
基于YOLO算法的不同品种枣自然环境下成熟度识别*
2022-10-27 04:02王菁范晓飞赵智慧张君孙磊索雪松
中国农机化学报 2022年11期
王菁,范晓飞,赵智慧,张君,孙磊,索雪松
(1. 河北农业大学机电工程学院,河北保定,071001; 2. 河北农业大学园艺学院,河北保定,071001)
0 引言
枣富含维生素、多糖、有机酸和氨基酸等,具有极高的营养价值和药用价值[1]。枣园中果实密集和枝叶遮挡严重现象,为枣果实采摘增加了难度。现主要采摘方式为人工采摘与机械采摘[2-4],人工采摘费时费工,也会出现因人工采摘时间较长导致枣错过采摘期、遗漏等问题;机械采摘主要通过抖动枝叶使其落果,这个方式会将未熟的果实一起摘下,增加了果实品质筛选的困难和经济损失。为实现枣树自动采摘,针对枣果实的精确识别技术至关重要。
随着科技和经济的发展,机器视觉技术愈加成熟,受到了广泛的关注和研究,已经被应用在各个领域,成为工农业发展的重要组成部分[5-6]。针对果实成熟度识别问题,近几年有学者进行了传统机器学习的研究[7-10]。其中针对荔枝成熟度识别,基于RGB-D相机结合传统机器学习算法的识别准确率最好,绿色荔枝为89.92%,红色荔枝为94.50%。由于传统机器学习方法在自然环境下鲁棒性和实时性都比较差,很难满足果实智能机械化精准采摘的需求。
随着深度学习的不断完善,卷积神经网络(CNN)在目标识别上体现了强大的优越性。有少数学者将CNN用在单一品种的果实成熟度识别上[11-12],其中成伟等[11]将改进YOLO V3算法用在番茄识别上,得到最优估产模型的平均精度均值mAP为95.7%;刘坤等[12]以灵武长枣为研究对象,探究利用BP神经网络实现对灵武长枣成熟度的分级,准确率可达84%。单一品种果实成熟度检测具有一定的局限性,难以满足市场多品种的需求。
以上研究为卷积神经网络在枣果实成熟度识别上提供了依据,本文结合卷积神经网络对多品种枣果实进行自然环境下的成熟度识别研究,对比不同YOLO算法在成熟度识别上的差异。
1 材料与方法
1.1 试验数据集
本文图像采集地点为河北省保定市河北农业大学三分厂枣园,在自然环境下的晴天和阴天、白天和傍晚进行采集。拍摄设备使用尼康D7100相机,共采集18个品种的枣果实图像(18个品种分别为金丝小枣、义乌大枣、观音枣、磨盘枣、辣椒枣、蜂蜜罐枣、月光枣、毛卜彦玲枣、六月鲜、冬枣、雨帅、赞硕、大金丝王枣、星光、阜帅、阜香、雨娇、MX),获得枣图像数据集。共选取2 395幅枣图像作为枣果实成熟度检测试验所用数据集,并使用图像标注工具LableImg对枣果实目标进行标注,得到VOC格式的xml文件。本文采取了两种标注方式,常规识别方式Ⅰ将枣果实分为未熟果实和成熟果实两种类型标注,其中未熟果实为全绿硬果,成熟果实为果皮带红的果实;由于鲜食品种需要在采摘时只采摘枣果皮红绿相间的果实,识别方式Ⅱ为满足枣的鲜食品种采摘将方式Ⅰ中的成熟果实分为半红果实(果皮红绿相间)和完熟果实(果皮全红),即未熟果实、半红果实和完熟果实三种类型进行标注,如图1所示。

(a) 未熟果实 (b) 半红果实 (c) 完熟果实
将标注的枣果实数据集划分为训练集、测试集、验证集且比例关系以7∶1∶2进行随机分配,分别为1 881、209、505幅图像。
1.2 试验运行条件
模型训练和测试均在同一台计算机进行,硬件配置为Inter Core i5-10400fCPU@2.9 GHz,GPU为6 GB 的GeForce GTX 1660SUPER,16 GB运行内存,软件环境为64位Windows10系统,Keras深度学习框架。
1.3 基于YOLO算法的枣果实成熟度训练模型
本文采用YOLO算法的YOLO V3、YOLO V4、YOLO V4-Tiny和Mobilenet-YOLO V4-Lite四种神经网络目标检测模型对多个品种的枣果实进行训练。
1.3.1 YOLO V3目标检测模型
YOLO V3[13-14]是一个端到端的回归网络模型,其主干特征提取网络为Darknet-53,它由连续的3×3和1×1卷积层组合而成,具备残差网络Residual和每个卷积部分使用了特有的DarknetConv2D结构两个特点。YOLO V3网络结构如图2所示,将尺寸为416×416×3的数据集输入到Darknet-53中,经过一次32×3×3卷积层和4次残差网络输出3个特征层,3个特征层位于主干部分Darknet-53的不同位置,分别位于中间层、中下层、底层,3个特征层的尺寸分别为(52,52,256)、(26,26,512)、(13,13,1 024)。利用这3个有效特征层构建特征金字塔FPN(Feature Pyramid Networks)进行加强特征提取,构建方式如下。
1) 位于底层的特征层进行5次卷积处理后利用YoloHead获得预测结果,一部分用于进行上采样UpSampling2D与中下层的特征层进行结合。
2) 结合特征层再次进行5次卷积处理后利用YoloHead获得预测结果,一部分用于进行上采样UpSampling2D后与中间层的特征层进行结合。
3) 结合特征层再次进行5次卷积处理后利用YoloHead获得预测结果。
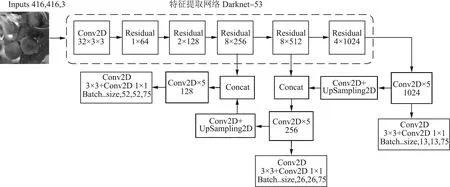
图2 YOLO V3网络结构图
1.3.2 YOLO V4目标检测模型
YOLO V4[15-17]是YOLO V3的改进版,YOLO V4的主干特征提取网络CSPDarknet-53将跨阶段部分连接(CSP)、Mish激活函数、马赛克数据扩增等方法加入到YOLO V3算法的主干特征提取网络中,特征金字塔部分使用了空间金字塔池化结构(SPP)和路径聚合网络(PAN),其SPP与PAN结构如图3所示。
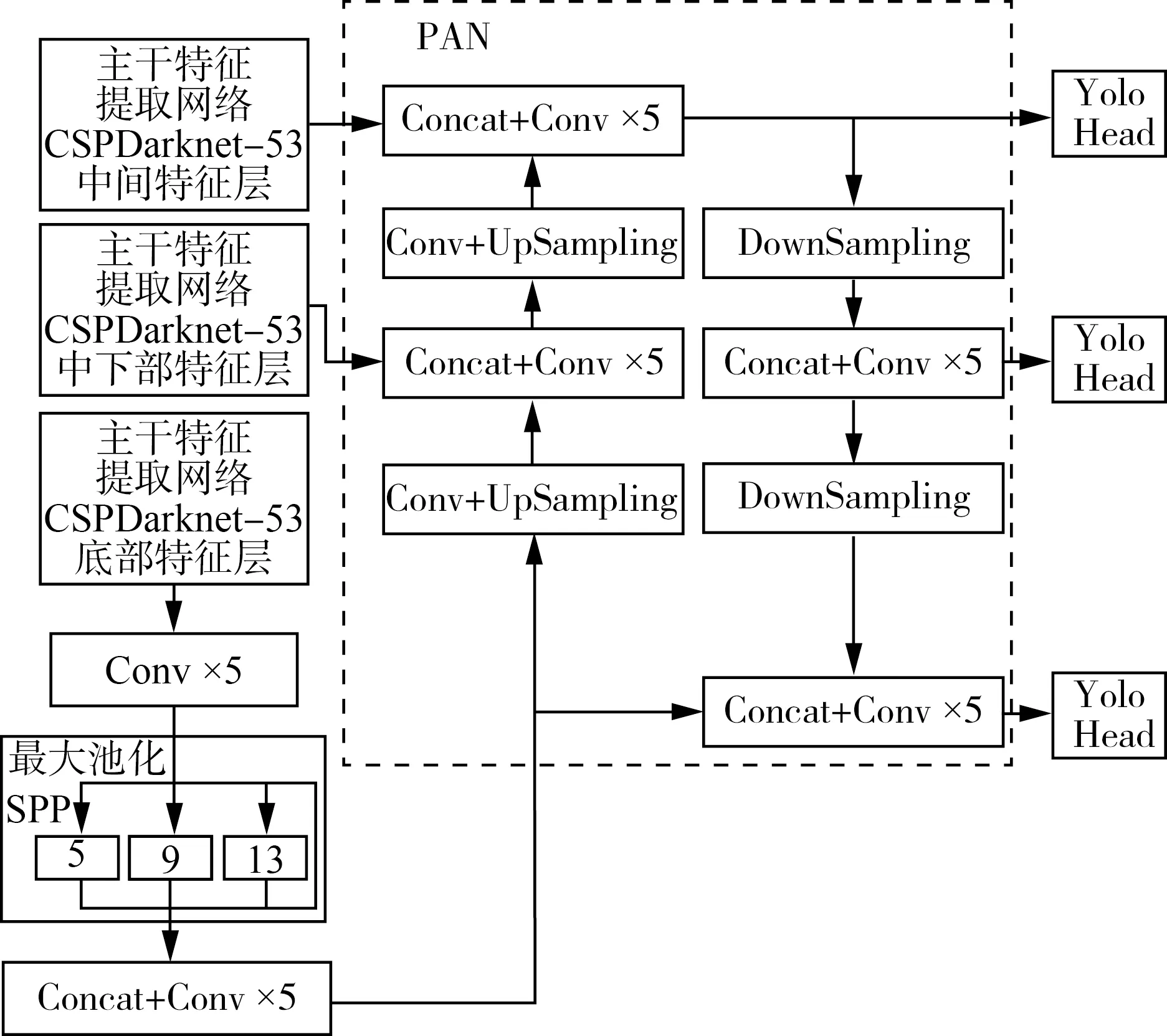
图3 特征金字塔SPP与PAN网络结构
1.3.3 YOLO V4-Tiny目标检测模型
YOLO V4-Tiny[18-19]在YOLO V4的基础上减少了一些结构,达到了增加速度的目的。与CSPDarknet相比,YOLO V4-Tiny的主干特征提取网络将激活函数重新修改为YOLO V3中使用的LeakyReLU。通过CSP Darknet-tiny获得最后两个尺寸的有效特征层,输入到加强特征提取网络当中进行FPN的构建。
1.3.4 Mobilenet-YOLO V4-Lite目标检测模型
Mobilenet[20-21]系列网络使用深度可分离卷积结构构建轻量级深度神经网络模型,Mobilenet-YOLO V4-Lite利用MobilenetV1、MobilenetV2和MobilenetV3三个网络替换CSPDarknet主干特征提取网络,如图4所示为Mobilenet模型的核心思想深度可分离卷积(Depthwise Separable Convolution)的结构。
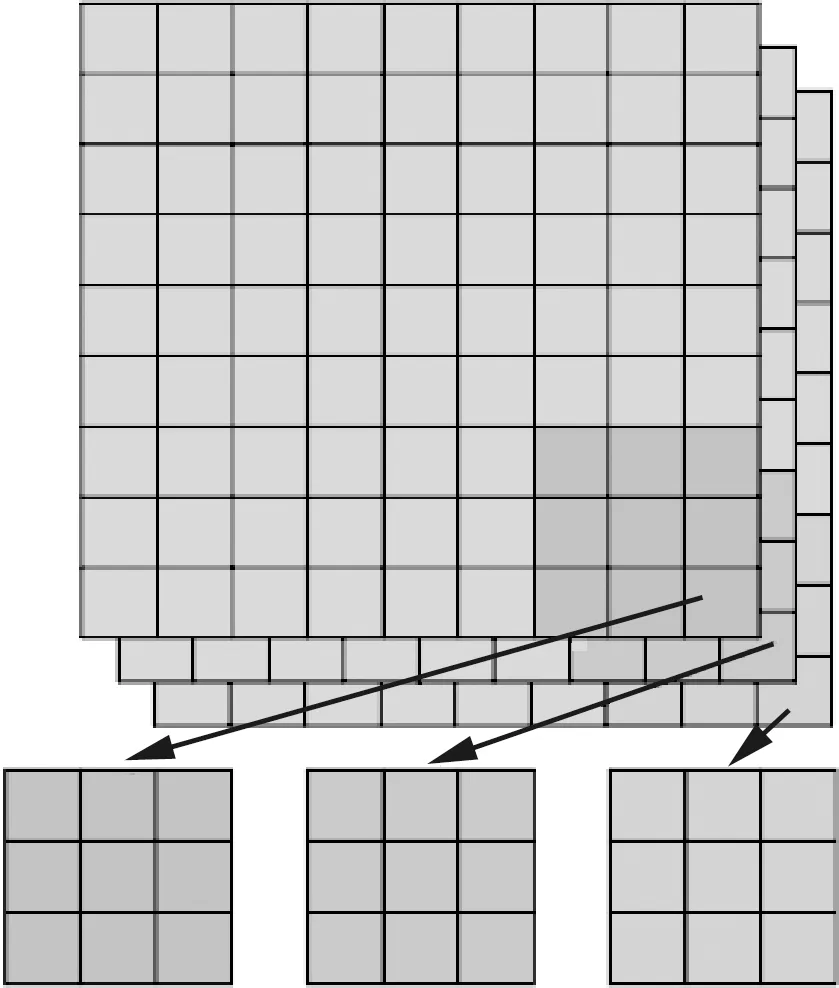
(a) 空间卷积层 (b) 通道卷积层
1.4 评估指标
为了评估出所得到的枣成熟度检测模型的准确性和稳定性,选取精确度P、召回率R、平均检测精度mAP以及调和平均数F1作为评价指标。置信度阈值对模型的评估结果有重要影响,这是因为在使用模型进行实际检测时,需要设置置信度阈值来对检测目标进行取舍。因此,在模型检测时,置信度阈值选取比较关键。在训练结束后设置不同置信度阈值得到多组评估指标进行对比。
(1)
(2)
(3)
式中:TP——正确识别目标的数量;
FP——错误识别目标的数量;
FN——未识别目标的数量。
2 结果与分析
本文使用相同的数据集,将不同成熟度的枣果实按不同标注方式(方式Ⅰ和方式Ⅱ)在四种不同的卷积神经网络模型(YOLO V3、YOLO V4、YOLO V4-Tiny和Mobilenet-YOLO V4-Lite)中进行训练,通过对比不同标注方式和不同的卷积神经网络模型,找到最合适的模型应用到枣果实成熟度检测的研究中。
每种模型的训练周期为100轮(epoch),每1轮训练验证1次。前50轮训练学习率(Learning rate)为0.001,后50轮训练学习率(Learning rate)为0.000 1。由于不同网络结构的差异,为了得到最优模型,本文将4种网络模型分别设置了不同的批处理集尺寸(Batchsize),经过反复试验,最终将YOLO V3的前50轮Batchsize设定为8个样本,后50轮Batchsize设定为2个样本;YOLO V4的前50轮Batchsize设定为8个样本,后50轮设定为4个样本;YOLO V4-Tiny前50轮Batchsize设定为32个样本,后50轮Batchsize设定为16个样本;Mobilenet-YOLO V4-Lite模型前50轮Batchsize设定为16个样本,后50轮Batchsize设定为8个样本。为防止过拟合,设置训练时当5个epoch过后,若模型性能没有提升,则降低学习率,若没有产生损失值下降即结束训练。
2.1 枣成熟度识别方式I的YOLO目标检测模型
方式Ⅰ按照现有枣果实成熟度识别方式将枣果实直接分为未熟果实和成熟果实。图5为不同模型训练集损失(train-loss)与测试集损失(val-loss)对比,可知YOLO V4-Tiny的训练周期最长(epoch=90),YOLO V4训练周期最短(epoch=66)。对比训练集与测试集损失值,YOLO V4的最终损失值最低,训练集最终稳定在1左右,测试集稳定在2左右;YOLO V4-Tiny与Mobilenet-YOLO V4-Lite的最终损失值相似,训练集均稳定在1.2左右,测试集均稳定在2左右;YoloV3的最终损失值最高,训练集最终稳定在3左右,测试集稳定在4左右。

(a) 训练集损失曲线
将未进行训练与测试的剩余505幅枣果实图像作为验证集输入到已经训练好的4种不同模型中,其中枣果实成熟个数为470个,未熟个数为142个。表1显示了不同模型在方式Ⅰ的性能评价参数。
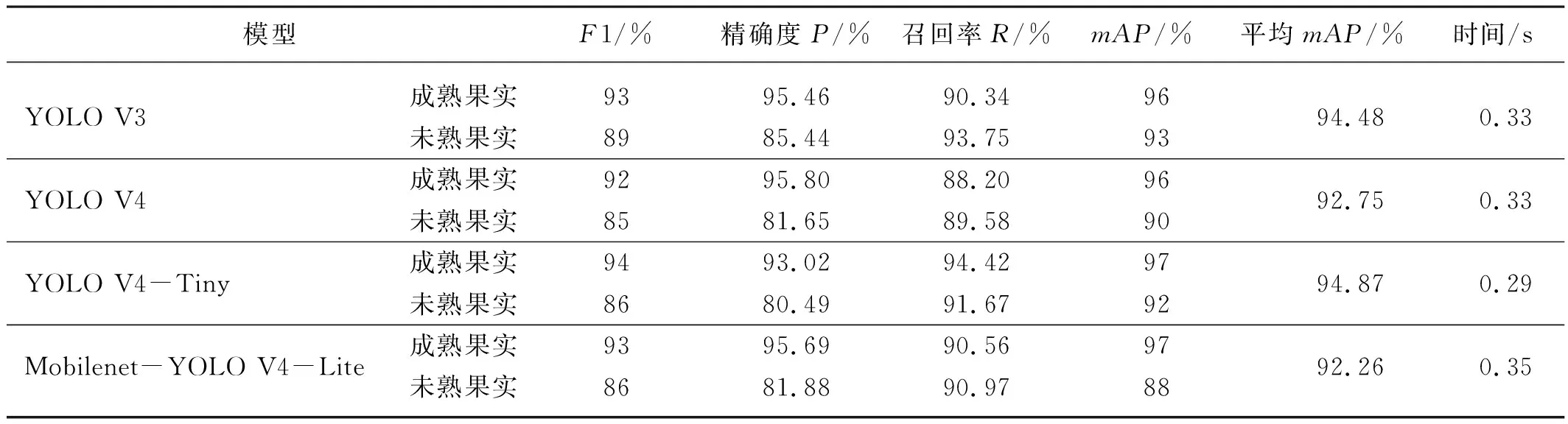
表1 方式Ⅰ四种模型性能评价Tab. 1 Performance evaluation of the four models Ⅰ
可知方式Ⅰ中对比同一标注标签各评价参数4种模型效果相差不大,平均mAP均大于92%,其中YOLO V4-Tiny模型表现最好。对方式Ⅰ中两种标注标签进行对比发现,4种模型识别成熟果实的F1、精确度P和mAP均高于未熟果实,说明将未熟果实识别为成熟果实的概率大于将成熟果实识别为未熟果实,但召回率R除YOLO V4-Tiny模型外成熟果实均高于未熟果实,说明除YOLO V4-Tiny外的其他三种模型未标出成熟果实的概率高于未熟果实。
2.2 枣成熟度识别方式Ⅱ的YOLO目标检测模型
由于在现实采摘过程中,对适合鲜食与适合制干品种有不同的采摘要求,所以在标注时将方式Ⅰ中成熟果实分为半红果实与完熟果实,以满足不同的采摘需求,即方式Ⅱ分为未熟果实、半红果实和完熟果实3种类型。如图6所示,YOLOV4-tiny模型的训练周期最长(epoch=92),YOLOV4与YOLOV4-tiny模型最终的训练损失值与测试损失值类似(train-loss为1左右,val-loss为2左右)。

(a) 训练集损失值对比曲线图
将未输入到训练集与测试集的验证集505幅枣果实图像输入到最终训练得到的4种卷积神经网络模型中,其中未熟果实个数为142个,半红果实为167个,完熟果实为303个。表2为方式Ⅱ验证集各模型性能评价,可知方式Ⅱ中平均mAP均大于89%,其中YOLO V3模型表现最好,其次为YOLO V4-Tiny模型。对方式Ⅱ中三种标注标签进行对比发现,4种模型除Mobilenet-YOLO V4-Lite模型外完熟果实与未熟果实的F1、精确度P、召回率R和mAP均高于半红果实,说明各模型识别半红果实的效果低于其他两种标注标签,且完熟果实在各模型中识别效果要高于未熟果实。

表2 方式Ⅱ四种模型性能评价对比Tab. 2 Comparison of performance evaluation of the four models Ⅱ
2.3 枣成熟度识别方式综合对比
为进一步找到适合枣果实的成熟度识别模型,将两种标注方式的4种识别模型平均mAP作对比,如图7所示。从平均mAP可以看出不同模型中方式Ⅰ均比方式Ⅱ效果好,但相差不大,两者mAP的差值在0.29%~3.52%范围内。基于YOLO算法的4种识别模型中,两种标注方式在YOLO V3与YOLO V4-Tiny两个模型中表现较好,平均mAP约为94%,除方式Ⅱ的YOLO V4模型平均mAP为89.23%外,其余3个模型约为92%。

图7 两种标注方式模型效果对比图
3 讨论
3.1 不同识别方式对枣果实成熟度识别的影响
本文将不同品种间的枣果实按两种标注方式进行成熟度识别,方式Ⅰ的标注方式是常用的标注方式,将果实按红果和绿果分为成熟果实和未熟果实。由于适合鲜食品种的枣在现实采摘过程中需要采摘半红果实[12],为了满足多品种枣的采摘要求,本文增加了方式Ⅱ的标注方式,将成熟果实分为完熟果实和半红果实,即方式Ⅱ将枣的成熟度分为完熟果实、半红果实和未熟果实。
比较同一训练模型的不同标注方式,验证方式Ⅱ的可行性。从训练模型可以看出,同一模型的两种标注方式差距很小,说明两种标注方式并不会影响训练模型;通过精确度P和召回率R两个评价参数可以看出,方式Ⅰ的成熟果实的识别准确率高于未熟果实,但是未识别到的成熟果实比例也高于未熟果实,这一现象可能与成熟果实中带有红色部分与全部为绿色的未熟果实易区分,未熟果实表皮多为光滑,在阳光照射下易反射,易被识别为成熟果实;方式Ⅱ中完熟果实的识别效果高于半红和未熟果实,这与完熟果实整个枣面积为红色,与半红果实、未熟果实差别明显,不易被识别错误和不被标记。其次未熟果实识别效果比半红果实效果更佳,且未标记的半红果实比例较大,这与未熟果实整个面积为绿色,极易与完熟果实区分,而半红果实介于两者之间,若表皮红色部分较少则被识别为未熟果实的可能性较大,若表皮颜色红色较多,则易被识别为完熟果实。由于方式Ⅰ中成熟果实和方式Ⅱ中完熟果实占验证数据集的比值较大,所以在评价指标和综合评价中的效果比其他类型高。
3.2 不同模型对枣果实成熟度识别
为了建立最适合枣果实成熟度识别的最优模型,本文将两种标注方式的枣果实用4种神经网络模型进行了研究。比较同种标注方式的4种模型平均mAP,YOLO V3与YOLO V4-Tiny模型高于其他两种模型,在94%左右。通过比较4种模型的特点可知YOLO V3模型采用Darknet53为主干特征提取网络,其有两个重要特点:(1)残差网络Residual通过不断的1×1卷积和3×3卷积以及残差边的叠加大幅度加深网络,从而提高准确率;(2)每一个卷积部分使用了特有的DarknetConv2D结构,每一次卷积进行正则化,完成卷积后进行BatchNormalization标准化与LeakyReLU。而YOLO V4-Tiny是YOLO V4的简化版,通过减少YOLO V4的一些结构达到增加速度的目的,并且仅使用了两个特征层。YOLO V3与YOLO V4-Tiny在这4种模型中属于简单的网络结构,说明在枣果实的成熟度识别问题上较为简单的网络效果更好。
4 结论
1) 本文通过采集适合鲜食和适合制干的18个品种枣果实的图像,利用卷积神经网络中极具有代表性的目标检测YOLO算法的4种模型建立两种不同标注方式的枣果实成熟度识别模型,结果表明,YOLO V3与YOLO V4-Tiny两种模型均适用于两种类型的标注方式,且两种类型的标注方式效果均在94%左右,说明将不同品种枣果实按市场需求分为完熟果实、半红果实和未熟果实进行基于YOLO算法的成熟度识别具有一定的可行性。
2) 此次研究由于采集的枣果实在同一地区,且在同一时期具有一定的局限性,因此在今后的研究中为更满足市场需求,首先增加具有代表性多地域的枣果实图像,如新疆、山西和河北等其他地区;其次增加不同枣成熟时期的果实图像;最终通过不断改进算法提高其精准度,更好地满足现实需求。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
航天工业管理(2020年9期)2020-12-28
航天工业管理(2020年1期)2020-04-20
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2019年11期)2019-07-04
雷达学报(2018年5期)2018-12-05
装甲兵工程学院学报(2018年4期)2018-10-19
