
基于GNFA-SVR污水出水总氮软测量研究
2022-10-25 07:18郭利进李博仑
工业水处理 2022年10期
郭利进,李博仑
(天津工业大学控制科学与工程学院,天津 300387)
氮是微生物繁殖的必要元素,但也是引发水体富营养化的元素之一〔1〕。出水总氮(TN)是污水排放的重要指标之一,当出水TN检测结果不达标时,污水厂会采取应急措施,通过调整某个工艺段的工艺参数来解决问题。因此,根据实时进水水质情况判断未来出水TN是否存在超标可能并提前对工艺参数进行调整,对污水处理系统的优化具有重要意义。
在污水水质预测创建模型方面,众多学者从污水处理过程机理和数据驱动方式去构建模型。O.S.DJANDJA等〔2〕提出一种根据生化反应温度与原料中元素含量关系的前馈神经网络氮含量预测模型。乔俊飞等〔3〕采用一种基于递归径向基(RBF)神经网络算法的氨氮软测量方法。尽管神经网络算法在预测领域有着不错的性能表现,但也存在一定局限性,如收敛速度慢、易陷入局部极值、过度拟合等〔4〕。
与神经网络算法相比,支持向量回归机(SVR)具有训练时间短、泛化能力强、预测精度高的优点,并且克服了神经网络算法在小样本、非线性问题中的重复性差、过度拟合等不足,更适用于预测研究〔5-8〕。然而,SVR模型构建的关键是解决核参数σ和惩罚因子c的最优取值问题,初期算法的参数选取多依赖于主观经验,缺乏严谨的数学依据。本研究通过引入基于高斯函数递减步长的萤火虫算法(GNFA)对SVR参数进行优化,可有效提高模型的预测准确度。
1 基本原理
1.1 支持向量回归机
支持向量回归机(SVR)是一种监督性机器学习算法,是在支持向量机(SVM)理论基础上延伸出的一种对回归分析问题的应用模型。SVR通过引入不敏感损失系数ε让所有的样本点与超平面距离和最小,得到一个最佳条状区域(2ε宽度),以达到期望风险最小的目的〔9〕。
给定n个训 练 样 本D={(xi,yi)|i=1,2,…,n},且xi∈Rn,yi∈Rn,xi为预测模型的相关输入向量,yi为对应的输出向量,构造回归决策函数,见式(1)。其中,ω是权向量;φ(x)是原始样本数据的非线性映射函数,可将数据映射至特征空间;b为偏置值。

引入不敏感损失系数ε与惩罚因子c,yi为实际值,f(xi)为模型的输出预测值,当yi与f(xi)差的绝对值大于ε时计算损失;反之则认为预测正确,不计算损失〔10〕。不敏感损失系数ε对模型影响较小,选取0.15即可。根据最小结构风险原则,建立约束条件〔式(2)〕与目标函数〔式(3)〕。
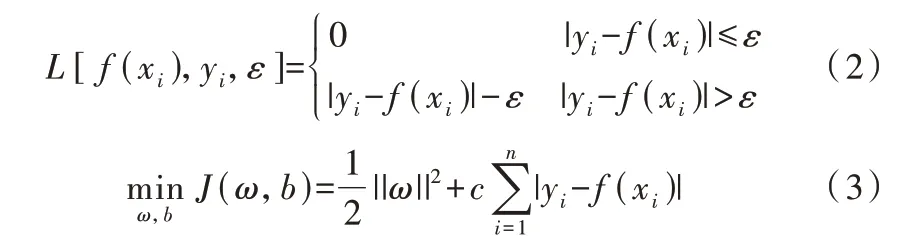
图1为SVR的示意图,黑色实心的数据点表示模型预测结果是有效的。

图1 支持向量回归示意Fig.1 Support vector regression diagram
惩罚因子c的取值影响模型的结构风险,取值过大,结构风险越大,模型容易出现过拟合;取值过小,模型会过于简单化,易出现欠拟合问题〔11〕。
引入松弛变量ξi与ξ*i,建立新的目标函数〔式(4)〕。

引入拉格朗日乘子α、α*,将式(4)变换为对偶形式〔式(5)〕。式中,K(xi,xj)=φ(xi)φ(xj)为核函数。

根据式(5)的函数关系式可求出α与α*,最终可得到回归函数,表达式见式(6)。
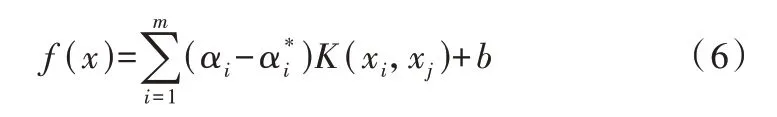
映射时发现,当变量增多时,映射到高维空间的维度呈指数增长,导致计算难度骤增;而引入核函数可使低维计算结果等效于高维。核函数根据需要选取,研究中选用径向核函数,表达式见式(7)。σ为径向核函数的核参数,其取值大小也会影响模型效果,取值过小会导致模型的泛化能力减弱,取值过大会令模型出现过拟合现象。

综上,SVR模型构建的关键是解决核参数σ和惩罚因子c的最优取值问题。
1.2 改进萤火虫算法
萤火虫算法(FA)是一种启发式算法,是根据自然界中萤火虫的发光行为提出的〔12〕。在FA中,空间里的每一个解就好比萤火虫种群里的每一只萤火虫,空间里的初始解可以理解为萤火虫种群的初始位置,萤火虫通过个体之间的吸引进行移动,完成位置的更新,即完成解的更新〔13〕。
搜索过程涉及到萤火虫的发光亮度和相互吸引度〔14〕,这2个参数都与萤火虫之间的距离成反比,这与自然现象中光在空间传播时被传播介质吸收而逐渐衰减的特性一致。
FA算法中萤火虫发光强度的计算公式见式(8)。

式中,Ir表示发光强度;rij表示萤火虫i与萤火虫j之间的距离,rij=||Xi-Xj||;吸收系数γ的改变可以理解为传播介质的改变,可设置为常数;当萤火虫个体与光源的距离逐渐趋近于0时,萤火虫的发光亮度最为明亮,即为I0〔15〕。
萤火虫的吸引度β见式(9),与萤火虫发光强度同理,当萤火虫个体与光源的距离逐渐趋近于0时,吸引度最大,即为β0〔16〕。

萤火虫i被吸引向萤火虫j移动的位置更新由式(10)决定。

式中,X′i为下一次迭代的位置;α(rand-0.5)为扰动项;α为步长因子,是介于0~1之间的常数;rand是[0,1]上服从均匀分布的随机因子。扰动项的加入是为了扩大寻优区域〔17〕。
在文献〔18〕中,优化粒子群算法引入了线性递减权重。受该思路启发,不妨将萤火虫的步长进行线性递减优化,定义该种改进算法为线性递减步长萤火虫算法(LFA),具体步长变化表达式见式(11)。
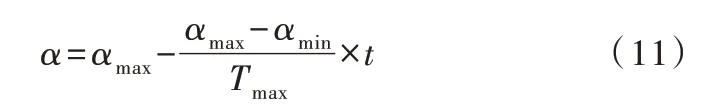
因为FA算法在实际问题的寻优过程中是复杂非线性的,所以步长也呈动态非线性变化预计会出现较好的寻优结果。结合高斯函数分布的特性,猜想当步长的随机变化呈正态分布时,能够提高算法的寻优精度。因此,根据高斯函数分布特性,把相应的步长参数带入步长变化表达式,实现对步长α的非线性映射,得到最终的高斯递减函数调整步长策略,见式(12)。
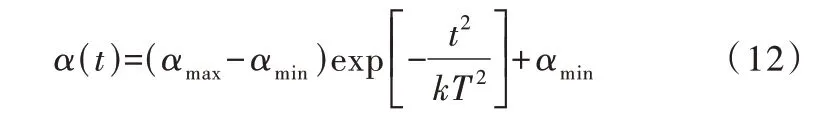
式中,常数k可以影响曲线的凹凸程度,即曲线的变化率可通过k进行调整。
以步长取值范围为0~1、最大迭代次数为100时为例,图2给出了不同k值对应步长的变化曲线。

图2 k取不同值时步长的变化Fig.2 Change of step with different k
由图2可看出,当k≤0.1时,步长过早收敛于0,导致寻优效果过于局限;当k≥0.3时,步长在整个迭代过程中的变化趋势较为平缓,不利于算法收敛。所以本研究中k取0.2,高斯函数递减步长的萤火虫算法(GNFA)位置更新表达式见式(13)。

2 GNFA算法性能测试
为验证改进算法的性能,分别将FA、LFA与提出的GNFA进行比较。选择Sphere函数和Ackley函数作为测试算法性能的函数,Sphere函数多用来检验算法的收敛速度和精度,Ackley函数可以测试算法的局部寻优能力。这2个函数是最常见的测试函数,被广泛应用在算法测试性能实验中〔19〕。
在仿真环境中,萤火虫步长改进优化算法的具体参数设置为:萤火虫数目M=20,光强吸收系数γ=1.0,初始吸引度β0=0.8,步长因子αmax、αmin分别设置为0.8、0.1,最大迭代次数T=500,α的变化停止阈值Th设置为10-3。而FA算法步长设置为0.4,其他参数和改进算法设置一致。测试函数的搜索范围、期望目标值、搜索空间维数及函数类型等见表1。
(2)仔猪出生后7~l5日龄开始饲喂优质全价饲料,换料应逐步更换,并适量补充矿物质,多喂富含维生素的青绿饲料,供给充足、清洁、新鲜饮水。

表1 测试函数特征Table 1 Test function characteristics
测试函数的优化结果见表2,平均最优值随迭代次数增加的变化曲线见图3。
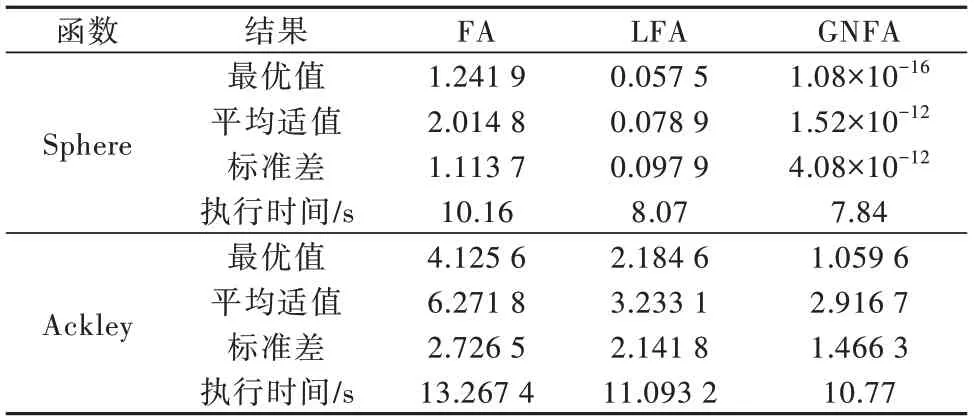
表2 测试函数的优化结果Table 2 The optimization results of the test functions
从表2的优化结果可看出,相比LFA与标准FA算法,GNFA算法综合表现更佳,说明当采用高斯非线性递减方式改进步长策略时,萤火虫个体寻优性能强,且算法执行时间也得到优化。
从图3可看出,3种算法对单峰值Sphere函数的优化结果在寻优精度上相差不大,但GNFA收敛速度快于其他2种算法。3种算法对多峰值Ackley函数的优化结果说明,在迭代后期,标准FA算法定值步长容易导致算法陷入局部最优;而LFA算法的性能表现介于其他2种算法。虽然线性递减改进步长策略并非最好的优化方式,但也说明了步长α是影响算法性能的一个关键参数。总之,与传统FA算法相比,GNFA算法在局部寻优能力、全局搜索精度及收敛速度方面都得到改善。

图3 Sphere函数(a)和Ackley函数(b)收敛曲线Fig.3 Convergence curves of Sphere function(a)and Ackley function(b)
3 基于GNFA-SVR的TN软测量建模
3.1 模型数据选取与处理
如果进水水质组分全部被选作特征向量,其中部分特征变量存在弱相关性的问题往往会被忽视,导致维度过高,模型的计算时间和计算难度增加,不利于模型预测结果分析。主成分分析(PCA)是一种对高维度特征数据降维的统计分析法,有利于确定特征变量维数。图4为使用PCA对数据特征变量进行降维分析的相关度,当选取6个特征变量时,总体的累计方差贡献率已经达到了90%。故本研究选取6个特征变量:进水COD、TN、NH4+-N、温度(T)、浊度(SS)、DO,并以出水总氮(TN)作为模型输出。

图4 累计方差贡献率Fig.4 Cumulative variance contribution rate
从某污水厂2021年6月至9月水质信息库共获取657组样本数据,部分采集数据见表3。其中200组数据作为测试数据用于检验模型性能,457组数据作为训练集用于预测模型训练。
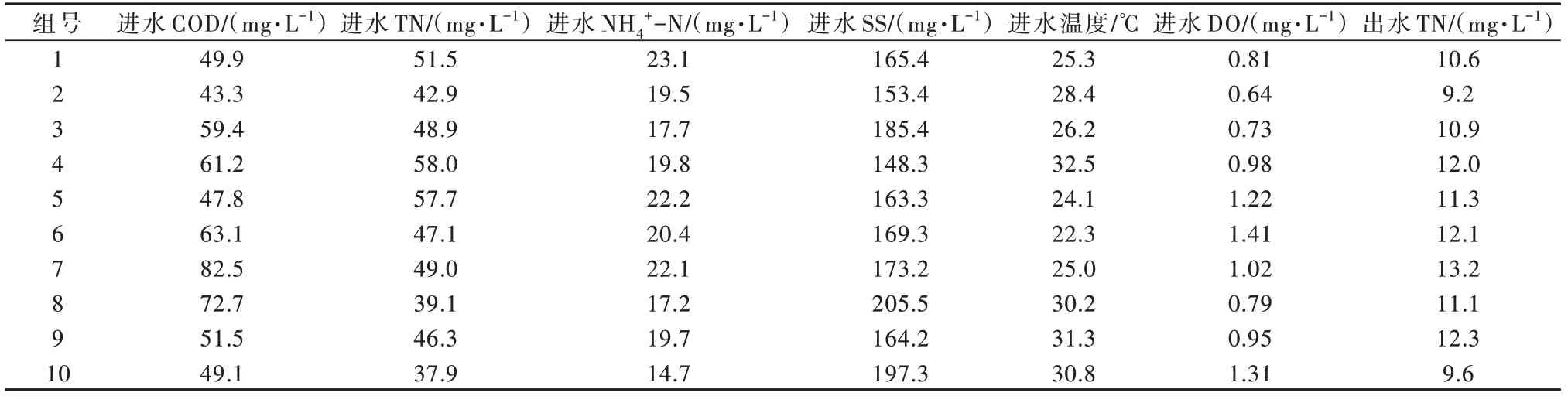
表3 部分采集数据Table 3 Part of collected data
样本数据通常不直接使用,因为不同类型数据的量纲不同;且样本数值波动较大时,不利于模型的学习训练。为消除特征向量间的量纲影响、保证模型运行速度以及提高预测精度,需对训练样本数值进行归一化处理。归一化公式见式(14)。

式中,x是任意一组样本的某一维数据,最大值用max(x)表示,最小值用min(x)表示,x′为归一化后的数据。
3.2 算法流程
步骤1:将经过预处理后的n组水质样本数据(x1,y1),(x2,y2),…,(xn,yn)归一化,并将其分为训练集和测试集2部分。
步骤2:对GNFA算法参数进行初始化设置,包括萤火虫数量M、初始吸引度β0、光强吸收系数γ、步长因子上下限αmax和αmin、最大迭代次数T。
步骤3:[c,σ]作为SVR的初始参数,也代表萤火虫的1个位置;将训练集样本作为SVR模型的输入,并输出预测集
步骤4:将预测值与实际值的均方根误差作为GNFA-SVR算法的适应度。
步骤5:判断终止条件,即当前迭代次数是否大于设置的最大迭代次数;满足终止条件执行步骤7,不满足则执行下一步骤。
步骤6:根据萤火虫的相对亮度决定下一个位置的移动方向并调整步长α;若目标位置劣于之前的位置,萤火虫位置保持不变,否则萤火虫进行位置更新,产生新的[c,σ],返回步骤3。
步骤7:将输出的最优解[c*,σ*]代入SVR预测模型,利用测试集检验算法的准确性和可靠性,评估预测模型性能。
3.3 污水厂出水TN预测
设置模型参数:萤火虫数目M=40,光强吸收系数γ=1.0,初始吸引度β0=0.8,步长因子αmax=0.8、αmin=0.1,最大迭代次数T=600,α变化停止阈值Th=10-3,惩罚因子c取值范围为[0.01,1 000],σ取值范围为[0.001,10]。在MATLAB R2018b环境下借助支持向量回归机工具箱运行GNFA-SVR模型。基于GNFA-SVR模型对测试集的出水TN预测结果见图5,GNFA-SVR可以较好地预测出水TN的实际值,预测误差较小。

图5 出水TN预测结果Fig.5 Prediction results of total nitrogen in effluent
为进一步验证3种算法在实际问题上对SVR算法的优化效果,现用GNFA-SVR、LFA-SVR和FA-SVR这3种预测算法对出水TN进行预测。部分测试样本的预测结果见图6,其中GNFA-SVR与LFA-SVR的模型参数设置同上;FA-SVR所需参数步长α=0.4,其他参数和GNFA-SVR算法设置一致。

图6 出水TN预测结果对比Fig.6 Comparison of predicted results of TN in effluent
从3种模型预测对比图(图6)可看出,3种模型的预测值与实测值的变化趋势基本一致,其中GNFA-SVR模型预测值与实测值拟合效果最佳,预测误差最小。
对3种模型的性能进行具体评估,采用平均绝对误差(MAE)、最大误差(Maxer)和均方根误差(RMSE)对预测结果进行评定,表达式见式(15)~(17)。
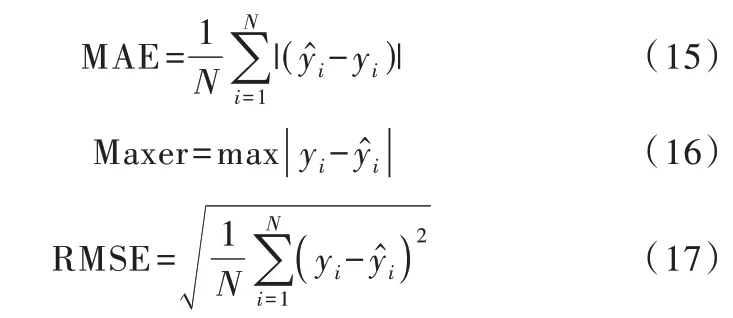
式中,N为样本总个数;为预测值;yi为实际值。
3种预测模型的评价指标见表4。

表4 不同预测模型的评价指标Table 4 Evaluation indicators of different prediction models
由表4可知,GNFA-SVR算法预测结果的各项指标均优于其他2种算法,其中MAE为0.352 1,预测误差控制在±0.5 mg/L以内可满足污水厂实际生产需求;RMSE较LFA-SVR算法与FA-SVR算法分别降低了29.7%、63.2%。说明GNFA-SVR组合模型在改进策略的优化下预测性能有所提升,可实现对出水TN的精准预测。
4 结论
针对污水处理厂出水水质检测存在大滞后性的问题,本研究提出一种基于GNFA-SVR算法的预测模型。在SVR算法基础上,引入萤火虫算法对其进行参数寻优。针对标准FA算法的步长不随迭代次数变化、易出现陷入局部最优的现象,提出基于高斯函数非线性递减步长策略,有效提高了算法的性能。通过对污水处理厂的实际数据进行仿真验证,GNFA-SVR算法在平均绝对误差、最大误差和均方根误差3个评价指标方面均明显优于LFA-SVR与FA-SVR算法,预测精度最高,误差控制在±0.5 mg/L以内,可实现对出水TN的精准预测,在实际水质预测方面具有良好的应用前景。
猜你喜欢
福建师范大学学报(自然科学版)(2022年2期)2022-03-16
成都信息工程大学学报(2021年5期)2021-12-30
西安邮电大学学报(2021年1期)2021-04-19
无线电通信技术(2019年4期)2019-06-25
领导决策信息(2018年16期)2018-09-27
小天使·一年级语数英综合(2018年7期)2018-09-12
小天使·一年级语数英综合(2017年6期)2017-06-07
数学学习与研究(2017年3期)2017-03-09
为了孩子(孕0~3岁)(2016年1期)2016-01-16
小天使·一年级语数英综合(2015年8期)2015-07-06
