
基于YOLOv5s融合SENet的车辆目标检测技术研究
2022-11-02 11:19赵璐璐王学营张美月
图学学报 2022年5期
赵璐璐,王学营,张 翼,张美月
基于YOLOv5s融合SENet的车辆目标检测技术研究
赵璐璐1,王学营2,张 翼1,张美月1
(1. 长安大学信息工程学院,陕西 西安 710064;2. 内蒙古自治区交通建设工程质量监测鉴定站,内蒙古 呼和浩特 010050)
针对交通监控视频的车辆目标检测技术在早晚高峰等交通拥堵时段,车辆遮挡严重且误、漏检率较高的问题,提出一种基于YOLOv5s网络的改进车辆目标检测模型。将注意力机制SE模块分别引入YOLOv5s的Backbone主干网络、Neck网络层和Head输出端,增强车辆重要特征并抑制一般特征以强化检测网络对车辆目标的辨识能力,并在公共数据集UA-DETRAC和自建数据集上训练、测试。将查准率、查全率、均值平均精度作为评价指标,结果显示3项指标相比于原始网络均有明显提升,适合作为注意力机制的引入位置。针对YOLOv5s网络中正、负样本与难易样本不平衡的问题,网络结合焦点损失函数Focal loss,引入2个超参数控制不平衡样本的权重。结合注意力机制SE模块和焦点损失函数Focal loss的改进检测网络整体性能提升,均值平均精度提升了2.2个百分点,有效改善了车流量大时的误检、漏检指标。
车辆检测;交通监控;注意力机制;焦点损失函数;YOLOv5模型
交通监控视频提供的数据对缓解城市交通拥堵、提高道路通行效率以及合理分配交通资源具有重要作用。基于交通监控视频的车辆目标检测是后续进行车辆跟踪、道路车流量统计的基础。基于交通监控视频的车辆目标检测,对检测的实时性要求较高[1],且易受复杂环境背景及天气光线等干扰,尤其是城市交通拥堵路段,环境复杂、车流量,车辆互相遮挡严重,对车辆目标检测提出了挑战。
目标检测技术是基于交通监控视频的车辆检测核心技术。传统目标检测方法,输入一张待检测图片,首先采用滑动窗口的方式对图片进行候选框提取,接着提取每个候选框中的特征信息,最后利用分类器进行识别。典型的目标检测算法有Haar+Adaboost[2],Hog+SVM[3]和DPM[4]。传统方法采用滑动窗口操作[5]易导致算法产生大量冗余的候选框,使得检测速度慢、效率低、消耗资源多,而且传统算法采用基于手工设计特征提取方法的鲁棒性低、泛化效果差[6]。
LEE[7]提出的背景差分法利用当前图像与背景之间的差距识别车辆,在背景情况复杂时,难以应对车流量大的识别场景。TSAI和LAI[8]提出的帧间差分法,其需要选定合适的时间间隔,且容易出现漏检、错检问题。
随着机器学习和GPU并行计算技术的蓬勃发展,基于学习的特征提取技术方兴未艾。目前基于深度学习的目标检测主要包括:基于区域建议的Two-Stage检测算法和基于回归思想的One-Stage检测算法[9]。两阶段算法需要先生成预选框,再进行细粒度的物体检测,检测精度高,但效率低,其代表算法有:R-CNN[10],Fast R-CNN[11]和Faster R-CNN[12]。单阶段算法不必生成预选框,直接在网络中提取特征实现物体分类和位置的预测。相比两阶段算法,单阶段算法检测速度快,代表算法有RetinaNet[13]和YOLO[14-15]。其中,YOLO系列算法基于PyTorch框架,便于扩展到移动设备,属于轻量级网络。YOLOv5包括YOLOv5s,YOLOv5m,YOLOv5l和YOLOv5x 4种网络结构,随着网络宽度和深度的增大,参数量依次增加。YOLOv5s是轻量级网络的首选,便于部署到嵌入式设备。
YOLOv5系列经COCO2017测试集测试,平均准确率达72%,在GPU Nvidia Tesla V100的设备上检测速度为每张2 ms,处于目标检测算法中领先水平。由于单阶段检测算法未生成候选框,所以检测速度快,但精度相比两阶段算法偏低,该系列算法在检测精度方面仍有改进的空间。
本文在YOLOv5s的基础上进行改进,以改善在车辆遮挡或小目标情况下检测准确率偏低的问题。首先在Backbone主干网络、Neck网络层以及输出端分别加入注意力机制SE,测试得到注意力机制的最优引入位置。其次,考虑到单阶段结构存在正负样本和难易样本不平衡的问题,引入Focal loss函数计算目标损失和分类损失,以优化训练过程。在公开数据集UA-DETRAC进行模型训练和验证,并且在自建数据集上测试算法的性能。
1 YOLOv5s模型及改进
YOLOv5s网络采用One-Stage结构,由Input输入端、Backbone主干网络、Neck网络层和Head输出端4个部分组成,如图1所示。Input输入端具有Mosaic数据增强,自适应锚框计算以及自适应图片缩放功能。Backbone主干网络包括Focus结构,CSP结构[16]以及空间金字塔池化(spatial pyramid pooling,SPP)[17]结构,通过深度卷积操作提取图像中的不同层次特征。Neck网络层由特征金字塔(feature pyramid networks,FPN)和路径聚合网络(path aggregation network,PAN)组成。Head作为最后的检测,在大小不同的特征图上预测不同尺寸的目标。
1.1 YOLOv5s融合注意力机制
YOLOv5s网络层次不断加深,输出端提取到的信息逐渐抽象,检测监控视频中远处小目标车辆更难以实现,本文在网络中融入注意力机制的方法有效改善了这一问题。
1.1.1 SENet网络
SENet[18]是典型的通道注意力网络,曾获得ImageNet2017分类比赛冠军。在深度学习神经网络中,并非所有提取的特征都是重要的。SE注意力机制的作用是增强重要特征、抑制一般特征,并对卷积得到的特征图进行包含Sequeeze,Excitation和特征重标定3步操作[19],如图2所示。Sequeeze对卷积得到的××进行全局平均池化,得到1×1×大小的特征图。Excitation使用一个全连接神经网络,对Sequeeze之后的结果做一个非线性变换。特征重标定使用Excitation得到的结果作为权重,与输入特征相乘。SE模块具有即插即用的便利特征,已经在一些网络中得到应用,但其融合在网络中的哪个部分效果更好,目前还没有完整的理论说明。
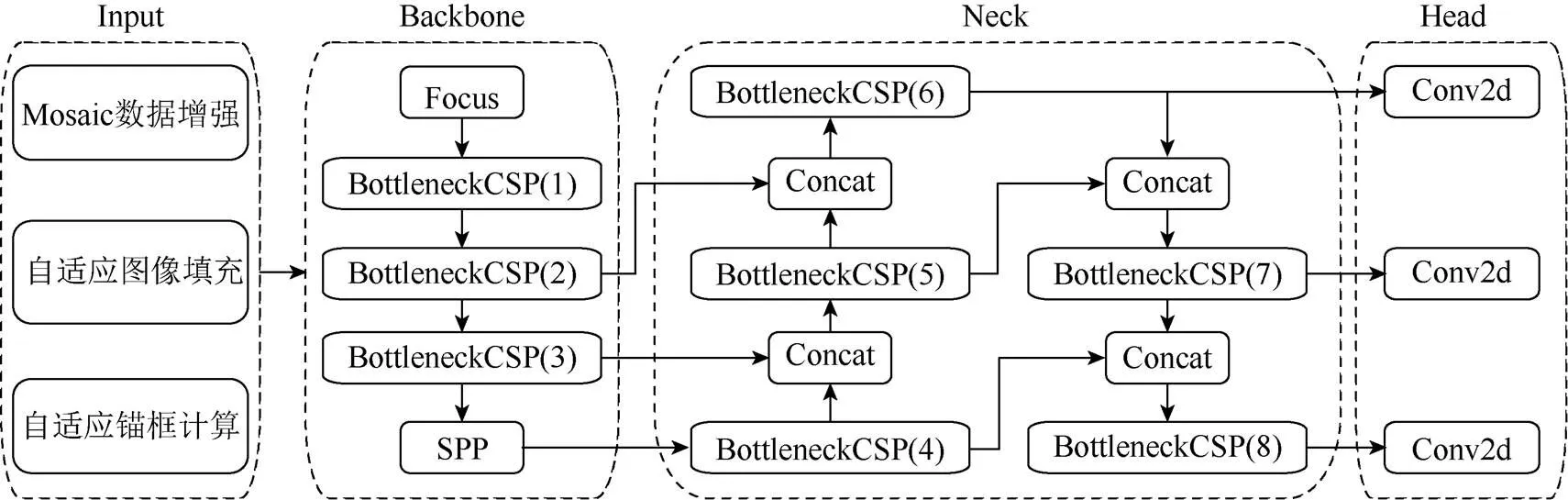
图1 YOLOv5s网络结构
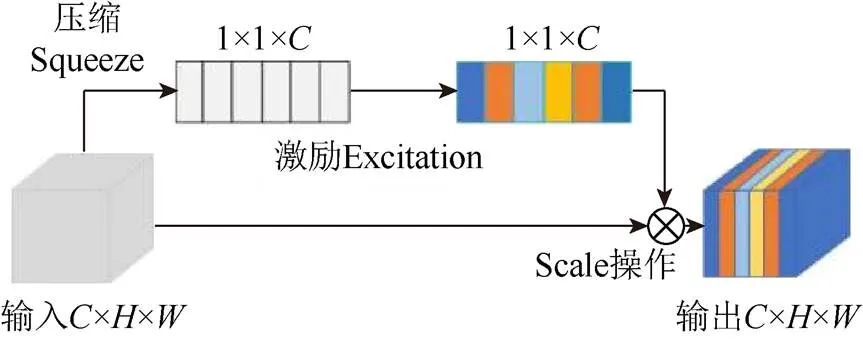
图2 SENet网络结构
1.1.2 3种融合方法
针对YOLOv5s,本文设计了3种不同位置的融合方法。将SE模块分别融合Backbone,Neck和Head 3个模块,未考虑Input的原因是因其只对图像进行预处理,并没有特征提取的作用。由此产生3个网络模型,本文分别将其记为YOLOv5s_A,YOLOv5s_B和YOLOv5s_C。
将SE模块融合在Backbone主干网络形成YOLOv5s_A。Backbone的主要作用是通过一个比较深的卷积网络提取图像中的深度特征,随着网络层数的加深,特征图宽度越来越小,深度越来越深,可以使用SE模块对不同位置的特征图进行通道注意力重构,BottleneckCSP结构聚合不同层次特征,因此将SE放在BottleneckCSP之后,如图3所示。
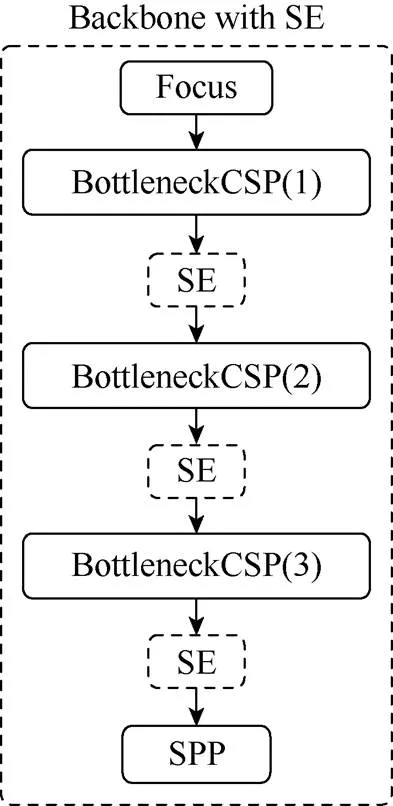
图3 Backbone主干网络融合SE模块
将SE模块融合Neck中形成YOLOv5s_B。Neck中的PAN和FPN结构可以自上而下地传递语义信息,自下而上地传递定位信息,通过4个Concat操作将深层与浅层信息进行融合,因此将SE模块放在Concat之后,对融合的特征图进行通道注意力重构,如图4所示。
将SE模块与网络最后的Head融合,形成YOLOv5s_C。YOLOv5s通过3个尺度大小不同的特征图预测目标,在小特征图上预测大目标,大特征图上预测小目标,考虑在预测之前,对每个特征图进行注意力重构,如图5所示。
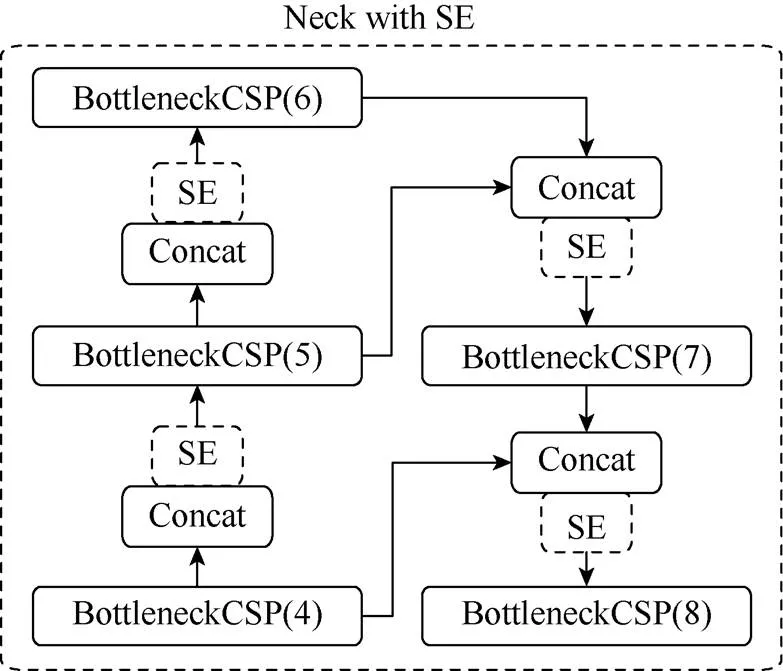
图4 Neck层融合SE模块
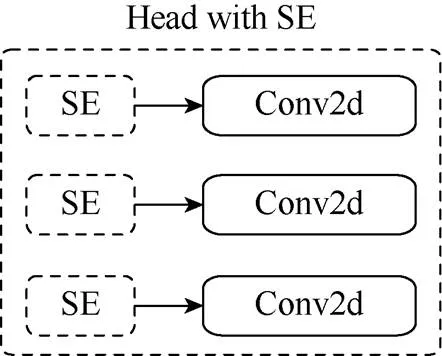
图5 Head输出端融合SE模块
1.2 引入Focal loss函数
1.2.1 正负样本不平衡问题
YOLOv5s的损失包含目标损失、分类损失和边界框回归损失。YOLOv5s使用BCE With Logits作为目标损失函数和分类损失函数,即
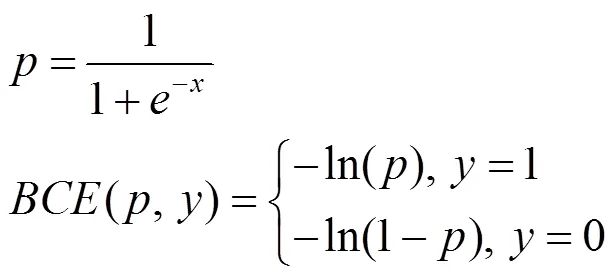
其中,为经过Sigmoid激活函数输出的概率;为真实的样本标签,取值为0或1。
图像中包含车辆的部分为正样本,其余部分为负样本。对于正样本,输出概率越大则损失越小;对于负样本,输出概率越小损失越小。对于One-Stage目标检测算法,正、负样本不均衡的问题较为突出,在交通道路图中背景的占比明显大于车辆的占比,损失函数得出的损失值绝大部分是负样本背景损失,并且大部分负样本背景是简单易分的,对于模型的收敛几乎没有作用。因此,本文引入焦点损失函数Focal loss,使用参数平衡正、负样本对损失的影响,将样本分为难分和易分样本,降低易分样本对总损失的权重。
1.2.2 Focal loss函数
对于正、负样本权重的控制,需要降低大量负样本对损失的影响,利用平衡因子
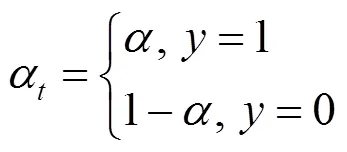
因子在样本标签不同时,提供不同的权重,例如BCE With Logits损失
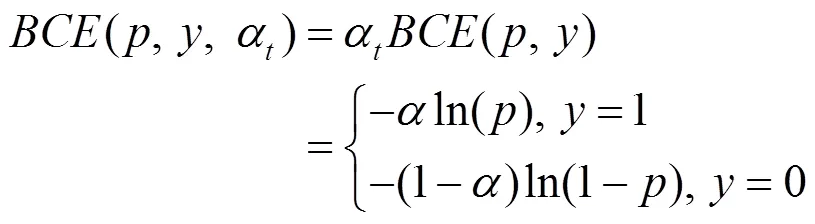
通过改变的大小控制正、负样本在损失的占比:在[0.50,1]区间,能够增加正样本损失的占比,降低负样本损失的占比。在[0.25,0.75]范围,能够取得较好的AP值。LIN等[20]分别取值为0.25,0.50和0.75,因0.25不在[0.50,1]范围内容,将其舍弃并用后2个值进行实验。
是为了控制正、负样本对损失的贡献,但不影响易分、难分样本的损失,因此使用调制因子(1-)和控制难分样本和易分样本的权重,即
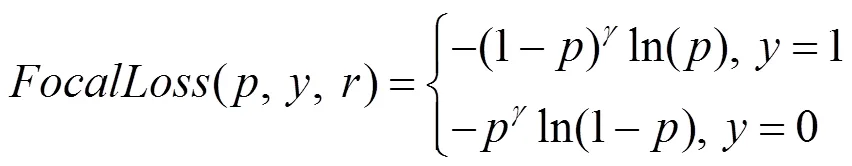
其中,取值范围[0,5],通过控制调制因子的大小,以控制难分、易分样本损失权重的大小。当=0,式(4)是标准二分类交叉熵损失函数;当0<≤5,可以实现降低易分类样本对损失的贡献,使得模型更加专注于难分类样本。
将平衡因子和调制因子(1-)和结合得到最终的Focal loss,即
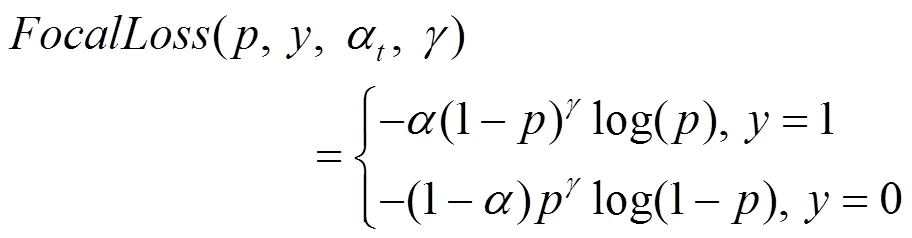
其中,平衡因子可以平衡One-Stage检测模型中正、负样本不均衡的问题;调制因子(1-)和控制难易样本差异对损失的影响。
2 机器学习实验结果及分析
2.1 实验准备
(1) 实验平台。网络训练平台采用腾讯云服务器,规格为Tesla V100-NVLINK-32G GPU,40 G RAM。模型框架采用Python 3.8,PyTorch 1.9,CUDA 10.2。
(2) 数据集。UA-DETRAC[21]是美国奥尔巴尼大学车辆目标检测和跟踪的数据集,采集于北京和天津24个不同的地点,包括100个具有挑战性的视频,超过14万帧视频图像和8 250辆人工标记的汽车目标,共计121万标记过的目标检测框。由于数据中包含夜晚、晴天、阴雨天等不同天气场景,以及城市公路、道路交叉口等丰富的交通场景并且拍摄角度接近于监控探头。马芸婷和乔鹏[22-23]及本实验均选用该数据集。为避免相邻帧之间图像变化过小,每10帧选取一帧的方式,得到14 000张视频图像。从中选取1万帧车流量较大的图像作为本文的实验数据集。
(3) 数据标注。为验证本文算法的泛化性能,模拟监控视频采集于西安市南二环文艺路天桥,采集场景包括傍晚、阴雨天以及光照较强的晴天总量1 500张,部分数据如图6所示。

图6 数据实例((a) UA-DETRAC;(b)自建数据)
自建数据集采用LabelImg标注工具进行人工标注,生成的Txt标签格式如图7所示。
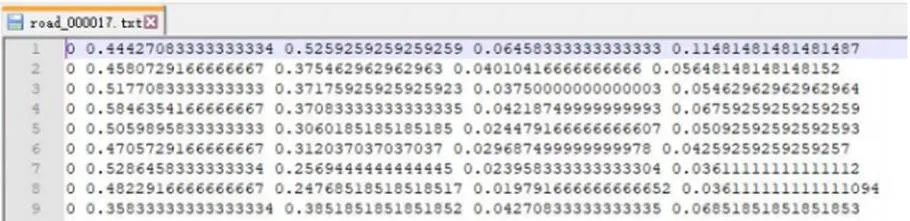
图7 Txt 数据标签文件
标签文件中每行为一个车辆信息,依次表示车辆类别,车辆中心坐标,,以及标注车辆矩形框的宽度和高度。车辆类别car,bus和van分别对应数字0,1和2。坐标均被归一化,将车辆中心坐标和宽度除以图像宽度,车辆中心坐标和高度除以图像高度。
本实验采用查准率Precision、查全率Recall、均值平均精度mAP作为评价指标,即

其中,,和分别为正确检测出的车辆数目,错误检出的车辆数目以及未被正确检出的车辆数目。为单类别平均精度;为各类别的平均值,用于对所有目标类别检测的效果取平均值,可以代表检测性能[24]。
2.2 SE模块融合对比实验
本文将UA-DETRAC数据按照9:1的比例随机划分为训练集和测试集,将自行采集并标注的图像作为测试集。实验均不采用预训练模型,训练过程使用相同的参数配置,输入图像大小为640×640,优化器为SGD,初始学习率设为0.01,动量设为0.937,衰1减系数为0.000 5。测试集上的实验结果见表1。
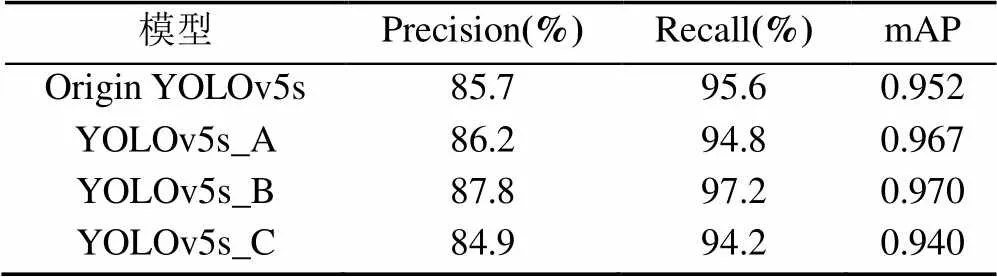
表1 融合SE的结果对比
并非所有融合SE的网络均能提升检测效果。YOLOv5s_A相较于原始YOLOv5s网络查准率Precision和均值平均精度mAP有所提高,但召回率Recall却有明显下降,图像中车辆被检测到的情况较差。YOLOv5s_B对于原始网络在3个评价指标上均有提升,均值平均精度mAP也是4个网络中最高的,达到0.970。YOLOv5s_C在3个评价指标中全面落后原始网络。
分析表1可知,注意力机制并不是在网络中的任何位置均有作用,在Backbone中,网络提取的特征还不够充分,因此只有Precision和mAP两项指标提高;在Neck中,网络对深层和浅层的特征图进行融合,在此基础上对特征图进行注意力融合,对不同的通道特征的重要性重新标定,因此取得了最好地检测结果;Head中是在不同特征图预测目标之前进行SE融合,但此处的特征图已损失了很多低层的语义信息,SE模块难以从这种高度融合的特征图中区分出重要的特征通道,因此所有的指标均有下降,是4个网络中效果最差的一个。基于以上分析本文将YOLOv5s_B作为车辆检测的基础模型。
2.3 Focal loss实验
由式(5)可以看出,Focal loss主要通过2个超参数和控制正、负样本和难、易样本对损失的贡献,为了更好地融合Focal loss函数与YOLOv5s网络适应车辆检测任务的需求,确定一组最优的和值成为进一步研究的内容。
实验中网络使用未融合SE模块的YOLOv5s,损失函数采用Focal loss函数,其他各种参数均与2.2节对比实验保持一致。选择几组不同的与进行对比实验,即取0.50和0.75,取值[1,5]范围的整数,遵循控制变量法的原则,各参照组仅有和的取值不同,测试结果见表2。
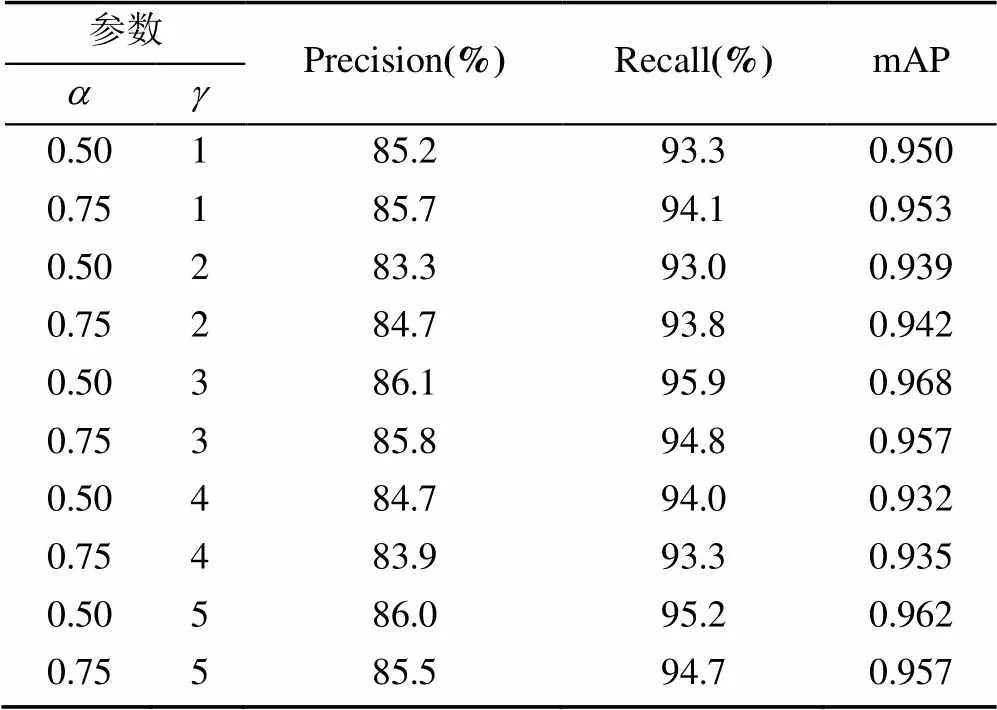
表2 不同参数组合的结果对比
从表2可知,并非所有超参数和的组合能对结果产生好的影响。在实验中,当=0.50,=3时,网络在测试集上取得了最好的检测结果,3项评价指标均高于其他组合,并且高于原始YOLOv5s的结果,证明了改进损失函数的有效性。
2.4 综合实验结果可视化
对原始YOLOv5s同时进行SE模块融合和Focal loss损失函数改进,在UA-DETRAC训练集上进行训练并在本文自建测试集上进行测试。实验结果见表3。可以看出,同时引进SE和Focal loss之后,网络的检测结果有了进一步提升,mAP达到最高0.974,相较原始YOLOv5s提升了2.2个百分点。

表3 原始网络和改进后网络的结果对比
图8为自建数据集对部分晴朗白天、阴雨天和夜晚检测结果的可视化。可以看到,原始网络对一些路段的目标和密集车辆出现了漏、误检现象,而本文改进网络检测出了这些目标。白天组中标记1处,车辆密集,原始网络出现了漏检现象,将多辆车识别为一辆;在标记2处,将一个车辆目标识别为了2辆。本文改进的网络模型解决了这样的问题,没有出现漏、误检。阴雨天和夜晚监控图像受天气和光线影响,增加了检测的难度,原始网络和改进网络检测性能均受到影响。但图中对比显示,改进网络对远处以及遮挡车辆的误、漏检率总体更低,具有明显优势。

图8 原始网络和改进网络的结果对比((a)原始网络;(b)改进网络)
3 结束语
本文使用改进的YOLOv5s网络检测交通监控中的车辆目标。针对检测中出现的误、漏检问题,提出将注意力模块SE引入YOLOv5s,为判断SE位置不同对检测结果造成的影响,在网络的3个不同位置Backbone,Neck和Head分别引入并进行对比实验;使用焦点损失Focal loss替代原始的损失函数,改善网络的正、负样本和难、易样本不平衡的问题,设置不同的参数并根据实验结果选择最合适的组合。分别在UA-DETRAC和自建数据集上训练、测试。实验结果表明,本文改进方法相比原始YOLOv5s在评价指标mAP上提高2.2%,根据可视化结果,本文方法可以有效降低漏、误检率。目前监控探头往往是算力较低的边缘设备,因此,在低算力设备上部署车辆检测模型并达到实时检测的要求是下一步的研究重点。
[1] 蒋镕圻, 彭月平, 谢文宣, 等. 嵌入scSE模块的改进YOLOv4小目标检测算法[J]. 图学学报, 2021, 42(4): 546-555.
JIANG R Q, PENG Y P, XIE W X, et al. Improved YOLOv4 small target detection algorithm with embedded scSE module[J]. Journal of Graphics, 2021, 42(4): 546-555 (in Chinese).
[2] TIAN D X, ZHANG C, DUAN X T, et al. The cooperative vehicle infrastructure system based on machine vision[C]//The 6th ACM Symposium on Devel Opment and Analysis of Intelligent Vehicular Networks and Applications. New York: ACM Press, 2017: 85-89.
[3] DROŻDŻ M, KRYJAK T. FPGA implementation of multi-scale face detection using HOG features and SVM classifier[J]. Image Processing & Communications, 2016, 21(3): 27-44.
[4] FELZENSZWALB P F, GIRSHICK R B, MCALLESTER D, et al. Object detection with discriminatively trained part-based models[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(9): 1627-1645.
[5] ZHU H G. An efficient lane line detection method based on computer vision[J]. Journal of Physics: Conference Series, 2021, 1802(3): 032006-032014.
[6] 李妮妮, 王夏黎, 付阳阳, 等. 一种优化YOLO模型的交通警察目标检测方法[J]. 图学学报, 2022, 43(2): 296-305.
LI N N, WANG X L, FU Y Y, et al. A traffic police object detection method based on optimized YOLO model[J]. Journal of Graphics, 2022, 43(2): 296-305 (in Chinese).
[7] LEE D S. Effective Gaussian mixture learning for video background subtraction[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(5): 827-832.
[8] TSAI D M, LAI S C. Independent component analysis-based background subtraction for indoor surveillance[J]. IEEE Transactions on Image Processing, 2009, 18(1): 158-167.
[9] 杨亚峰, 苏维均, 秦勇, 等. 基于语义标签的高铁接触网图像目标检测研究[J]. 计算机仿真, 2020, 37(11): 146-149, 188.
YANG Y F, SU W J, QIN Y, et al. Research on object detection method of high-speed railway catenary image based on semantic label[J]. Computer Simulation, 2020, 37(11): 146-149, 188 (in Chinese).
[10] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2014: 580-587.
[11] GIRSHICK R. Fast R-CNN[C]//2015 IEEE International Conference on Computer Vision. New York: IEEE Press, 2015: 1440-1448.
[12] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[13] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(2): 318-327.
[14] REDMON J, FARHADI A. YOLOv3: an incremental improvement[EB/OL]. [2022-01-20]. https://arxiv.org/abs/1804. 02767?context=cs.CV.
[15] BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: optimal speed and accuracy of object detection[EB/OL]. [2022-02-05]. https://arxiv.org/abs/2004.10934.
[16] WANG C Y, MARK LIAO H Y, WU Y H, et al. CSPNet: a new backbone that can enhance learning capability of CNN[C]///The IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Washington New York: IEEE Press, 2020: 390-391.
[17] HE K M, ZHANG X Y, REN S Q, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916.
[18] HU J, SHEN L, ALBANIE S, et al. Squeeze-and-Excitation Networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 42(8): 2011-2023.
[19] 谭芳喜, 肖世德, 周亮君, 等. 基于改进YOLOv3算法在道路目标检测中的应用[J]. 计算机技术与发展, 2021, 31(8): 118-123.
TAN F X, XIAO S D, ZHOU L J, et al. Application in road target detection based on improved YOLOV3 algorithm[J]. Computer Technology and Development, 2021, 31(8): 118-123 (in Chinese).
[20] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(2): 318-327.
[21] WEN L, DU D, CAI Z, et al. UA-DETRAC: a new benchmark and protocol for multi-object detection and tracking[J]. Computer Vision and Image Understanding, 2020, 193(C): 102907-102926.
[22] 马芸婷. 基于深度特征的车辆检测与跟踪[D]. 兰州: 西北师范大学, 2020.
MA Y T. Vehicle detection and tracking based on depth feature[D]. Lanzhou: Northwest Normal University, 2020 (in Chinese).
[23] 乔鹏. 基于深度学习和边缘任务卸载的交通流量检测研究[D]. 西安: 西安电子科技大学, 2019.
QIAO P. Research on traffic flow detection based on deep learning and edge task offloading[D]. Xi’an: Xidian University, 2019 (in Chinese).
[24] 谢富, 朱定局. 深度学习目标检测方法综述[J]. 计算机系统应用, 2022, 31(2): 1-12.
XIE F, ZHU D J. Survey on deep learning object detection[J]. Computer Systems and Applications, 2022, 31(2): 1-12 (in Chinese).
Vehicle target detection based on YOLOv5s fusion SENet
ZHAO Lu-lu1, WANG Xue-ying2, ZHANG Yi1, ZHANG Mei-yue1
(1. School of Information Engineering, Chang’an University, Xi’an Shaanxi 710064, China; 2. Inner Mongolia Autonomous Region Traffic Construction Engineering Quality Monitoring and Appraisal Station, Hohhot Inner Mongolia Autonomous Region 010050, China)
To address the problem that the vehicle target detection technology of traffic monitoring videos has high rates of false detection and missed detection due to serious vehicle occlusion in traffic congestion periods such as morning and evening peaks, an improved vehicle target detection model based on YOLOv5s network was proposed. The attention mechanism SE module was introduced into the Backbone network, Neck network layer, and Head output of YOLOv5s, respectively, thus enhancing the important features of the vehicle and suppressing the general features. In doing so, the recognition capability of the detection network for the vehicle target was strengthened, and training and tests were performed on the public data set UA-DETRAC and self-built data set. The results show that the three indicators were significantly enhanced compared with the original network, which was suitable for the introduction of the attention mechanism. The evaluation rate, the value, and mean average accuracy were evaluated, and the results showed that compared with the original network, the three indicators were significantly improved, suitable for the introduction of attention mechanisms. To address the imbalance between positive and negative samples and that between difficult and easy samples in YOLOv5s network, the network combined the focus loss function Focal loss and introduced two super-parameters to control the weight of unbalanced samples. Combined with the improvement of attention mechanism SE module and focus loss function, the overall performance of the detection network was improved, and the average accuracy was improved by 2.2 percentage points, which effectively improves the index of false detection and missed detection in the case of large traffic flow.
vehicle detection; traffic monitoring; attention mechanism; focus loss function; YOLOv5 model
TP 391
10.11996/JG.j.2095-302X.2022050776
A
2095-302X(2022)05-0776-07
2022-03-08;
2022-05-09
8 March,2022;
9 May,2022
2020年度陕西省交通运输厅科研项目(20-24K,20-25X);内蒙古自治区交通运输发展研究中心开放基金项目(2019KFJJ-003)
Scientific Research Project of Shaanxi Provincial Department of Transportation in 2020 (20-24K, 20-25X); Open Fund of Inner Mongolia Autonomous Region Transportation Development Research Center (2019KFJJ-003)
赵璐璐(1998-),女,硕士研究生。主要研究方向为基于深度学习的目标检测。E-mail:2689797652@qq.com
ZHAO Lu-lu (1998-), master student. Her main research interest covers object detection based on deep learning. E-mail:2689797652@qq.com
王学营(1991-),男,博士研究生。主要研究领域为沥青路面新材料及检测。E-mail:2020124099@chd.edu.cn
WANG Xue-ying (1991-), Ph.D candidate. His main research interests cover new asphalt pavement mate rials and testing. E-mail:2020124099@chd.edu.cn
猜你喜欢
数学小灵通·3-4年级(2021年5期)2021-07-16
中学生数理化·高一版(2021年2期)2021-03-19
今日农业(2019年15期)2019-01-03
知识经济·中国直销(2018年8期)2018-08-23
小太阳画报(2018年3期)2018-05-14
数学学习与研究(2017年3期)2017-03-09
阅读与作文(小学低年级版)(2016年12期)2016-12-22
中国老区建设(2016年1期)2016-02-28
共产党员(辽宁)(2015年2期)2015-12-06
汽车文摘(2015年11期)2015-12-02
