
基于人口聚集城区物流配送需求的细分及预测
——以青岛为例
2022-10-28 07:48聂闻聪楚龙娟刘永权
物流技术 2022年9期
聂闻聪,向 楠,楚龙娟,刘永权
(1.中建地下空间有限公司,四川 成都 610200;2.四川交投物流有限公司,四川 成都 610200)
1 城市配送需求预测存在的问题
国内针对物流需求预测的研究先后经历了从区域物流、城市物流、第三方物流等宏观层面,到冷链物流、港口物流、农产品物流等针对某一细分领域的研究转变,已经由宏观的体系化研究,转变聚焦到更加贴合生活、工作的类似社区团购、外卖送餐、货拉拉等专业化城市配送物流研究上。近年来,我国大型城市发展也逐步形成不同的人口聚集区域,住宅区域、办公区域和商业区域的功能存在明显的差异,从时效、品类等方面也形成了不同的物流需求特征。
需要特别指出的是,物流需求不能等同于物流需求量,只有被满足的物流需求才能叫做物流需求量。因此,物流需求与物流需求量是有区别的,本文是基于物流需求分析,暂未考虑逆向物流,其目的是为城市规划、企业运营提供预测方法及数据参考。
现有的物流需求预测研究强调特定方法在实际生产生活中的具体应用,侧重解决我国城市经济发展的实际问题,这也使得城市配送需求研究一直是目前国内学者不断探讨的热门主题。在物流需求预测方法方面,国内外学者也主要集中于采用经典的时间序列模型、模糊理论、回归分析、指数平滑、灰色模型,求解方法从启发式算法,再到人工智能、复杂网络等,相关模型的应用多样,但基于城市配送基础数据的统计分析、数据规律模型研究相对较少。
在实际应用中,通常是以统计数据中货运量或货物周转量进行近似替代,或是根据经验值进行折算,将其中部分作为城市配送需求预测的基础数据,仅能得到趋势性预测结论。虽然从货物周转量的角度,城市物流需求可以通过物流各个环节(如运输、仓储、配送、流通加工等)的支撑能力进行研究,但目前我国物流统计指标比较单一、粗放,各项预测基本只有依靠货物运输量和货物运输周转量来进行比较笼统的换算,缺乏实际有效的数据支撑。因此在预测城市配送物流需求时存在较大偏差,主要原因如下:
(1)官方对货运量的粗放统计,与实际有效物流量需求存在结构性差异。其中,官方货运量统计同时包含了第一、二、三产业的物流量。由于城市分工和产业聚集,每一个城市所生产的农产品以及大部分工业产品并不一定在本城市进行消费,导致官方粗放统计形成的数据基数往往偏大,同时,各产业的占比结构不同,以常规产业占比作产业物流量的区分,将会影响预测数据的准确性。
(2)同城内部的配送暂未纳入货运量官方统计,导致同城配送量的数据统计缺失。随着物流的社会化发展,社区团购等新业态下,部分日用品和生鲜产品的销售渠道转移到了线上,即出现了以同城即时配送为代表的物流需求,包括送餐服务、社区团购、生鲜仓配等模式,这一部分物流量不适用基于货运量的物流需求预测方法。
(3)统计数据与实际值有一定的差距。官方统计数据仅能描述宏观经济的运行情况,由于统计调查方法、数据收集能力、调查范围等限制以及我国现行统计制度不完善,导致统计数据不完备,与实际有一定出入。
(4)城市配送系统是开放系统,影响物流需求的因素众多,量化处理难度大,且数据灰性大,一般又包含许多随机性因素之间的相互作用,很多过程具有后效性,关系不确定性较强,因此,目前对于各项经济因子与物流需求规模间的关系还没有建立确定的数学模型。
然而,城市配送需求的准确性是影响城市规划及新业态下城市物流基础设施建设的关键,也是物流企业运营最为关注的核心因素。其主要原因在于城市配送服务能力不可储存,具有易逝性,一旦配送车辆驶出配送中心,在配送车辆还有额外装载能力和行驶里程的情况下,这些未被利用的配送能力就会浪费,无法像实体产品那样利用库存等措施进行存储。这也就导致当城市的物流基础设施或企业的配送规划出现偏差时,很难通过低成本策略进行改善。
2 城市配送需求分析
通过分析物流行业统计指标结构以及7个大城市物流需求规律可知,城市化进程的加速以及电子商务活动的快速发展,部分商贸流通的物流需求转化为网上购物形成的包裹快递物流需求,特别是随着城市快速发展,产生各类新需求新业态的同时,必然会有企业为满足这种需求,调动必要的资源,进行新业务开发、运营和销售。随着消费趋势和消费结构的持续演变,城市配送需求规模也将受到一定影响。
由于城市配送需求的预测复杂程度高,存在较多的影响因素,导致针对其进行估计的数据准确性不高。因此,要分析城市配送需求,首先需要对城市物流配送的层级结构、居民支出结构、物流设施以及主要的需求区域进行分析。
考虑到统计数据获取的难度以及时间和成本的限制,无法对所有城市进行抽样调查,需构建一个基于统计数据的城市配送需求预测方法,初步分析城市配送的物流量以及主要品类。
城市配送需求品类可分为三种:城市农副食品配送需求、城市内部产生的即时配送物流需求以及城市工业品配送需求,如图1所示。

图1 城市配送需求分析框架
2.1 城市农副食品配送需求
不同城市所处的地理位置不同,经济发展水平不同,因此食品消费习惯也存在差异。城市配送需求主要以服务消费者为目的,因此农副食品物流需求预测与人口数量相关,在一定时间内人均农副食品消费不会出现大幅的波动,城市农副食品配送需求可通过国家统计局《统计年鉴》中不同地区的主要农副食品消费量以及城市人口进行估算。
2.2 即时配送需求
城市内部的即时配送主要集中在送餐业务、社区团购等同城短距离配送,由于该类物流需求具有非常强的互联网粘性,目前已形成了以美团、阿里饿了么等为龙头的寡头市场。在市场竞争趋于平稳时期,其每单成本差异不大,因此在预测该类需求时,可以参考以上两家公司公开发布的年报进行测算:以2019年为例,美团外卖佣金为496.64亿元,交易笔数25.05亿单;饿了么外卖佣金为180.58亿元,可粗略推算出,同城即时配送需求量为36.07亿单。由于此类需求对城市配送需求的影响集中在特定时间段和短距离区域,其需求相对较为独立,因此,本文仅对数据测算进行说明,不作深入探讨。
2.3 城市工业品配送需求
城市工业品配送涉及耐用品、日用品这两部分,对应《统计年鉴》中的限额以上批发和零售业商品分类销售额,其中包括了27大类(见表1)。
3 物流量估计方法
由于统计年鉴中的相关统计数据仅提供了销售额数据,没有重量数据。因此需采用网络大规模调研的方式,取得对应的平均重量,从而换算出较为准确的物流需求量。
单位价格重量调研针对两类物资,一类为批发物资,可以考虑以专业市场的定价为标准,通过批发市场价格表获取;另一类为零售类物资,可以采用抽样调查的方式获取。以上两种物资的调研,均存在样本获取难度大、花费时间长、成本高等问题,直接调研实施难度大,目前电子商务数据比较全面,数据真实有效,因此通过收集电商平台数据进行调研,获取该品类货品的价格、重量数据,通过聚类的方式得到相对准确的单位价格重量,通过以农产品对标的误差分析,将误差弹性系数引入模型,从而将统计数据当中的金额转化为物流需求重量。
在完成对城市配送物流量的测算之后,可以根据不同年份的价格指数,对单位价格重量均值进行年份还原,进而使用时间序列数据对城市物流配送量进行预测。
城市内部产生的同城配送物流需求量主要集中在几个大型即时配送公司,可以通过其公布的年报测算出相应的物流订单数量,此部分物流需求预测可单独进行。整体预测思路如图2所示。

图2 预测城市配送物流需求思路
3.1 预测步骤
第一步:确定预测范围。
第二步:根据预测范围及考查的物流需求细分类收集年鉴数据,包括:GDP、第一产业值、第二产业值、第三产业值、人口规模、居民可支配收入、居民消费水平、地区消费品零售总额;批发和零售业商品分类销售额;商品零售价格指数;人均消费农产品数量。
第三步:进行网络调研,获取分类单一产品销售量、单价、毛重(注意获取数据尽可能全面,网络调研取数时间点与相应年鉴年份一致)。
第四步:对数据进行分析,进行数据清洗,确保数据的有效性,由于长尾效应,取前80%权重的数据集作为有效数据(注意异常数据、空值、虚假数值)。
第五步:根据不同年份的价格指数,对单位价格重量均值进行年份还原,得到预测数据集。
第六步:以GM(1,1)或回归预测模型进行预测,也可选取合适的时序预测方法,根据需要预测出预测范围内对应年限城市配送需求。
3.2 大品类分类
根据统计年鉴中定期报表数据,涉及物流的大品类分为27项,根据目前城市配送实际,需剔除工矿、原料、机电类,以及医药、汽车等有专门物流系统的品类,因此涉及到城市配送的有13项,见表1。
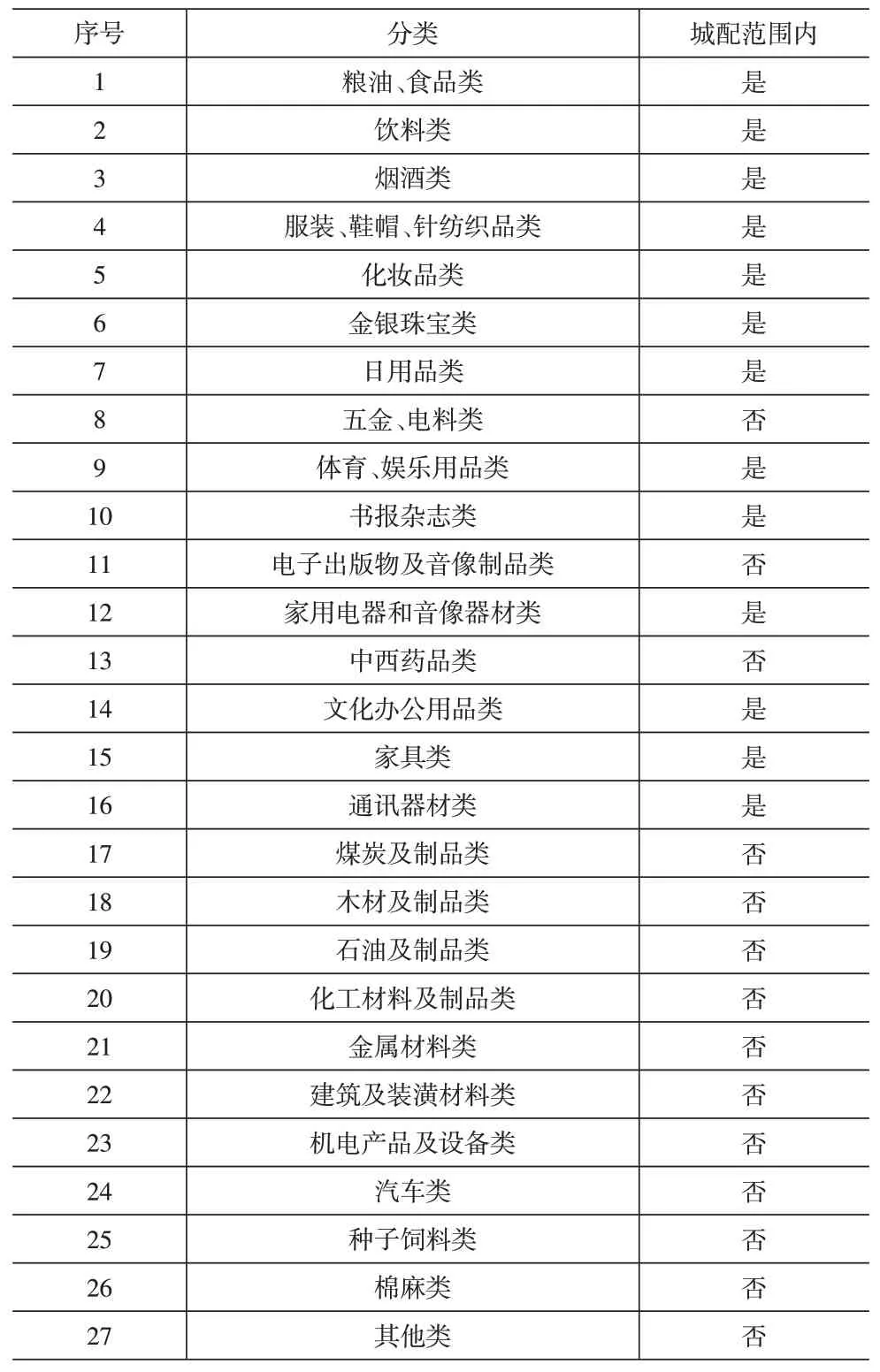
表1 城市配送品类
3.3 构建预测模型
根据预测思路及调研数据,构建数学模型如下:

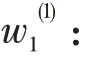
Q:人均消费食品数量;
:预测范围内人口总数。
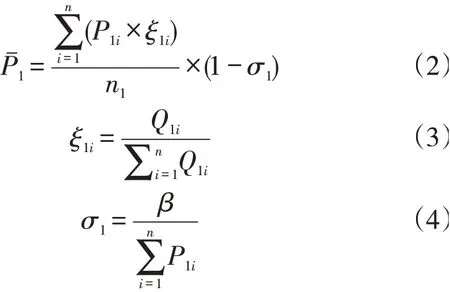
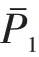
:第i个食品调查单品单公斤价格(元/kg);
:第i个食品调查单品权重系数;
:食品调查单品总数;
:电商配送价格系数;
:第个食品调查单品销售数量;
:调查产品配送价格(元)。

:根据调查估算的食品物流配送量;
:食品批发零售销售总额。

:产品估算误差系数,一般小于5%,若大于5%,则返回查看调研数据是否存在异常,关键词是否准确。

w:第项品类根据调查估算的产品物流配送量(根据前述城市配送需求存在于13个大项中);
C:第项品类批发零售销售总额;
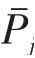
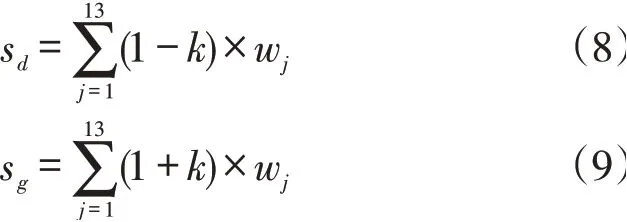
s:总城市配送物流需求下限;
s:总城市配送物流需求上限。
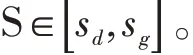
由于调查数据是一个时间点上的数据集,因此需要对历史数据进行折算,得出整个预测数据序列,补全方法如下:
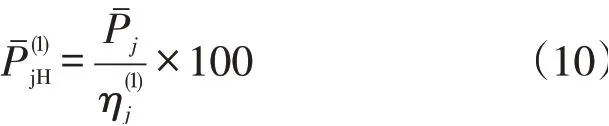

3.4 预测方法
目前对于灰色关联分析的理论已有较为详细的阐述,通过实例分析可知组合预测方法的误差值更小。如果灰色预测的精度达不到要求,就应试探性采用多项式拟合、回归预测方法等。因此,本文针对不同品类,采用灰色预测或线性拟合的预测方法,以达到更好的预测精度。
(1)灰色预测。灰色GM(1,1)模型的研究对象是“部分信息已知,部分信息未知”的贫信息不确定系统。把预测数据序列看作随时间序列数据序号变化的灰色量或灰色过程,适用于对单调非负光滑数据序列进行分析处理,此时的误差较小,预测精度较高。
(2)线性或多项式拟合。在GM(1,1)预测后验差较大,达不到预测精度时,采用线性拟合或多项式拟合,取得预测数据。根据不同数据集的趋势情况确定合理的预测方法,最终获取各项分类的预测量,求和得出城市配送需求预测值。
4 案例预测——以青岛为例
4.1 数据分析
根据已获取的电商数据集进行品类分析,共涉及1 373个品类、1 922万条数据。
为了对数据的有效性进行验证,选取农副食品品类,通过人均农副食品消耗量测算,与调研数据进行对比校验。
对电商数据中的13万条食品信息进行分析,经过清洗处理,剔除重复、异常数据后,可得到农副食品数据分布情况,如图3所示,可以发现非常明显的长尾效应,即大部分有价值(销量更大,即权重更大)的信息集中在头部,因此取置信区间80%的数据集作为分析依据,舍弃尾部无价值信息。
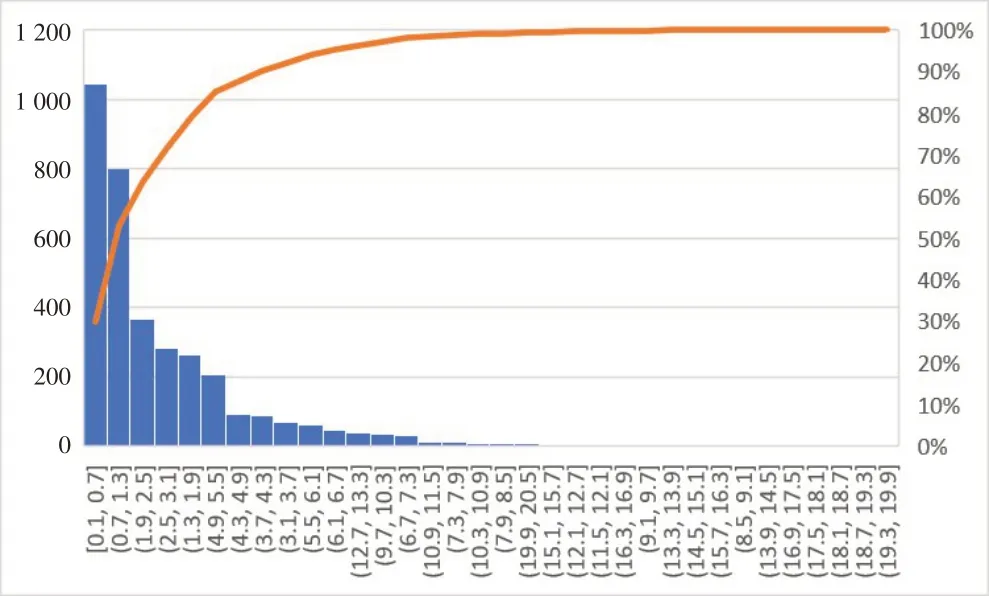
图3 农副食品数据长尾分布情况
对于置信区间内的数据分布进行进一步分析,纵坐标为价格(元),横坐标为毛重(kg),气泡大小为采购量(kg),如图4所示,可以看出置信区间内的数据相对比较集中,可以聚集出一个有效单位重量价格,以便换算出物流量。
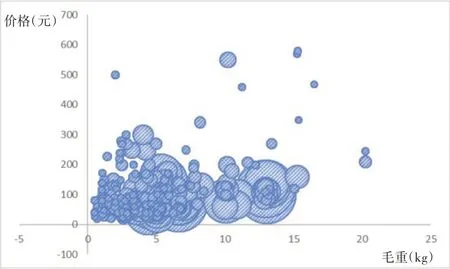
图4 调查农副食品价格重量分布
4.2 物流量估计验证
以青岛市数据进行测算,关键指标测算见表2,与调研数据对比,通过人口数据进行测算的人均农副食品消耗量误差在3.60%,说明根据通过调研获取的数据能够作出有效预测。

表2 根据模型测算出的关键指标
按照模型测算剩余13项品类数据,结果见表3。
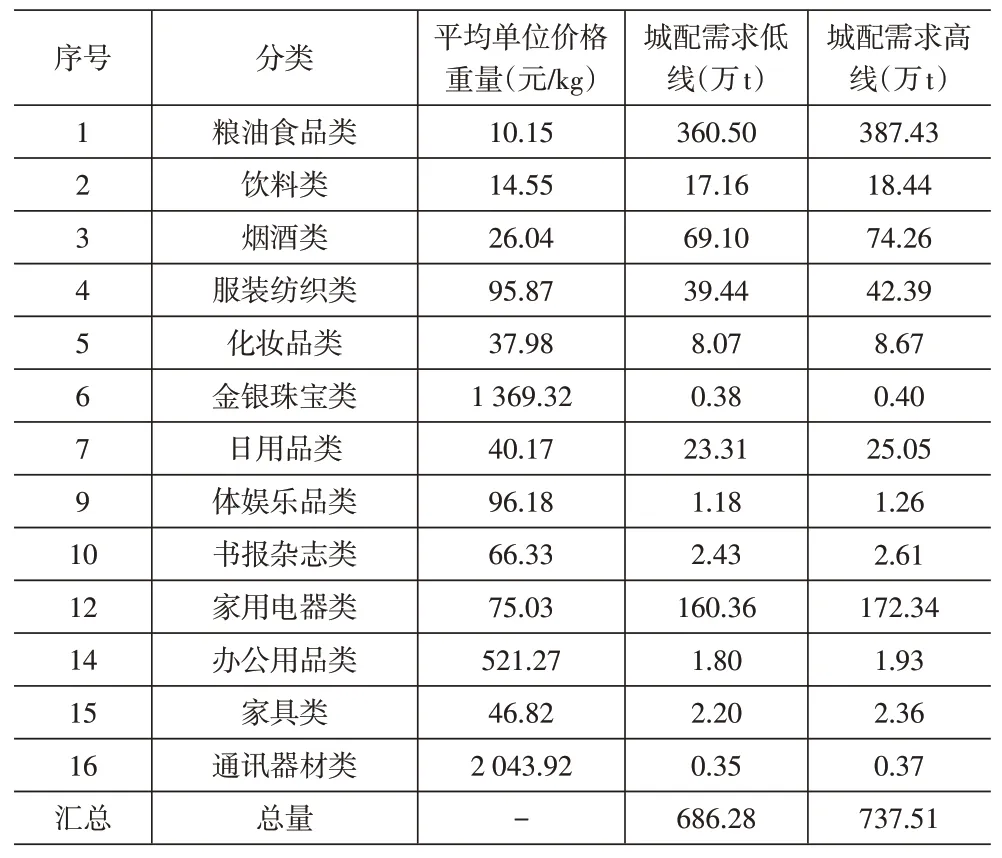
表3 模型测算13项城配品类结果
通过对历年单位价格重量测算,采用GM(1,1)和线性拟合方式,对各项分量进行外推预测,预测至2025年,城市配送需求低值为1 947.75万t,高值为2 087.54万t,见表4、表5。

表4 各品类2025年低线预测值及选取模型
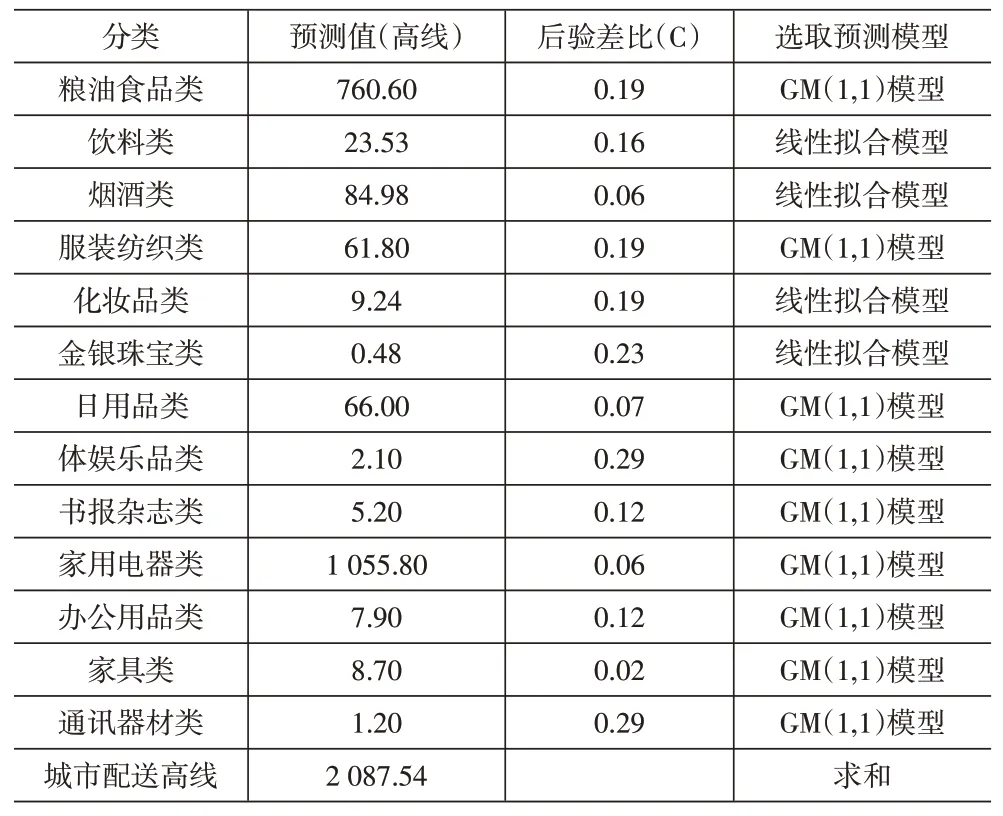
表5 各品类2025年高线预测值及选取模型
预测至2025年,青岛市城市配送需求在1 947万t至2 087万t之间。
5 预测结果分析
通过对需求模型的细化分类,可根据数据的特性选择更优的预测模型,将多个单一方法的预测结果进行有效组合,在一定条件下可以克服单一预测方法的局限性,提高物流需求的预测精度。如GM(1,1)模型在预测过程中会将不规则变动视为干扰,对波动变化明显的序列而言,预测误差相对较大,因此采用线性拟合模型进行预测,确保各分量模型精度均达到优(C<0.35)。
从预测结果可以看出,考虑经销商相互之间购买、配送的情况,青岛市城市配送需求总量呈快速上升趋势,其中粮油食品类、家用电器类为增长量最大的两类。
本文研究对于在政府主导下进行物流配送基建工作具有指导意义,结合当前市场供应商的饱和度以及现存的配送物流业态,可从规划的角度避免区域内同质化竞争和不必要的浪费。
6 结论与展望
城市配送需求实际是一个随着人口聚集区域的要素禀赋、需求结构、技术进步而变化的供需优化配置的过程。供需匹配程度越高,其资源配置效率就越高。本文从大数据调研的角度分类处理城市配送物流量,推导出相对准确的城市配送需求估计及预测方式。通过该方法可对城市配送需求进行细分类别预测,从而在规划及资源配置时,考虑不同的类型和应用场景。如通过某类城市配送量的预测,为该类城市配送企业网络规划提供参考,匹配相应的分拨中心、城内中转物流节点、客户收取点。在物流资源供给规划方面,也可以为大型卖场、专业市场、综合商业体等的规划提供分类预测数据。
然而模型仍然存在一些待解决的问题,一是调研取样不够全面,缺乏实地调研数据进行修正;二是当统计分类调整时,会造成相应数据无法进行历史数据还原。
猜你喜欢
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
华声(2022年4期)2022-05-05
汽车观察(2016年11期)2017-06-03
金点子生意(2014年4期)2014-04-10
中外玩具制造(2013年11期)2014-02-10
中外玩具制造(2013年8期)2013-11-25
中外玩具制造(2013年5期)2013-10-15
物流技术与应用(2009年4期)2009-04-28
中学生英语高效课堂探究(2008年9期)2008-11-17
