
基于神经网络算法的水资源生态承载力智能监测方法
2022-10-25 13:17:18于国宝
水利技术监督 2022年10期
于国宝
(辽宁省朝阳水文局,辽宁 朝阳 122000)
当前我国水资源可持续发展的一项重要指标为水资源生态承载力,该指标也是学者们研究的一个热点话题。目前,仅对水资源生态承载能力进行研究的文献很少,而且多是将其纳入到城市可持续发展中分析。在国外,一般用压力指标、可持续用水量指标、水资源生态限度、水资源系统自然系统极限、水资源短缺程度等指标来表示类似的意义。根据我国目前的发展状况,现有的水资源生态承载能力研究多集中在水量方面。在保证水资源供求均衡的前提下,对研究区的可用水量进行了分析。
文献[1]提出了基于DPSIRM模型的水源地水资源脆弱性评价方法,在DPSIRM模型的基础上,提出了一种基于DPSIRM的流域水资源承载能力评估方法。然后,利用模拟退火算法求解各指标对水资源生态承载力的影响;文献[2]提出了基于区域水量-水质的水资源生态承载力研究方法,以水质为目标,建立了水资源生态承载能力评价指标体系,并对区域水资源承载能力进行了分析。上述2种方法只考虑了水质不合格,没有考虑到水环境纳污能力和生态需求。尽管已有学者从水质的观点出发,对水资源的生态承载能力进行了研究,但并未将其纳入到水质状况和水量状况中。为此,本文提出了基于神经网络算法的水资源生态承载力智能监测方法。
1 河道水环境纳污能力分析
依据水体污染负荷计算的相关规定,构建河流纳污能力数学模型。结合朝阳水文站具体情况,分别构建零维模型、一维模型、二维模型。对于零维模型的使用,是在污染物均匀混合情况下分析河流纳污能力;对于一维模型的使用,是在河流流量小于100m3/s情况下分析河流纳污能力;对于二维模型的使用,是在河流流量大于等于100m3/s情况下分析河流纳污能力[3]。
由于朝阳水文站的河流流量小于100m3/s,所以通过构建一维模型来分析河流纳污能力,公式为:
(1)
式中,ηR—河道水环境纳污能力,t/a;C1—河道下游污染物目标浓度值,g/L;C0—河道上游污染物目标浓度值,g/L;λ—污染物降解系数;L—河道长度,m;v—平均流速,m/s;q—河流流量,m3/s。
朝阳河流域的河流为中小河流,天然河流流量不大[4]。在短时间内,忽略横向、纵向污染浓度对污水排放口分布所造成的复杂问题,采用一维模型对朝阳河段河流纳污能力进行分析。
2 水资源生态承载力智能监测
2.1 水资源容量数据动态采集
以2017、2019年朝阳水文站数据为例,对水资源智能监测。
(1)2017年
2017年水资源智能监测步骤为:对降雨量自记仪器进行虹吸调试及浮子室清洗养护,养护后清洗20cm蒸发器及E601型蒸发器,做好缆道测流系统涂油养护检查及更换循环索,重新安装备用电源及电路改造,调试发动机,实现朝阳站汛前校测工作[5]。
在各项测验任务中严格按照规范操作,保质保量完成各项测验任务,全年实测流量103次,较大洪峰2次,分别于7月6日发生较大洪峰,水位99.92m,流量463m3/s;8月3日发生全年最大洪峰,水位101.34m,实测流量1100m3/s。全年共采沙65次,最大含沙量40.0kg/m3,发生在8月3日。
(2)2019年
2019年水资源智能监测步骤为:对降雨量自记仪器进行虹吸调试及浮子室清洗养护,养护后清洗20cm蒸发器及E601型蒸发器,做好朝阳站断面及水尺零点高程进行汛前校测和水准点校测工作,完成缆道系统调试、三索涂油、发电机维修养护、朝阳站铝合金窗户的密封维修及窗帘制作工作。
全年水文测验工作:1—8月实测流量64次,8月17日实测最高水位98.95m,最大流量85.4m3/s;5月26日,最大降雨量62.9mm。发送水情报文300余份。完成了松岭门、白腰、骆驼营子流量巡测任务,实测流量20余次;完成龙潭、六合成等9个墒情站巡测工作,发送墒情报文100余份。
2.2 水资源生态承载力模型构建
通过分析河道水环境纳污能力,结合2017、2019年朝阳水文站智能采集的数据,根据该区域河道实际污染情况,充分考虑生态用水需求,以河道水环境纳污能力为研究对象,保证生态需水量达到最低。选择一维模型计算朝阳河段河流纳污能力,分析可利用的生产、生活水资源数量,进而估算研究区域水资源的生态承载能力[6- 7]。
以人口规模和GDP规模衡量我国水资源承载能力,并以此为依据反映其人口承载能力与经济承载能力。以研究区可用水量、综合用水量、人均GDP为依据,对研究区水资源的可承载GDP和人口进行测算。构建水量-水质的水资源生态承载力模型,如图1所示。
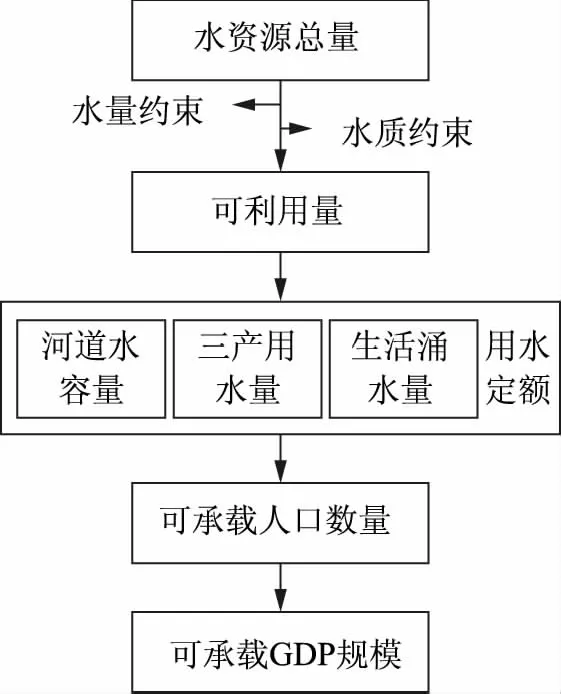
图1 水资源生态承载力模型
如图1所示,首先计算出最小的需水量,以保证该地区的生态环境不会受到损害。然后通过对水资源的限制,计算出可利用的水资源量。之后通过对水质的控制,对研究区的水环境容量进行计算[8- 10]。最后通过对地下水的综合利用指标,可以确定水资源生态承载力[11]。
2.2.1水量约束
根据河流的生态需求量,确定各流域的水资源限制条件。在维持河流流域生态环境所需的最小生态需水量基础上,保持河道基本生态环境满足该区域实际需求[12]。
在水资源短缺和用水紧张的区域,通常按“好”等级划分,并根据各节点的最小生态流量和径流特性,选择最佳生态环境。该环境下对应的流量百分比见表1。

表1 不同状况对应的流量百分比 单位:%
由表1可知,在河流年径流量中,河流的宽度、水深、流速都在30%以上。
2.2.2水质约束
水质约束是指每年排放到江河中的污染物总量不超过河道的环境容量,并根据河水的环境容量确定其在水质约束条件下的可用水量。根据河道水环境纳污能力ηR计算结果,确定河道纳污能力[13]。根据河道内主要河流污染负荷,确定污水排放系数,使污水排放不超过河道纳污能力。由于河道生态环境随气候和周围环境变化,因此河道水流变小会影响水环境容量,导致水资源生态承载力变化[14]。计算GB/T 23598—2009《水资源公报编制规程》中水资源总量,公式为:
W=ηR+q+q1
(2)
式中,q1—地下水资源量,m3。
为了满足河道需水量要求,对流域内的水环境容量进行了测算,并制定出了以水量、水质为基础的水资源生态承载能力3种方案,第1种方案为排水全用,全部排水都被用来纳污;第2种方案为排水半用,一半排水被用来纳污,另一半被用作供水;第3种方案为排水不用,全部排水都被用作供水[15]。
从水量-水质约束条件角度出发,分析了水资源生态承载力。充分考虑上述这3种水资源生态承载力,求取最优水资源生态承载力智能监测结果。为此,提出了基于神经网络算法的最优承载力计算方法。
2.3 基于神经网络算法的最优承载力计算
神经网络是一种前馈性的神经网络,通过该网络获取的结果是最优的,3层神经网络的结构如图2所示。

图2 神经网络拓扑结构
由图2可知,基于神经网络算法的最优承载力计算步骤如下:
步骤1:初始化神经网络,赋予网络连接权值;
步骤2:设置误差函数,随机选取k个输入采样及相应的预期输出结果,以获取运算准确度及最大学习次数;
步骤3:根据预期输出结果,确定输出层各个神经元偏导数;
步骤4:输出层中各神经元的连接权重由各神经元的输出结果进行校正;
步骤5:计算全局错误,判定错误是否低于设置的临界值,在错误的运算次数最多时终止,否则继续进行下一次学习;
步骤6:从下一轮学习中选取学习样本及对应的期望输出结果,在确定最大期望输出结果情况下,分析水资源生态承载力在3种方案下的监测指标,详细内容如下:
(1)对于方案1的监测指标,计算公式为:
(3)
(2)对于方案2的监测指标,计算公式为:
(4)
(3)对于方案3的监测指标,计算公式为:
(5)

通过上述分析结果可知,第3种方案应用效果最差,第1种方案和第2种方案水资源生态承载力比第3种方案大。但第1种方案没有考虑将河水流量作为供水水源,相比第2种方案,不利于水资源可持续发展。第2种方案在确保获取最小需水量情况下,将一半排水用作供水水源。
3 实验
3.1 实验背景
根据GB/T 23598—2009要求,朝阳水文局分析了河南郑州“7.20”特大暴雨灾害报告。全体职工从灾害特点、应对策略、相关部门单位责任问题、改进措施等方面进行深入剖析。河南郑州特大暴雨给当地居民生活带来严重危害,所以需要尽快制定措施,尽快修复电力和通讯设施,保障正常饮水和食品安全,恢复交通正常出行,对地铁等受损严重的场所要尽快恢复。水文作为水利战线的尖兵,防汛抗洪的耳目,在抗洪救灾中发挥着极其重要作用。
面对类似的强降雨天气,水文站要及时制定出安全策略,充分利用气象部门的应急体系,精准分析雨情、水情等水文数据。
3.2 实验数据采集
统计2022年水资源生态承载力数据,见表2。

表2 2022年水资源生态承载力数据
结合表2数据和上述研究的3种水资源生态承载力方案,统计理想情况下的数据,见表3。

表3 理想情况下2022年水资源生态承载力数据
由表3可知,第2种方案承载人口多和承载GDP规模大,在2022年可承载人口达到230万人,可承载GDP规模达到3325.22亿元。
3.3 实验结果与分析
通过上述分析结果可知,方案2水资源生态承载力最优,以此为研究对象,分别使用基于DPSIRM模型的水源地水资源脆弱性评价方法、基于区域水量-水质的水资源生态承载力研究方法和基于神经网络算法的水资源生态承载力智能监测方法,对比分析2022年水资源生态承载力各项数据,对比结果见表4。
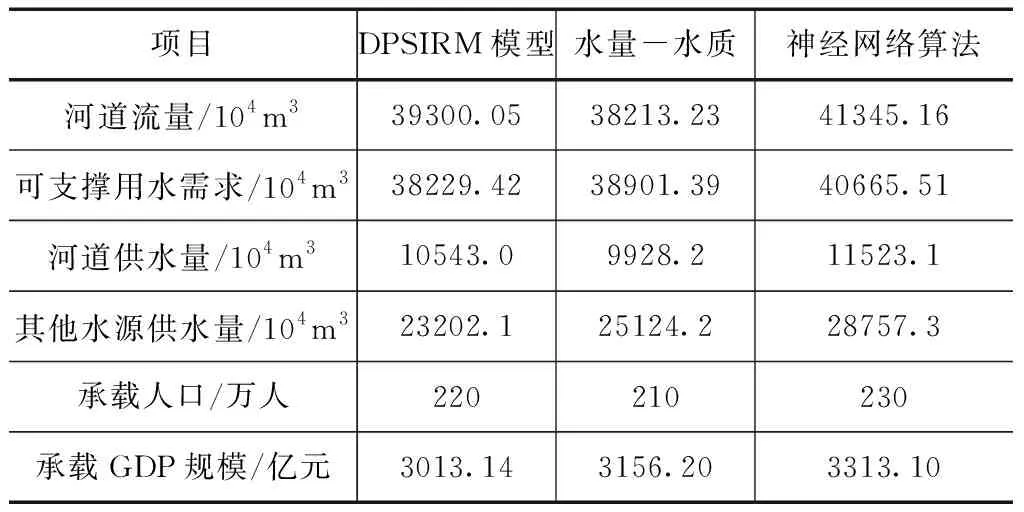
表4 3种方法水资源生态承载力各项数据对比分析
由表4可知,使用基于DPSIRM模型的水源地水资源脆弱性评价方法、基于区域水量-水质的水资源生态承载力研究方法,各项数据均与表2理想数值不一致。其中在承载人口和承载GDP规模两方面与理想数据分别存在10万人、20万人和312.08亿元、169.02亿元误差。使用基于神经网络算法的水资源生态承载力智能监测方法,各项数据均与表2理想数值基本一致,只是承载GDP规模与理想数据存在12.12亿元的误差。
为了进一步验证所研究方法的有效性,将上述各项数据作为输入数据,对不同方法使用的适应度值进行对比分析,对比结果如图3所示。

图3 3种方法适应度值对比分析
由图3可知,基于神经网络算法的水资源生态承载力智能监测方法,在监测时间为4个月时趋于稳定;使用基于DPSIRM模型的水源地水资源脆弱性评价方法和基于区域水量-水质的水资源生态承载力研究方法,分别在监测时间为8、10个月时才趋于稳定。
通过上述分析结果可知,使用基于神经网络算法的水资源生态承载力数据监测结果精准,且适应度值趋于稳定时长短,说明使用该方法收敛速度快,明显优于其余2种方法。
4 结语
基于神经网络算法的水资源生态承载力智能监测方法,利用神经网络算法克服传统方法存在的问题,获取承载力监测最优解,提高了收敛速度。因此,水资源生态承载力模型的构建解决了目前水资源生态承载力分析仅注重水资源的资源量的问题,从而丰富了水资源的生态承载力,提高了水资源的可持续利用能力。
下一步研究,仍需进一步分析收敛因子,努力提高寻优效率。而且有关分析的项目还不全面,所以接下来要分析由于天气、突发事件等原因造成的非规律用水需求,并综合考虑多种因素,以保证该监测方法的可行性和实用性。
猜你喜欢
小太阳画报(2019年4期)2019-06-11 10:29:48
作文周刊·小学二年级版(2018年21期)2018-09-06 11:00:08
散文诗(2018年20期)2018-05-06 08:03:44
现代园艺(2018年1期)2018-03-15 07:56:44
中国资源综合利用(2017年4期)2018-01-22 02:46:36
广西科技大学学报(2016年1期)2016-06-22 13:10:41
水利科技与经济(2016年10期)2016-04-26 08:40:30
少儿科学周刊·少年版(2015年11期)2015-12-17 20:49:15
浙江大学学报(工学版)(2015年2期)2015-05-30 07:04:46
中国舰船研究(2014年6期)2014-05-14 06:45:22
