
基于高光谱成像技术小麦籽粒霉变鉴别方法研究
2022-10-26 04:41孙钰莹李光磊邢常瑞
中国粮油学报 2022年9期
孙钰莹, 章 银, 沈 飞, 李光磊, 邢常瑞, 袁 建
(南京财经大学食品科学与工程学院;江苏省现代粮食流通与安全协同创新中心; 江苏高校粮油质量安全控制及深加工重点实验室,南京 210023)
小麦是我国重要的粮食作物之一,产量仅次于水稻,位居第二位,是中国主要粮食作物之一[1],具有种皮薄、组织结构疏松和储藏性好的特点[2],是一种重要的储备粮。但由于小麦在收储运过程中抗霉性差,容易受到外界环境的影响,发生理化性质的改变,出现发热霉变等现象[3,4],影响农业生产和粮食安全。传统的小麦霉变检测方法有平板计数法、酶联免疫法、荧光染色法和液相色谱-高分辨质谱法等。这些检测方法虽然准确性高、特异性强,但前处理时间长,操作复杂。因此,需要寻找一种快速无损的小麦霉变检测方法。
高光谱成像技术结合了成像和光谱分析的技术特点,获取的信息囊括了光谱以及其二维空间的分布信息,相比传统的单一波段光电探测技术,它能够提供更加丰富的目标信息[5]。目前国内外已有文献报道关于利用高光谱成像技术鉴别品种的可行性,如Willams等[6]利用图谱结合的方法,先对高光谱图像进行主成分分析,在主成分的得分散点图中根据感染霉菌的玉米籽粒像素和健康玉米籽粒像素形成的不同聚类,识别出受镰刀菌污染的玉米籽粒;龚中良等[7]利用高光谱成像技术快速无损鉴别不同霉变程度的籼稻;张楠楠等[8]利用高光谱图像技术对霉变玉米籽粒进行检测,其正确检出率为93.75%。这些研究表明高光谱成像技术可以用于粮食霉变籽粒的鉴别。
因此,本实验拟通过可见光-高光谱成像系统获得不同品种小麦样品的高光谱图像。通过不同的光谱预处理方法建立不同的预测模型,选出最优光谱信息预处理方法。同时,采用连续投影算法(SPA)和竞争性自适应重加权采样(competitive adaptive reweighted sampling,CARS)提取特征波长,基于支持向量机(SVM)算法建立小麦霉变籽粒鉴别模型,为实际应用提供参考。
1 材料与方法
1.1 实验材料
选取白麦(淮麦22)和红麦(宁麦13)为研究对象。两类小麦样品均为2020年市场采购的新收获小麦。
1.2 仪器与设备
高光谱成像的采集设备采用推扫式高光谱影像系统,采集软件为HSI Analyzer。该系统主要由4个部分组成:光源、光谱相机、电动移动平台和计算机[9]。
1.3 数据采集与校正
选择每个样品的整个区域作为感兴趣区域(Region of interest,ROI)进行数据分析,通过计算ROI内所有像素的平均反射率来获得每个样本的平均光谱数据。为了减小相机、传感器暗电流和光强变化对图像信号的影响,在进行数据分析之前,需要对数据进行黑白校正[10]。将采集的原始图像信息(Isample)、黑色背景信息(Idark)、白色背景信息(Iwhite)根据式(1)进行黑白校正,R为黑白校正后所得图像。
(1)
其中黑背景数据采集时用镜头盖将相机镜头盖上。白板背景采集是将反射率约99%的标准白色校正板放置在与样本平齐的位置进行采集,保证采集状态与样品保持一致。
1.4 数据处理
1.4.1 光谱预处理方法
对待测样品的光谱信息进行预处理能够减少基线漂移现象的影响,同时也可以提升预测模型的准确性和稳定性[11]。本实验所用到的预处理方法有多元散射校正法(multiplicative scatter correction,MSC)[12]、变量标准化法(standard normalize variate,SNV)[13]、正交信号校正(orthogonal signal correction,OSC)[14]和一阶导数法(First derivative)[15]。
1.4.2 特征波长的选取
本实验中共有558个波段,其中很多光谱波段带有大量冗余的信息,从而导致算法性能下降[16]。因此,高光谱原始数据特征波长的提取是建立快速、精确检测模型必不可少的步骤。故采用连续投影算法(successive project algorithm,SPA)[17]和竞争性自适应重加权算法(competitive adaptive reweighted sampling,CARS)[18],筛选特征变量,确定最优的变量选择方法。
2 结果与讨论
2.1 光谱特性分析
采集到的原始高光谱信息的光谱范围为383~1 011 nm。由于前后波段的光谱信噪比较低,需要消除383~400、1 000~1 011 nm的首尾噪声,最终在400~1 000 nm范围内获得了558个波长信息的平均光谱用于进一步分析,得到如图1所示的不同小麦品种健康籽粒与霉变籽粒的平均光谱反射率。
从图1可以看出,不同品种小麦样品的平均光谱曲线的趋势是相似的,两者均随波长的增加呈抛物线趋势,在400~1 000 nm的光谱区间,霉变组样品的平均光谱反射率低于健康组样品的,说明霉变导致籽粒褐变,使籽粒相对吸光度增大[19]。对于不同品种的小麦样品来说,随着波长的增加,光谱反射率呈现先上升后下降的趋势,在400~1 000 nm波段之间的光谱反射率差异明显,可以用来区分不同品种小麦样品的健康籽粒和霉变籽粒。
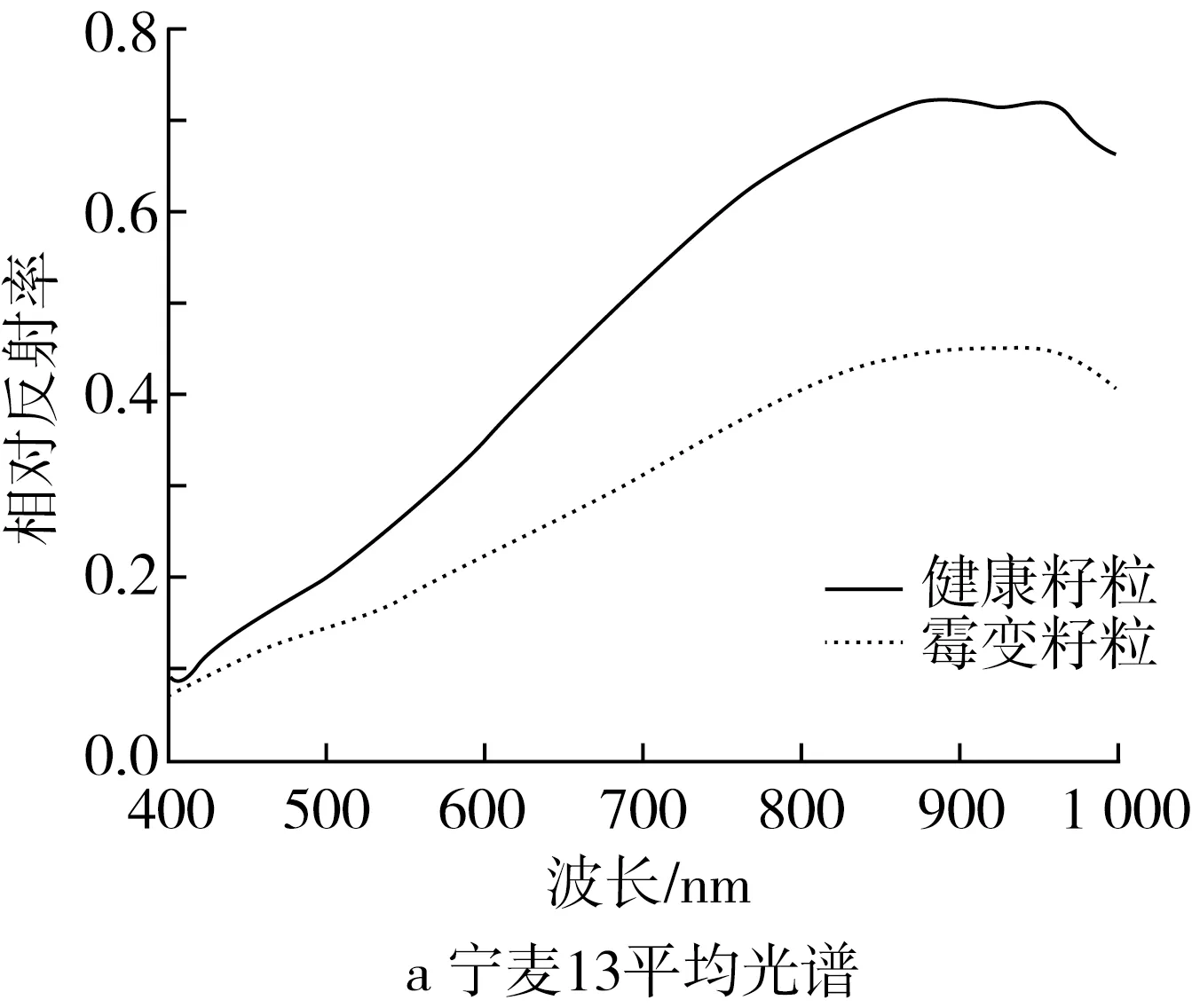

图1 平均反射光谱曲线
2.2 样本集的划分
将样品进行分组,按照3∶1的原则将200个小麦样品随机分为建模集和预测集,建模集150个样品,预测集50个样品。
2.3 预处理方法的选择
由于提取的原始光谱中包含了较多噪声,本实验分别釆用MSC、SNV、OSC和一阶导数(FD)预处理方法。基于原始平均光谱及不同预处理方法后的平均光谱建立的小麦霉变籽粒全波段鉴别模型的预测结果如表1所示。
模型的预测准确性受到光谱预处理的直接影响,不同的预处理方法对模型的预测效果有不同程度的影响,所以在建立模型中没有统一的最优预处理方法。MSC和OSC 2种预处理方法都能有效提高预测模型的准确性,而原始光谱经过SNV和FD预处理方法处理后RMSECV有所升高。这是由于在对原始光谱进行预处理时,可能会引入其他噪声或者放大原有的噪声,从而降低光谱的信噪比,导致模型的预测准确度降低。
在白麦(淮麦22)样品中基于SNV-PLS-DA处理的模型RMSECV最小,即SNV-PLS-DA为白麦(淮麦22)样品霉变籽粒全波段鉴别预测模型的相对最优预处理方法,但是本实验中经SNV-SVM处理的模型RMSECV并不是SVM组里最小的,说明建模方法的选择会影响最优预处理方法的选择。但是在红麦(宁麦13)样品中基于OSC-PLS-DA和OSC-SVM处理的模型RMSECV都是组里最小值,分别为0.219 5和0.014 4,说明OSC预处理方法为红麦(宁麦13)样品霉变籽粒全波段鉴别预测模型的相对最优预处理方法。
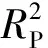
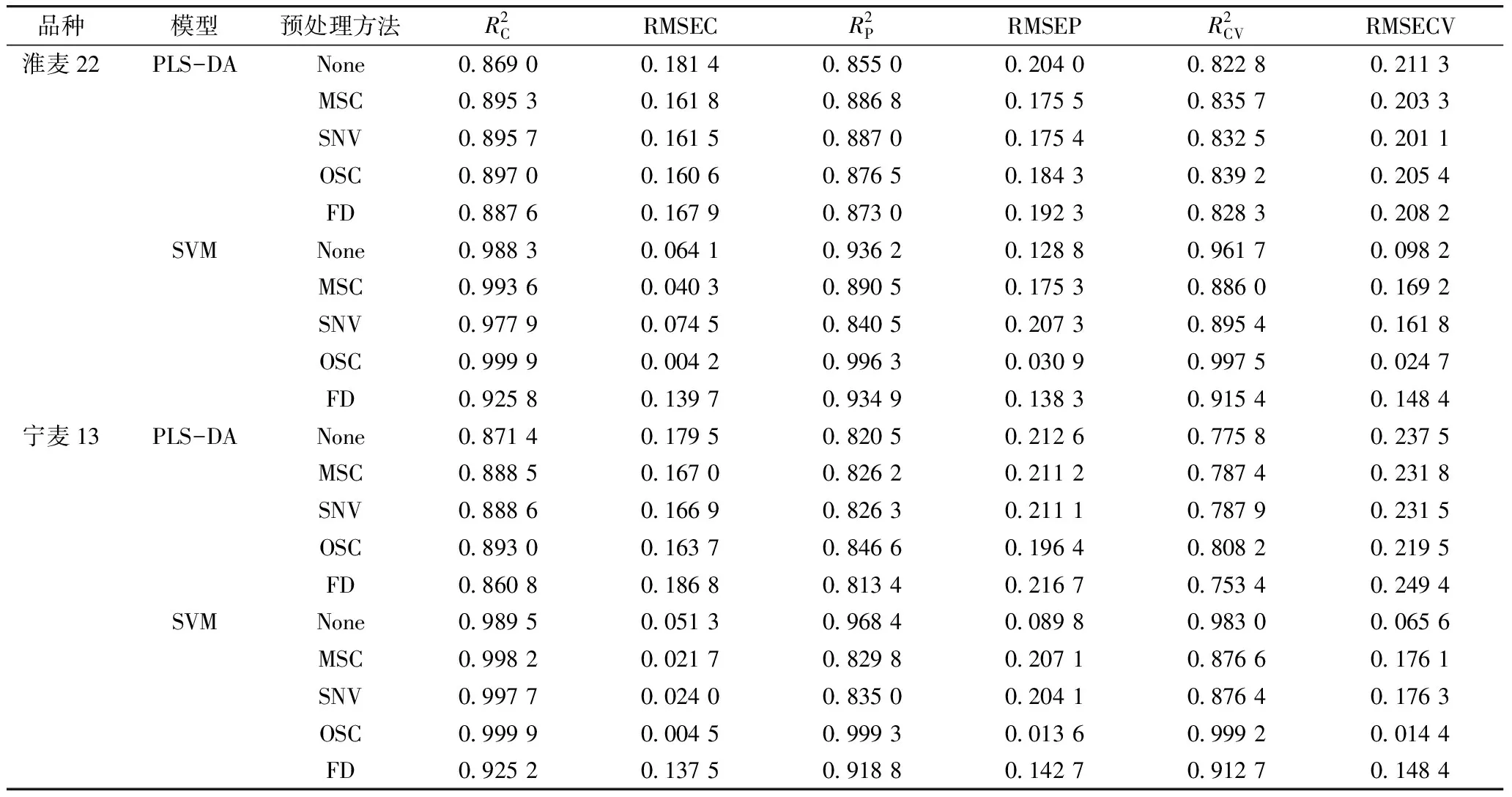
表1 不同光谱预处理方法小麦霉变籽粒鉴别模型预测结果
2.4 特征波长的提取
利用全波段光谱建立的小麦霉变籽粒鉴别模型虽然有较高的模型准确性,但存在建模变量数过多、信息冗余和数据共线性等缺点[21],导致建模效率降低。因此对全波段光谱进行特征波长的提取,筛选出光谱中的有效波段信息,从而提高模型的运算速度和准确性。为研究小麦霉变籽粒鉴别模型对应的特征光谱波长,对全部样品进行特征波长的提取。经过预实验的比较,选用SPA和CARS算法进行特征波长的提取。SPA是一种采用前向选取方法的算法[22],能够从光谱变量中找出信息量最少的波长,以解决变量之间的共线问题。CARS方法是一种用于变量筛选的方法,筛选出最优变量,提高模型预测能力[23]。不同特征波长的提取方法如图2和图3所示,表2列出了在400~1 000 nm波段基于两种算法提取的特征波长。
从图2a和图2b可以看出,在SPA特征波长提取方法中,随着特征波长数目的增加,均方根误差(RMSE)减小,当模型中包含的变量个数为7和8时,RMSE开始缓慢变化,当变量个数增加至9时RMSE取得最小值0.142 8和0.131 9。依据RMSE越小,模型效果越好的原则选择如图2c和图2d所示的9个特征波长。由表2可知,利用SPA方法提取的不同小麦样品的特征波长,除了两者在999.06 nm处有波长重合外,其余波长均可作为不同小麦样品的特征波长。

表2 不同方法挑选的特征波长


图2 SPA特征波长提取方法
CARS算法的运行结果如图3所示。随着抽样次数的增加,抽样变异数逐渐减少,变异数与抽样次数之间呈现指数关系递减,与陈华舟等[24]的研究结果相似。同时,随着抽样次数的增加,RMSECV也逐渐减少,表明光谱数据中部分无用的信息被剔除,当抽样次数为31时达到最小值,之后趋于平缓。每个选定点的回归系数趋势从20次迭代之后开始发散。最后,确定了4个关键波长,如表2所示。基于此特征波长建模可以简化建模所需数据,提高模型运算效率。
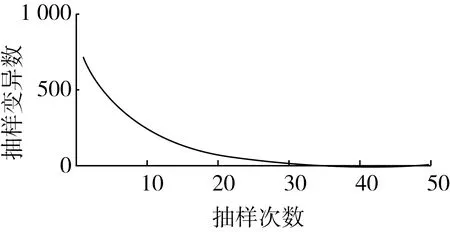

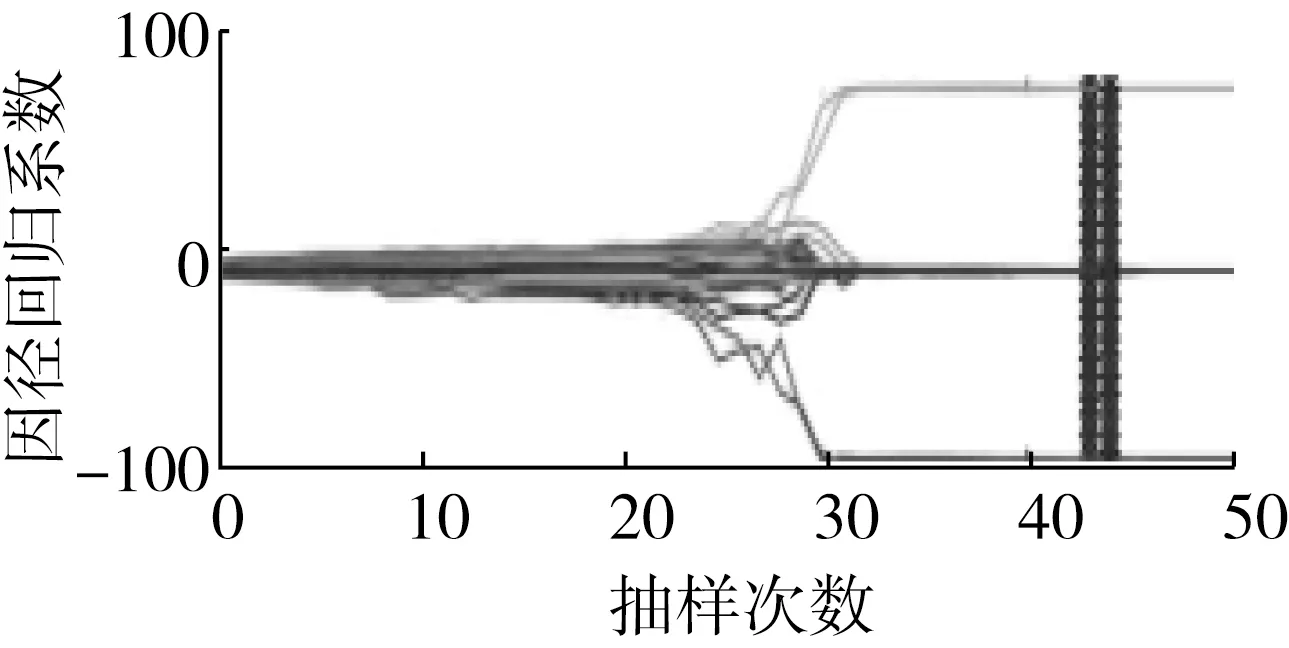
图3 CARS特征波长提取方法
为了比较所选特征波长的有用性,将得到的特征波长分别作为变量建立小麦霉变籽粒的OSC-SVM鉴别模型。在建模过程中,按照3∶1的原则将200个小麦样品随机分为建模集和预测集,建模集150个样品,预测集50个样品。模型鉴别效果如表3所示。
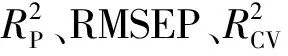
对2种不同品种的小麦样品建立霉变籽粒鉴别模型,将所有样品籽粒带入模型中,利用混淆矩阵分析分类结果,结果如表4所示,对于不同品种的小麦样品,霉变籽粒鉴别模型的准确率均达到99%,Kappa系数为0.960 0,表明所建立的小麦霉变籽粒鉴别模型的预测结果与实际分类结果相一致,说明基于高光谱成像技术进行小麦霉变籽粒鉴别是可行和有效的。
另外,为验证所建模型的稳定性,在白麦与红麦2个品种中分别重新挑选35粒健康籽粒与15粒霉变籽粒放于培养皿中,采集其高光谱图像作为独立验证集。将独立验证集带入所建模型中,在白麦中有1个健康籽粒误判;红麦中有1个健康籽粒误判,总体来说模型对每个品种籽粒中的霉变籽粒的均有较好的判别效果。

表3 基于特征波长的霉变籽粒鉴别效果

表4 霉变籽粒鉴别结果的混淆矩阵
3 结论
猜你喜欢
材料与冶金学报(2022年2期)2022-08-10
杭州电子科技大学学报(自然科学版)(2022年3期)2022-06-08
中国农学通报(2022年13期)2022-05-31
温州大学学报(自然科学版)(2022年2期)2022-05-30
现代畜牧科技(2021年4期)2021-12-05
阅读(科学探秘)(2021年8期)2021-09-01
粉末冶金技术(2021年3期)2021-07-28
辽宁农业科学(2021年1期)2021-03-17
建材发展导向(2021年23期)2021-03-08
科学种养(2017年6期)2017-06-13
