
基于FairMOT的隧道交通车辆检测及追踪系统研究
2022-11-02 12:13康盛范益群李铮伟
电气自动化 2022年5期
康盛,范益群,李铮伟
〔1. 上海电气自动化设计研究所有限公司,上海 200023; 2. 上海市政工程设计研究总院(集团)有限公司,上海 200092;3.同济大学 机械与能源工程学院,上海 201804〕
0 引 言
随着城市规模扩大和汽车拥有量的快速增长,国内外大中城市的交通拥塞现象日趋严重。受制于车辆不断增长和道路资源有限扩张的矛盾,在20世纪90年代,国内外科学家就开展了智能交通的研究。典型代表就是美国交通能源部提出的智能运输系统(intelligent transportation system,ITS)。ITS的目标是通过对交通的信息化智能化管理,从而形成一种定时、准确、高效的新型综合运输系统。然而,由于道路种类繁多,道路环境差异、道路参与方众多且行为多样,ITS涉及技术种类繁多,系统建设投入巨大,但效果不明显。
近年来,随着物联网、大数据、人工智能和数字化城市道路建设,汽车网联化和对汽车自动驾驶的研究不断升级,人、车、路、云协同一体化的信息交互技术显得尤为重要[1]。智能交通系统可全方位实施车车、车路动态实时信息交互的车路协同道路全息感知系统,在全时空动态交通信息采集与融合的基础上开展车辆主动安全控制和道路协同管理,充分实现人、车、路、云的有效协同,保证交通安全,提高通行效率,从而形成安全、高效和环保的智能交通系统。
1 研究现状
1.1 多目标追踪
多目标追踪(multi-object tracking, MOT)的目的是在目标数量未知的情况下,对监控视频中的行人、车辆和动物等多个目标检测并赋予ID进行运动轨迹追踪。MOT是计算机视觉领域的一项关键技术,在自动驾驶、智能监控和行为识别等方面应用广泛。近年来,随着人工智能技术的突飞猛进和计算机算力的大幅度提高,基于机器视觉的目标追踪方法逐步应用于交通监控系统[2]。
1.2 国内外研究现状
目前采用深度学习的多目标追踪算法基本采用一种Tracking-by-Detection的架构。这种架构的两个关键部分就是目标检测和数据匹配。目标检测负责得到边界框,数据匹配负责得到正确的身份ID。
随着深度学习领域的目标检测近些年的飞速发展,越来越多追踪器开始使用更好的检测器来获得更好的追踪效果。YOLO系列是多目标追踪中常用的典型单阶段目标检测算法[3],Zhou等[4]也在2019年提出了CenterNet方法。
数据关联也是多目标追踪非常重要的一个环节,位置、运动轨迹和特征是进行匹配经常需要考虑的内容。SORT利用卡尔曼滤波预测轨迹得到下一帧的位置,然后通过计算与检测得到的边界框之间的IoU来进行匹配[5]。DeepSORT利用一个浅层Re-ID来得到特征信息。关于匹配策略的选择上,SORT一般直接利用IoU匹配一次,而Deep SORT利用一种级联匹配的策略。近些年,也有很多工作利用注意力机制来进行匹配。
最近,越来越多MOT算法尝试将检测网络与Re-ID网络整合到一起。Zhang等[6]在2020年基于CenterNet和JDE框架,通过提取高分辨率特征从而更好地定位中心点,提出了FairMOT,在目标追踪时同时提取检测框和检测框内目标的Re-ID信息。研究表明,与传统的JDE相比,该方法不仅提高了精度,而且减少了ID切换的次数。
2 FairMOT网络模型
2.1 模型框架
FairMOT模型框架如图1所示。

图1 框架结构
2.2 特征提取网络
在FairMOT中,特征提取采用多层融合的网络。编码器-解码器网络提取的高分辨率特征图中,三个分支被用来检测目标,分别得到热图、框的尺寸、中心点偏移;剩下一个分支专门负责目标Re-ID特征的提取。每个分支除了最后输出通道维度的不同,其组成都类似:由一个3×3卷积层后面接一个1×1卷积层实现。
3 损失函数与训练策略
3.1 损失函数
3.1.1 目标中心点损失函数
基于变形的focal loss计算预测热图和实际热图间的损失,如式(1)所示。
(1)
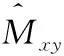
3.1.2 偏移和尺寸损失函数
偏移和尺寸的损失相加得到的定位损失,计算如式(2)所示。
(2)
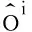
(3)
(4)
式中:(cx,cy)为目标的中心点坐标;(x1,y1)和(x2,y2)分别为目标的左上角和右上角两个角点的坐标;i为图片中的第几个目标。
3.1.3 重识别分类损失
本文选择softmax损失,重识别分类损失值的计算如式(5)所示。
(5)
式中:K为类别总数;Li(k)为第k个目标的one-hot编码;p(k)为第k个目标的预测类别可能性分布。
3.2 训练策略
训练任务流程为:
(1) 在训练任务中,经过训练得到权重文件。
(2) 准备测试集文件。测试任务中将每个监控视频图片序列的标签整理为MOTChallenge标准格式文件,标签格式为:帧、车辆ID、x坐标最小值、y坐标最小值、宽度、高度、轨迹是否激活、目标类别以及是否有交叠。最后,创建序列信息文件记录每个测试文件夹的车辆数以及帧数等信息,便于程序读取。
(3) 整理完测试集格式后,运行程序,开始测试。
测试程序运行时,首先读取图片文件和标签文件,初始化类,将图片放入对象中;然后,通过函数得到每一帧的信息和对应目标的ID。这些信息将保存在列表中,通过OpenCV进行追踪可视化显示。
最后,利用标签文件得到结果。程序将结果放入Evaluator对象中,计算得到MOTA、MOTP等信息,每一帧读取还会利用FFMPEG计算帧率,经过计算本文算法的FPS大约为25。
4 试验设计与结果分析
4.1 试验方法
4.1.1 试验基本配置
训练和测试FairMOT目标检测网络使用的计算机主要硬件:CPU为IntelXeon(R) Silver 4214R CPU@2.40GHz×24;GPU为NvidiaTeslaV100(16 GB)×2;内存为DDR4 128 GB。计算机系统环境:CentOS8,CUDA10.2,pytorch1.7.1,python3.8。
4.1.2 试验数据集
本文使用某公路隧道的真实监控视频作为数据集训练及测试FairMOT算法,同时对测试后的结果进行了可视化,并分析性能。
上述监控视频数据集拍摄的视角为高位拍摄,涵盖隧道入口、隧道内、隧道分岔路和隧道出口的场景。分别截取了3段不同场景的视频,每段视频50 s左右,共计约3 800帧图片,按照MOTChallenge标准数据集格式MOT16,利用Darklabel2.4工具进行标注,分别命名为MOT16-12、MOT16-16和MOT16-47对应3个场景。在数据集划分中,将数据集的80 %作为训练集,剩余的20 %作为测试集进行试验,部分数据集图片标注如图2所示。

图2 数据集图片标注
4.1.3 评价指标
为了更客观地评价算法的性能,本文采用多目标追踪领域通用的MOTChallenge评价体系。如表1所示,该体系的主要评价指标共有5个,其中上箭头表示该指标数值越高越好,下箭头表示该指标数值越低越好。

表1 评价指标及其解释说明
其中,MOTA直观地衡量了追踪器在检测目标和保持轨迹时的性能,是当前多目标追踪的最主要评价指标,由式(6)计算。
(6)
式中:FN为漏检的总数量;FP为误检的总数量;IDs为目标切换次数;gtDet为目标真实目标数量。
MOTA取值范围为负无穷到1。其中,负值表示追踪失败,正值且越接近1表示追踪效果越好。
4.2 结果与分析
测试结果如表2所示,列出了不同数据集下5个主要评价指标的数值。由表2可知,MOTA最高为88.5 %,MOTP最高为0.232,MT最高为22,ML最低为0,IDs最低为0,表明FairMOT算法在隧道车辆追踪中能较好地检测目标,达到较好的追踪准确度和追踪精度。
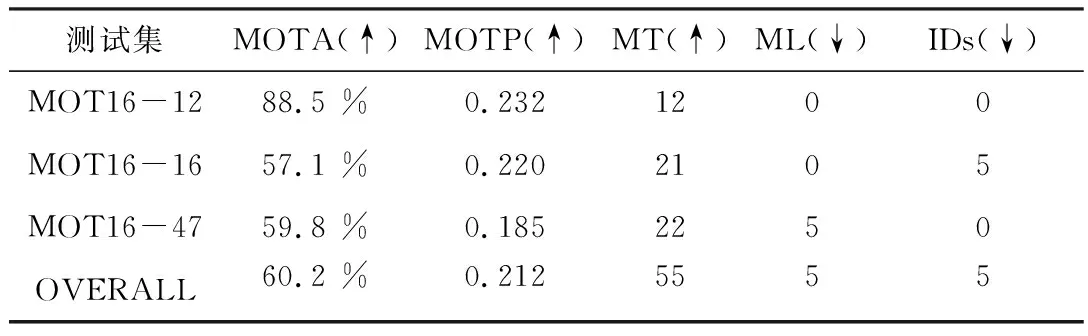
表2 不同数据集的准确率测试结果
图3分别是隧道入口、隧道内场景下的监控视频部分可视化追踪结果。其中车辆框中的数字为算法分配给每个目标的ID。由图3可知,检测中能准确预测目标的坐标和尺寸,未出现漏检现象,检测性能较好。

图3 追踪结果可视化
5 结束语
在车辆多目标追踪的问题上,由于没有针对车辆进行轨迹预测,在发生遮挡等事件时,一些算法很容易丢失目标。为了减少计算量,本文并没有对车辆的历史轨迹进行分析。因此下一步的工作,在对车辆历史轨迹分析的基础上,结合车辆颜色等图像特征及车辆位置特征等信息,在追踪时将目标与原目标进行关联,减少在车辆发生遮挡、拥堵时频繁地切换目标,提高追踪的连贯性。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年4期)2022-05-25
云南画报(2021年9期)2021-12-02
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
小天使·二年级语数英综合(2019年10期)2019-11-08
中国外汇(2019年6期)2019-07-13
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
小天使·四年级语数英综合(2016年11期)2016-11-29
共产党员(辽宁)(2015年2期)2015-12-06
