
基于变量优选和近红外光谱技术的红富士苹果产地溯源
2022-11-02 01:29张立欣杨翠芳陈杰张晓果张楠楠张晓
食品与发酵工业 2022年20期
张立欣,杨翠芳,陈杰,张晓果,张楠楠,张晓*
1(塔里木大学 信息工程学院,新疆维吾尔自治区 阿拉尔,843300)2(南京理工大学 理学院,江苏 南京,210094) 3(河南城建学院 数理学院,河南 平顶山,467036)
中医认为苹果具有生津止渴、润肺除烦、健脾益胃、养心益气等功效,并且它的味道酸甜适口,营养丰富,因此,成为老幼皆宜的水果之一。由于环境因素、土壤特征等的不同,各产地苹果的品质存在差异,其口感也不尽相同,而这些差异无法通过肉眼直接准确地辨别,化学鉴定法费时费力,不适合进行大批量操作。
近红外光谱检测以其方便、高效、快速、无污染、无需对样品预处理等优点,被广泛应用到现代农业检测分析中。主要应用领域包括:农产品成熟度的鉴别[1]、复溶果品损伤的鉴别[2]、复溶同一农产品不同基因型的鉴别[3]、复溶农产品产地的鉴别[4]、农产品新鲜度[5]、货架期[6]、霉变程度[7]、掺假的检测[8]等。在光谱分析中,经常会受到背景等随机因素的干扰,因此需对光谱数据进行预处理[9],常用的光谱预处理方法有:一阶导数(first derivative,1-DER)[10]、二阶导数(second derivative,2-DER)[11]、标准正态变换(standard normal transformation,SNV)[12],多元散射校正(multivariate scatter correction,MSC)[13]、平滑变换(smooth transformation,SG)[14]、标准化[15]、归一化(normalization,NOR)[16]、中心化(centralization,CEN)[17]等。为降低模型的复杂度,减少共线性的干扰,需要提取特征波段[18],常用的方法有:连续投影算法(successive projection algorithm,SPA)[19]、竞争性自适应重加权算法(competitive adaptive reweighted sampling,CARS)[2]、主成分分析(principal component analysis,PCA)[20]、随机蛙跳算法(random frog,RF)[21]等,也有将几种方法联合起来选择特征变量的。程介虹等[22]提出一种改进联合区间的RF选择特征波长,通过联合区间偏最小二乘法对全谱进行变量初选,此时得到的波长对目标变量变化最为敏感,将其作为RF的初始变量子集,以解决其运行时间较长、效率较低的问题。袁凯等[23]采用3步混合策略,提出了间隔偏最小二乘、区间变量迭代空间收缩法和迭代保留信息变量联用的特征变量选择方法,对生鲜鸡胸肉的近红外光谱进行特征波长选择,建立了鸡肉水分R检测模型。结果表明,建模波长数量经3步选择后减少为全光谱建模的0.76%,但模型精确度和稳定性逐步提高。FANG等[2]将SPA、CARS、过滤式特征选择。3种方法选取的特征变量组合起来建模,取得了很好的预测效果。
研究表明,光谱技术在农产品的检测分析中具有广泛的应用,但是,对苹果产地溯源的研究相对较少。目前见刊的有马永杰等[24]采用多种数据降维方法,建立k近邻(k-nearest neighbor, KNN)模型,对红富士苹果进行产地溯源,建模集和预测集的正确率分别达到97.3%和92.3%,模型的正确率有待进一步提高。本研究在前人研究的基础上,基于近红外光谱技术,以新疆阿克苏、甘肃静宁、河南灵宝和山东烟台的红富士苹果为研究对象,利用光谱分析的理论和方法,借助于光谱预处理算法,特征波长选择方法,建立概率神经网络模型对苹果的产地进行判别分析,重点研究不同的光谱预处理方法、不同的变量筛选方法对预测模型的影响,为实现红富士苹果的产地溯源提供理论参考。
1 材料与方法
1.1 材料与仪器
以阿克苏、静宁、灵宝和烟台的红富士苹果为实验对象,在实验中所使用的苹果均为2020年10月份在各苹果产地邮寄所得。挑选表面没有缺陷、直径范围为65~85 cm、大小均匀的苹果样品256个,去除表面的污垢,放置在冰柜内保存,温度控制在4 ℃,实验前分批拿出,待其恢复到室温(20~25 ℃)环境后开始实验。
实验中所用的推扫式高光谱分选系统(Hyperspectral Sorting System)为北京卓立汉光公司生产。光谱测定的范围为900~1 700 nm(实际可测量到1 750 nm),光谱分辨率5 nm,光谱采样点4 nm,选取果身中心前后左右4个方位,提取大小为20像素×15像素,4个面均进行提取,共1 200像素点,选取平均值为该样本反射率。通过自带的ENVI5.3软件提取ROI的光谱值,最后导出为Excel文件。
1.2 光谱数据的采集和校正
为了得到清晰的图像,在采集光谱数据前需要多次的相机聚焦和移动平台的速度测试,反复尝试后,确定平台的移动速度为0.35 cm/s,相机曝光时间为0.09 s。为了减少光照不均匀和暗电流对实验的影响,需要对采集到的光谱数据进行黑白校正,校正公式如公式(1)所示:
R=(I-B)/(W-B)
(1)
式中:R是校正后的光谱数据,I是原始光谱数据,W为对准白板采集到的数据,B是盖上相机镜头采集到的数据。
1.3 数据处理
1.3.1 光谱数据的预处理
在光谱检测的过程中,会受到样品背景等随机因素的影响,导致光谱数据中含有噪声,为提高模型的准确性和稳健性,需要对数据进行预处理,采用的方法有NOR、CEN、1-DER、2-DER、SNV、MSC、小波变换(wave transformation,WT)、SG、傅里叶变换(Fourier transformation,FT)。
1.3.2 特征波长提取
光谱能够体现物质所含成分及含量,但同时包含大量的冗余信息,为降低模型的复杂性,减少共线性的影响,因此,需要提取特征波长。采用的方法有PCA、SPA、CARS和RF。
1.3.3 判别分析模型
概率神经网络(probabilistic neural network,PNN)是径向基网络的一个分支,属于前馈网络的一种。它具有学习过程简单、训练速度快、分类更准确、容错性好等优点。
1.3.4 模型验证
将样本以2∶1的比例间隔分为训练集和测试集,依靠训练集建立上述判别分析模型,测试集将通过已经建立好的PNN模型进行验证,以正确率为标准来评判各类方法的优劣。
2 结果与分析
采集的红富士苹果光谱数据中,剔除异常值后,共得到阿克苏、静宁、灵宝、烟台4个产地的苹果样本各60个,其原始光谱曲线如图1所示。
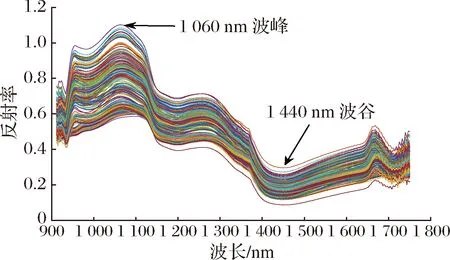
图1 原始光谱图Fig.1 Original spectrogram
不同产地的红富士苹果样本的光谱曲线变化趋势大致相同,反映不同产地的苹果之间也有着极大的相似性。但是在一些波峰和波谷处存在明显的偏离,这是由于不同产地的苹果内部成分含量的多少存在差异。在1 060 nm处也有1个明显的波峰,这与C—O—C基团有关;在1 440 nm处有1个明显的波谷,这与H2O的二倍频吸收带有关。成分含量上的差异会导致光谱曲线的差异,这为基于光谱技术对苹果产地的识别研究提供了信息。
阿克苏、静宁、灵宝、烟台4个产地的苹果样本均以2∶1的比例间隔产生训练集和测试集,得训练集中4个产地的苹果样本各为40个,即160个苹果样本组成训练集,测试集中4个产地的苹果样本各为20个,即80个苹果样本组成测试集。
2.1 光谱数据的预处理
在光谱检测的过程中,会受到样品背景等随机因素的影响,导致光谱数据中含有噪声,为提高模型的准确性和稳健性,需要对数据进行预处理。分别采用NOR、CEN、1-DER、2-DER、SNV、MSC、WT、SG、FT等9种预处理方法对原始光谱进行预处理,以消除各类随机因素对模型性能的干扰。分别以没有经过预处理的原始光谱(no pretreat, NO)和经过预处理之后的光谱数据作为输入自变量,分别建立线性的偏最小二乘判别分析(partial least squares discrimination analysis,PLSDA)模型和非线性的PNN模型,对苹果的产地进行判别,其结果如表1和表2所示。

表1 不种预处理方法下PLSDA模型的准确率 单位:%
由表1可知,不同的预处理方式下,PLSDA模型的总准确率为60%~85%,以总准确率最高为标准,最优预处理方法为MSC,此时阿克苏、静宁、灵宝、烟台4个产地的苹果识别率分别为100%、95%、85%、60%。由表2可知,PNN模型总准确率为86.25%~97.50%,最优预处理方法亦为MSC,此时阿克苏、静宁、灵宝、烟台4个产地的苹果识别率分别为100%、100%、90%、100%。

表2 不种预处理方法下PNN模型的准确率 单位:%
比较表1和表2可以发现,在相同的预处理方式下,PNN模型的总准确率高于PLSDA模型的总准确率,这是因为苹果内部的结构复杂,光在苹果内部的传输是一种复杂的结构,拥有非线性判别能力的PNN优于线性的PLSDA。为提高模型的识别率,后续的判别分析模型中,均采用MSC预处理之后的光谱数据,建立PNN模型。
2.2 特征波长的选取
对MSC预处理之后的光谱数据,分别采用PCA、SPA、CARS提取光谱数据中的重要变量作为建模输入自变量。
2.2.1 PCA选取特征变量
采用PCA算法提取主成分,各主成分解释的总方差如表3所示。
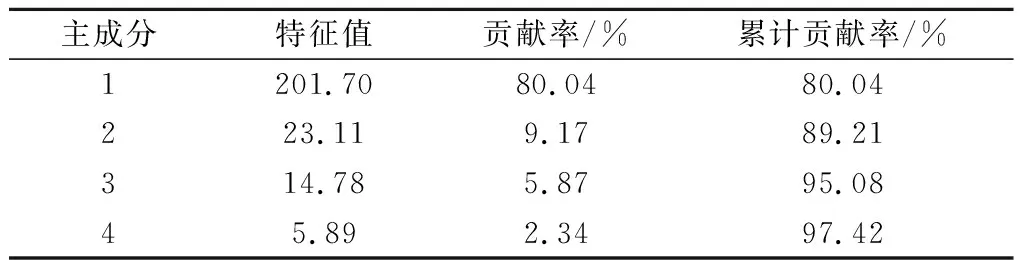
表3 解释的总方差Table 3 Eexplained total variance
前3个主成分累计贡献率达到95%以上,因此,选取前3个主成分,作为下一步判别分析模型的输入自变量。不同产地的苹果光谱数据前3个主成分的得分分别如图2所示。

图2 主成分图Fig.2 Principal component diagram
由图2可知,阿克苏红富士苹果的前3个主成分可以和其他产地的分开,而其他3个产地的苹果光谱数据之间重叠比较多,这将影响模型的识别效果。
2.2.2 SPA选取特征变量
SPA进行波长变量选择,指定波长数为1~20,采用均方根误差最小来确定最终参与建模的波长变量个数,选取过程如图3所示。

图3 SPA选取变量过程Fig.3 Variable selection process
由图3可知,随着所选的特征波长数的增加,参与建模的波长变量数增加,而均方误差整体呈现递减的趋势。当选取特征波长变量数为14时,均方根误差为0.318 4,之后均方误差逐渐趋于平缓,此时,若再多选取变量,过多的波长变量参与建模会增加模型的复杂性,而均方根误差并不会有太大的变化。因此,最终选取14个波长变量参与建模,选取的特征波长如图4所示。

图4 SPA选取的特征变量Fig.4 Selected variable
最终选取的14个特征波长为图4中的小方块对应的横坐标,即对应波长分别为911.06、923.53、929.78、980.02、1 092.04、1 175.88、1 368.46、1 402.29、1 453.03、1 529.06、1 693.72、1 704.37、1 711.48、1 715.03 nm。
2.2.3 CARS选取特征变量
采用CARS方法进行特征波长的选取,蒙特卡罗方法抽样迭代200次,抽取过程如图5所示。
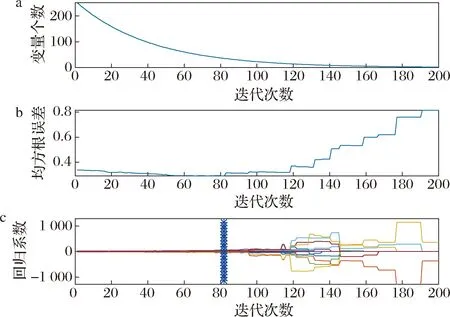
a-变量优化过程;b-均方根误差变化趋势;c-回归系数变化图5 CARS 选取变量结果Fig.5 Variable selection results
从抽取结果来看,到第82次迭代时,均方根误差达到最小为0.290 1,此时选出35个波长变量,对应的波长为:914.17、920.41、929.78、932.90、967.41、1 127.08、1 133.56、1 136.81、1 146.55、1 375.21、1 378.59、1 405.68、1 409.08、1 412.47、1 415.87、1 419.27、1 456.80、1 484.23、1 487.67、1 491.11、1 494.55、1 497.99、1 501.43、1 504.88、1 508.33、1 515.23、1 522.14、1 529.06、1 581.17、1 584.66、1 588.15、1 591.64、1 697.27、1 700.82、1 736.41 nm。
2.2.4 RF选取特征变量
采用RF算法提取特征波长变量,迭代1 000次,每个波长变量被选中的频率如图6所示。
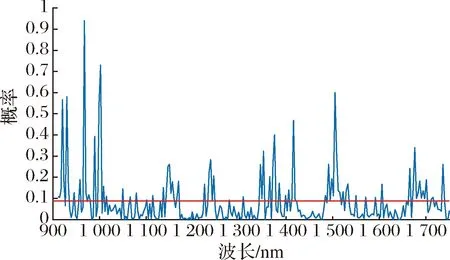
图6 每个波长变量被选中的概率图Fig.6 Probability diagram of each wavelength variable being selected
由图6可知,波长变量被选中的概率范围为0~0.941 0,优先选择率较大的波长变量,采用交叉验证的均方根误差最小来确定最终选取的变量个数,均方根误差和所选变量个数的关系如图7所示。

图7 RF选取变量过程Fig.7 Process of selecting variables by RF method
由图7可知,随着所选变量个数的增加,均方根误差迅速下降,当所选变量个数为82时,交叉验证的均方根误差最小,为0.272 2。所选取的变量为图6中概率大于0.088 0的波长,即图6中概率在水平线上方的波长变量,所对应的波长分别为:911.06、914.17、917.23、920.41、923.53、929.78、932.90、945.43、957.98、967.41、970.56、976.86、980.02、989.49、998.98、1 002.15、1 008.48、1 014.83、1 049.87、1 065.87、1 078.70、1 101.23、1 114.14、1 130.32、1 136.81、1 143.30、1 146.55、1 149.80、1 153.06、1 156.31、1 159.57、1 166.09、1 169.35、1 225.09、1 234.98、1 238.28、1 241.59、1 244.89、1 278.04、1 308.03、1 344.89、1 348.25、1 351.61、1 365.09、1 371.83、1 375.21、1 385.35、1 398.90、1 405.68、1 412.47、1 415.87、1 419.27、1 484.23、1 491.11、1 494.55、1 497.99、1 501.43、1 504.88、1 508.33、1 511.78、1 515.23、1 522.14、1 529.06、1 532.52、1 549.85、1 570.71、1 591.64、1 605.63、1 658.34、1 665.41、1 672.47、1 676.01、1 679.55、1 683.09、1 686.63、1 690.17、1 693.72、1 697.27、1 700.82、1 711.48、1 715.03、1 736.41 nm。
由于CARS和RF算法选出的 特征变量的个数仍然比较多,变量之间可能还存在共线性,为简化模型,将CARS和RF选出的特征变量再进一步优选。
2.2.5 CARS-SPA选取特征变量
对CARS方法选取的特征波长变量,采用SPA算法进一步优选,变量的选取过程如图8所示。

图8 CARS-SPA优选变量过程Fig.8 Process of optimizing variables by CARS-SPA method
随着所选变量个数的增加,均方根误差呈现递减的趋势,当选取变量个数为16时,均方根误差达到最小0.261 9。此时选取的特征波长变量如图9中小方块所对应的横坐标。

图9 CARS-SPA优选的变量Fig.9 Preferred variables by CARS-SPA method
最后选出16个特征波长变量,对应的波长为:920.41、929.78、967.41、1 127.08、1 133.56、1 146.55、1 375.21、1 378.59、1 405.68、1 412.47、1 415.87、1 504.88、1 581.17、1 591.64、1 700.82、1 736.41 nm。
2.2.6 RF-SPA选取特征变量
对RF方法选取的特征波长变量,采用SPA算法进一步优选,变量的选取过程如图10所示。

图10 RF-SPA优选变量过程Fig.10 Process of optimizing variables by RF-SPA method
随着所选变量个数的增加,均方根误差整体下滑,综合考虑均方根误差和模型的复杂性,当所选变量为17时,均方根误差为0.260 9,之后,随着变量个数的增加,均方根误差并无明显减少的趋势,因此,选取17个特征波长变量。所选取的变量波长如图11中小方块对应的横坐标。

图11 RF-SPA 优选的变量Fig.11 Preferred variables by RF-SPA method
最后选出的17个特征波长变量对应的波长为:911.06、914.17、920.41、929.78、932.90、980.02、1 114.14、1 169.35、1 371.83、1 405.68、1 453.03、1 515.23、1 591.64、1 658.34、1 693.72、1 700.82、1 736.41 nm。
2.3 建模结果分析
以选出的特征波长变量作为输入变量,建立PNN判模型,对苹果的产地进行判别分析。模型识别的准确率如表4所示。
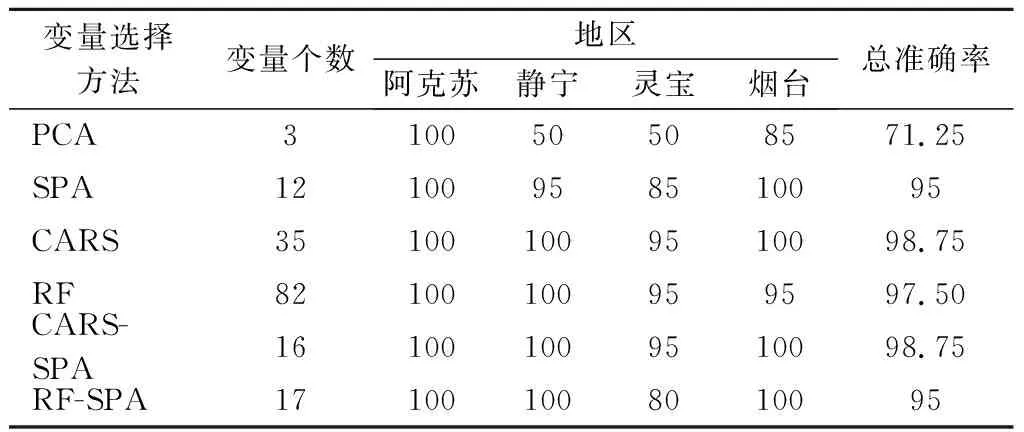
表4 不同的变量选取方式下模型的准确率 单位:%
由表4可知,总准确率范围为71.25%~100%,PCA方法选取的特征变量建模识别率最低,这是因为PCA在选取过程中,只是对样品的自变量进行重新组合,没有考虑因变量的影响。SPA算法可以最大程度地降低被选中变量间的共线性问题,但是对于光谱而言,有效变量之间的投影距离不一定最大,因此,筛选出的变量子集中可能包含一些无用信息,甚至是干扰信息,降低模型的泛化能力。CARS和RF算法选出的特征变量个数比较多,无法克服变量之间的共线性的影响,这都将会影响模型的泛化能力。CARS-SPA和RF-SPA在初选特征变量的基础上再进一步优选,选出的变量个数适中,消除了变量之间的共线性。其中CARS-SPA选出的特征变量建模,阿克苏、静宁、灵宝、烟台4个产地的红富士苹果识别率分别达到了100%、100%、95%、100%,总识别率达到了98.75%。综合考虑识别率和模型的复杂性,最优模型为MSC-CARS-SPA-PNN模型。
2.4 与KNN模型的比较
采用马永杰等[24]的K最近邻算法,分别以PCA、SPA、CARS、RF、CARS-SPA、RF-SPA选出的特征波长变量作为输入变量,建立KNN模型。k的取值范围为3~9,通过交叉验证的方式确定最佳的k值,识别结果如表5所示。

表5 KNN的识别结果 单位:%
比较表4和表5可知,在PCA、SPA、CARS、CARS-SPA变量选取方式下,PNN模型的总准确率均高于KNN模型的总准确率;在RF变量选取方式下,PNN模型和KNN模型有相同的总准确率;在RF-SPA变量选取方式下,PNN模型的总准确率略低于KNN模型的总准确率。但是,在CARS-SPA变量选取方式下,PNN模型的总准确率达到最高98.75%。
3 讨论与结论
采集阿克苏、静宁、灵宝和烟台的红富士苹果近红外光谱数据,分别进行归一化、中心化、一阶导数、二阶导数、标准正态变换、多元散射校正、小波变换、平滑变换、傅里叶变换共9种预处理方法,建立概率神经网络模型对苹果产地进行识别,结果表明,多元散射校正预处理的效果最优,4个产地的苹果样品识别率分别为100%、100%、90%、100%,总识别率为97.5%。
为了简化模型提高识别率,将多元散射校正预处理后的光谱数据分别采用主成分法、连续投影算法、竞争性自适应重加权算法、随机蛙跳算法、竞争性自适应重加权-连续投影算法、随机蛙跳-连续投影算法选取特征变量建模。研究结果表明,竞争性自适应重加权-连续投影算法效果最佳,MSC-CARS-SPA-PNN模型的总识别率达到了98.75%,4个产地的红富士苹果识别率分别达到了100%、100%、95%、100%。因此,近红外光谱技术能够快速、无损地识别苹果的产地,为红富士苹果的产地溯源提供理论参考。
猜你喜欢
宝藏(2022年8期)2022-09-27
杭州电子科技大学学报(自然科学版)(2022年3期)2022-06-08
阅读(科学探秘)(2021年8期)2021-09-01
海峡姐妹(2020年2期)2020-03-03
飞天(2019年6期)2019-07-08
意林·全彩Color(2018年9期)2018-10-12
新高考·高二数学(2015年2期)2015-05-27
新高考·高二数学(2014年7期)2014-09-18
中学生英语高效课堂探究(2008年3期)2008-04-01
