
车货匹配中考虑注意力机制的基于SENet双塔模型的司机点击率预测模型
2022-11-02 02:55王成浩合肥工业大学管理学院安徽合肥230009
物流科技 2022年10期
方 芳,王成浩 (合肥工业大学 管理学院,安徽 合肥 230009)
0 引 言
车货信息不对称的问题在车货匹配平台出现后得到了有效的缓解,但是货源和车源数量在不断增加,因此车货匹配平台也承受着越来越大的压力。然而,随着机器学习和深度学习的发展,大量的车货源数据也为车货匹配带来了新的机会,通过对数据的分析处理,可以实现更加精准的车货匹配。因此,越来越多的研究人员开始从大规模数据的角度去探索新的车货匹配方法。
在大数据时代,伴随着机器学习和深度学习的浪潮,研究人员进行了以下探索。黄美华等人通过网页爬虫采集到车货匹配平台中真实的历史数据,并利用C4.5决策树算法建立车货匹配模型,所建模型能够达到较高的匹配精确度;在此基础上,黄美华等人运用最小二乘支持向量机建立车货信息匹配模型,在保持匹配精确度的同时,缩短了一半的计算时间。Tian等考虑到目前研究理想环境、小数据集、静态匹配和匹配效率低等方面的局限,提出了一种基于改进动态贝叶斯网络的车货匹配算法,并利用从物流行业大数据平台中获得的数据进行验证,证明了该方法能够提高车货匹配的效率,同时为中小型物流企业的车货匹配提供理论参考。周夏考虑了“滴滴打车”的模式,在不平衡数据的二分类问题的实验背景下,利用集成学习的方法建立车货匹配预测模型,并利用P平台的大规模数据进行验证,为车货匹配的预测研究提供参考与借鉴价值。肖斌在虚拟环境中具体定义了车货匹配问题的半马尔科夫过程,并基于深度前馈网络设计了深度Q网络算法,有效地提高了车货匹配的效率。从这些研究中可以看出,机器学习和深度学习方法逐渐被应用于车货匹配中,并且具有很好的效果。
推荐系统中常用的模型之一就是双塔模型,其运用了深度学习的方法,具有快速筛选海量数据和准确度较高的优势,因此被广泛地应用在搜索、广告等领域。DSSM(Deep Structured Semantic Model)模型由微软于2013年提出,这便是最早的双塔模型,其通过搜索引擎里文档和查询的海量点击曝光日志,用DNN深度网络将文档和查询表达为低维语义向量,并通过余弦相似度来计算两个语义向量的距离,最终训练出语义相似度模型。视频召回双塔模型是YouTube于2019年提出的,通过计算用户和候选视频的相似度,为用户推荐其可能感兴趣的视频。莫比乌斯模型是由百度在2019年提出的,通过计算用户查询和广告之间的相似度,生成推荐序列。统一嵌入模型是Facebook在2020年提出的,通过计算查询和文档之间的相似度,为用户提供准确的搜索结果。双塔模型之所以受欢迎有以下两个原因,一是双塔分离的结构使其可以快速筛选海量数据,二是其本身是一个监督学习的过程,能够提供良好的结果。
因此,考虑到双塔模型的优势和车货平台中大量的车货数据,本文将双塔模型应用到车货匹配中,提出了一种考虑注意力机制的基于SENet双塔模型的司机点击率预测模型——A-SENet双塔模型。A-SENet双塔模型主要包括货物塔、Attention模块、司机塔和点击率输出模块。在货物塔中,对货物的多个特征进行嵌入处理,并进一步通过SENet和DNN计算货物隐向量。在Attention模块中,将与司机相关的所有货物通过Attention机制进行加权求和,为得到更加准确的司机隐向量做准备。在司机塔中,对司机的多个特征进行嵌入处理,并通过SENet进一步处理,与Attention模块的输出拼接,一起输入DNN中计算司机隐向量。最后,通过计算司机隐向量和货物隐向量的点积,预测司机点击货物的概率。基于某车货匹配平台的数据集,最终的实验结果证明了A-SENet双塔模型的有效性和优越性。
1 基于A-SENet双塔模型的司机点击率预测
面对车货匹配平台中的大规模车源和货源数据,双塔模型在保持匹配精准度的同时,也能提高匹配效率,可以快速筛选数据。当面对司机和货物大量的特征时,不同特征对点击率预测的重要性不同,而SENet可以动态地增加重要特征的权重,降低不重要特征的权重。在表示司机向量时,除了利用常规的司机特征,也可以利用历史点击货物的特征,通过Attention机制对点击过的货物隐向量进行加权求和,得到更加准确的司机隐向量。下面首先对车货匹配问题进行形式化描述,然后详细介绍基于A-SENet双塔模型的司机点击率预测。
1.1 车货匹配问题描述

通过司机塔和货物塔对司机特征和货物特征加以处理,可以得到司机隐向量和货物隐向量,从而计算出司机点击货物的概率。此时司机点击货物的标签用y表示,其中,y=1意为司机点击了的货物,y=0表示司机未点击的货物。综上所述,实验的最终目标便是预测司机点击货物的概率。
1.2 基于A-SENet双塔模型的司机点击率预测框架
基于A-SENet双塔模型的司机点击率预测框架(如图1所示),共由四个模块组成,分别是货物塔、Attention模块、司机塔和点击率输出模块。首先,货物塔通过SENet和DNN得到货物隐向量。然后,将货物塔中与司机相关的货物隐向量通过Attention机制进行加权求和。司机塔中通过SENet对司机特征进行处理。处理后的特征向量与Attention机制加权求和后的向量进行拼接,共同输入DNN中,得到司机隐向量。最后,司机隐向量和货物隐向量通过点乘和Sigmoid激活函数,计算出司机点击货物的概率。

图1 基于A-SENet双塔模型的司机点击率预测框架Fig.1 Click-through rate prediction framework of drivers based on A-SENet two-tower model
1.2.1 货物塔
在普通的双塔模型中,将处理后的货物特征输入DNN中,可以得到表示该货物的货物隐向量。在选取具体特征时,一般是根据相关知识和经验进行选取,但无法判断特征的重要性。因此,为了判断不同特征的重要性,引入SENet机制,可以动态地增加重要特征的权重,降低不重要特征的权重,从而获取更加准确的货物隐向量。

不同的货物特征向量对于货物隐向量的表示具有不同的重要性,所以引入SENet机制动态地增加重要货物特征向量的权重,降低不重要货物特征向量的权重,对嵌入后的货物特征向量做进一步的更新。SENet机制共分为三步:挤压阶段(Squeeze)、激励阶段(Excitation)、再称重阶段(Re-Weight),接下来描述货物特征向量通过SENet机制更新的具体过程。
1.2.1.1 挤压阶段

1.2.1.2 激励阶段

1.2.1.3 再称重阶段

通过上述操作,可以得到货物i的货物隐向量,同理,可以得到由n个货物的货物隐向量构成的货物塔。
1.2.2 Attention模块本研究认为司机历史点击过的货物可以表示司机的兴趣,所以将货物塔中与司机相关的货物抽取出来。但是,点击货物的重要性并不完全相同,为了更好地表示不同货物的权重,利用Attention机制对相关货物的货物隐向量分配不同的权重,并进行加权求和,为司机塔中的拼接操作提前做好准备。

α为司机j第c个相关货物隐向量的权重,S为司机j相关货物隐向量的综合表示。
通过上述操作,可以得到司机j相关货物隐向量的综合表示,同理,我们可以得到m个司机的相关货物隐向量的综合表示。
1.2.3 司机塔
司机塔的操作与货物塔的操作基本相同,目的是得到司机的隐向量表示。上一节中已经提到,为了得到更加准确的司机隐向量表示,考虑了司机的历史点击货物,并通过attention机制为不同的相关货物赋予不同的权重,得到相关货物隐向量的综合表示。在司机塔中,将其与SENet操作后的司机特征向量进行拼接共同输入DNN中,得到司机隐向量。

1.2.3.2 激励阶段

1.2.3.3再称重阶段


通过上述操作,可以得到司机j的司机隐向量,同理,可以得到由m个司机的司机隐向量构成的司机塔。
1.2.4 点击率输出模块

通过上述操作,可以得到司机j点击货物i的概率,同理,可以得到司机塔中任意一个司机点击货物塔中的任意一个货物的概率。
因为司机是否点击货物属于二分类问题,所以选择负对数似然函数作为目标函数,具体公式如下:

其中S表示总训练集,x和y分别是网络的输入和标签,()是网络的输出,表示司机点击货物的概率。
2 实 验
本节描述了为评估A-SENet双塔模型的性能而进行的实验设计,其中包括实验使用的数据集、评价指标、对比方法和实验流程。
2.1 数据集
本研究中所使用的数据集是某车货匹配平台提供的非公开的司机行为数据集,该数据集包括667名司机和2 208 579个货物,在这2 208 579个货物中,包括了与667名司机发生过交互的1 751 673个货物,而司机的交互行为包括浏览货物、点击货物和打电话,由于浏览货物的行为占司机行为中的绝大多数,所以认为浏览货物属于未点击行为,即负样本;点击货物和打电话属于点击行为,即正样本。在货物塔中所使用的也是这1 751 673个货物。为了保证实验的真实性,还进行了数据处理工作。具体来说,就是删除历史行为不超过100次和点击行为次数不超过10次的司机。因此,最终的实验数据集包括582名司机和1 105 719个货物。
2.2 评价指标
本研究选择了两种评价指标来评估我们的方法,如下所示:
AUC(Area Under Curve)是点击率预测领域常用的评价指标,将样本根据预测点击率由大到小排列,然后随机抽取一个正样本和一个负样本,正样本排在负样本前的概率即为AUC。计算公式如式(19)所示,表示从正样本集合中随机抽取的样本,表示从负样本集合中随机抽取的样本,和分别表示正负样本的数量, ()表示样本i的预测点击率的排名。AUC的上限是1,结果越大表示性能越好。

LogLoss(Log-likelihood Loss)用交叉熵来度量每个样本的预测概率和实际标签之间的距离。计算公式如式 (18)所示,LogLoss值越低,表明与实际标签的偏差越小,性能越好。
2.3 对比方法
为了验证所提出的A-SENet双塔模型的性能,与LR、双塔模型、DNN、SENet双塔模型、DeepFM方法进行了比较。其中,LR是非DNN方法,其他是基于DNN的方法。具体来讲,DNN是单模型,双塔模型、SENet双塔模型和DeepFM是双组合模型。每个方法的介绍如下:
LR (Logistic Regression,逻辑回归)是用于点击率预测的多字段分类数据的最广泛使用的模型,它执行基本形式的逻辑函数来模拟二元因变量。
双塔模型是在推荐系统召回和粗排环节中广泛应用的模型,双塔的结构使其能够快速筛选海量数据。
DNN是一个标准的深度神经网络,只包括用于预测的嵌入层和MLP层。
SENet双塔模型在双塔模型的基础上,在左右双塔均添加了SENet模块,动态地表示不同特征的重要性,在不影响双塔模型速度的前提下,增加了双塔模型的准确度。
DeepFM由Deep部分和FM部分组成,能够同时学习低阶和高阶特征的交互。
2.4 实验流程
使用PyTorch实现本文提出的方法和所有的对比方法。采用60%的数据集作为训练集来学习参数,20%的数据集作为验证集来调整超参数,20%的数据集作为测试集来评估性能。对于所有的实验模型,默认使用Adam作为优化器,学习率初始为0.001。神经网络的隐藏层设定为与嵌入维度相同,Batch size设为64。使用Dropout来防止神经网络中的过拟合。根据经验,设置如下超参数:在{32,64,128,256,512}中测试嵌入维度,在{0.1,0.3,0.5,0.7,0.9}中测试Dropout比率。
3 讨 论
本节将A-SENet双塔模型与对比方法进行比较以评估性能,同时探讨了嵌入维度和Dropout比率对模型的影响。因为在对比方法中有双塔模型和SENet双塔模型两种,关于SENet模块和Attention模块的必要性可以根据实验结果证明,所以在本节中没有做消融实验。
3.1 结 果
实验结果如表1所示,所有实验结果都是通过5次实验以平均值报告的。从表1中可以发现,不论是AUC指标,还是LogLoss指标,A-SENet双塔模型是优于其他对比方法的。具体来说:

表1 AUC和LogLoss下的方法性能比较Table1 Performance comparison of methods by AUC and LogLoss
LR的结果最差,说明非DNN的方法相比DNN的方法还是要差一些,即使在准确度上不占优势的双塔模型,其AUC和LogLoss结果相比LR也分别有1.26%和2.05%的改进,这也表明深度学习模型的非线性泛化能力有助于预测司机点击货物的概率。
DNN的AUC和LogLoss结果要优于双塔模型,虽然双塔模型包含两个DNN模块,但是每个DNN模块只服务于司机特征或货物特征,而DNN输入的为司机特征和货物特征,能够捕捉到司机和货物交互的特征,这表明司机特征和货物特征的交互有助于预测司机点击货物的概率。
SENet双塔模型的AUC和LogLoss结果要优于DNN,虽然没有融合司机特征和货物特征,但SENet模块的添加使司机特征和货物特征的权重进行了动态调整,增加了重要特征的权重,能够得到更加准确的司机隐向量和货物隐向量,这表明SENet的使用有助于预测司机点击货物的概率。
DeepFM的AUC和LogLoss结果要优于SENet双塔模型,DeepFM实现了司机特征和货物特征的低阶和高阶交互,相比之前增加了特征的低阶交互,这表明同时进行高阶和低阶特征的交互有助于预测司机点击货物的概率。
A-SENet双塔模型的AUC和LogLoss结果要优于DeepFM,因为A-SENet双塔模型通过Attention机制将司机的相关货物加权求和,加强了司机隐向量的表示,这表明Attention和SENet的同时使用有助于预测司机点击货物的概率。
仅从双塔模型的角度考虑,即同时考虑双塔模型、SENet双塔模型和A-SENet双塔模型这三种方法。首先,从结构方面,虽然对普通的双塔模型进行了结构的调整,但整体思路不变,仍是得到司机隐向量和货物隐向量,这表明结构复杂度的增加并没有影响模型处理数据的效率。其次,从结果来看,相比双塔模型,SENet双塔模型在AUC和LogLoss方面分别获得了8.79%和10.51%的改进,这表明了SENet模块的必要性。同理,A-SENet双塔模型相比SENet双塔模型也有一定的改进,这也表明了Attention模块的必要性。综上所述,融合了SENet和Attention的双塔模型不仅保留了处理车货数据的高效率,还提高了预测司机点击货物概率的准确度。
3.2 嵌入维度的影响
在这一小节,研究嵌入维度对模型性能的影响。具体来说,在保持其他参数固定的情况下,嵌入维度在{32,64,128,256,512}的集合中搜索。图2显示了不同嵌入维度下双塔模型、SENet双塔模型和A-SENet双塔模型在AUC和LogLoss方面的比较结果。从图2中可以看到,随着嵌入维度的增加,方法性能呈现先上升后下降的趋势,嵌入维度为128时AUC和LogLoss取得最好的结果。这一结果表明较大的嵌入维度可以包括更多有用的特征,然而嵌入维度如果设置得过大,整个模型会更加复杂,容易遭受过拟合问题,从而导致模型性能下降。因此,选取嵌入维度为128。
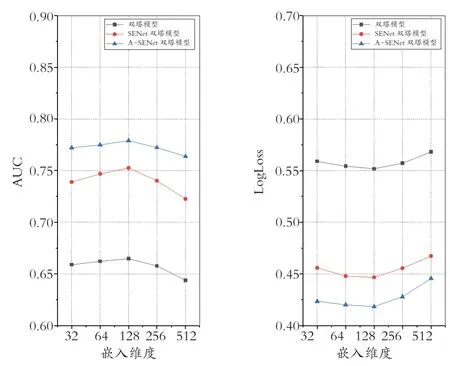
图2 不同嵌入维度下的方法比较结果Fig.8 The comparison results of methods at different embedding size
3.3 Dropout比率的影响
深度学习方法总在遭受拟合问题的困扰。Dropout是一种通过在训练过程中随机丢弃神经元来缓解过拟合问题的有效策略。所以,在这一小节来研究Dropout比率对模型性能的影响。具体来说,在保持其他参数固定的情况下,Dropout比率在{0.1,0.3,0.5,0.7,0.9}的集合中搜索。图3中展示了不同Dropout比率下双塔模型、SENet双塔模型和A-SENet双塔模型在AUC和LogLoss方面的比较结果。从图3中可以看到,方法性能呈现先上升后下降的趋势,Dropout比率为0.3时AUC和LogLoss取得最好的结果。这一结果表明丢弃较多的神经元会损失过多的信息,导致模型的性能降低,而丢弃较少的神经元又无法有效地解决过拟合问题。因此,选取Dropout比率为0.3。

图3 不同dropout比率下的方法比较结果Fig.9 The comparison results of methods at different dropouts
4 结 语
文章以车货匹配平台中的大规模数据为切入点,结合深度学习,提出了考虑注意力机制的基于SENet双塔模型的司机点击率预测模型——A-SENet双塔模型。在双塔模型的大框架下,利用Attention和SENet对司机特征和货物特征进行处理,得到司机隐向量和货物隐向量,进一步计算司机点击货物的概率。在某车货匹配平台数据集的支持下,经实验结果证明了该方法的有效性和优越性,也证明了利用深度学习方法进行车货匹配的可行性。
猜你喜欢
电力科技与环保(2022年3期)2022-07-15
能源工程(2022年1期)2022-03-29
小猕猴学习画刊(2019年9期)2019-11-08
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
水利规划与设计(2018年1期)2018-01-31
小天使·三年级语数英综合(2017年6期)2017-06-07
海峡姐妹(2015年8期)2015-02-27
读写算(中)(2014年2期)2014-03-05
海关与经贸研究(2014年3期)2014-02-28
海外英语(2013年3期)2013-08-27
