
基于YOLOX的小目标烟火检测技术研究与实现
2022-11-02 11:19金林林董兰芳
图学学报 2022年5期
赵 辉,赵 尧,金林林,董兰芳,肖 潇
基于YOLOX的小目标烟火检测技术研究与实现
赵 辉1,赵 尧1,金林林1,董兰芳2,肖 潇2
(1. 国网安徽省电力有限公司亳州供电公司,安徽 亳州 236800;2. 中国科学技术大学计算机科学与技术学院,安徽 合肥 230026)
火灾是日常生活中最常见的社会灾害之一,会对人类的财产、生命安全造成巨大威胁,如何准确而快速地发现小面积的烟火点并实时发出预警,对维护正常的社会生产具有重要意义。传统的烟火检测算法通过识别图像的各种低维视觉特征如颜色、纹理等,进而判断烟火的位置,方法的实时性和精度较差。近些年深度学习在目标检测领域的成就显著,各种基于深度神经网络的烟火检测方法层出不穷,但大部分深度学习模型在小目标上的检测效果远不及大目标,而烟火检测任务需要在烟火面积很小时就做出及时地识别和预警,才能避免火势扩大造成更大的经济损失。对此,基于YOLOX模型对激活函数和损失函数做出改进并结合数据增强算法和交叉验证训练方法,实现了更好的小目标检测算法,在烟火检测数据集上获得了78.36%的mAP值,相比原始模型提升了4.2%,并获得了更好的小目标检测效果。
烟火检测;小目标检测;深度学习;数据增强;YOLOX
火灾事故的发生会造成巨大的经济损失,还会严重威胁人们的生命安全。如在电力系统的发电、输电、变电过程中,由于设备不稳定很容易导致火灾事故的发生。2017年11月18日北京市大兴区西红门镇新建村发生火灾,造成19人死亡,8人受伤,事故原因是埋在聚氨酯保温材料内的电气线路发生了故障;2021年4月16日,北京一储能电站发生火灾,导致2名消防员牺牲,1名消防员受伤,电站内1名员工失联,除了设备本身问题,人为操作失误也可导致事故发生。由此可见,火灾的发生不仅会对人民的生命财产造成巨大的危害,也会严重影响社会的经济发展和安全稳定,因此如何有效地预防火灾,对小面积的烟火进行有效精确地监测和预警至关重要。
1 相关方法
目前对于火灾进行有效预警的方法是通过检测火灾早期产生的烟雾和火焰进行跟踪、定位来实现的,由于易燃物分布十分广泛,全部采用人工方法进行巡检会造成极大的人力消耗。随着视频监控技术的普及,一些直接对视频序列中的图像信息进行处理的方法也陆续出现,如传统的图像处理方法通过识别图像所具有的一些低维视觉特征(如形状、颜色和纹理等)进行烟火的检测,文献[1]通过识别火灾中火焰和烟雾的颜色和运动特征来检测烟火;文献[2]采用视觉图像分割与堆叠技术来判别烟火特征从而检测烟火。但这些传统方法易受背景变化的影响,而火灾产生处的场景十分复杂,使得传统图像处理方法在烟火检测领域所能达到的精度十分有限。
近年来,随着深度学习技术在各个领域的蓬勃发展和广泛应用,尤其是在目标检测领域,深度学习方法得益于能够自适应地学习到不同环境背景下的特征差异,在处理图像信息任务时表现出较传统方法更高的精度和自学习的能力,烟火识别预警就属于特定场景下(火灾)的目标检测任务,可基于目标的几何和特征统计对视频或图像中的火焰和烟雾进行准确识别和定位。目前,基于深度学习的目标检测算法可以分为一阶段算法和两阶段算法,其中两阶段算法需要经过两步完成:①获得候选区域,②对候选区域进行分类;而一阶段算法则不需要获取候选区域,从图像中直接预测目标所在的区域。
在图像分类任务中,卷积神经网络(convolutional neural networks,CNN)较传统方法显现出巨大的优势,基于CNN进行图像分类逐渐成为主流。随后,GIRSHICK等[3]首次将CNN运用到了目标检测领域,提出了基于候选框选取的R-CNN目标检测算法,其以图像像素为单位根据纹理特征的相似性逐渐向上融合,获得若干候选区域,再将候选区域送入CNN进行分类,并校正目标检测的边界框。该算法需要获得大量的候选区域以获得更高的精度,且很多区域间是彼此重叠的,模型对于不同的候选区域进行了大量的重复计算,降低了模型的速度。之后,Fast R-CNN[4]做出了改进,使用CNN先提取整个图像的特征,而不是对每个图像块多次提取,然后将创建候选区域的方法直接应用于提取到的特征图上,因此大大减少了提取特征所花的时间,但其速度则依赖于外部选择性搜索算法。于是Faster R-CNN[5]算法用区域生成网络代替了候选区域方法,区域生成网络将前面CNN的输出特征图作为输入,在特征图上滑动一个3×3的卷积核,通过CNN构建出与类别无关的候选区域再送入分类网络。上述算法均为两阶段算法,而一阶段算法中具有代表性的主要有:①LIU等[6]提出的SSD算法,其不通过事先选取候选框,而是在多尺度特征图上的每个点生成一个预选框,然后将所有的预选框集合进行极大值抑制,最后输出预测结果;②REDMON等[7]提出的YOLO算法,将目标检测当作一个回归问题,通过单一的神经网络同时预测边界框的坐标和各个类别的概率,检测速度也能达到45 FPS以上。除了基于CNN的一阶段算法之外,还有LIU等[8]提出的基于自注意力机制的swin transformer算法,该算法能取得更高的精度,但计算速度较慢。
上述目标检测算法中,两阶段算法由候选区域选取再对候选区域进行分类,往往需要花费较多的时间,而烟火检测是一个对实时性要求很高的任务,因此本文将采用一阶段算法识别烟火,相比于两阶段算法而言能够在保证预测精度不降低的同时,大大减少烟火检测的时间,提高了检测的效率。得益于YOLO算法,在确保目标检测任务能获得较高精度的同时,处理速度也接近实时应用的要求。
因此,本文以YOLOX[9]算法作为基础的网络模型,并结合火灾场景下烟火检测任务的要求进行调整,从而实现了构建烟火小目标检测效果足够好的模型。
2 YOLO系列算法简介
YOLO系列算法经过了3次改进,并以此为基础,衍生出了各种不同的版本。将目标检测问题当作回归问题进行处理,将整张图片作为网络输入,然后在输出层对预测框的位置和类别进行预测。算法首先将一张图片分割成×个网格,如果预测目标的中心点位于某个网格中,则对此目标进行进一步预测,在实际输出中,每个网格预测个框,并分析每个框中是否包含目标以及目标所属的类别。这会导致一个目标可能有多个预测框对其进行预测,算法使用非极大值抑制方法,该方法选择所有预测框中得分最高的那个,然后对该预测框与其他预测框计算交并比(intersection over union,IoU),IoU计算方法如图1所示,其值为2个矩形框的交集与并集面积之比。

图1 IoU计算方法
非极大值抑制需要设置一个IoU阈值(一般为0.5),将计算结果小于该阈值的预测框抑制掉,再对剩下的预测框迭代使用该方法,直至没有能抑制的预测框为止,最终输出的是不含重叠框的预测结果。
3 烟火检测的网络模型
3.1 烟火检测模型概述
目标检测模型一般可以抽象成backbone,neck和head网络。如图2所示,其中backbone网络进行特征提取,head网络进行分类和回归分析,neck网络为可选的部分,一般对backbone网络获得的特征图进行多尺度的融合。

图2 检测模型总体结构
3.2 烟火检测模型backbone网络
烟火检测模型使用CSPDarkNet[9]作为backbone部分,其使用YOLOV3[10]中的DarkNet[10],结合CSP结构而成,如图3(a)所示;CSPDarkNet主要使用卷积层和CSP结构进行连接,其中CSP结构如图3(b)所示。CSP结构类似于残差结构[11],输入首先通过次的1×1卷积和3×3卷积操作,然后再将得到的结果与原始输入拼接在一起作为输出。烟火检测模型使用GELU[12]激活函数,在训练时能够收敛得更快,即

图3 烟火检测模型的backbone网络((a)CSPDarkNet;(b)CSP结构)

其中,erf函数为高斯误差函数,即
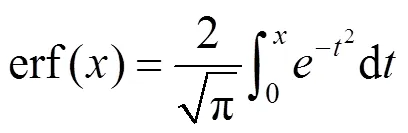
CSPDarkNet的输入是一张640×640×3的图片,首先对图片进行Focus结构的操作。Focus结构如图4所示,在一张图片中每隔一个像素获取一个值,这时可获得4个独立的特征层,并对其进行堆叠,此时的宽、高信息就集中于通道信息,输入通道扩充了4倍,拼接起来的特征层由原3个通道变成12个通道。Focus结构其实就是进行了一个下采样操作,但该过程与其他方法相比没有进行任何计算,从而减少了模型进行推理时所需要的计算开销。
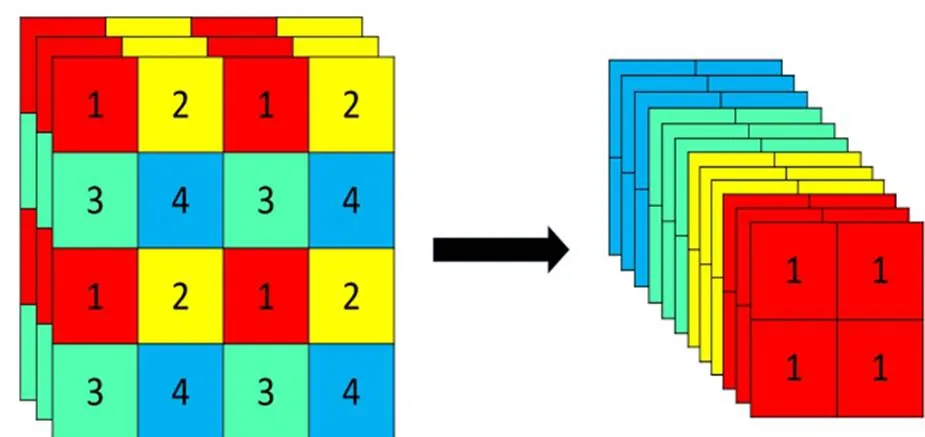
图4 Focus结构
经过Focus结构后,模型再通过卷积层和CSP结构的堆叠,不断地提取特征,在进入最后一个CSP结构之前,模型通过了一个SSP结构的处理,SSP结构有点类似于GoogleNet[13]中使用的Inception结构,如图5所示,通过使用不同的池化核大小的max-pooling进行特征提取,提高网络的感受野。

图5 SSP结构
3.3 烟火检测模型neck网络
烟火检测模型neck网络基于图像特征金字塔网络FPN[14]搭建,FPN能融合不同尺度的特征图,从而得到不同尺度的目标预测结构。烟火检测任务需要在烟火目标还小时或烟火目标被遮挡时也能准确及时地检测到,从而减少损失。CNN在进行特征提取时会不断地进行下采样,从而使最后获得的特征图上的一个点对应原始图像中的32×32或更多像素,于是一些小于32×32个像素的目标就很难被检测出来。但之前的卷积层所获得的特征图,还存在着较多的细节特征,如果将前面卷积层所保留的细节特征和最后的语义特征进行综合,就可以获得小目标的相关特征,从而检测到原始图片上所存在的小目标。
图6为基于FPN而构建的neck网络,neck网络将backbone网络获得的特征图进行两次上采样,然后与backbone网络对应大小的特征图进行拼接,每次拼接后均经过一次CSP结构处理。经过两次上采样将细节特征与语义特征融合获得特征图1后,再进行两次下采样,每次下采样后的结果在与上采样之前的对应大小的特征图进行拼接,拼接后的特征图分别经过一次CSP结构处理获得特征图2和3。1,2和3分别为3个不同大小尺度的特征图,1检测小目标,2检测中目标,3检测大目标。
3.4 烟火检测模型head网络
Head网络对neck网络得到的3个不同尺度的特征图分别进行回归分析,其网络结构如图7所示。
Head网络首先通过一个1×1的卷积将每个特征图的通道数减少到256,然后通过2个平行的分支进行两次3×3卷积后分别进行分类和回归,同时在回归的分支加了一个IoU的分支。于是对于每一个特征层,均可获得3个预测结果:
(1) Reg_output(,,4)。对目标框的位置信息进行预测,4个参数分别为,,,,其中和为预测框的中心点的坐标;和为预测框的宽和高。
(2) Obj_output(,,1)。用于判断目标框是前景还是背景,经过Sigmoid函数处理后,即为前景的置信度。
(3) Cls_output(,,)。判断目标框内属性,给每类目标一个分数,经过Sigmoid函数处理后可得到每一类目标的置信度。
将3个预测结果进行堆叠,每个特征层获得的结果为Output(,,4+1+),其中前4个参数判断每一个目标框的位置信息;第5个参数判断目标框内是否包含物体;最后个参数判断目标框内所包含的物体种类。

图6 烟火检测模型的neck网络

图7 烟火检测模型head网络部分[9]
4 烟火检测模型的训练
4.1 数据增强
数据增强是计算机视觉中一种扩充数据集的手段,可对图像进行数据增强,从而弥补训练图像数据集不足,达到对训练数据扩充的目的。在本文的烟火模型中,可使用Mosaic算法和Mixup[15]算法进行数据增强。
Mosaic算法的增强效果如图8所示,将4张图像进行随机的裁剪缩放,然后将其拼接在一起,这样做的好处有:①缩小图片中的目标以满足本文对小目标精度的要求;②增加背景的复杂度。火灾发生地的背景往往十分复杂,需要模型对复杂的背景拥有较好的鲁棒性。

图8 Mosaic数据增强算法((a)烟火数据集中的4张随机图像;(b)拼接后的图像)
另一种数据增强算法Mixup源自于图像分类任务,可将2个不同分类的数据进行混合,以达到混合增强的目的,Mixup算法可以在几乎不增加任何计算的基础上,稳定提高一个百分点的分类精度。假如x是一个batch的样本,而x是另一个batch的样本,其标签分别是y和y,选取一个由参数和确定的Beta分布计算得到混合参数,再计算混合batch和标签。
Mixup算法可以描述为
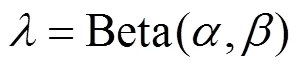



4.2 损失函数计算
目标检测任务是检测出目标并进行定位,而损失函数的功能则是让检测的准确率更高、定位更精确,且需要指出的是,预测框与真实框的接近程度、预测框中是否含有需要检测的目标以及目标类别是否是真实的类别。损失函数和模型的预测结果相同,主要由3部分组成:①回归损失,由模型预测出的,,,可以定位预测框的位置,利用真实框和预测框计算IoU损失,作为回归损失的Loss组成;②目标损失,根据模型预测出的特征点可知是否包含目标,而所有真实框对应的特征点均是正样本,剩余点均为负样本,根据正负样本和特征点是否包含目标的预测结果计算交叉熵损失,作为目标损失的Loss组成;③分类损失,根据模型预测出特征点,从中提取该特征点所预测的种类结果,然后根据真实框的种类和特征点的种类预测结果计算交叉熵损失,作为分类损失的Loss组成。
对于回归损失,采用DIoU[16]代替IoU来计算损失值,IoU所度量的是预测框与真实框之间的交并比。但如果预测框与真实框之间没有交集,那IoU的计算结果就会一直为0,而且当2个框中一个在另一个内部时,则框的大小不变,那么计算出的IoU值也不会发生变化,这样模型将难以进行优化。图9为DIoU计算回归损失的原理,相应的计算为

其中,c为预测框与真实框并集的外接矩形对角线距离;d为预测框与真实框的中心点距离,即使2个框没有交集也不会使损失值为0,且当2个框其中一个在另一个内部时,也可以获得很好地度量效果。
为了提高模型对小目标的检测效果,将目标损失中的交叉熵损失改为使用Focal Loss[17]损失函数,即

当分类为正样本时,损失函数为-logʹ,反之,损失函数为-log (1-ʹ)。损失函数需对所有的样本均采用同样的损失度量方式,然而在实际的预测中,小目标总是比大目标难以预测,因此小目标所获得的预测概率总是比较低,交叉熵损失函数并提高对小目标的预测精度。而Focal Loss损失函数为

Focal Loss损失函数使用一个超参数来控制模型对小目标的偏向程度,当预测的结果ʹ趋近于1时,在经过1-ʹ的指数运算后,损失函数的结果会比较小,若预测的结果ʹ比较小,则可获得比较大的损失值。大目标的检测对于模型来说比较容易,大目标的预测值一般会比较大,而小目标的检测则不易,所以小目标的预测值一般会偏小,经过Focal Loss损失函数的计算,小目标会获得相对比较大的损失值,因此模型会偏向于提高自身对小目标的预测能力。
5 实 验
5.1 实验数据集
目前尚未见烟火的公开数据集,所以本文收集了2 153张图像作为烟火检测的实验数据集。图10为数据集中的部分图像,其中包括面积比较大和面积比较小的火焰目标。使用LabelImg软件将图像进行标注后转换成VOC数据集格式,分别使用“smoke”和“fire”对目标进行标注。

图10 烟火检测数据集中的部分图像
5.2 预训练
由于烟火数据集的样本数并不多,模型训练后的泛化性能不强导致检测效果不高。因此采用目前比较有效的迁移学习策略来解决数据集匮乏的问题,采用在大型数据集ImageNet上预训练的参数作为模型的初始化参数。此外,为了充分利用数据集并防止过拟合,采用交叉验证的方法对模型进行训练,将训练集分成6份,逐次选取其中1份作为验证集,其他5份作为训练集,一共训练180个epoch,最后将所有训练集一起训练20个epoch。其中,训练的前180轮使用Mosaic和Mixup数据增强算法,后20轮取消使用数据增强算法。
5.3 实验结果与分析
目标检测网络的性能评价指标采用平均精度均值(mean average precision,mAP),计算预测的各个类别目标在查全率和查准率下面积的平均值,即


其中,为真正例,即预测框与真实框的IoU≥0.5的目标个数;为假正例,即预测框与真实框的IoU<0.5的目标个数;为假负例,即未预测出目标个数。
实验中的超参数设置为:学习率0.001,一个batch的大小为8,迭代次数epoch为200。
表1为本文使用的烟火模型的检测结果。由表1可知改进后mAP值为78.36%,相比基础的YOLOX模型提高了4.2%,其中烟雾和火焰的P-R曲线分别如图11和图12所示,图中,P-R曲线与坐标轴围成的面积为AP值,可以得出烟雾和火焰的AP值分别为81.42%和75.30%。

表1 在烟火数据集上检测网络的实验结果对比(%)

图11 烟雾P-R曲线

图12 火焰P-R曲线
5.4 实际场景的验证与分析
对模型进行训练后,本文使用实际场景中的火焰图像进行测试。图13和图14分别为原始模型和本文改进后模型在消防演练图像上的检测结果,可以看出,改进后的模型不仅能检测出原始模型能检测出的烟火大目标,还能检测出原始YOLOX模型未检测出的,图像左侧面积极小的火焰目标。因此本文使用的烟火检测模型不仅能准确地识别出大面积火焰,而且对小面积的火焰也具有很好地检测效果,可以及时发现火灾产生的信息,从而做出预警。

图13 原始模型在消防演练图像上的检测结果

图14 改进模型在消防演练图像上的检测结果
6 结束语
本文主要研究的是烟火检测尤其是对小目标烟火以及被遮挡住的烟火的检测。通过使用交叉验证提高模型的泛化能力,通过使用FPN特征金字塔网络提高模型对小目标的检测能力,通过使用Focal Loss提高模型对小目标的学习偏好,通过使用Gelu和DIoU提高模型的收敛速度。最终在烟火数据集上获得了78.36%的mAP值,相比原始模型提高了4.2%。在实际火灾的测试中也能精确地检测出不同面积的火焰,本文使用的烟火检测模型能够对烟火进行实时地检测,并在火灾初发时就能检测出小面积的火焰,能满足火灾预警对实时性和准确性的要求。
[1] 韩美林, 张文文. 基于视频图像的多特征融合的森林烟火检测系统研究[J]. 无线互联科技, 2021, 18(17): 67-68.
HAN M L, ZHANG W W. Research on forest fireworks detection system of multiple characteristic fusion based on video image[J]. Wireless Internet Technology, 2021, 18(17): 67-68 (in Chinese).
[2] 严成, 何宁, 庞维庆, 等. 基于视觉传感的地面烟火监测系统设计[J]. 广西大学学报: 自然科学版, 2019, 44(5): 1290-1295.
YAN C, HE N, PANG W Q, et al. Design of ground pyrotechnic monitoring system based on visual sensing[J]. Journal of Guangxi University: Natural Science Edition, 2019, 44(5): 1290-1295 (in Chinese).
[3] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2014: 580-587.
[4] GIRSHICK R . Fast R-CNN [EB/OL]. (2015-9-27) [2022-01- 15]. https://arxiv.org/abs/1504.08083v2.
[5] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[6] LIU W, ANGUELOV D, ERHAN D, et al. Ssd: single shot multibox detector[C]//The 2016 European Conference on Computer Vision. New York: IEEE Press, 2016: 21-37.
[7] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 779-788.
[8] LIU Z, LIN Y T, CAO Y, et al. Swin transformer: hierarchical vision transformer using shifted windows[C]//2021 IEEE/CVF International Conference on Computer Vision. New York: IEEE Press, 2021: 9992-10002.
[9] GE Z, LIU S T, WANG F, et al. YOLOX: exceeding YOLO Series in 2021 [EB/OL]. (2021-08-6) [2022-01-15].https:// arxiv.org/abs/2107.08430,2021.
[10] CHOI J, CHUN D, KIM H, et al. Gaussian YOLOv3: an accurate and fast object detector using localization uncertainty for autonomous driving[C]//2019 IEEE/CVF International Conference on Computer Vision. New York: IEEE Press, 2019: 502-511.
[11] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 770-778.
[12] HENDRYCKS D, GIMPEL K. Gaussian error linear units (GELUs)[EB/OL]. [2021-10-09]. https://arxiv.org/abs/1606. 08415.
[13] SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions[EB/OL]. [2021-09-10]. https://www.docin.com/p-1257582907.
[14] LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 936-944.
[15] ZHANG H, CISSE M, DAUPHIN Y N, et al. mixup: beyond empirical risk minimization[EB/OL]. (2018-04-27) [2022-01- 15]. https://arxiv.org/abs/1710.09412v2.
[16] ZHENG Z H, WANG P, LIU W, et al. Distance-IoU loss: faster and better learning for bounding box regression[J]. The 2020 AAAI Conference on Artificial Intelligence,2020, 34(7): 12993-13000.
[17] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]//2017 IEEE International Conference on Computer Vision. New York: IEEE Press, 2017: 2999-3007.
Research and realization of small target smoke and fire detection technology based on YOLOX
ZHAO Hui1, ZHAO Yao1, JIN Lin-lin1, DONG Lan-fang2, XIAO Xiao2
(1. Bozhou Electric Power Supply Company, State Grid Anhui Electric Power Company, Bozhou Anhui 236800, China; 2. School of Computer Science and Technology, University of Science and Technology of China, Hefei Anhui 230026, China)
Fire is one of the most common social disasters in daily life, which will pose an enormous threat to human property and life safety. How to accurately and quickly identify small areas of smoke and fire and issue early warnings in real time is important for normal social production significance. The traditional smoke and fire detection algorithm identifies the location of smoke and fire based on various low-dimensional visual features of the images, such as color and texture, so it is of poor real-time performance and low accuracy. In recent years, deep learning has made remarkable achievements in the field of target detection, and various smoke and fire detection methods based on deep neural networks have sprung up one after another. In the case of small areas of smoke and fire, timely identification and early warning should be made to avoid greater economic losses caused by the expansion of the fire. In this regard, based on the YOLOX model, the activation function and loss function were improved, and a superior small target detection algorithm was realized by combining the data augmentation algorithm and cross-validation training method, and the mAP value of 78.36% was obtained on the smoke and fire detection data set. Compared with the original model, it was enhanced by 4.2%, yielding a better effect of small target detection effect.
smoke and fire detection; small target detection; deep learning; data augmentation; YOLOX
TP 391
10.11996/JG.j.2095-302X.2022050783
A
2095-302X(2022)05-0783-08
2022-01-21;
2022-05-17
21 January,2022;
17 May,2022
国网安徽省电力有限公司科技项目(5212T02001CM)
State Grid Anhui Electric Power Co., Ltd. Science and Technology Project (5212T02001CM)
赵 辉(1983-),男,高级工程师,学士。主要研究方向为图像处理、视频图像智能分析。E-mail:5659020@qq.com
ZHAO Hui (1983-), senior engineer, bachelor. His main research interests cover image processing and intelligent analysis of video images. E-mail:5659020@qq.com
金林林(1990-),男,工程师,学士。主要研究方向为电力调度运行、无功电压电力系统及其自动化。E-mail:jll90315@163.com
JIN Lin-lin (1990-), engineer, bachelor. His main research interests cover power dispatching operation,reactive voltage power system and automation. E-mail:jll90315@163.com
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
数学小灵通·3-4年级(2021年5期)2021-07-16
阅读(快乐英语中年级)(2021年2期)2021-04-01
学生天地(2020年35期)2020-06-09
读友·少年文学(清雅版)(2019年10期)2019-05-21
今日农业(2019年15期)2019-01-03
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
火花(2016年7期)2016-02-27
