
东巴象形文字文档图像的文本行自动分割算法研究
2022-11-02 11:24康厚良杨玉婷
图学学报 2022年5期
康厚良,杨玉婷
东巴象形文字文档图像的文本行自动分割算法研究
康厚良1,杨玉婷2
(1. 苏州市职业大学体育部,江苏 苏州 215000;2. 苏州市职业大学计算机工程学院,江苏 苏州 215000)
以卷积神经网络(CNN)为代表的深度学习技术在图像分类和识别领域表现出了非常优异的性能。但东巴象形文字未有标准、公开的数据集,无法借鉴或使用已有的深度学习算法。为了快速建立权威、有效的东巴文字库,分析已出版东巴文档的版面结构,从文档中提取文本行、东巴字成为了当前的首要任务。因此,结合东巴象形文字文档图像的结构特点,给出了东巴文档图像的文本行自动分割算法。首先利用基于密度和距离的k-均值聚类算法确定了文本行的分类数量和分类标准;然后,通过文字块的二次处理矫正了分割中的错误结果,提高了算法的准确率。在充分利用东巴字文档结构特征的同时,保留了机器学习模型客观、无主观经验影响的优势。通过实验表明,该算法可用于东巴文档图像、脱机手写汉字、东巴经的文本行分割,以及文本行中东巴字和汉字的分割,具有实现简单、准确性高、适应性强的特点,从而为东巴文字库的建立奠定基础。
东巴象形文字;东巴文档分析;文本行分割;投影分割;d-K-means
1 东巴象形文字手写文档分析
东巴文是一种十分原始的图画象形文字,是人类早期图画文字中象形文字、标音文字过渡的一种文字形式[1-2],主要是由东巴法师用于抄写经文。由于其还未发展成为一种字形比较固定、统一的表意文字[3-4],因书写的东巴法师不同而具有明显的个体差异性,导致非常多异体字[5]的存在,使得通过计算机实现东巴字的自动识别面临很多挑战。
随着以卷积神经网络(convolutional neural networks,CNN)为代表的深度学习技术的设计越来越深层化,图像特征的标识能力越来越强,深度学习在图像分类和识别领域表现出了非常优异的性能[6-8]。但深度学习的优势有赖于大数据,数据量的不足会直接导致模型出现过拟合的问题[9]。虽然很多专家也针对此问题提出了小样本学习[10],甚至是1-样本学习(one-shot learning)[11]的解决方案,但对样本仍有一些限制条件。如,样本需要达到一定的数量或具有某些方面的特征(文字样本需包含某些笔划特征或书写顺序[11]等)。因此,拥有权威、充足的东巴字样本才能为东巴字的自动识别提供更多的途径,但目前东巴字还未有标准、公开的数据集,并且大量的文档资料均是非常古老的纸质资料,且多珍藏于世界各大著名图书馆和博物馆,使东巴字的样本采集难度增大。
电子文档的普及化、共享化使东巴字的样本采集有了更加方便、快捷的途径,通过对原有已出版书籍,特别是绝版、权威书籍文档图像中东巴字的提取,可快速扩充文字库,增加字库的容量。而原有的样本采集工作也转化为对文档图像的版面分析和识别、文本的分割和提取工作。
文本行分割作为东巴字提取、东巴字译注段落分析、特定样本采集等一系列文档分析和采集工作的基础,有着非常重要的意义,但是却鲜有研究对其进行探讨。由于东巴文档图像中兼有东巴文和脱机手写汉字(例如:《纳西象形文字谱》),若能借鉴或使用已有的脱机手写汉字版面分析技术,则可大幅提高工作效率。文献[12-14]结合脱机手写文档图像的结构特征,采用改进的投影分割算法以直观的方式实现了手写文本行的分割。这类算法符合人类分割文本行的习惯,具有直观、简单、易实现的特点,但仍或多或少地受到经验参数的影响(如,实现上下两行粘连字符分割时,凭经验将行分割线设置为文字高度的1/10[12],文本行分割和合并时将手写字的大小限定在一定范围之内[13]等)。为了克服这一问题,目前学者们更多是采用与深度学习相结合的方法。GRÜNING等[15]提出了一种两阶段的历史古籍文本行检测算法。该方法通过ARU-Net深度学习网络,结合数据增强策略,将全页训练样本的数量降低至50张以下,并且能够用于任意方向和曲线的文本行检测。HAZEM等[16]采用以主题为单位的文档分割思想,按照祈祷者的时间顺序实现了对中世纪手稿的文本行分割及段落、文档结构等更高层次的分析,并建立了对应的数据集。但由于缺乏大量的标注训练数据,无法采用深度学习的方法来测试数据集。BOILLET等[17]在Doc-UFCN[18],dhSegment[19]和ARU-Net[15]等3种深度学习网络的基础上给出了具有通用性的历史古籍文本行分割算法,并提出了统一的数据标注方式以提高识别效率。WANG等[20]提出了端到端的中文文本页面检测、识别系统。通过将文本检测和文字识别统一到一个框架中,实现了全局文本特征与文本核的结合,降低了文字识别对文本检测的依赖性,提高了系统的鲁棒性。LIU等[21]提出了基于图卷积网络(graph convolutional network,GCN)的文本行检测算法。该算法将文档中的单词作为基本单元,以单词为基础得到文本行,再以文本行为基础得到段落,是非常少有的既能检测脱机手写文本行,又能检测文档段落的方法。但是,该方法以脱机手写单词为基本单元,单词在文档中的识别效率将直接影响算法最终的准确率。
基于深度学习的方法具有精度高、健壮性好、不受经验参数影响等优点,但针对于特定领域,对训练数据的规模、数据标记方式等均有着不同的要求。并且,一些研究[15,17,19,21]对文档中文本行的分割及文档结构的分析是建立在利用已有的文字检测和识别算法的基础上完成的。这与本文通过分析东巴文档图像的结构,分割并提取其中的东巴字、脱机手写汉字,形成完整的东巴象形文字数据集的思路是相悖的。
因此,结合东巴象形文字文档图像的结构特点,本文提出一种适用于东巴字文档图像的文本行自动分割(automatic text line segmentation,ATLS)算法,以传统投影分割算法为基础加入了基于密度和距离的k-均值聚类算法(distance & density K-means,d-K-means),保证了文本行分割的合理性和彻底性。ATLS算法充分利用了东巴字文档的结构特征,同时又保留了机器学习模型客观、无主观经验影响的优势,使算法的健壮性更好、准确性更高、适用范围更广,从而为以更小的文档单位研究东巴字,建立具有权威性的东巴字库奠定基础。
2 东巴字文档图像的文本行自动分割算法
2.1 东巴字文档图像研究对象的选择
《纳西象形文字谱》[22]、《纳西族象形标音文字字典》[23]和《纳西语英语汉语语汇》[24]是代表东巴文编撰领域较高水平的三部字典,如图1所示。其中,方国瑜先生编撰的《纳西象形文字谱》是一本纯手写的字典,与其他两本字典相比,其排版、布局更加复杂,加之全部为脱机手写字文档,文字的大小、文本行的间距、段落的缩进距离等随意性更强,难以做到完全一致。因此,选择《纳西象形文字谱》作为研究对象具有一定代表性,有利于提高ATLS算法的适用性和扩展性。
ATLS算法的核心思路是:首先,采用垂直和水平投影对东巴文档图像进行初次分割,提取文字块;其次,将文字块作为聚类的数据样本,结合d-K-means算法对文字块进行自动分类,确定文字块的属性;最后,对其中的异常文字块进行二次处理,保证文档中单个文本行的独立性和完整性。
2.2 文档图像的预处理及初次分割
由于东巴文档图像中的页眉和页脚一般为印刷体,排版位置固定、大小相同(图1)。因此,在预处理阶段,首先计算文档中页眉和页脚的位置并去除,以减少对文档正文结构的干扰,效果如图2(a)和(b)所示;其次,采用水平和垂直投影算法对文档图像进行初分割,分割时将投影值为0的像素行作为文档图像的分割行/列,并提取文档中的文字块,如图2(a)和(c)所示。其中,图2(a)为初次水平分割的结果,图2(c)为初次垂直分割的结果。
由于脱机手写文档的书写比较随意,文本行的间距大小不同,单个字符内部可能存在局部分离,而字符间又易发生重叠、粘连和交错,加之东巴字大小不一,使得由初次分割得到的文字块中存在分割不彻底或过渡分割的文字块,如图2(a)和(c)所示。并且,初次分割得到的文字块属于无标记样本,文字块的属性、包含的文本行数量或文字块的有效性都是未知的。为了找出无标记样本的内在特征,实现文档中文本行的有效提取,选择无监督学习(unsupervised learning)中广泛应用的聚类算法[23]——K-means来分析文字块的属性。

图2 文档图像的预处理和初次分割((a)原始文档图像;(b)去除页眉和页脚;(c)初次垂直投影;(d)垂直投影合并)
2.3 基于密度和距离的k-均值聚类算法
K-means基于“以物聚物”的原理是将一组个体按照相似性归为若干类,使得属于同一类别的个体之间的差异性尽可能的小,而不同类别则尽可能的大,具有简洁、快速的优点[25]。但是,K-means一般要求事先指定分类数量,且对初始点敏感,导致聚类结果稳定性差,使用范围受限。为克服原始算法的缺陷,选择基于密度和距离的k-均值聚类算法(d-K-means)[26]。该算法在K-means算法的基础上权衡了密度和距离对聚类的影响,首先在权值的基础上通过引入最小最大原则来选择初始聚类中心,避免初始聚类中心选择随机性引起的局部最优解问题,减少算法的迭代次数;其次,通过比较预分类前后所有数据点BWP指标[27]平均值的变化来自动确定类中心及其个数,保证了K-means聚类中心及其数量的有效性。使用d-K-means算法实现东巴文档图像中文字块的分类与属性识别的操作步骤为:
步骤1.确定样本集合及采样特征。将投影算法得到的文字块作为聚类分析的数据样本。由图2可知,在水平方向上,文字块的属性判断与文字块的高度有关(过大,可能是分割不彻底;过小,可能是过分割),因此将文字块的高度及其在文档图像中的序号作为水平样本的特征。在垂直方向上,由于空白分割列的位置相对固定,变化幅度较少,因此选择文档中连续的空白分割列作为垂直样本,将其起始位置和列宽作为样本特征。那么,对于包含个文字块的样本集合,其水平样本及垂直样本的特征描述为


其中,和分别为水平样本的序号和行高;和分别为垂直样本的起始位置和列宽。由于在水平和垂直方向上的文字块处理方式类似,且水平分割的处理过程更为复杂,因此以水平样本的分类过程为例来描述整个算法的流程。图3(a)和图4(a)的分布给出了《纳西象形文字谱》文档图像水平和垂直样本的特征分布情况。
步骤2.计算水平样本P的半径,得

其中,P_nearest()为与水平样本P距离最近的个样本;()为2个样本点之间的欧氏距离;为初始时每个聚类包含的样本数,在二维空间中一般取m=4[28]。
步骤3.根据水平样本P的_领域,计算权值,选择权值最大的样本点作为聚类的第一个中心点,即
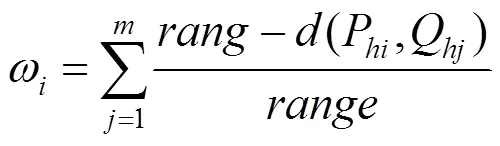

其中,Q为P的_领域内的样本;为样本P的_领域内的样本数量;()为2个样本点之间的欧氏距离;为样本集向量空间的大小;max和min为样本集合二维特征的最大值和最小值;|| ||2为欧氏距离的平方。
步骤4.计算每个水平样本的中心点指标C,选取中心点指标最大的样本作为新的备选聚类中心,并加入到中心点列表中,对样本集合进行预分类,即

图3 基于d-K-means的东巴文档水平文字块的分类((a)文档中水平样本的分布;(b) BWP平均值的变化情况;(c)基于d-K-means的分类)
Fig. 3 Classification of horizontal text blocks in Dongba documents based on d-K-means ((a) Distribution of horizontal samples in the document; (b) Variation of BWP mean; (c) Classification based on d-K-means)

图4 基于d-K-means的东巴文档垂直文字块的分类((a)文档中垂直样本的分布;(b) BWP平均值的变化情况;(c)基于d-K-means的分类)

其中,为水平样本P的权值;为水平样本P与距离自身最近的类簇中心点之间的距离,为当前中心点的数量。
步骤5.计算类间距离。类间距离(,)指的是第类中的第个样本P到其他每个类中样本的欧式距离平均值的最小值。显然,(,)的值越大,则类间分离性越好,得


步骤6.计算类内距离。类内距离(,)指的是第类中的第个样本P到类中其他样本距离的平均值。显然,(,)越小,类内紧密性越好,密度越高,即

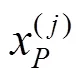
步骤7.根据预分类结果,计算集合中所有水平样本BWP指标的平均值,即

其中,为集合中的样本数。若BWP指标的平均值增大,则将该点作为聚类中心,并删除其领域中的数据,然后接着寻找下一个聚类中心;若BWP指标的平均值减小或不存在可选取的数据点,说明所有聚类中心已找到,则停止算法。通过5次迭代过程,BWP指标平均值的变化情况如图3(b)所示。由此可知,文档图像中的水平样本可分为4类,根据中心点列表中的4个聚类中心位置,使用K-means对水平样本进行分类的结果如图3(c)所示。
图3(c)中,4个聚类行高的取值范围分别为:橙色聚类[17, 58];蓝色聚类[71, 207];绿色聚类[239, 346];红色聚类[426, 449]。结合图2(a)的分割结果可看出,蓝色聚类为单个文本行的聚类,橙色聚类为过分割文字块的聚类,而绿色和红色聚类为分割不彻底的大文字块的聚类。同理,对垂直样本进行处理得到的样本特征分布情况、BWP值和分类结果如图4所示。结合图2(c)的垂直样本分布情况可知,橙色和紫色聚类为文档最左侧和最右侧的空白列,绿色和蓝色聚类为文档中的分割列,而红色聚类为过分割空白列。由此,根据不同聚类的取值范围,可快速判断文字块的类别属性,并针对异常字块进行二次处理。
2.4 文字块的二次处理
文字块的二次处理包括:过分割文字块的合并和大文字块的二次分割。
(1)过分割文字块的合并。垂直方向上,只需去除红色聚类中无效的空白分割列即可,实现简单,合并前后的效果如图2(c)和(d)所示。水平方向上,由图3(c)的分类结果可知,单个文本行的高度范围为[71, 207],那么当文字块的高度<71时,该文字块为过分割文字块,需要合并。结合文字排版和书写习惯可知,一般情况下,行内字块的上下间距一定小于行间字块的上下间距,也就是说,距离越近的文字块,其关系越亲密。因此,将过分割文字块与其间距更近的相邻文字块进行合并。即,对于相邻的3个文字块block-1,block和block+1,其起止点的坐标分别为:(0, sy-1)和(0, ey-1),(0, sy)和(0, ey),(0, sy1)和(0, ey+1),则文字块block-1和block之间的上下间距为

那么,可合并文字块combine为

过分割文字块的合并效果如图5(c)所示。
(2) 大文字块的二次分割。由于受文档图像中东巴字及手写字上下行粘连的影响,使文本行在分割的过程中产生了很多无法分割的大文字块,有的包含2个文本行,也有的包含多个文本行,如图5(a)所示。为了实现大文字块的有效分割,一种简单、快捷的方式是选择字块中水平投影值较小的行作为分割行。但这又会将处于文字块上下边界处投影值较小的像素行也错误地作为分割行。因此,在选择分割行时,首先对所有像素行的投影值按照从小到大的顺序排列,选择投影值较小的行作为备选分割行;然后,计算备选分割行与文字块上下边界的高度差,如果高度差大于单个文本行的最小值,则将其作为分割行,否则继续从备选行中查找满足条件的像素行。
因此,设单个文本行的高度范围为[1,2],则对于行高为h的文字块block,若文字块的起止坐标为(0,sy)和(0,ey),且h>s2,该文字块的分割步骤为:
步骤1.计算第sy行至第ey行的水平投影值,并存储到集合中;
步骤2.选择集合中投影值最小且与sy或ey的高度差均>1的像素行作为分割行,并将该行从集合中删除。满足条件

图5 文本行的水平分割与合并((a)文本行的水平分割效果;(b)大文字块的水平投影值统计;(c)文字块的二次合并与分割)

步骤3.使用分割行对文字块进行二次分割,得到2个子块。
步骤4.判断每个子块的行高,若子块的行高>2,则重复执行步骤1~步骤3,直至所有子块的高度介于[1,2]为止。
由图3(c)的分类结果可知,单个文本行的高度范围为[71, 207],则对文档中的大文字块进行判断和分割,结果如图5(c)所示。通过二次处理,东巴文档图像中的单个文本行得到了有效提取,保证了文本行的独立性和完整性。
2.5 算法的复杂度分析
ATLS算法由3个核心模块组成,即:基于投影的文档分割、基于d-K-means的文字块分类及文字块的二次处理。假设单个文档图像包含行列(>)像素点,一本书籍包括页文档,且投影分割最多得到个文字块,则:
(1) 基于投影的文档分割,需要计算每个像素行或列的投影值,因此时间复杂度(1)=(×)≈(2);

(3) 文字块的二次处理包括异常文字块的合并及大文字块的二次分割。其中,异常文字块的合并需计算文字块的高度及与其上下相邻文字块的间距。最坏情况下,需合并的文字块数量为,则时间复杂度(31)=();大文字块的二次分割需要根据文字块的高度再次进行分割线的筛选和投影分割。最坏情况下,大文字块的高度为,其时间复杂度为(32)=(2)。因此,该阶段的时间复杂度(3)=(31)+(32)≈(2)。

3 实 验
3.1 准确性测试
三部字典中,正文部分《纳西象形文字谱》包括554页,《纳西族象形标音文字字典》包括360页,《纳西语英语汉语语汇》包括655页。由于这些文档中,有部分文档页不包括东巴字(如,前言、绪论等),为了准确分析最终文本行的提取效果,从三部字典中随机抽取150页含有东巴字的文档图像和30页不含东巴字的文档图像作为测试样本,分别选择基于图像结构特征分析的文本行提取算法[12]、集成了PANNet,ResNet和DenseNet等3种神经网络结构的端到端文本行提取算法[18]和本文算法进行比较,结果见表1。

表1 不同类型算法提取东巴文档文本行的正确率
为了便于比较,文献[18]采用了由CASIA- HWDB2.0-2.2数据集训练后得到的网络模型,由于该数据集中不包含东巴字,因此在采用该模型提取包含东巴字的文本行时,准确率较低,而在处理不含东巴字的脱机手写文档时,由于受到表格、文字下划线等其他因素的影响,正确率也低于其他2种算法。但是,当文档中仅含印刷体汉字时,其准确率显著提高。文献[12]的整体表现均优于文献[18],但是当文档中含东巴字时,由于文档的排版结构发生较大变化,因此文献[12]的正确率也受到较大影响。
3.2 扩展性测试
《创世纪》是一部非常具有代表性的东巴经典,很多东巴经均采用此类格式排版。这类文档一般由东巴经原文和中文译注两部分组成,文档内容往往与表格交叠,比前述东巴文档图像更加复杂。并且,一些东巴祭祀在书写东巴经时,还经常将表格的下框线作为东巴文字的一种补充,实现连字成句的效果,使文本行的分割难度增大,如图6所示。

图6 《创世纪》的文档结构
由于《创世纪》中东巴经部分和汉字注解部分的位置固定,对上下2个组成部分的内容单独使用ALTS算法进行初次分割、计算BWP指标、分类,结果如图7(a)~(e)所示。由此可知,东巴经部分的聚类中心数量为3,单个文本行的高度范围为[57, 83];而汉字注解部分的聚类中心数量也为3,单个文本行的高度范围为[23, 42]。因此,结合文本行的高度范围,对图7(e)的初次分割结果进行二次处理的效果如图7(f)所示。此时,原有文档中存在的过分割文字块得到了有效合并,文档的整体结构更加显著。可见,当文本行中既有东巴字,又有脱机手写汉字,甚至文档中包含少量噪音时,ATLS算法也能得到较好的效果。
同时,分别使用文献[12]、文献[18]和ATLS算法对《创世纪》全书37页文档图像的东巴字部分和脱机手写汉字部分分别进行文本行分割,其正确率见表2。可见,ATLS的可扩展性优于其他2种算法。
3.3 文字分割测试
由于文本行中的文字分割过程,与文档中的垂直分割过程非常相似。因此,将ATLS算法进一步应用到文本行上单个文字的分割中。首先,将已提取的文本行进行垂直投影分割,得到文字样本,如图8(a)所示。其次,将文字样本的宽度及其在文本行中的序号作为特征,求出其BWP指标,并使用K-means进行分类,如图8(b)~(d)所示。其中,蓝色聚类中文字样本的宽度范围为[18, 150],红色聚类中为[154, 278]。结合图8(a)可知,红色聚类中的文字样本为分割不完全的大文字块。因此,对大文字块进行二次分割,结果如图8(e)所示。

图7 《创世纪》文档分割过程((a)东巴经的BWP值;(b)东巴经的分类结果;(c)汉字注解的BWP值;(d)汉字注解的分类结果;(e)文档图像的初始分割;(f)文档图像的二次处理)
Fig. 7 “Genesis” document segmentation process ((a) The BWP of the Dongba scripture; (b) The classification of the Dongba scripture; (c) The BWP of the Chinese annotation; (d) The classification of the Chinese annotation; (e) Initial segmentation of the document; (f) Secondary processing of the document)

表2 不同类型算法提取《创世纪》文本行的正确率(%)
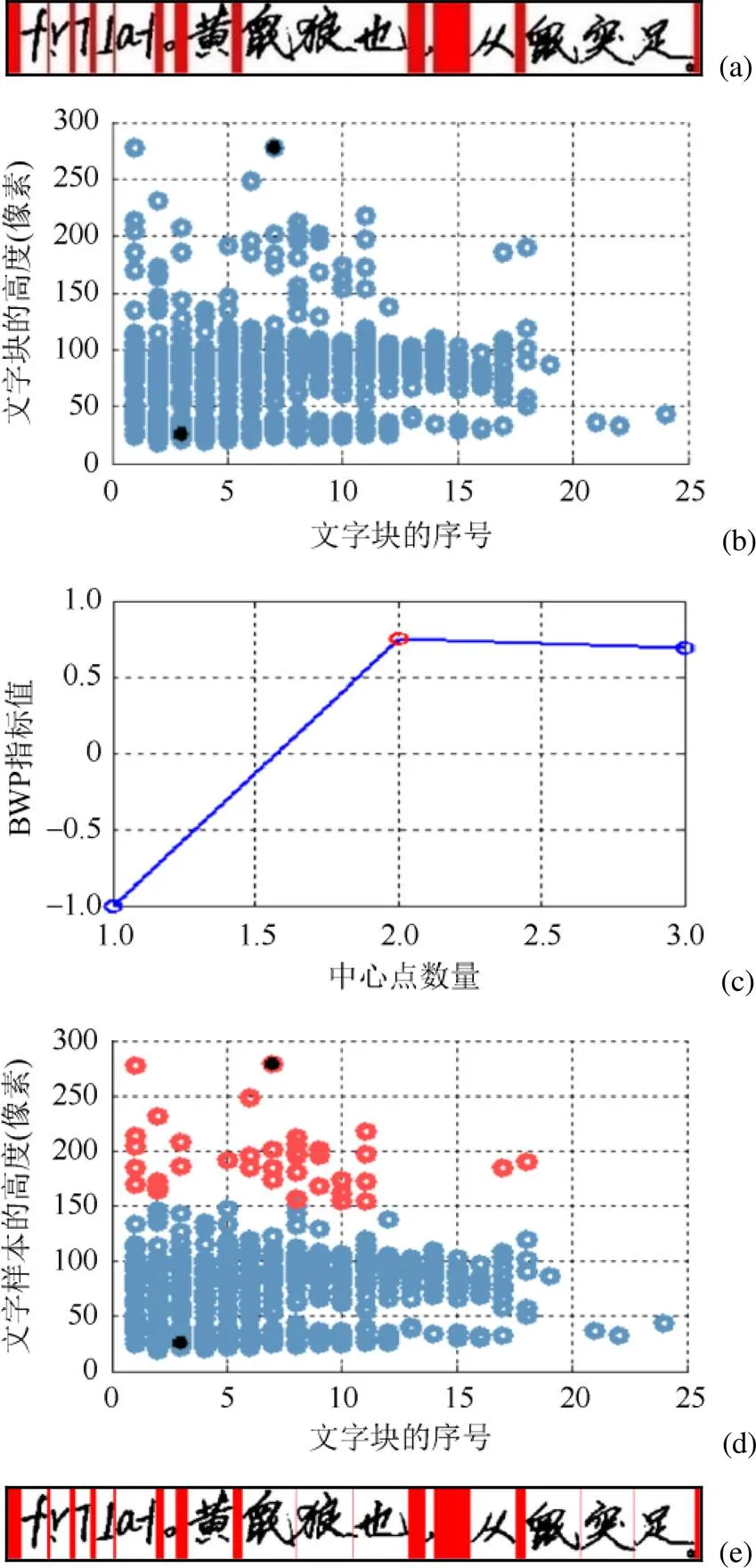
图8 基于d-K-means的文字样本分类((a)文本行的垂直分割;(b)文字样本的分布;(c) BWP平均值的变化情况;(d)基于d-K-means的分类;(e)文字块的二次分割)
由于文本行中除了包含脱机手写汉字之外,还包含国际音标、东巴字、数字和标点符号等多种类型的文字样本,如图9(a)所示。当文本行中存在文字过分割时,ATLS算法可能无法有效地辨别和合并,如图9(b)和(c)所示。但是,ATLS算法在文字分割方面仍能取得较好的效果,准确率整体上达到了95.26%。说明,ATLS算法也可用于文本行中单个文字的分割。

图9 文本行的组成((a)包括东巴字的文本行;(b)存在大字块和过分割的文本行;(c)大字块的细分)
4 结束语
文本行分割是一项重要的预处理工作,是字符分割、东巴字提取、东巴字译注分析、不同层次样本采集等是一系列文档分析和采集工作的基础。因此,结合东巴字的特殊形态及文档的独有结构特征给出了适用于东巴字文档图像的ATLS算法。通过引入d-K-means聚类分析和文字块的二次处理,使文本行分割更加准确、彻底。通过实验表明,本文算法除了可用于东巴字文档图像的文本行分割之外,也可用于东巴经的文本行分割及文本行中的文字分割,算法具有实现简单、准确性高、适应性强的特点。后续将结合ATLS算法进一步细化文档结构分析,完成东巴典籍中东巴象形文字的提取及文字注释的分离,从而为东巴文档的分析和数据采集,建立东巴文字集奠定基础。
[1] 和力民. 试论东巴文化的传承[J]. 云南社会科学, 2004(1): 83-87.
HE L M. On transition of dongba culture[J]. Social Sciences in Yunnan, 2004(1): 83-87 (in Chinese).
[2] 杨玉婷, 康厚良. 东巴象形文字特征曲线提取算法研究[J]. 图学学报, 2019, 40(3): 591-599.
YANG Y T, KANG H L. Research on the extracting algorithm of dongba hieroglyphic feature curves[J]. Journal of Graphics, 2019, 40(3): 591-599 (in Chinese).
[3] 胡瑞波, 张晓松, 徐人平, 等. 纳西族东巴象形文字字体构造研究[J]. 郑州轻工业学院学报: 社会科学版, 2013, 14(2): 94-100.
HU R B, ZHANG X S, XU R P, et al. A Study on the Font Structure of Naxi Dongba Hieroglyphs[J]. Journal of Zhengzhou University of Light Industry: Social Science, 2013, 14(2): 94-100 (in Chinese).
[4] 杨玉婷, 康厚良, 廖国富. 东巴象形文字特征曲线简化算法研究[J]. 图学学报, 2019, 40(4): 697-703.
YANG Y T, KANG H L, LIAO G F. Research on simplification algorithm of dongba hieroglyphic feature curve[J]. Journal of Graphics, 2019, 40(4): 697-703 (in Chinese).
[5] 郑飞洲. 纳西东巴文字字素研究[M]. 北京: 民族出版社, 2005: 45-127.
ZHENG F Z. Research on Naxi Dongba character grapheme[M]. Beijing: National Publishing House Press, 2005: 45-127 (in Chinese).
[6] WANG L, LI S J, LV Y J. Learning to rank semantic coherence for topic segmentation[C]//2017 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: Association for Computational Linguistics , 2017: 1340-1344.
[7] KOSHOREK O, COHEN A, MOR N, et al. Text segmentation as a supervised learning task[C]//2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: Association for Computational Linguistics, 2018: 469-473.
[8] ARNOLD S, SCHNEIDER R, CUDRÉ-MAUROUX P, et al. SECTOR: a neural model for coherent topic segmentation and classification[J]. Transactions of the Association for Computational Linguistics, 2019, 7: 169-184.
[9] 刘颖, 雷研博, 范九伦, 等. 基于小样本学习的图像分类技术综述[J]. 自动化学报, 2021, 47(2): 297-315.
LIU Y, LEI Y B, FAN J L, et al. Survey on image classification technology based on small sample learning[J]. Acta Automatica Sinica, 2021, 47(2): 297-315 (in Chinese).
[10] GAO H H, XIAO J S, YIN Y Y, et al. A mutually supervised graph attention network for few-shot segmentation: the perspective of fully utilizing limited samples[J]. IEEE Transactions on Neural Networks and Learning Systems, 2022, PP(99): 1-13.
[11] LAKE B M, SALAKHUTDINOV R, TENENBAUM J B. Human-level concept learning through probabilistic program induction[J]. Science, 2015, 350(6266): 1332-1338.
[12] 周双飞, 刘纯平, 柳恭, 等. 最小加权分割路径的古籍手写汉字多步切分方法[J]. 小型微型计算机系统, 2012, 33(3): 614-620.
ZHOU S F, LIU C P, LIU G, et al. Multi-step segmentation method based on minimum weight segmentation path for ancient handwritten Chinese character[J]. Journal of Chinese Computer Systems, 2012, 33(3): 614-620 (in Chinese).
[13] 朱宗晓, 杨兵. 特征离散点计算在手写文本行分割中的应用[J]. 计算机工程与应用, 2015, 51(8): 148-152, 204.
ZHU Z X, YANG B. Using feature discrete-point computing in handwritten documents line segmentation[J]. Computer Engineering and Applications, 2015, 51(8): 148-152, 204 (in Chinese).
[14] 雷鑫, 李俊阳, 宋宇, 等. 用于手写汉字识别的文本分割方法[J]. 智能计算机与应用, 2018, 8(2): 126-128.
LEI X, LI J Y, SONG Y, et al. Text segmentation method applied for handwritten Chinese characters recognition[J]. Intelligent Computer and Applications, 2018, 8(2): 126-128 (in Chinese).
[15] GRÜNING T, LEIFERT G, STRAUß T, et al. A two-stage method for text line detection in historical documents[J]. International Journal on Document Analysis and Recognition: IJDAR, 2019, 22(3): 285-302.
[16] HAZEM A, DAILLE B, STUTZMANN D, et al. Hierarchical text segmentation for medieval manuscripts[C]//The 28th International Conference on Computational Linguistics. Stroudsburg: International Committee on Computational Linguistics, 2020: 6240-6251.
[17] BOILLET M, KERMORVANT C, PAQUET T. Robust text line detection in historical documents: learning and evaluation methods[J]. International Journal on Document Analysis and Recognition: IJDAR, 2022, 25(2): 95-114.
[18] BOILLET M, KERMORVANT C, PAQUET T. Multiple document datasets pre-training improves text line detection with deep neural networks[C]//2020 25th International Conference on Pattern Recognition. New York: IEEE Press, 2021: 2134-2141.
[19] ARES OLIVEIRA S, SEGUIN B, KAPLAN F. dhSegment: a generic deep-learning approach for document segmentation[C]//2018 16th International Conference on Frontiers in Handwriting Recognition . New York: IEEE Press, 2018: 7-12.
[20] WANG Z H, YU Y W, WANG Y B, et al. Robust end-to-end offline Chinese handwriting text page spotter with text kernel[M]//Document Analysis and Recognition - ICDAR 2021 Workshops. Cham: Springer International Publishing, 2021: 21-35.
[21] LIU S, WANG R S, RAPTIS M, et al. Unified line and paragraph detection by graph convolutional networks[M]// Document Analysis Systems. Cham: Springer International Publishing, 2022: 33-47.
[22] 方国瑜. 纳西象形文字谱[M]. 昆明: 云南人民出版社, 2005: 25-247.
FANG G Y. Naxi hieroglyphs dictionary[M]. Kunming: Yunnan People’s Publishing House, 2005: 25-247 (in Chinese).
[23] 李霖灿. 纳西族象形标音文字字典[M]. 昆明: 云南民族出版社, 2001: 15-70.
LI L C. Naxi pictographs and transcription characters dictionary[M]. Kunming: Yunnan People’s Publishing House, 2001: 15-70 (in Chinese).
[24] ROCK J F. A Na-Khi-English encyclopedic dictionary (Part I)[M]. Roma: Roma Istituto Italiano Peril Medio ed Estreme Prientale, 1963: 45-655.
[25] 张冬梅, 李敏, 徐大川, 等. k-均值问题的理论与算法综述[J]. 中国科学: 数学, 2020, 50(9): 1387-1404.
ZHANG D M, LI M, XU D C, et al. A survey on theory and algorithms for k-means problems[J]. Scientia Sinica: Mathematica, 2020, 50(9): 1387-1404 (in Chinese).
[26] 唐泽坤, 朱泽宇, 杨裔, 等. 基于距离和密度的d-K-means算法[J]. 计算机应用研究, 2020, 37(6): 1719-1723.
TANG Z K, ZHU Z Y, YANG Y, et al. D-K-means algorithm based on distance and density[J]. Application Research of Computers, 2020, 37(6): 1719-1723 (in Chinese).
[27] 王法胜, 鲁明羽, 赵清杰, 等. 粒子滤波算法[J]. 计算机学报, 2014, 37(8): 1679-1694.
WANG F S, LU M Y, ZHAO Q J, et al. Particle filtering algorithm[J]. Chinese Journal of Computers, 2014, 37(8): 1679-1694 (in Chinese).
[28] 孙凌燕. 基于密度的聚类算法研究[D]. 太原: 中北大学, 2009.
SUN L Y. Research of clustering algorithm based on density[D]. Taiyuan: North University of China, 2009 (in Chinese).
Automatic segmentation algorithm for text lines of Dongba hieroglyphs document image
KANG Hou-liang1, YANG Yu-ting2
(1. Sports Department, Suzhou Vocational University, Suzhou Jiangsu 215000, China; 2. School of Computer Engineering, Suzhou Vocational University, Suzhou Jiangsu 215000, China)
Deep learning technologies represented by convolutional neural networks (CNN) have shown excellent performance in the field of image classification and recognition. However, since there is no standard and public dataset for Dongba hieroglyphs, we cannot draw on or use the existing deep learning algorithms. In order to establish an authoritative and effective Dongba hieroglyphs dataset, the current primary task is to analyze the layout structure of the published Dongba classic documents, and extract the text lines and Dongba hieroglyphs in the documents. Therefore, based on the structural features of Dongba hieroglyphic document images, an automatic text-line segmentation algorithm was proposed for Dongba document images. The algorithm first employed the d-k-means clustering algorithm to determine the classification quantity and classification standard of text lines; then, the wrong results in the segmentation were corrected through the secondary processing of the text blocks, so as to enhance the accuracy of the algorithm. While making full use of the structural features of Dongba characters, the algorithm retained such advantages of the machine-learning model as objectivity and immunity to subjective experience. Experiments show that the algorithm can be used for the text line segmentation of Dongba document images, offline handwritten Chinese characters, Dongba scriptures, and the segmentation of individual Dongba and Chinese characters in text lines. It is simple in implementation, high in accuracy, and strong in adaptability, thus laying the foundation for the establishment of the Dongba character library.
Dongba hieroglyph; Dongba documents analysis; text line segmentation; projection segmentation; d-K-means
TP 391
10.11996/JG.j.2095-302X.2022050865
A
2095-302X(2022)05-0865-10
2021-12-31;
2022-05-05
31 December,2021;
5 May,2022
苏州市职业大学引进人才科研启动金项目(201905000034)
Suzhou Vocational University Introduced Talents Scientific Research Start-up Fund Project (201905000034)
康厚良(1979-),男,教授,硕士。主要研究方向为民族文化及数字化。E-mail:kangfu1979110@163.com
KANG Hou-liang (1979-), professor, master. His main research interests cover national culture and its digitization. E-mail:kangfu1979110@163.com
杨玉婷(1983-),女,副教授,硕士。主要研究方向为图形图像处理、计算机视觉等。E-mail:tudou-yeah@163.com
YANG Yu-ting (1983-), associate professor, master. Her main research interests cover digital image processing and pattern recognition, etc. E-mail:tudou-yeah@163.com
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
云南档案(2021年1期)2021-04-08
数学物理学报(2021年1期)2021-03-29
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
学生天地·小学低年级版(2019年5期)2019-06-05
学生天地(2019年15期)2019-05-05
民族古籍研究(2018年1期)2018-05-21
信息安全研究(2016年4期)2016-12-01
中国西部(2016年1期)2016-03-16
