣莹, 等. 融合运动特征和深度学习的跌倒检测算法[J]. 计算机应用, 2021, 41(2): 583-589.
CAO J R, LYU J J, WU X Y, et al. Fall detection algorithm integrating motion features and deep learning[J]. Journal of Computer Applications, 2021, 41(2): 583-589 (in Chinese).
[18] 宋爽, 张悦, 张琳娜, 等. 基于深度学习的轻量化目标检测算法[J]. 系统工程与电子技术, 2022, 44(9): 2716-2725.
SONG S, ZHANG Y, ZHANG L N, et al. Lightweight target detection algorithm based on deep learning[J]. Systems Engineering and Electronics, 2022, 44(9): 2716-2725 (in Chinese).
[19] 张陶宁, 陈恩庆, 肖文福. 一种改进MobileNet_YOLOv3网络的快速目标检测方法[J]. 小型微型计算机系统, 2021, 42(5): 1008-1014.
ZHANG T N, CHEN E Q, XIAO W F. Fast target detection method for improving MobileNet_YOLOv3 network[J]. Journal of Chinese Computer Systems, 2021, 42(5): 1008-1014 (in Chinese).
[20] 许德刚, 王露, 李凡. 深度学习的典型目标检测算法研究综述[J]. 计算机工程与应用, 2021, 57(8): 10-25.
XU D G, WANG L, LI F. Review of typical object detection algorithms for deep learning[J]. Computer Engineering and Applications, 2021, 57(8): 10-25 (in Chinese).
[21] HE K M, ZHANG X Y, REN S Q, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[C]//IEEE Transactions on Pattern Analysis and Machine Intelligence. New York: IEEE Press, 2014: 1904-1916.
[22] LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 8759-8768.
[23] WANG C Y, MARK LIAO H Y, WU Y H, et al. CSPNet: a new backbone that can enhance learning capability of CNN[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. New York: IEEE Press, 2020: 1571-1580.
[24] HOWARD A, SANDLER M, CHEN B, et al. Searching for MobileNetV3[C]//2019 IEEE/CVF International Conference on Computer Vision. New York: IEEE Press, 2019: 1314-1324.
[25] SANDLER M, HOWARD A, ZHU M L, et al. MobileNetV2: inverted residuals and linear bottlenecks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 4510-4520.
[26] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 7132-7141.
[27] HOWARD A G, ZHU M, CHEN B, et al. MobileNets: efficient convolutional neural networks for mobile vision applications[EB/OL]. [2021-06-23]. https://arxiv.org/abs/1704. 04861.
[28] WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[M]//Computer Vision - ECCV 2018. Cham: Springer International Publishing, 2018: 3-19.
[29] TAN M X, PANG R M, LE Q V. EfficientDet: scalable and efficient object detection[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition . New York: IEEE Press, 2020: 10778-10787.
[30] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]//2017 IEEE International Conference on Computer Vision. New York: IEEE Press, 2017: 2999-3007.
An object detection method of falling person based on optimized YOLOv5s
WU Li-zhan, WANG Xia-li, ZHANG Qian, WANG Wei-hao, LI Chao
(School of Information Engineering, Chang’an University, Xi’an Shaanxi 710064, China)
To address the problems of easy missing, poor robustness and generalization ability when object detection model is detecting a person falling down, a new detection method YOLOv5s-FPD was proposed based on the improved YOLOv5s. Firstly, the Le2i fall detection data set was expanded in various ways for model training to enhance model robustness and generalization ability. Secondly, MobileNetV3 was employed as the backbone network for feature extraction, which could coordinate and balance the relationship between lightness and accuracy of the model. Furthermore, BiFPN (bi-directional feature pyramid network) was utilized to boost model multi-scale feature fusion ability, thereby improving the efficiency and speed of fusion. Meanwhile, the CBAM (convolutional block attention module) lightweight attention mechanism was adopted to realize double focus attention to channel and space, enhancing the effect of attention mechanism on model accuracy. Finally, Focal Loss evaluation was used to pay more attention to hard example mining and alleviate the samples imbalance problem. The experimental results show that the precision, F1score, and detection speed of YOLOv5s-FPD model were improved by 2.91%, 0.03, and 8.7 FPS, respectively, compared with the original YOLOv5s model on Le2i fall detection dataset, which verified the effectiveness of the proposed method.
object detection; YOLOv5s; MobileNetV3; lightweight attention; multi-scale feature fusion; focal loss function
TP 391
10.11996/JG.j.2095-302X.2022050791
A
2095-302X(2022)05-0791-12
2022-04-13;
2022-06-10
13 April,2022;
10 June,2022
国家自然科学基金项目(51678061)
National Natural Science Foundation of China (51678061)
武历展(1989-),男,硕士研究生。主要研究方向为图形图像处理、目标检测与动作识别。E-mail:1215719889@qq.com
WU Li-zhan (1989-), master student. His main research interests cover graphic image processing, object detection and action recognition. E-mail:1215719889@qq.com
王夏黎(1965-),男,副教授,博士。主要研究方向为图形图像处理与模式识别。E-mail:1225947082@qq.com
WANG Xia-li (1965-), associate professor, Ph.D. His main research interests cover graphic image processing and pattern recognition. E-mail:1225947082@qq.com
猜你喜欢
核科学与工程(2021年4期)2022-01-12 06:30:22
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
电子制作(2019年11期)2019-07-04 00:34:38
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
计算机应用(2018年5期)2018-07-25 07:41:26
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
数学学习与研究(2017年3期)2017-03-09 18:12:42
中国老区建设(2016年1期)2016-02-28 09:32:00
轴承(2015年2期)2015-07-25 03:51:04
